
基于混合深度学习模型的洪水过程概率预报研究
2023-09-19 02:49郭生练周研来
水利学报 2023年8期
崔 震,郭生练,王 俊,,张 俊,周研来
(1.武汉大学 水资源与水电工程科学国家重点实验室,湖北 武汉 430072;2.长江水利委员会水文局,湖北 武汉 430010)
1 引言
随着人工智能技术快速发展,出现了能够有效处理非线性、非稳态时间序列的深度学习模型。长短期记忆(LSTM)神经网络是最具代表性的模型之一[1],相较于传统的人工神经网络,它有更先进的理论基础和模型结构,能够在多时段洪水预报中取得较好的预报精度[2]。但深度学习模型缺少物理机制支撑,可解释性较低[3-4],而且无法量化预报不确定性,预报价值和可靠度较低[5]。
近年来,概念性水文模型与深度学习耦合的混合模型引起水文学者的广泛关注[6-9]。混合模型可以在神经网络中学习概念性模型的产汇流过程,一定程度上提高了LSTM模型的可解释性和预报精度。随着深度学习的研究不断深入,出现了可以解决序列到序列问题的编码-解码结构[9]。耦合递归编码-解码(RED)结构的LSTM-RED神经网络,可以在编码和解码过程中将前一时刻提取的有效特征传递给后一时刻[10-12],在保证输出变量时间相关性的前提下,获得多时段洪水过程预报,具有较高的内部可解释性和适用性[10]。但LSTM-RED模型存在曝光偏差问题(即训练和验证过程不一致问题)[11],使得模型性能不稳定,在多时段洪水过程预报的精度不佳。Cui等[11]将新安江(XAJ)模型预报流量过程输入到解码过程中代替递归过程,建立了基于外源输入编码-解码(EDE)结构的XAJ-LSTM-EDE模型,不仅可以学习XAJ模型的产汇流过程,还克服了LSTM-RED模型的曝光偏差问题,提高了预报精度。
目前,深度学习模型输出形式多为确定性点估计,由于模型参数、结构和输入资料等不确定性因素的影响,水文预报不可避免地存在不确定性问题[13],仅提供点估计的深度学习模型为防洪决策提供的不确定性(或风险)信息是有限的。已有研究通过引入先进的不确定性量化技术或改进现有的神经网络构建了深度学习概率预报模型[8,14-16]。混合密度网络(MDN)是一种可以估计目标变量条件概率分布的神经网络。MDN将神经网络与混合密度函数相结合,借助神经网络生成多个核函数的权重和参数,将核函数按照权重相加组合为混合密度函数,理论上可以表示任意条件概率分布[15],在能源、气象等领域获得广泛关注[19-21],其损失函数依据最大似然估计法构建[19]。当前,多数深度学习概率预报研究主要集中在单个时间步长的概率预报中,无法在考虑预报洪水过程时间相关性的前提下获得不确定性估计,缺乏可解释性和适用性。因此,有必要开展基于混合深度学习模型的多时段洪水过程概率预报研究,实现实时量化预报洪水过程的不确定性,为水库防洪调度等决策提供更多的风险信息。
