
融合BERT与句法依存的性格识别方法研究
2023-09-25 08:55张忠林袁晨予陈丽萍吴奕霖
计算机工程与应用 2023年18期
张忠林,袁晨予,陈丽萍,吴奕霖
1.兰州交通大学电子与信息工程学院,兰州730070
2.中国科学院自动化研究所多模态人工智能系统全国重点实验室,北京100190
3.中国科学院大学人工智能学院,北京100049
随着社交媒体和电子商务的迅速发展,中国互联网络信息中心发布的第50 期《中国互联网络发展状况统计报告》中显示,截至2022年6月,我国网络购物用户规模达8.41亿,网络视频用户规模为9.95亿。这些用户可以在平台上对于产品、政策等发表评论、表达观点,海量的用户数据中蕴含了性格特征,深入挖掘评论及观点的语义、识别不同的写作风格、准确识别性格特点有助于商家及管理部门更好地理解受众兴趣、意图及反馈,快速做出决策,提升用户的满意度[1-3]。
现有基于文本的性格分析大致可分为两类。一类是基于心理学词典的方法[4-7],该方法利用心理语言学的先验知识,对文本中的词汇进行分类与统计,将不同的词汇归并到不同类别中,随后对各类别中词汇的频率进行统计以预测性格。基于心理词典的方法需要投入大量人力物力更新维护词典。另一类基于深度学习的方法[8-10],利用卷积神经网络或循环神经网络自动识别关联特征,并通过分类器进行性格识别。然而,基于深度学习的方法无法有效利用心理学特征词汇提供的额外语义线索进行性格识别。
近年来,预训练模型发展迅猛,为更好地学习深度语义提供了有效的机制。以BERT为例,其特征提取和双向的特征融合能力使其在大多数任务中取得了较好的效果。句法依存关系中,动词作为句子的核心,经常会与其他成分建立关联,LIWC(linguistic inquiry and word count)词典中动词和形容词的占比较高,包含了更多的性格线索。因此,如何进一步有效融合预训练模型与性格线索以提升性格识别的性能是性格识别亟须解决的关键技术挑战。
针对以上问题,本文提出了基于BERT与句法依存的性格识别模型BERT-SDFM(syntactic dependent fusion model),该模型利用词性标注(part-of-speech tagging,POS)对文本进行分词及词性标注,提取出在句法依存分析中处于句子主导地位的这类包含更多性格线索的心理学词汇,利用BERT分别学习文本和心理学词汇的表征向量,设计条件融合机制将额外的性格识别线索的向量表示作为条件编码嵌入到文本表示向量中,显示建模两者之间的依赖关系,以此利用额外的心理学先验知识提高性格识别的性能。最后通过全连接网络降维并预测性格,实现协同建模的性格预测。构建了面向中文电影评论的性格数据集,并实验证明了本文提出的模型在面向主题的社交媒体短文本上的性格识别的有效性。
1 相关工作
1.1 基于文本的性格识别数据集
目前基于大五人格理论,基于文本的性格识别数据集主要有Essays、MyPersonality、FriendsPersona 和Pandora。Essays由英文文章组成,每篇文章针对五个性格维度有一个二进制值,表示是否具备该性格特征,其次每个性格维度对应一个评分,表示对应性格得分;
MyPersonality(https://sites.google.com/michalkosinski.com/mypersonality)是由匿名Facebook用户的个人状态更新组成的一个集合,包含对应性格的评分;FriendsPersona(https://github.com/emorynlp/personality-detection)是从《老友记》电视节目的对话中提取的文本数据集,包含对话中人物五个性格维度的评分标签;Pandora(https://paperswithcode.com/dataset/pandora)是Reddit 评论数据集,包含基于大五人格理论、MBTI人格理论和九型人格理论的三种用户人格模型以及年龄、性别和位置的人口统计数据。
