
融合底层信息的电气工程领域神经机器翻译
2023-09-18 13:29陈媛,陈红
河南科技大学学报(自然科学版) 2023年6期
陈 媛,陈 红
(河南科技大学 a.外国语学院;b.信息工程学院;c.河南省电力电子装置与系统工程研究中心,河南 洛阳 471023)
0 引言
机器翻译是指利用计算机等相关技术自动将一种自然语言转换成与之语义等价的另一种自然语言的过程[1]。机器翻译自提出以来主要可以分为规则机器翻译[2]、实例机器翻译[3]、统计机器翻译[4]和神经机器翻译[5]4种。神经机器翻译作为当前机器翻译的主流翻译方法,其在通用领域内的翻译已经达到了不错的效果,但是在小语种或专业领域这样的低资源领域仍面临很大的挑战[6]。随着目前智能电网的不断建设,技术人员国际交流越来越频繁,因此做好电气工程领域内的神经机器翻译工作是很有必要的。
自神经机器翻译提出以来,翻译模型经历多次的迭代更新,由最初的序列到序列的翻译模型(sequence to sequence,Seq2Seq)[7]、基于注意力机制的翻译模型Attention-NMT[8]到如今主流的完全基于注意力机制的翻译模型Transformer[9],模型提取特征的能力逐步获得了提升。为取得更好的翻译效果,针对翻译模型陆陆续续提出了很多改进方法。对于神经机器翻译来说,如何充分利用现有的语料资源,并从中提取到更多的特征信息是提升模型翻译性能的一个关键点。文献[10]将机器翻译后的译文作为解码器端的输入,并对神经机器翻译模型解码器端的掩码结构进行了改进,可以进一步利用源语言信息对机器翻译的文本进行重解码过程,提高了译文的翻译质量。文献[11]使用语言模型单词预测概率作为辅助信息,将其与翻译模型的编码信息拼接后进行全连接层的映射,得到融合语言模型知识的特征向量,并将其用于翻译模型的解码过程,得到了翻译效果的提升。文献[12]使用卷积神经网络对训练语料进行字符级别的特征提取,并将其与词级别的特征向量使用拼接的方法进行向量融合,并提出基于注意力机制嵌入的长短时记忆网络(long short-term memory,LSTM)神经机器翻译模型,取得了翻译效果的提升。文献[13]对句子中的小句进行标注,并提出多路协同自注意力机制和编码器-解码器小句对齐注意力子层地方法对翻译模型进行改进,很好地融合了小句内的知识信息,提升了模型的翻译效果。为在模型中获得更全面的源语言表示,文献[14]通过字典、语义消歧和随机候选3种方法获取单词的翻译作为其词义信息,并将得到的词义信息融合至编码器端,得到融合词义信息的源语言表示向量,提升了模型的翻译性能。文献[15]针对篇章级的神经机器翻译,对句子内的单词和篇章内的所有句子以及句内单词进行词句权重和词词权重的计算,并将其与编码器端本身的自注意力机制进行融合,再通过门控机制得到最终的源语言向量,一定程度上解决了篇章翻译在翻译当前句时只关注前后几个句子的问题。
