
Multi-style Chord Music Generation Based on Artificial Neural Network
2023-09-22 14:28YUJinming郁进明CHENZhuangHAIHan
YU Jinming(郁进明), CHEN Zhuang(陈 壮), HAI Han(海 涵)
College of Information Science and Technology, Donghua University, Shanghai 201620, China
Abstract:With the continuous development of deep learning and artificial neural networks (ANNs), algorithmic composition has gradually become a hot research field. In order to solve the music-style problem in generating chord music, a multi-style chord music generation (MSCMG) network is proposed based on the previous ANN for creation. A music-style extraction module and a style extractor are added by the network on the original basis; the music-style extraction module divides the entire music content into two parts, namely the music-style information Mstyle and the music content information Mcontent. The style extractor removes the music-style information entangled in the music content information. The similarity of music generated by different models is compared in this paper. It is also evaluated whether the model can learn music composition rules from the database. Through experiments, it is found that the model proposed in this paper can generate music works in the expected style. Compared with the long short term memory (LSTM) network, the MSCMG network has a certain improvement in the performance of music styles.
Key words:algorithmic composition; artificial neural network(ANN); multi-style chord music generation network
0 Introduction
In today’s world, music, as an art form, is more and more needed in our daily life. However, due to individual differences, people have their own standards and requirements of music types. At the same time, music creation has been very professional since its appearance, which requires creators to have profound insights into music theory[1]. It is precisely because of this high threshold that it is basically impossible for non-professionals to create pleasant music. Therefore, in the past, people would regard music more as a subjective product of musicians. Only musicians can compose those masterpieces. But with the development of artificial intelligence (AI) and deep learning, scientists realize that people can create music through computers[2], which seems to be a path completely different from that of musicians, and people who create music through this method often do not need to have strong professional knowledge of music, and can create satisfactory music works through computers. This kind of technology that uses algorithms to create music is called algorithmic composition[3].
Algorithmic composition can be generally divided into two types. The first type is to formulate a series of rules for music creation based on specific music knowledge[4]. The second type is to learn the relevant composition rules through machine learning or deep learning algorithms for creation[5]. The first type of algorithmic composition often requires the creator to have high musical literacy. In contrast, the second type of algorithmic composition uses machine learning or deep learning to create music, which is more adaptable and versatile. At the same time, it greatly reduces the threshold of music creation. Compared with the first type, the second type does not require the creator to formulate corresponding music rules. It only requires the creator to understand the basic knowledge of music theory, which greatly reduces the threshold for music creation. The research in this paper is all based on the method of the second type of algorithmic composition.
In a narrow sense, algorithmic composition can be equated with computer automatic composition systems. With appropriate human intervention, computers can automatically generate music. Most of the early research was conducted using the first type of algorithmic composition, which required the researchers to have a high level of musical literacy themselves. However, with the use of artificial neural network (ANN) technology, algorithmic composition has entered a new stage[6].
The so-called ANN is a network established by imitating human neurons. The network has a strong learning ability. Compared with other algorithms, the network is used to create music by learning and analyzing a large amount of data. In order to find the corresponding composition mode and law and then create music according to the law, a large number of new technologies and new algorithms have been applied, and the recognized influential technologies are mainly Markov chains, genetic algorithms, music theory library systems based on music rules, ANNs, fuzzy rules,etc. Because these technologies closely followed the development trend of computer technology, they were frequently applied at that time. Thanks to the use of new technologies, more and more achievements have emerged, covering the melody, rhythm, chords and other aspects of music. For example, Ecketal.[7]first proposed the use of the long short term memory (LSTM) network to generate musical chords. Huangetal.[8]generated music according to the mathematical laws, and proposed the problem of chords in the text. Yangetal.[9]proposed a combination of two LSTM models(CLSTM) framework to solve the chord problem in algorithmic composition. Zhuetal.[10]proposed a model framework for multi-track music generation, which considered not only the chords and rhythms of music, but also the harmony between multi-track music, and gave specific evaluation criteria. In addition, Wangetal.[11]combined music theory grammars and LSTM neural networks to generate jazz music, which showed that different genres of music could be generated, such as blues, rock and Latin, by defining different music grammars and combining models.
