
基于半监督的3D肝脏CT自动分割方法研究
2023-09-14 09:31谢宏彪刘志勤王庆凤
计算机技术与发展 2023年9期
谢宏彪,刘志勤,王庆凤,黄 俊,陈 波,周 莹
(1.西南科技大学 计算机科学与技术学院,四川 绵阳 621010;2.绵阳市中心医院,四川 绵阳 621010)
0 引 言
肝脏是人体内最大的器官,在人体众多部位有着无可比拟的地位,承担着存储、解毒和合成三个方面的功能。由于人们高压力工作、作息不规律等原因,致使肝脏过度使用,因此肝脏疾病的发病率极高,并且具有多种类、多发性等特点,而这些肝脏疾病均具有较高几率诱发肝癌,也叫做肝脏恶性肿瘤[1]。肝癌在全球癌症中有着极高死亡率,每年约有84万多新病例和78万多死亡病例[2]。人类的生命健康正被肝癌等疾病摧残着。
在临床治疗中,自动肝脏肿瘤分割[3-5]在CT(computed tomography)图像中有着重要的研究价值,不但可以减少医务人员在分析病情中所耗费的时间,有些还能模仿临床手术操作,提高治疗成功率。但自动肝脏肿瘤分割的准确性在较大程度上依赖标签数据的质量和数量[6-7],获取这些肝脏区域标注既需要医学专家进行细致的手动勾画,专家个人的主观因素也会影响到标注精度,会影响后续治疗时间,降低效率[8]。并且CT图像是三维图像,一些分割方法[9-10]只利用了二维图像,由于2D网络结构本身的不足,导致CT图像的三维信息没有得到很好的利用,对2D网络结构的各种改动也仅限于提高单张切片分割的准确率,让肝脏肿瘤的整体分割性能的提升受到限制。
对于以上问题,该文提出了一种基于半监督协同训练的3D CT肝脏自动分割方法。主要有以下几个方面的贡献:
(1)为了更好地利用医学分割图像中少量的肝脏数据,提出了半监督协同训练方法。
(2)提出使用3D U-Net和3D Res U-Net方法可以更好地利用CT图像的三维信息。
(3)用全连接条件随机场(Dense Conditional Random Filed,Dense CRF)把预测得到的伪标签通过边缘细化,提升伪标签的精确度。
1 相关研究
深度学习[11]的发展推进了图像分割性能的大幅提升,通过对标注数据进行学习,能够自动提取大量的特征值,从而提升肝脏分割的准确性。因为肝脏CT图像边界不清晰,准确分割出肝脏又需要较多高分辨率信息;同时,人体器官的位置相对固定,分割有一定的规律,语义简单清晰,所以对目标器官的识别还需要低分辨率信息。Ronneberger等人[12]在2015年首次提出将U-Net应用到医学图像分割中。U-Net在编码器和解码器之间加入跳跃连接,可以将低分辨率信息和高分辨率信息很好地结合起来,能够更好地分割肝脏和肝肿瘤。跳跃连接虽然结合了低分辨率信息和高分辨率信息,但没有筛选一些无用的低分辨率信息,使得低分辨率信息过多而导致图像边界模糊。为了解决这个问题,Seo等人[13]改进了网络框架,提出了mU-Net,他们引入了一个剩余路径,加到U-Net的跳跃连接部分,其中包含激活操作和反卷积操作,有效地加强了全局特征的提取能力和高分辨率的边缘特征。Fan等人[14]提出了一种多尺度嵌套U-Net,优化了跳跃连接区域,解决了跳跃连接传递过多低分辨率信息的问题。由于医学CT图像为3D图像,使用2D网络无法有效利用CT图像的三维信息。Milletari等人[15]在2016年提出3D网络V-Net,该方法解决了2D网络无法利用CT图像的三维信息的问题。紧接着,Jeong等人[16]提出一种深度三维注意力U-Net(3D attention U-Net)有效学习了各个形状的肝脏。Jin等人[17]提出用于肝肿瘤分割的RA-UNet,在网络中加入注意力剩余机制,可以较好地获取并利用上下文信息。
以上肝脏自动分割的研究方法都需要大量的肝脏标注数据进行全监督学习训练,但获取这些肝脏区域标注需要医学专家进行细致的手动勾画,费时费力。因此有研究者提出了一种半监督学习,以减少对人工标注的依赖。在2013年Lee等人[18]提出“伪标签”一词,通过网络自训练利用少量标签数据训练大量无标注样本,分割结果较好。Yang等人[19]提出了一个基于图嵌入的半监督学习网络框架,可以共同预测伪标签和图形中的邻域上下文信息。但上述方法生成的伪标签部分效果欠佳,容易使网络错误学习。在这个问题上,Zhou等人[20]提出从矢状面、冠状面和轴向平面等多个平面挖掘共识信息,采用多平面融合生成更可靠的伪标签,减少了伪标签中出现的误差,有助于训练更好的分割网络。Liu等人[21]提出使用全连接条件随机场处理伪标签,提升伪标签精度,其改进了网络的并行空间和激励模块,能更好地保留图像边缘信息。
2 方 法
该文充分利用少量带有肝脏分割标记的CT图像来预测大量无标记的肝脏CT图像,提出一种基于协同训练[22]的肝脏CT图像自动分割方法,包括全监督训练、伪标签挑选和伪标签优化三个阶段。(1)将有标签数据输入3D U-Net和3D Res U-Net进行全监督训练,然后把得到的两个分割模型分别对无标签图像进行预测,得到多个伪标签;(2)利用两种分割网络之间的差异性,将得到的伪标签用Dice值进行挑选,挑选出Dice值较高的伪标签进行下一步处理;(3)把挑选后的伪标签用全连接条件随机场进行细化处理,提高伪标签的准确性。处理后的伪标签加入到训练集继续训练,直到第二步Dice值不再增大后停止训练。所提方法可以减少分割模型对肝脏区域手动勾画标注数据的依赖,同时还可以提升CT肝脏器官的分割结果精度。半监督分割网络框架如图1所示。具体方法如下所述。

