
一种Spark轻量级客户端实现方法研究
2023-09-15 01:33卢居辉朱海勇
河南科技 2023年15期
张 凤 卢居辉 朱海勇 吴 文
(厦门市美亚柏科信息股份有限公司乾坤大数据操作系统研究院,福建 厦门 361001)
0 引言
2022年3月5日,李克强总理在第十三届全国人民代表大会第五次会议上作《政府工作报告》[1],该报告明确提出“建设数字信息基础设施,逐步构建全国一体化大数据中心体系”。2022年4月10日,《中共中央国务院关于加快建设全国统一大市场的意见》发布,明确提出要加快培育统一的技术和数据市场[2]。2022年12月19日,《中共中央国务院关于构建数据基础制度更好发挥数据要素作用的意见》(以下简称“数据二十条”)发布,从数据产权、流通交易、收益分配、安全治理等方面出发,为构建数据基础制度提出20条政策举措。“数据二十条”的出台,将充分发挥中国海量数据规模和丰富应用场景的优势,激活数据要素潜能,做强做优做大数字经济,增强经济发展新动能[3]。因此,数据资源大一统将会成为接下来大数据领域研究的热点和发展的趋势[4]。
大数据领域的研究往往涉及海量数据,而处理海量数据的技术也是研究的热点问题。其中,YARN 作为一种统一资源管理机制,因其可运行多套计算框架而备受好评[5]。Spark 作为一种常用的大数据计算框架[6-7],也是一个通用的并行计算框架[8],Spark on YARN 运行模式是基于YARN 弹性资源管理机制,确保用户在YARN 集群中运行的服务和资源能被完全隔离,从而实现对同时运行在集群中的多个任务进行管理。
在YARN 集群环境中,每个应用实例都有一个Application Master 进程,负责向集群资源管理器请求Container 资源。Spark 运行架构主要由Driver、Executor组成[9],Driver负责作业调度,Executor负责执行具体的计算任务。根据Spark Driver 和Application Master 在运行时所处的相对位置,Spark on YARN 可分为两种模式,即YARN-Client 模式和YARN-Cluster模式[10]。
在YARN-Client 模式中,Spark Driver 单独运行在集群边缘节点服务器上,通过部署在YARN集群上的Application Master 进行通信,在申请Container 资源后,启动Spark Executor 来执行具体任务,二者分属集群内外两个不同的进程。在运行过程中,前端用户可与Spark Driver 保持在线连接,进行更多交互操作,适合处理交互类型的Spark作业。
在YARN-Cluster 模式中,Spark Driver 运行于YARN 集群的Application Master 中,共享同一个Container进程。在任务提交后,Spark Driver断开与前端用户的连接,其生命周期由YARN 控制,不适合运行交互类型的作业。
