
基于多对抗性鉴别网络的人脸活体检测
2023-09-18 02:04况立群谢剑斌谌钟毓谢昌颐
计算机工程与科学 2023年9期
任 拓,闫 玮,况立群,谢剑斌,谌钟毓,高 峰,郭 锐,束 伟,谢昌颐
(1.中北大学大数据学院,山西 太原 030051;2.国防科技大学电子科学学院,湖南 长沙 410073;3.辽宁科技大学电子与信息工程学院,辽宁 鞍山 114051;4.墨尔本大学医学、牙科和健康科学学院,澳大利亚 墨尔本 3010)
1 引言
人脸活体检测是人脸识别的关键一环,通过人脸活体检测可以有效筛选出伪造人脸,从而保障人脸识别系统的安全。然而,现阶段人脸活体检测方法普遍存在泛化能力不足的问题。一些学者提出诸如DeSpoof(face De-Spoofing)[1]、STDN(Spoof Trace Disentanglement Network)[2]及GOAS(Generic Object Anti-Spoofing)[3]等解纠缠表示学习方法来解决泛化问题,通过解析伪造人脸图像上的噪声模式、欺骗模式等来实现解离伪造痕迹,进行活体检测。但是,这些方法都是在有限的脸部区域寻找伪造痕迹,容易忽略一些局部细节问题,说明检测器对伪造痕迹的元素及特征缺乏了解。本文针对面部局部细节的优化,对人脸活体检测解纠缠学习方法展开深入的研究。
1.1 相关工作
人脸活体检测技术[4]是指一种判断人脸是否伪造(如人皮面具、数字照片、打印照片和视频等)的技术。现有的人脸活体检测技术主要分为3类:第1类使用传统人脸活体检测方法实现活体检测;第2类使用深度学习模型实现活体检测;第3类使用解纠缠表示学习实现活体检测。
第1类技术通过提取LBP(Local Binary Pattern)[5,6]、HOG(Histogram of Oriented Gradient)[7,8]和SIFT(Scale Invariant Feature Transform)[7]等静态特征和面部活动[9]、眨眼[10]、光线变化[11]和远程生理信号特征RPPG(Remote PhotoPlethysmoGraphy)等运动特征实现活体检测。但是,静态特征包含信息相对较少,并且操作繁琐;基于运动特征对回放视频类的攻击检测不友好。
第2类技术使用深度学习模型,主要包括Auxiliary[12]、STASN(Spatio-Temporal Anti-Spoof Network)[14]、CDCN(Central Difference Convolutional Network)[15]等,其中,Auxiliary[12]将循环神经网络RNN(Recurrent Neural Network)模型估计的人脸深度和利用视频序列估计的RPPG信号融合在一起,来区分真实人脸和伪造人脸。STASN[14]使用LSTM(Long Short-Term Memory)对时间信息编码进行分类,使用SASM(Spatial Anti-Spoofing Module)模块从多个区域中提取特征,寻找边界、反射伪影等细微证据,从而有效地识别伪人脸。CDCN[15]指中心差分卷积网络,通过聚合强度信息和梯度信息来获取人脸内在的细节模式。除此之外,也有一些研究人员开始研究少镜头/零镜头的人脸活体检测方法,零镜头指对未知欺骗攻击的检测,包括DTN(Deep Tree Network)[16]和AIM-FAS(Adaptive Inner-update Meta Face Anti-Spoofing)[17]。DTN[16]即深层树网络,它将欺骗样本划分为语义子群。当受到已知或未知的攻击检测时,DTN[16]将其路由到最相似的欺骗集群,并做出二进制决策。AIM-FAS[17]指自适应内部更新数据人脸反欺骗方法,训练一个后设学习者,通过学习预先确定的真实人脸、欺骗人脸和一些新攻击的例子,着重于发现看不见的欺骗类型的任务。
