
基于深度学习的稠油蒸汽驱汽窜时间预测方法
2023-09-22 03:58崔传智陆水青山吴忠维盖平原刘廷峰
深圳大学学报(理工版) 2023年5期
崔传智, 陆水青山, 吴忠维, 盖平原, 刘廷峰
1)中国石油大学(华东)非常规油气开发教育部重点实验室,山东青岛 266580;2)中石化胜利油田分公司石油工程技术研究院,山东 东营 257099
蒸汽驱往往伴随着汽窜现象的发生,汽窜通道的形成严重影响稠油油藏的开发效果[1-2].实时可靠的稠油井汽窜时间预测方法可以为及时采取防治措施提供支持,提高稠油油藏的开采效果.
对于电子版文本,只需将其格式转换成txt格式即可入库。对于无电子版资源的纸质语料,我们首先对其进行扫描,然后经过OCR软件的识别、格式转换和人工去噪等环节后,对最终文本进行入库处理。其中,非双语版的汉语语料还要进行人工翻译和校对后方可入库。鉴于语料的收集、转换、去噪、翻译、校对等环节十分烦琐复杂,因此需要采集团队格外细致与耐心,才能保证语料的真实性和有效性。在此之后,双语语料将通过Anticonc软件进行对齐处理。
由于独立学院学生英语底子薄、学习积极性不强,视听说课堂活动流于形式,教学效果不佳。为充分调动学生积极性,提高其听说能力,优化视听说教学设计尤为重要。
国内外学者对汽窜时间开展了相关研究.示踪剂监测法和试井分析法等传统的汽窜识别方法所需时间长,成本高,且一定程度上会影响油田的正常生产[3-4].动态分析法由于具备现场数据获取方便和成本低等优势,已成为蒸汽窜流通道判别的主流方法,并且生产动态数据的波动性能够很好地反映注采井间的窜流关系.传统数学方法建立的预测模型难以适用于目前大数据背景下的油田实际应用场景[5-6].伴随大数据和人工智能等技术的兴起与发展,传统的油田开发问题可以依赖信息时代的新兴技术加以解决[7-8].其中,朱璇等[9]针对压裂井网气驱效果预测,结合误差逆传播算法(back propagation algorithm, BP)、长短期记忆(long short-term memory, LSTM)神经网络和双向长短期记忆(bidirectional long short-term memory, Bi-LSTM)神经网络等深度学习算法,建立日产油、地层压力和采出程度预测代理模型,为致密低渗油藏压裂井网气驱模拟预测提供了新途径;SYED 等[10]针对非常规油藏提高采收率方案设计问题,基于深度神经网络建立了提高采收率效果评价模型,该模型可以很好地预测不同时间轴下的采油性能.
现阶段采用深度学习方法对汽窜时间预测的研究较少,本研究在深度学方法和油井自身注采数据的支撑和约束下,提出一种基于数据驱动方式预测稠油井汽窜时间的新方法.通过实际的预测验证,该方法可以有效提高汽窜时间预测的效率和精度,对汽窜智能预警具有一定指导意义.
1 基于变异系数-G1 混合交叉赋权法的汽窜时间表征方法
基于变异系数-G1 混合交叉赋权法是一种汽窜时间表征方法,通过组合动态数据,构建了表征汽窜时间的指标参数,引入变异系数-G1 混合交叉赋权方法对各表征指标进行赋权,从而得到综合的汽窜时间判别曲线.
1.1 基于生产动态时间序列的汽窜时间表征指标
温度是蒸汽突破过程中一个重要因素.当高温蒸汽前沿突破到生产井时,井底温度会突然上升,井底温度曲线的拐点则标志着蒸汽突破的开始.然而,在油田实际应用中,由于井口温度受多种因素的影响,噪声较大,没有明显的拐点.汽窜后生产井的产水量绝大部分来自邻近窜通的注汽井,产水量的数据波动与注汽量的数据波动具有很强的相关性[11].因此,选取日产油量(qo)、日产水量(qw)、注汽井的井口温度、生产井的井口温度、累积注汽量以及累积产油量等具有代表性,且易于测量的特征参数作为基本表征参数,通过基本参数的组合,得到表征蒸汽时间的指标R1(生产井日产水量与日产油量之比)、R2(生产井井口温度和注入井井口温度之比)和R3(注汽井的累积注汽量和生产井的累积产油量之比)分别为
其中,tp和ti分别为生产井和注入井的井口温度.Gi和Np分别为注汽井的累积注汽量和生产井的累积产油量.R1从瞬时产量的角度反映了蒸汽驱过程中生产井随日产油量变化的产水程度,R1值越大,说明生产井日产水量增加程度越大,形成窜流通道的可能性越大.生产井井口温度tp越高,R2值越大,说明高温蒸汽向生产井方向移动,蒸汽前缘在此方向移动较快,有可能发生突破.R3值越大,说明累积注汽量在增加的情况下油却没有被有效的驱替出来,汽窜通道形成的可能性大.