图1 网络协同训练示意图
2.1 基于3D U-Net和3D Res U-Net的全监督训练
实验先把有标签数据分别输入到3D U-Net和3D Res U-Net进行全监督训练,训练网络中损失函数均采用DiceLoss,如公式(1):

(1)
2.2 挑选伪标签
将无标签数据分别输入基于3D U-Net和3D Res U-Net训练出的两个分割模型中进行预测,预测结果作为伪标签集。在半监督学习方法中,难点是如何选择可靠的伪标签加入到训练集中以扩大训练集,该文选用常用的评估指标Dice(Dice similarity coefficient)值的大小来判断,如公式(2)所示。Dice值超过0.85的伪标签在下一步进行标签优化。

(2)
式中,P1和P2分别代表3D U-Net与3D Res U-Net网络对同一CT图像的分割结果。
2.3 基于全连接条件随机场的伪标签优化
在网络训练中,若有通过3D U-Net与3D Res U-Net协同网络预测产生精度不高的伪标签,未作处理便加入训练集中进行训练,会导致迭代训练过程中网络学习出错,致使错误累积。Dense CRF可以优化伪标签中粗糙和边缘不确定的标记,修补零星的区域,使其趋近于金标签。Dense CRF的能量函数[23]如下:
(3)
式中,τe(ki)为一元势能,用于衡量像素点的类别概率,τe(ki)=-logP(fi),fi为经过分割网络后像素i得到的预测结果,P(fi)为f的概率;τf(ki,kj)为像素i和像素j上的预测结果ki,kj之间的二元势能,解释各个像素点之间的关系,表达式如下:
(4)
式中,ω1,ω2为线性组合权重;μ为标签兼容性函数,μ(ki,kj)为标签兼容项[24],它约束了像素间传导的条件,当ki≠kj时,μ(ki,kj)=1,否则为0;像素之间的邻近程度和相似度由系数σα和σβ控制;σγ=1,其将较小的独立区域去除;mi,mj分别为像素i和像素j的位置关系,ni,nj分别为像素i和像素j的强度值。二元势能函数会多于注意到具有相似位置m、相似强度n但具有不同标记的k像素。能量E(Z)越小,预测的类别标签m就越准确。
在实验中,预测的伪标签用Dense CRF进行优化,可以提高伪标签的准确度,使其更趋近金标签。
2.4 具体训练方案
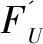
Algorithm1:半监督训练算法
I.Network training
Input:输入有标签数据集FL={XL,YL}
Output:ModelMU,MR//MU为3D U-Net网络模型,MR为3D Res U-Net网络模型
1:Training 3D U-Net,3D Res U-Net
2:Save modelMU,MR
II.Semi-supervised training
Input:输入无标签数据集FU={XU}
1:Load modelMU,MR
2:fori=1,2,…,Ndo //i表示样本集编号

