
MMRGait-1.0:多视角多穿着条件下的雷达时频谱图步态识别数据集
2023-09-15 01:37:48陈晓阳薛世鲲
雷达学报 2023年4期
杜 兰 陈晓阳 石 钰 薛世鲲 解 蒙
(西安电子科技大学雷达信号处理国家重点实验室 西安 710071)
1 引言
步态识别是一种新兴的生物识别技术,旨在通过人体行走特点的不同对人体的身份进行识别[1]。相比于指纹识别、虹膜识别等传统的生物识别技术,步态识别具有非合作、远距离、不易伪装等优点,可用于智能门禁、安防监控、刑侦监测等领域,具有十分广阔的应用前景[2]。
近年来,由于深度学习的成熟发展和大量光学步态识别数据集的支撑,基于光学传感器的步态识别方法相关研究取得了有效的进展。然而,光学传感器易受天气和光线条件影响,且采集的图像或视频存在隐私泄露的风险。与光学传感器相比,雷达通过发射电磁波的方式来探测和感知目标,可以有效防止隐私泄露,同时雷达可以在不同的天气和光线条件下工作,具有较强的环境鲁棒性[3]。因此,基于雷达的步态识别方法具有非常高的实际应用价值,目前已受到广泛关注[4-8]。
人在行走时,人体各个部位的微运动会在雷达回波信号上引起频率调制产生微多普勒信号[9]。由于每个人行走的姿态、方式不同,微多普勒信号中包含的步态信息也会有所差异。对微多普勒信号进行时频分析得到的时频谱图能够反映人体丰富的步态微多普勒信息,因此利用时频谱图进行步态识别是一种十分有前景的处理方法。传统的基于雷达的步态识别方法通常使用手动提取特征的方式进行识别,识别过程一般分为两步:(1)从时频谱图中提取躯干和四肢运动周期、多普勒展宽等特征;(2)将提取到的特征输入到支持向量机、决策树等传统分类器完成识别。然而,此类方法非常依赖先验知识,计算复杂度较高且泛化性较差,通常难以获得满意的识别效果[10]。
近年来,深度学习技术在基于雷达的步态识别领域逐渐兴起,与传统的基于手动提取特征的方法相比,基于深度学习的方法可以自动地从时频谱图中提取具有鉴别力的步态特征,识别性能得到了极大的提升[11,12]。目前已有许多学者对基于时频谱图的步态识别问题展开了相关研究,南京航空航天大学的Cao等人[4]首次提出了一种基于AlexNet卷积神经网络的步态识别方法,在采集的20人数据集上达到了较好的识别效果。意大利贝内文托大学的Addabbo等人[11]利用时序卷积神经网络对步态时序信息进行建模,并在采集的5人数据集上验证了所提方法的有效性。Doherty等人[12]使用空间注意力和通道注意力机制增强特征表示以获取更具判别力的步态特征,所提方法在39人数据集上达到了较高的识别性能。天津大学的Lang等人[5]设计了一种动作分类与步态识别的多任务模型,并在采集的15人数据集上验证了模型的有效性。Yang等人[13]使用多尺度特征融合策略融合了网络不同层提取到的步态信息,在15人的数据集上达到了较高的识别准确率。复旦大学的Xia等人[14]使用Inception模块以及残差模块搭建了识别网络,并取得了较好的识别效果。上述工作证明了深度学习技术应用于雷达步态识别领域的可行性,推动了雷达在步态识别领域的发展。然而,上述研究仅局限于分类任务,即训练集和测试集中人的身份必须一致,无法对训练集中未出现的身份进行有效识别,这限制了基于雷达的步态识别在真实世界中的应用。
在真实世界中,步态识别通常被认为是一项检索任务[15],即给定一个查询样本,步态识别模型需要从步态样本库中检索出与查询样本匹配度最高的样本并赋予身份标签。与基于分类任务的步态识别方法相比,基于检索任务的步态识别方法具有以下特点:(1)检索任务不要求训练集和测试集中人员的身份相同,因此离线训练的步态识别系统可以直接部署到新场景中;(2)当新身份的人出现时,只需要更新样本库而无需重新训练模型。
基于检索任务的步态识别模型通过对比不同样本在特征空间中距离的远近来衡量样本之间的匹配度,距离越近则样本之间的匹配度越高。检索任务模型的训练需要足够多身份数目的样本支撑,以保证模型能够学习到将相同身份样本之间的距离拉近、不同身份样本之间的距离拉远的能力,使相同身份样本之间的匹配度最高。同时,在基于检索任务的步态识别中,训练集和测试集中人的身份通常是不相同的,这对数据集中人的身份数目提出了更高的要求。然而,现有基于雷达的步态识别研究大多使用私有时频谱图数据集进行实验,这些数据集中人员的数目通常较少,无法满足检索任务对数据量的需求。由于数据采集的时间成本和人力成本较大,目前暂时没有人员数目充足的雷达时频谱图步态识别数据集公开,因此基于检索任务的雷达步态识别仍然是一个亟待研究的领域。
为了填补基于检索任务的雷达时频谱图步态识别数据集的空缺,并为相关研究提供数据支撑,本文公开了一个121人的大型雷达步态识别时频谱图数据集。考虑到毫米波雷达具有较高的分辨率以及较低的功耗,且容易在实际应用中部署,本文选择毫米波雷达作为传感器来获取步态数据。同时考虑到在真实世界中,不同的行走视角[16]以及不同的穿着条件[17]会导致人体微多普勒特征的变化继而影响到步态识别模型的性能,因此,我们采集的数据包含了受试者在多种穿着条件下沿雷达不同视角行走的情况。此外,本文提出一种基于检索任务的雷达步态识别方法,并在公布数据集上评估了在多视角、跨视角以及相同穿着条件、跨穿着条件下的识别性能,实验结果可以作为基准性能指标,该数据集已可通过《雷达学报》官网的相关链接(https://radars.ac.cn/web/data/getData?newsColumnId=c 2cae1d9-521f-444e-ad1e-f009bf7b9acc)免费下载使用,供更多学者在此数据集上开展进一步研究。
2 MMRGait-1.0数据集信息
2.1 毫米波雷达简介
本文使用德州仪器(Texas Instruments,TI)开发的77 GHz调频连续波(Frequency-Modulated Continuous-Wave,FMCW)雷达AWR 1843[18]采集原始的人体雷达回波数据。该雷达采用低功耗的COMS工艺,以较小的尺寸实现了极高的集成度,同时该雷达拥有3个发射天线和4个接收天线,在方位维和俯仰维上具有一定的角度分辨率,雷达天线阵列分布如图1所示。