In recent years, with the continuous improvement of various computer technologies and the rapid development of computer central procession unit(CPU) and graphics procession unit(GPU), the computer has made a huge leap in its computing power, which greatly shortens the time required for ANN training. Based on this, some research teams and companies at home and abroad have been able to create musical works that are “real”. The Google Brain team has developed a set of AI called Magenta based on the TensorFlow machine engine, which uses the LSTM network for automatic machine composition, and specializes in the research of AI art based on machine learning, including automatic composition, audio generation, picture generation and so on. At the same time, the Sony Computer Science Laboratory in Paris[12]also developed a flow machine AI system. The emergence of these research results has promoted the development of algorithmic composition, and it also means that the art of combining AI and music has more possibilities.
The style of the generated chord music is studied in this paper. In order to enable the computer to generate the expected style and satisfactory music, a new network model is proposed. There are two main aspects of breakthrough.
1) A music-style extraction module and a style classifier are adopted to the original model in this paper. The music-style extraction module divides the music content into two parts, namely the music-style informationMstyleand the music content informationMcontent.Mstyleembeds abstract information related to the musical style. Content information such as pitch and duration is encoded inMcontent.
2) For the performance evaluation of music, a combination of subjective and objective methods is adopted in this paper. In the subjective evaluation, the audience is invited to rate the style and melody of the music, respectively, and the evaluation result is obtained with the objective analysis.
1 Relevant Music Theory and Technology
1.1 Basic theory of music
Sounds are produced by the vibration of objects. In nature, we can hear many sounds, but not every sound in nature can be used in music. In the long-term historical development, in order to express their own emotions and their own life, some of the sounds have been selected, and these selected sounds have become music through historical development. The selected sounds slowly formed a system, which was used to express the emotions of the music thoughts. Tone has four properties, namely pitch, strength, length and timbre which are expressed in music as pitch, sound intensity, duration and timbre and also commonly referred to as the basic attributes of music. Depending on the frequency of the vibration of the object, the pitch is also different. Western music divides an octave into twelve equal parts (chromatics) according to the frequency of vibration, which is called the twelve equal temperament[13].
Melody is the soul and foundation of music, and whether a piece of music sounds good or not is also affected by its chord accompaniment. Melody refers to an independent monophonic part that combines musical rhythms, modes and beats to reflect the thoughts and emotions of a piece of music. Due to some specific emotional colors contained in music, the national characteristics formed by history and the national character of music displayed by melody are of great significance in music[14]. People call combinations of three or more tones that can be arranged in a third relationship as musical chords. Common third chords are triads, sevenths, ninths, elevenths, and thirteenths. This division is based on the difference in the number of notes that make up the chord. In this article, we will mainly start from two elements of music to explore the pros and cons of generated music, and at the same time we will also evaluate the generated music styles.
1.2 Grouping-combing algorithm (GCA)
ANN is a research field that has emerged in the field of AI since the 1980s. The network is a mathematical model that processes information by simulating the human brain from the perspective of information processing[15]. It can form different networks according to different connection methods, and its structure is shown in Fig.1.
People often use the recurrent neural network (RNN) to solve the problem of sequence generation. However, in the process of practical RNN application, there will be some problems, such as gradient disappearance and gradient explosion problems[16], which often make it difficult for the model to be successfully trained. Compared with the RNN, the LSTM network has its own advantages[17]. The network selectively forgets or retains memory information by designing a “gate” structure, and at the same time adds a memory unit to store memory information[18]. Thus it is able to solve the gradient problem and learn long-term dependency information, and it turns out that the LSTM network is successfully used in many tasks. The specific structure of the LSTM network is shown in Fig.2, where A represents the previous unit and the next unit of LSTM,xtrepresents the unit input at the current moment,htrepresents the unit output at the current moment, andσis the sigmoid activation function.

Fig.1 ANN structure

Fig.2 Structure of LSTM network
Previously, in order to make the generated music have satisfied chords, a GCA model was proposed based on the original LSTM model for music composition[19]. The structure of the GCA model is shown in Fig. 3, wherehchd,trepresents the output of the second layer LSTM, andxt-nandht-nrepresent the input and output beforenmoments.

Fig.3 Structure of GCA model
The model consists of a two-layer LSTM network:one for training and generating note sequences, and the other for training and generating chords. Specifically, entering a sequence of notes affects the resulting notes and chords for that measure. We process the note sequence input as a feature vector for training the first layer of the LSTM network. For convenience, the first layer of the LSTM network is called the note layer. At the same time, the note sequence input in this bar passes through the note layer to obtain the output of the corresponding time step. The output of each adjacent four time steps in the note layer is used as an input of the second layer of the LSTM network for chord training and generation. The second layer of the LSTM network is called the chord layer. It can be seen that the model is able to generate a chord for each measure of music.