上述基于文本的性格识别数据集均是主题宽泛的多标签数据集,当前缺乏特定主题下用户评论的相关数据集,因此构建了两个面向主题的数据集以分析在特定主题下用户的性格。
1.2 基于心理学词典的性格识别
在早期的研究中,Pennebaker 等人[4]发现写作风格对于性格分析具有重要意义,随后提出了LIWC 方法,并发布了LIWC2001[5],该方法通过对文本中的词汇进行分类与统计,将不同的词汇归并到“功能词”(如:冠词、连词、代词)、“情感历程”(如:气愤、感恩、失望)和“认知行为”(如:理解、选择、质疑)等类别中,然后对各类别中词汇的频率进行统计分析以预测性格。此后,Boot 等人[6]和Pennebaker 等人[7]对LIWC 方法进行了改进并先后发布了LIWC2007和LIWC2015。为了方便用户在Web 上进行性格检测,Golbeck[11]开发了Receptiviti API,该接口提供了基于LIWC的性格分析工具,支持基于大五人格理论的可视化预测结果展示。在实际运用中,崔京月等人[3]利用LIWC 心理词典分析用户的性格及歌词偏好特征,发现歌词文本的关键词特征在一定程度上符合不同用户群体的人格特点。上述研究表明,心理学词汇与性格识别有着密切的关联,然而,基于性格词典的分析方法,词典的构建及维护需要投入大量人力物力,而社交文本中性格的表达具有多样性及动态变化的特点,仅依赖词典中的词难以动态捕获上下文语义信息,导致识别性能不佳。
1.3 基于深度学习的性格识别
1.3.1 词嵌入方法
词嵌入技术通过将词元转换为多维向量,以此解决独热编码稀疏问题,同时语义相近的词元会被相似的向量表示,这使得词向量会包含少量的语义信息。Word2Vec作为词嵌入技术的代表,Majumder等人[8]采用该技术对文本内容进行嵌入,然后通过CNN 进行性格识别。为进一步丰富词向量的语义表示,Pennington 等人[12]提出了GloVe(global vectors for word representation),一种基于大语料库的预训练词嵌入技术。Xue 等人[13]基于GloVe 对单词进行嵌入并结合BiGRU 形成包含文本语义信息的词向量,最后通过这些词向量进行性格识别。
1.3.2 神经网络及预训练模型
端到端的多层神经网络在文本的深度特征提取方面发挥了巨大作用。卷积神经网络CNN和循环神经网络RNN 作为最具代表性的两大深度学习架构,已经在许多自然语言处理任务中被成功地应用。Majumder等人[8]针对Essays数据集设计了独特的卷积神经网络用于从文本中提取文档级特征向量并进行基于大五人格的性格识别。Ren 等人[9]对比了CNN 和RNN 在性格分类任务中的表现,发现CNN 对于提取与位置无关的局部特征信息时的表现比RNN 更有优势,因此在性格识别与情感分类这类依赖关键词的任务中CNN表现得往往比RNN 更好。Darliansyah 等人[10]针对MyPersonality 数据集提出了融合CNN与LSTM的NNLM(neural network language model)模型,该模型充分利用卷积神经网络和循环神经网络的优点进行性格识别。
