
基于YOLOV5-MobilenetV3 和声呐图像的鱼类识别轻量化模型
2023-09-21 15:28罗毅智陆华忠周星星齐海军刘志昌
广东农业科学 2023年7期
罗毅智,陆华忠,周星星,袁 余,齐海军,李 斌,刘志昌
(1.广东省农业科学院设施农业研究所,广东 广州 510640;2.广东省农业科学院动物科学研究所(水产研究所),广东 广州 510645;3.农业农村 部设施农业装备与信息化重点实验室,浙江 杭州 311000;4.广东省农业科学院,广东 广州 510640)
【研究意义】近年来,随着对动物蛋白需求的不断增加和传统渔业资源的严重减少,渔业正逐步向水产设施养殖转型[1-4]。其中,网箱生物识别是海洋牧场的关键作业流程之一。由于网箱养殖局部密度大、水体透光率不足,视觉成像效果不佳,大大影响智能渔场的作业效率[5-6]。浑浊水中悬浮颗粒可导致图像对比度低、模糊和失真[7],尽管光学成像类型的相机提供了高分辨率图像,但未知的成像条件,包括光学水类型、场景位置以及海洋介质的吸收和散射特性,对光信息的传输有重大影响,进而导致严重的图像失真[8]。考虑到光学传感器在水下场景中的客观局限性,浑浊水体成像检测方法常利用非光学传感器,如激光雷达、声呐等[6,9-14]。声呐系统根据声波发射和回收的计算过程获得图像,其中发射的声波在遇到目标物体后会被反射和接收。因此,接收到的回波包含不同物体显著的声波吸收特性。由于水声通道的复杂性和声波散射的多变性,接收到的回波中还混杂着环境噪声、混响和声呐自噪声等干扰,对声呐图像的准确目标检测提出重大挑战。
【前人研究进展】传统的目标检测 方法手动提取目标区域的特征,通常使用一定大小的帧作为滑动窗口来遍历整个图像,称为“锚点”。通过设置不同的长宽比和尺寸,采用穷举方法确定目标,导致模型耗时长、鲁棒性差[15-17]。近年来,随着计算机技术的发展,以深度学习为代表的技术在水下图像除雾和目标识别领域得到广泛应用[18-19]。Liu 等[20]利用图像处理和深度学习相结合的方式,实现海洋生物的物种识别和密度计算,该模型主要解决了非均匀光场下生物图像的特征优化问题。邓步等[21]提出一种基于声呐信息融合的水下图像增强模型,该模型采用去雾技术,显 著提高检测目标的对比度。刘承峰等[22]采用了一种基于多尺度卷积核双端注意力机制融合的模型,该模型采用多尺度卷积滤波算子,构造多分辨率卷积神经网络,进一步提高水下小目标的检测精度。此外目标检测的主流算法可大致分为两阶段检测模型和单阶段检测模型两种类型。其中基于区域卷积神经网络(Faster Regions with CNN features,Faster RCNN)引入 区域生成网络(Region Proposal Network,RPN),该模型提取输入图像的特征,同时生成候选区域,避免重复提取特征图,同RCNN 相比,降低了模型的计算复杂度,提高了目标检测的速度和精度[23]。单阶段检测模型将目标检测定义为“一步完成”,同时完成目标分类、定位以及检测,在精度上,两阶段检测模型要优于单阶段检测模型;在速度上,单阶段模型实时性更强[24]。