
面向微服务的制造执行系统关键技术研究*
2023-09-18 08:42:16李亚杰李昭楠
制造技术与机床 2023年9期
李亚杰 李昭楠
(河南科技大学机电工程学院,河南 洛阳 471003)
随着智能制造研究与应用的不断深入,制造执行系统作为连接企业计划层与控制层的纽带,在企业智能制造体系架构中的作用也显得更加重要。为了得到最好的应用效果,制造执行系统需要根据企业制造车间的个性化需求进行定制。随着客户个性化定制需求的不断增加,企业的生产组织模式、管理流程与生产过程也呈现出多样化、动态多变的特点,因此要求制造执行系统具有更加敏捷、灵活的动态配置与重构能力。
传统的MES 系统大多采用单体架构,系统功能之间耦合程度高,随着企业需求的不断变化,系统规模与复杂度不断增加,造成系统可扩展性差、变更周期长、成本高,在企业需求变更出现后难以快速对系统进行重构,造成企业现状与系统功能之间的脱节,影响系统的应用效果,甚至造成系统实施的失败。为了改善制造执行系统的可重构性,文献[1]提出了面向生产过程云服务的制造执行系统,采用面向服务的技术架构(service oriented architecture,SOA),将复杂的车间管理业务定义为松散耦合的服务组件,便于车间业务流程进行灵活、动态的配置与重构。文献[2]基于可重构流程模型和组件技术建立了可重构MES 流程模型,以提高MES 系统流程的可重构能力。文献[3]提出了一种面向MES 生命周期的模型驱动定制化方法来进行MES 系统的自动生成和持续改进,降低MES 实施和重构的复杂性。文献[4]针对具有高度自动化水平的制造系统提出了一种MES 定制化方法,将可变性指数作为评价生产系统有效性的参数来驱动MES 模型进行调整。文献[5]从底层的体系结构入手,建立了支持网络化制造的数控车间可插拔制造执行系统。文献[6]提出一种制造执行系统集成可重构的框架,并分别从业务实体、业务逻辑和系统间集成层研究了集成可重构实现方法。文献[7]针对制造执行系统扩展性问题,建立了基于工厂方法模式的可扩展MES 系统体系结构。以上研究为提高MES 的可重构性和可扩展性提供了解决思路,但仍无法从根本上避免采用单体架构造成的系统复杂度高、维护成本高、交付周期长等问题[8]。
微服务架构将大型软件系统拆分为多个可独立运行的服务,拆分后的微服务可以独立进行开发、测试、部署、重构,很大程度地降低了系统的耦合性[9],基于微服务架构的系统具有开发周期短、扩展性与复用性更好的优点[10],微服务架构的这种特性使其在系统开发中被广泛接受和应用[11-13]。因此,本文开展了面向微服务的制造执行系统研究,建立了面向微服务的制造执行系统架构,并提出了基于用例-数据访问关系模型的制造执行系统微服务划分方法,将用例和数据之间的访问关系作为微服务划分的依据,将制造执行系统划分为多个相互独立的微服务,便于在不影响系统运行的条件下进行系统功能的重构,以提高系统持续满足车间业务需求变化的能力,进而提升系统的应用效果和车间管理效率。