1.5 统计学处理 采用SPSS 20.0进行数据处理,计量与计数资料分别行t与χ2检验;采用多因素回归分析对各脑叶CT值与临床特征的相关性进行分析。P<0.05为差异有统计学意义。
1.2 基于变异系数-G1 混合交叉赋权法的表征参数赋权
为综合考虑上述表征指标的影响,需要确定各指标时间序列的权重,从而构建汽窜时间的综合判别曲线[12].
变异系数法属于体现数据本身客观信息的赋权方法,变异系数越大说明指标的影响越大,重要程度越大[13].变异系数赋权法计算流程如下:
1)计算变异系数
选取2014年12月~2017年1月在本中心进行妇科体检的患者1000例作为研究对象,根据体检时间将其分为对照组(2014年12月~2015年12月)与观察组(2016年1月~2017年1月)。其中,年龄27~84岁,平均年龄(67.3±1.2)岁,个人体检361例,集体体检639例。
因为古意是属于康美娜的,而守护康美娜的爱情是我毕生所愿。所以,每当我和二乐恰逢其会地出现在古意的风月场上时,二乐成了我突然出现的最好理由。
众所周知,库切是流散写作的代表作家,其文本写作必然呈现其重要的历史观。库切的系列作品中,对于后殖民主义与后种族隔离时代所呈现的白人与黑人间的个中冲突的持续关注与冷静探索贯穿其中,《耻》一书中黑人对露西的强暴场面不能不唤起我们对过去殖民者所犯下的种种滔天罪恶的记忆。库切在这样的冷静客观的描述中深刻表达了对过去殖民历史罪恶的痛憎,对南非当前社会现实苦难的深切关怀。
其中,ωk为第k个指标的权重值.
G1 赋权法是一种主观赋权法,该方法凭借决策者对指标的重要性排序,从而根据相邻指标之间的相对重要程度确定各指标的权重.G1 赋权法计算流程如下:
1)决策者确定指标排序
其中,Xk为第k个指标(k= 1, 2, …,m).
2)决策者确定相邻指标重要性程度之比的理性赋值
其中,和分别为第k和k-1 个指标的权重系数.重要性程度之比的赋值是人为规定.
3)计算权重值
其中,为第m个评价指标的权重.
基于变异系数-G1 混合交叉赋权法使用各指标的变异系数代替了G1 法中人为规定的步骤,从而确定相邻指标的重要性程度之比.该方法很好地契合了汽窜判识应用场景中综合考虑现场经验以及数据客观信息的需求.具体的计算步骤如下:
1)决策者对评价因素进行重要程度排序;
其中,N为样本总数(i= 1, 2, 3, …,N);Xi和Yi分别为第i个样本的输入和输出;m为第i个样本中的特征维度;n为第i个样本中的时间序列长度.
2)利用变异系数法赋权原理,采用式(6)计算变异系数Vk;
赵四指着自家的三间大瓦房和满园鲜嫩的时令菜蔬说,“我住的这个院子原来是沙丘,自从有了三北防护林,生态变好后,沙丘后移,沙地变成了菜园子。这些蔬菜,用的是农家肥,不打农药,除自家吃外,每年还能销出去一些,增加了不少收入。”
4)根据式(11)计算所得的rk代入式(9)和式(10),即可得到基于变异系数-G1 混合交叉赋权法确定的各指标权重.
1.3 窜时间综合判识曲线的构建
按照上述计算步骤,结合油田生产数据,可以求出各生产井的汽窜时间综合判识曲线,结果如图1.其中,陡然上升的拐点即为蒸汽窜流通道的形成初始时刻.以图1 中4 口生产井为例,J4 井的汽窜时间为第678天和第782天,J23井的汽窜时间为第674、1 860、2 050 和第2 359 天,J30 井的汽窜时间为第892天以及第2 001天,J40井的汽窜时间为第1 726 天.将根据汽窜时间综合判识曲线得到的汽窜时间与该井实际汽窜时间进行对比,绝对误差均小于10 d,验证了该判识曲线的准确性.
