
基于BO-LightGBM混合模型的热轧带钢板凸度预测
2023-09-15 09:15赵志挺
机械工程师 2023年9期
赵志挺
(沈阳化工大学机械与动力工程学院,沈阳 110142)
0 引言
板形是指板带材的外貌形状,包含带钢截面几何形状和自然状态下板带材平直度两方面,因此要定量描述板形就涉及到凸度、平直度、楔形、边部减薄和局部高点等多项指标[1]。在热连轧生产中,板凸度是评价带钢质量的重要指标之一,板凸度的好坏直接决定带钢的质量[2]。带钢板凸度的偏差不仅会造成工艺中断和许多问题,还会造成板形的缺陷和产品故障,造成巨大的浪费和潜在的风险[3]。而在实际的生产中,带钢的板凸度缺陷问题一直很严重,带钢板凸度的控制一直是一项艰巨的任务[4]。改进和寻求更加完善的凸度控制策略,提高带钢凸度控制精度已经成为当前轧钢领域研究的热点。
由于板带材的性能直接由轧机决定,但轧机由各种轧制模型控制。为了分析带钢缺陷,纯数学模型、新型轧机、有限元法( finite element method, FEM )等理论得到了发展和应用。纯数学模型过于复杂,且难以解释。而新型轧机总是需要新的投资和研究,花费巨大。随着计算机技术的发展,有限元法被用于轧制的模拟。在多道次轧制过程中,Zhang等[5]成功地利用FEM比较了非对称剪切轧制和对称轧制中带材的应变、组织演变和温度。Faini等[6]通过FEM分析了热轧主要参数(如冷却时间、压下率等)对空洞闭合指数的影响,得到了新定义的几何指标与空洞闭合之间的关联式。事实上,对于FEM,人为的设置是必不可少的,包括模型和约束条件,但一次只能进行一种情况。通过大量的试验,上述理论在热轧行业得到了广泛的接受和应用。然而,模型的改进需要复杂的数学公式推导和检验,工作量巨大。
随着人工智能和工业大数据的兴起,学者们开始将人工智能方法引入热轧带钢板凸度控制技术。曹建国[7]提出了基于数据挖掘的调整策略,可以有效改善板凸度控制情况,可为宽厚板板形质量控制研究提供参考。Sun等[8]建立了基于随机森林的热轧带钢板凸度模型,能够稳定和精确地预测带钢板凸度。Wang等[9]应用思维进化算法和人工神经网络预测热轧工艺的型材和平整度,该模型能代替传统的基于数学公式分析的机理模型来研究热轧过程中复杂、非线性的板形控制。Wu等[10]改进局部异常因子的热轧带钢凸度的高斯过程回归预测模型,与传统的高斯过程回归、人工神经网络和SVR比较,具有更好的预测精度和稳定性。Sudipta等[11]进行了一项研究,应用结构简单的ANN来预测不同宽度的带钢的板凸度。Li[12]建立基于集成学习的热轧带钢凸度预测方法,具有高效率和高精度。以上方法对板凸度控制研究起着重要的作用,但在实际应用过程中,由于建模的参数较多,面临着调参困难和调参时间长的问题。因此,建立快速、高精度的板凸度预测模型十分重要。
轻量梯度提升机是一种先进的机器学习算法,它使用直方图算法和具有深度限制的Leaf-wise策略来提高模型的准确性。由于其运算速度快、节省内存,在多个领域都有应用。Wang等[13]建立LightGBM模型对186家企业的融资风险状况进行预测,实验表明,LightGBM在企业融资风险预测的几个指标上比常规算法具有更好的预测结果。孙泉等[14]通过LightGBM对温室番茄冠层作物水分胁迫指数(CWSI)进行预测,精度较高,为实现温室番茄按需灌溉提供参考。而贝叶斯超参数优化是一类黑箱优化问题[15]。在参数优化过程中,只有输入和输出才能解决函数极值问题。丁昌伟等[16]为了进一步提高小断层地震解释的精确度,提出了利用信息价值对地震属性进行约简,结合改进的贝叶斯优化算法,优化XGBoost参数以识别小断层。黄新烨等[17]运用贝叶斯优化方法在需钠弧菌生产1,3-丙二醇,降低了成本,并且提高了实验效率。