对于电气工程这样的低资源领域,如何充分利用现有的语料并从中提取出更多的特征信息显得更加重要,本文以目前主流的神经机器翻译模型Transformer为基线模型,针对模型内单元堆叠的结构造成的顶层单元输出和底层单元输出在语义和语法信息上偏重差距较大的问题,在翻译模型编码器侧底部额外添加了特征提取层,用于提取源语言内包含的底层信息,将其输出,继续用于后续的编码器编码,增加编码环节的特征提取层数,并采用残差连接的方式将提取到的底层信息向上传递,以在翻译模型内部得到包含更全面信息的源语言表示向量。同理,也将目标语言的底层信息向上传递,进一步发挥编码器底层信息融合的优势。采用特定的电气工程领域内的中英平行语料进行模型训练,提升模型在电气领域内的翻译效果。
1 融合底层信息的神经机器翻译模型
Transformer模型虽然通过多层编码器单元的堆叠结构实现了编码器特征提取能力上的提升,但是随着模型深度的增加,也很容易造成模型底层信息的丢失。对于提取特征的编码器,顶层编码器单元输出的源语言表示向量相比于底层编码器单元输出的源语言表示向量会更侧重于语义信息;相反地,底层编码器单元输出的源语言表示向量相比于顶层编码器单元输出的源语言表示向量则会更侧重于词义信息。而原始的Transformer翻译模型直接使用编码器的顶层输出作为源语言的特征向量进行解码会一定程度上导致特征向量中包含的源语言底层信息不足,因此本文在Transformer模型的基础上对其进行结构上的改进,在模型编码器之前添加了额外的特征提取层,并分别使用多种网络结构进行源语言底层信息的特征提取,最后将提取到的信息传输至顶层编码器单元的输出处,使用残差连接的方式对2个向量进行融合,将融合后的特征向量作为最终的源语言表示向量送入至解码器端,用于后续解码和翻译过程。并对解码器端进行改进,使用残差连接的结构将解码器端底层的目标语言词嵌入向量传输至顶层的解码器单元输出处,实现解码器端底层信息的传递,在编码器端融合底层特征的基础上发挥更大的底层信息优势,使得解码过程中能充分利用目标语言的底层特征,模型结构如图1所示。
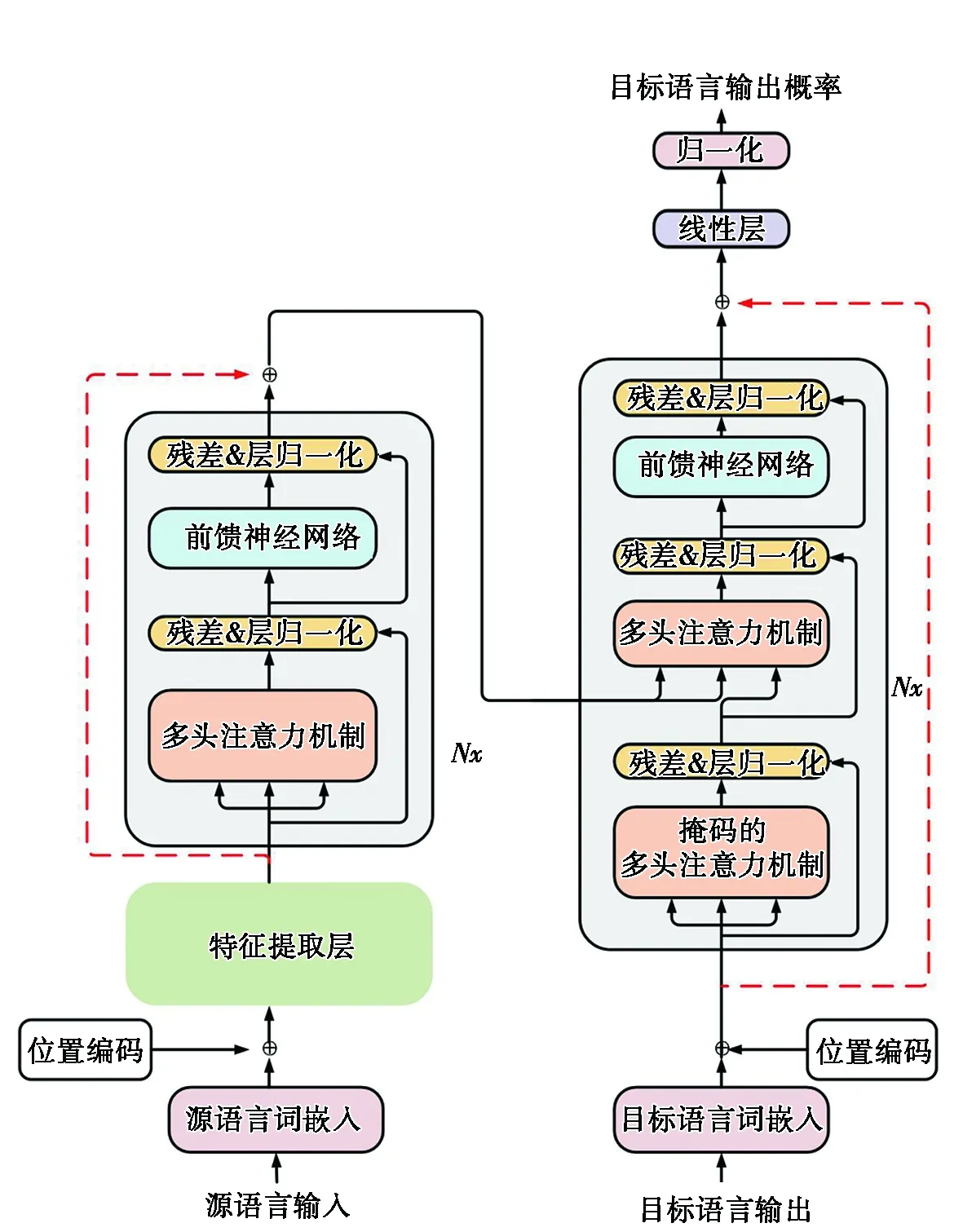
图1 融合底层信息的电气工程领域神经机器翻译模型
