
基于偏自相关分析和残差修正的径流量GRU预测模型
2023-09-23 13:55严春华姜中清高志发
水力发电 2023年9期
严春华,张 玥,姜中清,梅 杰,高志发
(江苏省水利勘测设计研究院有限公司,江苏 扬州 225000)
0 引 言
径流量预测是洪水预报的关键环节,对于水库大坝、堤防、水闸等水利工程的安全稳定及正常运行有着至关重要的作用,关系到流域人民生命财产安全[1]。随着人工神经网络和深度学习的发展,基于数学模型的径流量预测的研究成果也越来越多,如王军等基于TCN-Attention模型对黄河径流量进行预测[2],李代华构建了基于PCA-SHO-SVM和PCA-SHO-BP模型进行径流预测[3]。这些组合模型可以较好地实现对径流量的预测,但忽略了径流量的时间序列的滞后性和误差累积,从而导致误差的增加和收敛速度的下降。因此,需要综合考虑组合模型的特性,进一步深度研究算法的优缺点,进而构建高精度和稳定性的径流量预测数学模型。
为了解决径流量时间序列的滞后性,本文引入偏自相关函数进行研究[4]。偏自相关函数在处理时间序列数据时可以研究监测序列和本身的k阶滞后序列两者的相关性,从而得出径流量序列对某时刻的影响作用程度。在智能学习算法中,目前以神经网络模型(如CNN、RNN和LSTM等网络)的预测能耐较好,其缺点为运算时间长,如果训练和预测集过大的话,迭代速度会大大减慢、收敛时间长。为了解决和克服常用神经网络算法的缺点,2014年Cho等[5]优化了LSTM算法模型,构建了GRU算法模型,借助设置隐藏层提高训练学习的速度。GRU相比于LSTM网络优化了网络参数,计算收敛速度更快,并且两个算法预测精度相差不大,所以本文选择GRU网络构建径流量预测模型。为了进一步地提高径流量预测模型的精度,需要解决预测过程中的误差修正问题。由于径流量的非稳定性,任何模型模拟出的径流量均具有一定偏差,并且误差的积累是一种非线性问题,而1998年Huang等[6]提出了一种可以较为高效地解决非线性与非平稳信号时频分解难题的方法——经验模态分解(EMD),因而采用EMD方法对残差部分进行预处理。该处理时间序列的方法被广泛运用到很多研究领域并有不错的结果精度,如测绘空间定位[7]、风力预测[8]、军事雷达[9]、工程爆破[10]研究等领域。因此,本文提出了以GRU为主要建模手段的径流量预测方法,采用偏自相关方法确定时滞步长的前处理和EMD进行误差修正的后处理,分别解决径流量预测中存在的收敛速度慢、时序滞后性和误差积累的问题。通过工程案例以及和其他预测模型进行对比,验证了该径流量预测模型的精度和可靠性。