本文首先将XAJ模型的预报流量过程嵌入XAJ-LSTM-EDE模型的解码过程;其次,将MDN耦合至XAJ-LSTM-EDE模型解码过程的输出层以实现概率分布转换,构建XAJ-LSTM-EDE-MDN混合深度学习模型;最后,依据最大似然估计法构建损失函数,以优化XAJ-LSTM-EDE-MDN模型的权重等参数。本文以陆水和建溪两个流域为案例,对XAJ-LSTM、XAJ-LSTM-EDE和XAJ-LSTM-EDE-MDN模型进行对比验证,并分析了所提模型的不确定性量化性能。
2 研究方法
2.1 XAJ-LSTM模型长短期记忆(LSTM)神经网络由遗忘门、输入门、更新记忆单元状态和输出门等4个计算结构构成。XAJ-LSTM模型结构见图1(a)。XAJ-LSTM模型是将XAJ模型的预报流量作为LSTM神经网络在预报时刻的输入。其中,XAJ模型参数率定方法和结果见文献[11]。XAJ模型预报流量与目标输出变量(即每一预见期对应的实测流量)有较强的相关性,因此期望其可引导神经网络产生较合理的预报流量过程。同时,XAJ模型预报流量增加了模型输入数量,可在一定程度上缓解过拟合问题。XAJ-LSTM模型为单输出结构(与文献[3]相似),未在时间维度上考虑预报洪水间的相关性。

图1 XAJ-LSTM和XAJ-LSTM-EDE-MDN模型结构图
2.2 XAJ-LSTM-EDE模型基于外源输入编码-解码结构的XAJ-LSTM-EDE模型由编码过程(图1(b)-(1))和解码过程(图1(b)-(2))构成。为克服传统递归编码-解码结构的曝光偏差问题,将XAJ模型的预报流量过程与解码过程相耦合(图1(b)-(2)虚线框),以替代解码中的递归过程,使得解码过程的输入始终为编码过程提取的重要信息(即图1(b)-(2)中的中间向量C)和XAJ模型的预报流量。XAJ-LSTM-EDE模型可以在考虑输出变量时间相关性的前提下,实时预报多时段洪水过程,相对XAJ-LSTM模型更具可解释性和适用性。XAJ-LSTM-EDE模型未考虑预见期内预报降雨数据,为保持输入变量一致,XAJ-LSTM模型同样未考虑预报降雨数据,即Pt+m+1~Pt+m+n为0 mm。
2.3 混合深度学习模型本文将MDN耦合至XAJ-LSTM-EDE模型解码过程的输出层,即将XAJ-LSTM-EDE模型解码过程隐含层输出X作为混合密度网络(MDN)的输入,增加了概率预报过程(图1(b)-(3)),从而构建XAJ-LSTM-EDE-MDN混合深度学习模型。该模型可以在考虑输出变量时间相关性的前提下,将解码过程产生的点估计转化为概率分布估计,能够反映预报过程的不确定性,提供更多的风险信息。
XAJ-LSTM-EDE-MDN模型输出多个核函数的权重w和参数θ,其中w通过Softmax函数进行归一化,以确保核函数形成有效的分布函数,其他输出值可通过适当的函数处理(如指数函数),以确保其值在规定范围内。洪水预报序列一般为一维时间序列,给定XAJ-LSTM-EDE模型隐含层输出X时,目标变量Y的条件概率密度函数f(Y|θ,X)为
(1)
(2)
(3)
式中:m为核函数的数量,一般采用试错法来确定m,其范围一般为1~5;函数φi是第i个核函数;Yw为MDN对应权重参数的输出信息。
常用的核函数为高斯核函数,公式为:
(4)
式中:μ为期望值;σ为方差,采用指数函数处理,σ=exp(Yσ),以保证为非负值函数。
