
基于数据挖掘的数据库信息查询访问控制系统设计
2023-09-19 13:34李廷鹃李玉健向梦芸庞雅琪
电子设计工程 2023年18期
吴 浩,李廷鹃,李玉健,向梦芸,庞雅琪
(1.青海省科技发展服务中心,青海西宁 810000;2.青海省科学技术信息研究所有限公司,青海西宁 810000)
数据挖掘思想对于数据类型的要求并不十分严格,可用于挖掘处理的数据参量既可以是结构化状态参量,也可以是半结构化状态参量,甚至一些形态特殊的异构型参量也可以被作为挖掘指令的处理对象。在既定数据库存储环境中,数据挖掘方法既可以总结出信息参量的数学归纳规律,也能够将主变量指标与因变量指标的数学关系对调,从而使得数据库主机能够对传输信息参量完成准确记录[1-2]。与其他类型的搜索算法相比,数据挖掘方法对于信息参量的包容性更强,既不需要准确掌握待处理数据来源,也不限制信息参量的实时传输速率。
数据库信息查询机制是指网络主机在数据库环境中,按照向量分布形式,提取数据信息文件的执行算法,能够将已存储数据的参量全部筛选出来,并可以借助传输通路,将这些数据文本反馈回核心网络主机[3]。随着待处理数据信息参量的不断累积,数据库信息查询机制会出现明显的缺失状态,极易使网络主机无法对数据信息参量的访问连接行为做出有效控制。
传统RBAC 访问控制系统以B/S 架构为基础,能够联合云计算主机与TLoa 设备对已存储信息查询,并可以将完成检测的指令文件存储于数据库主机之中[4]。然而,此类型应用系统并不能提升数据库信息查询机制的完整度水平,不利于有效控制数据信息参量的访问连接行为。为解决上述问题,设计基于数据挖掘的数据库信息查询访问控制系统。
1 系统硬件设计
1.1 CloudFileUser控制主机
在数据库信息查询访问控制系统中,CloudFile User 控制主机负责与TCP 端口、UDP 端口进行对接,可以在建立数据库访问机制的同时,协调数据信息参量的实时存储行为,并可将所生成执行指令借助网络通信模块,传输至下级硬件应用设备之中[5-6]。对于CloudFileUser 控制主机而言,TCP 端口与UDP 端口是两个完全独立的连接结构,前者负责处理已存储的数据信息参量,后者负责记录与查询机制相关的执行指令,但在访问连接行为非可逆的情况下,两者之间会建立虚拟数据反馈关系。完整的CloudFileUser 控制主机连接形式如图1 所示。

图1 CloudFileUser控制主机连接结构
为避免数据库主机对待查询信息参量的实时存储能力受到影响,访问连接指令的传输方向只能由TCP 端口与UDP 端口指向下级客户端平台。
1.2 Server查询模块
Server 查询模块作为CloudFileUser 控制主机的下级负载结构,能够借助连接管脚深入数据库主机内部,并可以对其中存储的信息参量实现分类提取。在数据挖掘算法的作用下,由Server 查询模块提取的信息参量可被系统主机直接调取,完成调取指令后的数据信息可以暂时存储于数据处理模块中,以便控制设备可将其直接用于完善系统主机所遵循的查询机制[7-8]。Server 查询模块的设计主要针对String、Array、List等多个端口节点。

