
融合隐性社交网络社团划分和协同过滤的推荐算法
2023-09-23 02:00:02孙海岗李玲娟
南京邮电大学学报(自然科学版) 2023年4期
孙海岗,李玲娟
(南京邮电大学 计算机学院,江苏 南京 210023)
推荐系统作为一种能够根据用户习惯及兴趣进行信息过滤和推送的系统,可以在很大程度上弥补搜索引擎的不足,解决信息过载问题[1]。
协同过滤是个性化推荐系统中应用最为广泛的技术之一[2]。 基于用户的协同过滤算法UserCF 是推荐系统的经典算法之一,该算法依据与目标用户有相似行为的“近邻”对项目的兴趣来预测目标用户的兴趣[3]。 虽然传统的协同过滤算法已得到广泛应用,但是仍存在对数据稀疏敏感、可扩展性差等缺点[4]。 针对这些问题,国内外学者已经对传统的协同过滤算法进行了改进。 文献[5]提出了基于SVD 模型的协同过滤算法,使用更加稠密的隐向量表示用户和物品,虽然能在一定程度上降低协同过滤对评分矩阵稀疏的敏感性,但是容易过拟合且计算量大,可扩展性仍有待提高。 文献[6-9]通过对用户进行聚类提高了推荐准确度,但可扩展性仍有待提高。 文献[10-11]提出了基于社交网络的协同过滤算法,虽然能在一定程度上提高推荐的准确性,但是需要用户之间的显式社交关系,然而在一些系统(如电影推荐系统)中并不具备这些信息。 总之,各种算法都一定程度上提升了推荐准确性,但是如何使推荐算法的性能得到全面提升,仍是需要深入研究的问题。
本文设计了一种融合隐性社交网络社团划分和协同过滤的推荐算法(Recommendation Algorithm Integrating Implicit Social Network Community Division and Collaborative Filtering,ICDCF)。 该方法先对用户做社团划分,再实施基于用户的协同过滤推荐。在社团划分阶段,将用户对项目的共同兴趣视为社交关系,利用改进的Jaccard 相似系数衡量用户间的社交关系强弱;再基于相似度构建用户隐性社交网络(即基于兴趣关系的社交网络);并进一步基于谱聚类思想对隐性社交网络进行用户社团划分;最后在划分的社团内进行协同过滤推荐。 在MovieLens-100K 和FilmTrust 数据集上与其他算法的对比实验结果验证了ICDCF 算法能同时提高准确性和可扩展性。
1 相关知识
1.1 基于用户的协同过滤推荐算法UserCF
UserCF 算法的框架如图1 所示。
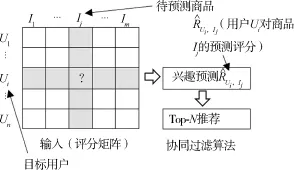
图1 UserCF 框架
算法的输入是记录了用户对项目历史评分的评分矩阵,其中{U1,U2,…,Un}表示用户集,{I1,I2,…,Im}表示项目集。 首先,根据用户的历史评分记录,使用相似度计算方法,为目标用户找到具有相似兴趣的最近邻居集;然后通过最近邻居对项目的评分,预测目标用户对未评分项目的评分;最后根据预测结果,选出评分高的前N个项目进行推荐[12]。随着用户数、项目数的增长,用户对项目的评分矩阵变得稀疏,会产生用户相似度计算不准确、计算开销大等问题。
1.2 相似度计算方法
UserCF 算法的核心是用户间相似度计算。 常用的计算方法有欧几里德距离、Jaccard 相似系数、余弦相似度和皮尔逊相关系数等。 本文涉及到其中的皮尔逊相关系数和Jaccard 相似系数。