1 径流量预测模型构建的基本理论及实现流程
1.1 径流量时间序列相关性确定方法
为了寻取径流量时间序列的滞后特性,采用偏自相关分析方法,并通过分析结果分析输入量与预测值之间的关系[11]。偏自相关函数主要研究yt和yt+k之间的相关性,而排除了它们之间元素yt+1,yt+2,…,yt+k-1对yt的影响,其表达式如下[12]
(1)
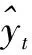
1.2 GRU时序预测模型基本原理
GRU模型保留了LSTM模型的基本网络构造,同时增加隐藏层,模型的基本架构由细胞状态、更新门和重置门组成,该算法模型架构如图1所示。
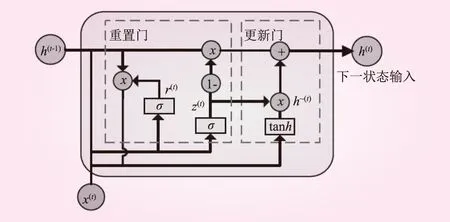
图1 GRU网络模型的架构
GRU算法的隐藏层的输入由上一个时间节点的隐藏层状态输出h(t-1)和当前时间序列实际输入x(t)组成。模型内部的更新门z(t)和重置门r(t)是优化时序预测模型的内部结果和减少参数数量的关键组成部分[13]。
更新门的作用是对当前时间节点输入值的梯度判断,与LSTM算法输入门的功能基本一致,能够极大程度克服梯度消失的难题,其门结构为
z(t)=σ(Wz·h(t-1)+Uzx(t)+bz)
(2)
式中,σ为激活函数,一般是sigmoid函数;Wz、Uz分别为更新门结构中的权重;bz为更新门结构中的偏置。
重置门的作用是判断前一时间节点隐藏层状态的h(t-1)对当前时间节点的x(t)的影响程度。如果程度不大,从而打开重置门,其门结构为
r(t)=σ(Wr·h(t-1)+Urx(t)+br)
(3)
式中,σ为激活函数,一般是sigmoid函数;Wr、Ur分别为重置门结构中的权重;br为重置门结构中的偏置。
确定更新隐藏层中的细胞状态。细胞状态的更新由更新门与重置门的输出确定,其中隐藏层状态中最右侧的h~(t)为
h~(t)=tanh(W(r(t)∘h(t-1))+Ux(t)+b)
(4)
式中,tanh为该部分的激活函数;W、U分别为更新h~(t)结构中的权重;b为更新h~(t)结构中的偏置。
当前时间节点隐藏层的输出h(t),结合更新门的输出更新细胞状态得到当前时间节点隐藏层的输出h(t)