为保证特征提取层提取底层特征的能力,本文分别使用前馈神经网络(feedforward neural network,FNN)、双向长短时记忆网络(bi-directional long short-term memory,BiLSTM)[16]、双向门控循环单元(bidirectional gate recurrent unit,BiGRU)[17]、多头自注意力机制(Multi-Head Self-Attention)4种网络结构在翻译模型的编码器侧对源语言进行底层信息的特征提取。其中,FNN采用两次与模型维度相同的全连接层映射实现;BiLSTM、BiGRU网络内的隐藏层向量均设置为512,对其网络输出进行维度变换后作为底层特征提取层的输出;Multi-Head Self-Attention网络为防止由于层数堆叠过多,导致模型发生过拟合和信息丢失的问题,使用与Transformer内部编码器单元相同的网络结构,并在其内部采用与Transformer编码器端相同的掩码机制,且其网络结构内部的隐藏层向量维度设置为512,与Transformer模型保持一致。
2 实验设置
2.1 数据集
为实现电气工程领域内的神经机器翻译,本文全部采用搜集到的电气工程领域内的中英平行语料对翻译模型进行训练,其内容主要来自于电气领域内的一些公开资料,如电气领域内具有中英文对照的专业书籍[18-21]、公开发表的期刊、专利、电气设备说明书,以及电气领域内的大型技术论坛或官方网站等,其中训练集约19×104条,验证集和测试集各为2 000条。
2.2 实验设置
本实验以Transformer为基线模型,并使用PyTorch 开源神经翻译模型(open source neural machine translation in PyTorch,OpenNMTpy)[22](https://github.com/OpenNMT/OpenNMT-py)进行模型的复现。实验运行环境为Ubuntu18.04操作系统,并采用1张型号为NVIDIA GeForce RTX 3090的显卡。实验过程中设置中英文词表大小为40 000,将中英平行语料的句子长度设置在100以内,对语料中长度超过100的句子进行过滤,并分别采用空格和jieba分词对训练语料的英文和中文进行分词。模型内词向量维度和编解码器内部传递的隐藏层维度均设置为512,注意力头数设置为8头。训练过程中batch_type设置为“sents”,batch_size设置为64,采用Adam优化算法进行优化,神经元随机失活的概率dropout设置为0.1,并采用束搜索的机制进行解码,其中beam_size设置为5,其余参数均采用OpenNMT的默认参数。本次训练共设置25 000步,每1 000步进行1次模型的验证和保存,并使用系统内的multi-bleu-detok1.perl文件对机器翻译的译文进行双语评估研究(bilingual evaluation understudy,BLEU)值的评价。
