
风力发电机温度时序预测方法优化
2023-09-14 09:52王言国秦冠军兰金江
计算机技术与发展 2023年9期
王言国,秦冠军,兰金江
(1.南京南瑞继保电气有限公司,江苏 南京 211101;2.中国三峡新能源(集团)股份有限公司,北京 100032)
0 引 言
近年来,国内风电行业发展迅速,随着风电装机容量的增加和精细化运维要求的提升,风机故障成为业主越来越关注的问题。发电机作为核心部件,其温度过热往往是发电机故障的综合表现[1]。目前学术界已开展了发电机温升故障预警和风机主轴承故障预测的研究[1-5]、风机齿轮箱故障预测的研究[6-8]。上述研究在筛选智能算法的自变量时,尚未交代自变量筛选的原则。同时,工程中正常的风机scada样本数据本身存在着数据缺失、数据异常等各种情况[9],这些异常数据会对机器学习算法的精度产生很大的影响,但实际生产环境下,又无法仅靠人工和固定规则做数据剔除,而上述文献也尚未给出剔除异常数据的自动化手段。除了风机本体部件健康状况外,环境因素(如风速、气压、环境温度等)是决定风机运行工况的重要原因[2,10],而环境因素的变化趋势在小时级时间粒度上是随机性的,ARIMA(差分整合移动平均自回归模型,Autoregressive Integrated Moving Average model)等单维度的时序预测算法很难收到预期的效果,风力发电机温度时序预测的研究中必须考虑多维度的影响因素。
该文基于业务场景明确了自变量和因变量的非线性关系,并在此基础上采用合适的算法做特征筛选;分析了多维时序数据集到有监督学习数据集变换的可行性,从而把多维时序预测转化为回归算法模型;随着风机的老化、环境的变化等影响,风机发电机温度与其特征变量之间的对应关系也在发生变化,工程中需要定期基于近期数据自动更新预测模型,面对庞大的样本集和多样的异常数据,该文把iForest(孤立森林,Isolation Forest)算法[11-12]引入模型训练流程,实现了异常数据剔除的自动化;最后通过多种算法的对比,明确了2阶Ridge回归、XGBoost(极端梯度提升,eXtreme Gradient Boosting)算法[13-14]在本场景中的优越性。
1 基本理论
1.1 数据集变换
本场景的原始数据为时间序列数据集,时序预测是根据前k步的数据来预测第k+1步至第k+h步的值。对此,可以把前k步的数据视为自变量X,第k+1~第k+h步的数据视为因变量Y,转化为有监督学习数据集,进而使用有监督学习算法。
首先,根据业务规律和预测需求确定参数k和h(为简化说明,该文以h=1为例做说明)。对于时间序列数据集中相邻的k+1个向量Xt,Xt+1,…,Xt+k-1,Xt+k,构建Xt,Xt+1,…,Xt+k-1与Xt+k的子集Yt+k之间的对应关系矩阵,如公式(1)。则对于样本数量为n的时间序列数据集,构建出的有监督学习数据集样本数量为n-k。
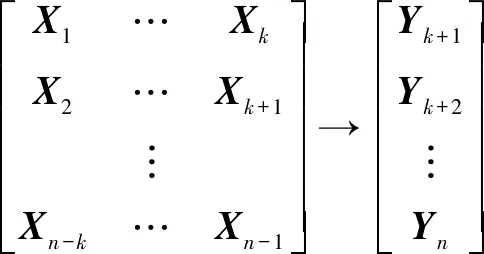
(1)
其中,左侧自变量矩阵中每个X元素为r维向量(r≥1),整个矩阵为(n-k)*k*r的3D张量,在利用回归算法构建预测模型时,自变量矩阵需进一步转化为(n-k)*(k*r)的2D张量。实际使用中,可根据需要舍弃第2~k列,以便简化自变量矩阵;右侧因变量矩阵中每个Y元素为s维向量(r≥s≥1),整个矩阵为(n-k)*s的2D张量。
1.2 特征优选算法
风机的实时测量值有数百个之多,若把这些数据全用于模型输入,会大大增加建模计算的复杂度,并极易引起过拟合问题。对此需要特征优选,剔除与预测目标弱相关或不相关的特征。