The advantage of this model design is that if the music used for training has relatively good chords, when the training of the note layer is completed, there is no need to input the chord progression for training to the chord layer again. The chord layer will complete the training with the note layer, and there is a probability to learn the chords of the training music. In addition, considering the different probabilities of generating notes in the note layer, this randomness will be further reflected in the output of the chord layer, so the chords generated by this model will reduce their repeatability and make the generated chords more diverse.
According to the design principle and model characteristics, the input note is output through the first layer of the note layer network, and the output result is consistent with the output principle of the LSTM model. In other words, the input mode and the output mode of the note layer are the same as those of the LSTM model, and the difference lies in the second layer of the chord layer. After the four time steps, the outputs of the four time steps of the note layer will be combined to be used as the input of the chord layer, and the calculation formula of the input of the chord layer is
xchd,t=[yt-3,yt-2,yt-1,yt],
(1)
whereyt-3,yt-2,yt-1andytrespectively represent the output of the current four time-step note layers, which will be used as the input of the note layer to obtain the final result of the chord layer.
According to the model principle of the chord layer (based on LSTM), the expressions in each state of the chord layer can be obtained, and the calculation formulas are
fchd,t=σ(Wchd,f[hchd,t-1,xchd,t-1]+bchd,f),
(2)
ichd,t=σ(Wchd,t[hchd,t-1,xchd.t-1]+bchd,i),
(3)
ochd,t=σ(Wchd,o[ht-1,xchd,t]+bchd,o],
(4)
(5)
(6)
wherehchd,tis the final output of the chord layer for this measure;Wchd,f,Wchd,tandWchd,oare the weight matrices of the input gate, the forgetting gate and the output gate, respectively.
From the above formulas, the final output expression of the chord layer can be obtained, and the calculation formula is
hchd,t=ochd,t×tanh(ychd,t).
(7)
2 Multi-Style Chord Music Generation (MSCMG)
In order to solve the stylistic problem of generating chord music and ensure the quality of the generated music, MSCMG was proposed based on the previous GCA model. The network is roughly divided into an encoder, a GCA model, a music-style extractor, a style classifier, and a decoder. The newly added music-style extraction modules and the style classifier modules in MSCMG are used to solve the style problem of the generated music. The network model diagram of MSGMG is shown in Fig.4.

Fig.4 Flow chart of MSCMG model
Since we could not choose the general style of the generated music independently, the generated music style could not meet the user’s expectations, and the music-style extractor was proposed to solve this problem. The idea behind this module is that the network no longer directly encodes the entire piece of music, but separately encodes the information related to the music-style and the information not related to it. By using the music-style extraction module to separate the music style and music content in the original generation results, and then separately encoding the music-style information from the music, the style of the music could be manipulated during the generation process, thus giving some control over the generation of the music style.
In order to separate the music-style informationMstylefrom music, the music-style extractor uses one-hot encoding to generate a categorical variableMcv∈{0,1}N, whereNrepresents the number of styles in the entire music database[20]. The ultimate purpose of the experiment is to control the style type of the generated music. It is also necessary to perform style embedding processing onMcv, so that it can finally obtainMstylecontaining music-style information. The module that performs style embedding processing is called style embedding unit. The style embedding unit containsNstyles, all of which come from the original music database. The dimension of each style in the style embedding unit is the same, and is set to beMfor convenience, so that the size of the entire style embedding unit isN×M. In order to obtainMstyle, a dot product is performed on the style embedding unit style_unit andMcv, and the calculation formula is
Mstyle=Mcv·style_unit.
(8)
Then,Mstylewith the dimensionMis retrieved style from the style embedding unit. In order to ensure that MSCMG has correctly learned the style of the input music, the cross-entropy loss functionCsis used to optimize the result ofMcv, and the calculation formula is
(9)
Mcontentalso needs to be processed before it can be connected withMstyleto generate the final result. Here, the style information is further removed fromMcontentusing a style extractor. By design, the model should only encode style-independent information intoMcontent, and all style information will be encoded intoMstyle.In practice, the style information of music may exist in the form of music content. That is,Mcontentwill also contain some style information. In fact, a song is likely to span several different sub-genres or genres, and the information across genres is not a common denominator of music in the same genre. Thus it cannot be encoded into theMstyle.On the contrary, the characteristics of these songs will be encoded into the music contentMcontentas their respective music content, so that the music-style information appears inMcontent.Therefore, we need to remove these “entangled” styles from the content, so that the styles of the final generated music all come fromM.
