
景区行人检测YOLOv5-GSPE算法模型研究与实现
2023-09-14 09:31陈宇拓
计算机技术与发展 2023年9期
何 薇,陈宇拓
(中南林业科技大学 计算机与信息工程学院,湖南 长沙 410004)
0 引 言
景区中的行人高密度、小目标、易遮挡的特点尤为显著,行人检测作为计算机视觉领域的一个重要分支,对景区的安全管理有着重要的现实意义。目前基于深度学习的行人检测算法在准确度和检测速度方面都有明显提升,但很多算法只是在单维度方面不断深究,引入多种复杂模块来提升检测精度,很难兼顾算法模型复杂度以及检测速度,同时在行人遮挡、行人小目标检测等方面仍存在诸多挑战。
针对行人检测的现状,目前主流的行人检测算法主要分为两类:单阶段(One-stage)检测算法[1]和两阶段(Two-stage)检测算法[2]。One-stage检测算法包括SSD[3]、YOLO[4]算法等。Huang等[5]提出一种基于改进的YOLOv5的微小物体检测算法,将提取特征划分为四种特征分类,以增强原始输入图像的特征。郭磊等[6]将通道注意力和空间注意力结合的CBAM[7]注意力模块引入YOLOv5网络中,并利用图像增强算法对图片进行预处理后进行迭代训练,提高算法模型的鲁棒性。此类算法主要通过回归预测出目标边界框,能够以较高的速度和精度完成检测。
Two-stage检测算法包括Faster-RCNN[8]、Mask-RCNN[9]算法等。音松等[10]基于Mask R-CNN网络的Mack分支中增加了CFPN模块和CA[11]注意力模块,降低了遮挡对于行人检测精度的影响。此类算法发展较早,在检测精度方面有一定优势,但是整个过程计算量大、检测速度慢,很难满足实时性需求。由于景区行人检测的应用需要兼顾检测速度和精度,因此,基于One-stage检测算法中最新的YOLOv5算法模型,该文提出了YOLOv5-GSPE(GhostConv &SPPF &PrFPN &EIoU)综合改进算法模型,主要解决如下几个方面问题:
(1)将GhostConv[12]和改进后的SPPF模块集成到主干网络中,降低模型复杂度,增强提取的目标特征信息,降低行人遮挡及小目标的漏检率。
(2)针对YOLOv5模型特征金字塔网络FPN[13]结构忽略原始输入特征融合的缺点,提出一种增强的特征金字塔网络PrFPN结构,提升模型的检测精度。
(3)基于YOLOv5模型中GIoU损失函数在预测框位于真实框内部情况下不准确定位的问题,采用EIoU[14]损失函数代替GIoU,并引入正态分布对EIoU损失函数进行优化计算,提升边界框的回归精度,进而改善遮挡及小目标行人检测效果。
1 算法模型网络结构
Redmon J等[15]提出了One-stage检测算法YOLO,目前YOLO系列算法已更新至YOLOv5,YOLOv5有多种版本:YOLOv5s、YOLOv5l、YOLOv5m、YOLOv5x等。其中YOLOv5s是最小的算法模型,考虑到检测类别的单一性,该文基于YOLOv5s算法模型提出YOLOv5-GSPE算法模型,其网络结构如图1所示。