(1) 皮尔逊相关系数
皮尔逊相关系数的计算如下
其中,sim(i,j)表示用户i和用户j之间的相似度,Iij表示用户i和用户j共同评分的项目集合,Ri,c和Rj,c分别表示用户i和j对项目c的评分,分别表示用户i和j对项目评分的均值。
(2) Jaccard 相似系数
Jaccard 相似系数的计算如下
其中,sim(i,j)表示用户i和用户j之间的相似度,Ii和Ij分别表示用户i和用户j已评分的项目集。
皮尔逊相关系数的计算依赖于用户共同评分的项目集,如果用户共同评分的项目集较小,则存在一定的偶然性,不能为目标用户提供准确的预测。Jacccard 相似度系数通过用户整体评分信息进行相似度计算,可以有效避免此类问题。
1.3 谱聚类与社团划分
谱聚类[13]算法以数据集中的样本为顶点,以样本间的相似度为顶点间连边的权值,构建出无向加权图,将聚类问题转化为图的最优划分问题,划分出的子图内的边权和尽可能大,子图间的边权和尽可能小。 它能对任意形状的样本空间聚类并能收敛于全局最优解。 其总体步骤如下:
(1) 计算被聚类样本的相似度矩阵W,该矩阵映射了无向加权图;
(2) 计算拉普拉斯矩阵并求解其前k个最小的特征值与特征向量,构建特征向量空间,将高维空间的数据映射到低维空间;
(3) 利用经典的聚类算法对特征向量空间中的特征向量进行聚类。
社团划分旨在从社会网络中发现模块化的社团结构,社团内节点连接紧密,社团间节点连接疏远[14]。 社会网络可以用由节点和边构成的网络图表示,因此社团划分也被称为图聚类[15]。 不难看出,谱聚类与社团划分的目标是一致的,因此适用于社团划分。
2 ICDCF 算法设计与分析
2.1 设计思路
本文设计融合隐性社交网络社团划分和协同过滤的推荐算法ICDCF 的出发点是:减少因稀疏的评分矩阵中用户共同评分项目少使相似度计算不准确而给推荐准确性带来的负面影响,以及搜索近邻计算量大对协同过滤推荐时间效率的负面影响,使推荐准确性和可扩展性都得到提升。
针对UserCF 算法搜索近邻时相似度计算开销大的问题,考虑采用先对用户做社团划分,再在社团内进行协同过滤推荐的策略。 将用户对项目的共同兴趣(共同评价项目的情况)视为社交关系,用相似度表示关系的强弱,以用户为节点,以用户相似度为连边的权值,构建无向加权的隐性社交网络。 由于谱聚类算法适用于社团划分,并且能体现节点间关系的强弱,因此考虑基于谱聚类思想进行社团划分。
针对稀疏的评分矩阵中共同评分项目少,使得所计算的相似度不够准确而影响最终推荐准确性的问题,做了两方面考虑:(1) 构建隐性社交网络时,用Jaccard 相似系数计算用户相似度,而在后续协同过滤的近邻搜索阶段,采用皮尔逊相关系数计算相似度,通过两者互补使相似度更准确;(2) 对Jaccard 相似系数加以改进,不仅考虑用户间是否有共同评分的项目,还考虑当用户间无共同评分项目时,在分别与其有共同评分项目的用户之间是否存在交集,以便更全面准确地反映用户间可能存在的兴趣关系,进一步提高用户相似度的准确性。
2.2 ICDCF 算法的总体流程
融合隐性社交网络社团划分和协同过滤的推荐方法ICDCF 的总体流程如图2 所示。

图2 ICDCF 总体流程