图1 毫米波雷达天线阵列分布图Fig.1 Antenna array distribution of millimeter-wave radar
毫米波雷达的天线配置为1发4收,雷达发射波形为线性调频连续波,其中单个线性调频信号又被称为Chirp信号。发射波形的具体参数配置如表1所示。在此配置下,该雷达可以达到0.097 m/s的速度分辨率,较高的速度分辨率容易获取丰富的人体步态信息。

表1 雷达发射波形参数配置Tab.1 Parameter configurations of the radar transmitting waveform
2.2 数据采集设置
步态数据的采集平台和室内采集场景如图2所示,图2(a)所示毫米波雷达用于采集步态数据,光学相机用于记录采集场景。本数据集中共包含121位受试者的步态数据,其中,男性72人,年龄21~26岁,身高163~187 cm,体重55~100 kg;女性49人,年龄21~27岁,身高在155~176 cm,体重在40~67 kg。本文采集了受试者在3种穿着条件下沿8个不同视角行走的数据,行走视角示意图如图3所示。我们规定行走轨迹与雷达法线方向的夹角为行走视角,8个视角分别为0º,30º,45º,60º,90º,300º,315º,330º。图4展示了3种穿着条件的示例,3种穿着条件分别为正常穿着、穿大衣和挎包。正常穿着行走时,人体的各个部位正常运动且没有被物体遮挡;挎包行走时,一只手需要扶包,有一条胳膊无法正常摆动;穿大衣行走时,大腿上半部分被遮挡,且大衣的下摆有无规则摆动。

图2 数据采集平台和室内采集场景Fig.2 Data collection platform and indoor collection scene
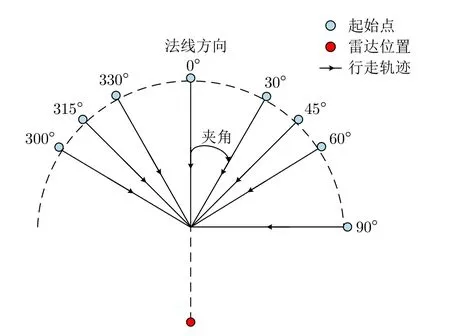
图3 行走视角示意图Fig.3 The view of walking