图1 YOLOv5-GSPE网络结构
在主干网络中使用GhostConv取代Conv作为卷积层,降低算法模型的复杂度,提高模型检测速度;将SPPF模块(见图1中标注为①的区域)中max pooling操作改为空洞卷积(Dilated Conv),减少行人特征信息的丢失。提出一种增强的特征金字塔网络PrFPN结构(见图1中标注为②的区域),丰富多尺度特征融合。
2 算法模型改进方法
YOLOv5-GSPE算法模型主要包括对主干网络中的卷积层、SPPF模块、特征金字塔网络以及损失函数等。
2.1 主干网络
2.1.1 卷积层优化
YOLOv5主干网络卷积层为常规卷积Conv,使用各个通道中的特征图与多个卷积核进行运算。假设Input端输入尺寸为w*s的图像,Output端输出尺寸为w'*s'的图像;c和n分别是Input端和Output端的通道数,则Conv的计算总量Q1如公式(1)所示。
Q1=w*h*c*n*w'*h'
(1)
GhostNet[12]提出的GhostConv将卷积流程主要分为常规卷积和Ghost卷积,如图2所示。
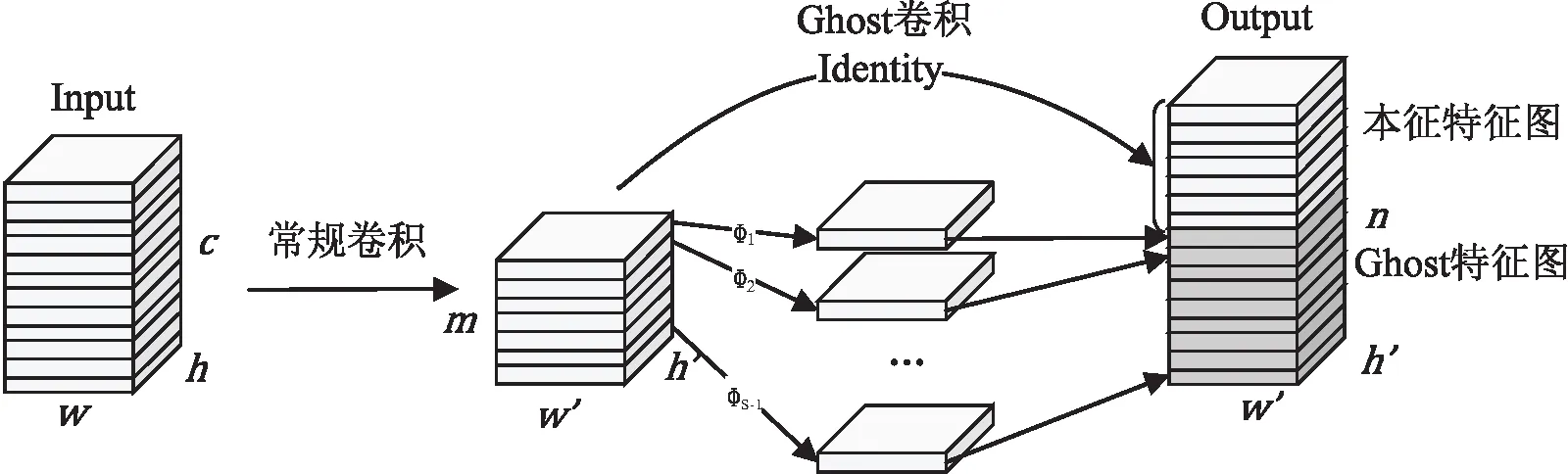
图2 GhostConv流程示意图
常规卷积计算总量Q2见公式(2)。假设s(s>1)为Ym*w‘*h’通道产生的总映射数,其中包含1次恒等变换(Identity)将Ym*w‘*h’映射成本征特征图,以及s-1次单位映射运算Φij操作生成Ghost特征图。Ghost特征图与本征特征图连接成n个通道的输出特征图,其计算总量Q3见公式(2)。
(2)
d*d为单位映射运算Φij操作的平均卷积核大小,与w*h具有相似大小,c为Input端输入特征图通道数,远大于s,即c>>s,因此,GhostConv的计算总量为Q2+Q3,通过公式(3)能近似计算出Conv的计算总量Q1是GhostConv计算总量的s倍,由s>1可知GhostConv具有更小的计算量。
(3)
综上所述,GhostConv相比Conv减少了卷积过程的计算量,进而表明卷积过程中参数量的减少。因此,将GhostConv代替主干网络中的Conv能够有效降低算法模型复杂度。
2.1.2 SPPF模块的改进
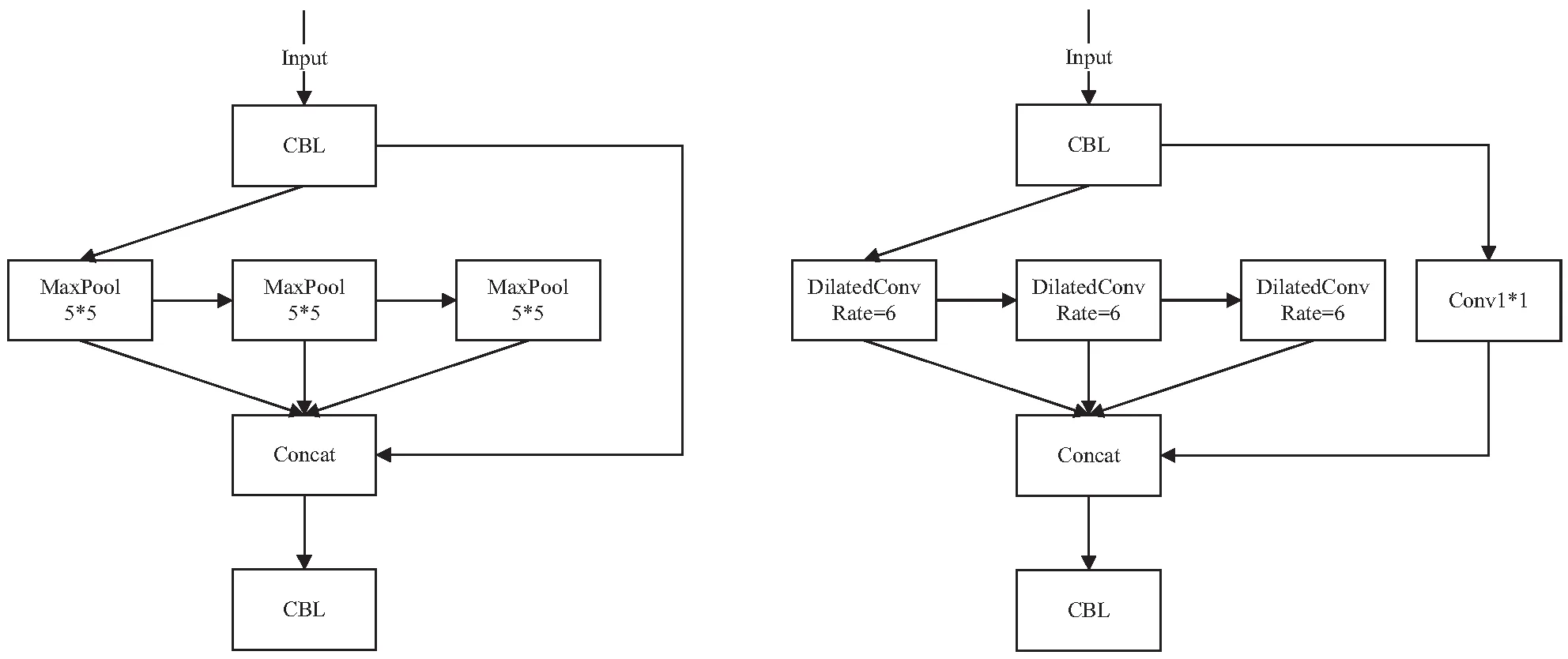
YOLOv5主干网络中SPPF模块如图3(a),通过串行max pooling操作集合不同感受野的特征进行连接,虽然一定程度上增强了主干网络的感受野,但max pooling操作不可避免地造成一定的特征信息丢失。因此,改进的SPPF模块使用空洞卷积来代替max pooling操作,如图3(b)。
(a)SPPF模块 (b)改进的SPPF模块
