
基于表型及经济性状构建蒜头果初选核心种质
2023-09-21 01:09李洪果段润梅周炳江劳庆祥
西北植物学报 2023年8期
李洪果,段润梅,覃 坚,曾 冠,周炳江,劳庆祥
(1 中国林业科学研究院热带林业实验中心,广西凭祥 532600;2 藤县国有共青林场, 广西藤县 543300;3 岑溪市七坪林场, 广西岑溪 543200)
核心种质是以提高种质资源管理和利用水平为目的,在对整个遗传资源科学评价的基础上,以最少的资源数量,代表整个遗传资源多样性的样本集[1-2],自提出至今,已在小麦(Triticumaestivum)、水稻(Oryzasativa)和棉花(Gossypiumhirsutum)等众多物种上取得了良好的应用效果[3-5]。核心种质通常基于表型或分子标记数据产生,表型数据侧重反映不同材料对环境的适应性和育种潜力[6],分子标记数据侧重反映材料间的遗传差异。研究表明,基于2种标记的遗传距离仅存在微弱的相关性(0.01)[7],遵循的变异模式也不同[8]。通常认为,数量性状估计的个体或群体间差异一般大于等于用分子标记估计的差异,基于分子标记对群体分类相对保守[8-10]。因此,表型性状是构建核心种质不可或缺的对象。
蒜头果(Malaniaoleifera)是中国狭域分布(云、桂、黔三省交界的石漠化地带)的特有单种,属(铁青树科、蒜头果属)极小种群古老植物,也是国家二级保护植物,仅广西的巴马、凤山、凌云、乐业、田林、隆林,以及云南的广南和富宁有少量种群分布,且以石山立地为主。蒜头果种仁富含油脂及神经酸,神经酸对修复神经纤维、防止脑神经衰老、脑萎缩和抑郁症等有很大作用[11]。蒜头果的叶、果、种仁及其内含物均存在丰富的遗传变异,经济性状指标油脂和神经酸含量,相差可达1倍以上,存在种源和家系选择的基础[12]。随着中国老龄人口增多,老年痴呆、记忆力减退等脑疾病相关的问题也日益突出,记忆力维持和脑疾病治疗等对神经酸类药品的需求量将十分可观[11]。然而,蒜头果资源数量稀少,分布区域狭小,繁殖困难,仅存的天然林资源已长期处于不可逆的持续减少状态[13],为尽快明确天然林中蒜头果保存和良种选育的目标种源及单株,本研究基于21个表型及经济性状,构建蒜头果核心种质,明确建立蒜头果育种和保存群体的目标材料,为其资源保育提供依据。
1 材料和方法
1.1 试验材料及取样和测量方法
2021年9-10月,从广西巴马、凤山、凌云、乐业和田林,云南富宁和广南共7个蒜头果天然群体中采集的97个蒜头果单株的叶片、枝条、果实及种仁,采样单株的树龄均在20年以上。采样区域覆盖了8个有蒜头果种群分布县市中的7个,基本涵盖了蒜头果中心分布区的变异类型。