This experiment uses the music-style classifier to solve the style entanglement problem. The music-style classifier is a feed-forward network, and it will be trained separately from the model. Generally, the music-style classifier will be completed before the model training. When it is trained, it is used to perform the separation style function in the whole model. The input and output of the style classifier are bothMcontent.The difference is that the relevant style information is required to be deleted from the output music content. This module uses cross entropy as the loss function for training, and the calculation formula is
(10)
whereCcis the loss function ofMcontent.
The loss function of the whole network consists of three parts:a GCA model, a music-style extractor and a music-style classifier. The loss of the GCA model is also represented by the cross entropy functionC, and the calculation formula is
(11)
Therefore, the loss function of the entire networkCvis
Cv=C+Cs+Cc.
(12)
3 Experiment
3.1 Database
The database used in this experiment contains three different music types, namely classical, Western ballad and popular music. The database sample format is unified in the musical instrument digital interface(MIDI) format. Among them, there are about 400 pieces of classical music. The music of this style is mainly composed of four parts, namely tenor, bass, soprano, and mezzo-soprano. This type of music is mainly composed of chords and connecting transition sounds in the middle. The melody of the whole music is mainly composed of chords, which is also an important feature of the classical music. Most of the Western ballad is written for playing on musical instruments. Although there are some differences, the ballad is very different from other types of music due to its strong national and regional colors.
The last type of music is popular music, which has the largest number of samples, including more than 2 000 pieces of music. This type of music does not have the obvious style characteristics of the above two kinds of music. On the contrary, its style is often unlimited. Because popular music is not limited to a specific form or style in terms of settings and common sense, according to different audiences, its corresponding styles will also be different. Thus we allow genres of music to span different sub-genres such as jazz, rock, blues,etc.
3.2 Data preprocessing
The music in this dataset is represented in the form of MIDI. Technically speaking, a MIDI file is a binary file in which all the musical information is stored as 0 s and 1 s. This file type contains event messages for songs generated by digital instruments. Unlike wave files, MIDI files do not sample the music, but record each note in the music as a number, so the size of MIDI files will usually be small enough to meet the needs of long-term music.
In this experiment, we use the multi-hot vectors(P,T,D) to represent the sequence of the note content, where each vector represents a note.Pacts as a one-hot tensor andP∈{0,1}t, n, wherenrepresents the total number of distinct pitches in the note andtrepresents the number of multi-hot vectors.Trepresents the time difference between the current note and the previous note.Drepresents the duration of the current note.
TandDare both one-hot tensors of size {0, 1}t, 33. The superscript 33 means that the note is divided into 33 units. The basis for this division is to model common notes more conveniently. WhenT=0, the current note and the previous note are played at the same time, and the sequence information of the music can be obtained by combining different multi-hot vectors together. Using it to encode MIDI files allows us to model music relatively easily for later experiments. Figure 5 shows an example of the conversion from MIDI to the representation described here. From the Fig.5, it can be seen that each column in the multi-hot vector represents a note, while each row of the multi-hot vector represents a different characteristics of the note:pitch, interval and duration. The ratio of training set to the test set is 5∶1 for specific experiments.