YOLO 系列模型被认为目标检测领域的里程碑。科研人员在YOLO 模型基础上进行了系列改进,提出YOLOV2、YOLOV3 以及YOLOV4 版本等,进一步提高了模型的检测精度,同时保 持了模型的实时性。与Faster RCNN 不同,YO LO 系列将目标检测作为一个回归问题,直接得出检测对象的位置、类别以及置信度。有效的目标特征检测器和分类器为深度学习方法提供了在浑浊水环境中的优势[25-26]。此外,偏振成像技术通过深入挖掘散射光场中偏振信息的独特性和差异性,在去除背景散射光和获得清晰 的水下图像方面具有明显优势,该方法利用入射偏振光的偏振特性,可 以分离场景中的这两种光,有效还原清 晰的场景,提高成像结果的对比度和清晰度,辅助水下目标的检测和识别[27]。
【本研究切入点】综上所述,环境噪声、混响和声呐自噪声为对水下声鱼类检测的主要难点之一,对目标检测模型的网络结构进行优化可以大幅度提高检测精度,截至目前,很少学者研究兼容鱼类检测精度和轻量化模型。【拟解决的关键问题】本文以罗非鱼为研究对象,通过比较不同水下成像方式的优缺点,采用一种前视声呐声学成像技术,提出一种轻量级的鱼类识别网络(LAPR-Net,Lightweight Aquatic product Recognition Network),实现浑浊水体下的鱼类检测。
1 材料与方法
1.1 试验条件
试验周期为2022 年9—11 月。如图1 所示,浑浊场景鱼类识别平台包含帆布池(长×宽×高=2.0 m×2.0 m×0.8 m)、多源信息采集平台、网箱(长×宽×高=0.6 m×0.6 m×0.6 m)。其中,多源信息采集平台包含机械结构、水下摄像头、录像机、声呐以及声呐数据采集器。
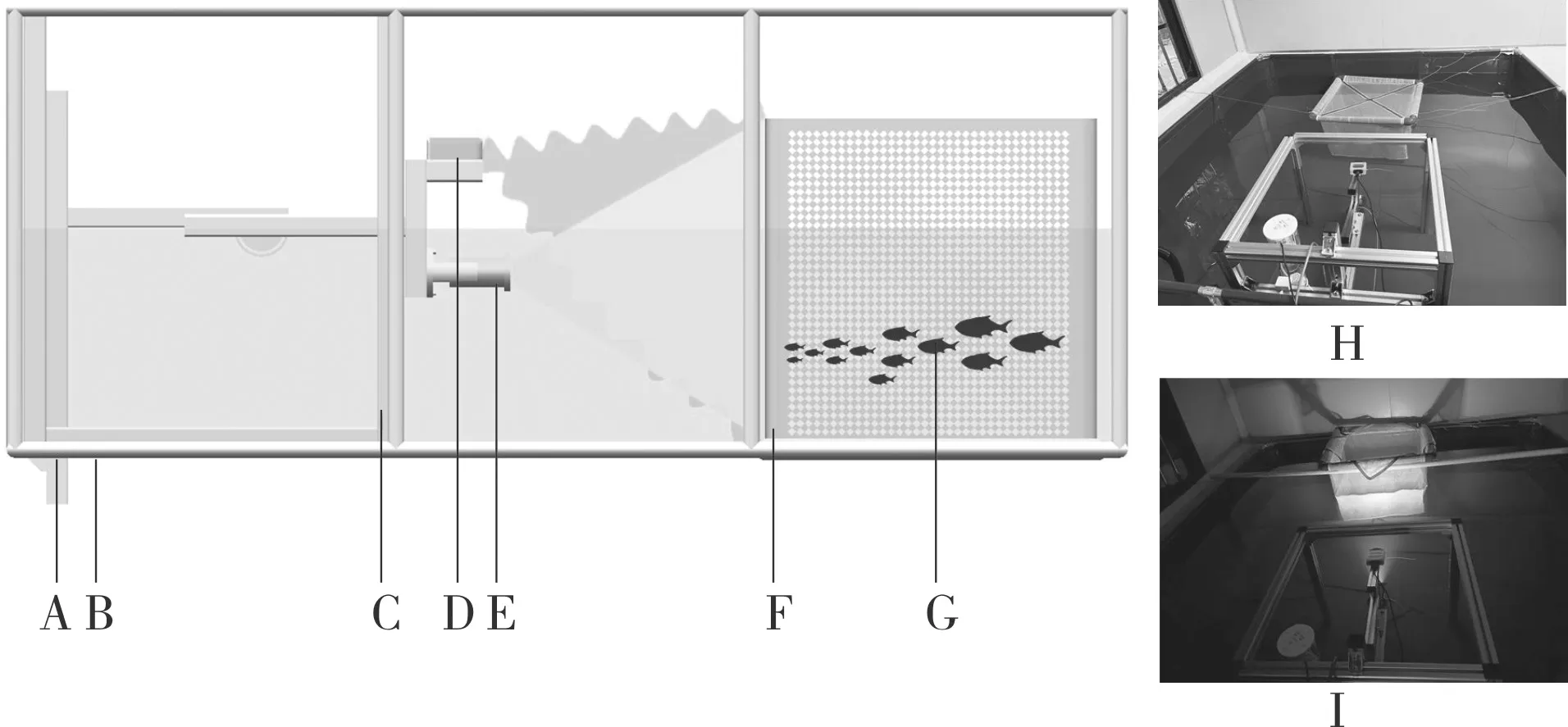
图1 试验场景示意图Fig.1 Schematic diagram of the test scene
多源数据集由水下摄像头(霸勒思,E5MP3CX10)和前视声呐(珠海蓝衡科技有限公司,1206D)记录如图2 所示。相机的底部固定在铝型材上,为捕捉网箱以及鱼群(网箱鱼群数量n=6),相机镜头逆时针向上倾斜10°。视频同时记录并存储在硬盘,声呐数据集存储于声呐数据采集器。此外,声呐的声速为1 493.84 m/s,压力约为0.0015 Mpa,声呐采集视角设置为130°。
图2 检测模型数据标注实例Fig.2 Data labeling instances of detection model
1.2 数据集构建
为提高模型的泛化能力与鲁棒性,将全天视频文件(.DB)转化为MP4 视频,分离出不同时段的图像数据2 004 张,经图像翻转、对比度调整以及亮度调整后,最终浑浊场景鱼类识别数据集(WR-dataset)扩增至6 012 张,其中训练集和验证集5 400 张、测试集612 张。采用开源交互式标记工具Labelme 进行标注,标注类别共有两个,红色框代表网箱,绿色框代表鱼类。为减少人为标记误差,标记时2 人1 组,标记过程中如果对图像标记的结果不确定,则将图像从数据集中删除;最后,以MSCOCO 格式保存为JSON文件。