第3类技术使用解纠缠表示学习,在面部反欺骗中,欺骗图像可以被看作是对真实图像加入欺骗媒体和环境的“特殊”噪声的再现。解纠缠表示学习通过将伪造人脸图像上的伪造痕迹解离出来实现人脸活体检测,具体实现方法主要包括DeSpoof[1]、DSDG(Dual Spoof Disentanglement Generation)[18]、STDN[2]和GOAS[3]等。其中,DeSpoof[1]即面部去伪装,反向分解伪造人脸图像为一个欺骗噪声和一个真实人脸,然后利用欺骗噪声进行分类。DSDG[18]利用可变自动编码器VAE(Variational AutoEncoder)在潜在空间中学习面部身份表示和欺骗模式表示的联合分布。STDN[2]将输入人脸的欺骗痕迹作为一个多尺度模式的层次化组合。通过分离伪造痕迹并进行几何校正,拟合出原始伪造人脸的副本。GOAS[3]指通用对象反欺骗,使用一种基于GAN(Generative Adversarial Network)的结构来拟合和识别可见和不可见介质/传感器组合的噪声模式。特别是在CycleGAN[19]的激励下,Zhu等人[19,20]采用类似GAN的架构将潜在特征分解为活性特征和内容特征,解决了人脸防欺骗问题,结合了低层纹理和高层深度的特征,使活性空间规则化,便于分离表征学习。
1.2 本文主要工作
本文主要使用基于解纠缠表示学习的方法实现活体检测,针对解纠缠学习网络做出改进。本文的主要工作有:
(1)修改伪造痕迹解纠缠网络整体网络结构,设计多对抗性鉴别器网络,将原有的一个生成器和一个鉴别器的网络架构设计为一个生成器、一个主鉴别器和一个辅助性鉴别器的网络架构,重新设计了2个鉴别器。
(2)在设计的鉴别器中使用人脸的关键点产生五官(眼睛、鼻子、嘴巴)和皮肤上的遮罩,2个鉴别器各自独立处理五官和皮肤的细节问题,使生成器在学习的过程中除了注意全局特征外,更注重五官和皮肤上的细节,强化伪造人脸图像五官和皮肤上的特征,对本文的人脸活体检测起到了关键作用。
2 本文工作
本文提出一个基于多对抗性鉴别网络的人脸活体检测模型,改进了现有的伪造痕迹解纠缠网络架构,同时引入面部遮罩生成模块并设计2个新的鉴别器。
2.1 改进的多对抗性鉴别网络框架
本文对现有的伪造痕迹解纠缠网络框架[2,21]进行改进,提出一种多对抗性鉴别网络模型,设计了由一个生成器和多个鉴别器组成的网络架构,解析伪造人脸图像上的欺骗痕迹,在鉴别器部分设计主鉴别器和辅助鉴别器,并引入人脸遮罩模块,生成人脸皮肤和五官遮罩蒙版,整合人脸局部信息,使生成器拟合的图像更接近人脸照片的分布,同时解离出加强版的伪造痕迹。改进的网络架构以CycleGAN[19]为基本框架,主要包括生成器、线性重构器、皮肤遮罩生成模块和鉴别器(包含主鉴别器和辅助鉴别器)4个部分,如图1所示。图中G代表生成器,生成器采用U-Net结构,先下采样得到人脸图像的特征,再通过上采样将这些特征解析为痕迹元素(s,b,C,T),同时通过下采样将这些特征解析为一个8×8的二值化特征张量,生成器的具体实现在2.2节中介绍。R代表线性重构模块,通过将人脸图像与伪造痕迹元素线性加和得到重构的真实人脸图像和拟合的伪造人脸图像,线性重构模块的实现在2.3节中介绍。M代表面部遮罩生成模块,M的具体实现将在2.4节中介绍。D1代表主鉴别器,用于监督使用皮肤全局掩码的生成人脸图像;D2代表辅助性鉴别器,用于监督使用五官局部掩码的生成人脸图像,这2个鉴别器网络在2.5节中介绍。