总体上,ICDCF 算法包括3 大部分:(1) 隐性社交网络构建;(2) 社团划分;(3) 协同过滤推荐。 各部分具体设计如下。
2.3 隐性社交网络构建
(1) 相似度计算方法设计
构建隐性社交网络是进行基于谱聚类社团划分的基础,而相似度计算又是构建无向加权隐性社交网络的关键,必须采用合适的相似度计算方法。
按照2.1 节所述思路,本文将用户关系分为“好友”、“间接好友”、“不相关用户”3 种。
定义1好友:具有共同评分项目的用户互为“好友”。
由于用户对项目的反馈信息可以在一定程度上表示用户的兴趣,如果用户i和用户j对相同项目进行了评分,可以认为两者的兴趣存在相似性,因此本文将他们视为“好友”。
定义2间接好友:没有共同评分项目但有共同好友的用户互为“间接好友”。
如果用户i和用户j没有共同评分的项目,即不是“好友”,但与他们有共同评分项目的用户存在交集,即两者有共同的好友,基于好友的好友可能成为好友的思想,将用户i和用户j视为“间接好友”。
定义3不相关用户:既没有共同评分项目,也没有共同好友的用户为“不相关用户”。
为了全面衡量上述的用户间的关系,本文对Jaccard 相似系数做了改进,改进的Jaccard 相似系数如式(3)所示。
其中,Ii和Ij分别表示用户i和用户j已评分的项目集合,Ni和Nj分别表示用户i和用户j的好友集合。对照定义1 至定义3,可以看出:自上而下依次为好友的、间接好友的和不相关用户的相似度;好友之间的相似度高于间接好友,不相关用户的相似度为零。
(2) 构建隐性社交网络
基于评分矩阵,用式(3)计算用户相似度,构建用户相似度矩阵,该相似度矩阵可视为社交网络的邻接矩阵W,如式(4)所示,其中,wij表示节点i和节点j之间连边的权值(即边权),wij=S(i,j)。
矩阵W映射着一个无向加权的隐性社交网络,该网络的每个节点对应一个用户,相似度不为零的用户i和j(i≠j) 所对应的节点之间都有连边,即好友和间接好友之间都有连边,边权取值为相似度。
2.4 社团划分
按照2.1 节所述思路,ICDCF 用谱聚类思想对隐性社交网络进行社团划分,具体流程如下。
输入:无向加权隐性社交网络的邻接矩阵W和社团划分数目k。
输出:k个社团。
步骤:
Step1 计算矩阵W的度矩阵D
其中,di为节点的度,
Step2 用式(6)计算拉普拉斯矩阵L。
Step3 计算L的特征值,取前q个最小特征值{λ1,λ2,…,λq},并计算特征值所对应的特征向量{f1,f2,…,fq}。
Step4 将q个最小特征值对应的特征向量作为列,组成n×q阶矩阵Fn×q ={f1,f2,…,fq}。
Step5 令yi为Fn×q第i行向量,yi作为节点i的指示向量,其中i =1,2,…,n。
Step6 用K-means 算法对新样本集Y={y1,y2,…,yn}聚类,产生k个簇C1,C2,…,Ck。
Setp7 分别以簇C1,C2,…,Ck中指示向量所对应的网络节点集合构成k个社团S1,S2,…,Sk。
2.5 协同过滤推荐
按照2.1 节所述思路,ICDCF 在社团内实施基于用户的协同过滤推荐,推荐流程如下。
输入:评分矩阵、社团集{S1,S2,…,Sk}、推荐数N。
输出:Top-N个项目。
步骤:
Step1 在目标用户u所属的社团内,用式(1)计算u与其他用户的相似度。
Step2 基于相似度找到与目标用户u最相似的lu个近邻用户。