为满足与前端用户的频繁交互需求,实现对Spark on YARN运行模式下的Spark作业生命周期的自主控制,在集群边缘服务器上部署YARN-Client模式的Web服务,通过Web API来接收、处理前端用户发送的Spark作业请求[11]。由于Spark Driver 被集成在Web 服务中,相当于该服务内部提供一个Spark Session 入口,通过该入口将Spark 作业提交到YARN 集群上运行,其作业运行结果也将被同步返回给前端用户,实现与前端用户的在线交互需求。但该方案也有不足之处,在YARN-Client 模式下,Spark Driver 运行在集群边缘节点服务器上,由于Spark 任务要处理的数据量较大且耗时较长,在Spark Executor 数量较多的情况下,Spark Driver 与Spark Executor(s)的交互过程会占用大量的边缘节点服务器系统资源,造成性能瓶颈,影响边缘节点服务器上其他业务的正常执行。
在YARN-Cluster 模式下,为避免由前端用户直接访问集群内部节点而造成的安全隐患,通常要在边缘节点服务器上部署一个Web Server,通过保持与集群上Spark Driver 的长连接会话关系,可实现前端用户与Spark 的在线交互,但该方案仍无法避免集群间的网络连接消耗。
为解决上述重量级客户端方案存在的弊端,可以通过轻量级开源应用框架Spring Boot 来构建Web 应用服务[12],在内部集成Spark Driver,以YARN-Cluster 模式将多个无差别的Web 服务部署到YARN 集群中,利用Restful API 来完成Spark 在线交互式作业的提交请求[13]。这些服务进程将长期驻留在集群内部,可避免因频繁申请Container资源而造成的时间消耗。
同时,在边缘节点服务器上部署高性能负载均衡和动态代理组件HAProxy[14]。将Spring Boot服务所在的IP 地址和Restful API 端口通过HAProxy 动态配置接口(HAProxy Data Plane API)实时注册到HAProxy 后端代理配置中,利用HAProxy 的自动重载机制来实现动态加载后端配置,使前端用户能在无感知情况下,通过HAProxy 的统一对外接口将Spark 作业无差别地提交到分散运行在集群上的Spring Boot 服务中运行,可避免外部用户直接访问集群内部节点,在实现安全隔离的同时,也实现多个Spring Boot服务间的并行调度,且互不干扰。
通过上述方法,边缘节点服务器与集群节点之间无须保持长连接会话,即可动态实现Spark on Yarn 运行模式下Spark 作业的异步提交及整个Spark作业生命周期的自主控制。
1 系统框架
本研究通过提供一种轻量级客户端提交Spark作业的实现方法来克服重量级客户端方案带来的弊端,系统具体实现框架如图1所示。
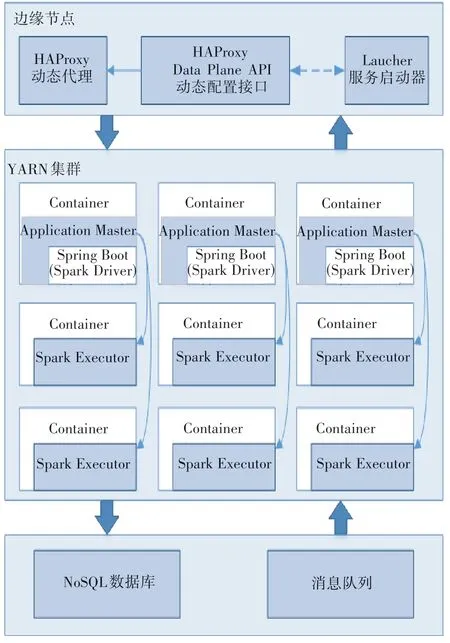
图1 系统实现框架