Figure 1 Architecture of the proposed model
2.2 生成器网络设计
为了提取伪造人脸图像上的伪造痕迹,本文采取对抗学习的方式生成伪造痕迹,该生成器的网络架构如图2所示。该网络分别在3个尺度下提取特征,兼顾图像的颜色、上下文和纹理等信息,具体实现如下:首先使用下采样对图像进行编码,将图像由128*128变为64*64,32*32,16*16的特征图;其次再通过上采样对特征图进行解码,分别得到32*32,64*64,128*128的特征图,该3种分辨率下的特征图分别代表图像伪造信息,比如包含颜色范围的图像特征s和均衡偏差b,图像上下文内容信息C和图像纹理T。同时将下采样得到的3个不同尺度的特征图归一化为16*16并拼接起来;再次经过卷积神经网络将其提取为一幅代表伪造信息的二值化特征图,若该图像为伪造人脸,生成的二值化特征图分布应该尽可能接近1,反之,该分布应该尽可能接近0。
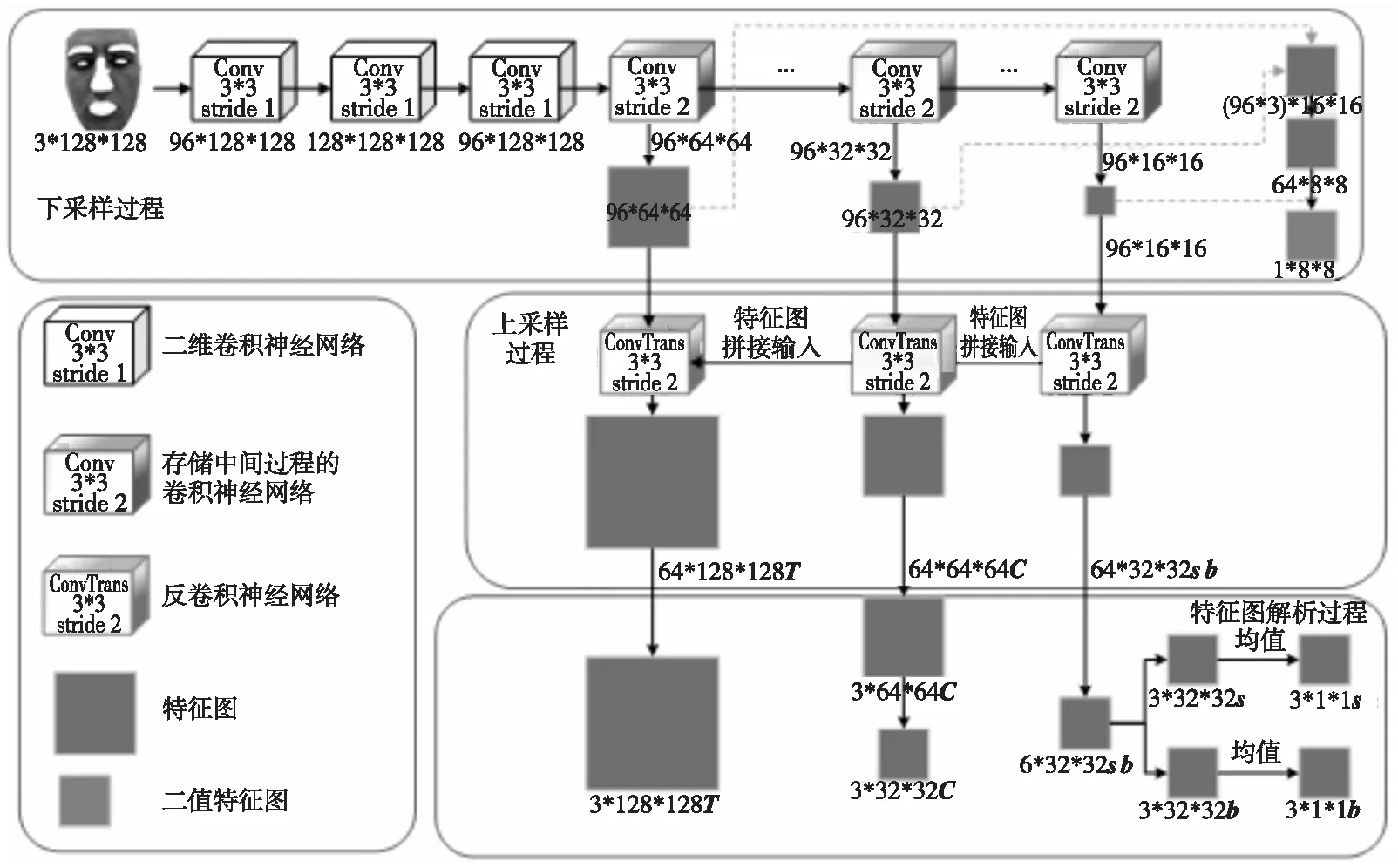
Figure 2 Generator architecture
在生成器训练过程中,对生成器生成的二值化特征图、合成的真实人脸图像和伪造人脸图像分别进行约束LG1、LG2、LG3,其中,LG1约束二值化特征图的生成,LG2和LG3均是对合成的人脸图像的约束。LG1的定义如式(1)所示:
LG1=MSE(fIlive,0)+MSE(fIspoof,1)
(1)
其中,f表示特征提取器,Ilive和Ispoof分别表示真实人脸图像和伪造人脸图像。
2.3 线性重构模块设计
线性重构模块主要负责2部分内容,其一是将生成器生成的伪造痕迹元素(s,b,C,T)与真实图像拟合伪造人脸图像;其二是用伪造痕迹元素与伪造人脸图像重构真实人脸图像,同时生成伪造痕迹图像。具体重构方式如式(2)~式(4)所示:
(2)
(3)
(4)