2.3 机器翻译性能评估
对于机器翻译任务来说,如何评价一个翻译模型的效果对于模型的翻译效果体现和后续模型的改进方向是有很大的指导意义的。翻译结果的评价,可以分为人工测评和自动测评两种方法,人工评价的方式需要大量的语言学专家对翻译的文本进行质量评估,需要耗费大量的人力物力,且人工评价的方式具有很强的主观性,没有客观统一的评价方法,而采用自动评价的方法,通过计算的方式来对翻译文本进行质量的评估,虽不如人工评价准确,但相对来说会更方便和快捷,因此机器翻译的评测指标也是机器翻译领域内一个很重要的研究方向。
本文采用自动评测技术BLEU[23]对机器翻译的结果进行评估。该方法以句子为单位,对机器翻译译文内n元词组与人工翻译得到的参考语句的n元词组之间的相似度来判断翻译效果。首先,对特定的n元词组分别在机器翻译译文和多个参考语句内出现的最大次数进行统计,取二者中的最小值作为最终统计的共现次数,然后将该共现次数除以机器翻译译文内总的n元词组的个数,得到其对应的精度Pn,然后对Pn进行求对数、加权求和、取指数的计算用于求取BLEU值。BLEU值越高,则代表机器翻译的输出译文与参考语句越接近。为了防止计算过程中由于句子过短导致的BLEU值虚高,在进行完对数的加权求和后,又乘以惩罚因子BP,句子越短BP值的数值越接近0,其计算公式如下:
Countclip(n-gram)=min{Count(n-gram),Max RefCount(n-gram)};
(1)
(2)
(3)
(4)
其中:Countclip(n-gram)为经过修剪(clipping)后的n-gram计数;Count(n-gram)为n元词组在机器翻译结果中出现的次数;Max RefCount(n-garm)为n元词组在参考语句中出现的最多次数;C为候选翻译的集合;C′为从候选翻译集合中选择的一个特定的候选翻译;Countclip(n-gram′)为经过修剪后的候选翻译集合中n-gram′的计数值;BP为长度惩罚因子;c为机器翻译语句的长度;r为参考译文的长度;wn为n-gram精确度的权重;在本文中N取值为4,wn=1/N。
3 实验结果与分析