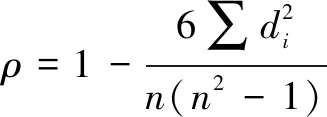
(2)
其中,n为样本数量。
1.3 iForest数据过滤算法
iForest算法[11-12]是基于集成学习的快速异常检测方法,属于无监督学习,由多个iTree(isolation Tree,孤立树)分类器组成,每个iTree是一个二叉树结构。在构建iTree时,先对数据集D随机选取一个特征f,并在该特征的取值范围内随机选取一个分割点p,按特征f把D分割为左右两部分,若di(f)>p,则数据di被划分在右子树,反之则划分在左子树,循环递归直到每个数据与其他数据完全分割开或达到最大树层次。风电scada数据中,异常数据要远少于正常数据,则异常数据会更靠近树的根节点,根据实际数据集中异常数据的出现机率实现数据过滤。
2 风力发电机温度时序预测
所述优化方法的完整流程如图1所示。本节选用风电集控系统中某风场某风机2021年10月的125个遥测量每10分钟采样的共计4 464条记录为样本数据集,以未来30分钟的最高发电机温度最大值为预测目标进行建模。

图1 风力发电机温度时序预测方法优化流程
2.1 原始样本数据集变换
先从业务角度出发,选择2021年10月1日到10日之间的“最高发电机温度最大值”以及与此紧密相关的“平均风速”“平均有功功率”“平均发电机转速”4个数据每个整30分钟1条记录,共计480条记录进行数据透视(见图2,横轴为测点记录序号)和ADF检验(见表1)[21-22],可知除发电机转速外,其他数据本身非平稳序列,即:本数据集中选取k大于1的连续多步自变量数据,对因变量的预测精度提升并没有帮助,该文选取k=1。
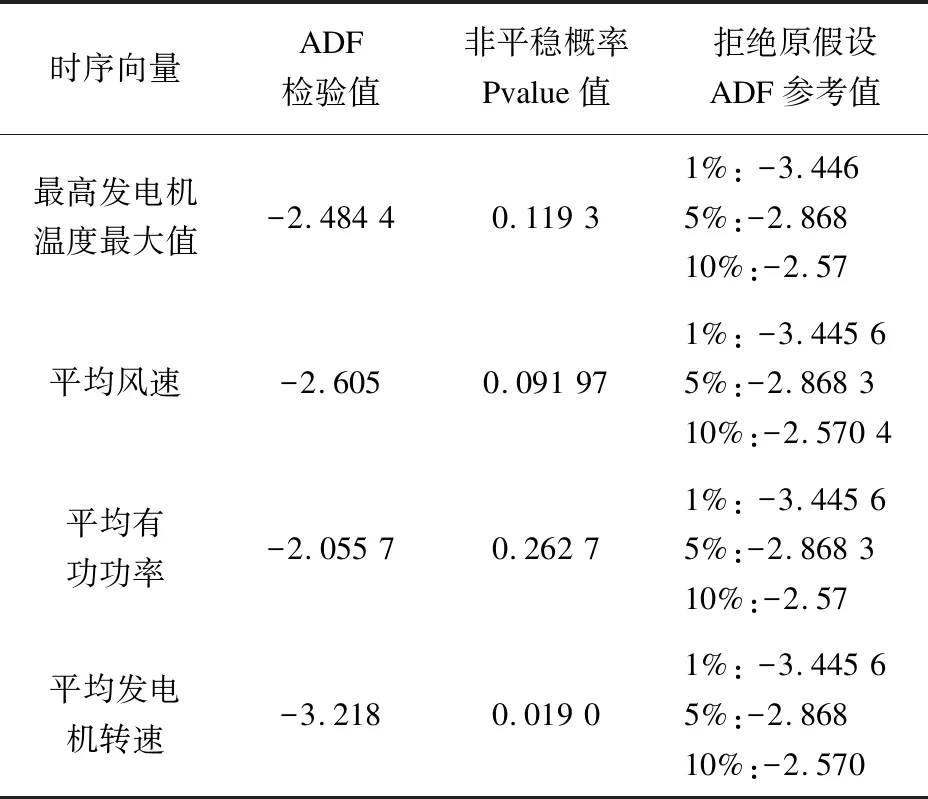
表1 样本集关键数据ADF检验