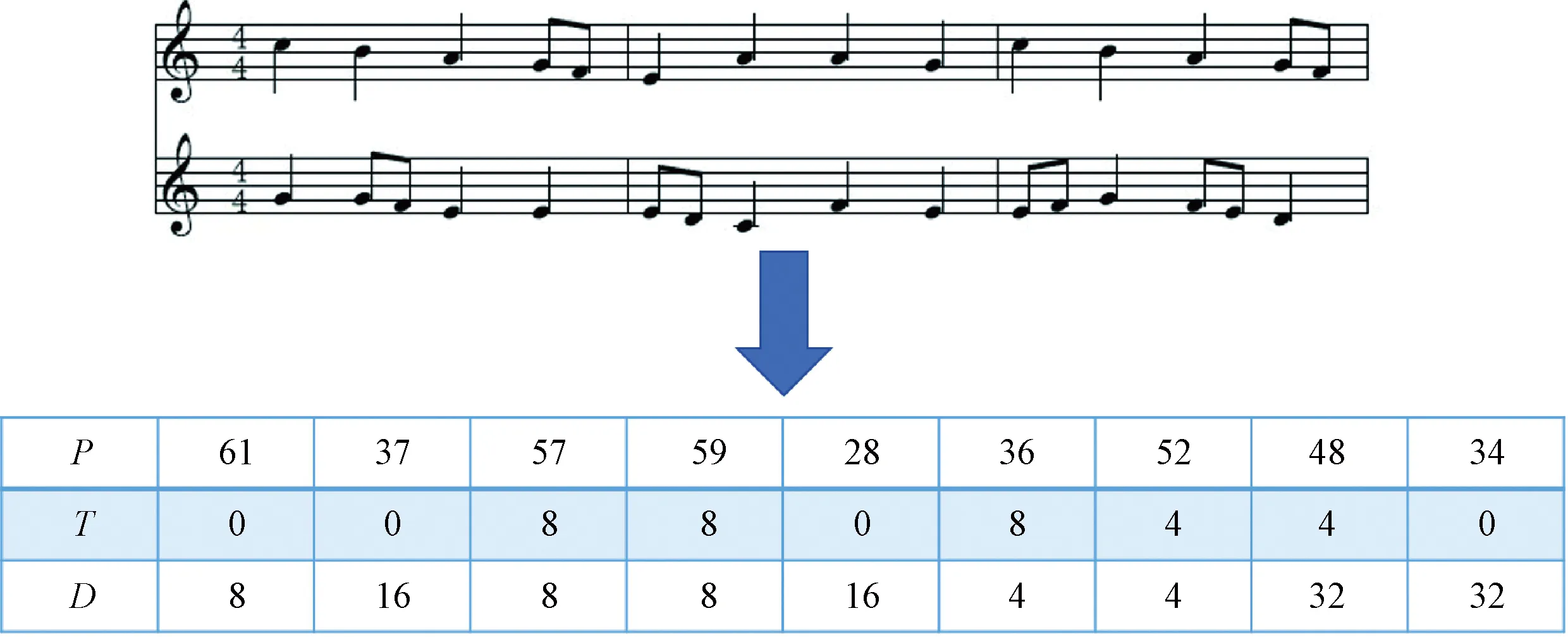
Fig.5 Conversion from MIDI to multi-hot vector
3.3 Music generation
The MSCMG network is used in this experiment to generate chord music. Before training, the music database used in the experiment needs to be processed. The music samples with three different styles are processed separately. The purpose is to facilitate the subsequent exploration of the generation of different styles of music. After setting the training parameters of the model, the model is trained.
Then, the trained model is used for music creation. In the process of music generation, the music-style extraction module is used to process the results generated by the model to a certain extent. The entire generated music result is divided intoMcontentandMcv, then the music-style information contained inMcontentis eliminated by the music-style classifier, and at the same time, the style embedding unit is used to embedMcvto obtain the final music-style informationMstyle.
Finally, the combined music information is processed according to certain rules, as shown in Fig. 6. The purpose of this step is to remove those high and low notes in the generated music result, and make the whole music more harmonious. After processing, the MIDI music with the corresponding styles embedded in it would be gotten.

Fig.6 Music result processing flow chart
4 Evaluation of Experimental Results
In this experiment, three different models are set up to verify the effectiveness of the music-style extraction module and the music-style classifier in the MSCMG network. MSCMGnetais the basic model,i.e, the model does not include the music-style extraction module and the music-style classifier. A music-style extraction module is added to the MSCMGnetbmodel, and the corresponding music style is added to the result by the method of style embedding, so that it can generate music with different styles. The MSCMGnetcmodel not only includes a music-style extraction module, but also includes a music-style extractor. The validity of the model is judged by analyzing and comparing the music generated by these three models and the previous model.
4.1 Similarity comparison
The similarity in the results generated by different models under different music styles and the effectiveness of the models are verified. The similarity between the music generated by four models and the database samples is compared. The similarity between the generated results and the database can indicate to a certain extent whether the model has generated music works in the current music style as a whole. The higher the similarity, the more similar the music generated by the model to the current music style. We generated 50 pieces of music for each model under each music style, compared the generated results with the music samples in the database, and finally obtained the similarity between the results under different music styles and the database samples. The results are shown in Table 1.