图4 3种穿着条件示例Fig.4 Examples of three wearing conditions
本数据集中每位受试者共采集80组数据,每组数据时长为2.4 s。具体来说,8个行走视角每个视角各采集10组,其中,6组为正常穿着,2组为穿大衣,2组为挎包。121位受试者共采集9680组数据。
2.3 信号处理流程
本文使用1发4收的天线配置采集数据,因此每组数据包含4个通道的原始雷达回波信号,对雷达回波信号进行信号处理可以得到时频谱图,具体的信号处理流程如图5所示。首先我们将4个通道的雷达回波信号进行非相干积累,其次对积累后的信号进行距离维快速傅里叶变换(Fast Fourier Transform,FFT)得到时间-距离图,然后使用高通滤波器滤除静止杂波,最后选取时间-距离图中人体行走时所在的距离单元(0~9.375 m),对每个距离单元的信号进行短时傅里叶变换(Short-Time Fourier Transform,STFT)并求和得到最终的时频谱图,时频谱图可以反映人体目标各个散射点能量强度和频率随时间变化的过程[19]。

图5 信号处理流程Fig.5 Signal processing flow
短时傅里叶变换是一种常用的时频分析方法,其通过滑动窗口的方式对时间窗内的信号做FFT得到时频谱图,对信号s(t)做短时傅里叶变换的表达式如下:
其中,h(·)表示信号的汉明窗(Hamming)窗函数,t表示时间维,ω表示频率维。根据经验,本文将短时傅里叶变换的采样点数设置为512,汉明窗窗长设置为0.047 s,滑窗的重叠率设置为80%。图6展示了同一人在3种穿着条件下沿8个视角行走的2.4 s时频谱图,横坐标表示时间,为直观展示人体的行走速度,将纵坐标的频率转换为速度,速度范围为-6.23~3.12 m/s。当穿着条件相同时,不同行走视角的时频谱图反映的微多普勒信息有所差异,视角从0º变换到90º的过程中,时频谱图中速度维的延展逐渐变小,微多普勒信息逐渐变少。当行走视角相同时,不相同穿着条件下的时频谱图也有所不同:挎包行走时,由于一条胳膊无法正常摆动,其时频谱图相较于正常穿着的时频谱图缺失了部分微多普勒信息。穿大衣时,由于大腿上半部分被遮挡,且大衣下摆的不规则摆动会对回波信号产生额外的频率调制,因此穿大衣行走的时频谱图相较于正常穿着行走的时频谱图也会有所差异。

图6 8种行走视角、3种穿着条件下的时频谱图Fig.6 Time-frequency spectrograms for eight walking views and three wearing conditions
2.4 数据集格式
本数据集包含时频谱图的矩阵和图片两种格式的数据,为方便数据集的使用,我们对数据进行了统一的命名,格式为AAA-BB-CC-DDD,其中,AAA表示受试者的ID,取值范围为001~121;BB表示3种穿着条件,分别为NM(正常)、BG(挎包)、CT(穿大衣);CC表示在BB穿着条件下采集的第CC组数据。在NM条件下采集6组数据,因此CC取值范围为01~06,在BG条件下采集2组数据,CC取值为01,02,在CT条件下采集2组数据,CC取值为01,02;DDD表示行走的视角,分别为000,030,045,060,090,300,315,330。矩阵数据的后缀为“.mat”,每个矩阵的大小为192×246,总样本数为9680。图片数据的后缀为“.jpg”,每张图片的尺寸为477像素×429像素,总样本数为9680。以矩阵格式的数据为例,具体的数据集结构如图7所示。