h(t)=(1-z(t))∘h(t-1)+z(t)∘h~(t)
(5)
计算预测值的输出是对当前时间节点的预测值输出,则输出门的输出为
y(t)=σ(Vh(t)+c)
(6)
式中,V、c分别为权重参数及偏置。
1.3 EMD基本理论
EMD是一种自适应分解法,把具有时序特性的信号分解成不同频率特征的本征模态函数(Intrinsic Mode Function,IMF)和一个长期趋势项。EMD法根据原始信号的上包络线和下包络线的均值求解瞬时均值,进而实现对原始信号的特征分解[8]。给定原始数据信号xt,EMD法的实现基本分为5个步骤。
第1步,求解原始信号xt的上包络线u(t)与下包络线l(t)。计算xt中所有的局部极值点,再采用三次样条插值法对极值点插值处理,从而得到原始信号的上下包络线。
第2步,计算瞬时均值。把第1步得到的上包络线u(t)和下包络线l(t)取均值,即为瞬时均值m(t),
(7)
第3步,把原始信号xt减掉瞬时均值m(t),可得新序列f1(t),
f1(t)=xt-m(t)
(8)
第4步,得到IMF分量一定要有两个条件:其一为序列f1(t)的局部极值点与过原点的个数的差值必须是0或1;其二为任何时刻,瞬时均值都为0。基于构成IMF的条件对序列f1(t)进行判别,如果达到IMF特征条件,序列f1(t)为IMF分量;如果序列f1(t)达不到条件,把f1(t)作为原始信号序列重复步骤1到3,一直分解得到的序列满足IMF的特征条件。而且设置c1(t)=f1(t),得到信号xt和c1(t)的差值,从而一阶残差量为r1(t),再把残差量作为原始信号重复步骤1到3。
第5步,当有第1个IMF分量f1(t),使c1(t)=f1(t),把原始信号xt减掉c1(t)可以得到1个残差量r1(t),为
r1(t)=xt-c1(t)
(9)
上述5步完成了EMD法的首次信号分解。进一步地,把残差量r1(t)重新重复上述步骤从而可以分解得到若干个IMF分量。当第n个残差量rn(t)只有单个极值点或者为单调序列时分解停止,EMD分解流程结束。
原始信号xt经过分解可以得到若干IMF分量为
(10)
式中,fi(t)为分解的第i个IMF分量;rn(t)为第n次分解的残差量;n为原始信号的分解次数,同时是分解得到的IMF分量数。
1.4 径流量预测模型实现步骤
综上理论,构建基于GRU的径流量预测模型,该模型的基本实现流程如下:
第1步,确定径流量序列的训练学习集和预测集。
第2步,通过偏自相关性方法确定径流量序列的时滞步长。
第3步,基于GRU算法进行学习训练,输出径流量预测值。
第4步,提取残差并基于EMD分解后利用GRU对各分量进行残差修正。
第5步,并与其他常用算法对比,验证本文模型预测结果的精度和模型的可靠性。
2 案例分析
2.1 径流量监测数据提取
将某河流的径流量采集数据作为本章方法的建模对象,研究时段为2015年1月1日至2019年12月31日,共计5 a,该时段的径流读取频次为每日一次,其径流量原始数据如图2所示。在进行建模分析时,首先需要对径流量数据进行数据集的划分,本文以2015年1月1日~2018年12月31日4年的日径流量数据作为训练样本集,2019年1月1日~2019年12月31日1年的日径流量数据作为测试样本,以分析提出的径流量预测模型的有效性。
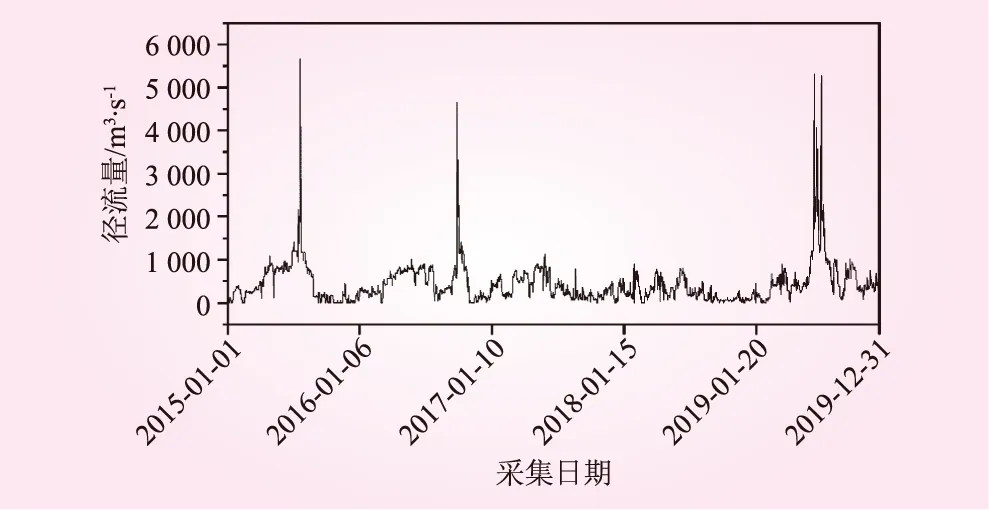
图2 径流量原始变化数据
2.2 径流量时间序列相关性分析
由理论部分可知,对河流径流量建立GRU模型进行径流时序特性分析之前,首先应当确定时间序列的时滞步长,这对于正确建立历史径流量与当前径流量之间的关系具有重要意义。若是确定的时滞步长过小,则不足以有效建立径流量的时序关系;若是时滞步长过大,则将增加过多无用信息,GRU模型在学习径流量时序关系时的效果也将变差。因此,本文按照理论部分提出的偏自相关分析方法进行时滞步长确定,若将径流量的当前时刻确定为t,本案例中分析了t-1,t-2,t-3,…,t-12共计12个时间点处径流量与当前时刻径流量之间的偏自相关性,如图3所示。
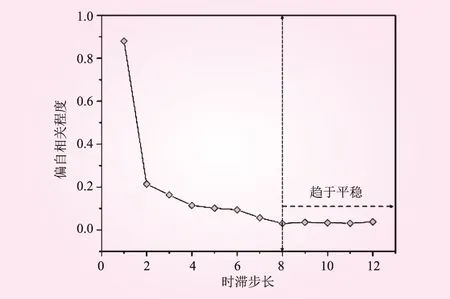
图3 相关性分析
由图3可以看出,当径流量时间序列的时滞步长小于8时,历史径流数据与当前径流量之间的相关性是逐渐下降的;当时滞步长的取值大于8时,历史径流数据与当前径流量之间的相关性趋于平稳且处于较低相关程度。因此,在后面的时序建模中,将时滞步长的取值确定为8。
2.3 GRU建模分析和残差提取
通过2.2节设定的径流量时间序列时滞步长,可以对原始径流量时间序列进行GRU建模。在此过程中,以2015年1月1日~2018年12月31日4年的日径流量数据作为训练样本集,2019年1月1日~2019年12月31日1年的日径流量数据作为测试样本,即训练集样本数和测试集样本数的比例为4∶1。首先通过训练集样本训练GRU模型,然后将训练完成的模型应用在测试集上,则径流量GRU模型在测试集上的分析结果如图4所示。