表1 Server查询模块设置标准
在数据库信息查询访问控制系统中,Server 查询模块的连接位置存在于CloudFileUser 控制主机与数据处理模块之间。
1.3 数据处理模块
数据处理模块由处理终端、控制主机两部分组成。完整的数据处理模块连接结构如图2 所示。
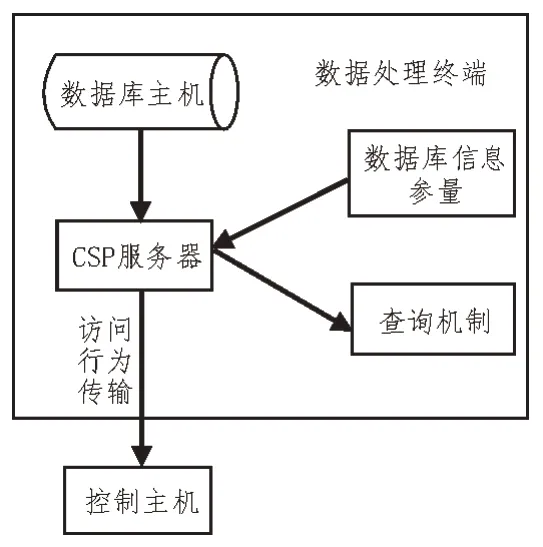
图2 数据处理模块的结构示意图
其中,数据处理终端以CSP 服务器作为核心应用结构,可以准确地提取数据库信息参量,并可以在数据库主机元件的作用下,规范查询机制的作用形式[9-10]。为增强数据库信息查询机制的完整性,在建立数据处理模块时,要求信息参量不具有双向传输的执行能力。
2 软件设计
2.1 数据簇中心提取
数据簇中心是指数据库信息参量的核心存储位置。在数据挖掘算法中,系统主机只有准确掌握数据簇中心的定义表达式,才能够最大化提升查询机制的完整性水平[11-12]。定义数据簇中心表达式需要确认访问行为系数、连接行为系数的实际取值。设e表示访问行为系数取值,w表示连接行为系数取值,在数据挖掘算法的影响下,e指标、w指标的最小取值结果都等于物理自然数1。设re表示基于系数e的参量查询特征,rw表示基于系数w的参量查询特征。联立上述物理量,可将基于数据挖掘的数据簇中心提取表达式定义为:
式中,β表示查询参量的提取系数,ΔP表示数据库信息的单位提取量。为使数据簇中心提取表达式的求解结果更符合实际应用需求,系数re与系数rw的赋值不能同时等于极大值或极小值。
2.2 数据集转换
数据集转换是执行数据挖掘算法的必要处理环节,可以将待检测数据库信息参量与查询机制对应起来,从而使得控制主机能够对信息访问行为进行按需调节[13-14]。设Z表示一个标准的数据库信息参量集合空间,其定义式如下:
其中,i1,i2,…,in表示n个不同的信息参量定义系数。设d1,d2,…,dn表示与信息参量定义系数相关的数据转换度量值,φ表示信息参量调节系数,γ表示数据库信息参量的查询向量。在上述物理量的支持下,联立式(1)、式(2),可将数据集转换条件定义为:
2.3 数据挖掘深度的优化
挖掘深度对系统主机数据库信息参量的处理能力具有关键性影响[15-16]。由于数据挖掘算法的执行不具备逆运算的能力,所以在计算挖掘深度指标时,要求数据库信息参量的传输必须满足一致性原则。设λmax表示数据库信息参量挖掘特征的最大取值结果,v1、v2表示两个随机选取的信息参量挖掘定义项系数。数据库信息在查询访问控制系统中的挖掘深度计算式为:
当挖掘深度指标符合既定实值标准时,增大λmax系数取值可以充分激发查询访问控制系统对于数据库信息参量的处理能力[17-19]。
3 实例分析
数据库信息查询机制的完整性(η)可以描述网络主机对于数据信息参量访问连接行为的控制有效性,且完整度水平越高,网络主机对于数据信息参量访问连接行为的控制也就越有效。
数据库信息查询机制的完整性(η) 的计算式如下:
式中,M表示数据库信息检测总量,B表示趋向性访问行为系数。
以基于数据挖掘的数据库信息查询访问控制系统作为实验组应用方法,以传统RBAC 访问控制系统作为对照组应用方法,分别将两类应用系统的执行程序输入所选定的实验主机,记录在相同实验时间内,实验组、对照组变量指标的数值变化情况。具体实验流程如图3 所示。
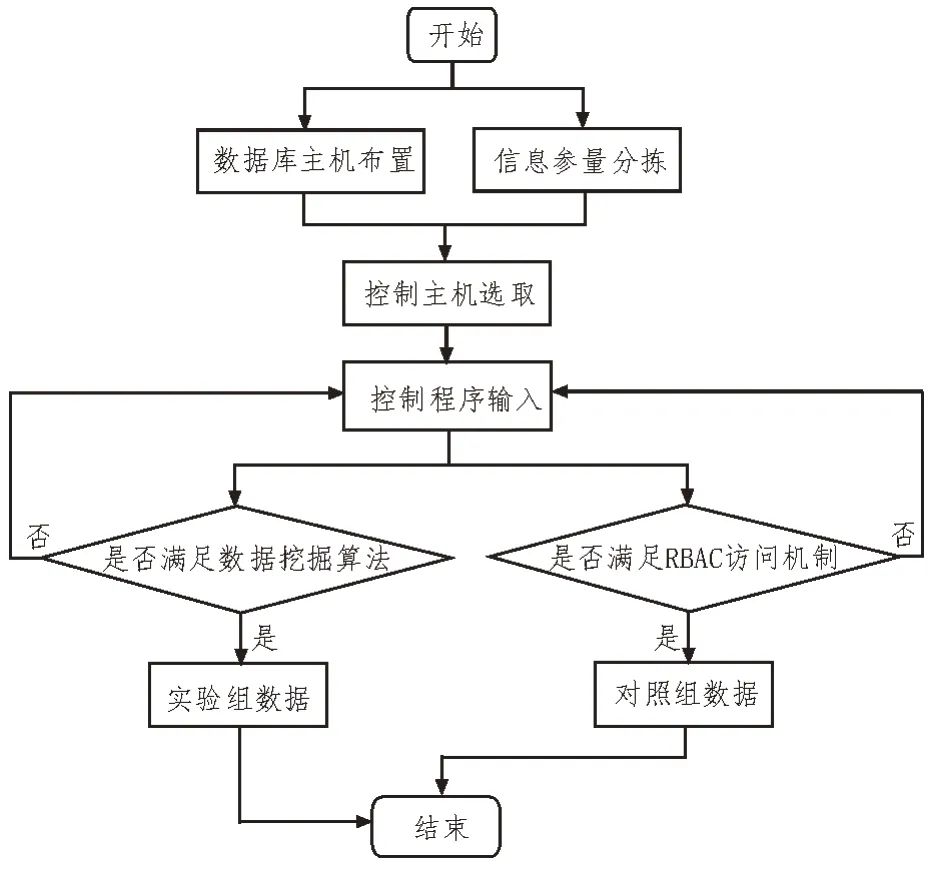
图3 实验流程图
以60 min 作为实验时长,分别记录该段实验时间内,实验组、对照组数据库信息检测总量(M) 与趋向性访问行为系数(B)的数值变化情况,详情如表2、表3 所示。