轻量级Web应用服务(Spring Boot)内部集成执行引擎Spark Driver,通过Spark on YARN 的Cluster模式在YARN 集群内部运行,由Restful API 来接收处理请求,并在Spring Boot 服务内部直接通过Spark Driver 来调度执行器Spark Executor(s),从而完成Spark作业的执行和其他相关请求操作。该服务长期驻留在YARN 集群内,以在线交互的方式及时处理不同类型的Spark 作业,可避免频繁启动Spark容器造成的时间消耗。
HAProxy(可提供高性能负载均衡、基于TCP和HTTP 应用的动态代理)部署在YARN 集群的边缘服务器节点上,代理前端用户发送Spark 作业相关操作请求,根据负载均衡策略将其发送到分散在后端YARN 集群上的Spring Boot 服务上进行相应处理。前端用户只需通过HAProxy 统一访问接口就可无差别使用后端YARN 集群上的Spring Boot 服务,从而实现前端用户与YARN集群的安全隔离。
HAProxy Data Plane API 是一种能实现HAP-roxy 配置动态更新的Restful API。在启动Spring Boot 成功后,将其监听的IP 地址和端口通过HAP-roxy Data Plane API 动态注册到HAProxy 代理配置中,HAProxy Data Plane API 会根据配置的变更情况来自动重载HAProxy 服务,使前端用户能在无感知的情况下访问所有后端服务。
服务启动器(Launcher)用于监听并保证在YARN 集群中始终运行一定数量的Spring Boot 服务。Launcher 会将失效的Spring Boot 服务接口从HAProxy Data Plane API 中动态删除。当YARN 集群上Spring Boot 服务数量不足时,Launcher 会启动新的Spring Boot服务,直至满足数量要求。
Spring Boot 服务在接收到Spark 作业提交请求后,会直接将其写入轻量级的消息队列服务中,排队等待处理,实现前端用户请求与后端执行引擎的解耦与异步化。
NoSQL 数据库用于保存和更新Spark 作业的执行进度,并在作业运行完毕后,会保存一定数量的采样数据或结果数据,用于向前端用户展示。
2 动态代理服务
使用动态代理服务的好处是其能屏蔽前端用户与后端YARN 集群间的直接交互访问,保证内网安全,同时使Spark Driver 分散运行于YARN 集群上,减少集群边缘节点的运行压力,从而实现轻客户端服务的目的,具体处理流程如图2所示。

图2 动态代理服务处理流程
动态代理服务管理执行步骤如下。
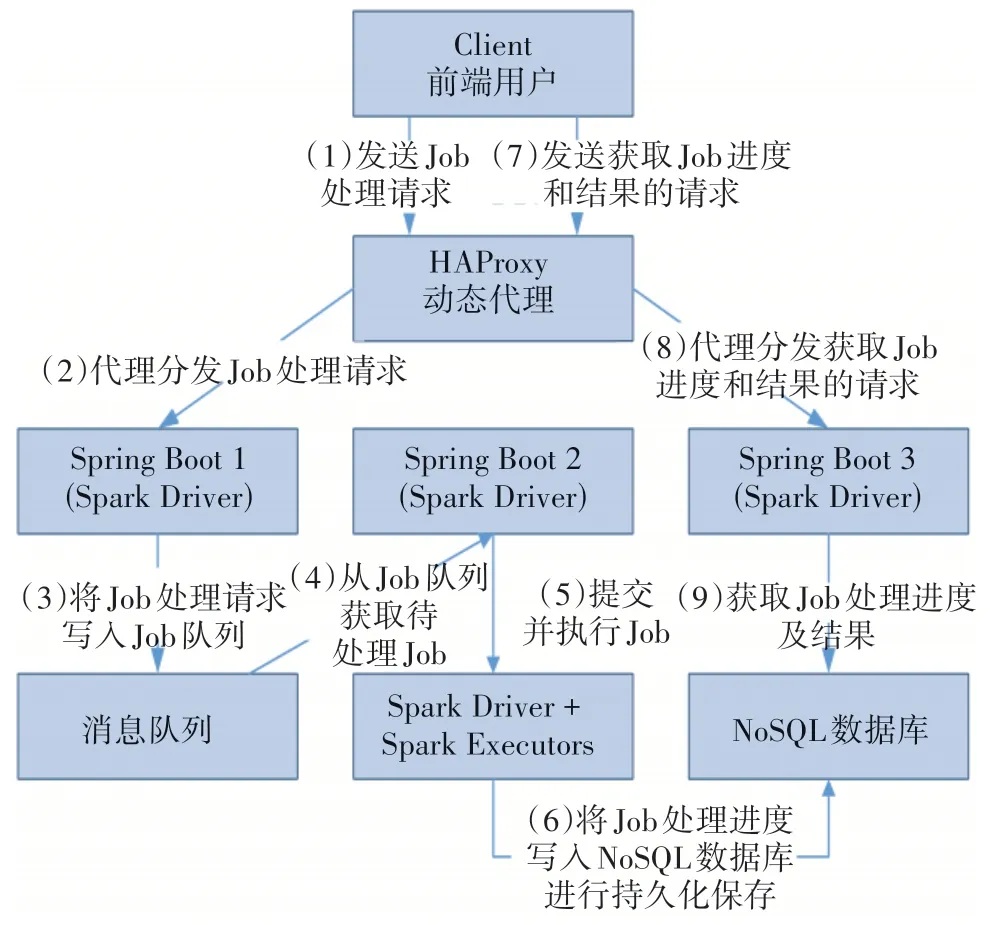
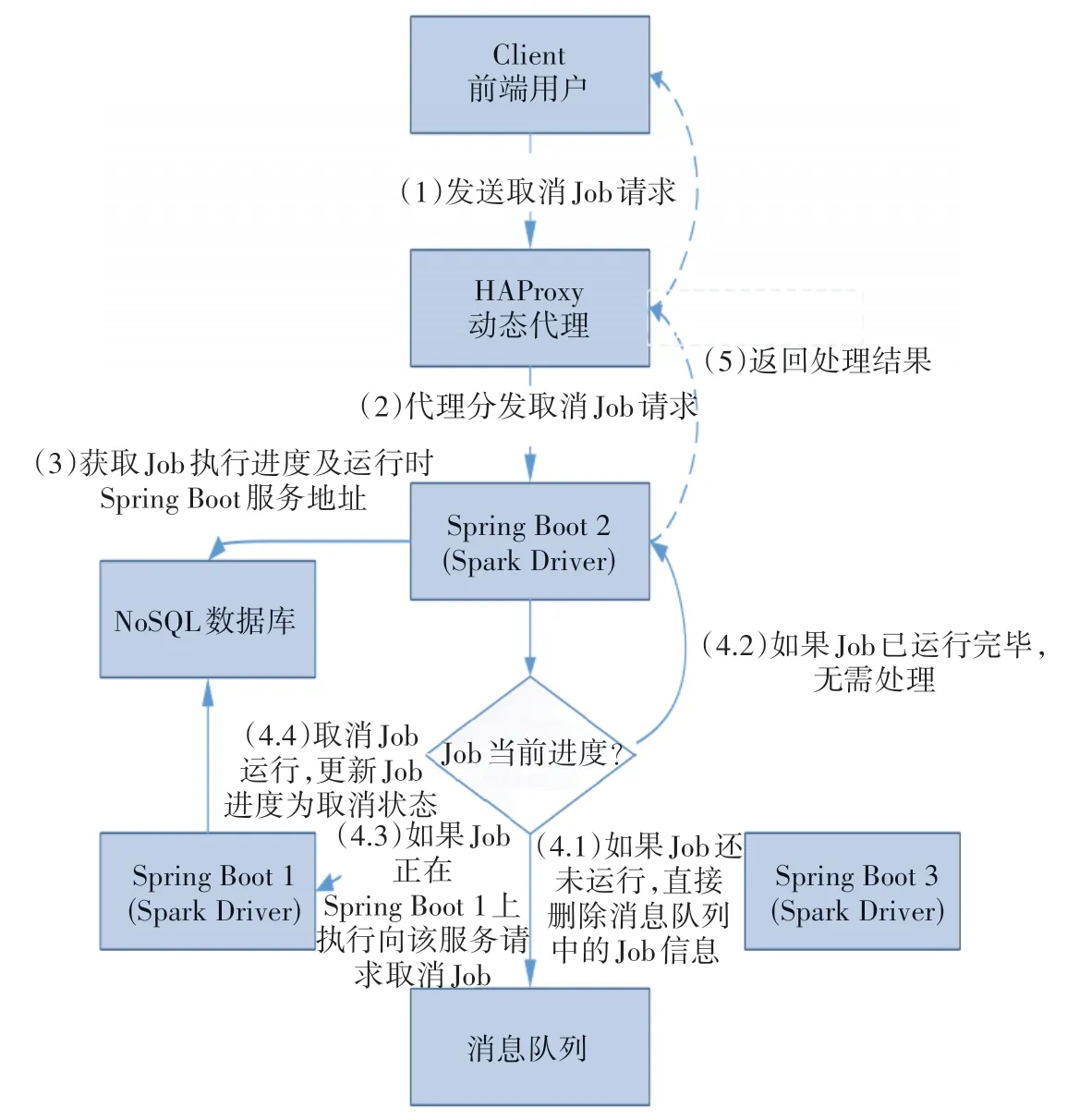
(1)在YARN 边缘节点服务器上启动Launcher服务,启动并保持一定数量的Spring Boot 服务。Launcher 服务会定期通过HAProxy Data Plane API来获取HAProxy 当前已配置的Spring Boot 后端服务接口。在Launcher 与Spring Boot 进行服务通信时,检查所有后端服务的有效性,将当前有效的Spring Boot服务数量N与实际需要启动的服务数量M进行比较。