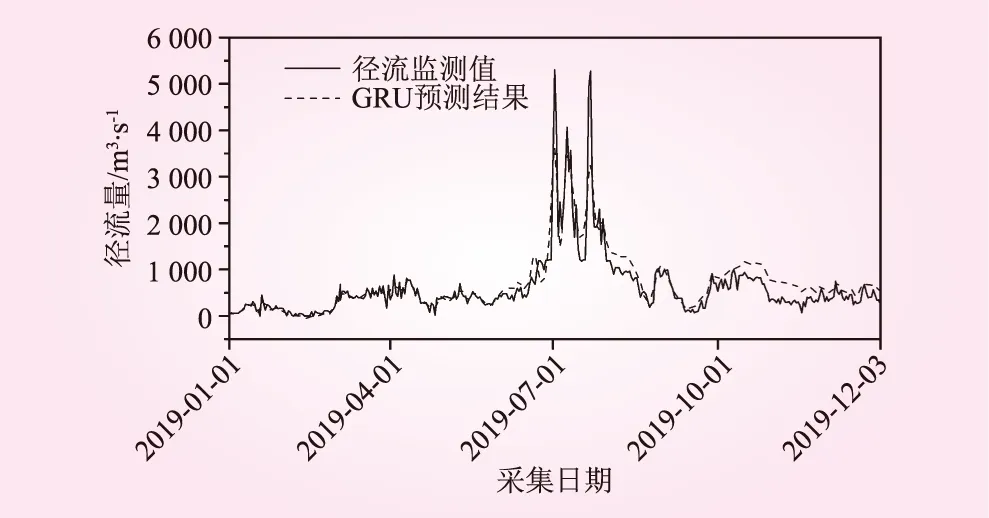
图4 基于GRU模型的径流量预测结果
通过图4可以看出,该方法能够大体模拟径流量的变化趋势,然而由于径流量波动性较大,导致分析结果不能够准确估计其波动性,因此,本文提出了残差修正的方法对训练集部分拟合残差进行进一步分析,训练集部分拟合结果如图5所示,由此得到的径流量残差如图6所示。

图5 基于GRU模型的训练集径流量拟合结果
2.4 径流量预测结果的残差修正
由理论部分可知,本小节主要针对GRU分析结果残差进行修正,目的是得到更为准确的径流量预测结果。首先采用EMD方法对上图中的径流量残差进行分解,从而降低径流量残差序列的复杂性以提升建模分析结果的精度,EMD分析结果如图7所示。
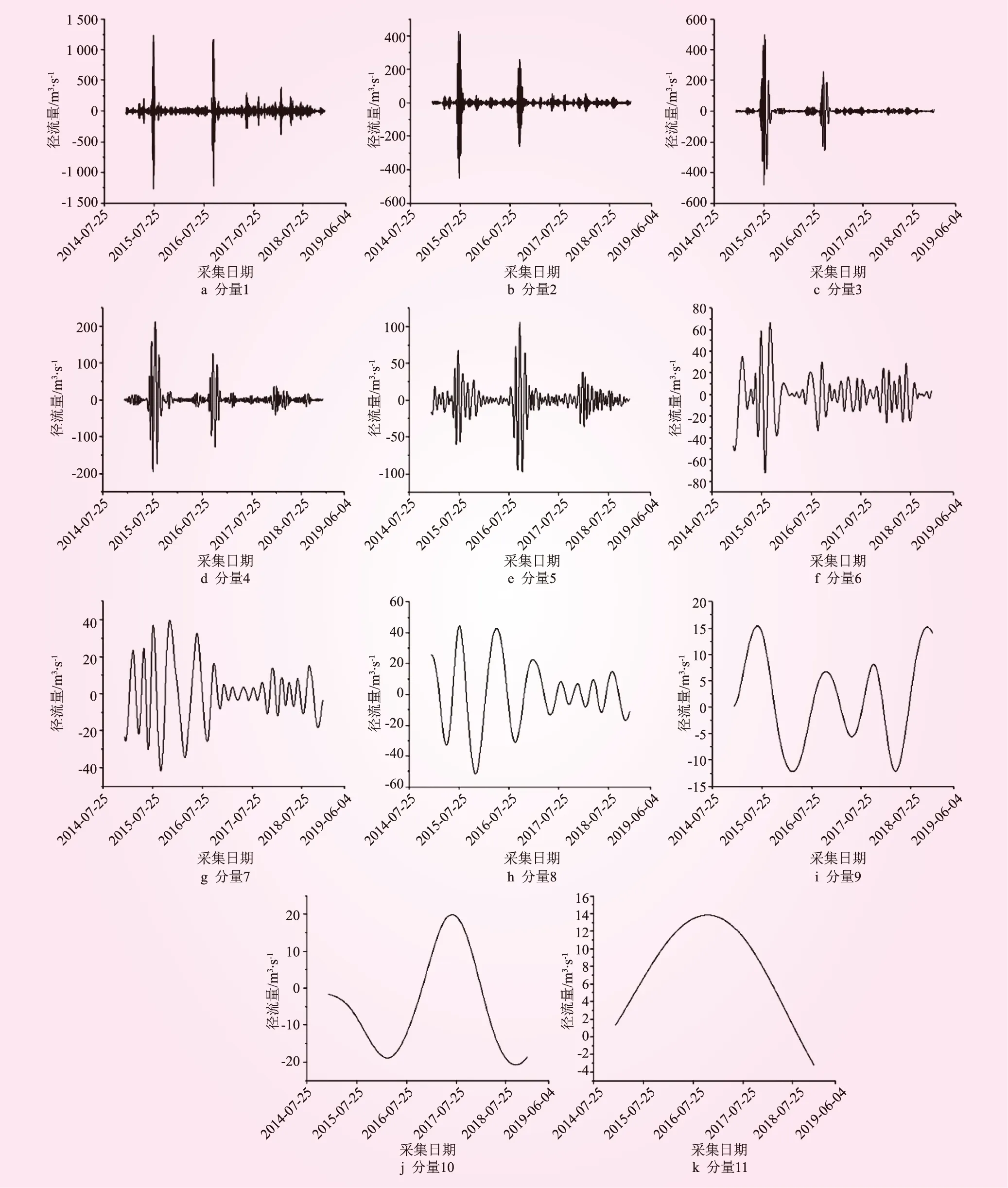
图7 基于EMD的径流量残差分解结果
由图7可以看出,径流量残差经过EMD处理后,原本具有很强不规则特性的残差变成了具有不同变化频率的残差分量,这对于残差建模分析提供了基础。与直接对径流量包含残差的建模分析相比可知,通过对具有较低频且规律较为明显的分量进行建模,更容易学习其包含的径流量信息,残差修正的效果更明显。通过对径流量各残差(IMF1~IMF11)分别建立GRU模型,并对各GRU模型的预测结果进行综合得到最终的径流量预测结果,如图8所示。
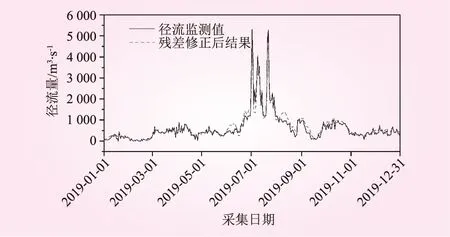
图8 基于残差修正的径流量预测结果
对比图4和图8径流量测试阶段的预测结果,很显然在经过残差修正后,径流量的预测结果更加接近径流量真实值,分析结果的波动性较之残差修正之前也更接近真实值,验证了本文提出的径流量预测方法的有效性。
2.5 模型对比分析
上文已分析得到基于偏自相关分析和残差修正的径流量预测模型的预测结果,为说明该方法在径流预测领域的优越性和可靠性,选取ARIMA和LSTM这2种常用的时间关系分析模型进行对比说明。其中在建立上述2个模型时,径流数据集的划分同上述案例。3种模型的预测结果对比如图9所示。
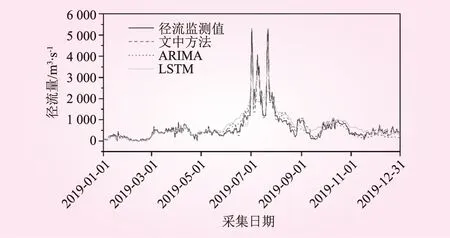
图9 3种方法径流量预测结果
