
基于无监督学习的多语言神经机器翻译模型研究
2023-09-15 01:56陈驰
数字通信世界 2023年8期
陈 驰
(北京七彩拇指科技有限公司,北京 100079)
1 无监督学习的多语言神经机器翻译模型研究现状
Transformer全新模型结构于2017年提出,其不再依赖循环和卷积两种神经网络,而是应用自注意力机制,提升了机器翻译的性能。为解决神经机器翻译存在的缺点,提供了研究单语数据训练机器翻译模型的新思路。2017年,行业专家通过无监督方法的应用完成了跨语言嵌入,训练后获得了词对词模型,在此基础上,通过降噪处理和反向翻译方式,实现了伪平行语料的生成,并通过训练得到结果。随后在2018年,相关专家学者依据前期工作,将无监督神经机器翻译过程总结为三个步骤(也称三项原则):①词对词模型初始化;②基于单语语料,训练源语言模型、目标语言模型,在训练中采用降噪自编码器方式;③转换无监督,使之成为有监督形式,在转换过程中采用反向翻译方法。由于不同语言的词汇不同,语言结构和语法却类似,所以应用多任务学习策略,对无监督的多语言神经机器翻译进行训练,其目的在于学习不同目标语言中有价值的语义信息、结构信息[1]。
2 基于无监督学习的多语言神经机器翻译模型的研究
2.1 模型构建
下面以Transformer模型结构为基础展开研究,通过这一模型,为各类语言建立编码器和解码器,实现部分参数共享,并结合上述三项原则,在三种语言之间构建训练任务,即英语、德语、法语,进而得到训练模型。
2.1.1 Transformer架构
Transformer并不依赖循环和卷积两种神经网络,而是通过自注意力机制,实现端到端的神经机器翻译,这是Transformer的关键特点。所谓自注意力机制,指的是对句子中的每个词及其他所有词进行注意力计算,作用在于对句子中的依赖关系加以学习,以此获取句子内部结构。在Transformer架构中,无论是编码器,还是解码器,都是多层网络结构且包含诸多相同层。各子层都应用残差方式进行连接。
2.1.2 双语单任务无监督神经机器翻译模型
在这一模型训练过程中,仅应用Transformer结合三项原则对单个训练任务进行训练,这种单个任务为英语→法语、英语→德语以及德语→法语中的其中一种。在研究中,源语言用S表示,目标语言用T表示,源语言单语训练出的语言模型用Ps表示,目标语言单语训练出的语言模型用Pt表示,源语言到目标语言翻译模型的预测概率用Ps→t表示,目标语言到源语言翻译模型的预测概率用Pt→s表示。无监督神经机器翻译过程主要包括以下三个环节。
(1)初始化。模型的初始化方式有两种:①基于Word2vec对两种语言的词向量进行单独训练,进而通过变换矩阵学习,在相同潜在空间中映射两种语言的词向量,以此得到具备较高精确度的双语词表;②使用字单元,即单词的字节对编码,这种方式不仅能减小词表大小,还能清除翻译中存在的未知问题[2]。
(2)语言模型。在双语单任务无监督神经翻译模型中,需要对语言模型降噪自编码器最小损失函数予以明确,即:
从本质上讲,语言模型训练过程是将噪声加入处理后的句子C(x)作为源端输入句子,而目标端输入句子则为原始句子x,进而以[C(x),x]为平行句子对进行训练。
(3)反向翻译。在这一过程中以伪平行句对为平行句对进行训练,损失函数公式为:
在反向翻译过程中,主要以[u*(y),y]和[u*(x),x]为平行句对进行训练,转换无监督问题,使之成为有监督问题。而语言模型和反向翻译环节反复迭代的过程,为双语单任务无监督神经机器翻译模型训练的过程。
2.1.3 多语言多任务无监督神经机器翻译模型
这一模型是基于Transformer架构,并结合前文所讲三项原则,对多任务训练后得到的模型[3]。多语言多任务无监督神经机器翻译模型主要由编码器、解码器、生成对抗网络以及潜在空间四部分组成。其中,编码器和解码器内部都包括四个子层,并分别共享编码器、解码器的后三层参数和前三层参数。为使共享潜在空间的作用得到强化,通过生成对抗网络的训练,针对不同语言所对应的编码器建立不同任务,其目的是对编码语言的所属类别进行预测,进而基于最小化交叉熵损失函数实现优化,即:
式中,EX(S’)指的是通过语言X编码器对当前编码句子S’进行预测后得到的结果,而当前编码的句子可能源于源语言,也可能源于目标语言;θD表示生成对抗网络的参数。为对这一生成对抗网络进行训练,还要优化训练编码器。
2.2 实验设置
本文针对英语、法语、德语三种语言之间的无监督神经机器翻译进行实验,并利用评测标准双语互译评估值对实验的翻译性能予以评估。
(1)在实验训练集的选择上,抽取WMT2007~2010语料库中三种语言的单语句子各1 000万行;在开发集的选择上,采用数据集newstest 2012中的德语↔英语、英语↔法语以及德语↔法语任务;在测试集的选择上,采用数据集newstest2013中的德语↔英语、英语↔法语以及德语↔法语任务。
(2)实验优化器选用Adam,设置失活率为0.1,设置单词维度、最大句子长度分别为512、175。在句子超过175个单词时,会截取超出部分,设置训练步长为35 000,其他参数依据Transformer模型默认参数进行设置。
(3)在三种语言翻译模型中进行三种语言的词表共享,并将BPE操作数设置为85 000,基于fastText工具的应用,基于子词化的训练集进行跨语言词向量学习训练。
(4)设置对比实验,在以往双语单任务无监督神经机器翻译模型中,对两种语言词表进行共享,并将BPE操作数设置为60 000,其他参数依据多任务无监督神经机器翻译模型进行设置。
2.3 实验结果
单任务、多任务无监督神经机器翻译模型在测试集上的翻译性能如表1所示。从表1中数据可知,虽然多任务无监督神经机器翻译模型在四项翻译任务上得到显著提升,但提升效果存在差异性。在英语→德语和德语→英语这两项翻译任务上,测试结果BLFU提升程度较小;但在德语→法语和法语→德语这两项翻译任务上,测试结果BLFU提升程度较大;而在英语→法语和法语→英语这两项翻译任务上,多任务无监督神经机器翻译模型的翻译性能相较于单任务模型有所下降。因此,在p为0.01显著性测试中,本研究模型在四项翻译任务上翻译性能良好,即英语→德语、德语→英语、德语→法语、法语→德语[4]。