图3所示为线性重构模块的实现流程,其中,图3a表示由伪造人脸图像拟合真实人脸图像的过程,(s,b,C,T)表示伪造人脸图像经过生成器生成的伪造痕迹元素;图3b表示伪造痕迹图像的生成过程;图3c表示使用真实人脸图像与伪造痕迹拟合伪造人脸图像的过程。图3中加号符号表示将真实人脸图像和伪造痕迹图像线性相加,减号符号表示伪造人脸图像和伪造痕迹元素线性相减得到拟合的真实人脸图像,箭头与符号相交表示该输入为被减数,反之为减数。

Figure 3 Linear reconstruction process
为了使生成器生成的元素和人脸图像计算得到的人脸不失真,本文使用鉴别器对拟合图像进行约束,定义如式(5)所示:
LG2=(D1(Igen)-1)2
(5)
其中,Igen表示使用线性重构模块拟合的所有图像,包括拟合真实人脸图像和拟合伪造人脸图像。D1表示主鉴别器,D1(·)表示将生成器合成的图像放入主鉴别器里进行评价得到的数值,该数值在0~1,趋近于0表示鉴别器认为该图像为生成器合成的,趋近于1表示鉴别器认为该图像为数据集原始数据。

(6)
2.4 面部遮罩生成模块
为了拟合逼真的人脸,生成器必须保证生成的人脸与真实人脸图像的局部一致性,受Li等人[22]的启发,本文使用Face-Alignment提取人脸关键点,将人脸分割为皮肤、眼睛、鼻子、眉毛、嘴巴、发际线和耳朵等多个部位,从中提取面部皮肤和五官的区域,并解析为2个预先定义的区域,即:人脸面部皮肤和五官(眼部、鼻部、嘴部)。人脸遮罩区域生成的流程如图4所示。

Figure 4 Generating face mask
首先,采用文献[23]中预先训练的面部解析器fp获取人脸皮肤遮罩Mskin和五官特征的遮罩Mkey,如式(7)所示:
Mskin,Mkey=fp(I)
(7)
其中,I为人脸图像,遮罩Mskin和Mkey的像素取值在0~1。
其次,将第1步生成的遮罩作为人脸图像的预定模板,将模板应用到人脸图像上得到皮肤Iskin和五官特征Ikey,如式(8)~式(11)所示:
Iskin=I×Mskin
(8)
Ikey=I×Mkey
(9)
(10)
(11)

由于遮罩生成模块的引入,对生成器引入新的约束,即全局约束和区域约束。
全局约束指面部皮肤生成部分的约束条件,在式(5)的基础上修改为:
LG2_1=(D1(mask1(Igen))-1)2
(12)
其中,D1表示鉴别器,mask1表示针对人脸生成皮肤的遮罩。
区域约束指面部五官生成部分的约束条件,在式(5)的基础上修改为:
LG2_2=(D2(mask2(Igen))-1)2
(13)
其中,mask2表示针对人脸生成面部五官的遮罩,比如人的眼部、鼻部和嘴部等。
最后在生成器生成的数据对与输入数据对之间引入L1损失,使生成的数据对按照预定的方向生成,同理,将式(6)修改为:
LG3=L1_Loss(mask1(I),mask1(Igen))+
L1_Loss(mask2(I),mask2(Igen))
(14)
综上,整个生成器网络损失定义如式(15)所示:
LG=LG1+LG2_1+LG2_2+LG3
(15)
2.5 鉴别器网络设计
多对抗性鉴别网络包括主鉴别器和辅助鉴别器,主鉴别器D1用于约束生成器,进行人脸图像中面部皮肤的鉴别;辅助鉴别器D2作为区域鉴别器,用于改进人脸五官细节的生成,进行人脸图像中面部五官的鉴别。鉴别器网络的具体架构如图5所示。将人脸遮罩图像经过下采样映射为一个二值化张量,该特征张量每个位置的值代表了该像素点是否为生成器生成,而不是使用单一的数值代表整幅图像是否是生成器生成的人脸图像。

