
高校智慧图书馆信息组织及挖掘研究
2023-09-22 11:45佘欣媛林娜哈尔滨工业大学威海图书馆
中国信息技术教育 2023年18期
佘欣媛 林娜 哈尔滨工业大学(威海)图书馆
●引言
当前,图书馆面临的主要现状如下:一是馆藏资源类型越来越多,资料不再局限于纸质图书、电子图书,视频、音频、图片资料库也越来越庞大;二是读者阅读习惯改变,移动设备的便捷性让人们更倾向于无纸化阅读;三是图书馆角色改变,图书馆已经不是读者唯一的知识提供者,网络世界丰富多样的信息有时更能吸引读者的目光;四是人工智能程序迅速发展,有成为下一代信息中心的趋势。然而,虽然网络资源数量庞大,但读者进行信息筛选的代价也不小;虽然人工智能程序能够与人类无障碍交流,但其资料库并不专业,无法给用户提供高质量的信息。面对这些问题,图书馆应肩负起知识传递者的责任,做好业务转型,明确建设智慧图书馆的发展方向。
智慧图书馆建设研究主要有以下几个方面:元宇宙背景下虚实结合、数字孪生技术在图书馆中的应用,建立多元学习空间模型,将用户部分学习行为放到网络上提高用户互动性[1-4];用5G、区块链等技术改变图书馆底层数据存储逻辑和网络拓扑结构,增加数据安全性[5];人工智能生成程序(Artificial Intelligence Generative Content,AIGC)与图书馆信息咨询业务结合[6];智慧图书馆开放性和共享性研究,将公司、政府、技术小组等多类对象纳入图书馆服务平台中来,减少交流障碍,提高服务效率[7];使用物联网射频技术打造智慧图书馆硬件体系,如智慧书架等设施。[8-9]
信息时代的图书馆尤其是读者信息质量需求更高的高校图书馆,应该重视加强信息管理及分析。所以,本文尝试从智慧信息平台架构、元数据组织格式、检索算法等方面阐述高校智慧图书馆框架下信息组织与分析挖掘方法。
●智能信息平台框架
高校智慧图书馆背景下的信息平台应为用户提供24小时全天候的实时信息服务,并满足用户个性化的需求。同时,不同于网络资源多而杂,图书馆应为读者提供更深层次的精细化的知识,减少检索代价,提高信息质量。因此,高校智慧图书馆的信息平台架构自底向上设计主要包括三个层次:数据层、算法层、用户接口层(如下页图1)。

图1 智能信息平台框架
数据层按存储对象不同分为两大库:用户信息库和知识库。其中,用户信息库用于存储每位用户个人特征数据,便于后续程序进行特性化服务处理;知识库按照数据类型不同又包括纸质图书库、电子图书库、电子期刊库、视频库、音频库、图片库等。所有这些馆藏数据库合并在一起组成综合信息平台。