1.2 试验方法
1.2.1 核心种质构建
取样方法:按县域分组,基于聚类,优先选择有极值表型的个体。聚类单元内的材料均无极值时随机选取;只有1个材料时直接入选,每种取样策略下至少1份材料入选。
构建方法:在分组及多次聚类优先取样的基础上,分别采用遗传多样性法(G)、比例法(P)和对数法(L)构建,除L法外,G法和P法分别设定10%、20%和30%的取样比例,共7种取样策略(G1、G2、G3、P1、P2、P3和L),见表1。其中,遗传多样性法是以各地理分组的遗传多样性占原种质遗传多样性的比例,在分组中提取相应数量的样本;比例法是以各地理分组样本数占原种质样本数的大小,抽取相应比例的样本数;对数法是以各地理分组样本数的自然对数抽取相应的样本数。以上方法至少保证各分组有1份材料入选核心种质群体,其余按比例,反复聚类抽取,直至达到该组设定的取样比例。
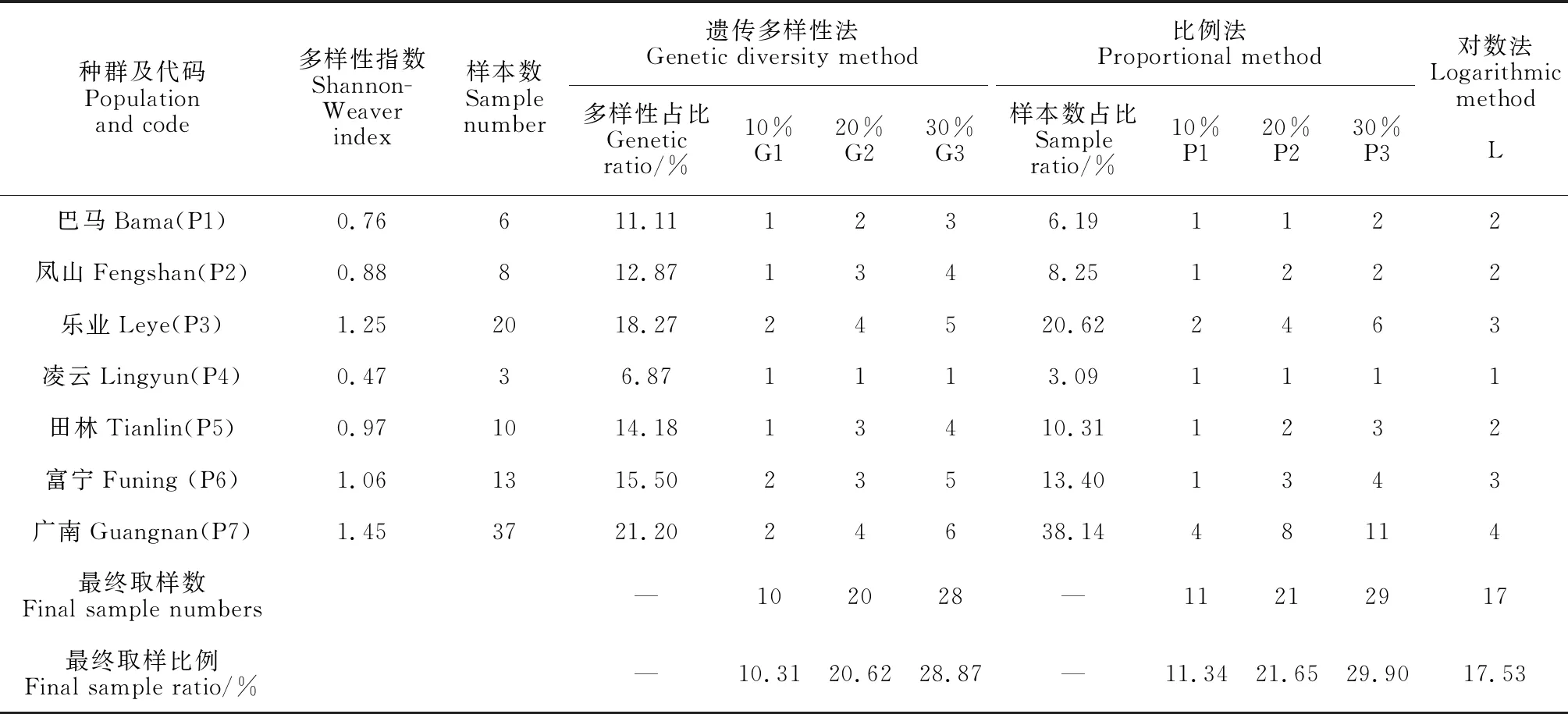
表1 不同取样策略下的样本数及其比例
1.2.2 核心种质评价
核心种质代表性评价标准:7种取样策略下构建的蒜头果核心种质,均采用极差符合率(CR)、多样性指数(MI)、最大值变化率(CRMAX)和最小值变化率(CRMIN)、变异系数变化率(VR)、均值差异百分率(MD)、方差差异百分率(VD)和平均值变化率(CRMEA)等8个参数评价筛选核心种质,各参数的计算公式见文献[14]。评价标准:均值差异百分率(MD)<20%,且极差符合率(CR)>80%时,可认为核心种质具有代表性,且MD参数值越小,其他参数值越大,则代表性越强[14-16]。各参数的有效性排序[14]为:CR>MI>CRMAX、CRMIN>VR>MD>VD>CRMEA。
1.2.3 核心种质验证
核心种质有效性验证方法:①多样性指数的t检验,核心种质与原种质群体的多样性指数(H)在21个性状上差异不显著,则构建的核心种质有效;②均值、极大值、极小值、多样性指数的符合率检验,核心种质与原种质群体在4个参数上的符合率越高,有效性越好;③主成分分析,核心种质与原种质群体的主成分相比,方差累计贡献率略有提高,说明去除了部分遗传冗余;④基于主成分的样品分布图,核心种质的样品分布相对均匀,且显著降低原种质样品分布较为集中或重叠的样本,则构建的核心种质有效。
1.3 数据分析