Step3 用式(7)基于最近邻的预测方法预测用户u对项目i∊I(I为近邻用户已评分而用户u未评分的项目集)的评分
Step4 按预测评分的降序对项目进行排列,选取Top-N个(即前N个)项目推荐给目标用户。
2.6 ICDCF 算法时间复杂度分析
假设用户数量为n,ICDCF 在构建隐性社交网络的过程中,需要按式(3)计算每个用户与其他用户的相似度,时间复杂度为O(n2)。 在社团划分过程中,时间复杂度主要集中在拉普拉斯矩阵的特征分解和K-means 聚类,矩阵特征分解的时间复杂度可以近似看作O(n3);K-means 算法的时间复杂度为O(nkt),k表示聚类数目,t表示聚类中心的迭代次数,k和t通常可以看作常量。 因此,K-means 的时间复杂度也可以近似看作O(n)。 ICDCF 在实施基于UserCF 的Top-N推荐时,需要按式(1)计算目标用户和其所在社团内各用户的相似度,时间复杂度为O(l),l为目标用户所在社团的用户数量,l≤n。 实际上,隐性社交网络的构建和社团划分过程属于系统模型训练部分,只需要在系统空闲时定时执行,不影响推荐过程。 因此,ICDCF 算法实时推荐的时间复杂度可以近似看作O(l)。
3 实验与结果分析
为了检验ICDCF 的性能, 在经典数据集MovieLens-100K 和FilmTrust 上做测试实验,并与UserCF、基于用户聚类的二分图网络协同推荐算法[9](在以下图表中简称为“基于用户聚类”)和基于K-means 的协同过滤算法(在以下图表中简称为“基于K-means”)进行对比。
3.1 实验数据
MovieLens-100K 数据集[16]由Minnesota 大学的Grouplens 项目组提供。 该数据集由943 个用户、1 682部电影以及100 000 次评分组成,数据稀疏程度为93.695%。 每条记录包含user_id、item_id、rating、timestamp 四个字段,分别对应用户标识、电影标识、评分值和评分时间。
FilmTrust 数据集[17]是在2001 年从FilmTrust 网站爬取的。 该数据集由1 508 个用户、2 071 部电影以及35 497 个评分组成,数据稀疏度为98.863%。 每条记录包含userId、moviId 和movieRating 三个字段,分别对应用户标识、电影标识和评分值。
3.2 评价指标
实验中以平均绝对误差MAE 和推荐速率F为性能指标,分别评价ICDCF 的准确性和实时性。 此外,通过测试数据集规模增大时推荐速率F的变化情况,评价其可扩展性。
(1) 平均绝对误差MAE
MAE 是评价推荐准确性的常用指标之一,反映预测评分与用户实际评分的差异,计算公式如下
其中,pi表示算法所产生的目标用户对项目i的预测评分,qi表示目标用户对项目i的实际评分,N表示已为目标用户预测评分的项目数量。 MAE 值越小,则预测准确性越高,推荐效果越好。
(2) 推荐速率F
推荐速率F是指单位时间内的推荐次数,具体计算公式如下
其中,R为推荐次数,T为推荐所用的时间,F值越大,则实时性越好。
3.3 实验结果分析
实验时将数据随机分成5 份,依次选取其中的1 份作为测试集,其余4 份作为训练集,共进行5 次测试,以5 次测试结果的均值作为最终结果。
