
知识与数据混合驱动的高速飞行控制方法综述
2023-09-22 12:56:16柳嘉润张华明贾晨辉刘晓东
宇航学报 2023年8期
黄 旭,柳嘉润,张 远,张华明,贾晨辉,刘晓东
(1. 北京航天自动控制研究所,北京 100854;2. 宇航智能控制技术全国重点实验室,北京 100854)
0 引 言
随着飞行器任务多样性不断提高,拥有宽速域和跨空域等特点的高速飞行器成为了21世纪航空航天领域的前沿研究热点之一。相比于传统飞行器,高速飞行器的宽飞行包线、非常规先进布局/变体布局、复合材料和灵巧材料结构、多元混合控制效应、容错/可重构的控制需求等新技术特征不断涌现[1],发动机与动力学的耦合、气动热弹性力、动力学耦合等特性更加显著[2],意味着其控制难度上升,对先进控制方法的需求更为迫切。一般地,高速飞行器的控制器设计需考虑以下几个关键问题[3-9]:
1) 不确定性
该类飞行器的实际飞行数据相比于常规航空飞行器较少,且空气动力学数据库中的数据值与实际值的差异不易评估与修正,从而产生参数不确定性。建模及设计控制器时对模型进行了简化,可能会忽略一些高阶模态,产生未建模动态。马赫数(Ma)大于6时会产生真实气体效应影响飞行器表面压力分布从而改变气动力与力矩系数,产生气动不确定性。机体弹性特性显著时产生的形变使飞行器表面受力不均,带来的机体不确定性。发动机和机体,以及非常规布局等,产生耦合不确定性。测量误差和噪声等,产生状态不确定性。
2) 伺服特性和控制分配
工程应用中需充分考虑伺服特性,如舵面饱和、延迟和死区等,这些特性的影响在高速飞行器这类具有较快动态响应的对象中更加显著。且单一的控制形式可能在某些飞行段受限,需要进行复合控制。如再入过程中大气稀薄、动压较小的阶段,气动舵面控制能力不足,需要设计分配方法实现其与反作用控制系统(Reaction control system, RCS)的复合控制。这类具有异类操纵机构配置的飞行器必然存在异构伺服特性问题。
3) 变外形/组合构型的控制
首先该类飞行器飞行速域宽且飞行空域大,固定布局难以满足要求,其次不同的构型可以灵活分配飞行任务。飞行器拥有变外形能力时,需要考虑构型间的切换控制以及变外形过程的稳定控制。在将变形量作为控制输入进行研究时,则进一步增加了系统复杂度,需考虑控制分配等问题。传统基于线性模型的增益预置控制等方法难以满足此类飞行器的高品质控制需求。
4) 容错控制与安全控制
该类飞行器的飞行环境复杂且恶劣,控制系统需要具备一定的容错控制能力以应对执行机构和传感器故障等。提高控制系统的鲁棒性和自适应性,或者建立故障诊断与控制器重构的机制,都是有效的容错控制思路。此外,飞行过程中存在超燃冲压发动机状态边界在内的安全边界,设计控制器时也需要充分考虑这类约束,在保证安全的前提下尽量提高控制器的性能。
针对上述关键问题,当前主要手段是基于建立的飞行器模型进行控制器的设计工作。飞行器模型、控制理论以及控制器的设计经验等均属于本文中定义的“知识”范畴,是对原始数据等进行人为提炼和总结后的产物。知识驱动的控制方法应用于高速飞行器时,一方面,模型过于复杂时,以小偏差线性化和线性控制理论为基础的传统工程设计方法面临严峻挑战,可靠控制系统的设计难度剧增;另一方面,模型不匹配、测量手段不足和建模成本高等问题导致难以对被控对象进行较为精确的建模甚至无法建模,依赖模型的非线性控制方法能力受到限制。相比于知识驱动的控制方法,数据驱动的方法则直接通过数据构建相应的映射关系,具有对精确建模依赖弱、算法通用性强和算法库丰富等特点[10]。其中以深度强化学习(Deep reinforcement learning, DRL)为代表的数据驱动方法已在行星探测[11]、空间操控[12]、飞行决策[13]和目标打击[14]等领域得到了研究与应用。然而当前数据驱动方法存在物理意义不够清晰和对高质量数据需求大等问题,对于高速飞行器这类历史数据不丰富且需要保证飞行安全性的对象而言,其工程应用相对困难。
随着人工智能技术的发展,知识与数据结合相关的人工智能思路不断被提出,如知识、数据、算法和算力四要素驱动的第三代人工智能[15]以及知识/数据算法级组件化协同控制[10]等。在航空航天领域中,诸多学者也都提出了关于知识与数据结合的控制观点[16-17]以应对飞行器发展所带来的新的控制问题。
本文将从知识与数据混合驱动的不同控制框架出发,对此类方法在高速飞行控制中的应用进行总结、分析和展望。文中所涉及的数据驱动方法以机器学习方法为主,且主要着眼于高速飞行器的在线姿态控制问题。值得注意的是,由于智能控制发展过程中所涉及的理论和应用场景十分广泛[18],文中并没有以“智能控制方法”来表述所提及的数据驱动和混合驱动控制方法。