Transformer[14]通过多头注意力机制和前馈神经网络优化中文纠错、中文翻译、问答系统等seq2seq 任务。基于Transformer,谷歌提出了预训练模型BERT[15],该模型通过掩码机制和下句预测机制使其能获取双向语义信息,最终生成包含深层语义信息的词向量。Ren等人[9]针对Essays数据集,利用BERT模型提取文本语义信息形成句子级嵌入,同时结合了文本情感信息进行性格识别。Yang 等人[16]针对Pandora 数据集,通过基于BERT的多级文档编码(Transformer-MD)机制对长文本进行语义建模,并使用维度注意力机制进行性格识别。胡任远等人[17]提出基于BERT提取的文本语义信息融合目标领域多层次语义信息的情感分析方法。
上述方法针对Essays 和MyPersonality 等主题较为宽泛的数据集时,都仅使用文本进行语义建模。然而,在特定主题下的用户评论与用户日常动态或文章存在着明显的表达风格上的差异,例如在面向主题的情况下,用户使用修饰词例如程度副词、形容词等的频率会明显的提高,本文通过条件语义融合机制将POS有效融合到语义表示中,解决了当前性格模型无法利用POS作为辅助信息的问题,从而提高面向主题下短文本数据的性格识别性能。
通过使用预训练语言模型,捕获文本深层语义信息,充分挖掘社交媒体短文本中包含的用户性格特征,解决上述方法存在的针对短文本性格识别心理学词汇缺乏的问题,从而提高了短文本数据上性格识别的性能。
2 基于BERT与句法依存的性格识别模型(BERTSDFM)
2.1 模型设计
图1所示为提出的基于BERT与句法依存的性格识别模型框架图。主要包括基于预训练BERT 的语义编码层、融合文本和性格线索的语义交互层以及性格识别层三个主要部分。语义编码层通过BERT 对文本信息和句法依存提取到的蕴含性格特征的心理学词汇信息进行深层的语义抽取,分别形成包含二者全部语义的特征向量。语义交互层通过条件语义融合模型将心理学词汇中抽取出的包含性格线索的向量作为外部条件融合到文本的特征向量中。性格识别层采用融合后的特征向量对性格进行识别,解决单一BERT模型缺乏领域先验知识的挑战。
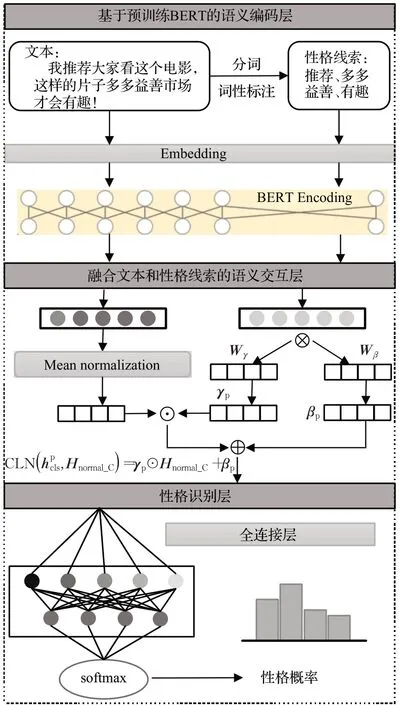
图1 BERT-SDFM模型Fig.1 BERT-SDFM model
2.2 基于预训练模型BERT编码层
BERT模型由多层Transformer构成,通过自动掩码机制和上下句预测任务,在无监督目标下对大规模语料进行预训练,有效学习文本潜在的深层语义、语法信息,获得蕴含丰富语义的文本表征。现有研究表明心理学知识及语言词性特征有助于提升性格识别性能[18],为了更好地挖掘性格,采用BERT学习文本和心理学词汇的向量表示,再通过微调的方法适应性格识别任务模式。
首先,对原始的文本数据进行预处理去除换行符、制表符等无意义的符号形成句子C,接着,通过词性标注与心理学先验知识提取文本中包含更多性格线索的动名词和形容词集合A={A1,A2,…,Ai} ,将A中的单词进行拼接形成句子P,最后采用预训练模型BERT分别对句子C和P进行向量化处理,计算每个单词的上下文表示,得到对应的词向量矩阵,表示为HC和HP。
2.3 融合文本和性格线索的语义交互层
基于上述生成的文本和性格线索特征向量,为了更好地体现二者之间深层次的语义交互,挖掘动态交互语义,设计了融合文本和性格线索的条件语义交互模型,该模型将性格线索特征向量作为条件信息,动态生成文本向量的增益和偏置,通过条件融合函数将增益和偏置集成到性格文本表示中,获得词性特征对于性格文本语义的影响程度,一定程度上解决单纯编码文本信息,无法感知文本中重要词性特征的不足,如图2所示。

图2 融合文本和性格线索的条件语义交互模型Fig.2 Conditional semantic interaction model combining text and part-of-speech features