为验证特征提取层的有效性,本次实验共分为3组。首先,对由FNN、BiLSTM、BiGRU和Multi-Head Self-Attention等4种网络结构组成的特征提取层进行翻译模型改进的实验效果分析。并对由Multi-Head Self-Attention构成的特征提取层进行多层堆叠的对比实验,探寻最佳的特征提取层数。最后,在特征提取层的基础上在解码器端添加残差连接,实现解码器端底层信息的向上传递。
3.1 特征提取层对比实验
本文以Transformer为基线模型Baseline,并对基线的翻译模型进行特征提取层的改进,分别实现以FNN、BiLSTM、BiGRU、1层的Multi-Head Self-Attention等4种网络结构作为特征提取层的翻译模型FNN+、BiLSTM+、BiGRU+、Multi-Head Self-Attention1+。实验中的训练环境和所有参数均保持一致,实验结果如表1所示。表1中:σ=(融合底层特征的翻译模型BLEU值-基线模型BLEU值)×100 。
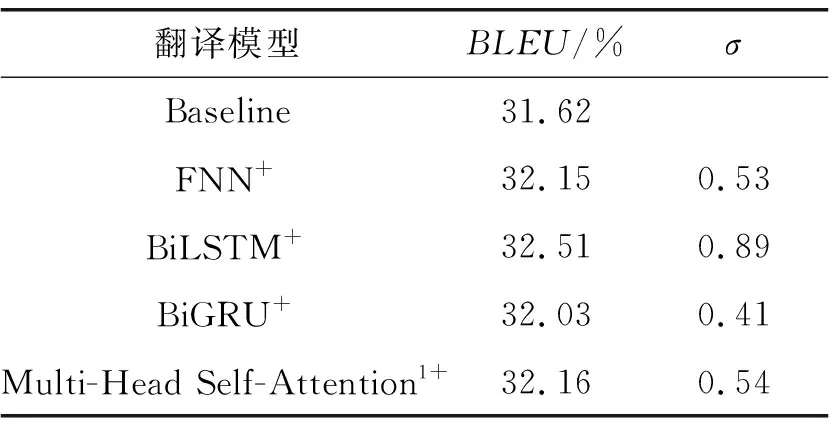
表1 特征提取层对比实验BLEU值
由表1的实验结果进行分析可知:
(Ⅰ)本文提出的多种基于特征提取层的底层信息融合实验均对基线模型有翻译效果的提升,证明了底层信息融合方法的有效性。
(Ⅱ)单层网络结构构成的特征提取层中,以参数量最多的BiLSTM网络结构提升效果最佳,充分证明了LSTM网络提取特征的有效性。相比于BiLSTM的实验效果,BiGRU组成的特征提取层对翻译模型的提升效果较差,考虑是由于网络结构简化的同时,也降低了BiGRU网络对特征提取的效果。
(Ⅲ)由FNN和Multi-Head Self-Attention1+构成的特征提取层对翻译模型的提升效果相当,但其中结构在模型内引入的参数量较少,说明对于底层信息的特征提取来说,简单的网络结构反而能实现更好的特征提取功能。
(Ⅳ)BiGRU和Multi-Head Self-Attention1+在模型中引入的参数量相似,但Multi-Head Self-Attention1+对翻译模型的提升效果更强,说明了特征提取的能力强于结构简化的BiGRU网络。
3.2 Multi-Head Self-Attention多层对比实验
为探索多层自注意力机制对模型特征提取能力的影响,本文另外设置了多层的Multi-Head Self-Attention网络结构作为特征提取层时的对比实验。分别取1~6层的Multi-Head Self-Attention作为特征