空洞卷积和池化操作都可以增强感受野,但池化操作增大感受野的同时不可避免地造成特征信息丢失。空洞卷积可以尽量保留内部数据结构和避免下采样,增大感受野的同时不改变图像输出特征图的分辨率,减少了特征信息丢失。通过控制不同的卷积核参数来设置空洞卷积速率,可以灵活地替换三个串行max pooling操作,丰富主干网络提取的特征。改进的SPPF模块降低行人特征信息丢失,进而增强主干网络的特征提取,降低遮挡及小目标行人的漏检率。
2.2 特征金字塔网络
YOLOv5算法模型中特征金字塔网络为PANet结构,PANet结构中同层相邻连接方式导致输出特征图忽略了原始输入特征的融合。如图4所示,该文基于BiFPN[16]的启发,提出了增强的特征金字塔网络PrFPN结构,在输出特征图(上采样特征图,如N3、N4、N5)中分别利用了同层的原始输入特征图(如C3、C4、C5)的特征融合,如图中虚线所示。
PrFPN结构基每层的输出特征图将上采样特征图、下采样特征图(如B3、B4、B5)和原始输入特征图进行特征融合,丰富了特征融合多样性,更好地利用原始输出特征信息,增强小目标特征敏感度,提升算法模型检测精度。
2.3 损失函数
YOLOv5算法模型采用GIoU损失函数,主要通过预测框A与真实框B的最小闭包区来计算损失函数值,当预测框位于真实框内部时,即A∩B=B,就无法精确定位效果最佳的预测框。
针对以上问题,该文选择了更为出色的EIoU损失函数(LEIoU),将预测框与真实框的重叠区、长宽比以及中心点距离三个参数都融合到计算中,如式(4)所示。

(4)
其中,r为A与B中心点之间的欧氏距离,A与B之间的长宽之差分别为h和w,A与B最小闭合区为C,其高度为Ch,宽度为Cw,对角线距离为c。LEIoU融合多参数能够更加精确地计算损失函数值,但式(4)中的损失函数LEIoU是随着定位损失(IoU)线性变化的,不利于模型训练。因此,引入正太分布函数对LEIoU进行新的定义,用LEIoU-N表示,见公式(5)。
(5)
其中,μ=-0.6,σ2=0.2,C=0.03为调整常数。
如图5所示,LEIoU都随着IoU的不断增大线性下降,但LEIoU-N随着IoU的梯度增大加速减小。IoU在逐步增大的过程中波动对LEIoU-N影响是逐步减少的,表明LEIoU-N比LEIoU的稳定性更好,更具合理性。
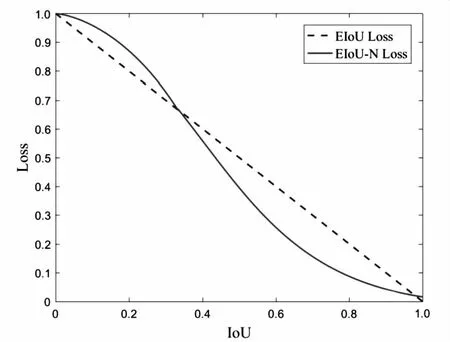
图5 LEIoU与LEIoU-N对比示意图
3 实验结果与分析
实验环境如下:操作系统为Windows 11,CPU为AMD Ryzen 7 4800H 2.9 GHz,运行内存为16 GB。算法模型基于Pytorch深度学习框架,编程语言为Python。
3.1 实验数据来源
该文使用了两种公开的数据集进行训练及测试,一种是数据建模和分析竞赛平台Kaggle(https://www.kaggle.com/)网站公开的行人检测数据集Pedestrian,其中训练集944张、验证集160张和测试集235张。另一种是生物识别与安全技术研究中心(http://www.cbsr.ia.ac.cn/)公开的密集行人基准数据集WiderPerson,其中训练集8 000张、验证集1 000张和测试集4 382张。两种实验数据集包含了不同姿态、相互遮挡以及多种场景下的行人,有效提升了行人检测的鲁棒性。