3.3.1 准确性测试与评价
(1) 最近邻居数增加时MAE 的变化情况
实验中设定社团个数为5,最近邻居数以10 为单位逐渐增加。 测试结果如图3 所示。
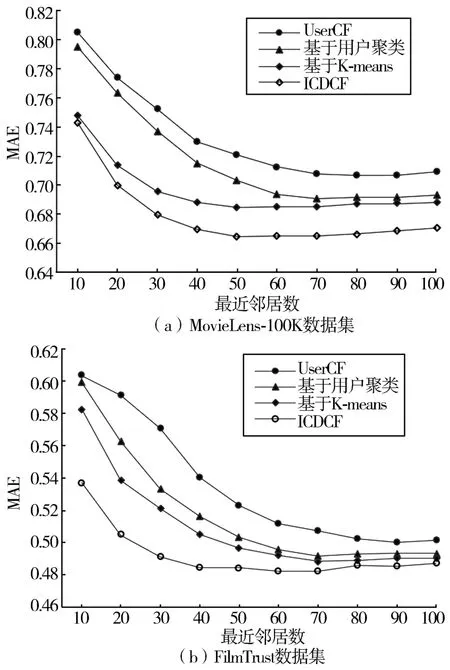
图3 最近邻居数增加时MAE 的变化
可以看出:①在两种数据集上,随着最近邻居个数的增加,4 种算法的MAE 值都是先呈现下降趋势,然后趋于稳定,而在邻居数增加到一定量后又略有回升(如邻居数为100 时,回升已比较明显)。 这是因为随着最近邻居数量的增加,在预测评分值时可以有更多的参考项,预测出来的值也更接近真实值;但邻居数过多也会因有些邻居参考价值不高而形成干扰。 ②ICDCF 算法的MAE 值始终最小,并且从最近邻个数为30 时开始趋于稳定。
(2) 不同社团个数下MAE 的变化情况
实验中最近邻居数设为图3 中效果较好时的30,社团个数以1 为单位逐渐增加。 测试结果如图4 所示。

图4 不同社团个数下MAE 的变化
可以看出:①没有社团划分环节的传统UserCF的MAE 值保持稳定且最高。 随着所划分的社团个数的增加,基于用户聚类的二分图网络协同推荐算法、基于K-means 的协同过滤算法和ICDCF 算法的MAE 值略有波动,在社团数增加到一定量(如MovieLens-100K 数据集上划分为6 个社团)后呈现略微回升的趋势。 ②在两种数据集上,ICDCF 算法的MAE 值始终最小,并且当社团为某个数量(如在FilmTrust 数据集上划分为5 个社团)时,ICDCF 算法的MAE 值最低,推荐准确性达到最高点。 这说明社团个数不是越多越好,因为协同过滤推荐在社团内进行,社团划分过细,可能会使有价值的参考项流失于社团外。
(3) 不同数据集规模下MAE 的变化情况
实验中最近邻居数设为30,社团个数设为5,数据量分别为MovieLens-100K 和FilmTrust 数据集的20%、40%、60%、80%和100%。 测试结果如表1所示。
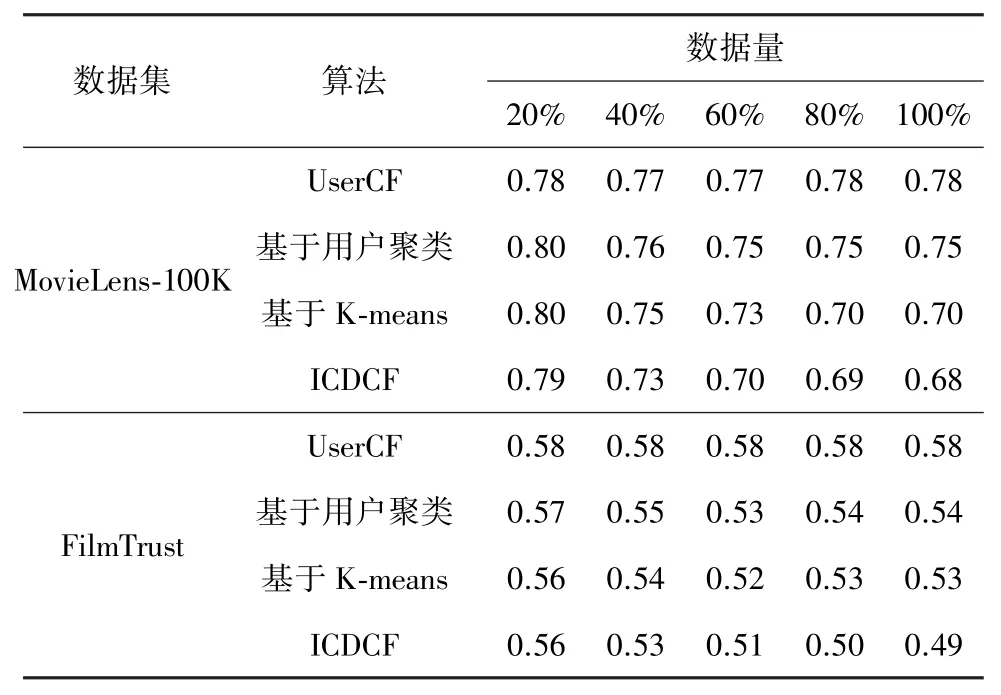
表1 不同数据规模下MAE 的变化情况
可以看出:①随着数据量的增大,UserCF 算法的MAE 值相对稳定,而基于K-means 的协同过滤算法和ICDCF 算法的MAE 值呈下降趋势,并且ICDCF 算法的MAE 值始终保持在更低水平。 ②随着数据集的不断增大,基于用户聚类的二分图网络协同推荐算法和基于K-means 的协同过滤算法的MAE 值已经趋于稳定,而ICDCF 算法的MAE 值依然呈下降趋势。
综合各种情况,4 种算法中ICDCF 算法的准确性最高,并且合理设置最近邻个数和社团个数将能更充分地发挥其优势。
3.3.2 实时性与可扩展性测试与评价
(1) 不同社团个数下推荐速率F的对比
实验中最近邻居数设定为30,在基于K-means的协同过滤算法中,社团个数就是其聚类个数。 测试结果如表2 所示。
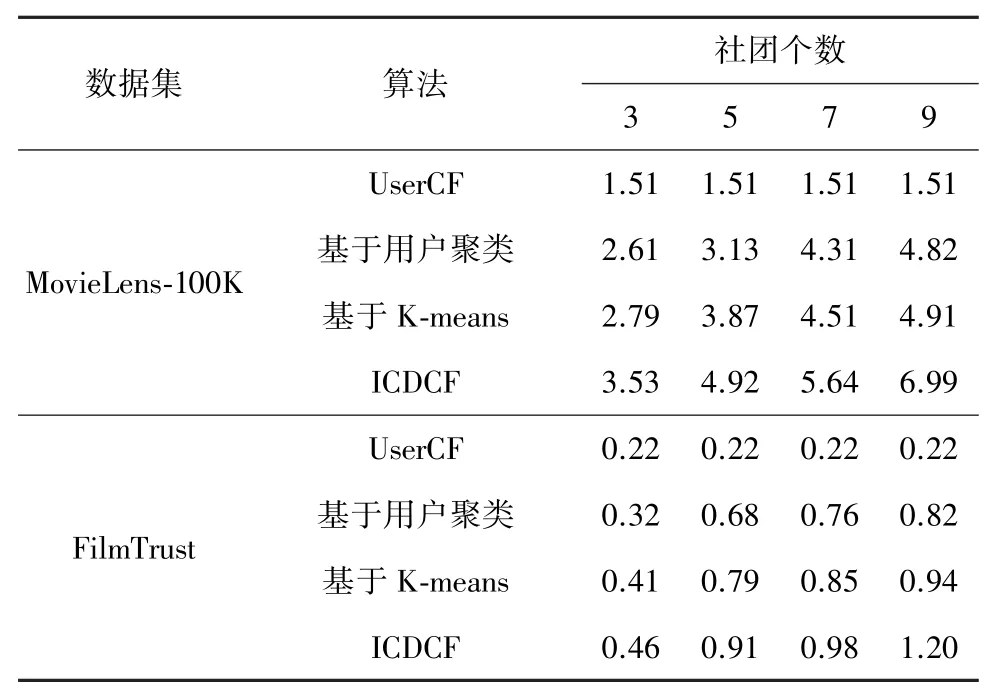
表2 不同社团个数下推荐速率F 的对比 千次/s