若N (2)启动成功的Spring Boot 服务会将其所在IP和监听端口通过HAProxy Data Plane API 注册到HAProxy后端配置中。 (3)HAProxy Data Plane API 会根据最新配置动态重载HAProxy,并对外提供统一代理服务,将Spark 相关请求转发到分散在YARN 集群中的Spring Boot服务上进行处理。 通过动态代理HAProxy 提供的统一访问接口,前端用户Client将Spark作业Job提交到后端YARN集群的Spring Boot 服务上执行,并异步获取作业的执行进度和处理结果。提交作业处理流程如图3所示。 图3 提交作业流程 提交作业具体执行步骤如下。 (1)Client 向HAProxy 统一访问接口发送Job 处理请求。 (2)HAProxy 在接收到Job 处理请求后,根据负载均衡策略选择一个后端服务(如Spring Boot 1)来处理当前请求。 (3)Spring Boot 1服务会直接将Job处理请求信息写入到消息队列中,通知前端用户该Job 已提交成功,进入调度队列等待后续处理。 (4)YARN 集群中其他空闲的后端服务(如Spring Boot 2)从消息队列中获取Job 处理请求信息。 (5)利用Spring Boot 2 服务内部集成的Spark Driver 调用集群中的Spark Executor(s)对Job 进行调度执行。 (6)Spring Boot 可定时将Job 处理进度写入到NoSQL 数据库,并将Job 的最终处理结果和采样数据写入NoSQL数据库。 (7)Client 从步骤(3)接收到Job 提交成功的信息后,向HAProxy 统一访问接口发送获取Job 实时进度和处理结果的请求信息。 (8)对获取到的Job 进度和结果请求信息,HAProxy 按照负载均衡策略选择一个后端服务(如Spring Boot 3)进行处理。 (9)Spring Boot 3 在接收到请求信息后,从NoSQL 数据库中获取Job 实时进度和处理结果,并经HAProxy 返回给前端用户,完成此次作业的提交过程。 Spark 作业Job 在被提交到集群上的Spring Boot 服务后,因某种原因,前端用户要提前终止作业执行。此时,可通过HAProxy 提供的统一访问接口来及时撤销Spark 作业。取消作业流程如图4 所示。 图4 取消作业流程 取消作业具体执行步骤如下。 (1)前端用户向HAProxy 统一访问接口提交取消Job的请求。 (2)HAProxy 按照负载均衡策略将请求分发到后端服务(如Spring Boot 2)上执行。 (3)Spring Boot 2从NoSQL数据库中获取Job执行进度和Job 当前运行时所在的Spring Boot 服务信息。 (4)Spring Boot 2 根据Job 的进度状态来执行不同的取消操作。①若Job 执行进度不存在,则说明该Job 未执行,Job 信息仍在消息队列中,直接删除消息队列中的Job 信息,标记Job 已取消,继续执行步骤(5);②若Job 执行进度为已完成状态(如成功、失败、取消等终结状态),则说明该Job 已执行完毕,无须处理,直接标记Job 已取消,继续执行步骤(5);③若Job 执行进度为未完成状态,则说明该Job 正在执行。