算法层是在数据层的基础上对馆藏数据进行文本分词、特征提取等操作,将信息细化并挖掘其中关联关系。数据类型不同处理方式也有所区别,图像信息需要进行图像识别工作,音频信息需要进行语音文字提取工作。
当用户接入信息平台咨询或检索信息时,接口层的人工智能生成程序—如ChatGPT,通过交流获取用户输入信息并传递给算法层,算法层提取信息中的关键词并在综合信息平台中检索,检索结果根据用户个人特征排名后通过人工智能程序使用自然语言反馈给用户。
●以用户为中心的信息维护
高校智慧图书馆框架下的信息资源平台区别于传统平台的其中一个特征就是建立以用户为中心的信息管理、组织、检索模式。一改以往无差别的信息反馈形式,以用户为中心的信息平台搜集、存储用户日常行为数据,为每位用户建立特征库。当用户使用平台咨询、检索信息时,平台根据用户特征数据对检索结果筛选、排序后再将最终结果传递给用户。平台搜集的用户特征类别如图2所示。

图2 用户特征分类
数据库记录用户的身份信息、日常浏览习惯、年级年限、学科专业、重要的浏览记录等。其中,身份信息包括在读学生、教师、科研员、机关管理员等;年级年限指用户所处年级或在校时长,通常认为在校时间越长信息需求深度越深、知识领域越窄;专业涵盖学校所涉及的学科领域如海洋、汽车等;浏览习惯包括用户日常惯用的数据库平台、浏览及下载的信息类型、高重复的检索关键词等。不同身份及年龄的用户信息需求深度及宽度有所差别,大一、大二等低年级学生可能较为关注本专业基础学科知识的学习和积累,研究型教师的学科领域更细化且对信息质量要求更高。同样,不同专业之间权威数据库不尽相同,平台在用户个性化服务中要参考用户研究的细分领域有针对地进行检索。
●多资源融合的元数据格式
图书馆的信息资源来源于多个平台,包含多种类型,主要有馆藏的纸质图书、电子图书、各期刊数据库、专利数据库、视频资料库、音频资料库、图片资料库等。虽然大部分图书馆均提供一站式检索,但基本是以商用平台为主,很少自己开发,这导致了商家之间购买协议及接口不兼容的问题,统一检索不能针对本馆馆藏的所有资源,并且馆内用户均使用同一个账户或IP地址段访问,无法做到用户区分及个性化服务。高校智慧图书馆的信息服务应该具备全面、智能、高质量、个性化等特点,建立图书馆自己的综合信息平台是图书馆服务深化的必然需求。