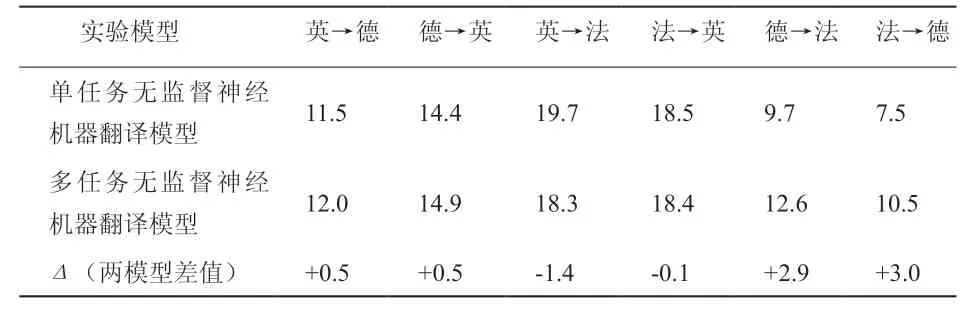
表1 两种模型翻译性能比较
2.4 实验分析
在该多任务无监督神经机器翻译模型中,需要共享多种语言的词表,所以关键在于合理选择词表大小,基于此,文章多次开展实验进行比对,实验结果如表2所示。
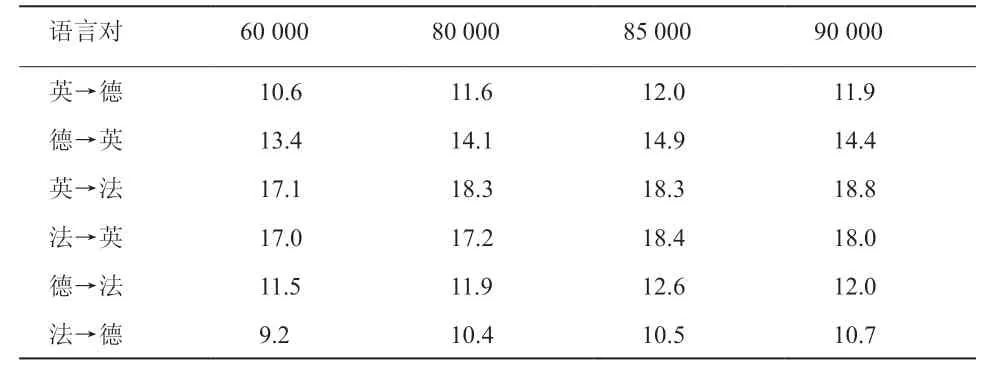
表2 不同词表大小实验结果对比
从表2中数据可知,在85 000和90 000的BPE操作数设置下,所获得的实验结果较好,但两组实验结果BLEU值相差较小。而且在部分语言对中,BPE操作数设置为90 000时的BLEU值比设置成85 000时的BLEU更低。因此,加大词表大小不能显著提升试验结果,在该模型中,最终设置BPE操作数为85 000。
为直观地对比翻译性能和训练速度,文章以统计方式汇总了实验中需要训练的各项参数。通过统计结果可知,多语言多任务翻译任务参数数量是双语单任务翻译任务参数数量的1.3倍左右,两者总参数分别为1.3×108和1.7×108,数值远远小于六个翻译任务单独训练的参数总和。与单任务无监督神经机器翻译相比,多任务无监督神经机器翻译训练时长缩短了一半左右。为直观对比翻译性能和训练速度,针对两种模型在翻译效果变化最为显著的德语→法语和法语→德语任务,利用折线图呈现两种模型效果,如图1所示。
从实验结果可知:①多任务无监督神经机器翻译确实能改善翻译性能,但针对不同种类语言的翻译任务,翻译效果存在差异性。②针对本身具备较好翻译效果的语言种类,如果利用多语言多任务无监督神经机器翻译模型进行翻译,提升翻译效果并不乐观,甚至会产生反向作用;而针对本身具备较差翻译效果的语言种类,如果利用多语言多任务无监督神经机器翻译模型进行翻译,可能会获得显著效果,出现这一结果的原因是训练数据采样对低资源语言对更有利所致。③多语言无监督神经机器翻译可同时建立多种语言的翻译任务,从而显著减少训练所需要的总时长[5]。
3 结束语
为解决神经机器翻译存在的缺点,文章主要探究基于无监督学习的多语言神经机器翻译模型。通过分析多任务学习在无监督神经机器翻译中的应用,并针对部分语言提出了能提升翻译性能的训练模型,在联合训练多个训练任务的基础上,让源语言在向目标语言的翻译过程中学习第三种语言单语语料中有价值的语义信息和结构信息。本文研究的基于无监督学习的多语言神经机器翻译模型,不仅能显著提升翻译性能,还能在多种语言对的翻译中有效缩短训练时长。■
猜你喜欢
天津外国语大学学报(2020年1期)2020-03-25
中国生物医学工程学报(2019年6期)2019-07-16
文化交流(2019年1期)2019-01-11
池州学院学报(2016年2期)2016-12-01
英语知识(2016年1期)2016-11-11
自动化学报(2016年3期)2016-08-23
外语教学理论与实践(2016年4期)2016-06-11
电测与仪表(2016年5期)2016-04-22
外语学刊(2016年4期)2016-01-23
环球时报(2015-02-09)2015-02-09