针对以上问题,本文通过轧制数据建立了BOLightGBM算法,希望通过贝叶斯优化算法,快速实现模型的参数调优,并满足热轧带钢板凸度的预测精度要求。
1 算法
1.1 LIghtGBM算法
Light GBM是boosting集成模型的成员,LightGBM是GBDT的有效实现[18]。原则上,它类似于GBDT和XGBoost,两者均使用损失函数的负梯度作为当前决策树的残差来近似拟合新的决策树。残差(包括一阶和二阶导数信息)由损失函数的泰勒展开式近似表示,正则化项用于控制模型的复杂度。但是LightGBM的最大特点是使用叶子分裂策略代替XGBoost的水平分裂策略,只选择具有最大的分裂增益的节点进行分裂,从而避免部分增益较小节点的代价,LightGBM的叶子分裂策略如图1所示[19]。
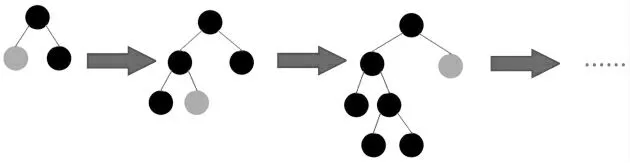
图1 LightGBM的叶子分裂策略
此外,LightGBM使用基于直方图的决策树算法只保存特征的离散值而不使用XGBoost,并使用精确算法中使用的预排序算法来减少内存的使用,加快模型的训练速度。直方图通过分段函数将连续值离散化为相应的bin,如式(1)所示:
对于式(1),将不小于0的连续特征分为3部分,特征分割点数减少为3,即bin为3,大大加快了训练速度。直方图包含每个bin样本中的梯度和每个bin中的样本数量,如式(2)和式(3)所示:
每个面元的累积梯度包含一个一阶梯度和一个二阶梯度。
1.2 贝叶斯优化
贝叶斯参数优化采用高斯过程,该过程考虑了之前的参数信息并不断更新先验。它具有迭代次数少、训练速度快的特点,贝叶斯的具体参数优化思想如下。
假设函数f(x)的定义域在R区间,需要在X区间内找到x,如式(4)所示,其中x是一个超参数。
如果f(x)是凸函数且定义域也是凸函数,则可以通过凸优化问题来研究。然而在实际的机器学习中,f(x)一般是一个黑箱优化问题,在计算过程中需要耗费大量的资源。在解决这个问题时,贝叶斯优化有一定的发言权。贝叶斯优化的算法思想如表1所示,其中f为一组超参数的输入,X为超参数搜索空间,D为数据集,S为集合函数,M为通过拟合数据集D得到的模型。

表1 贝叶斯优化参数的框架
2 热轧数据获取和预处理
本文从工厂控制系统的数据采集系统(Process Data Acquisition,PDA)中得到某热轧生产线数据,根据物理冶金及轧制成形理论,筛选出34个关键特征(如表2),包括每个机架的轧制力、工作辊弯辊力、中间辊弯辊力、窜辊量、厚度、宽度、轧制温度等,共计5100个样本,预测目标为热轧带钢板凸度大小。
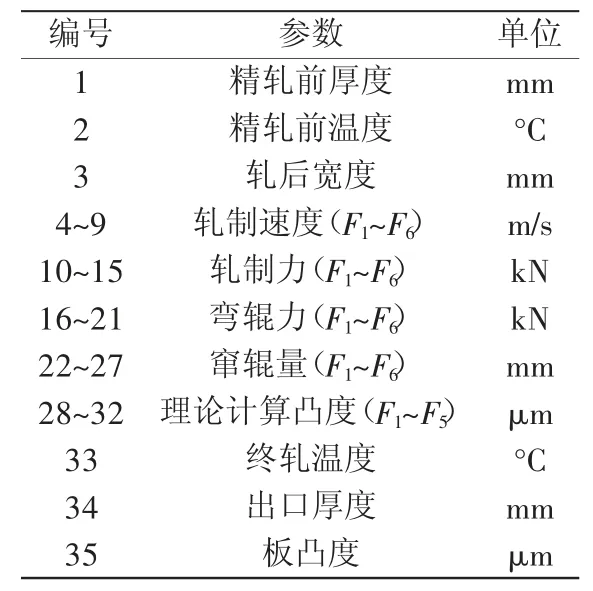
表2 模型特征表述
由于工业数据含有空值、异常值和噪声数据,所以对数据进行预处理。首先去除空值数据,其次采用贝塞尔公式[20]去除异常值,贝塞尔公式如式(5)~式(7)所示:
式中:yi为样本的输出值;L为样本数量为样本均值。
最后对数据进行五点三次平滑降噪[21],公式如式(8)所示,图2所示为降噪后部分样本的板凸度值,由图2可以看出,降噪后的样本曲线比降噪前更光滑。
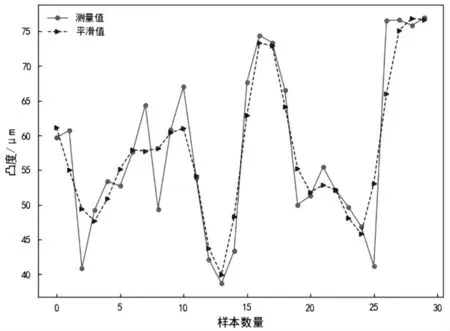
图2 降噪后的部分数据图
同时为了防止不同参数的量纲对模型的影响,对输入数据进行标准化:
式中:x*和x为标准化后的样本和训练样本;μ为x的均值;σ为x的标准差。
3 实验与结果
实验流程图如图3所示,将预处理后的数据集随机划分70%的样本为训练集,30%的样本为测试集,分别建立RF、GBDT、XGBoost和LightGBM模型,并使用10折交叉验证进行验证,交叉验证原理图如图4 所示,并使用R2、MAE和MSE进行模型性能的评价,公式如式(10)~式(12)所示。
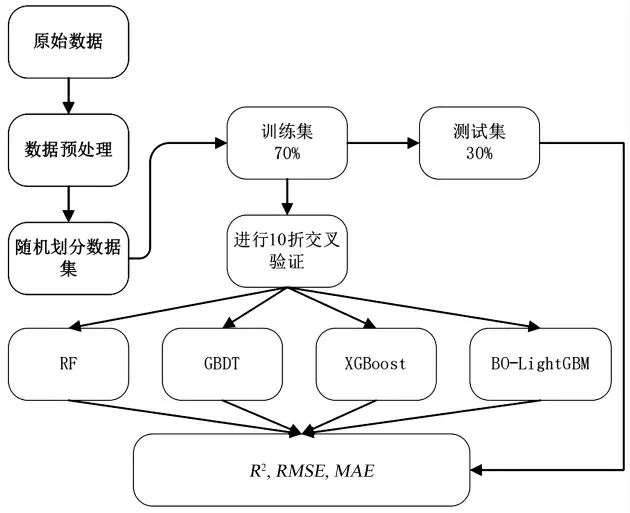
图3 实验流程图
图4 10折交叉验证原理图
R2反映因变量的全部变异能通过回归关系被自变量解释的比例。R2取值在[0,1]。一般来说,R2越接近1,则模型拟合效果越好。同样,MAE、RMSE越小,模型的预测效果越好。
如图5所示,4个模型经过10次交叉验证后,LightGBM拥有最高的R2,且最小和最大的R2值在0.96~0.98之间浮动,其次是RF、XGBoost,最差的是GBDT模型,该模型R2的最小值和最大值在0.92~0.95之间浮动。
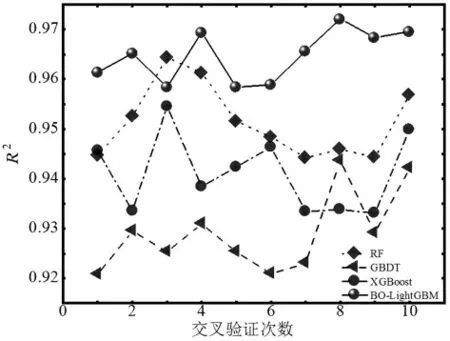
图5 4个模型基于交叉验证的性能
用贝叶斯算法对LightGBM进行参数优化。优化后的模型与RF、GBDT、XGBoost进行比较,如图6所示,最优模型 为BO -LightGBM, 其 次 为RF、XGBoost和GBDT。BO-LightGBM的R2、MAE和MSE均为最优值,分别为0.97、1.49 μm、2.28 μm。
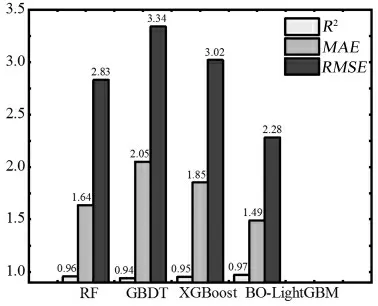
图6 4种模型的性能
将预测值与真实值进行对比,图7(a)、(b)、(c)、(d)分别为RF、GBDT、XGBoost和BO-LightGBM的真实值与预测值比较图。由图7可知,4种模型的真实值与预测值都均匀地分布在y=x的直线上,都具有较好的预测性能,同时也可以看出,BO-LightGBM的分布最密集,具有最好的预测性能。

图7 4种模型的真实值与预测值对比
4 结论
针对热轧带钢板凸度预测精度不足和建模调参困难的问题,建立了一种贝叶斯优化结合LIghtGBM的板凸度预测模型,能够实现板凸度快速建模和精确预测,得出如下结论:
1)对于工厂采集的原始数据,通过贝塞尔公式去除异常值、五点三次平滑公式降噪和标准化处理,为后续建立高精度的模型提供了条件。
2)通过对RF、GBDT、XGBoost和LightGBM经过10折交叉验证后,发现LIghtGBM模型的预测稳定性最高,且预测精度最高。
3)通过对LightGBM模型参数进行贝叶斯优化,发现优化后模型的预测性能高于其他3种模型的预测性能,最优的R2、MAE和MSE分别为0.97、1.49 μm、2.28 μm。因此,可以认为BO-LightGBM能满足板凸度预测的精度要求,能实现较简单的调参需求。
猜你喜欢
哈尔滨轴承(2022年1期)2022-05-23
冶金设备(2021年4期)2021-10-29
中南大学学报(自然科学版)(2020年11期)2020-12-18
重型机械(2020年3期)2020-08-24
数理化解题研究(2017年4期)2017-05-04
铁道通信信号(2016年6期)2016-06-01
现代冶金(2016年6期)2016-02-28
大型铸锻件(2015年4期)2016-01-12
电子器件(2015年5期)2015-12-29
焊接(2015年3期)2015-07-18