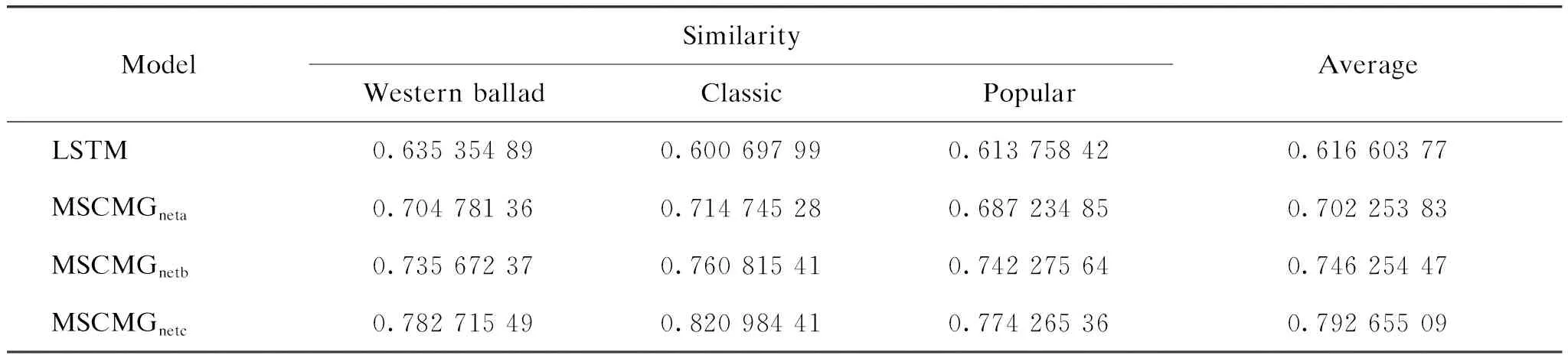
Table 1 Comparison of similarity between music generated by models and database samples
It can be seen from Table 1 that under three different music styles, the similarity between the music generated by MSCMGnetcand the database samples is the highest. In addition, it can be seen that the music generated by other three models is more similar to the samples than that generated by LSTM. It shows that the network model with the new music-style extraction module and the new music-style classifier can generate music that is closer to the embedded style, and to a certain extent, it also shows that two new music modules in the network can indeed play their role in generating multi-style music.
4.2 Model advantage comparison
The similarity mentioned above can indeed explain the learning ability of the model to some extent, but if you want to show the advantages of the model more comprehensively, just evaluating the similarity is not comprehensive enough. Then it is analyzed whether the model can learn the corresponding music creation information from the database to illustrate the effectiveness of the model.
For this part of the evaluation, if the pitch distribution in the generated music is roughly the same as the pitch distribution in the database, it can be judged that the model generates music similar to the sample style, because the music pitch distribution has a great relationship with the style mode and the scale of the music. Figures 7-9 show the pitch distributions of the model-generated music with different music styles in the key of C major.
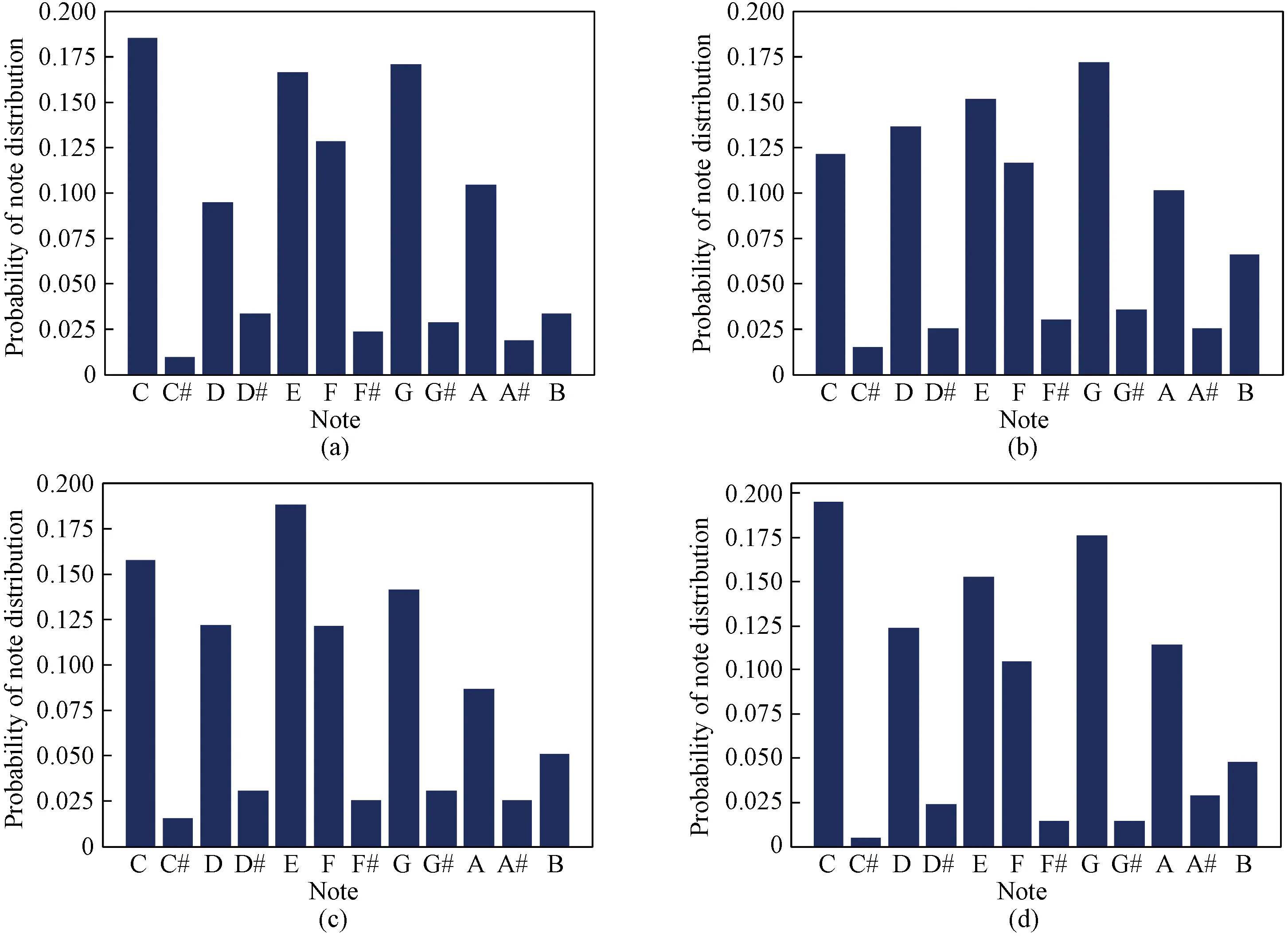
Fig.7 Pitch distribution of music with Western ballad style:(a) database; (b) MSCMGneta; (c) MSCMGnetb; (d) MSCMGnetc

Fig.8 Pitch distribution of music with classical style:(a) database; (b) MSCMGneta; (c) MSCMGnetb; (d) MSCMGnetc


Fig.9 Pitch distribution of music with popular style:(a) database; (b) MSCMGneta; (c) MSCMGnetb; (d) MSCMGnetc