图7 具体数据集结构示意图Fig.7 Structure of the dataset
3 基于检索任务的雷达步态识别方法
现有的大多数雷达步态识别方法仅局限于分类任务,只能对训练集中出现过的身份进行识别,新身份的样本会被错误判断为训练集中的某一个身份,因此这种基于分类任务的雷达步态识别方法在实际应用场景中十分受限。相较于基于分类任务的雷达步态识别方法,基于检索任务的雷达步态识别方法更适用于实际应用场景,其流程如图8所示,检索任务遵循“受试者独立”准则,即测试集中人员身份未在训练集中出现,测试集中样本的身份均为“新身份”[2]。在特征提取模型的训练阶段,需要身份数目足够多的样本支撑,使模型能够学习到将相同身份样本之间的距离拉近、不同身份样本之间的距离推远的能力。在测试阶段,测试集被进一步分为查询样本与样本库,其中,查询样本为待识别身份的样本,样本库中的样本为身份已知的模板样本。将给定查询样本与样本库中所有样本分别输入到特征提取模型中得到各自的特征,计算该查询样本特征与样本库中所有样本特征之间的距离,将样本库中与查询样本特征距离最近的样本的身份赋予该查询样本,不同样本在特征空间中距离的远近可以衡量样本之间的匹配度,距离越近则样本之间的匹配度越高。
基于检索任务的步态识别方法可以应用到门禁系统、犯罪追踪等领域,以公司的门禁系统为例,步态识别系统需要事先采集该公司所有员工的步态数据作为样本库,每当员工进入公司时,步态识别系统会采集员工此时的步态数据作为查询样本,只有从样本库中检索出该查询样本的身份时,门禁才会放行。本文提出一种基于检索任务的雷达步态识别网络模型。此外,为充分挖掘时频谱图中不同时间尺度的微多普勒信息,本文提出了一种长短时特征提取模块。下面将详细介绍本文提出的步态识别网络模型。
3.1 总体框架
本文提出的步态识别网络模型总体框架如图9所示,该模型以ResNet18[20]为主干特征提取网络,为获得更大尺寸的特征图,本文去掉了原始Res-Net18网络中第一个残差模块之前的最大池化层。此外,使用空间注意力模块、长短时特征提取模块以及多尺度特征融合模块获取具有判别力的步态特征,最后使用度量学习中的三元损失[21]对网络进行优化。该网络以时频谱图作为输入,时频谱图表示为x ∈RB×C×D×T,其中,B表示网络训练一次所用的时频谱图数量;C表示时频谱图的通道数,其大小取决于输入格式,当时频谱图的输入格式为RGB图片时,通道数为3,当输入格式为矩阵时,通道数为1;D表示时频谱图的频率维;T表示时频谱图的时间维。输入时频谱图首先经过一层卷积核大小为7 ×7的 卷积层得到特征图然后再经过4个残差模块Conv Block得到4个不同尺度的特征图其中,C0,C1,C2,C3和C4分别表示不同尺度的特征图的通道数,每个特征图中不同的通道代表不同的特征。接下来使用空间注意力模块对不同尺度的特征图进行空间位置加权,然后使用长短时特征提取模块提取特征图中不同时间尺度的步态特征,最后使用多尺度特征融合模块将不同尺度的特征进行融合,并使用融合后的特征计算三元损失来优化网络。下面将详细介绍各个模块。

图9 基于检索任务的特征提取网络模型结构框图Fig.9 Framework for feature extraction network model based on retrieval task
3.2 模块介绍
3.2.1 空间注意力模块
时频谱图中除了存在人体运动产生的微多普勒信息之外,通常还存在背景噪声以及未滤除干净的静止杂波,对于步态识别任务来说,我们希望网络能够充分地提取人体的微多普勒特征,并且抑制背景噪声和静止杂波等无关特征的提取。此外,人体不同部位的微多普勒特征对最终识别的贡献程度也有所差异,因此我们也希望网络能够关注更具判别力的微多普勒特征。注意力机制的目的是按照特征的重要程度对特征进行加权,使网络重点关注重要特征而抑制无关特征。本文使用CBAM[22]中的空间注意力模块对时频谱图中不同空间位置的特征按重要程度进行加权。空间注意力图的计算流程如图10所示。

图10 空间注意力图计算流程Fig.10 Spatial attention map calculation process
其中,σ表示Sigmoid激活函数,GMP表示全局最大池化,GAP表示全局平均池化,f7×7表示卷积核大小为7 ×7的卷积层。
最后,将空间注意力图A(Fi)与 输入特征图Fi相乘即可得到空间位置加权的特征图
3.2.2 长短时特征提取模块
步态时频谱图能够反映人行走时各个身体部位散射点的能量强度以及多普勒频率随时间变化的过程。从时频谱图不同长度的时间段中提取的特征反映的步态信息有所差异,对于一张具有完整步态周期的2.4 s时频谱图来说,对整个2.4 s的时频谱图进行特征提取,得到的是长时的“全局”特征;而对时频谱图某一时间段(例如0~0.3 s)进行特征提取,得到的则是短时的“局部”特征。“全局”特征能够反映整个步态周期内的信息,“局部”特征则反映了某一时间段内细粒度的步态信息,充分利用“局部”特征和“全局”特征能够提高步态特征的丰富性。