Figure 5 Architecture of mul-adversarial discrimination network
鉴别器网络在整个架构中的作用如下:将真实人脸、伪造人脸、重构真实人脸和拟合伪造人脸的遮罩图像输入到主鉴别器和辅助鉴别器中进行评分,得到人脸图像的初始得分。在设计的鉴别器中使用人脸的关键点产生皮肤和五官上的遮罩,2个鉴别器独立处理皮肤和五官的细节问题,使生成器在学习过程中除了注意全局的特征外,更注意皮肤和五官上的细节。这种设计进一步强化了伪造人脸图像五官和皮肤上的特征,便于人脸的活体检测,并且根据人脸图像的得分对初始对抗网络进行训练后可以得到更加准确的伪造痕迹元素和特征图,进而得到更加准确的人脸图像的最终得分,提高了人脸活体检测的准确率。
主鉴别器D1将生成的人脸图像皮肤遮罩和真实的图像的皮肤遮罩送入鉴别器,将鉴别器的结果反馈给生成器,主鉴别器的目的是使该损失尽可能地大,其损失函数定义如式(16)所示:
LD1=(1-D1(mask1(I)))2+
(16)
辅助鉴别器D2是对生成器的又一约束,针对人脸面部五官的遮罩,比如眼部、鼻部和嘴部,鉴别器对生成的人脸图像与真实人脸图进行评价,其损失函数定义如式(17)所示:
LD2=(1-D2(mask2(I)))2+
(17)
整个鉴别器的整体损失函数定义为上述2个损失函数之和,如式(18)所示:
LD=LD1+LD2
(18)
3 实验与结果分析
3.1 实验设置
3.1.1 数据集
本文在OULU-NPU[24]、Idiap Replay-Attack[25]和NUAA(Nanjing University of Aeronautics and Astronautics)[26]3个数据集上进行实验。OULU-NPU数据集包括纸质打印照片攻击和视频回放攻击,其数据在3种光照环境、2种攻击表示工具、6种数据采集设备(即6个不同的智能手机前置摄像头,如三星GalaxyS6edge、HTCDesireEYE、魅族X5、华硕Zenfone Selfie、索尼XPERIAC5UltraDual和OPPON3)下完成采集。Idiap Replay-Attack数据集包括照片和视频2种欺骗攻击,具体可细分为纸质打印照片、移动手机屏幕显示照片/视频、高清屏幕显示照片/视频。上述攻击欺骗根据检测设备是否固定分为2种,分别是手持设备和固定设备,根据光照环境又分为均匀光照背景和逆光照,综上,该数据集的攻击欺骗为5×2×2=20种。NUAA数据集包含真实人脸图像和手持打印人脸照片的翻拍图像。测试时,本文遵循所有的测试方案,并与近几年最先进的模型进行比较。与之前的大多数工作类似,本文只使用上述数据集中的人脸区域进行训练和测试。
3.1.2 评价指标
本文采用2种标准指标对实验结果进行评价与比较:APCER、BPCER、ACER和AUC[27]。其中,APCER、BPCER、ACER描述给定一个预定阈值的性能,AUC描述分类器效果的好坏。
APCER(Attack Presentation Classification Error Rate)表示伪造人脸图像被当成真实人脸图像的概率。计算公式如式(19)所示:
APCER=FP/(TN+FP)
(19)
其中,FP(False Positive),即假的正样本,表示伪造人脸图像被当作真实人脸图像的数量;TN(True Negative)表示即真实的负样本数量。
BPCER(Bona fide Presentation Classification Error Rate)表示真实人脸图像被当作伪造人脸图像的概率。计算公式如式(20)所示:
BPCER=FN/(FN+TP)
(20)
其中,FN(False Negative)即假的负样本的数量,表示真实人脸图像被当作伪造人脸图像的数量。
ACER(Average Classification Error Rate)指的是平均分类错误率,即APCER和BPCER的平均。
AUC(Area Under Curve)指的是ROC曲线下的面积,横坐标为FPR,纵坐标为TPR,TPR即APCER。FPR计算公式如式(21)所示:
FPR=1-BPCER
(21)
3.1.3 实验参数设置
本文实验在NVIDIA GeForce RTX 3060,16 GB内存的实验环境下进行,在PyTorch框架中实现,初始学习速率为1e-5。总共训练60次迭代,批处理大小为8,并以按照3个轮次不更新损失的规律等比例降低学习率。
3.2 实验结果
3.2.1 OULU-NPU实验结果
OULU-NPU[24]是一种常用的人脸抗欺骗基准,该数据集包含4个评价实验,实验1是测试光照环境对模型的影响,实验2是测试攻击表示工具对模型的影响,实验3是测试检测设备对模型的影响,实验4是测试光照环境、攻击设备和数据采集设备对模型的影响。图6~图8展示了不同测试实验的可视化效果图,图中real代表真实人脸图像,gen-real代表线性重构模块从伪造人脸图像上重构的真实人脸图像,fake代表伪造人脸图像,trace代表从伪造人脸图像上解离出来的伪造痕迹。其中,图6a和图6b分别展示了在光照1和光照2下的检测效果图,从上至下,依次为在打印设备1上的纸质打印照片、打印设备2上的纸质打印照片、普通显示器上的回放视频以及高清设备上的回放视频。图7为本文模型在实验2中的检测效果图,其中,图7a分别表示在打印设备1和显示设备1上的测试结果,图7b分别表示在打印设备2和显示设备2上的测试结果。图8展示了本文模型在不同检测设备、光照环境、欺骗设备下的测试效果图,从上至下分别表示检测设备1~检测设备6的测试结果。图8a中的图像构成是,每2行为一组,共分3组,分别对应光照1~光照3,每组的第1行图像为高质量纸质照片,第2行图像为低质量纸质照片。同理,图8b中也有针对高清视频欺骗和普通视频欺骗之分。