1 基于微服务的制造执行系统架构
基于微服务的制造执行系统架构如图1 所示。主要包括平台层、数据层、服务层、接口层、应用层和展示层。

图1 基于微服务的MES 系统架构
(1)展示层:展示层是MES 与用户进行交互的前端,主要负责接收用户的输入和操作指令,并将系统的运行结果展示给用户。
(2)应用层:应用层是系统提供给用户的功能,在应用层按照用户的业务流程将微服务封装为MES 的各个功能,在展示层接收到用户的输入和操作指令后通过调用应用层的功能实现对于不同业务的处理。
(3)接口层:接口层负责连接应用层和服务层,根据应用层中用户选择的不同操作通过接口调用对应的微服务进行处理,并将处理结果返回给应用层。
(4)服务层:服务层中封装了系统中包含的微服务,用户的业务逻辑主要反映在服务层中,负责按照用户指令进行数据查询与逻辑运算,并反馈处理结果,是系统的核心层。
(5)数据层:数据层中包含系统运行所需的数据库,为系统运行提供数据存储服务。
(6)平台层:平台层中包含系统运行所需的服务器、操作系统、数据库系统等软硬件条件。
在MES 的多层架构中,应用层实现对用户业务流程的封装和处理,服务层负责对数据的逻辑运算,接口层负责应用层和服务层之间的数据通信,通过这种分层划分解除业务流程和数据处理逻辑之间的耦合关系,当业务流程或业务逻辑发生变化时,只需要对应的重构业务层或服务层中受到影响的部分,不会对其他部分产生影响,降低系统重构的技术复杂度,便于对系统进行维护。
系统数据库分为业务系统构建数据库(图2)和业务数据库(图3)两部分。应用层的业务应用系统由各个微服务组合而成,它们之间的组成关系存储在业务系统构建数据库中,包括业务系统属性表和微服务表。业务系统属性表中存储各业务系统的信息,包括业务系统编号、业务系统名称和业务系统描述等。微服务表中存储系统各个微服务的信息,包括微服务编号、微服务名称、端口号和微服务描述等,微服务和业务系统之间的组成关系体现在这两张表的主外键关系上。
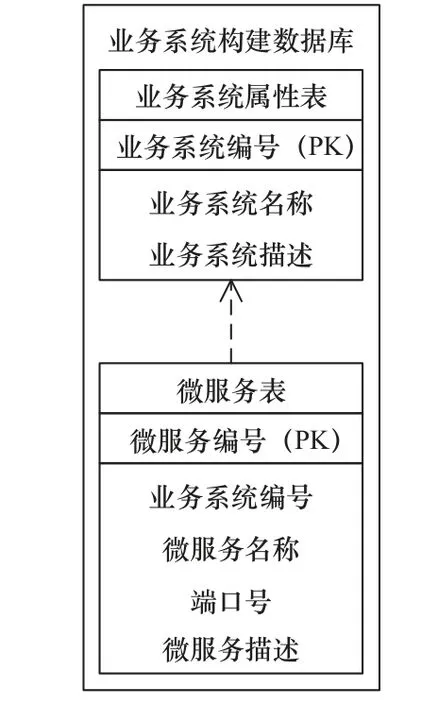
图2 业务系统构建数据库
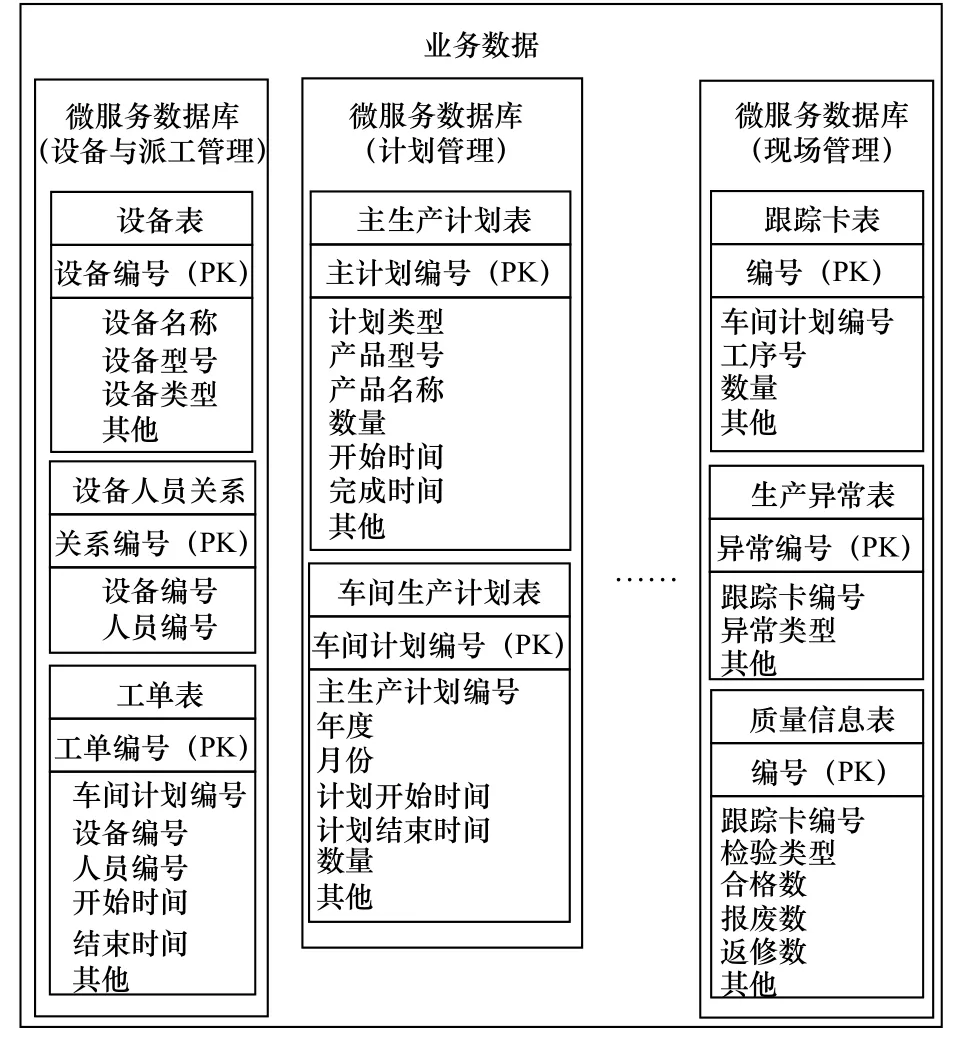
图3 业务数据库
业务数据库中存储业务执行过程中产生的数据。为了保证系统微服务的独立性,每个微服务在业务数据库中都对应于一个单独的数据库。例如在图3 中,将业务数据拆分为设备与派工、计划管理、现场管理等数据库供对应的微服务调用。