3.2 检测精度实验结果分析
两个算法模型对比300轮迭代训练中的变化明显的前50轮迭代的平均精度(mAP)及Loss值下降曲线,如图6所示,其中横坐标为训练的迭代轮次(epochs),纵坐标为每轮迭代的mAP。基于Pedestrian数据集的实验中,YOLOv5-GSPE算法模型的Loss值下降曲线及mAP上升曲线在收敛稳定性上优势明显。基于WiderPerson数据集的实验中,两个算法模型的Loss值下降曲线及mAP上升曲线收敛都较为稳定。综合来看,两种数据集在到达稳定迭代轮次后,YOLOv5-GSPE算法模型在mAP上优于YOLOv5s算法模型。

图6 两种数据集实验的mAP及Loss值下降曲线
在300轮迭代中,Pedestrian数据集实验的最高mAP达到了95.87%,相比YOLOv5s算法模型的91.82%提升了4.05百分点。WiderPerson数据集实验的最高mAP达到了77.46%,相比YOLOv5s算法模型的74.18%提升了3.28百分点。由公式(1)和(2)采用YOLOv5和YOLOv5-GSPE算法模型计算得到的总参数量分别为7 012 822和6 135 420,其复杂度降低12.51%。
将YOLOv5-GSPE算法模型与目前主流标准版本的目标检测模型进行对比实验,在召回率(Recall)、mAP和推理时间(Time)三个方面进行对比,Pedestrian数据集实验对比结果如表1所示,WiderPerson数据集实验对比结果如表2所示。

表1 Pedestrian数据集模型对比实验结果

表2 WiderPerson数据集模型对比实验结果
综上所述,通过表1和表2的对比结果可以看出, YOLOv5-GSPE算法模型在检测速度和精度方面, 较目前几个主流目标检测算法模型有一定优势。
3.3 消融实验结果分析
消融实验是针对YOLOv5-GSPE算法模型中每个改进合理性验证实验,主要有GhostConv卷积层、SPPF模块、特征金字塔网络PrFPN结构和损失函数EIoU四个改进。首先对各个改进进行独立的精度实验评估分析,如图7所示。

图7 各模块精度评估对比曲线
如图7所示,GhostConv代替Conv作为主干网络卷积层可以有效降低模型的复杂度及计算量,但对mAP的收敛稳定性造成影响。改进的SPPF模块能够一定程度上提升模型mAP,降低特征信息丢失可以提高模型检测效果,额外的开销导致mAP曲线收敛速度变慢。特征金字塔网络PANet结构改进能够大幅度提升模型mAP,增强mAP曲线稳定性。优化后的EIoU损失函数代替GIoU损失函数,能够小幅度提升mAP。基于Pedestrian数据集下训练和推理,实验结果如表3所示。
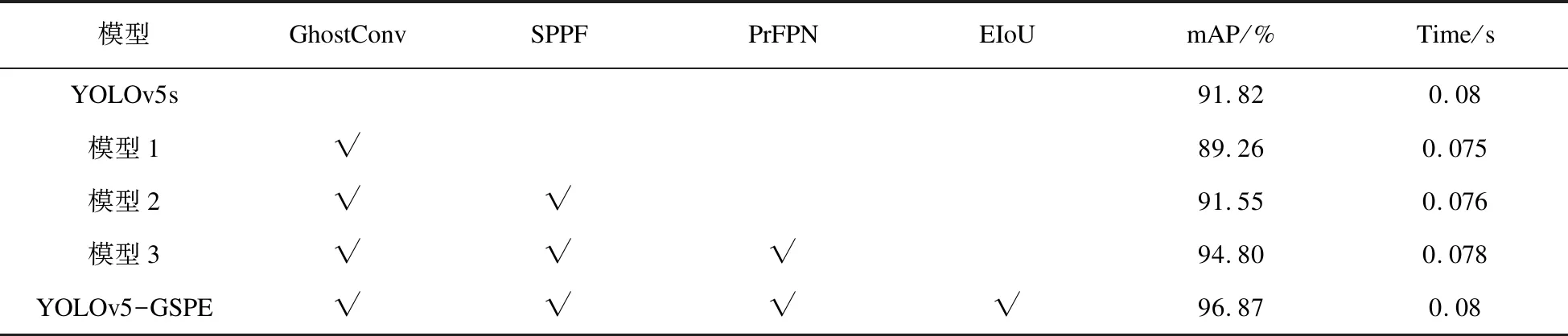