不同类型的资源信息内容不同、格式不同,要实现统一管理及检索,首先需要设计资源间可关联的统一的元数据格式。全方位的检索应该能够根据用户需求检全、检准,并为用户提供关联知识及交叉领域的信息推荐。为了体现信息资源之间的关系,笔者使用实体-关系模型(Entity-relationship model,ER)对元数据进行概念模型设计(如图3)。
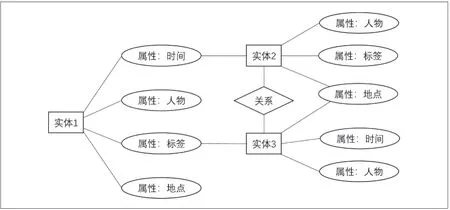
图3 元数据ER图
在图3中,数据被分为实体、属性、关系三种,每个实体包含若干个属性,实体与实体间存在不同类型关系。例如,新中国成立前及新中国成立初期文学家林徽因与徐志摩的相关内容就可以作为两个实体存储在数据库中,他们各自包含若干属性,如代表作、所处时间、地点、关系等。林徽因的代表作《你是人间的四月天》、徐志摩的代表作《徐志摩诗集》等都是馆藏书籍,且林徽因与徐志摩之间经常有学术上的往来,是朋友关系。当用户搜索林徽因时,信息平台应能够自动联想出与林徽因关联的以上信息供用户选择(如图4)。
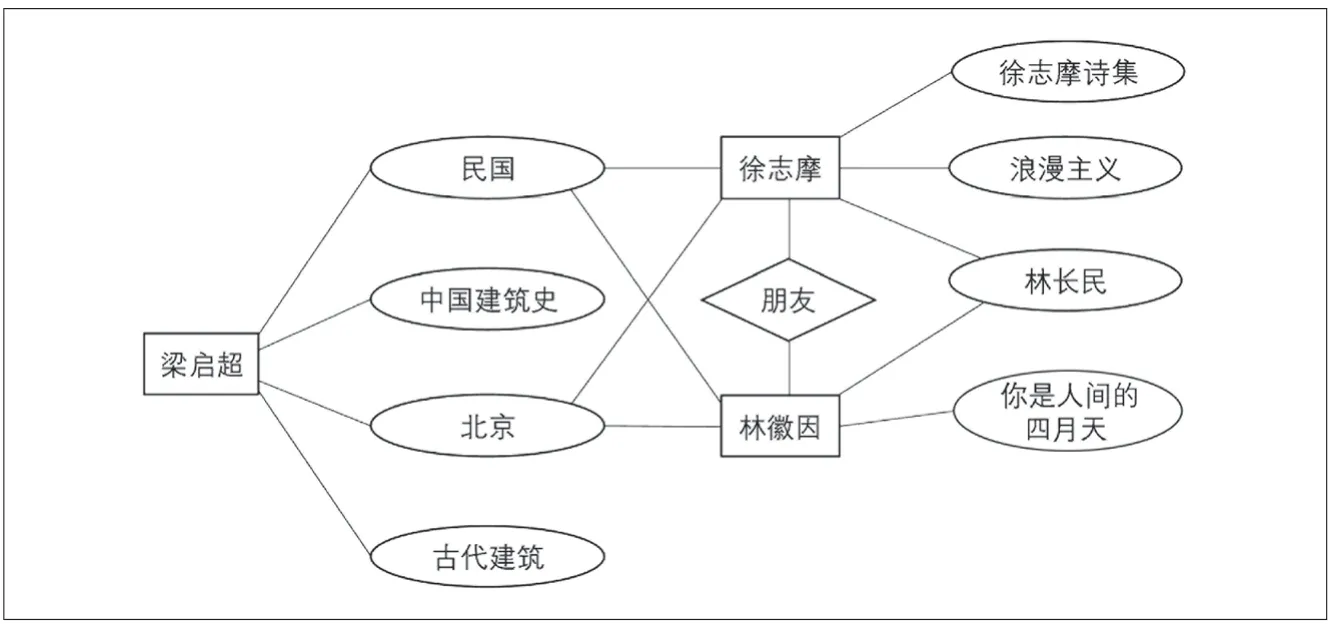
图4 元数据ER图示例
根据馆藏资源类别及ER图,还可以设计多资源融合信息平台元数据组织格式,如下页表所示。
每条元数据都包括表中的各个字段。其中,名称字段指元数据的标题或信息标识,如果是图书可以是书名,如果是人物、事件等信息可以是人物名称、事件名称;资源类型字段指该条元数据描述信息的类型,是纸质图书、期刊文章,还是某个文学作家、历史事件等;标签字段存储了元数据的描述性关键词,如某个教学视频主要讲解了Python面向对象的代码解释方式,那么标签属性就可以概括成“Python”“编译”“解释性语言”等;内容字段包括元数据的重点内容、名言名句等代表性信息,提高用户内容检索效率;时间、地点字段表明了作者、关联地点、重要时间节点等信息,便于用户根据时间段检索资源;学科字段存储了数据所属学科领域,该字段可以存储多个学科字段,是交叉学科发现以及用户定制检索的基础字段;互动数据字段用于表明元数据质量或者受欢迎程度,可以是文章下载量、浏览量,图书借阅量以及其他类型资源转发、点赞、评论量,一般认为该项数值越高,用户感兴趣可能性越大;其他关联关系字段可以存储多个值,用于指明该元数据与其他元数据之间的关系,如人物关系、包含关系、类别关系等。
●综合检索算法