1 知识驱动和数据驱动方法的界定及分析
1.1 知识驱动方法的界定及分析
本文所提到的知识,侧重于在执行具体飞行任务之前通过各种手段所掌握的先验知识,如飞行器模型。飞行器模型的内涵包括模型的形式以及模型的参数。对于飞行器运动学/动力学模型,常基于牛顿欧拉方程或拉格朗日方程进行建立(对于变外形飞行器还可能涉及如凯恩法在内的多体动力学建模方法),常用微分方程组的形式进行描述;气动模型则常以插值表或多项式等形式描述;除此之外,地球引力模型、风模型、温度模型和大气密度模型等均有不同的描述形式。模型参数是依赖于模型形式的具体数据,可通过不同手段进行测量或估算。如飞行器转动惯量和弹性模态参数可分别通过工程估算和振动实验等方式获得;气动参数可依靠风洞实验、计算流体力学方法(Computational fluid dynamics, CFD)和工程估算等手段获得;风场模型参数则可通过统计风速/风向数据或飞行前测量等方式获得。若飞行器可重复使用或飞行架次较多,则可基于已完成的飞行控制任务中所收集的数据对知识进行修正,从而形成新的先验知识。除此之外,控制领域的相关理论,如Lyapunov稳定性理论和Bellman最优原理等,以及控制器设计经验如参数的选取和性能指标的设定等,也都属于知识的范畴。
基于以上知识,形成了各类知识驱动的控制方法,如PID控制、动态逆、反步法、滑模控制、自抗扰控制和预设性能控制等。知识驱动的控制方法理论体系完备,具有较清晰的物理意义,且运算效率较高。但对于高速飞行器所面临的控制问题,工程中常用的基于经典控制理论的增益预置PID控制方法由于依赖小偏差线性化等理论,对强非线性和强耦合特点的被控对象适应能力差,且大飞行包线也会大大增加特征工作点的数量从而增加设计成本。其他方法除了依赖较为精确的模型外,存在动态逆的逆误差、反步法的“计算膨胀”、滑模控制抖振抑制与高精度控制的矛盾、自抗扰控制鲁棒性和抗噪性的矛盾以及预设性能控制的脆弱性等问题。相关方法已在许多文献[4,19]中进行了总结,本文不再进一步说明。以上提到的部分控制方法还常与干扰观测技术、指令滤波技术等配合使用,以进一步提升性能,但这类技术本质上也都基于模型进行设计。
综上,在飞行任务复杂程度加剧,强干扰、强非线性、强不确定等问题更加突出等背景下,知识驱动方法在保证稳定性和鲁棒性方面面临更大挑战。
1.2 数据驱动方法的界定及分析
本文定义的数据包括离线数据和在线数据,前者指通过各类地面实验获得的原始数据以及历史飞行数据等,后者指在执行具体飞行任务过程中通过各种实时测量手段所获得并在线进行处理和运用的数据。知识驱动和数据驱动的本质区别在于前者通过某些技术手段对原始数据进行了人为提炼,如简化、归纳和特征提取等,形成了以模型和经验等表现形式的抽象知识,并基于抽象知识实现控制目标。而后者则是基于较为原始的数据通过学习等方式完成控制任务。当前飞行器控制中常用具有强非线性和强决策能力等特点的机器学习方法完成包括系统辨识、不确定性补偿以及系统控制在内的各类任务,本文所述的“数据驱动方法”即主要讨论这些机器学习方法。
神经网络(Neural network, NN)、模糊逻辑系统(Fuzzy logic system, FLS)、支持向量机(Support vector machines, SVM)以及高斯过程回归(Gaussian process regression, GPR)等机器学习方法均具有高精度非线性逼近能力,且研究人员可以根据具体问题选择和设计相应的模型。控制领域中常用的神经网络经典拓扑结构包括全连接神经网络、径向基神经网络(Radial basis function neural network, RBFNN)和循环神经网络(Recurrent neural network, RNN)等。随着深度学习技术的发展,包括深度神经网络(Deep neural network, DNN)、长短记忆(Long short-term me-mory, LSTM)神经网络和深度贝叶斯神经网络在内的新拓扑结构被提出并用于解决更加复杂的分类和回归等问题。不同于NN,SVM基于不同的核函数处理各类线性和非线性问题,在解决小样本问题时具有一定优势。GPR则基于严格的统计学习理论,可有效处理具有高维和小样本特点的复杂问题,在解决回归问题时与NN和SVM相比具有易于实现、超参数自适应获取以及输出量的概率意义明确等优点[20]。对于FLS,本文讨论其中具有自适应逼近能力的相关方法,可通过模糊推理以任意精度逼近任意连续光滑函数。虽然上述方法均具有良好的性能,但实际应用时还需考虑飞行器控制系统的在线计算资源分配问题。常用思路是降低算法的在线计算复杂度并将学习形式从批量改进为增量以优化在线问题的求解,如增量支持向量机[21]、增量稀疏谱高斯过程回归[22]和增量集成高斯过程回归[23]等。除此之外。部分模型如DNN和LSTM在线时仅进行前向计算,对其自身的泛化能力和离线训练时样本的质量/数量提出了更高的要求。