Figure 6 OULU-NPU protocol 1 test renderings

Figure 7 OULU-NPU protocol 2 test renderings

Figure 8 Test renderings of OULU-NPU protocol 3 and 4
OULU-NPU数据集的评测结果如表1所示,表1中粗体表示错误率最低,即最优结果,-表示未找到数据。相对于STDN,本文模型在实验1和实验2上有明显改进,其中,实验1中本文模型的BPCER减少了77%,ACER减少了27%,实验2中的指标也相应明显下降,综合来看,本文模型抗光照干扰能力和抗欺骗设备噪声能力比其他对比模型更好。实验3结果表明,本文模型相对其他对比模型要差一些,具体细分检测结果如图9a所示,设备6的错误率明显高于其他设备,这是因为设备6的噪声相对明显,导致真实人脸图像被视为伪造人脸图像,错误率上升。由实验4结果可知,本文模型相对STDN有了明显改进,具体细分检测结果如图9b所示。由图9b可知,设备2、3、5的检测准确率相对较高,同理,设备6由于噪声过大,导致模型错误率上升。综上,本文模型在实验1中的结果相对文献[30]的要差一些,但是就整体错误率而言,本文模型在所有对比模型中达到了较优的水平。
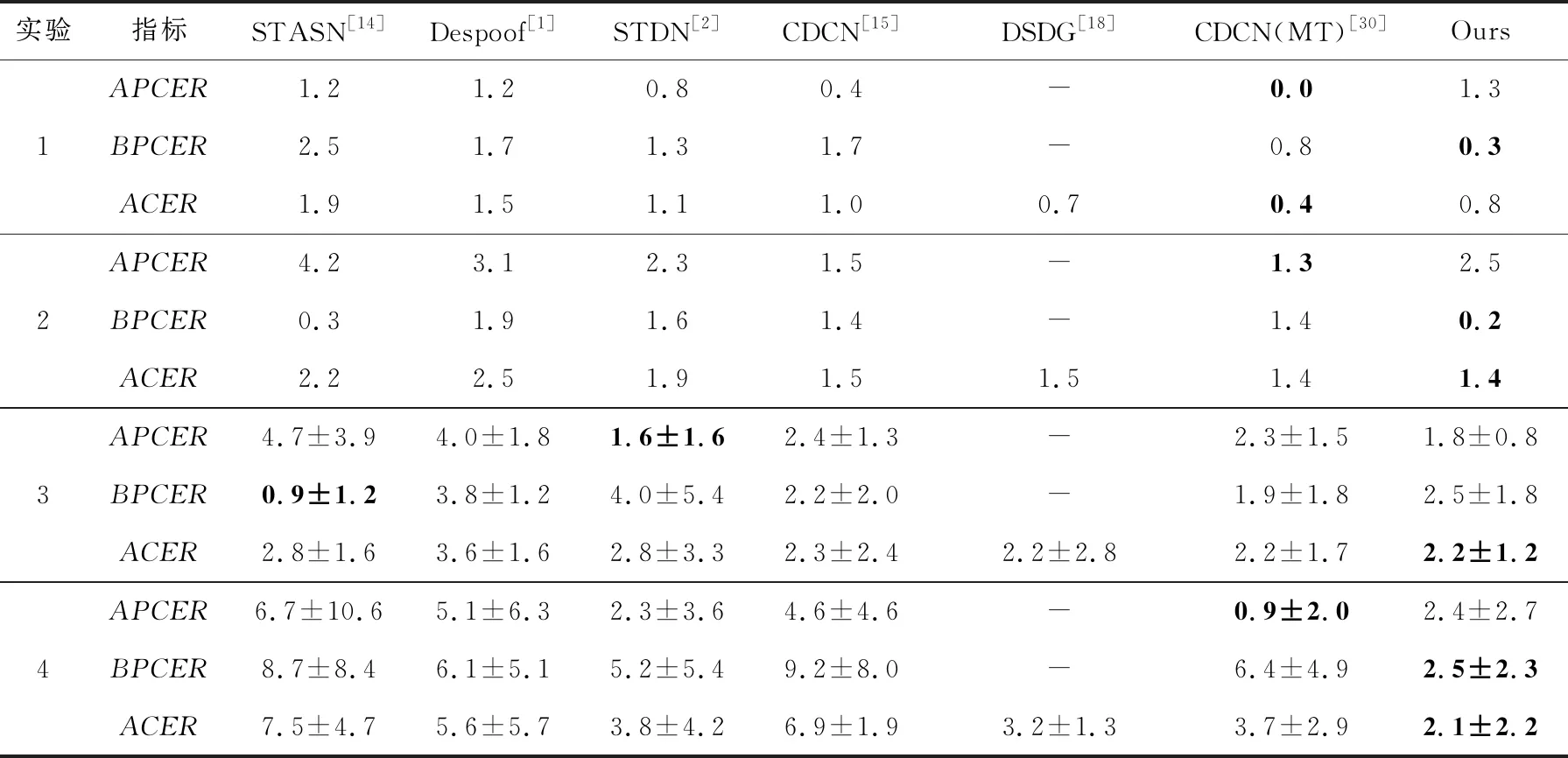
Table 1 Test results on OULU-NPU