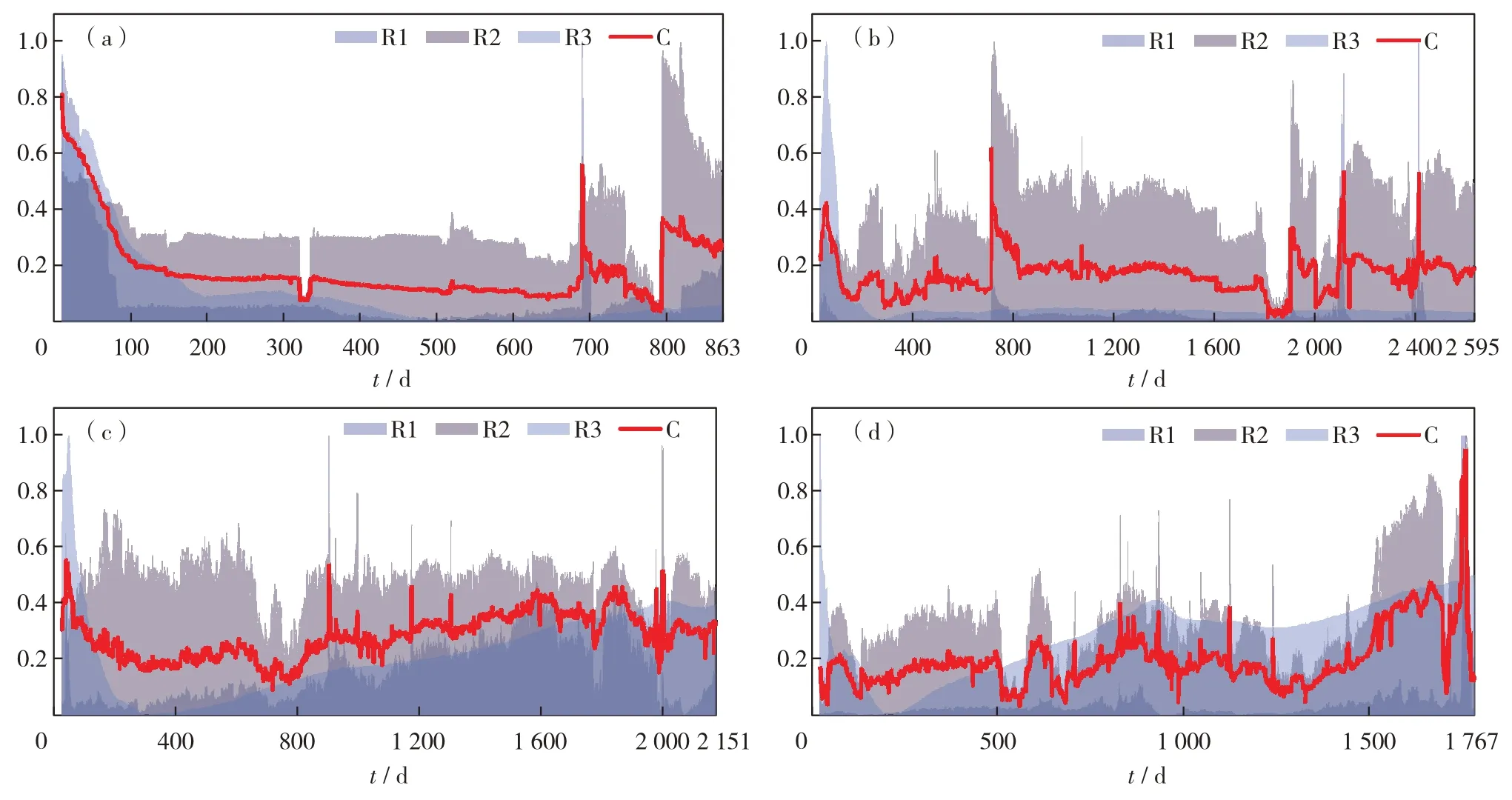
图1 不同样本井的汽窜时间综合判识曲线 (a)J4样本井; (b)J23样本井; (c)J30样本井; (d)J40样本井Fig.1 Comprehensive identification curves of steam channeling time of (a) J4 sample well, (b) J23 sample well, (c) J30 sample well,and (d) J40 sample well.
2 基于序列-序列的汽窜时间预测模型
2.1 样本生成
试验工区为S 油田稠油蒸汽驱区块,共有8 个蒸汽驱井组,其中,注汽井8口,生产井40口,区块原油黏度为98 500 mPa·s,平均孔隙度变化范围为32~34,平均渗透率变化范围为3.158 4~3.454 5 μm2.动态数据为注汽井与生产井从2016年1 月—2019 年12 月的注采数据,约5.2 万条记录.以生产井为基本单位,对应注入井的注入参数作为影响因素特征构建样本集,每个样本记录了包括注入参数、静态数据和生产数据等数据项.
2.2 汽窜时间特征选择
在多维时间序列数据的分析过程中,当样本存在冗余特征时会大大增加分析的复杂难度.为保证深度学习模型的精度,需要针对各样本的基础参数进行特征选择.本研究使用了基于标准互信息(normalized mutual information)的相似性度量方法[14],其表达式为
将构造好的输入特征矩阵和输出向量代入序列到序列结构中,随后将由编码器按照输入序列的时间顺序分步读入网络.编码器是由若干个LSTM 门控制单元组成的,每个时刻的隐含状态ht都由当前时刻的输入数据xt与上一时刻的隐含状态ht-1和单元状态ct-1共同决定,其表达式为
由式(12)定义可知,标准互信息的值越大,表明Y和X之间的相关性越强.基于标准互信息的相似性度量方法,计算样本中每个注采参数与汽窜时间判识曲线之间的标准互信息值,并且进行排序,结果如图2.在该区块中,由于孔隙度、渗透率和有效厚度等储层参数呈现的变化幅度较小,相应的标准互信息值较小,表明其对汽窜时间判识曲线变化的影响较小.从数据驱动的角度来看,在该实验区块下的储层参数对后续所建立的深度学习模型贡献不大,因此,选择标准互信息值在整体均值以上的10 个注采参数作为预测汽窜时间的输入特征,即日产液量、日产油量、累积产油量、日产水量、累积产水量、生产井井口温度、注汽井井口温度、日注汽量、累积注汽量以及注采井距.