图11 长短时特征提取模块计算流程Fig.11 Long-short time feature extraction module calculation process

图12 同一人不同起始状态下行走的两组时频谱图数据Fig.12 Two sets of time-spectrogram data of walking in different starting states
3.2.3 多尺度特征融合模块
将4个残差模块提取到的特征图依次输入到空间注意力模块、长短时特征提取模块中,得到4组不同尺度的步态特征由于卷积神经网络中不同层的感受野大小不同,网络不同层提取的步态特征中包含的信息也有所差异。浅层网络的感受野较小,提取到的步态特征中蕴含更多细粒度的信息,如时频谱图的轮廓、纹理、边缘信息等。深层网络的感受野较大,提取到的步态特征中蕴含丰富的语义信息。为充分利用网络不同层提取到的有价值信息,本文使用拼接操作将4组不同尺度的步态特征进行融合,拼接过程如下所示:
3.3 训练与测试
3.3.1 训练
本文使用度量学习中的三元损失训练网络,该损失的目的是在特征空间中将相同身份样本之间的距离拉近,不同身份样本之间的距离拉远。对每批训练样本计算三元损失,具体计算公式如下:
其中,H表示一批训练样本中身份的数目,K表示每个身份拥有的训练样本数目,D(·)表示欧氏距离,Dp表示第i个身份的样本a与相同身份的样本p构成的正样本对在特征空间中的欧氏距离,Dn表示第i个身份的样本a与第j个身份的样本n构成的负样本对在特征空间中的欧氏距离,m为控制正样本对与负样本对之间距离的阈值参数。
3.3.2 测试
测试时,给定查询样本q,目的是从样本库G={gi|i=1,2,...,N}(gi为样本库中的样本,N为样本数)中检索出与该查询样本相同身份的样本。具体测试过程为:
4 实验与分析
4.1 实验设置
本文使用图片格式的时频谱图数据集进行实验,我们将采集的121人中前74人的数据作为训练集,其余47人的数据作为测试集。输入网络的时频谱图时长为2.4 s,尺寸大小为224像素×224像素。网络第1个卷积层以及后续4个残差模块输出特征图的通道数C0,C1,C2,C3,C4分别为32,64,128,256,512。长短时特征提取模块中使用3种分割方式将特征图分成1,2,7份,全连接层FC输出特征向量的维度Hid为512。一批训练样本中身份的数目P为2,每个身份拥有的训练样本数目K为4,三元损失中阈值参数m设置为0.2。使用AdamW优化算法训练网络,其中初始学习率lr设置为0.0005,权重衰减项weight_decay设置为0.0001。训练迭代次数为400000次,每次迭代后使用OneCycleLR策略对学习率进行调整。我们在Pytorch框架上完成网络的搭建,并使用NVIDIA GeForce GTX 2080Ti显卡对网络进行训练。
4.2 评价准则
在测试阶段,我们将测试集划分成查询样本和样本库,以评估模型在多视角、跨视角以及多穿着条件、跨穿着条件下的识别性能。本文将多视角、跨视角、相同穿着条件、跨穿着条件下的识别准确度作为评价准则,4种准则的具体定义如下:
(1) 多视角条件下的识别准确度
给定某个视角的查询样本,样本库中包含查询样本视角在内的8个视角,计算给定视角的查询样本在多视角样本库中进行身份检索的Rank-1准确度。例如当查询样本的视角为0º时,样本库中样本的视角为0º,30º,45º,60º,90º,300º,315º,330º,计算0º查询样本在多视角样本库中进行身份检索的Rank-1准确度,该Rank-1准确度即为0º查询样本在多视角条件下的识别准确度。
(2) 跨视角条件下的识别准确度
给定某个视角的查询样本,共有7个单视角样本库,每个样本库中包含除查询样本视角之外的某个单一视角,分别计算给定视角的查询样本在单视角样本库中进行身份检索的Rank-1准确度,将计算得到的7个Rank-1准确度取平均作为给定视角的查询样本在跨视角条件下的识别准确度。例如当查询样本的视角为0º时,分别计算0º查询样本在单视角样本库中进行身份检索的Rank-1准确度,并将7个单视角Rank-1准确度取平均作为0º查询样本在跨视角条件下的识别准确度。
(3) 相同穿着条件下的识别准确度
给定某个穿着条件的查询样本,样本库中样本的穿着条件与查询样本的相同,计算给定穿着条件的查询样本在相同穿着条件的样本库中进行身份检索的Rank-1准确度,该Rank-1准确度即为相同穿着条件下的识别准确度。
(4) 跨穿着条件下的识别准确度
给定某个穿着条件的查询样本,样本库中样本的穿着条件与查询样本的不同,计算给定穿着条件的查询样本在不同穿着条件的样本库中进行身份检索的Rank-1准确度,该Rank-1准确度即为跨穿着条件下的识别准确度。
4.3 实验结果与分析
由于目前没有针对雷达时频谱图的基于检索任务的步态识别方法,我们对比了几种基于分类任务的步态识别方法,并将这些方法中的分类损失替换为三元损失以完成检索任务。也就是说可以认为这些方法都是已有的针对雷达时频谱图的基于分类任务的步态识别方法的变形,我们已经将这些方法的分类网络改成了检索网络,做的是检索任务的识别实验。其中,方法1[12]在VGG-16网络[25]中嵌入了注意力机制以获取更具判别力的步态特征,方法2[5]在自建网络中嵌入了残差模块以及密集模块,方法3[13]使用了多尺度特征融合策略以融合网络不同层提取的信息,方法4[14]使用Inception模块以及残差模块搭建了一个轻量级网络,方法5[11]使用时序卷积神经网络对时频谱图中的时序信息进行建模。
如2.5节所述,每位受试者共采集了10组数据,其中正常穿着的6组数据表示为NM01-06,挎包的2组数据表示为BG01-02,穿大衣的2组数据表示为CT01-02。本文实验中将NM05-06、BG01-02以及CT01-02分别作为查询样本,将NM01-04作为样本库。查询样本NM05-06在样本库NM01-04中进行身份检索可以评估相同穿着条件下的识别性能,查询样本BG01-02和CT01-02在样本库NM01-04中进行身份检索可以评估跨穿着条件下的识别性能。
表2给出了不同方法在多视角、相同穿着条件下和多视角、跨穿着条件下的识别结果,从表2可以看出,当查询样本为正常穿着NM(相同穿着条件)以及挎包BG、穿大衣CT(跨穿着条件)时,本文方法的识别性能均优于其他方法,这是因为方法1到方法4没有利用到时频谱图中的时序信息,方法5对全局时序信息进行了建模,但对局部时序特征的挖掘不足,而本文方法针对时频谱图的时序特性设计了长短时特征提取模块,该模块首先将时频谱图的特征图沿时间维分割成不同的份数,以提取不同时间尺度的步态特征,最后将从整张特征图中提取到的全局时序特征与从分割后的特征图中提取到的多粒度局部时序特征进行融合,以获得更加丰富的步态特征表示。同时,本文使用了多尺度特征融合策略,可以充分利用浅层特征图中的局部、细粒度信息以及深层特征图中的全局、粗粒度信息。虽然本文方法取得了不错的识别效果,但是在跨穿着条件下的识别准确度相较于相同穿着条件仍然有一定程度的下降,从表2可以看出,查询样本为BG时的准确度相较于NM时下降13.23%,查询样本为CT时的准确度相较于NM时下降15.27%。这是因为挎包和穿大衣行走时人体的步态微多普勒特征与正常行走时相比有所差异,因此在跨穿着条件下网络的识别性能会有所下降。