2 领域场景驱动的制造执行系统微服务划分技术
对于采用微服务架构的系统来说,微服务的粒度划分是否合适是最关键的因素之一[9],微服务粒度决定了系统微服务之间相互调用和通信的复杂度。目前大多数系统在进行微服务划分时依赖架构设计者的个人经验[14],受主观因素影响较大,并且面对大型系统时,微服务拆分效果较低且粒度划分合理性无法保证。
领域驱动设计倡导按照业务领域进行系统微服务划分,不同的业务领域之间使用独立的数据模型。制造执行系统作为一种数据库系统,其系统业务的实现最终都是围绕数据库实现的。在制造执行系统的系统设计阶段,用例图反映用户能够在系统中完成的操作,数据库结构模型反映用户执行业务过程中涉及的各类数据,通过对用例图和数据库表结构进行分析,能够得到系统的业务逻辑以及相互之间的数据调用关系。用例与数据表之间的关联关系对应于系统中的业务逻辑、功能与微服务之间的关系,对其进行分析之后能够得到系统的微服务划分结果。因此,本文建立了基于用例图和数据库表结构的MES 系统微服务划分方法,划分流程如图4 所示。
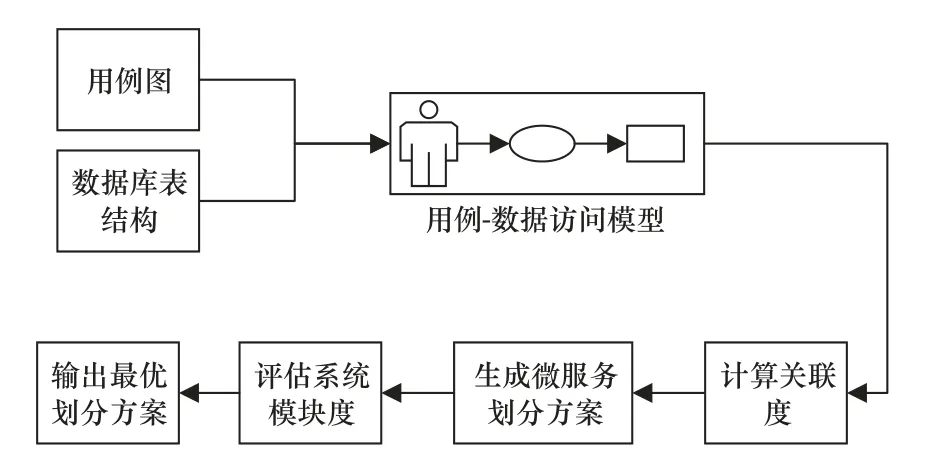
图4 微服务划分流程
步骤1:对用户进行调研,建立系统用例图和数据库表结构。
步骤2:分析用例和数据表之间的数据调用关系,建立用例数据访问模型。在系统中,当不同的用例操作同一个数据表时,虽然操作的类型与数据属性不同,但在最终实现时仅体现在前后端的接口程序中,对系统微服务的划分没有影响,因此本文在建立用例-数据访问模型时仅考虑用例对数据表的调用,不考虑数据表具体属性的调用。
步骤3:根据用例对数据表的数据调用类型,计算用例和数据表之间、数据表和数据表之间的关联关系。
步骤4:利用GN 算法生成微服务方案。
步骤5:评估微服务划分方案对应的MES 系统模块度,输出划分方案。
2.1 建立用例-数据访问模型
解析用例与数据表之间的访问关系,建立三元组W=(U,E,R),其中U 表示与数据表有关联关系的用例集合,E为数据表集合,R为用例-数据关系集合,例如Rm=(Ui,Ej,create)表示用例Ui和数据Ej存在名为create的调用关系。用例-数据访问模型如图5 所示,例如,对于用例U1和数据表E1之间通过一条边相连,这条边记为E1=(U1,E1,Delete)。

图5 用例-数据访问模型
建模过程如下:
步骤1:分析用例-数据关系图中的特征,建立数据表集合E 与用例集合U,每个用例与数据表都是模型中的节点。
步骤2:分析用例与数据表之间的调用关系与类型,对于每个用例,确定进行业务操作时与之关联的所有数据表,生成用例及与之关联数据表的边。
步骤3:依据节点与边的关联建立映射。对于图5 中任一边,由该边连接的两个节点作为此边的关联映射。