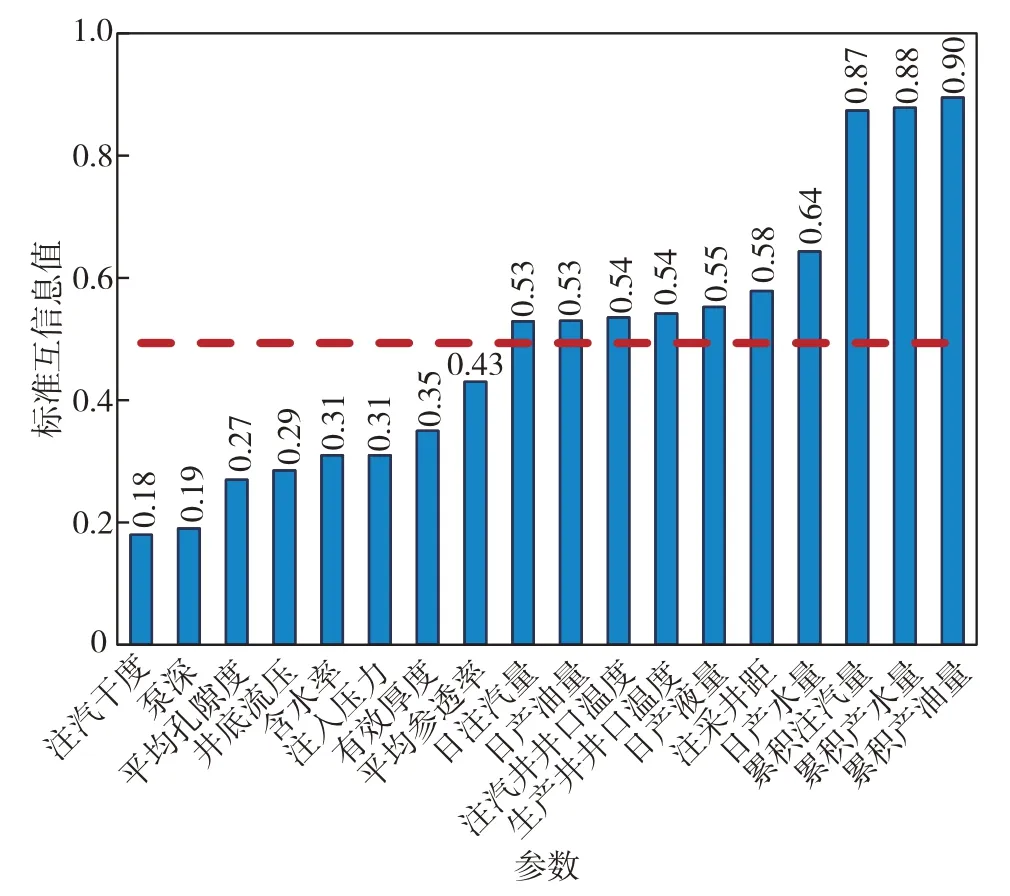
图2 十个注采参数的标准互信息值Fig.2 Standard mutual information values of 10 injection -production parameters.
2.3 时间序列数据预处理
由于量纲不同,实际的注采动态数据在维度上通常表现出值域范围跨度大的特点,因此,需要对时间序列数据进行预处理,以提高后续模型的训练速度以及预测的准确率.首先,对时间序列数据进行标准化处理,公式为
其中,Xnorm为标准化处理后的数据;X为原始数据;μ为原始数据的均值;s0为原始数据的标准差.
3)利用变异系数数值确定相邻评价因素的重要程度的比值rk;
中国共产党十分重视少数民族干部的培养,这些少数民族领导干部也勤奋工作,为红军长征取得最后胜利立下汗马功劳。遵义会议后,军委鉴于长征途中的物资供应工作的需要,红军将领杨至成(侗族)被任命为中央革命军事委员会先遣工作团主任,负责开辟路线、发动群众、筹措给养物资等工作。杨至成在工作中,要求先遣工作团成员一定要严格执行党的民族政策,部队面对粮食缺乏问题,杨至成严格执行党的民族政策,多渠道筹粮,一个月在毛尔盖筹到粮食30多万斤,为红军通过草地立下大功。
然而,经过标准化后的数据在时间上还存在一定的噪声波动,因此,还需要运用高斯滤波器对时间序列进行降噪处理[15],其表达式为
其中,sG为高斯分布的标准差.降噪处理只是去除了数据中不必要的峰值、趋势以及离群值,最大程度保留时间序列的结构信息,提高时间序列的辨识度.以J4 井为例,经过标准化处理后的时间序列特征如图3(a),运用高斯滤波器对这些时间序列数据进行降噪处理,结果如图3(b).