MDN的输出变量Yf元素个数为3m。
(5)
图2展示了以3个高斯核函数为例的MDN计算过程示意图。混合密度函数直接取决于网络输入。神经网络每次收到新的输入时,混合密度函数的参数都会发生变化,这意味着可以获得目标变量的时变条件分布函数,即时变的不确定性信息。XAJ-LSTM-EDE-MDN模型的确定性预报值为条件分布的期望值,并取95%置信度预报区间量化预报不确定性。

图2 包含3个高斯核函数的MDN计算过程示意图
为防止密度泄露等[19]问题,采用标准化方法消除各个特征量纲的影响。
(6)
式中:Z′和Z分别为未标准化和标准化后的变量;μZ和σZ分别为变量的均值和方差。
在训练神经网络时,采用最大似然估计法构建损失函数[19]。不同于确定性输出深度学习的损失函数(如均方误差和平均绝对误差等),XAJ-LSTM-EDE-MDN模型的损失函数原理是通过量化目标变量在网络输出条件分布函数f(Y|θ,X)中的概率密度大小来调整超参数。通过自适应矩估计(Adam)算法使得目标变量Y在对数似然函数log(f(Y|θ,X))中概率密度最大。Adam算法在反向传播算法中,总是朝损失函数减小速率最快的方向优化神经网络超参数,损失函数公式为
loss=-log(f(Yi|θi,Xi))
(7)
确定性预报结果采用纳什效率系数(NSE)、径流总量相对误差(RE)和平均绝对误差(MAE)三个指标进行评价[11]。概率预报采用平均相对宽度(RB)、平均覆盖率(CR)、可靠度(α-index)[13]和连续排位概率分数(CRPS)[17]四个指标进行评价。
3 研究区域和数据
3.1 陆水流域陆水河是长江中游的一级支流(图3(a)),流域面积约为3950 km2,地处亚热带季风气候区,年平均气温、降雨量和径流量分别约为15.5 ℃、1550 mm和30.3亿m3。降雨一般集中在4—9月,约占全年降雨量的70%。陆水水库位于河谷干流的出口处,水库的有效库容为4.08亿m3,防洪库容仅为1.63亿m3。由于水库防洪库容较小,且流域产汇流较快,准确的洪水预报对陆水水库的防洪和水资源管理至关重要。

图3 陆水和建溪流域
在陆水流域,收集整理了2012—2019年汛期5月1日—10月31日的数据,包括17个测站的3 h降雨量、3 h蒸发量和入库流量数据。采用泰森多边形法获得面平均降雨量。2012—2016年的数据用作训练模型(训练期),2017—2019年数据用作验证模型(验证期)。
3.2 建溪流域建溪河是闽江的支流(图3(b)),流域面积约为14 787 km2,地处亚热带季风气候区,其地形特征以丘陵和山地为主。年平均气温、降雨量和径流量分别约为18 ℃、2000 mm和158亿m3。降雨主要集中在4—9月,约占全年降雨量的75%。
在建溪流域,收集整理了2009—2013年汛期4月1日—9月30日的数据,包括16个测站的3 h降雨量、3个测站的3 h蒸发量和七里街水文站的3 h流量数据。面平均降雨和蒸发数据采用泰森多边形法计算。训练期和验证期分别为2009—2011年和2012—2013年。