不同类型信息检索算法有所区别,按照处理对象类型不同可将其分为文本检索、图像检索、音频检索等。其中,文本检索最基础、应用最广泛。文本检索过程包括清洗、分词、特征提取等方面,如下页图5所示。
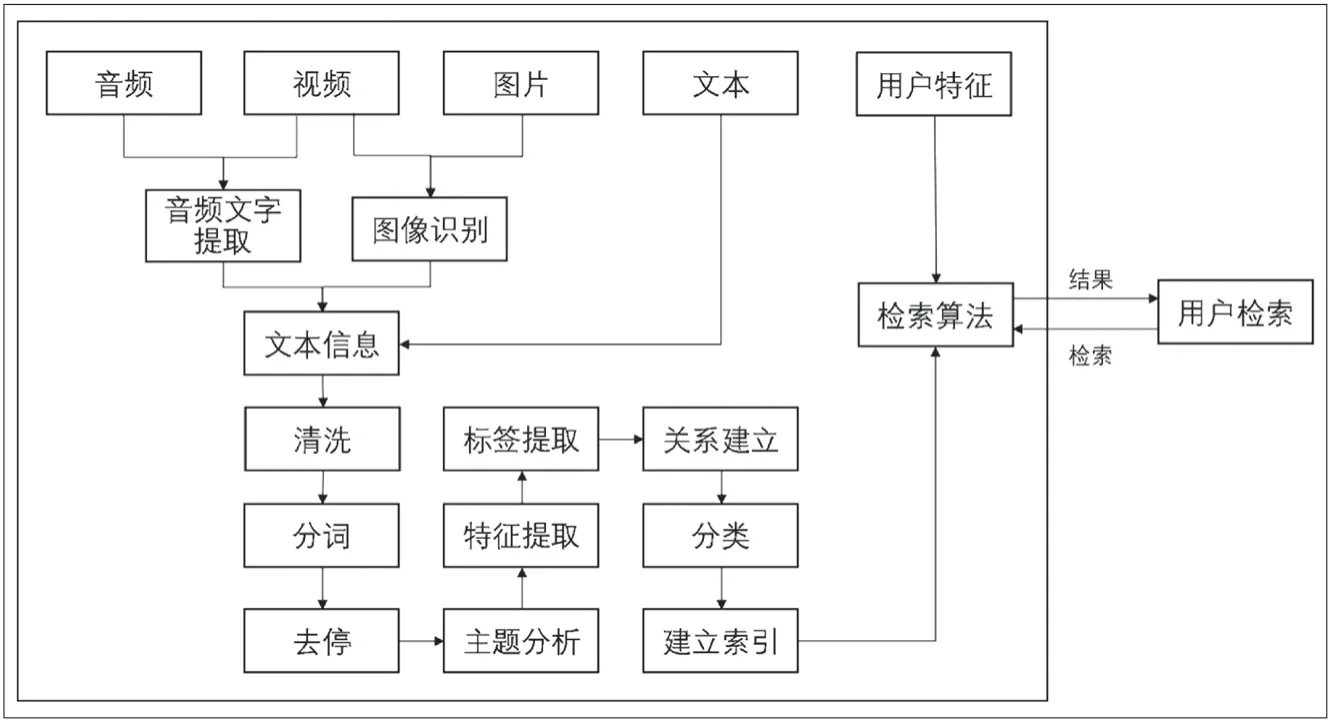
图5 综合检索算法流程图
首先,去掉文本中的重复项、空值、逻辑错误等影响分析的脏数据,即数据清洗;其次,对文本进行分词,也就是将一整句话划分为若干个有实际意义的词,分词处理时需要根据文本语种分别采用不同程序处理,Python语言框架下的NLTK(Natural Language Toolkit)库实现了多种英文分词算法,但是在中文分词方面表现不佳。相对而言,Jieba库的分词算法则比较适合中文分词场景。
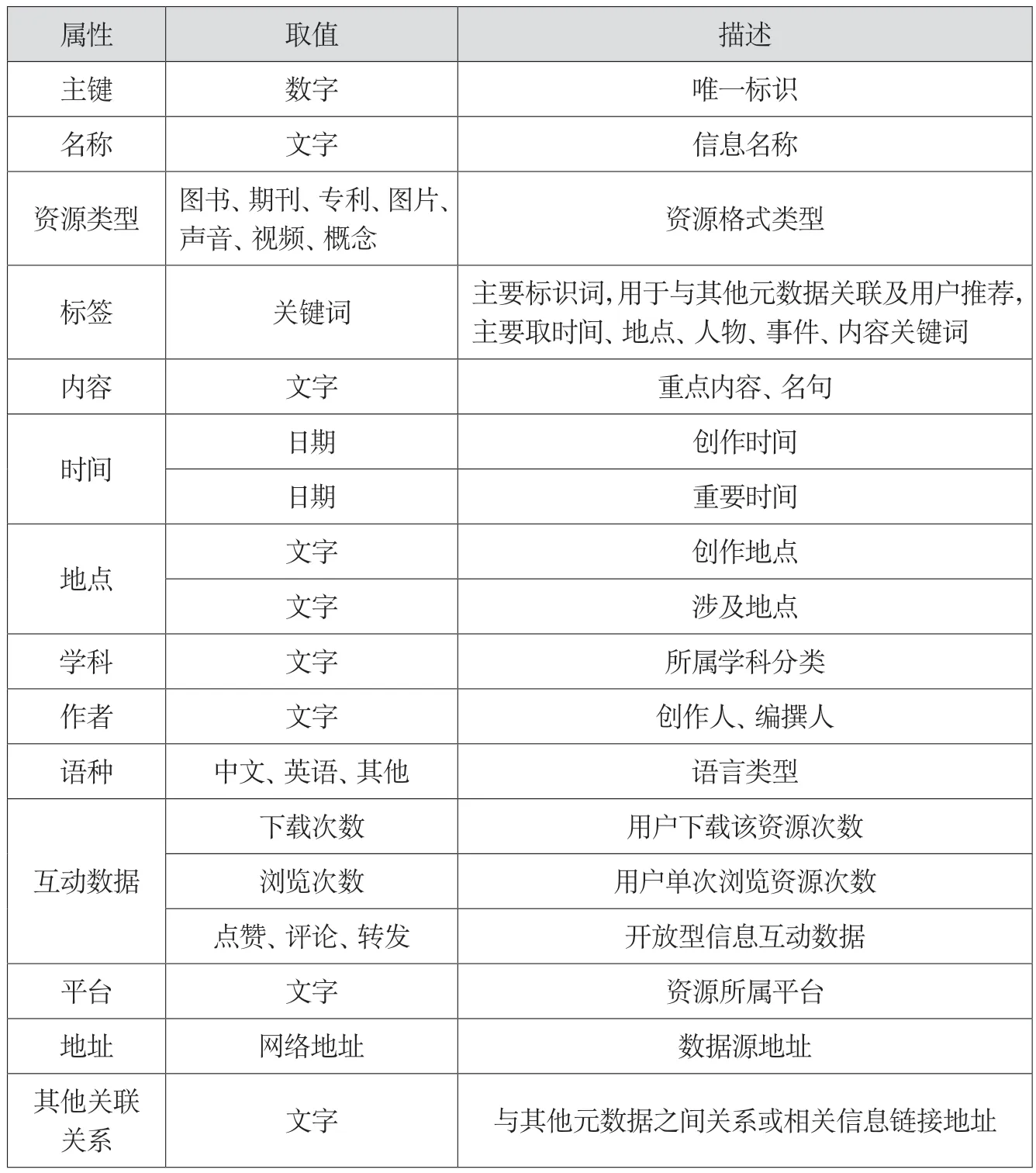
元数据信息组织格式
在得到词库后,需要根据停用词表去掉已经不用的词汇,NLTK和Jieba库中都有相应的停用词表。在去停后,通过主题分析算法找出文本主题词,主流主题词提取算法有文档主题生成模型(Latent Dirichlet Allocation,LDA)以及词频逆文本频率指数算法(term frequency–inverse document frequency,TF-IDF)。前者根据实体词在文档中出现概率高低找出文档主题;后者认为在本文档中出现概率高而在其他文档中出现率低的词具有很强的代表性,使用哪种算法需视情况而定。
在主题分析后,通过聚类算法在主题词中选出最具有代表性的几个词作为文档的特征标签项,并存储在数据库文档元数据标签字段中。同时,根据主题词分析结果使用神经网络算法,如膨胀卷积模型(Dilated convolution Model)提取文本特征并找出实体之间的关联关系,将实体作为元数据存储到数据库中并记录该关系。
检索算法有很多种,如哈希搜索、分支界限搜索(Branch and Bound Search Algorithm)等,无论使用哪种检索算法,针对高校智慧图书馆的智能信息平台这种用户信息需求专业性较强的场景,垂直搜索要比普通的页面搜索更能为用户提供有深度的服务。原因是,页面搜索注重信息广度和普遍性,垂直搜索追求信息挖掘深度和精度,所以垂直搜索更适用于高校智慧图书馆这种专业性高的场景。同时,高校智慧图书馆框架下的信息检索结果需要根据用户特征对结果进行排序后再反馈给用户。