2.2 计算数据关联度
在用例-数据表关系图模型中数据表之间没有直接相连的边,但数据表能够被不同用例通过访问调用进行关联,数据关联度体现在用例与数据表的调用关系上。当数据表被一个用例同时调用时,表示这些数据表之间的关联度较高,会同时被操作,因此,在进行微服务划分时,关联度高的数据表更应该被划分到同一个微服务中以提高微服务之间的独立性,降低微服务之间的调用频率,降低系统的数据耦合程度和复杂度。
设用例-数据访问模型中共包含n个用例,m个数据表,Counti代表操作数据表Ei的用例数量,Countij代表同时操作数据表Ei和Ej的用例数量,则数据表Ei和Ej的关联度Sij等于Countij除以分别操作Ei和Ej的用例数量之和,即:
按照上述公式计算可得E中m个数据表两两之间的关联度,表现为一个m×m的关联度矩阵S,矩阵中第i行第j列的元素表示数据表Ei和Ej之间的关联度Sij,由上述公式可知Sij=Sji,矩阵对角线上的元素取值为0,表示当i=j,即Ei和Ej为同一个数据表时关联度为0。
2.3 微服务划分
矩阵S反映了用例-数据表关系图中的数据表之间的关联度,用例-数据访问模型中的R反映了用例与数据之间的关联关系权重,本文采用Girvan-Newman(G-N)算法对用例和数据表进行聚类,通过聚类运算后,具有更高关联度的用例和数据表会被聚到一个微服务中。G-N 算法的流程如下。
步骤1:根据用例-数据访问模型和关联矩阵S构建无向图T,T 的顶点为集合U 中的用例和集合E 中的数据表,当Tij=0 时表示顶点i和j之间没有边相连,当Tij=a时表示顶点i和j之间有一条权重为a的边相连。对于连接用例和数据表的边,其权重根据用例与数据表的访问关系类型确定,用例对于数据的操作包括创建(Create)、修改(Update)、查询(Query)、删除(Delete)4 种,对应业务执行过程中对于数据库操作的4 种形式,创建代表该用例执行过程中会生成一条或多条数据,修改表明用例执行过程中会对数据表的某些属性进行修改,查询表明用例执行过程中需要查询数据表的某些属性,删除表明用例执行过程中会删除一条或多条数据。为了区分这4 种关系所反映的用例与数据表之间的关联程度,按照这4 种关系对数据的影响,为其赋予不同的权重值,分别为创建1、修改0.75、删除0.5、查询0.25。对于连接数据表的边,其权重为关联矩阵中对应数据表之间的关联度值。
步骤2:计算所有边的边介数,用边介数除以对应边的权重得到边权比,找到边权比最大的边将其移除。
式中:Cij表示顶点i和j之间的边介数,αij表示连接顶点i和j的边的权重。
步骤3:保存划分结果,并计算模块度Q,模块度的计算方法见式(4)。