图2 关键量测值曲线
首先,从125个遥测特征向量中基于业务背景去除明显与目标无关的特征,比如风向角度、故障累积时长初值等;然后做数据重采样,基于10分钟数据集构建30分钟数据集,再按照1.1节所述的数据集变换方法以k=1把2021年10月1日0点0分~2021年10月31日23点0分时间序列样本数据集转换为包含1 487条记录的有监督学习样本数据集。
2.2 特征优选
把数据变换得到的有监督学习样本数据集经spearman相关系数算法[15-17]得到特征向量与目标向量之间的相关性见表2,经随机森林算法得到的特征权重见表3。

表2 各特征与目标向量的spearman相关系数

表3 基于随机森林平均不纯度减少方法的特征权重
在随机森林平均不纯度减少方法中,对于相关联的多个特征,其中任意一个都可以作为指示器(优秀的特征),并且一旦某个特征被选择之后,其他相关联特征的重要度就会急剧下降,因为不纯度已经被选中的那个特征降下来了,其他的特征就很难再降低更多不纯度,这样一来只有先被选中的那个特征重要度很高,其他的关联特征重要度往往较低,比如“平均变桨电容2温度”在表2中排第16位,而在表3中排在第26位,即为此原因。综合表2、3的特征权重量化数据,兼顾“减少特征向量中相关联的多个特征”和“去除权重小的特征”两个原则,最终剔除“平均变桨电容2温度”“平均变桨电容3温度”“平均变桨逆变器2温度”“最高Topbox温度”“平均发电机后轴承温度1”共计5个向量,特征个数缩小为21个。
2.3 异常数据过滤
风场scada系统中的数据质量受到以下因素的影响:
(1)作为数据源头的风机主控送出的数据本身存在小概率的错误,比如在诸多风机型号上都发现过的发电量数据跳变问题。
(2)数据以风机主控为源头,经过风机能量管理系统、风场网关机、集控通信服务器等多个数据传输环节,中间难免出现通信中断等异常情况,造成最终的数据失真或错误。
经过对多个风电集控项目中数十个风场数据质量的研究统计,得到风电集控scada中坏数据出现的机率一般在3%~5%之间,该文的场景可用数据充足,以脏数据过滤比例为5%做iForest模型训练和预测,做脏数据的剔除。
2.4 时序预测模型优选
以4∶1的比例把上述数据集切分为训练集和测试集,分别构建2阶多项式ridge回归[23]、多层感知机(MLP)回归[24]、XGBoost回归[13-14]、基于LSTM构建深度学习多维时序预测网络模型[25-27],在同一计算环境下进行横向对比实验,以均方误差、解释方差、R2 score作为衡量模型精度的指标。以上4种预测模型超参数全部经网格搜索得到近似最优模型,最终各模型精度见表4。模型精度指标中,均方误差MSE是Mean Squared Error的简写,是预测数据偏离真实值差值的平方和的平均数,值越小代表模型预测越准确,算法见公式(3)。可解释方差Evar是Explained Variance的简写,衡量的是所有预测值和样本之间的差的分散程度与样本本身的分散程度的相近程度,值越接近1表示预测值和样本值的分散分布程度越相近,模型预测越准确,算法见公式(4)。R2 score又名决定系数,算法见公式(5),值可以为负值,值越接近1,代表模型预测效果越好。分析可知在该场景下深度学习模型比MLP简单神经网络要好,但2阶Ridge回归、XGBoost回归在更少的计算资源消耗下,取得了更好的效果。图3展示了对1 487条样本按1/5的比例取得的297条测试集用4种方法建模预测数据与实际数据的对比。
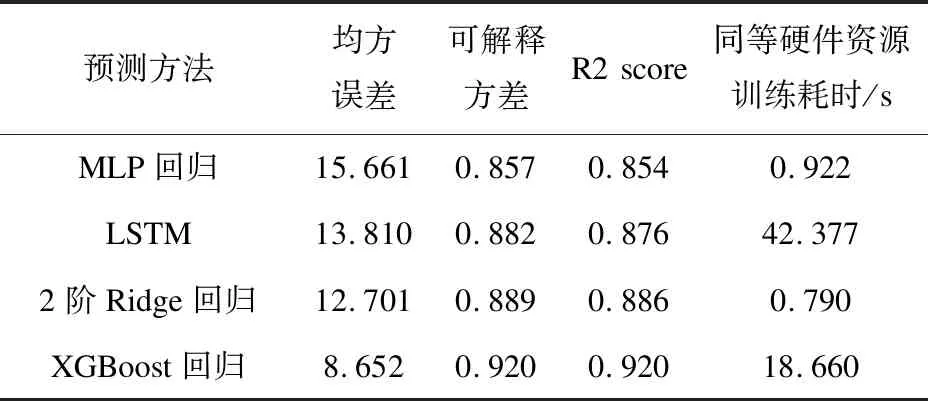
表4 各模型预测精度