1.3 网络框架
针对混响噪声和复杂背景的干扰造成鱼类难以检测的问题,本文提出一种改进的YOLOV5深度学习模型,实现浑浊水体下鱼类检测。YOLOV5 采用共享卷积核的方式,减少计算次数,降低模型参数量,提高网络计算效率。模型架构如图2 所示,主要由3 部分组成,包含主干特征提取网络、颈部网络以及预测头[28]。
(1)主干特征提取网络:如图3A 所示,沿用YOLOV5S 的网络结构,图片进入模型后经过切片后进行卷积操作,主体结构采用MobileNetV3 bneck 块(淡蓝色模块),不同于VGG、Resnet、ViT 等网络模型,MobileNet 参数少、计算快。如图3E 所示,以MobileNetV3-Large 的网络结构为例,模型使用非线性激活函数 h-swish,将第一层卷积核的数量修改为16 个3×3 卷积,进一步降低模型参数量,模型的网络配置见图3E。此外,在block 基础上引入通道注意力机制(Squeezeand-Excitation,SEnet)模块,利用注意力模块,提高对鱼类特征的捕获能力,如图3D 所示。一方面,该模块增强了图像的局部信息特征的提取能力,另一方面,充分利用上下文信息,提高了网箱和鱼的特征提取能力。

图3 LFR-Net 网络框架Fig.3 LFR-Net Network framework
(2)颈部网络:如图3B 所示,颈部网络常用于特征图融合,优化特征表达能力,本文模型采用路径聚合网络结构(Path Aggregation Network,PANet),其最早用于图像分割领域,例如,以输入图像尺寸(1 920×1 920 像素)为例,经过主干网络后分别获取4 种不同尺度的特征 图(240×240、120×120、60×60、30×30 像素),经过上采样和连接层后,用于检测不同大小的目标,进一步缓解鱼类目标检测精度不高的问题,增强特征融合能力。
(3)预测头:预测头是检测器的预测部分,用于输出图像中鱼类的位置和置信度,如图3C所示。基于非极大抑制方法进行最大局部搜索,去除冗余的检测框,筛选置信度最高的检测框,最终输出并显示目标检测结果,包含位置、类别以及检测目标的概率。
2 结果与分析
2.1 模型训练和评价指标
试验平台训练环境的基本设置如表1 所示。训练过程采用迁移学习的方式进行,模型加载ImageNet 的预训练权重进行微调,模型的超参数设置值见表2。为验证改进模型的有效性及改进模型的检测效果,采用4 种不同骨干网络进行对比试验[29-32]。

表1 训练环境设置Table 1 Training environment settings
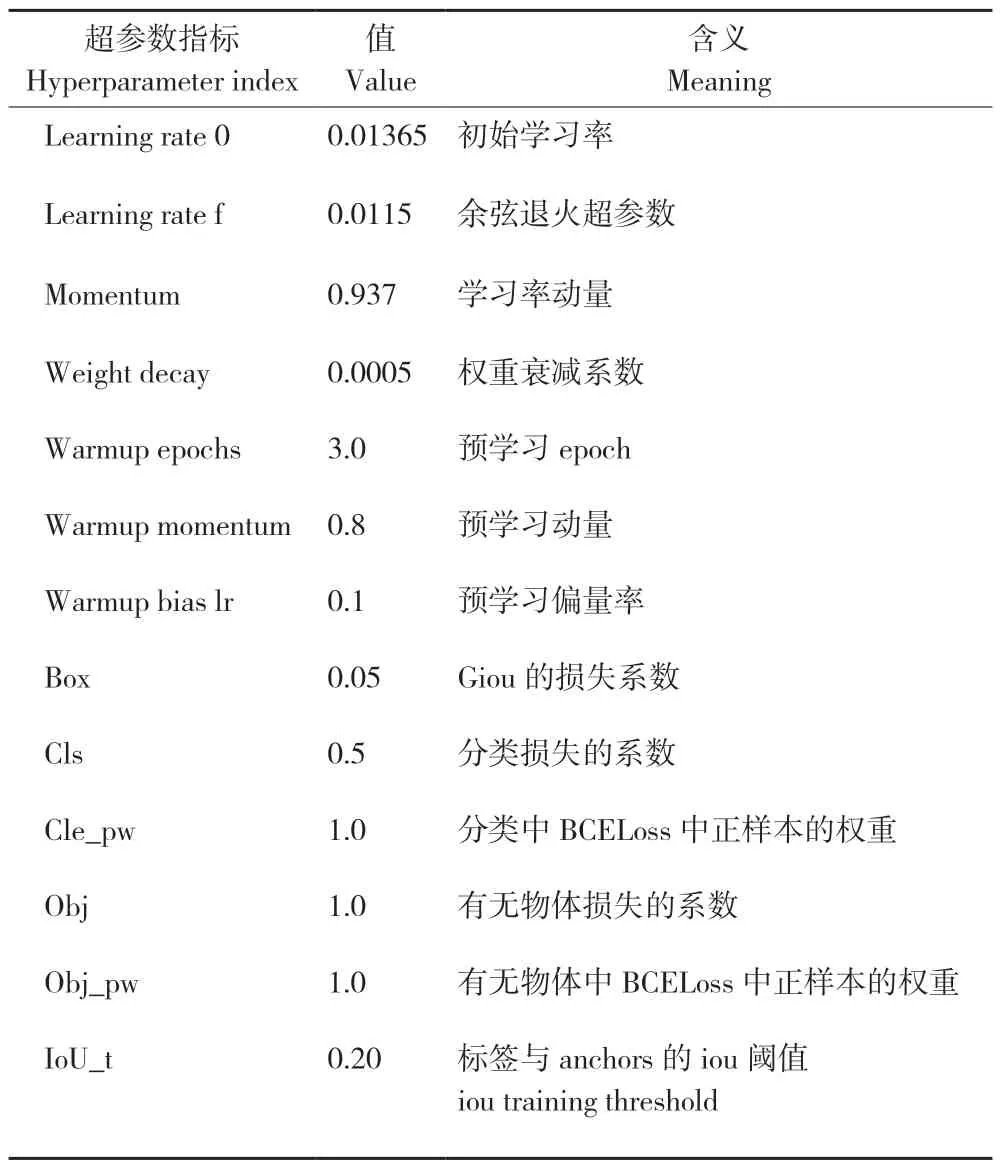
表2 模型超参数设置Table 2 Model hyperparameter settings
如表3 所示,模型的评价指标包含精确率、召回率、平均精度及F1 分数[33-34],其计算公式如下:

表3 模型评价指标Table 3 Model evaluation index