同样检索关键词“神经网络”,对于借阅书籍较多的低年级学生平台将图书检索结果排在前面,而对于科研型教师则更多地将期刊、专利等方面的信息反馈给用户。
与文本检索不同,图像检索和音频检索均需要提取视频、图片、音频中主要信息,需要将其转成文字后再进入文本检索过程。在图像特征提取方面,常用算法有卷积神经网络(Convolutional Neural Networks,CNN),它模拟生物视觉神经信息处理过程,输入图像经过模型卷积层、池化层、全连接层等多层处理输出特征信息,CNN主要用于物体识别、行为认知等领域。音频内容提取已有很多较为成熟的音频文字提取工具,如百度AI、讯飞听见等。
●知识图谱展现
用户接口层的人工智能生成程序接收到检索结果后,使用自然语言将结果反馈给用户。为了更直观地展现检索结果之间的关系以及衍生信息,平台同时使用知识图谱形式呈现检索结果内容。知识图谱工具有citespace、Gephi、vosviewer、SATI等。
仍以检索关键词“林徽因”为例,通过检索算法识别关键词“林徽因”,将数据库中与“林徽因”相关的元数据及彼此关系以图的形式反馈给用户,如果用户属于低年级学生,平台主要反馈馆藏图书相关信息。平台不但将“林徽因”的个人情况及文学作品《你是人间的四月天》反馈给用户,而且与“林徽因”相关的其他作家如“徐志摩”及其代表作也被显示了出来,同时也给出各个作品的链接平台,用户可以通过点击直接跳转到书籍页面。
●结论
高校智慧图书馆要重视信息的分析与处理,保证用户信息服务质量。智能信息平台使用融合的信息平台和综合检索算法为AIGC提供了与前台用户交流的资源库,但是图书馆的很多数据都有版权限制,能否将其直接传递给AIGC进行学习还需要进一步讨论。为了尽可能多地利用多个馆的馆藏资源,设计馆与馆之间通用的元数据组织格式也是智能信息平台未来改进需要考虑的问题。
猜你喜欢
金桥(2022年5期)2022-08-24
学生天地(2020年9期)2020-08-25
意林图解作文(小学版)(2019年6期)2019-07-16
专利代理(2016年1期)2016-05-17
海峡姐妹(2016年9期)2016-02-27
海峡姐妹(2016年2期)2016-02-27
小天使·一年级语数英综合(2014年6期)2014-07-22
智慧与创想(2013年7期)2013-11-18
质量与标准化(2010年5期)2010-05-03
质量与标准化(2010年3期)2010-05-03