可以看出:没有社团划分环节的传统UserCF 的推荐速率最低,并且与社团划分数量没有关系;ICDCF 算法的推荐速率最高,而且随着社团个数的增加,ICDCF 速度提升更明显。 这是因为随着社团划分数目的增加,单个社团所包含的用户数量更少,搜索目标用户最近邻居集的迭代次数更少。 需要说明的是,根据以上对准确性测试结果的分析,在实际使用中,社团个数的选择需兼顾准确性,并不是越多越好。
(2) 不同数据集规模下推荐速率F的对比
实验中最近邻居数设为30,社团个数设为5,数据量分别为MovieLens-100K 和FilmTrust 数据集的20%、40%、60%、80%和100%。 测试结果如表3所示。

表3 不同数据量下推荐速率F 的比较 千次/s
可以看出:①数据量增大时,ICDCF 在两种数据集上都体现出了速率上的优势。 ②随着数据量的增大,4 种算法的推荐速率均呈下降趋势,但是相较于UserCF、基于用户聚类的二分图网络协同推荐算法和基于K-means 的协同过滤算法,ICDCF 下降的幅度更小。 在MovieLens-100K 数据集上,当数据量从20%增加到100%时,UserCF 的推荐速率下降幅度为73.22%,基于用户聚类的二分图网络协同推荐算法为61.45%,基于K-means 的协同过滤算法为54.30%,而ICDCF 算法仅为43.77%。 在FilmTrust数据集上,当数据量从20%增加到100%时,UserCF的推荐速率下降幅度为80.18%,基于用户聚类的二分图网络协同推荐算法为78.20%,基于K-means 的协同过滤算法为77.99%,而ICDCF 算法为69.87%。
综合表2 和表3,ICDCF 算法具有更好的实时性和可扩展性。 此外,在准确性测试表1 中,ICDCF方法的MAE 值随着数据量的增大持续变小(准确性增高),也从另一个角度说明了ICDCF 方法有更好的可扩展性。
4 结束语
本文综合运用Jaccard 相似系数、皮尔逊相关系数、隐性社交网络、谱聚类和基于用户的协同过滤思想,设计了融合隐性社交网络社团划分和协同过滤的推荐算法ICDCF。 通过对Jaccard 相似系数加以改进并用于衡量用户兴趣关系和构建隐性社交网络,以及基于谱聚类思想对隐性社交网络进行用户社团划分,并在社团内进行基于用户的协同过滤推荐,不仅有效地避免了由于稀疏的评分矩阵中用户间共同评分项少而导致的相似度计算不准确问题,还减少了搜索近邻的迭代次数。 在MovieLens-100K和FilmTrust 两个数据集上与其他算法的对比实验结果,验证了ICDCF 算法具有更高的准确性、实时性和可扩展性,实现了性能较为全面的提升。
猜你喜欢
阅读(中年级)(2022年9期)2022-10-08 01:56:16
反歧视评论(2019年0期)2019-12-09 08:52:40
小雪花·初中高分作文(2019年10期)2019-02-12 09:08:52
军事文摘(2017年16期)2018-01-19 05:10:15
杂文月刊(2017年20期)2017-11-13 02:25:06
中学生(2016年13期)2016-12-01 07:03:51
新闻传播(2015年14期)2015-07-18 11:14:05
新闻传播(2015年8期)2015-07-18 11:08:25
世界科学(2014年8期)2014-02-28 14:58:30
高中生·青春励志(2009年4期)2009-04-21 05:17:16