由图9可以看出,ARIMA的预测结果较为平滑,且与径流量的真实值相差甚远;而具有时序学习能力的LSTM方法相对来说具有一定模拟原始径流量波动程度的能力,相比之下文中方法预测结果与真实的径流量变化过程一致,径流预测精度高。上述3种方法分析得到的径流量预测结果残差对比图,如图10所示。由图10可以看出,ARIMA的预测误差明显是最大的,甚至在某些时间内其误差高达3 000 m3/s,说明该模型并不适合应用于径流量预测问题;LSTM相对误差较小,而文中提出的方法径流量预测结果误差最小。3种方法径流量预测结果评价指标如表1所示。从表1可以看出,文中方法分析得到的径流量预测结果对应的RMSE值和MAE值是3种方法中最小的,其R2值也明显优于另外2种方法。以上关于3种方法的对比分析说明了本文所提出方法的优越性,这为洪水预报提供了高可靠度的技术支撑。
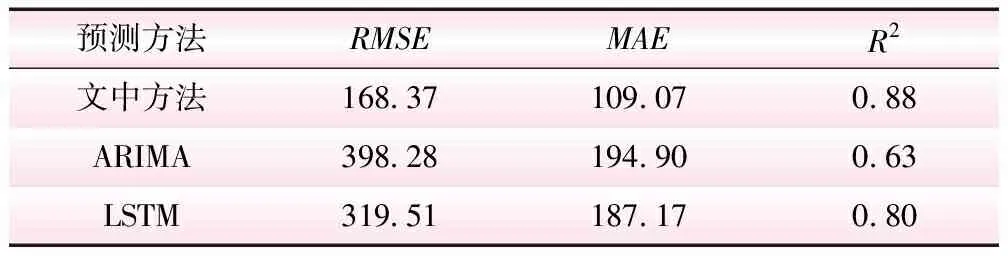
表1 3种方法径流量预测结果评价指标
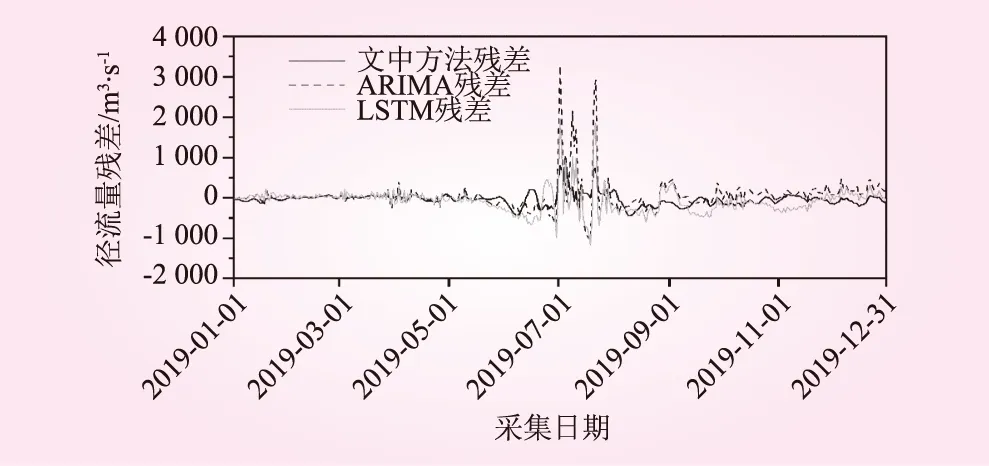
图10 径流量预测结果残差对比
3 结 论
本文通过偏自相关方法的前处理和EMD误差的后处理,构建了基于GRU模型的径流量预测模型,其结论如下:
(1)基于GRU模型的径流量预测结果更接近于径流量真实值,计算结果的波动性更接近真实值,预测误差更小,说明该模型的工程实用性高。
(2)通过与ARIMA和LSTM预测模型的对比表明该模型的优越性,验证了该径流量预测模型的有效性和可靠度,对洪水预报提供了有力的技术支撑。
(3)由于本文采用的是固定时滞步长,而河流在不同时间下的步长是变化的,可以进一步研究动态滞后步长对预测值的影响。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
成都信息工程大学学报(2021年5期)2021-12-30
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
水利规划与设计(2017年5期)2017-06-09
河南科技(2015年8期)2015-03-11
河北科技大学学报(2015年5期)2015-03-11
水土保持通报(2014年5期)2014-06-09
电测与仪表(2014年2期)2014-04-04
湖南水利水电(2014年3期)2014-02-27