原种质与7个核心种质的遗传多样性指数(H)在R4.2.1软件中计算;其余7个评价参数(CR、CRMAX、CRMIN、VR、MD、VD和CRMEA)和符合率检验,按公式在Excel 2013中计算;核心种质与原种质群体的多样性指数的t检验、主成分分析和基于主成分的样品分布,在SPSS 22中进行。
2 结果与分析
2.1 核心种质子集的评价
由表2可知, 7种取样策略下,均值差异百分率(MD)均为0,21个性状上的极差符合率(CR)在80.95%(P1)~98.22%(G3)之间,说明构建的7个核心种质子集均符合要求,从中选出最优即可。

表2 不同取样策略下遗传参数的比较
7个核心种质子集的平均遗传多样性指数(H)在1.69(G1)~1.96(G3)之间;最大值变化率(CRMAX)、最小值变化率(CRMIN)和平均值变化率(CRMEA)分别在95.75%(P1)~99.88%(P3)、100.82%(G3)~123.66%(G1)和80.95%(P1)~98.22%(G3)之间;变异系数变化率(VR)和方差差异百分率(VD)分别在116.54%(P3)~128.27%(G1)和0(P3)~23.81%(G1、G2和P1)之间。
按各参数的有效性排序(CR>MI>CRMAX、CRMIN>VR>MD>VD>CRMEA)可知,G3和P3策略构建的核心子集明显优于其他5种核心子集,而G3的CR和MI略优于P3,加之,G3的样本数更少,因此,选择G3策略,即“优先取样法+遗传多样性法+30%的取样比例”构建的核心种质子集。
2.2 核心种质的验证
采用多样性指数的t检验、符合率检验、主成分分析检验和基于主成分的样品分布等4重方法验证所构建核心种质的有效性及代表性。
2.2.1 多样性指数的t检验
由表3可知,核心种质与原种质在21个性状上的多样性指数差异均不显著(P>0.05),21个性状中,15个性状的多样性指数高于原种质,6个性状的多样性指数略低于原种质;核心种质21个性状的平均遗传多样性指数(1.96)与原种质(1.94)相比,略有提高。

表3 蒜头果天然群体的性状变异
以上说明,核心种质去除了原种质中的部分遗传冗余后,其多样性指数有所增加,构建的核心种质具有代表性且有效。然而,这并不意味着核心种质拥有比原种质更高的遗传多样性,该指数的增加是由于去除遗传冗余后,基于相同算法,统计频率改变所致,并非实质意义上遗传多样性的增加。
2.2.2 符合率检验