不同于以上主要基于监督学习机制进行参数更新的方法,强化学习(Reinforcement learning, RL)则是一类基于增强学习机制通过交互进行策略学习的方法。其中自适应动态规划(Adaptive dynamic programming, ADP)方法基于Bellman最优控制原理通过行动者-评论家(Actor-Critic)架构求解控制问题的哈密顿-雅克比-贝尔曼方程,从而得到近似最优控制策略。ADP又可分为启发式动态规划(Heuristic dynamic programming, HDP)以及二次启发式动态规划(Dual heuristic dynamic programming, DHP)等,DHP通过将价值函数对状态的导数作为Critic的输出来提高收敛性,但增加了对系统动力学信息的依赖。动作依赖(Action dependent, AD)型ADP方法如动作依赖型启发式动态规划(Action dependent HDP, ADHDP)则通过引入状态行为值函数的方式隐式获取系统的动力学信息,但同时也提高了方法对数据量的要求[24]。近年兴起的深度强化学习(Deep reinforcement learning, DRL)方法则是结合了深度学习和强化学习的优点,多用于解决复杂环境下高维系统的决策控制问题。无模型(model-free)的DRL方法开源算法库丰富且拓展性强,基于其获得的飞行控制策略常具有强泛化能力和鲁棒性等特点,但其实际控制效果也一定程度上依赖于地面飞行模拟器搭建的充分程度[25]。当前常用的无模型DRL算法包括深度确定性策略梯度(Deep deterministic policy gradient, DDPG)、随机策略优化(Proximal policy optimization, PPO)以及软行动者-评论家(Soft actor-critic, SAC)等,且算法的发展迭代十分迅速。
虽然数据驱动方法拥有弱模型依赖和强自适应能力等优点,但其物理意义并不清晰且对数据要求较高。应对复杂的飞行控制问题时相比于知识驱动方法的分析难度更大,且稳定性和收敛性不易保证。部分数据驱动方法无法独立完成控制任务,需要与知识驱动方法配合使用。表1从内涵、特征、优缺点等方面对知识驱动方法和数据驱动方法进行了总结和对比。

表1 知识驱动与数据驱动方法对比Table 1 Comparison between knowledge-based and data-driven methodologies
2 知识与数据混合驱动的控制方法分类与进展
结合本文第一节,无论是数据驱动还是知识驱动方法均有其不足与局限性,而将两者结合运用则可使其优势互补,进一步增强方法的性能。数据驱动方法具有非线性表达能力和离线/在线学习等特点,可一定程度上弥补模型复杂、无精确建模和环境不确定性下知识驱动方法的局限性。而基于知识可对复杂问题进行分解降维,或对数据驱动方法的参数初值和学习架构等进行优化,以利于数据驱动方法的收敛。图1总结了高速飞行器控制中数据驱动方法和知识驱动方法的具体作用形式以及多类混合驱动方法思路。混合驱动方法中除了智能观测器外,还有通过模仿学习、设计启发式目标函数以及知识化机器学习模型结构等方式对数据驱动方法进行增强的思路[10],对此本文不再展开。文中主要讨论混合驱动的控制方法框架,依据(知识增强的)数据驱动方法在框架中的重要程度以及知识和数据的结合形式将其分为三大类:1)基于数据修正的知识驱动控制框架;2)基于知识补偿的数据驱动控制框架;3)知识与数据并联型控制框架。
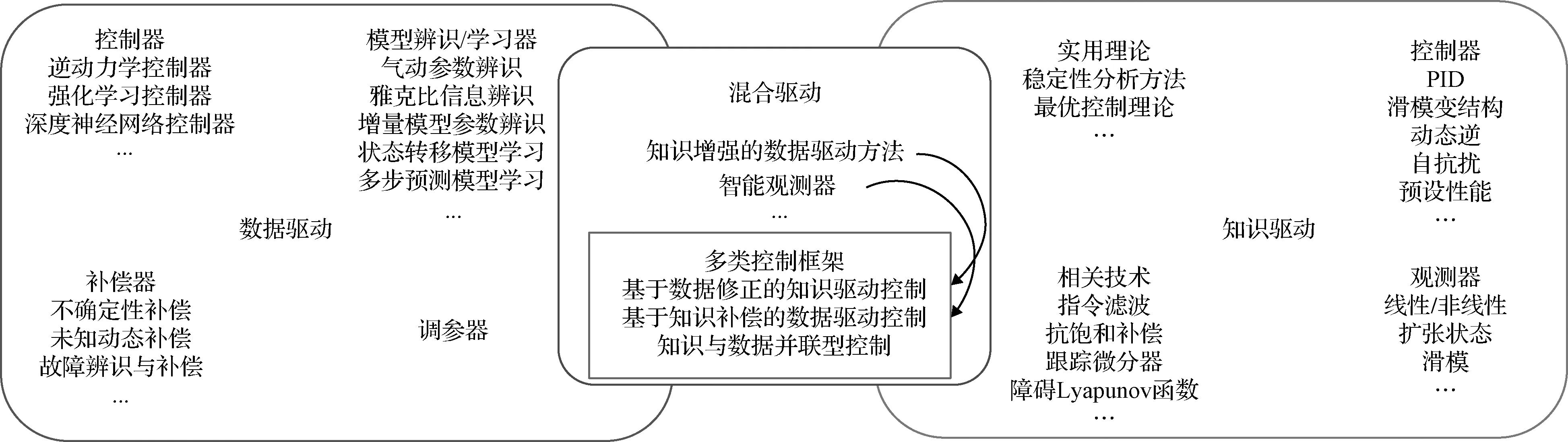
图1 高速飞行器控制中的知识、数据及混合驱动方法Fig.1 Knowledge-based, data-driven and cooperating methods in high-speed vehicle control
2.1 基于数据修正的知识驱动控制框架