首先对文本词向量矩阵HC中的每个词向量进行标准差归一化,其中,μ和σ代表每个词向量的均值与方差。其次采用条件融合函数CLN 将性格线索特征向量和标准差归一化后的文本词向量矩阵Hnormal_C融合,得到文本和性格线索动态语义交互的条件融合矩阵Hm。Hnormal_C的条件增益向量γP和条件偏置向量βP,分别由增益效果控制矩阵Wγ和偏置效果控制矩阵Wβ与性格线索特征向量相乘,并与各自的偏置值bγ和bβ相加得到,Wγ、Wβ、bγ和bβ均在模型训练中动态学习。
2.4 性格预测层
如图3,为了进行性格预测,将条件融合矩阵Hm按词向量维度求取平均形成条件融合向量he,并输入到负责性格识别的全连接网络并输出性格识别向量ho,随后对ho进行池化后得到性格概率向量hŶ。
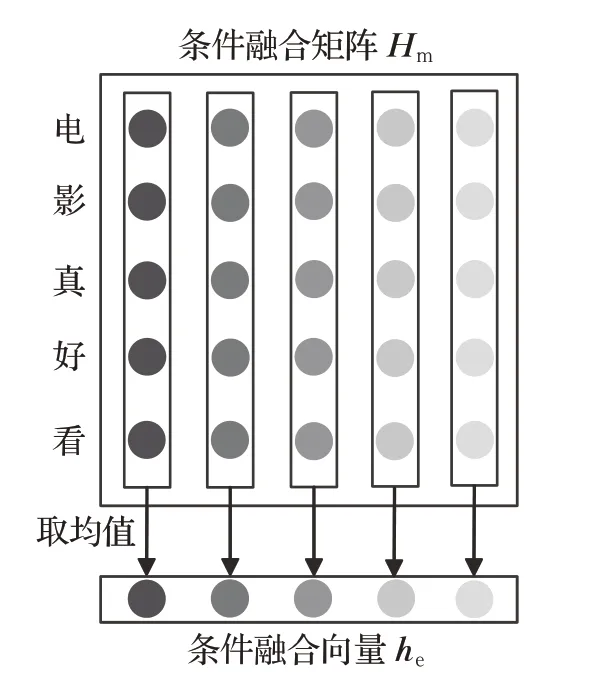
图3 条件融合矩阵降维Fig.3 Dimensional reduction of conditional fusion matrix
其中,W表示性格特征学习矩阵,b表示偏置值,softmax表示池化函数。
最后,采用交叉熵损失函数对模型进行优化:
3 实验与分析
3.1 实验环境
本文采用ubuntu18.04 操作系统,GPU 为A100,采用pytorch深度学习框架。
3.2 实验数据
针对现有面向主题的性格识别研究工作中公开数据集稀缺的问题,本文构建了面向都市爱情电影《爱情神话》和面向悬疑剧情电影《扬名立万》的性格数据集。
《爱情神话》性格数据集采集了从2021 年12 月到2022年6月,豆瓣电影、微博、西瓜视频的6 534条评论数据。
《扬名立万》性格数据集采集了从2021 年11 月到2022 年10 月,豆瓣电影、西瓜视频、抖音、时光网的4 225条评论数据。
将存在缺失、重复、乱码、中文繁体等问题的数据进行删除及简化等预处理,对数据长度太短(<5)不能有效表达性格的以及数据长度太长(>350)导致表达冗余的数据进行清除,分别得到4 493 条、3 167 条数据。删除不能体现性格的数据,例如“义乌小伙儿亚历山大为观众留下了深刻的印象。”以及“2022 年春节,济南,和家人”等陈述性评论数据。
根据大五人格性格领域词典,结合所采集电影的场景和数据,选取了大五人格中的四类性格作为标签进行标注,分别为开放性、宜人性、责任心、神经质。四种性格的描述如表1所示。

表1 性格描述Table 1 Description of personality
为了保证人工标注数据的准确性,借鉴文献[19-20]中的标注方法,邀请2 名熟悉性格领域的同学按照表1性格描述对数据进行标注。采用在心理学、社会学等常用一致性评价方法Kappa 系数[21]检验数据标注的一致性。两个数据集上标注一致性Kappa系数分别为0.71、0.73,表明数据标注的一致性很高,最终得到2 331 条、2 202条实验数据,数据集采集信息如表2所示。

表2 实验数据集Table 2 Experimental dataset
对保留的数据进行特征统计,《爱情神话》数据长度分布如图4(a)所示,分布较不均衡。《扬名立万》数据长度分布如图4(b)所示,与《爱情神话》数据集相比分布趋于均衡且数据长度分布范围小。

图4 数据长度分布Fig.4 Data length distribution
两个数据集中的性格分布如表3所示,宜人性和开放性数据占比较高,责任心和神经质数据量较少。对标注后数据进行整理、合并后,按照7∶2∶1划分训练集、验证集和测试集,进行实验测试。

表3 性格数据分布Table 3 Distribution of personality data
3.3 评价指标与参数设置
为了更好地度量模型的性能,采用准确率A(Acc)、精确率P(Precision)、召回率R(Recall)、F1 作为评价指标,其中,将F1 作为主要评价指标。计算公式如下:
其中,TP表示实际为正向、模型预测结果也为正向的样本,FP 表示实际为负向、模型预测结果为正向的样本,TN 表示实际为负向、模型预测结果也为负向的样本,FN表示实际为正向、模型预测结果为负向的样本。
本文模型BERT-SDFM 采用Google 预训练好的“BERT-Base-Chinese”中文模型,该模型采用12层Transformer,模型总参数大小为1.1×108,批次大小设置为8,学习率为2E-5,最大序列长度355,优化器为Adam。
3.4 基准方法描述
采用TEXTCNN、BERT、BERT-SDM作为基准方法:
(1)TEXTCNN[22]:基于词嵌入向量,经过卷积池化预测性格分类,模型结构简单,运行高效。通过预训练的词嵌入初始化权重。设置3 个大小为2、3、4 的滤波器,卷积核的数量为256。
(2)BERT[15,23]:利用预训练模型中Transformer 结构可并行、可叠加的优势,高效准确地捕获深层语义信息,提高性格预测能力。BERT 首先将句子输入到模型中,得到每个词的嵌入维度为768,再通过12层的Tansformer encoder结构得到富含句法语义特征的词特征向量。将[CLS]位置的特征向量作为句子的全局表示,然后使用全连接层对其进行降维,用softmax得到性格分类结果。
(3)BERT-SDM:利用开源工具LAC[24]得到文本中的词性特征作为条件信息与原始文本信息拼接。利用BERT 对拼接后的文本进行编码,使用全连接层对文本表示进行降维,用softmax得到性格分类结果。
3.5 实验结果与分析
3.5.1 实验结果
表4所示,对于《爱情神话》数据集,与基于预训练的词嵌入,通过卷积、池化等实现性格语义的表示与识别的TEXTCNN 方法相比,预训练系列的BERT 方法在精确率、召回率、F1、准确率各指标上均得到了提升,其中,精确率从0.582 7提升到了0.654 6,召回率从0.594 3提升到了0.635 2,F1 从0.578 1 提升到了0.638 6,准确率从0.583 7 提升到了0.659 4,体现了预训练方法获得深层次语义表示能力对于提升性格预测性能的有效性。在预训练系列方法中,通过在BERT上引入句法依存等先验特征信息,BERT-SDM进一步提升了BERT方法在各类指标的性能,以F1 为例,从0.638 6 提升到0.643 9,证明了融合句法依存对性格识别的有效性。提出的BERT-SDFM 方法进一步采用先验信息条件语义融合模型改进了句法依存信息的融合方式,在精确率、召回率、F1、准确率指标上均取得了最优的效果,分别为0.666 7、0.644 0、0.651 8、0.673 1,表明了挖掘性格语义与句法依存间的动态交互有助于捕获更深层次的语义信息,进而提升了性格分析效果。

表4 实验结果Table 4 Experimental results
对于《扬名立万》数据集,与TEXTCNN 方法相比,预训练系列的BERT方法的各指标同样得到了提升,其中精确率从0.560 8 提升到了0.664 4,召回率从0.545 6提升到了0.641 8,F1 值从0.544 3 提升到了0.647 0,准确率从0.581 8提升到了0.665 7。由于《扬名立万》短文本居多,简单的拼接不能更好地融合句法依存关系,引入先验特征信息后的BERT-SDM 方法在较短数据集中表现不佳。BERT-SDFM方法采用条件融合机制得到了最优结果,指标分别为0.669 0、0.653 6、0.657 0、0.674 8。
采用拼接方法融合句法依存信息后,BERT-SDM方法进一步提升了BERT方法在各个指标的性能。在《爱情神话》数据集中BERT-SDM 的F1 值和BERT 基准相比,分别从0.638 6 提高到了0.643 9。证明了句法依存信息对于《爱情神话》数据集效果更明显。而在《扬名立万》数据集中,简单拼接难以将句法依存关系更好地与文本信息融合,BERT-SDM在部分短文本预测中表现稍弱。