提取层添加至翻译模型中得到对应的Multi-Head Self-AttentionN+模型,实验结果如表2所示,其中σ=(Multi-Head Self-AttentionN+模型BLEU值-基线模型BLEU值)×100 。
由表2可知:由多个多头自注意力机制网络堆叠作为底层信息提取层,确实会带来翻译效果上的提升,但是其堆叠的层数并不能与翻译模型的提升效果成正比,其中以3层的Multi-Head Self-Attention结构对翻译模型的提升效果最好,因为在特征提取层数增加的同时,翻译模型内部的参数也会随之增加,而适当增加参数可以提升模型的翻译性能,但是过多参数的引入反而会导致模型在训练过程中出现过拟合的情况,反而对翻译效果的提升造成负面影响。
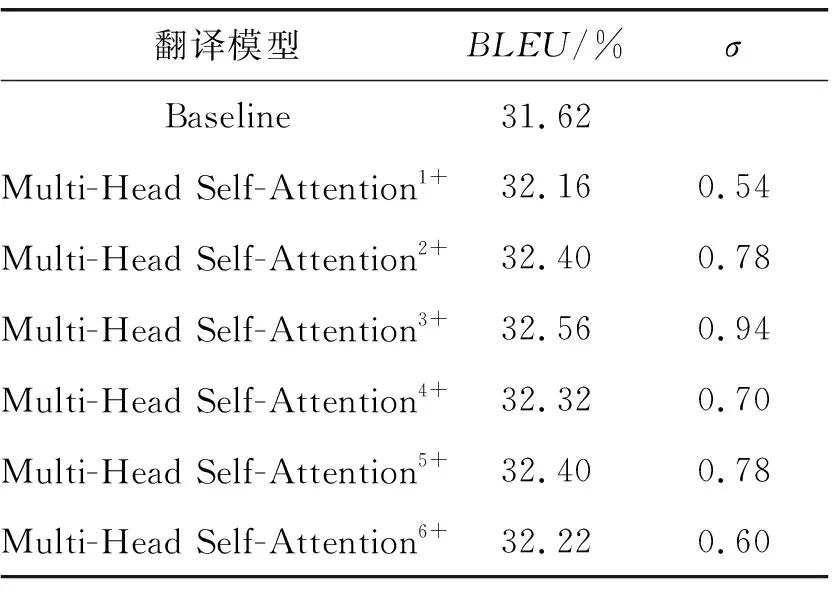
表2 层数对比实验BLEU值
3.3 综合实验
编码器端使用特征提取层融合底层信息的同时,在不添加额外参数的前提下,通过残差连接的结构将解码器端底层的目标语言词嵌入信息传输至解码器顶层单元的输出处,用于后续解码,分别得到对应的FNN+_Res、BiLSTM+_Res、BiGRU+_Res、Multi-Head Self-AttentionN+_Res模型,使得模型在融合源语言底层特征的同时,也能很好地利用解码器端的译文信息,充分利用融合底层信息后模型内部传递的特征向量,实现底层信息的叠加效果,进而提高模型的翻译性能,实验结果如表3所示。表3中σ=(综合改进模型BLEU值-基线模型BLEU值)×100。
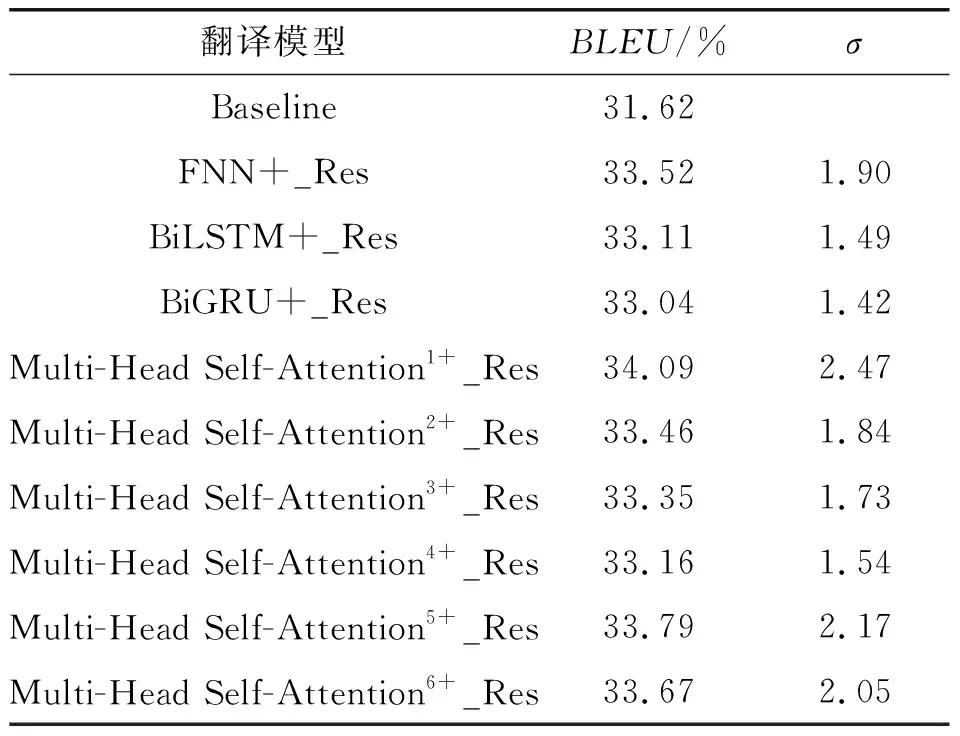
表3 综合实验BLEU值
对表3进行数据分析可知:
(Ⅰ)在解码器端添加残差连接的机制后,本文所提出的分别由4种网络结构组成特征提取层的翻译模型均有了翻译效果的进一步提升,说明在编码器端融合底层特征后对模型译文的生成有着很好的提升效果,而在解码器端再次使用残差连接的方法不仅可以实现目标语言端底层信息的传递,补全解码器低层的语法信息,而且可以实现提升效果的叠加,证明了融合底层信息方法的有效性。
(Ⅱ)对比表3与表1数据可知,在解码器端添加残差连接的机制后,减少了BiLSTM和BiGRU对模型提升效果的差距,说明解码器端残差连接的机制充分发挥了编码器端特征提取层的作用。
(Ⅲ)由表1与表3数据可知,由FNN作为特征提取层的翻译模型,在解码器端添加了底层信息的残差连接之后,对翻译模型有了进一步的提升效果,且其效果高于由BiLSTM和BiGRU特征提取层对模型的提升效果,再次证明了对于底层信息的特征提取,简单的网络结构也可以实现很好的效果。