核心种质与原种质在21个性状上的均值、极大值、极小值和多样性指数的符合率见表4。由表4可知,核心种质与原种质的均值符合率在80.84%~99.92%之间,平均为97.31%;极大值符合率在86.19%~100%之间,平均为99.16%;极小值符合率在82.87%~100%之间,平均为99.18%;多样性指数的符合率在86.98%~99.49%之间,平均为95.41%。另外,42个性状极值中,有39个被保留,其中,21个性状的极大值,有19个被保留;21个性状的极小值,有20个被保留,说明构建的核心种质对特异种质的保留效果较好。以上说明核心种质具有较好的代表性,尤其在保留特异种质方面具有优势。
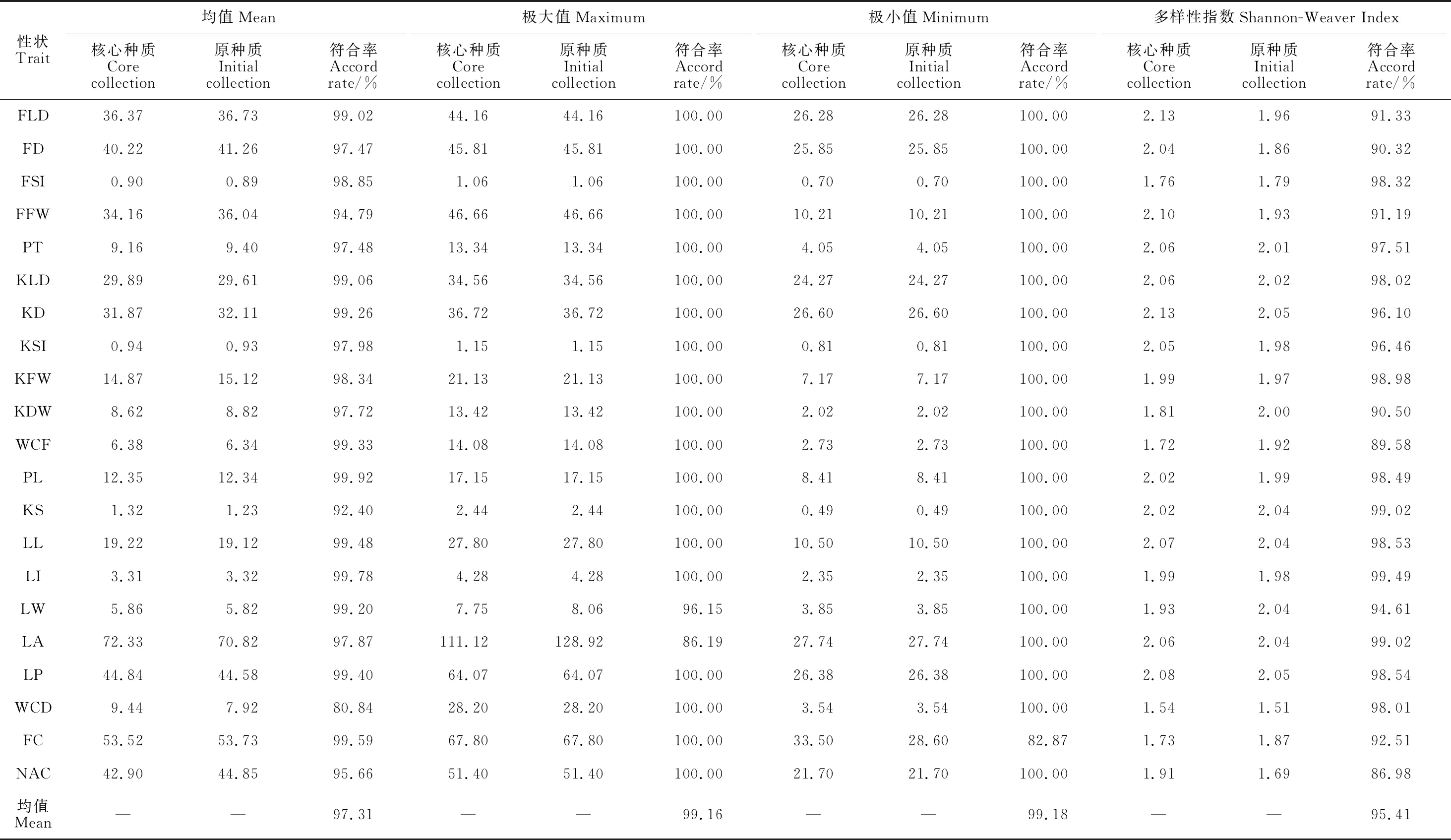
表4 核心种质与原种质表型性状的符合率检验
2.2.3 主成分分析和基于主成分的样品分布图
核心种质与原种质在21个性状上的主成分分析见表5。由表5可知,核心种质与原种质具有相近的特征值、贡献率和累计贡献率,两者的累计贡献率均在86%以上,即均能解释原种质86%以上的遗传信息。21个性状按特征值(λ>1)可提炼为6个主成分,方差累计贡献率86.64%。与原种质相比,核心种质同样提炼出6个主成分,方差累计贡献率为87.78%,说明构建的核心种质去除了原种质中的部分遗传冗余,使方差有所增加。

表5 核心种质与原种质的主成分分析
核心种质与原种质基于主成分的样品分布情况见图1。由图1可知,核心种质样品分布较为均匀,且显著降低了原种质中样品分布较为密集和重叠的部分,说明构建的核心种质有效。核心种质中也有个别较为相近的或重叠的样本,这可能是由于分组取样时,限于每组必需有1个样品入选的约束条件所致,如采用不分组构建核心种质,其分布可能会更为理想。

图1 核心种质与原种质基于第1和2主成分的样品分布
3 讨 论
3.1 种质分组
种质分组与否,是核心种质构建时首先要考虑的问题。分组一方面是为了保证取样的代表性,以期不同环境条件下的种质材料在核心种质中均有体现;另一方面是部分抵消不同种群表型性状所受的环境影响[17-18],因为相同区域内环境条件较为接近,是一种近似同质园的做法。如贵州核桃构建核心种质,是将一定区域内的核桃资源近似为同质园[19]。本研究中,相同县域采样的蒜头果样本基本处于同一群落内,外在环境条件,如气象因子等接近一致,对其影响较弱,而环境影响到表型的情况通常发生在较大的地理和气候尺度上。因此,本次在地理区域分组(县)和多次聚类优先取样的基础上构建的蒜头果初选核心种质,本质上是综合各地理分组构建的核心种质形成的叠加核心种质。