本文提出的BERT-SDFM 模型在两个数据集下,各项指标在BERT-SDM基础上得到了较大提升,F1值分别为0.651 8和0.657 0,准确率值分别为0.673 1和0.674 8。验证了句法依存关系的有效性和模型的识别能力。
3.5.2 句法依存关系的影响
为了避免模型在小数据量的情况下出现过拟合,保证最终结果的稳定和正确以及寻找在不同主题电影数据中最能体现性格的句法依存关系,采用K折交叉验证对两个数据集进行十折划分,将十次实验的评价指标取平均值作为了最终的评价指标。在划分的数据集上分别进行预训练模型在不同句法依存关系下的实验,实验结果如表5所示,表中数据均为十折交叉验证取平均后的结果。在《爱情神话》数据集上,BERT模型的F1值达到了0.638 6。在BERT-SDFM模型上,形容词和动名词的句法依存关系达到了最优,F1值为0.651 7。在《扬名立万》数据集上,与《爱情神话》数据集相比,BERT的F1值从0.638 6 提高到了0.647 0,表明《扬名立万》数据集中性格表现更加分明。形容词和动名词的句法依存关系同样达到了最优,F1值为0.657 0。

表5 句法依存关系在十折交叉验证中对F1值的影响Table 5 Effect of syntactic dependency on F1 values in ten fold cross validation
图5展示了句法依存关系对F1值的影响,对比了在两个数据集中不同句法依存关系组合的效果。形容词和动名词组合的句法依存关系在两个实验数据中,均取得了最好的性格识别效果。
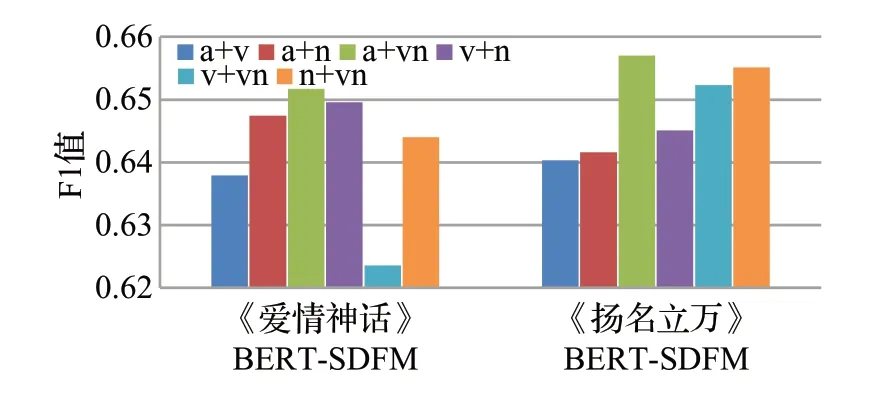
图5 句法依存关系对比Fig.5 Comparison of syntactic dependency relationship
与其他组合相比,F1值最高,达到了0.651 7和0.657 0。动名词是具有名词功能的一种动词,实验结果表明了形容词和动名词的句法依存关系在文本性格识别问题中更为重要。因此,选择形容词和动名词的句法依存关系作为BERT-SDFM模型的句法依存关系。
BERT-SDFM 在两个数据集中都取得了最好的效果,充分体现了模型的性格识别能力。表明了挖掘性格语义与句法依存信息间的动态交互有助于捕获更深层次的语义信息,进而提升了性格分析效果。
4 结束语
本文针对基于BERT模型在性格识别任务中缺乏心理学先验知识的技术挑战,提出了基于BERT与句法依存的性格识别模型(BERT-SDFM)并将其应用于性格识别任务中。在构建的面向中文电影评论的性格数据集上与TEXTCNN、BERT、BERT-SDM进行实验对比,实验结果表明所提模型BERT-SDFM具有更好的性格识别效果。未来工作会进一步完善数据集,对提出的方法进行更细致的测试,尝试将情感、主题等更多维度的特征融合到提出的模型框架中,深入研究不同要素之间的关联影响。
猜你喜欢
中华诗词(2021年3期)2021-12-31
小哥白尼(野生动物)(2021年2期)2021-07-16
大连民族大学学报(2021年2期)2021-07-16
开放教育研究(2020年2期)2020-03-31
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
现代语文(2016年21期)2016-05-25
中学生(2015年31期)2015-03-01
大连民族大学学报(2015年2期)2015-02-27
海外英语(2013年1期)2013-08-27