将取消Job 的请求信息转发到Job 运行时所在的后端服务(如Spring Boot 1)中进行处理,继续执行步骤④;④利用Spring Boot 1 内部集成的Spark Driver 来向集群提交Job 取消指令,完成后将NoSQL 数据库中的Job执行进度更改为取消状态,标记Job 已取消,并将取消结果反馈给Spring Boot 2。 (5)Spring Boot 2 将Job 取消结果通过HAProxy反馈给前端用户,结束操作。 基于轻量级Web 应用框架集成的Spark Driver 功能,采用YARN-Cluster 模式将多个无差别的Web 服务部署到资源充足的YARN 集群上,能分散运行,并行调度,减轻边缘节点服务器的资源使用负担,降低故障发生频率。 通过代理组件来实现动态配置更新与自动重载机制,代理后端多个无差别Web 服务,对外提供统一的服务访问接口,能在用户对后端无感知的情况下,接收和分发Spark 作业的交互式提交请求,从而完成对Spark 作业生命周期的管理。 代理组件仅提供Spark请求信息和结果数据的高性能代理和转发功能,无须在边缘节点服务器与集群之间保持长连接会话,具体请求由后端Web服务之间自动协作完成,能实现轻客户端的高效交互效果。 综上所述,本研究通过在边缘节点服务器上部署高性能负载均衡和动态代理组件HAP-roxy,提供一种轻量级客户端方式来提交Spark作业的实现方法,实现对Spark 作业进行动态调度与全生命周期的管理。通过Spark on YARN模式将多个具有相同功能但相互之间独立运行的Rest 服务部署到YARN 集群上,利用HAProxy的自动重载机制来动态更新和加载后端服务配置,使前端用户能在对后端变动无感知的情况下;通过HAProxy 的统一对外接口,将Spark 作业提交到分散运行在YARN 集群上无差别的Rest服务中执行。该方法无须在边缘节点服务器与集群节点服务器之间保持长连接会话,通过HAProxy 能有效避免外部用户直接访问集群内部节点,达到集群内外安全隔离的效果,同时实现Spark on YARN 运行模式下Spark 作业的交互式提交与异步调度,完成对Spark 作业全生命周期的自主控制。该方法在解决传统重客户端与Spark 应用服务保持长连接会话弊端的同时,也能满足前端用户的频繁交互需求。3 提交作业
4 取消作业
5 结语
猜你喜欢
铁道通信信号(2019年9期)2019-11-25
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
通信产业报(2016年44期)2017-03-13
网络安全和信息化(2017年10期)2017-03-08
知识就是力量(2017年2期)2017-01-21
知识产权(2016年8期)2016-12-01
网络空间安全(2016年3期)2016-06-15
雕塑(1999年2期)1999-06-28