基于数据调优的控制框架中,常利用RL类方法通过自适应调节知识驱动控制器的增益等手段优化控制品质。文献[26]针对具有未知不确定性和外部干扰的变外形近空间飞行器提出了一种切换自适应自抗扰控制律,利用角度和角速度两类误差设计ADHDP的代价函数在线调节自抗扰控制器的增益以提升变形过程中的姿态控制品质。文献[27]基于DDPG算法根据稳定性和鲁棒性指标设计奖励函数,训练智能体进行鲁棒控制器的参数调优,实现了含有气动伺服弹性的飞行器系统(系统状态除了位置姿态外还包括气动力滞后项和伺服机构的状态)的控制,且控制效果优于手动调参的鲁棒控制器。相比于上文,文献[28]还设计了含有控制输入约束的分段奖励函数,基于DDPG算法学习反步法设计的控制器的参数调节策略,在无抗饱和辅助结构和障碍Lyapunov函数(Barrier Lyapunov function, BLF)设计等条件下取得了较好的考虑状态约束下的抗饱和控制效果。该框架中知识驱动控制器需要根据系统知识进行设计,控制器参数范围可以事先设定,有较高的安全性。
基于数据补偿的控制框架中,数据驱动方法的使用形式灵活,既能够根据需求补偿系统的建模不确定项、干扰和难以建模的部分动态等,也能进一步设计混合驱动观测器以增强知识驱动观测器的性能。文献[29]针对非仿射飞行器模型使用模糊神经网络估计飞行器的未知动态并设计了新型鲁棒控制器,并基于Lyapunov理论推导了神经网络参数变化律,仿真结果表明该方法能够有效处理参数不确定性。文献[30]使用双RBFNN分别逼近高速飞行器高度和速度通道的不确定性,并基于高阶跟踪微分器设计了神经动态逆控制器,实现了高速飞行器的自适应高度与速度控制。文献[31]同样通过RBFNN对严格反馈多入多出非线性系统的不确定性动态进行逼近,利用误差动态和历史数据构造了新型临界预测误差增强了神经网络的非线性逼近能力,并将该方法用于高速飞行器再入控制中。不同于以上文献中考虑的标准飞行器模型形式,文献[32]对系统的全状态量进行非线性映射以处理状态约束并针对映射后的多变量系统使用多个RBFNN逼近未知动态,值得注意的是该文献引入了自适应界估计(Adaptive bound estimation)方法,减小了控制框架对多重随机不确定性先验上界信息的依赖。除了神经网络外,相关研究中还使用SVM和RL等数据驱动方法作为补偿器。文献[33]使用最小二乘SVM方法逼近高速飞行器高度和速度子系统的动态,该思路只需更新两个自适应标量,可有效减小在线计算量。文献[34]采用在线SVM拟合基于高速飞行器模型设计的理想非线性广义预测控制器中的不确定项,与使用RBFNN进行不确定性补偿的仿真结果对比表明该方法具有良好的鲁棒性和抗干扰能力。文献[35]使用RL方法离线训练并在线估计飞行控制系统中的总扰动,其中actor网络用于产生总扰动的估计,而critic网络则对估计精度进行评价。数据驱动方法还可与知识驱动观测器结合以提升观测器的状态估计和不确定性补偿等性能。文献[36]针对高速飞行器在各种扰动情况下的高精度姿态跟踪问题提出了一种基于极限学习机神经网络扰动观测器(ELM-NNDO)的滑模控制策略,并基于Lyapunov综合方法推导出神经网络权值更新律。文献[37]提出了一种由基于神经网络的Luenberger型观测器和同步扰动观测器组合而成的复合观测器,实现了未知非线性动力学和未知扰动同时存在时系统状态的估计。文献[38]利用区间II型FLS构造函数逼近器来逼近飞行器的未知动态,在此基础上设计了固定时间收敛的自适应模糊观测器用于估计未测航迹角以及攻角。文献[39]利用FLS逼近角度环的参数不确定性以及角速度环的综合扰动,并在此基础上设计了模糊扰动观测器。此外,数据驱动补偿器也常用于故障的辨识和补偿。文献[40]使用改进的RBFNN和自适应方法设计了一种容错滑模控制器,其中神经网络作为自适应律的一部分对故障值进行估计,该方法可以快速处理执行器的效益损失故障以及卡死故障。文献[41]设计了障碍Lyapunov函数处理攻角约束并使用鲁棒自适应分配律对已知形式但数值未知的执行机构失效故障进行补偿。文献[42]通过结合FLS和一种界估计方法处理与系统状态相关的时变执行机构故障。文献[43]针对具有初始系统故障和含非高斯噪声输出的高速飞行器系统,通过有理平方根B样条方法将测量的姿态角转化为相应的概率密度函数从而通过自适应模糊观测器估计干扰和故障。文献[44]设计了自适应观测器和SVM自适应补偿器以分别补偿瞬时故障和慢时变故障。文献[45]设计了FLS逼近系统模型并通过设定逼近残差阈值对传感器故障进行检测和隔离,最终基于模糊增强观测器对故障值进行准确估计。当存在更复杂的故障情况时,则需考虑故障辨识和控制器重构等手段。文献[46]提出了一种基于长短记忆(LSTM)神经网络的故障诊断单元实现了多源干扰下的执行机构故障诊断,将执行机构失效故障和偏移故障的信息采用鲁棒最小二乘分配方法为执行机构分配控制力矩,并结合扩张状态观测器对控制分配误差进行补偿。文献[47]对故障特征进行了相关性分析、降维和敏感特征提取,并通过含有遗传算法优化的SVR方法实现了故障模式识别,实现了针对多传感器融合故障的定位和诊断/单传感器故障时间判断。考虑气动伺服弹性[39,48-49]和执行机构非线性[50]的高速飞行器控制问题也常用该类框架解决。