图3 测试实际数据与各模型预测数据曲线对比
(3)

(4)
(5)

3 验证分析
以单纯spearman做特征优选过滤掉最后5个特征、不做脏数据过滤,以2阶Ridge回归、XGBoost回归构建预测模型,在同一计算环境下进行横向对比实验,其模型精度见表5优化前后的对比。

表5 优化前后各模型预测精度
由表5可知,优化后2阶Ridge回归模型的均方误差降低了0.8,可解释方差、R2 score在0.870精度基础上分别提高了0.014、0.012,计算耗时降低了5%左右。XGBoost回归模型的均方误差降低了0.8,可解释方差、R2 score在0.910精度基础上分别提高了0.010、0.009,计算耗时降低了3%左右。
4 结束语
该文在前人研究的基础上对风力发电机温度时序预测建模过程进行了多环节的优化,通过数据集转换将时间序列数据集转换为有监督学习数据集,通过量化自变量和因变量之间的非线性关系进行更合理的特征筛选,基于无监督学习算法实现了异常数据剔除的自动化,通过多种回归模型的对比优选出精度更高的预测算法。本研究成果已应用于多个新能源集控工程项目,实现了风力发电机温度超限提前预警,预测效果良好。同时,作者把该优化方法应用于风机轴承温度超限提前预警、风力发电机机舱温度超限提前预警等多个类似的场景,同样提高了预测精度。该数据转换案例是以时间步数k=1、预测步数h=1来组织数据集的,未来可结合不同应用场景,研究更长时间步数的数据集转换应用效果。
猜你喜欢
中国农业信息(2021年3期)2021-11-22
能源(2018年5期)2018-06-15
电子制作(2017年13期)2017-12-15
能源(2017年9期)2017-10-18
大电机技术(2017年3期)2017-06-05
电子制作(2016年15期)2017-01-15
军事文摘(2016年16期)2016-09-13
现代工业经济和信息化(2016年12期)2016-05-17
智能建筑电气技术(2015年5期)2015-12-10
安徽冶金科技职业学院学报(2015年3期)2015-12-02