2)计算权重值
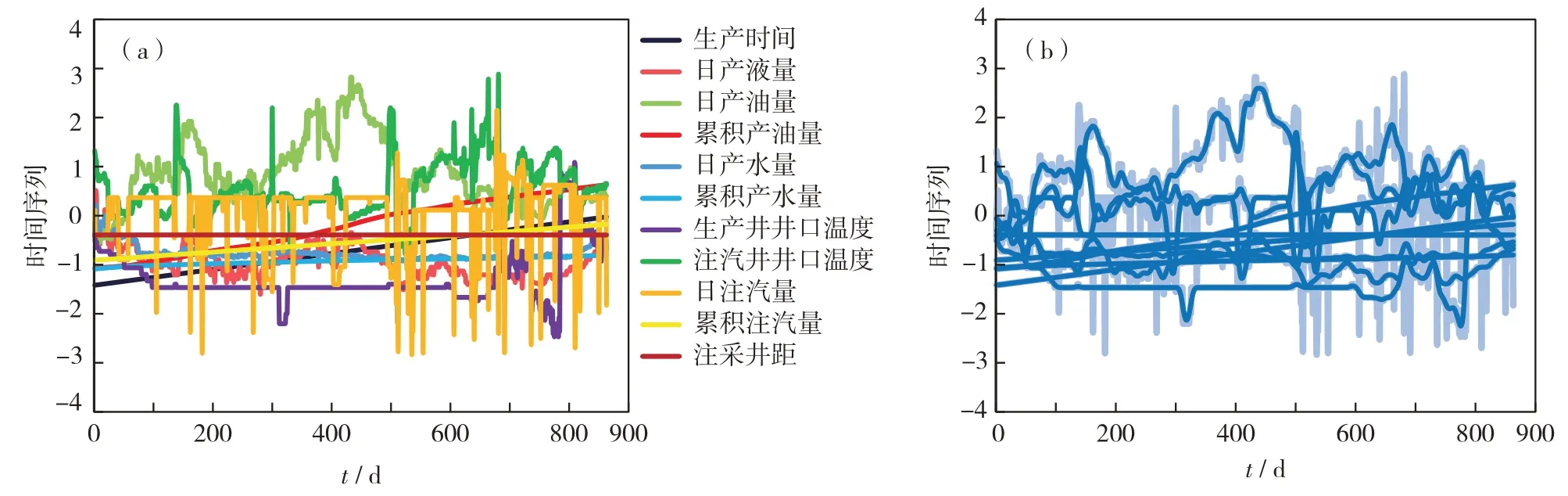
图3 J4样本井时间序列特征 (a)标准化; (b)降噪结果Fig.3 (a) Standardized and (b) smoothed time-series characteristic features of J4 sample well.
2.4 序列到序列深度学习框架
利用上述注采数据选择的特征作为输入,预测未来汽窜时间判识曲线的波动,以此确定生产井的汽窜时间.因此,选用序列到序列的深度学习框架(sequence-to-sequence,seq-to-seq)作为模型基础.序列到序列是一种通用的序列编码-解码深度学习框架,目前被广泛应用于自然语言处理(natural language processing, NLP)领域.与传统的循环神经网络(recurrent neural network, RNN)或LSTM只能处理单一维度且固定长度序列不同,序列到序列框架可以实现对多维度且任意长度序列之间的映射[16].该框架的核心是由编码器和解码器组成的特殊网络架构,编码器将可变长度时间序列编码为一个固定长度的特征向量,然后由解码器将固定长度的特征向量进行解码作为预测输出,图4为序列到序列深度学习框架的基本结构.其中,SN和hN均为隐含层变量.由图4可见,输入的历史注采数据的时间序列以及对应的输出汽窜时间判识曲线时间序列的长度为n.此时构造的输入特征矩阵I以及输出向量O为
其中,σk为第k个指标的标准差;Vk为第k个指标的变异系数;Xki为第i个目标中第k个指标的原始数据(i= 1, 2, …,n;k= 1, 2, …,m),-Xk为第k个指标的平均值.

图4 序列到序列模型结构Fig.4 Model structure of seq-to-seq.
通过对该疾病的研究,手术治疗为其常用治疗方法,本文就腹腔镜阑尾切除术、开腹阑尾切除术进行对比,发现,开腹阑尾切除术虽然能够彻底切除病灶,但是术后并发症多,切口大,恢复速度缓慢等缺点,整体疗效不甚理想,随着微创技术的不断完善,腹腔镜阑尾切除术逐渐取代开腹阑尾切除术,成为了主要的手术方法,应用价值极高,值得选用[5]。
其中,X和Y分别为特征序列和目标序列;p(x)和p(y)分别为特征值x和目标值y的边缘概率函数;p(x,y)为x和y的联合概率函数.