式中:eii表示社区i中所有边的权重与整个图中所有边权重的比值,ai表示与社区i顶点相连的所有边的权重与整个图中连接所有顶点的边的权重之间的比值。
步骤4:重复步骤2、3 直至所有的边都被移除,输出模块度最高的划分方案。
算法的核心代码如下:
3 应用实例
某轴承制造企业采用面向订单制造的管理模式,目前的生产管理采用人工和纸质文件管理的方式进行,生产计划采用纸质计划文件下达,每天由统计员统计现场完工情况,并逐级向上反馈,计划的变更由计划员口头通知,生产管理的规范性较差,生产计划的科学性不强,现场生产状态反馈不及时,难以实时、准确地获取订单的生产情况,延迟交付时有发生。在此情况下,企业开展了制造执行系统建设,通过调研分析,建立了图6 所示的用例-数据访问关系图(计划和现场管理部分)。

图6 用例-数据访问关系图
根据用例与数据表之间的关系,计算数据表之间的关联度,建立关联度矩阵:
算法的模块度迭代过程如图7 所示,算法输出结果见表1。

表1 微服务划分结果
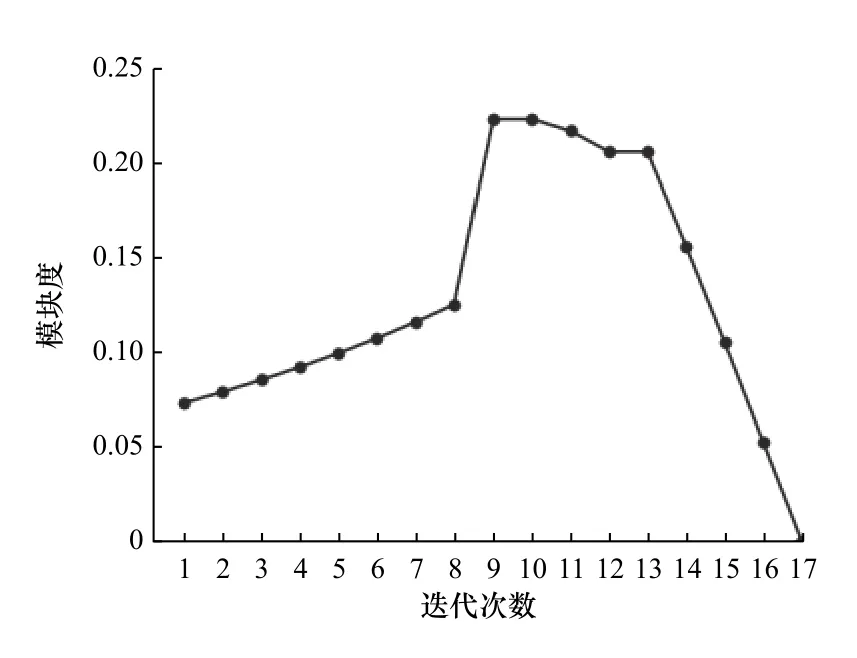
图7 模块度迭代曲线
根据算法计算结果,可将图6 划分为3 个微服务。至此,基于系统设计阶段建立的用例图和数据表结构,通过用例-数据访问关系驱动的划分方法获得了模块度最高的MES 系统微服务划分结果,可以为开发人员进行微服务划分提供参考。
4 结语
通过建立基于微服务的多层制造执行系统架构,降低制造执行系统的耦合性和复杂度,便于对系统进行维护。通过领域场景驱动的微服务划分技术,利用用例-数据表访问关系图进行分析,得到系统数据表之间的关联度,利用G-N 算法进行微服务划分,得到模块度最高的系统微服务划分方案,解决传统单体架构带来的重构和扩展困难的问题,提高制造执行系统的可重构性和可维护性,为制造执行系统快速响应业务重构需求变化提供支撑。
猜你喜欢
科学与信息化(2021年12期)2021-12-27 01:39:02
党员生活(2020年2期)2020-04-17 09:56:30
铁道通信信号(2019年11期)2019-05-21 03:05:46
铁道通信信号(2018年10期)2018-12-06 09:34:56
出土文献与古文字研究(2018年0期)2018-11-04 00:42:00
科技传播(2017年22期)2018-01-10 00:29:07
中小企业管理与科技·下旬刊(2017年8期)2017-09-13 18:58:33
中国石油企业(2014年4期)2014-11-30 06:13:06
计算技术与自动化(2014年3期)2014-10-28 23:40:34
河南科技(2014年24期)2014-02-27 14:19:25