分组构建的核心种质应用较为广泛,也是效果较好的一种策略,在小麦、新疆野杏(Armeniacavulgaris)、黍稷(Panicummiliaceum)等的核心种质构建中均有应用[3,20-21]。分组主要依据种质材料的特性和研究目的,并不局限于某一种分组方法,不存在一种通用的分组方法适用于各类动植物材料。目前,按地理分组是较为常见的分组方法,如灰楸(Catalpafargesii)、狗牙根(Cynodondactylon)和格木(ErythrophleumfordiiOliv.)等[22-24],也有按品种体系或成熟期分组[25-26]。也有很多物种采用不分组的方法构建核心种质,如:新疆野苹果(Malussieversii)、新疆野杏和番茄(Solanumlycopersicum)等[16,20,27],其优势在于只基于遗传距离考虑材料间的聚类结果,能最大限度的去除遗传冗余或相似种质,所构建的核心种质,其评价参数相对较优;其不足在于忽略了植物的表型可塑性,不同环境条件下表现迥异的种质材料,在相同环境条件下,可能表现出近似的表型。不分组的方法适用于在种质资源库中经过多年生长评价的种质材料,如杜仲(Eucommiaulmoides)和西伯利亚杏(Armeniacasibirica)等[28-29],而利用野生或天然群体初次构建核心种质时,不分组的方法可能会遗失重要种质材料。因此,蒜头果的核心种质构建采用分组的取样策略。
3.2 取样策略及聚类方法
不同的取样策略影响核心种质构建的目标能否实现。在聚类的基础上,较为常见的取样策略有随机取样、优先取样和偏离度取样。随机取样法能够维持原种质的遗传多样性形式,偏离度取样法能保留原种质的最大的遗传变异,而优先取样法能保留原种质最大和最小性状值,同时也保留了原种质的遗传变异结构[15]。本研究从育种及种质资源保存的角度,以尽可能多的保留特异种质资源为目的,选择优选取样法构建蒜头果核心种质。
常见的聚类方法,如:最短距离法、最长距离法、中间距离法和重心法等各有优劣及适用条件,有的过于扩张,有的过于浓缩,太扩张的方法在样本量大时容易失真,太浓缩的方法不够灵敏,其中类平均法比较适中,而且具有单调性[30]。因此,本研究在类平均聚类的基础上采用优先取样的策略,获得了较为理想的蒜头果核心种质。
3.3 核心种质评价参数及验证体系