3.3 模型输入及参数选择本研究选择降雨和流量变量作为神经网络的输入。通过不同滞时的降雨径流相关系数选择输入变量,依据相关系数最大时对应的滞时可大致估算出流域平均产汇流时间[8-9],进而选择输入变量的时间步数。由图4可知,陆水和建溪流域分别在12 h和21 h滞时的相关系数最高,则分别选择前12 h和前21 h的降雨径流数据作为编码过程的输入,解码输入(即外源输入序列)为XAJ模型的预报流量序列,对满足实际需求的3~12 h预见期预报流量分别进行确定性预报评价[8,11]。

图4 不同滞时降水与流量相关系数
采用试错法确定核函数个数和神经网络模型的超参数(如神经元数量、隐藏层层数、丢失率(dropout)等)。其中,核函数个数、神经元数量和隐藏层数的优选范围分别为1~5、16~128(间隔为16)和1~5,丢失率优选范围为0.1、0.01和0.001。本文采用Adam算法训练模型。批次(batch)大小和迭代次数(epochs)分别设置为120和600。
4 研究结果和讨论
建立XAJ-LSTM、XAJ-LSTM-EDE和XAJ-LSTM-EDE-MDN三种模型,经试算法优选计算,编码器和解码器中均选择采用一层包含64个神经元的LSTM神经网络。XAJ-LSTM模型选择采用一层包含64个神经元的神经网络结构。陆水和建溪流域的MDN均选择3个高斯核函数,丢失率优选为0.1。在获得最优超参数后分别训练模型10次,选取结果最优的神经网络进行对比分析。采用NSE、RE和MAE三个指标来评价各模型确定性预报精度。采用CR、RB、α-index和CRPS四个指标评价XAJ-LSTM-EDE-MDN模型量化不确定性的性能。
4.1 确定性预报结果评价表1显示了三种模型在陆水和建溪流域的确定性预报结果的评价指标。可以看出,预报精度随着预见期的增加而明显下降。根据NSE、RE和MAE指标可以看出,XAJ-LSTM-EDE和XAJ-LSTM-EDE-MDN模型预报性能相近,XAJ-LSTM模型相对较差。以评价指标差异较大的验证期12 h预见期为例进行说明。

表1 陆水和建溪流域三种模型在训练期和验证期的确定性预报结果的评价指标
在陆水和建溪流域验证期12 h预见期中,XAJ-LSTM模型NSE和RE值分别为0.76和-4.30%,0.91和-6.92%;XAJ-LSTM-EDE模型分别为0.81和0.97%,0.93和-2.10%;XAJ-LSTM-EDE-MDN模型分别为0.80和-0.48%,0.93和-4.34%。XAJ-LSTM-EDE-MDN和XAJ-LSTM-EDE模型12 h预见期的预报性能明显优于XAJ-LSTM模型。
图5和图6分别为XAJ-LSTM、XAJ-LSTM-EDE和XAJ-LSTM-EDE-MDN模型在陆水和建溪流域的散点图。R1和R2分别表示训练期和验证期散点图的相关系数。在陆水流域,验证期有较多高流量点在1∶1线以下,这可能因为训练期样本缺少验证期大量级的流量样本,导致各模型低估验证期的高流量点。同时,在6 h和12 h预见期的散点图差异明显。如图5所示,XAJ-LSTM-EDE和XAJ-LSTM-EDE-MDN模型的散点分布相对紧凑,更接近1∶1理想线。建溪流域不同模型的散点图差异较小。在12 h预见期内,XAJ-LSTM-EDE-MDN模型在高流量处的散点相对最接近1∶1的理想线(图6(f)),验证期相关系数为0.96。因此,可以得出结论XAJ-LSTM-EDE和XAJ-LSTM-EDE-MDN模型的散点图相对最优,XAJ-LSTM模型的散点图相对最差。