其中,ht和ht -1分别为t和t- 1 时刻编码器门控制单元的隐含状态;xt为t时刻的输入;ct -1为t- 1时刻编码器门控制单元的单元状态.
经历了1 9 7 9年那个冬天,殷燕才知道真的战场远比《英雄儿女》里更糟糕。2月2 7日晨,东线最关键的谅山战役开始。有一个河南开封的兵李民,高个,白净,爱说爱笑,会拉手风琴,医院的女孩儿们都喜欢和他搭腔聊天,与殷燕相熟。“2月2 8日那天,从6 5 0高地上抬下来许多尸体。大家都在忙着工作,一个女兵突然惊呼:这不是李民吗!头的一半已被炮弹炸飞,军装被血浸透,担架里都是血水。要不是拿出他左上兜能够证明身份的生死牌,谁也不知道他就是李民。”殷燕回忆。
具体的门控制单元由候选门(g)、输入门(i)、遗忘门(f)和输出门(o)4 个功能模块组成.可学习的参数包括输入权重W、循环权重R以及偏置b[17].
2.5 模型设置
采用序列到序列深度学习结构建立汽窜时间预测模型.序列输入层支持输入不同长度的多维时间序列数据,每个样本都具有11 个维度的时间序列特征,编码器和解码器隐含层则用于对输入序列进行训练学习,指定adam 求解器来代替随机梯度下降作为网络的优化算法.最终,本研究以汽窜判识曲线拟合准确度为目标函数,使用优化算法得到最合适的超参数搭配,即200 个隐含层,学习率为0.01,最小批分尺寸为16,迭代轮次为250次.
3 应用效果
3.1 效果评价指标
为评价模型的预测性能和精度,采用均方根误差(root mean square error, RMSE)和决定系数R2两种指标定量评价模型的性能.
其次是奶源和生产工厂,这在很大程度上决定了奶粉的品质。三聚氰胺事件后,消费者对奶粉安全性更加重视,来自爱尔兰、新西兰等北南纬45度黄金奶源带的奶源都是不错的。此外采用符合国际标准的生产工厂才能保证所有的生产线,生产的产品具有一致性,也更有品质保障。
其中,ytrue(i)为第i个样本的真实观测值;ypred(i)为第i个样本的预测值;n为样本总数;Sres为样本真实观测值与预测值之间的残差平方和;Stot为样本真实观测值与预测值之间的总离差平方和.
RMSE 描述的是模型预测值和真实观测值之间的偏差,σ值越接近0,表示模型整体拟合效果越好.R2描述的是预测值和真实观测值之间的变异程度,该值越大,说明预测值对真实观测值的解释程度越高,说明模型精度越高.
3.2 预测结果分析
将通过特征选择以及时间序列预处理的40 个实验工区样本随机划分为80%的训练集和20%的测试集进行预测.测试样本数据中后10%时间步的汽窜综合判识曲线看作未知数据,运用前90%的历史注采时间序列数据输入模型进行预测,测试集整体的预测结果如图5.从图5 可见,在该试验区快下运用序列到序列深度学习框架预测出的汽窜综合判识曲线与测试样本真实值之间的误差较小,并且随着时间序列长度的增加,预测误差没有显著的波动.说明序列到序列深度学习框架在此区块中具有一定的适用性,并且预测结果对测试样本的时间序列长度不敏感.
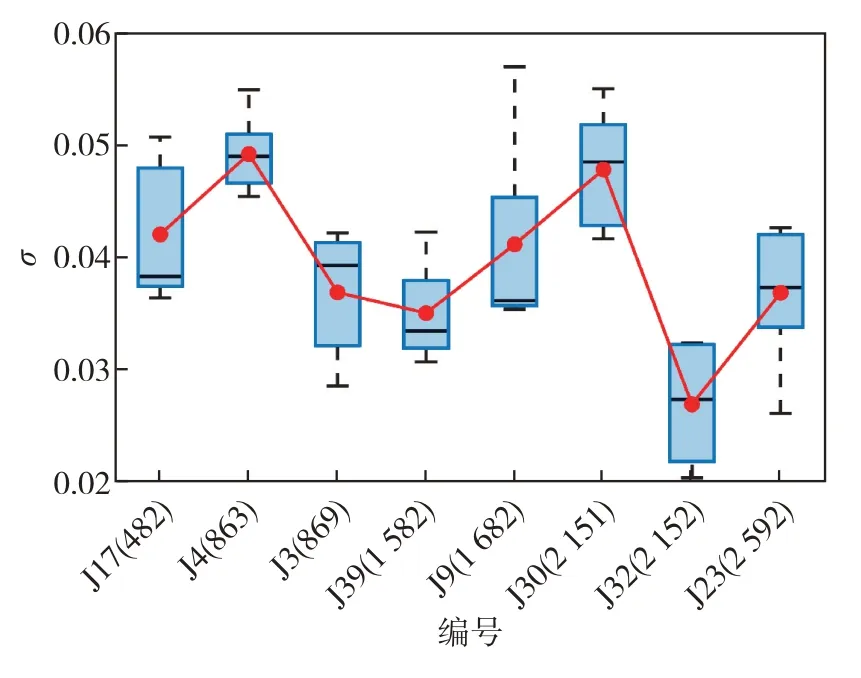
图5 测试集样本序列到序列深度学习框架预测结果(括号内数字为对应的序列长度)Fig.5 Prediction results of test set samples by seq-to-seq deep learning framework.(Values in parentheses are the length of the time series corresponding to the test samples.)