表2 数据库信息检测总量

表3 趋向性访问行为系数
分析表2 可知,实验过程中,实验组、对照组数据库信息检测总量均呈现出不断增大的数值变化状态,二者上升幅度相差不大,但实验组数据库信息检测总量均值高于对照组。
分析表3 可知,实验组趋向性访问行为系数呈现出先增大后稳定的变化状态,但其整体均值水平相对较低。对照组趋向性访问行为系数在整个实验过程中始终保持不断增大的数值变化状态,且其均值水平明显高于实验组。
根据表2、表3 中的数据可计算数据库信息查询机制的完整性(η),计算结果如图4 所示。

图4 数据库信息查询机制的完整性测试
分析图4 可知,在整个实验过程中,实验组η指标的均值水平更高,其最大值达到了71.6%;对照组η指标的均值水平则相对较低,其最大值只能达到43.3%,与实验组最大值相比,下降了28.3%。
综上可知,在数据挖掘算法的应用下,数据库信息查询机制的完整性提升了近30%,与传统RBAC访问控制系统相比,新型应用系统更能确保网络主机对于数据信息参量访问连接行为的控制有效性。
4 结束语
应用数据挖掘算法,设计新型数据库信息查询访问控制系统,重新规划了CloudFileUser 控制主机与Server 查询模块之间的实时连接关系,又借助数据处理模块,对数据簇中心进行按需提取。在实用性方面,新型控制系统增强了数据库信息查询机制的完整性,使得网络主机可以有效控制数据信息参量的访问连接行为,符合实际应用需求。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
中学生数理化·七年级数学人教版(2018年11期)2019-01-31
娃娃乐园·综合智能(2018年23期)2018-12-26
娃娃乐园·综合智能(2018年3期)2018-03-22
电力与能源(2017年6期)2017-05-14
中国照明(2016年6期)2016-06-15
信息通信技术(2015年6期)2015-12-26
物理实验(2015年9期)2015-02-28
数学年刊A辑(中文版)(2014年4期)2014-10-30
声学技术(2014年2期)2014-06-21