表3 消融实验结果
如表3所示,模型1基于YOLOv5s模型进行改进,检测精度有所下降。模型2在模型1基础上优化SPPF模块,提升了模型精度,少量的开销影响推理速度。模型3基于模型2提出的改进PrFPN结构,可以大幅度提升模型平均精度。YOLOv5-GSPE算法模型在模型3基础上引入优化后的EIoU损失函数,进一步提升模型检测精度。
3.4 检测实验效果分析
(1)Pedestrian数据集的检测效果分析。
如图8所示,YOLOv5-GSPE算法模型更为丰富的特征提取带来行人目标特征符合度下降,进而使得锚框置信度相比YOLOv5s算法模型稍有下降。由图8(a)可以看出,YOLOv5-GSPE算法模型能够对图中远近大小成像行人信息实现准确检测,对于遮挡目标也能保证一定的检测精度,而YOLOv5s算法模型(图8(b))对于较远成像的小目标的行人漏检率较高,如图8(c)与(d)局部放大图对比所示。
(2)WiderPerson数据集检测效果分析。
图9为对场景二中遮挡行人检测效果对比,由图9(a)可以看出,YOLOv5-GSPE算法模型对拥挤遮挡的行人相比YOLOv5s算法模型的检测效果更好,但遮挡行人的特征并不完整,容易导致算法模型重复锚框,如图9(b)所示,其漏检区域从图9(c)和(d)局部放大图可以清晰对比。

图9 WiderPerson数据集检测效果对比
综上所述,YOLOv5-GSPE算法模型相比YOLOv5s算法模型的检测效果更好,尤其对小目标行人以及遮挡行人的漏检率更低。
4 结束语
针对景区场景下的行人表现特征,目前的行人检测算法在景区场景下应用存在小目标及遮挡行人漏检率高、模型复杂度高、计算量大等问题。该文提出YOLOv5-GSPE算法模型,通过GhostConv和改进的SPPF模块优化主干网络;提出增强的特征金字塔网络PrFPN结构,在输出特征图中加入了原始输入特征的融合;用优化后的EIoU损失函数代替GIoU损失函数,提升边界框的回归精度。
实验结果表明,YOLOv5-GSPE算法模型在均衡检测精度和速度的情况下更具综合优势,同时大幅度地减少了模型复杂度,对小目标行人和遮挡行人检测漏检率有明显改善,为景区的行人智能检测应用提供一种有效途径。但算法模型中特征提取明显增强,使其在非拥挤场景下的应用中对目标背景的抗干扰度下降。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
意林(2021年5期)2021-04-18
电子制作(2019年11期)2019-07-04
扬子江(2019年1期)2019-03-08
电子制作(2018年11期)2018-08-04
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年6期)2017-06-07
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
电视技术(2014年19期)2014-03-11