基于模型辨识/学习的控制框架中,数据驱动方法一般通过辨识系统参数、学习正向模型映射以及预测未来状态等方式将相关信息提供给知识驱动控制器。文献[51-52]基于机器学习方法通过跟踪误差和系统状态等信息在线拟合力矩系数在内的气动参数,从而辅助姿态控制过程。文献[53]基于GPR辨识系统的增量模型以得到非线性动态逆控制器中的系统控制矩阵,一定程度上解决了带遗忘因子的递归最小二乘方法(RLS)针对快时变系统辨识效果差的问题。文献[54]使用FLS同时逼近仿射系统的未知动态和输入动力学,并通过设计非线性观测器来补偿逼近误差影响,最终得到了基于模糊重构的动态面控制器。文献[55]使用SVM回归模型在线拟合含有常数和动态不确定性的系统非线性模型,从而将原飞行控制问题转化为了二次规划问题,使用模型预测控制(MPC)方法进行在线求解。除了对模型的部分参数进行辨识或直接拟合飞行器线性/非线性模型外,也可考虑更复杂的数据建模形式,如概率空间下的状态转移模型和多步预测模型等,文献[56]基于LSTM神经网络设计了多速率采样器以从非平稳时间序列中更好的进行特征提取,实现了高速飞行器这类高速率系统的建模以及响应预测。该框架中主要关注数据驱动方法的收敛性以及辨识/预测的快速性和准确性等,最终效果除了与各类数据驱动方法的特点相关外,也与系统复杂度和参数的可辨识性等密切联系,且一般而言在线的辨识/学习过程需要一定的激励作用。
基于数据修正的知识驱动控制框架中知识驱动控制器的结构并没有较大改变,大部分情况下工程中相应的设计和分析方法仍然能够使用,当前该类框架相比于后两类更易于工程实现。
2.2 基于知识补偿的数据驱动控制框架
该类框架中数据驱动控制器一般通过监督学习或强化学习方式获得飞行器的控制策略。本文按照学习机理将该类框架进一步分为:1)基于逆系统学习的控制框架;2)基于RL理论的控制框架;3)基于人工样本的控制框架。该大类框架图如图3所示,知识驱动方法包括状态观测器和抗饱和补偿器等,ξ代表抗饱和补偿量。知识驱动方法也可输出不直接作用于系统的参考控制量ukc等,为数据驱动控制器的监督学习过程提供参考输出。
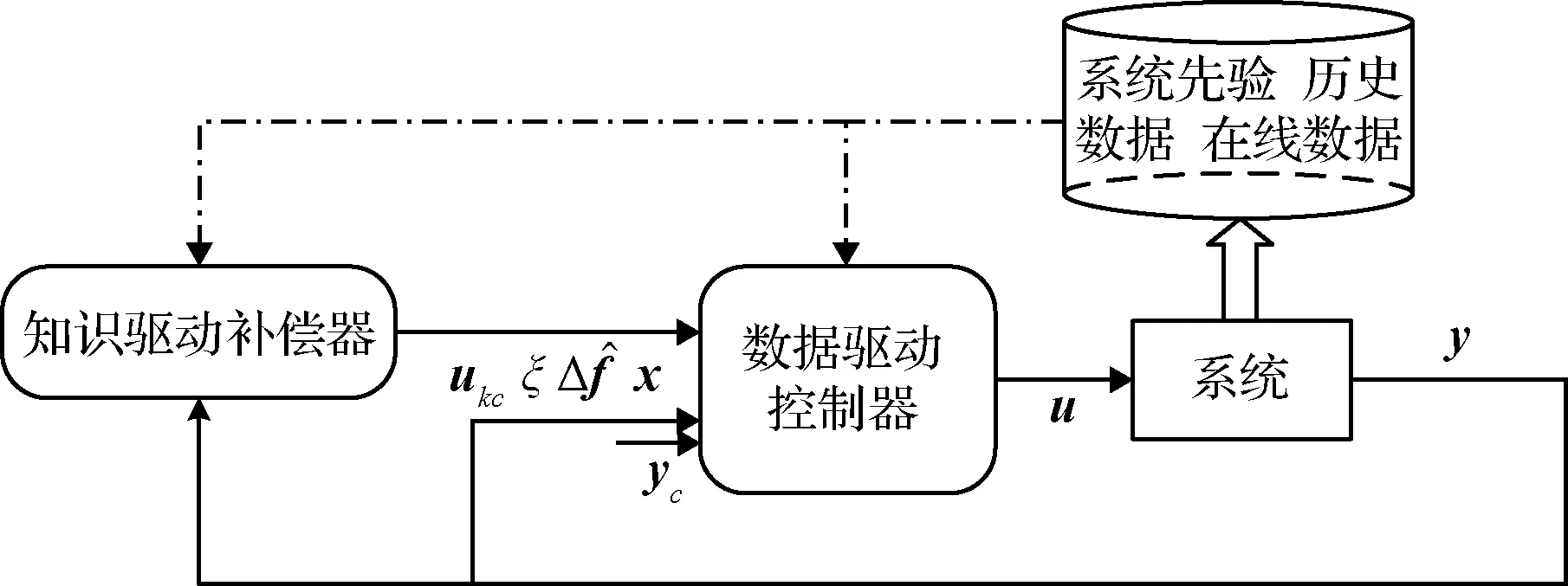
图3 基于知识补偿的数据驱动控制框架Fig.3 Data-driven control framework based on knowledge compensation
基于逆系统学习的控制框架中,数据驱动控制器本质上是在线解决以系统相关状态作为输入,系统控制量作为输出的回归问题。除了直接基于系统的输入输出数据学习前馈控制策略并结合反馈控制律完成控制任务外,还可将知识驱动控制器的输出作为回归问题训练集中的输出数据引导数据驱动控制器进行在线学习。如文献[57]设计了一种自适应模糊神经网络控制器,仅以跟踪误差作为控制器输入并将标称动态逆控制器的输出作为参考输出,基于反向传播法推导了控制器的自适应律,仿真结果验证了在大不确定条件下控制器的有效性和鲁棒性。当飞行器模型未知或存在不确定性时,还可通过数据驱动方法学习和补偿正向模型从而与逆动力学控制器配合使用,如文献[58]设计了双神经网络拟合正逆动力学的控制架构,将用于逆动力学学习的神经网络与另一个基于神经网络的正向动力学补偿控制器结合,通过飞行数据学习由状态量和目标状态到控制量的映射,随着学习的推进,神经网络逆动力学控制器的输出将占主导。
基于RL理论的控制框架中,数据驱动控制器通过交互的方式学习控制策略。该框架中可能存在基于知识设计的前馈控制部分,但前馈部分只与参考输入和系统动态有关,并不能单独使系统稳定,这里需要注意和下一节的知识与数据并联型的控制框架进行区别。文献[59]使用无迹卡尔曼滤波状态估计器估计了winged-cone飞行器纵平面姿态的不确定性并得到了前馈控制部分,反馈控制策略使用策略迭代(PI)方法自学习得到,且基于Lyapunov理论证明了单次迭代过程中价值函数单调递减且能收敛到Bellman最优解。文献[60]在系统模型完全未知的情况下,前馈动态逆控制器和系统模型均由神经网络学习得到,反馈控制律则由ADHDP方法学习得到。