(Ⅳ)对比表1与表3内数据可知,由多层的多头自注意力机制构成的特征提取层在添加解码器的残差连接后,很好地实现了模型的翻译性能,其中以单层的多头自注意力机制对翻译模型提升的效果最好,而层数的增加反而降低了模型的翻译性能,说明解码器端残差连接的结构会进一步放大底层优势,因此层数较少的多头自注意力构成的特征提取层反而能很好的提升模型的翻译性能。
(Ⅴ)取基线模型、编码器端效果最好的Multi-Head Self-Attention3+、信息增强后效果最好的Multi-Head Self-Attention1+_Res模型进行翻译效果的对比,如图2所示。由图2可知:编码器端融合特征提取层输出的源语言底层信息后,模型的翻译效果有了较好的提升,在此基础上对解码器端进行残差连接的改进之后,模型的翻译效果取得了进一步的提升,且从模型训练的开始就表现出更好的翻译性能。
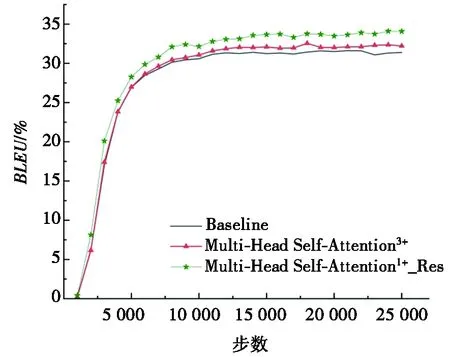
图2 综合对比图
(Ⅵ)取部分测试集的参考语句、基线模型翻译结果和使用单个多头注意力机制作为特征提取层的融合底层信息的翻译模型的翻译结果进行对比,如表4所示。由表4可见,与基线模型相比,向量融合改进后的模型翻译结果不仅减少了未登录词“

表4 翻译效果对比
4 结束语
本文针对Transformer模型多层单元堆叠的结构特点,提出一种融合底层信息的神经机器翻译模型,在编码器端底部添加额外的特征提取层,并分别采用FNN、BiLSTM、BiGRU和Multi-Head Self-Attention等4种网络结构实现源语言底层信息的特征提取,并通过残差连接的方式实现编解码器端底层信息的向上传递,实现底层信息的融合,一定程度上解决了模型结构堆叠造成的底层信息丢失问题,且由于底层信息与顶层输出分别包含更多的语法信息和语义信息,二者融合的方法也使得模型在编解码器输出处得到了信息更全面的特征向量,从而实现模型翻译性能的提升。使用电气工程领域内的中英双语平行语料对模型进行训练,其翻译性能最多提升了2.47个百分点。但由于目前的工作仍处于初步探索和尝试阶段,还有很多问题和任务有待解决,包括训练语料较少,电气工程学科特征融入不足等,针对以上问题,未来的工作会从数据增强和融入电气工程领域内的语言学特征两方面进行。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
速读·下旬(2016年7期)2016-07-20
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