核心种质构建后,需用一系列的参数及方法来评价验证其有效性和代表性。一般而言,确定了核心种质的评价参数,对其取样方法、取样比例等的研究才有判定标准。对于数量性状,均值作为数据的代表值,处于核心种质观察值的中心位置,是一个极其重要的参数[31]。多样性指数(H)考察核心种质与原种质的表型频率分布特点,以两者的分布结构是否一致,确定核心种质的代表性,是核心种质构建中最常用的方法[32]。研究表明:极差符合率(CR)是核心种质代表性评价的首选参数;平均Shannon-Weaver多样性指数(MI)是评价核心种质代表性的重要参数;变异系数(VR)的大小决定该性状是否能稳定遗传,因此,其变化率也是评价核心种质变异程度的重要参数;均值差异百分率(MD)是判断核心种质是否具有代表性的判定参数[14]。均值差异百分率(MD)<20%,且极差符合率(CR)>80%时,可认为核心种质具有较好的代表性,且MD参数值越小,其他如变异系数变化率(VR)、方差差异百分率(VD)等参数值越大,核心种质的代表性越强[15]。在育种和种质资源保存中,含有极值的个体往往作为特异种质,是重点关注的对象,因此极大值变化率(CRMAX)、极小值变化率(CRMIN)和平均值变化率(CRMEA)也被用于评价本研究构建的蒜头果核心种质。
核心种质评价参数符合要求后,常采用一些方法进一步验证其代表性,其中,多样性指数的t检验、符合率检验、主成分分析和基于主成分的样品分布图是应用较广的方法[20-24]。核心种质与原种质t检验差异不显著,说明两者在性状上对应的基因型频率近似,具有相似的分布结构;两者的极值、极差和多样性指数的符合率越高,核心种质的代表性越强;主成分分析可以近似的描述样品在几何空间的分布特征,并反映供试材料的遗传结构,可以用来比较核心种质和原种质的分布特征[15];基于主成分的样品分布图,也反映构建核心种质的分布特征,核心种质的分布特征与原种质越相似,分布越均匀,对原种质重叠部分去除的效果越明显,则代表性越好。本研究构建的蒜头果核心种质经以上4重检验,均符合要求,说明所构建的蒜头果核心种质具备有效性、代表性和实用性等特征,可以作为蒜头果种质资源收集保存和后期建立育种群体等的依据。
猜你喜欢
学苑创造·A版(2023年5期)2023-06-04
河北科技大学学报(社会科学版)(2022年4期)2023-01-06
四川蚕业(2022年2期)2022-11-19
四川蚕业(2022年2期)2022-11-19
闽南风(2020年6期)2020-06-23
中国现代中药(2020年2期)2020-04-29
四川蚕业(2020年4期)2020-02-10
现代园艺(2018年2期)2018-03-15
——勉冲·罗布斯达
文化遗产(2017年2期)2017-04-22
新疆农垦科技(2014年12期)2014-02-28