为验证所建立的汽窜时间预测模型的精度,以J4和J30样本为例,运用序列到序列深度学习框架预测的汽窜综合判识曲线结果分别为图6(绿色虚线左侧为训练集,右侧为测试集),性能评价指标见表1.由表1 可见,序列到序列深度学习框架在任意长度时间序列样本中均呈现了90%以上的R2值,预测精度较高;其预测出的曲线幅度变化与实际综合判识曲线相同,提供了明显的汽窜时间拐点,并且与油田实际汽窜时间的绝对误差在10 d以内,符合油田现场汽窜预警的要求.
急性心肌梗死(AMI)是较为常见的一种急性心血管疾病,具有发病重、死亡率高等特征,患者常伴有心力衰竭、心律失常以及休克等现象,若没有及时予以正确的护理措施,患者极易发生其他并发症,最终影响患者的预后效果、增加其经济负担[1]。本文主要分析优质护理干预与常规护理干预在急性心肌梗死患者护理中的实施价值,具体分析如下。
探讨我国医学影像互认共享的情况,首先要界定“互认”与“共享”。《关于医疗机构间医学检验、医学影像互认有关问题的通知》中把医疗机构间检查检验互认界定为检查资料互认和检验结果互认,具体内容则包括四个方面:①具体内容包括医学检验结果和医学影像检查资料;②临床生化、免疫、血液和体液等临床检验中结果相对稳定、费用较高的项目;③医学影像检查中根据客观检查结果出具报告的项目;④医学影像检查中依据动态观察过程出具诊断报告的,或诊断报告与检查过程高度相关的项目。互认强调的是结果性内容或是客观检查项目,其目的是确定互认项目以及避免重复检查。

表1 性能评价指标对比Table 1 Comparison of performance evaluation indexes
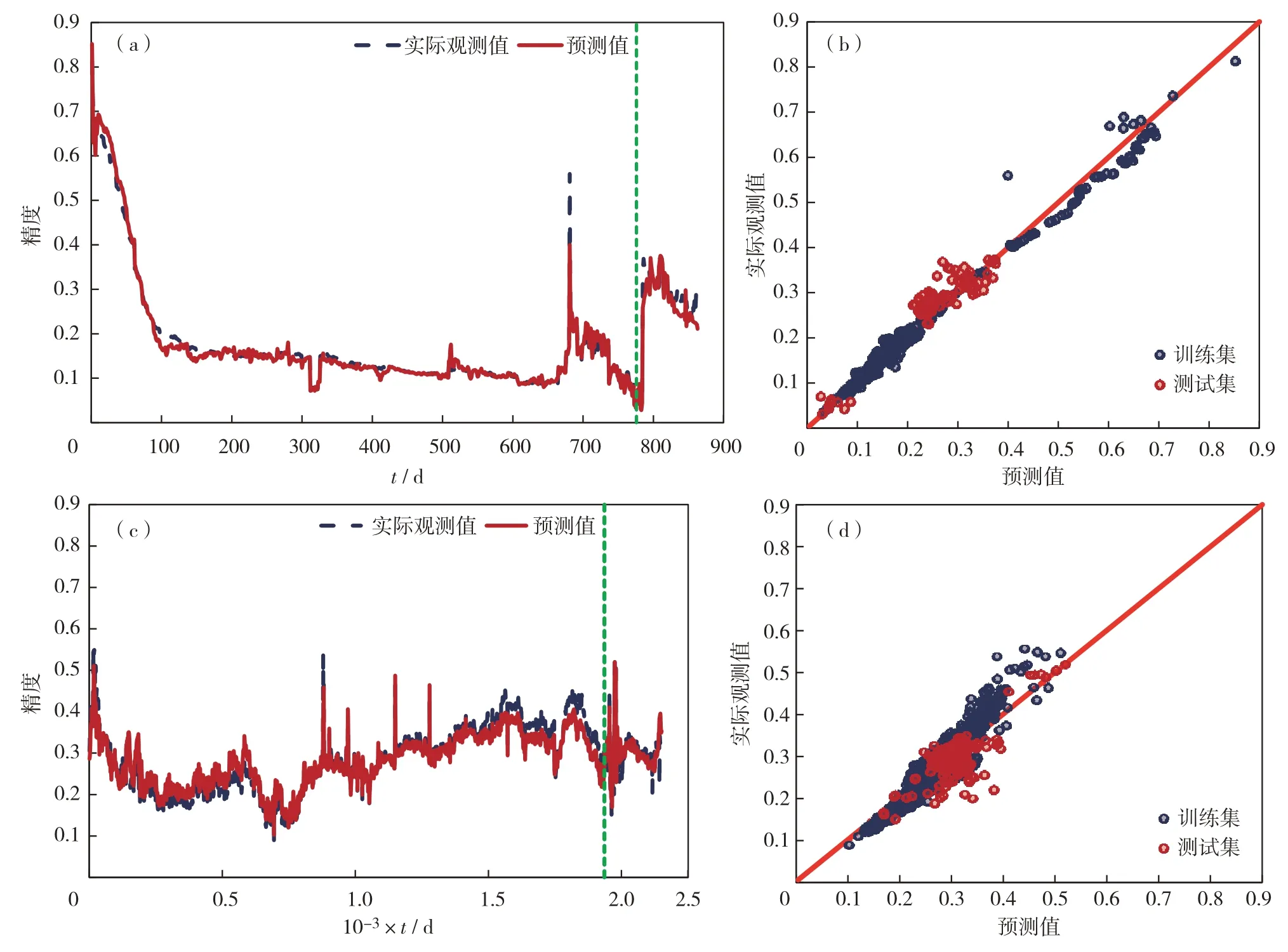
图6 J4和J30样本采用序列到序列深度学习框架的预测结果 (a)J4时间序列预测; (b)J4回归分析; (c)J30时间序列预测;(d)J30回归分析Fig.6 Prediction results of J4 and J30 samples by seq-to-seq deep learning framework. (a) Time series forecast plot of J4, (b)regression analysis plot of J4, (c) time series forecast plot of J30, and (d) regression analysis plot of J30. In the figure (a) and (c), the left side of the green dashed line represents the training set, and the right side represents the test set.