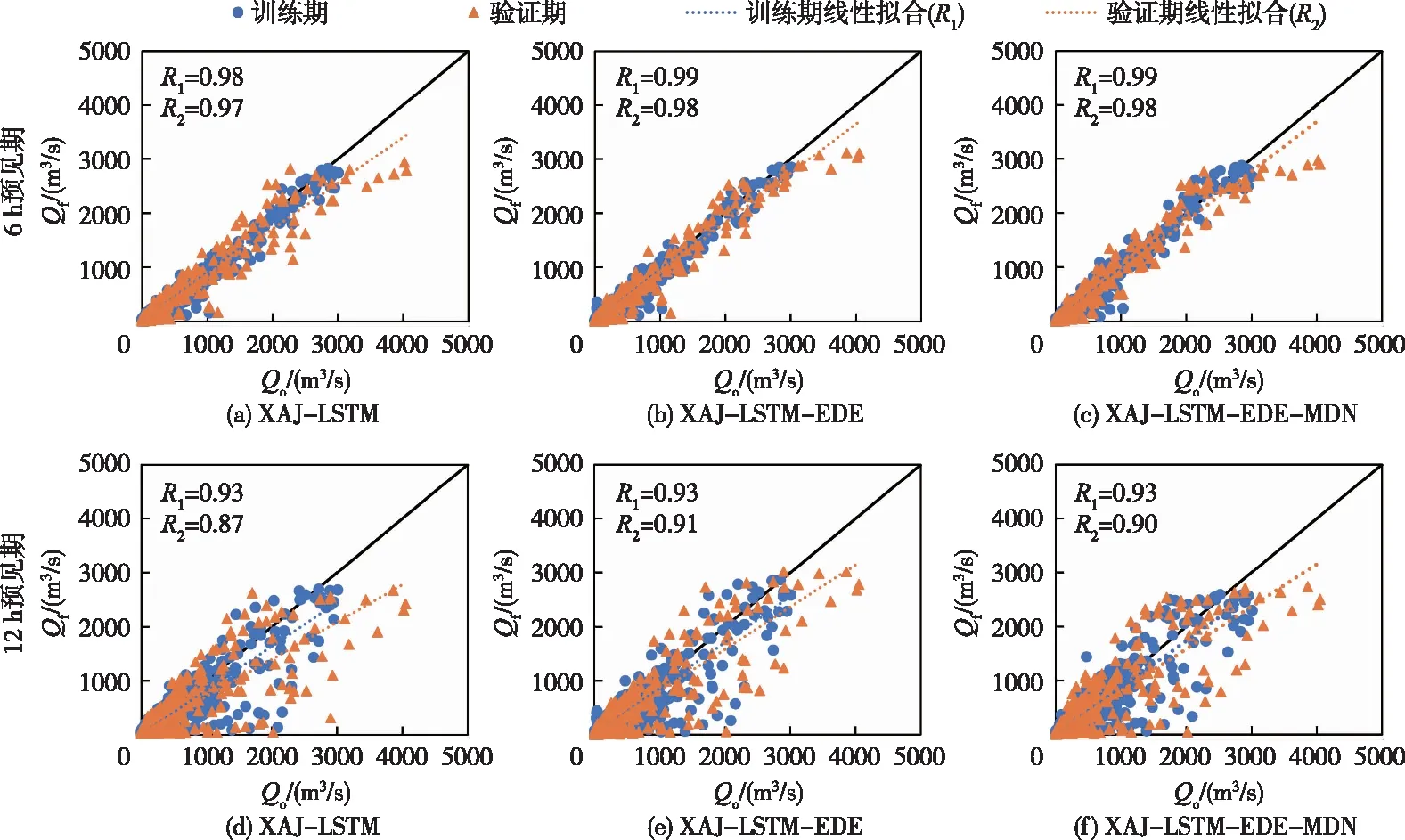
图5 陆水流域三种模型在预见期6 h和12 h的实测流量(Qo)和预报流量(Qf)散点图

图6 建溪流域三种模型在预见期6 h和12 h的实测流量(Qo)和预报流量(Qf)散点图
4.2 不确定性量化性能评价表2列出了XAJ-LSTM-EDE-MDN模型概率预报的评价指标。随着预见期的延长,CR值逐渐减小,RB值和CRPS值逐渐增加,表明预报不确定性逐渐增大,概率预报性能不断降低。在训练期和验证期,XAJ-LSTM-EDE-MDN模型的CR值均接近或超过95%置信度,表明置信区间是合理可靠的。

表2 XAJ-LSTM-EDE-MDN模型在陆水和建溪流域的概率预报评价指标
根据反映概率预报可靠性的α-index指标可知,XAJ-LSTM-EDE-MDN模型的α-index值均超过0.93,并接近理想值1,其中,在陆水和建溪流域的验证期分别为0.93~0.97和0.93~0.96,这表明所提模型的概率预报能够较好地捕捉预报不确定性,进一步反映了概率预报结果是合理可靠的。根据反映概率预报整体性能的CRPS指标可知,在陆水和建溪流域的CRPS值始终小于确定性期望值预报的MAE值,在验证期降幅分别在23.08%~25.93%和26.17%~26.83%范围内,这表明所提模型可以有效拟合目标变量的真实分布函数。
为进一步验证模型的预报性能,在陆水和建溪流域的验证期分别随机选取两场洪水过程。图7和图8分别为陆水和建溪流域的洪水预报置信区间图。

图7 XAJ-LSTM-EDE-MDN模型在陆水流域2017/6/12 T5∶00-6/15 T2∶00洪水事件的置信区间图
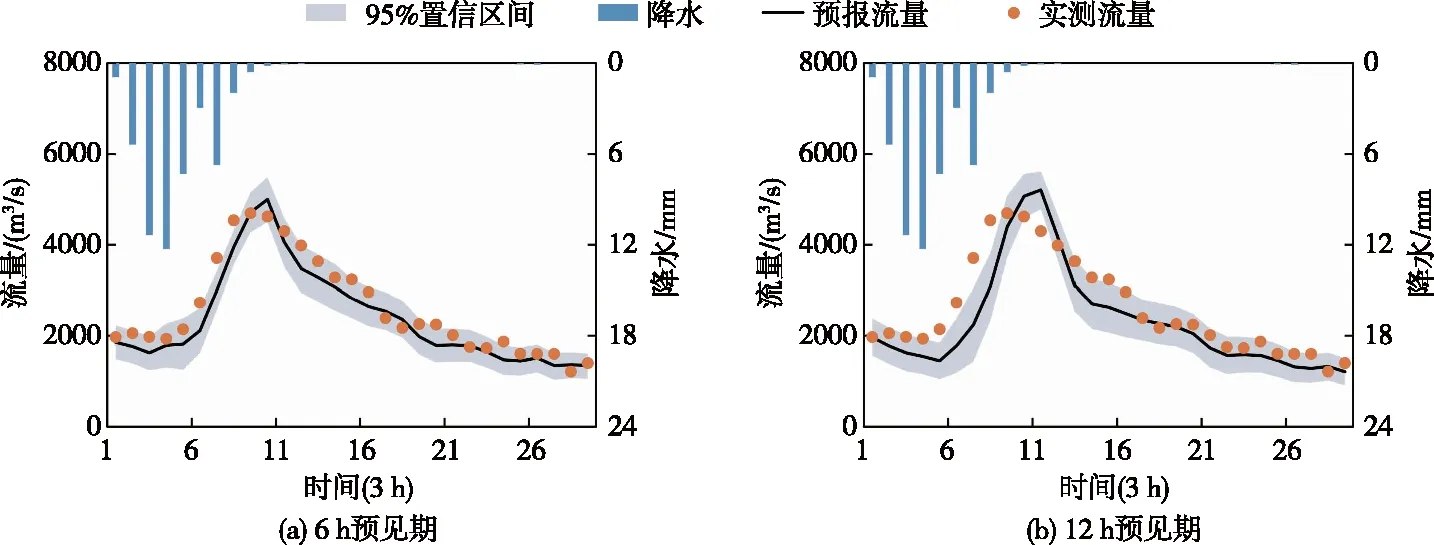
图8 XAJ-LSTM-EDE-MDN模型在建溪流域2012/5/3 T3∶00-5/6 T21∶00洪水事件的置信区间图
从图7可以看出,XAJ-LSTM-EDE-MDN模型在陆水流域6 h预见期可以较好地拟合实测流量,置信区间覆盖全部实测流量点,且区间宽度较窄,表明置信区间可以较好地反映预报不确定性。12 h预见期的预报洪水拟合效果有所下降,在涨水过程出现较大幅度波动,但仍然可以较为准确地预报洪峰及峰现时间;置信区间逐渐变宽,表明预报不确定性逐渐增大,但覆盖率仍接近95%。
如图8所示,XAJ-LSTM-EDE-MDN模型在建溪流域6 h预见期具有较好的预报效果。随着预见期的延长,在12 h预见期,预报洪水过程线拟合效果降低,并高估了洪峰,预报峰现时间滞后两个时段,但仍然可以较好地拟合退水过程;置信区间变宽,表明预报不确定性增加,但仍能覆盖大多数实测流量点。