文献[61]使用神经网络处理系统的参数不确定性和未建模非线性,并以此优化由离散最小值原理推导的Actor-Critic控制架构的最忧性条件,仿真结果验证了该设计方法在不确定条件下对吸气式高速飞行器跟踪控制的有效性。为了进一步减小ADP类控制方法在在线控制时对全局模型的依赖,Zhou等[62]提出了基于增量模型的自适应动态规划方法(iADP)以及其改进方法,应用于飞行器的在线自学习控制[63]、故障容错控制及状态部分可观测条件下的飞行控制[64]中,该类方法通过RLS方法在线辨识系统增量模型并预测下一拍状态,ADP则基于增量模型信息进行策略更新。文献[65]在iADP的基础上提出了基于误差动力学的DHP飞行器自学习控制方法,方法对误差状态进行了增广并基于RLS辨识误差动力学的控制矩阵和参数不确定性,实现了高速变外形飞行器三通道耦合条件下的姿态跟踪控制。虽然上述的部分方法对知识的依赖程度不高,但在线学习时当数据多样性不足时也易影响学习效果,常需通过注入持续激励和探索量等手段改善学习效果。近期也有将经验回放等方法代替传统激励条件的研究,如文献[37]提出一种基于复合观测器的RL跟踪控制器,推导了含有反馈控制量的误差动力学形式并采用历史经验重放和并行学习代替持续激励从而实现高速飞行器的最优姿态跟踪。
基于人工样本的控制框架中一般基于其他控制/优化方法生成数据集,后使用深度神经网络等数据驱动方法学习控制策略来达到提高在线计算效率和增强泛化能力等目的。文献[66]使用粒子群优化方法求解了含输入饱和及气动热等约束的最优控制问题,在不同初始化条件下生成了最优轨迹数据集,使用深度神经网络学习状态到动作的映射关系,从而能在线实时计算最优反馈控制量实现飞行器的6自由度控制。文献[67]通过MPC离线求解含有输入饱和约束的优化问题生成大量样本数据,训练深度神经网络学习控制分配策略,从而在在线控制时实现高效的优化问题近似求解。当要求初始数据驱动控制器拥有一定的控制能力以保证飞行的安全性或满足收敛条件时(如策略迭代方法收敛的前提之一是初始控制策略能够使系统稳定),除了基于RL方法进行离线学习外,基于知识驱动控制器产生的样本对数据驱动控制器进行预训练也是途径之一。相比于姿态控制,此框架更多时候应用于高速飞行器的在线轨迹规划中[68-70],耗时的优化计算和网络训练等过程是离线进行的,在线时仅进行网络的前向计算,控制器拥有良好的实时性和收敛性。
基于逆系统学习的控制框架和基于RL理论的控制框架均拥有无模型/弱模型依赖条件下的控制策略学习能力,这两类框架在如机械臂和四旋翼飞行器控制等领域已取得了一定的研究成果,但在高速飞行器这类复杂系统中应用时方法的收敛性和稳定性还有待进一步分析和研究。当前基于人工样本的控制框架在姿态控制领域的研究较少,更多用于解决更高层次的控制问题如在线轨迹规划。
2.3 知识与数据并联型的控制框架
本节将继续讨论数据驱动控制器和知识驱动控制器并联作用形式,方案框架如图4所示。此框架中两类控制器均输出控制量,常基于知识驱动控制器推导相应的误差动力学等方程,后使用数据驱动控制器解决最优跟踪/最优调节等问题。框架中知识驱动控制器单独作用时能够使系统保持稳定,数据驱动控制器则根据不同的设计思想完成如误差修正等任务。此类设计思想能够降低数据驱动控制器的学习复杂度,也能最大程度上利用知识来保证飞行过程中系统的稳定性等。

图4 知识与数据并联型控制框架Fig.4 Parallel control framework of knowledge and data
文献[71]针对高速飞行器的高度速度控制问题提出了数据驱动的强化学习辅助控制方法,其中滑模控制器控制飞行器稳定飞行,无模型的ADHDP方法仅通过数据学习跟踪性能优化策略。值得注意的是由于ADHDP这类方法在学习控制策略时能够隐式学习系统动态从而无需系统先验[72],故在设计时除了将飞行器跟踪误差和参考作为状态外,还常以误差积分等项作为智能体状态进一步增强控制性能,且知识驱动控制器也能一定程度上减弱此类方法需要数据量大带来的控制风险。文献[73]针对高速飞行器三通道姿态控制,快回路使用RBFNN拟合未建模动态并结合自适应积分滑模控制器作为跟踪器,将问题转化为最优跟踪问题后反馈部分利用ADP进行控制策略的学习,前馈控制量则直接由模型信息和参考轨迹得到。文献[74]基于RNN和反步法设计前馈控制器,将再入飞行器的姿态跟踪问题转化为姿态角/角速率跟踪误差的最优反馈控制问题,从而引入ADP方案解决。文献[75]提出了一种由基于DRL的辅助控制器和固定时间抗干扰控制器组成的复合控制框架,抗干扰控制器能够将部分可观测马尔科夫决策过程(POMDP)转化为马尔科夫决策过程,进一步由DRL学习辅助控制策略来提高控制性能,该框架可以一定程度上解决高速飞行器的强不确定和非真实环境训练下的DRL泛化问题。