4:Compare∈YU
5: OptimizeYUwith Dense CRF
6: end for
7:until converged
3 实验结果与分析
3.1 数据及预处理
实验数据来自公开数据集2017 MICC AI LiTS肝脏肿瘤分割挑战赛(https://competitions.codalab.org/competitions/17094),其中包括0~130号共131例的腹部CT图像及其金标签。将数据中的肝脏和肝肿瘤的标签融合为一个,肝脏CT图像大小为512×512×L(其中L为CT数据中的切片数量)。将肝脏CT图像的灰度值标准化到[-100,100]。
3.2 参数设置
网络学习率设置为1e-4;设置epoch=200;设置batch size=1或2。实验使用的服务器配置如下:Intel E5-2620 v2@2.10 GHz CPU和NVIDIA RTX 3090显卡,主要的软件环境Python3.7、CUDA11.1、Keras2.2.5等。
3.3 评估指标
Dice系数和Iou(Intersection over union)是医学分割任务中常见的评估指标,它们都是用来衡量网络分割结果与金标准mask之间的相似性,表达式如下:

(5)
(6)
式中,P为预测所得到的结果区域,G为金标签,即医师所标注的真实区域。
特异性(specificity)和灵敏度(sensitivity)两个指标经常用来描述分类器的性能,前者指识别出的负例占所有负例的比例,后者指识别出的所有正例占所有正例的比例,表达式如下:

(7)
(8)
式中,TP是真阳性,分类器预测结果为正样本,实际也为正样本,即正样本被正确识别的数量;TN是真阴性,分类器预测结果为负样本,实际为负样本,即负样本被正确识别的数量;FP是假阳性,分类器预测结果为正样本,实际为负样本,即误报的负样本数量;FN是假阴性,分类器预测结果为负样本,实际为正样本,即漏报的正样本数量。
3.4 分割结果
实验在2017 MICCAI LiTS肝脏肿瘤数据集随机选取100例CT图像作为训练集,剩余31例作为测试集。在这100例数据中将其分为30、50、70例有标签数据,剩下数据依次分为70、50、30的无标签数据。将这几种实验设置下获得的模型分别对测试集进行分割预测,将其结果与3D U-Net、3D KiU-Net[25]、3D SegNet[26]和3D ResU-Net使用100例灰度图像及其真值标注的全监督分割结果进行对比。
表1展示了四种网络的全监督分割结果与文中方法在不同有标签占比下的比较结果。文中方法在有标签占30%时便可达到3D ResU-Net全监督分割的效果。在表2中可以看出,随着有标签数据的减少,四种分割网络的半监督分割结果明显比全监督的时候有所降低。

表1 不同标签数量占比下的分割性能比较

表2 不同标签数量占比下的半监督分割性能比较
当有标签数据的占比达到70%时,文中方法比全监督3D ResU-Net的Dice值高出1.32%,比全监督3D U-Net的Dice值高出3.67%。为能更直观地展示文中方法的分割结果,在MP=70%的时候选取部分结果的分割图像,如图2所示。在图3展示了分割结果的三维可视化。

图2 分割对比网络效果图

图3 3D可视化分割图
4 结束语
提出的基于半监督的3D肝脏CT图像自动分割方法,有效利用了CT图像的三维信息,解决了医学图像需要大量有标签数据并且获取困难的问题,为医生诊断治疗节约时间。实验结果表明,该方法的肝脏分割精度相比3D U-Net等网络都有明显的提升。
在未来工作中,要进一步提高半监督学习中加入伪标签的模型的分割性能,达到用少量标签就可实现大量预测且达到高精度的效果。该研究还会将提出的半监督分割方法应用到其他医学图像数据集中,以提高该方法的普适性。
猜你喜欢
艺术家(2023年8期)2023-11-02
中老年保健(2022年4期)2022-11-25
肝博士(2022年3期)2022-06-30
小哥白尼(军事科学)(2022年2期)2022-05-25
家庭医学(下半月)(2020年4期)2020-05-30
红领巾·萌芽(2019年8期)2019-08-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
安徽医科大学学报(2016年12期)2017-01-15
公民与法治(2016年10期)2016-05-17