Figure 9 Protocol 3 and Protocol 4 subdivided test results
3.2.2 Idiap Replay-Attack实验结果
本文在Idiap Replay-Attack数据集上的18种实验中抽取3个实验,即打印照片攻击、数字照片攻击和视频攻击。具体实验测试结果如表2所示,表中加粗数据为最优结果,-为未找到数据。Idiap Replay-Attack数据集测试结果的效果图如图10所示。图10中由上至下分别表示纸质打印照片、数字照片、视频攻击,图10a和图10b分别表示录入数据的设备是手持的和固定角度的。

Table 2 Internal test results on Idiap Replay-Attack

Figure 10 Test renderings of Replay Attack
表2为Idiap Replay-Attack数据集上3种模型针对3种欺骗类型(纸质打印照片、数字照片、视频)的AUC值,AUC值指示分类器效果的好坏,AUC值越高,说明分类器效果越好。由表2中数据可知,本文模型在众多模型中达到了较好的效果,与最佳模型的效果持平。
3.2.3 跨域活体检测实验结果
本节进行跨数据集测试,训练数据为OULU-NPU数据集,测试数据分别为NUAA数据集和Idiap Replay-Attack数据集,测试的错误率如表3所示,表中加粗数据为最优结果,-为未找到数据。NUAA数据集上测试结果的可视化如图11所示。