为说明所建立的汽窜时间预测模型在油田实际应用场景下的优越性,将所建立的模型与传统时间序列预测模型LSTM 的预测结果进行了对比.运用传统的LSTM预测的结果分别为图7(绿色虚线左侧为训练集,右侧为测试集).由图7 可见,序列到序列深度学习结构在测试集中的精度高于传统的LSTM.这是因为传统的LSTM只能处理单一维度且固定长度的时间序列,在预测中不能准确反映实际汽窜时间判识曲线的真实波动.而序列到序列深度学习框架由于编码-解码的特殊结构,使其不受目标时间序列自身分布规律的限制,在预测过程中充分考虑了汽窜时间的多维影响因素,预测结果更符合油田实际情况.除此之外,在时间序列长度较长的样本J30 中,传统的LSTM 模型无法预测明确的拐点.这主要是因为传统的LSTM 在处理长度较长的时间序列时存在梯度爆炸或者梯度消失的现象.而在序列到序列深度学习框架中,中间特征向量提取了整个输入序列的信息供解码器使用,使得该模型在处理长度较长的时间序列上也能保持很好的性能.

图7 J4和J30样本采用LSTM的预测结果 (a)J4时间序列预测;(b)J4回归分析;(c)J30时间序列预测;(d)J30回归分析Fig.7 Prediction results of J4 and J30 samples by LSTM. (a) Time series forecast plot of J4, (b) regression analysis plot of J4, (a) time series forecast plot of J30, and (b) regression analysis plot of J30. In the figure (a) and (c), the left side of the green dashed line represents the training set, and the right side represents the test set.
综合上述分析可见,本研究所建立的基于序列到序列深度学习框架的汽窜时间预测模型不仅可以准确的预测出汽窜综合判识曲线的拐点,而且在面对任意长度的时间序列数据依然能显示出较强的优越性,也符合油田实际现场应用的要求,为现场蒸汽驱汽窜预警提供了智能决策.
4 结 论
1)以生产动态时间序列数据为基础,提出一种汽窜时间表征方法.该方法通过组合动态数据构建了表征汽窜时间的指标参数,再引入变异系数-G1混合交叉赋权方法确定各表征指标的权重,从而得到综合的汽窜时间判别曲线.该曲线充分融合了温度变化、含水变化和汽窜突破程度等因素的影响,使其在时间序列上去除了多余的扰动,显现出更易于区分的突破拐点,这种陡然上升的拐点即为蒸汽窜流通道的形成初始时刻.
2)以构建的汽窜综合判识曲线作为输出目标时间序列,以标准互信息的相似性度量方法选择的注采参数作为预测汽窜时间的输入特征,采用序列到序列深度学习框架建立了基于数据驱动的汽窜时间预测模型,其预测结果与油田实际生产井汽窜时间相符合.通过与传统时间序列LSTM 模型的对比,该模型在预测过程中不仅表现出更高的精度,而且其在任意长度的时间序列中都展现出了可观的性能.因此,针对同一区块相同地质条件的稠油井蒸汽驱汽窜时间预测场景来说,相比传统人工判识和数值模拟的方法,基于数据驱动的方式更适合现场应用,可为汽窜的智能预警工作提供新的科学依据.