It can be seen that under three different music styles, the pitch distribution of the music generated by the MSCMGnetcmodel has the highest similarity with the pitch distribution of the database samples. The pitch distribution of the MSCMGnetbmodel is basically similar to the pitch distribution of the database samples as a whole,i.e., the pitches with the highest frequency are roughly the same, but there is a certain deviation in the details of the pitch distribution. This is because the model has “entangled” style information when generating music, which has a certain impact on the final generated results. However, there is a big difference between the pitch distribution map of the music generated by the MSCMGnetamodel and the database samples. Although it is observed from the frequency of occurrence of different pitches, the two cannot be well corresponded, and there are obvious differences. However, it can be seen that the pitch distribution of the results generated by the MSCMGnetcmodel can still be distinguished between high and low frequencies, and generally match the database samples on the whole.
4.3 Subjective evaluation of music
The generated music is evaluated subjectively by the listener score. In addition to scoring the three models in this experiment, the audience also needs to evaluate the music generated by the previous models. The scoring is mainly composed of two aspects. The first is to invite listeners to evaluate and score the pleasantness of the generated music; the second is to evaluate and score whether the generated music style meets the expectations of the listeners. The highest is 5.00 points and the lowest is 1.00 point. Next, a weight is added to the results of the two aspects in order to get the final score. The size of the weight also depends on the audience. According to statistics, about 80% of the audience think that the pleasantness of a piece of music is more important, and the remaining 20% of the audience pay more attention to the style of the music. Tables 2-4 are the scoring results of Western ballad styles, classical styles, and popular styles.