式中,TP(True Positive)为IOU > IOU 阈值的检测框数(IOU 阈值=0.5);FP(False Positive)为IOU <=IOU 阈值(IOU 阈值=0.5)的检测框数;FN(False Negative)为未检测到GT的数量,GT为手工标注的外接矩形(标签);n为类别,AP为平均精确度。
此外,本文使用第三方Thop 库中的Pofile 函数对模型参数量和模型计算量进行计算。Profile函数实现机制是 利用PyTorch 中的注册模块前钩(Register_forward_hook),为所有模块注册一个全局前向钩子。
2.2 不同模型的试验结果
本文选择4 种其他模型进行对比试验,包含YOLOV3-ting(Darknet53)、YOLOV5(CSPdarknet53)、YOLOV5(Repvgg)、YOLOV5s(Transformer)。训练轮数是300 Epoch,模型训练的超参数见表2。对比结果如表4 所示,本模型的参数量最少、计算量最少,与YOLOV5 模型相比,改进后模型mAP 提高9.7%,推理数据集随机抽取50 张图片,本模型平均每张图片推理速度为0.08868 s。

表4 不同模型的检测结果Table 4 Test results of different models
各模型训练过程的评价指标,包括精确度、召回率以及mAP0.5 的趋势图如图4 所示,在精确度、召回率和mAP 的趋势图中,所有模型趋势基本在epoch=180 稳定,后续可以缩减训练轮数、加快训练进度。此外,本文提出的模型评价指标均优于其他模型,在参数总量和计算量减少下,mAP 为0.957,模型消融实验结果见表5。

表5 消融试验Table 5 Ablation experiment

图4 不同模型训练过程Fig.4 Training process of different models
图5 展示了网箱和鱼类检测实例,图5A、C为正确识别的实例,但由于姿态和噪声,模型存在假阳性案例(图5D),图像显示有两个检测框,后续可以提高冗余框筛选的阈值。另一现象表明,在网箱边缘识别效果不佳,鱼在网箱附近时,受噪声干扰影响,易错误识别为鱼(图5B)。

图5 LAPR-Net 模型检测实例Fig.5 Detection instances of LAPR-Net model
2.3 类激活图可视化分析
为更好地理解基于所提出改进模型的学习能力,选取模型的类激活图进行解释,本文结合GradCAM 热力图可视化,可视化的部分结果如图6所示[35]。可以发现,不同的特征图激活不同区域,如鱼所在的区域、鱼的背景。此外,由于识别的对象颜色和背景相似,网箱的轮廓边缘部分也被激活,后续在声信号转声呐图像过程中,可更换不同的颜色背景,提高模型的识别精度。

图6 不同卷积层热力图分析Fig.6 Thermodynamic diagram analysis o f different convolutional layers
3 讨论