表2 不同步态识别方法在多视角条件下的识别准确度(%)Tab.2 Recognition accuracy of different gait recognition methods in multi-view conditions (%)
表3给出了不同方法在跨视角、相同穿着条件下和跨视角、跨穿着条件下的识别结果,从表3可以看出,所有方法在跨视角条件下的识别准确度相较于多视角条件下的识别准确度均有大幅下降。这是因为雷达获取的是向视线方向投影的微多普勒信息,具有较强的方位敏感性,当一个人的行走视角发生变化时,时频谱图反映的微多普勒信息也会随之变化,因此在跨视角条件下的识别性能较差。但本文方法较这些方法在跨视角条件下还是能够在一定程度上提升识别性能的。

表3 不同步态识别方法在跨视角条件下的识别准确度(%)Tab.3 Recognition accuracy of different gait recognition methods in cross-view conditions (%)
此外,我们计算了不同方法的模型复杂度,其中输入时频谱图的格式为224像素×224像素的3通道RGB图片。表4展示了不同方法的模型复杂度,由表4可知,本文方法的计算量大于其他方法,参数量比方法1小,比其他方法大。说明我们针对检索任务设计合适的模块来提升模型识别率的同时,也在一定程度上增加了模型的复杂度,因此后续需要进一步研究一些轻量级架构以提高模型的识别效率。