Table 2 Comparison of scores between music generated by different models with Western ballad style
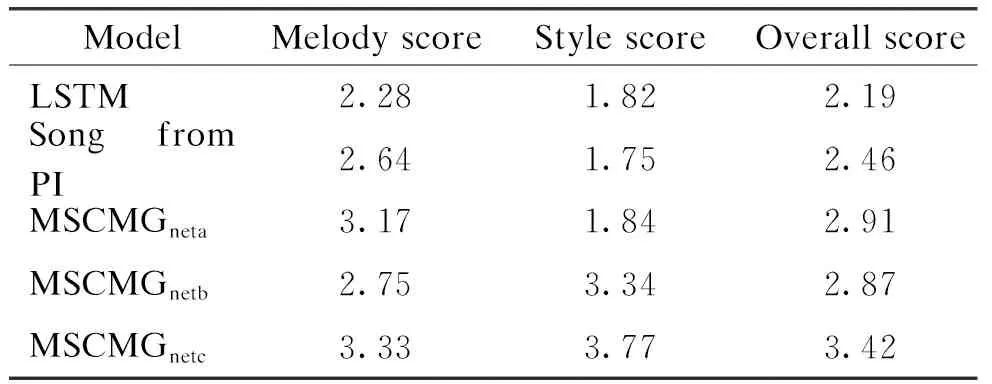
Table 3 Comparison of scores between music generated by different models with classical style

Table 4 Comparison of scores between music generated by different models with popular style
It can be seen that under different music styles, the performances of MSCMGnetaand MSCMGnetcare basically the same in terms of the melody score, while the performance of MSCMGnetbis slightly worse. This may be due to the fact that only a music-style extractor is added to the model, which will cause entangled style information in the process of music generation and affect the quality of the final generated music. The other two models do not have the problem of style entanglement, because MSCMGnetais directly generated, and the entangled style information is cleared in MSCMGnetc. In terms of the style score, it can be seen that the score of MSCMGnetcis higher than that of MSCMGnetb, and the score of MSCMGnetbis higher than that of MSCMGneta. Compared with LSTM, the model proposed in this paper performs better in generating music. Therefore, adding a model with a music-style extraction module and a music-style classifier can indeed control the generation of music styles to a certain extent, and can also ensure the quality of the generated music.
5 Summary and Outlook
In order to solve the problem of generating music, a MSCMG network is proposed, and a music-style extraction module and a music-style extractor are added to the network. The music-style extraction module can separate the content information and style information of the music, and then encode the two parts separately. The style embedding unit is used to embed the style information of the music and determine the generated music style. The function of the sample extractor is to delete the style information contained in the music content part, so that the style characteristics of the finally generated chord music are all controlled by the music style. Through comparative experiments and ablation experiments, it is found that the network can generate music with a style similar to the embedded music style, which shows that the network can indeed solve the problem of generating music styles to a certain extent.
In addition, there are still many problems to be solved. Firstly, the database used in this experiment is not comprehensive enough, and a more complete and comprehensive music database needs to be established for the experiment, including more styles and more samples. Secondly, more reasonable evaluation criteria are needed to evaluate the performance of generated music to verify the effectiveness of the model. Comparison of the consistency between the style of the generated music and the embedded music style has important implications for evaluating the effectiveness of the model. Finally, the generated music is not precise and diverse in style. The generated music will also contain many sub-genres under the main style. Most of these sub-genres are not what users expect, and when users want to generate music in a certain sub-genre style, the results are often unsatisfactory. Future research work may focus on solving the above problems.
 Journal of Donghua University(English Edition)2023年4期
Journal of Donghua University(English Edition)2023年4期
- Journal of Donghua University(English Edition)的其它文章
- Image Retrieval with Text Manipulation by Local Feature Modification
- Polypyrrole-Coated Zein/Epoxy Ultrafine Fiber Mats for Electromagnetic Interference Shielding
- Design of Rehabilitation Training Device for Finger-Tapping Movement Based on Trajectory Extraction Experiment
- High-Efficiency Rectifier for Wireless Energy Harvesting Based on Double Branch Structure
- Review on Development of Pressure Injury Prevention Fabric
- N-gamboyl Gemcitabine Inhibits Tumor Cells Proliferation and Migration