综上,对知识与数据混合驱动的飞行控制方法进行了分类,包括3大类与7小类,数据驱动方法可以在不同的框架中完成不同的任务以提高控制方法的鲁棒性和自适应性。值得注意的是知识与数据混合驱动的控制方法设计非常灵活,该种分类方法也并非绝对,部分子框架间也可以进行组合,设计的复杂程度和结构形式应依据具体对象以及控制需求而定。下面将针对本节总结的控制框架,讨论混合驱动方法在工程应用中的若干关键问题。
3 混合驱动方法在工程应用时的若干关键问题
3.1 理论可靠性问题
工程应用中为保证飞行任务的成功必须对系统的稳定性/可靠性进行评估,如基于经典控制理论设计控制器时可通过频域法定量分析开环系统的幅值和相位裕度,基于现代控制理论设计的控制器则多是通过Lyapunov函数进行稳定性分析。而数据驱动方法可解释性较弱且常涉及在线学习过程,混合驱动方法的收敛性、稳定性以及可靠性分析则成为其能否顺利工程应用的关键之一。
在当前混合驱动的方法研究中,考虑在线学习时通常是在模型不确定性和拟合误差有界等假设下开展Lyapunov稳定性证明或学习律的推导等工作,多为证明闭环系统的一致最终有界(UUB)稳定[31-32]和渐近稳定[42]等。证明的复杂度与具体控制框架和系统等相关,如基于数据调优的控制框架可以以满足稳定性条件的控制参数区间为基础进行寻优[26],控制框架中含有数据驱动补偿器或数据驱动控制器时则常设计含数据驱动方法参数估计误差在内的Lyapunov函数[37,71,73]。当仅有离线学习时,部分控制框架可对系统进行线性化从而分析稳定性[76]。但对大多数复杂系统而言,蒙特卡洛仿真可能是当前最为有效的间接验证或分析方式。除了使用控制领域中的稳定性证明工具,部分研究开始借助其他领域的方法对系统的稳定性进行分析,如文献[77]提出了一种自适应学习率的增量RL控制方法,通过小波分析监测飞行状态的振荡情况来间接分析系统的稳定性。
总而言之,当前混合驱动方法的理论性研究主要呈现两个特征。一是研究模型简化,其主要集中于飞行器的纵平面高度速度控制或单通道姿态控制,进行多通道姿态控制时也常将角度回路和角速度回路分离处理。而此类方法在高速飞行器的应用时则需要进一步考虑通道耦合,执行机构约束等条件。二是无统一理论支撑,目前知识驱动和数据驱动方法的理论研究处于相对“割裂”的状态,还未能有效实现混合驱动理论方法的统一和融合。当系统的复杂度进一步提升时,如何设计符合工程应用需求的可靠性、安全性理论分析模式是未来需要重点考虑的问题。
3.2 数据依赖性问题
数据的依赖性问题在混合驱动方法中依然存在。首先,当前的研究中考虑的不确定性并不全面,干扰观测技术对于传感器测量噪声和风干扰产生的状态不确定性的处理能力有限[5],数据驱动方法对此类不确定性相对敏感,在大增益下控制量易出现饱和或振荡等影响控制品质的现象,甚至导致系统失稳。其次,高速飞行器的历史飞行数据有限且在线数据呈现小样本特性,仅依靠历史数据和在线数据进行学习,在跨空域等新技术特征下存在一定的局限性。最后,数据驱动方法的参数更新律与拟合误差或跟踪误差等直接相关,当高质量数据不足时,数据驱动方法的参数更新效率降低,故部分方法在学习过程中需要激励作用或探索量以提高其收敛性,但同时两者对于系统而言也是额外的干扰,工程应用时需充分考虑这类“探索与利用”的矛盾。
对于混合驱动方法下的数据处理和利用问题,一方面需要从机理上对各类不确定性进行分析和处理,以减少状态不确定性对混合驱动方法的影响;另一方面可优化知识驱动方法与数据驱动方法间的不同组合形式以减小对数据的依赖,也可考虑基于模型离线产生的丰富低可信度全局数据和少量高保真历史/在线局部数据的结合处理方式。
3.3 计算高效性问题
混合驱动方法往往具有高于知识驱动方法的算力需求,如何在当前机载算力有限的条件下处理混合驱动方法带来的控制性能增强和算力需求提高的矛盾也需要重点关注。
针对该问题,目前主要从方法优化和硬件加速两个方面着手。在当前姿态控制相关的研究中常使用结构较为简单的神经网络等模型以一定程度上减小前向计算和参数更新的计算开销,但同时也限制了其表达能力。因此,为充分发挥数据驱动方法的优势,一方面可在算法和模型层面开展优化,如使用增量模式对数据驱动方法的参数进行在线更新;采用自动微分(Automatic differential, AD)技术[78]用于降低基于梯度的优化问题的计算复杂度;引入事件触发(event-triggered)机制[79]节省在线学习的计算开销;对复杂神经网络模型进行剪枝、量化和知识蒸馏以降低其计算功耗。另一方面则是从硬件入手,如设计高算力功耗比的通用型计算框架和专用AI处理器等等。