4.3 分析讨论根据前述评价指标可知,XAJ-LSTM-EDE-MDN模型可以在不降低XAJ-LSTM-EDE模型预报精度的前提下,获得相对较为可靠的概率预报。该模型的优势包括:
(1)无须假设分布函数。所提模型通过神经网络调整多个核函数的权重和参数来拟合条件分布函数,可以避免分布函数假设。
(2)目标变量条件分布中核函数的参数和权重可以随模型输入变化,提高了应对不同量级流量概率预报的适应性。
(3)XAJ-LSTM-EDE-MDN模型具有较高的预报精度,并可直接量化洪水过程预报的不确定性,为防洪减灾决策提供有效的风险信息。
本研究也存在几个不足,包括:
(1)因增加了MDN概率预报过程,模型训练成本有所增加;采用试错法优选网络参数,计算效率较低。
(2)条件密度函数可能更倾向于产生集中度高的概率预报性能,这一现象可能与训练神经网络使用的损失函数有关。采用目标变量在条件分布函数中的概率尽可能大作为网络训练标准,可能使神经网络预测的条件密度函数更加尖锐。
(3)将XAJ模型预报流量作为外源输入是在深度学习可解释性方面的初步尝试,距离在内部结构或参数中实现物理意义上的解释,还有很多工作需要进一步研究。
5 结论
本研究提出了一种新的深度学习概率预报模型,将不确定性量化层(MDN层)耦合至XAJ-LSTM-EDE模型的输出层,构建了可以量化预报不确定性的XAJ-LSTM-EDE-MDN模型。并以XAJ-LSTM和XAJ-LSTM-EDE模型为基准模型,从确定性预报和不确定性量化性能两个方面分析了所提模型的有效性。结论如下所示。
(1)根据NSE、RE和MAE指标可以看出,XAJ-LSTM-EDE-MDN模型可以获得与XAJ-LSTM-EDE模型相近的预报性能,并优于XAJ-LSTM模型的预报性能。
(2)XAJ-LSTM-EDE-MDN模型可以获得覆盖率接近95%置信水平的置信区间,同时根据α-index和CRPS指标,XAJ-LSTM-EDE-MDN模型的概率预报结果是合理可靠的,可以有效反映预报不确定性,并能产生相对接近预报量真实分布的条件分布。
(3)在深度学习模型中采用混合密度网络逼近后验分布是可行的,XAJ-LSTM-EDE-MDN模型可以获得时变的不确定性信息,且无须假设分布函数。
后续研究可集中于参数优化算法和探讨洪水过程概率预报在调度中的应用等,并对流域滞时和预见期长度对预报精度的影响进行研究。同时,还可探讨在深度学习模型的损失函数中加入额外约束,使得概率预报性能兼顾可靠性和集中度。
猜你喜欢
法律方法(2022年2期)2022-10-20
中国石油石化(2022年12期)2022-07-16
中国水土保持(2022年6期)2022-06-08
中国水土保持(2021年7期)2021-07-08
中国水土保持(2021年12期)2021-04-11
中国外汇(2019年19期)2019-11-26
中国外汇(2019年7期)2019-07-13
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
水利规划与设计(2018年1期)2018-01-31