表4 不同步态识别方法的模型复杂度Tab.4 Model complexity of different gait recognition methods
4.4 消融实验
我们进行了一系列消融实验以评估所提网络模型中空间注意力模块、长短时特征提取模块以及多尺度特征融合模块的有效性。表5给出了在多视角条件下进行消融实验的结果。

表5 消融实验识别准确度(%)Tab.5 Recognition accuracy of ablation studies (%)
表5中Base表示ResNet18主干特征提取网络,LST表示长短时特征提取模块,HPM表示文献[26]提出的水平金字塔映射模块,与本文所提的LST相比,HPM缺少向量取平均的操作,MSF表示多尺度特征融合模块,SA表示空间注意力模块。相较于Base+HPM,Base+LST的识别准确度提高了11.87%,这是因为LST中向量取平均操作聚合了分割后各个部分的特征,有效缓解了时频谱图中起始状态不对齐对识别性能的影响。与Base+LST相比,Base+LST+MSF的识别准确率提高了10.51%,证明了多尺度特征融合模块可以聚合网络不同层提取到的有价值步态信息。Base+LST+MS+SA为本文方法,其在Base+LST+MSF的基础上增加了空间注意力模块,识别准确率提高了4.07%,证明了对时频谱图中空间位置进行加权可以提高步态特征的鉴别性。上述消融实验证明了本文方法中各个模块的合理性与有效性。
5 结语
本文公开了一个大型的雷达时频谱图步态识别数据集,填补了基于检索任务的雷达步态识别数据集的空缺,同时为相关研究提供了数据支撑。本文使用毫米波雷达采集了121位受试者在3种穿着条件下沿雷达8个不同视角行走的时频谱图数据,每位受试者在每个行走视角下各采集10组,其中6组为正常穿着,2组为穿大衣,2组为挎包。同时,本文提出了一种基于检索任务的毫米波雷达步态识别网络模型,并在公布数据集上进行了相关实验,实验结果证明了所提模型的有效性。此外,跨视角和跨穿着条件下的步态识别是一项非常有挑战性的工作,本文所提模型的实验结果可以作为基准性能指标,方便后续相关工作者在此基础上开展进一步研究。
本文公布的数据集仍然存在一些不足需要改进,由于本文使用1发4收的毫米波雷达天线配置采集数据,雷达的方位维分辨率较低并且没有俯仰维分辨能力,在步态识别时无法利用人体的空间位置信息以及形状信息。后续考虑使用具有较高方位维和俯仰维分辨率的雷达采集人体步态数据,生成时频谱图、点云等形式的数据,以充分利用人体的微多普勒信息、形状信息和空间位置信息等进行步态识别。此外,本数据集的采集场景较为单一、背景较为干净,后续我们会进一步开展复杂场景中的步态识别研究。
附录
MMRGait-1.0:多视角多穿着条件下的雷达时频谱图步态识别数据集(MMRGait-1.0)依托《雷达学报》官方网站发布,数据及使用说明已上传至学报网站“MMRGait-1.0:多视角多穿着条件下的雷达时频谱图步态识别数据集”页面(附图1),网址: https://radars.ac.cn/web/data/getData?newsColumnId=c2cae1d9-521f-444e-ad1e-f009bf7b9acc.

附图1 MMRGait-1.0:多视角多穿着条件下的雷达时频谱图步态识别数据集发布网页App.Fig.1 Release webpage of MMRGait-1.0: A radar time-frequency spectrogram dataset for gait recognition under multi-view and multi-wearing conditions dataset
猜你喜欢
科学大众(2024年5期)2024-03-06 09:40:34
空间科学学报(2021年6期)2021-03-09 06:20:14
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
测控技术(2018年7期)2018-12-09 08:58:22
电子制作(2018年18期)2018-11-14 01:48:04
自动化学报(2018年6期)2018-07-23 02:55:42
专利代理(2016年1期)2016-05-17 06:14:36
无线电通信技术(2015年3期)2015-12-23 11:37:00
发明与创新(2015年33期)2015-02-27 10:40:00
电子设计工程(2014年19期)2014-02-27 12:00:41