由于高速飞行器的特殊性,混合驱动方法的计算高效性是必须关注的问题。耗时的学习过程可离线完成,在线控制时的混合驱动方法应尽量简洁和高效。
除了以上三类关键问题外,多性能指标下的代价/奖励函数设计、充分的地面验证方法、快时变系统条件下的学习效率等问题也需要重点考虑和研究。
4 方法展望
当前知识与数据混合驱动的控制方法虽然已在高速飞行控制领域取得了一系列成果,但大多数研究均是在一定的简化条件和假设下完成的,与工程应用还存在一定差距。为了进一步推动该类方法的工程应用,还需充分考虑飞行器这类被控对象的特点,将离线设计/验证与在线学习/控制过程充分结合,设计出更加高效、稳定且物理意义清晰的混合驱动方法。结合近年相关领域中基于人工智能技术产生的新成果和新思想,未来可从以下三点开展工作:
1) 数据的高效利用
从各类数据的利用上,首先可以通过数据驱动方法获得更准确的飞行器模型参数以间接提升控制品质,如通过监督学习自动检测已知数据的潜在不变关系以提高气动系数的外推准确性[80]。其次可以促进基于模型产生的低可信度全局数据与高保真数据的融合,如文献[81]提出一种线性动态导数模型与模糊神经网络相结合的机器学习框架,能够提升大攻角下非定常气动参数的预测精度和效率。最后也可充分利用先验知识提高在线学习速度和稳定性,如文献[82]将基于名义模型产生的系统轨迹周围的数据点作为样本加入RL的更新律中,加快了学习速度并降低了方法对激励信号的依赖。
2) 拓扑结构设计与优化
从拓扑结构的设计上,可以基于知识直接优化数据驱动方法的结构,将“黑箱”改进成“灰箱”,提高数据驱动方法在对应问题上的表达能力并赋予其更清晰的物理意义[83]。典型的研究如机械臂力学结构化的深度拉格朗日神经网络实现在线逆动力学学习控制[84];基于动力学神经常微分方程(Dyna-mics neural ordinary differential equation, DyNODE)实现的特定区间长度状态预测与RL控制[85];基于物理知识神经网络(Physics-informed neural network, PINN)的飞行器闭环最优制导与控制[86]和最优转移轨道设计[87]等等。对于具有变外形能力以及需考虑复杂故障的高速飞行器,当前并不能仅基于知识处理其飞行过程中复杂流场和系统耦合等产生的不确定性,可考虑探索拓扑结构更加复杂和专用性更强的混合驱动方法加以解决。
3) 安全飞行与保护
从飞行安全性考虑,除了进一步增强方法的可解释性外,还可通过切换保护的形式优化在线学习过程。其中安全边界可用高斯过程在内的贝叶斯类方法进行建模,基于安全边界设计切换控制策略或获得安全控制参数组合[88-89]。
5 结 论
高速飞行器是一类多学科交叉的复杂系统,对于其新技术特征下的控制问题,工程中常用的知识驱动方法以及人工智能领域的数据驱动方法均存在一定的局限性。本文在对两者进行界定与分析的基础上引出了混合驱动的思想,并对近年提出的相关控制方法进行了分类。知识与数据混合驱动的控制方法以多种组合形式使两类方法优势互补,是推进高速飞行器控制技术发展的重要思路。其中数据驱动部分发挥的作用呈现从无到有、比重从小到大的发展趋势,数据驱动的调参器、补偿器、模型学习器以及控制器等基于不同机理增强控制系统的鲁棒性和自适应性。然而当前混合驱动方法的相关研究对实际工程问题考虑并不全面,且在理论可靠性、数据依赖性以及计算高效性等关键问题上还需重点讨论和研究。一方面,设计控制器时需要充分考虑高速飞行器的不确定性、相关约束、容错和安全控制等问题。另一方面,还需理论研究和应用研究并行,推动针对性出针对性更强、可靠性更高、稳定性更优的混合驱动控制技术发展。
猜你喜欢
汽车实用技术(2022年7期)2022-04-20 11:45:04
凤凰动漫(军事大王)(2022年1期)2022-04-19 11:35:10
小资CHIC!ELEGANCE(2022年1期)2022-01-11 00:49:59
房地产导刊(2020年11期)2020-12-28 01:32:30
数学物理学报(2020年3期)2020-07-27 01:19:46
铁道通信信号(2019年4期)2019-10-10 03:42:56
电子制作(2018年2期)2018-04-18 07:13:25
法大研究生(2017年1期)2017-04-10 08:55:06
通信电源技术(2016年1期)2016-04-16 04:57:31
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:21