Table 3 Detection results across datasets

Figure 11 Test renderings on NUAA dataset
由表3中数据可知,在OULU-NPU数据集上训练的模型,在NUAA数据集上也可以达到较好的检测效果,相对而言,在Idiap Replay-Attack数据集上的测试效果较差一些,其中包括Liu等人[31]提出的特征生成和假设验证方法FGHV(Feature Generation and Hypothesis Verification)来实现人脸活体检测,首先使用特征生成模块生成特征,再使用假设验证模块判断该特征属于哪个分布;Wang等人[32]提出混合风格组装网络SSAN (Shuffled Style Assembly Network)以提高人脸活体检测的泛化能力,首先将不同的内容和风格进行组装生成风格化的特征空间,随后使用对比学习,强化与活体人脸相关的风格信息,弱化特定领域的风格信息,最终使用正确的表示集合来区分活体人脸与伪造人脸。由表3数据可知,本文模型比特征生成的模型相对较好,但是相对混合风格组装网络要差一些。这说明了该模型在已知欺骗类型的数据上的鲁棒性相对较好。
3.2.4 消融实验
本节在OULU-NPU数据集实验1上进行了消融实验,具体结果如表4所示,表中加粗数据为最优结果,-为未找到数据。本文以STDN为基准,分别对文中提出的皮肤遮罩模块STDN+mask1、五官遮罩模块STDN+mask2和自适应权重损失函数STDN+mask1+mask2+aw_loss进行消融实验。由表4数据可知,本文添加的遮罩模块对人脸活体检测的性能提升有一定帮助。
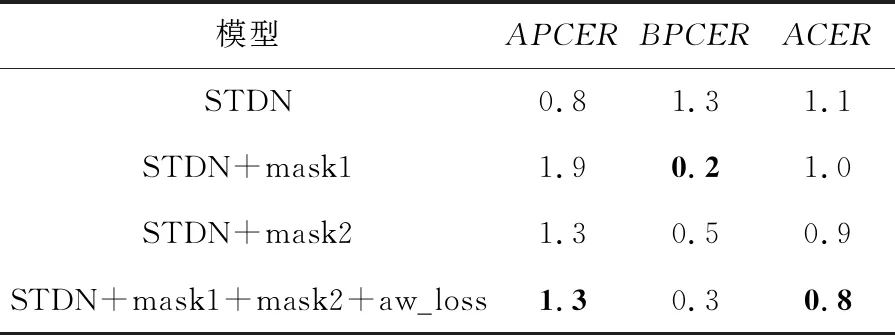
Table 4 Ablatoin experiment results
3.3 模型效率对比
模型对比分析主要从计算量(Flops)和模型参数量(Params)2个方面进行。本节对比了部分现有模型和本文模型的计算量和参数量。由表5结果可知,本文提出的模型(PyTorch平台)在CDCN模型(PyTorch平台)的基础上减少了计算量和参数量。但是,本文模型的参数量与计算量相对于STDN没有变化,这是由于本文模型并未改进STDN网络的生成器网络架构,在测试时仅使用生成器生成伪造痕迹进行人脸活体检测。
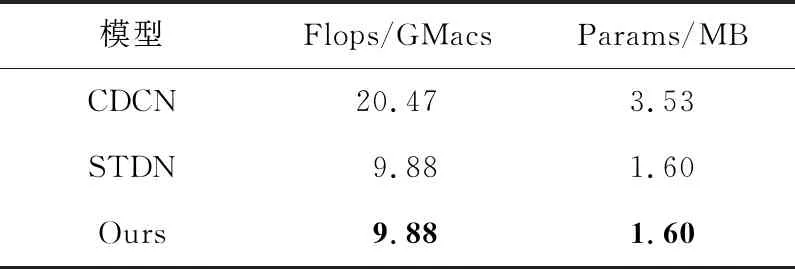
Table 5 Comparative analysis of models
4 结束语
本文提出基于多对抗性鉴别网络的人脸活体检测模型,根据面部皮肤及五官等人脸重要关键点生成人脸遮罩,构造鉴别器,以使解离效果更好,强化了对人脸皮肤和五官处的细节检测,并分离出伪造痕迹。该解纠缠表示网络不仅改善了已知和未知反欺骗的性能,而且为模型的决策提供了直观的依据。本文模型在OULU-NPU数据集上错误率显著降低,同时在Idiap Replay-Attack数据集上也达到了较好的检测效果。最后在3个数据集上进行跨域检测,验证了模型的可迁移性。但是,由对抗生成网络生成的图像往往存在一些不确定性,未来可在对抗网络中加入策略反馈机制,通过定位人脸图像上对检测结果有重大影响的敏感像素点来提取伪造痕迹,从而进一步提升活体检测能力。
猜你喜欢
通信学报(2022年10期)2023-01-09
肝博士(2021年1期)2021-03-29
华人时刊(2020年21期)2021-01-14
保健医苑(2020年1期)2020-07-27
国防科技大学学报(2019年4期)2019-07-29
小猕猴智力画刊(2019年3期)2019-04-19
系统工程与电子技术(2016年5期)2016-11-02
百科探秘·航空航天(2015年10期)2015-11-07
建筑设计管理(2014年6期)2014-02-28
飞碟探索(2013年2期)2013-08-13