近年来,随着对动物蛋白需求的不断增加和传统渔业资源的严重减少,渔业正逐步向水产设施养殖转型。其中,网箱生物识别是海洋牧场的关键作业流程之一。考虑到光学传感器在水下场景中的客观局限性,浑浊水体成像方法常利用非光学传感器,如激光雷达、声呐等,该方式有助于对结构复杂、浑浊黑暗的水下环境进行目标识别和计数。但是该类型设备成像分辨率低,易受运动载体和环境噪声影响,计算量较大[36]。本文采用前视声纳技术,提出一种轻量级的鱼类识别模型(LAPR-Net),实现浑浊或黑暗场景下水体鱼类识别。
相比于传统的机器视觉方法,利用基于人工设计特征,获取目标的位置信息,本文提出的模型可以自动提取目标特征,主干网络模块采用轻量级MobileNetV3 benck 块,利用线性瓶颈的逆残差结构和深度可分离卷积提取声呐图像中鱼类的特征,通过注意力机制SE-Net 来获取声纳图像多尺度语义特征并增强特征之间的相关性,本文选择4 种其他模型进行对比试验,包含YOLOV3-ting(Darknet53)、YOLOV5(CSPdarknet53)、YOLOV5(Repvgg)、YOLOV5s(Transformer),试验结果显示,本文提出的模型的参数量最少(3 545 453 M)、计算量最少(6.3 G),同YOLOV5 模型相比,改进后模型mAP 提高9.7%,为后续浑浊或者黑暗场景下鱼类检测模型部署提供参考。
此外,受网箱和水流振动产生噪声的影响,小目标易错误识别为噪声。随着设备算力的提高,以深度学习为代表的技术逐渐成为水产养殖识别研究的新方式,可以加快图像的处理效率,可推动多模态图像融合在水产领域的应用前景[37],结合不同类型的相机,利用信息融合技术实现水下动物多类型数据信息融合,在远距离范围,采用声呐信息,近距离或者小型鱼,采用光学相机,提高小型鱼的检测精度[38]。
4 结论
近年来,混响噪声和复杂背景的干扰是鱼类难以检测的问题的关键。本文提出了一种轻量级的鱼类识别模型(LAPR-Net),实现浑浊水体下鱼类检测。该模型在YOLOV5 模型基础上,主体结构采用MobileNetV3 benck 块,利用线性瓶颈的逆残差结构和深度可分离卷积提取声呐图像中鱼类的特征,通过注意力机制SE-Net 来获取声纳图像多尺度语义特征并增强特征之间的相关性。同YOLOV5模型相比,改进后模型mAP提高9.7%,模型参数量为3 545 453 M、计算量为6.3 G,对于海洋牧场智慧养殖提供鱼类检测方案。
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
海洋信息技术与应用(2022年1期)2022-06-05
儿童时代·幸福宝宝(2020年9期)2020-09-08
海洋信息技术与应用(2020年3期)2020-08-24
小学科学(学生版)(2019年10期)2019-11-16
电子制作(2017年24期)2017-02-02
渔业致富指南(2016年12期)2016-11-11
金色少年(奇趣科普)(2016年8期)2016-09-21
湖南农业(2016年3期)2016-06-05
现代盐化工(2015年3期)2015-01-23
