
基于聚类的LNS算法求解异构VRP问题
2023-09-14 09:51赵雄,李琳
计算机技术与发展 2023年9期
赵 雄,李 琳
(沈阳航空航天大学 理学院,辽宁 沈阳 110136)
0 引 言
车辆路径规划问题(vehicle routing problem,VRP)是规定一组车辆在一组客户集合间运输货物,并使车辆路径满足相应目标函数要求的研究,是物流运输行业中十分重要的一个研究命题,是优化物资分配,调度运输的方法之一。VRP自1959年被提出后便得到了学者们的关注,形成以VRP为基础的各项分支研究。HVRP便是其中之一,主要研究不同车辆在运输调度中的物资分配问题,其中车辆以车辆归属、车辆属性等进行区分。在HVRP下存在不同的研究方向,比如带时间窗的HVRP问题[1-3](heterogeneous fixed fleet vehicle routing problem with time windows,HVRPTW)、带取送货的HVRP问题[4-5](heterogeneous fixed fleet vehicle routing problem simultaneous pickup and delivery,HVRPSPD)等。
VRP已知是NP难问题,可知HVRP也是NP难问题。精确方法求解问题具有一定难度,为能快速求解问题,部分学者通过模拟自然演变,采用元启发式方法进行求解,并取得了不错的成果。Wu[6]在求解车辆数量限制下的VRP时,使用自适应大邻域搜索算法,并将算法的消除与添加两个变换步骤加以改进,将客户运用聚类方法分类,并在消除变换过程按照聚类结果消除,避免单客户消除方法中客户返回原位置这种算力上的浪费。Molina[7]在求解HVRPTW时设计了一种具有局部搜索的混合蚁群算法(ant colony system,ACS),称为memetic-ACS算法,并在其实验中得到了新的最优解。
鲁建厦[8]研究了不同初始解对算法的影响,并证明使用聚类算法生成的初始解能使算法收敛速度有较大改进。Meliani[9]和Wei[10]在其研究中就用C-W节约算法来求解模型的初始解。Jin[11]使用多启动策略来增加每次迭代的初始解的多样性,以此加大产生当前最优解的可能性。闫军[12]通过将客户集合分成不同的子群,简化数据复杂度然后再进行求解。
为提高初始解效率,该文通过均值漂移聚类算法将客户分成多个子类,在初始化时优化每条路径对客户个体的选择,从而优化算法初始解。而后通过单链设计优化邻域变换方法,加快LNS算法的收敛速度,并通过三组实验验证了MS-LNS算法的合理性及有效性。
1 问题描述与数学模型
HVRP包括车辆数量限制下(heterogeneous fleet vehicle routing problem)的HFVRP和无车辆数量限制(fleet size and mix vehicle routing problem)的FSMVRP两类[13]。HFVRP主要求解在现有资源下如何优化分配,而FSMVRP则更侧重于市场需求的最优调度方案。该文研究了FSMVRP。
1.1 问题描述
该模型以最小化总成本为目标函数值。共有N个客户需要服务,每个客户的需求量为qi。车场标记为0点。运输车辆数量为K,共有M种车辆。异构车辆按照最大载荷量区分,第k种车辆的载荷为Qk,启动成本为Ck,单位行驶成本为Cu。车辆从车场出发服务客户,服务完后回到车场。dij表示客户i到j的距离。
1.2 数学模型
(1)
s.t.

(2)
(3)
(4)
其中,式(1)F为目标函数,最小化车辆总成本;式(2)保证每辆车必经过0点,即车辆必从0点出发且回到0点;式(3)保证每个客户只有一辆车服务,且只服务一次(此条件可以消除子路径的可能性);式(4)保证车辆不会超载。xijk为0-1变量,当车辆k经过弧ij时为1,否则为0。
2 基于均值漂移聚类的LNS算法
在求解HVRP问题时常使用随机算法或贪心算法生成初始解。相较于随机算法,贪心算法获取的初始解距最优解更近,能加快算法前期收敛进度,但由于贪婪算法的最近邻选择机制减弱了初始解群的多样性,使算法容易出现早熟现象。为找到更合适的初始解,加快算法收敛,该文提出使用均值漂移聚类算法区分客户子集,依照客户子集初始化客户列表。
2.1 编 码
总路径Ω采用单链编码方式。客户从1开始编号V={1,2,…,N}。车辆依照类型从客户集后一位开始编号M={N+1,N+2,…,N+L},其中任意一个元素表示一类车辆。每辆车的子路径Ωk表示为(N+1,3,5,9,12,4,7),其中起始点为车辆类别,其后所有点为子路径中的客户点。总路径表示为Ω={Ω1,Ω2,…,ΩK}。
2.2 均值漂移聚类算法初始化
均值漂移聚类的主要方法是在客户区域内设置M个移动点粒子Xm,在每次迭代过程中移动点粒子搜索扫描半径内的所有客户点,依照公式(5)(其中Sm为fm限制条件)生成移动向量来更新移动点坐标(6),当某些移动点十分接近的时候将这些移动点合并,直到所有移动点不再变化时停止迭代。此时剩余移动点的个数就代表客户点聚类的个数,而每个移动点扫描过的客户就属于此类别的客户子集。
(5)
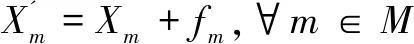
(6)
初始化步骤为:
Step1:随机选择车辆k,生成子路径Ωk;
Step2:随机选择客户子集Vl,l∈M,随机选择其中一客户作为当前点i,添加到Ωk末尾;
Step3:选Vl中距当前点i最近的客户点j=argmin{dij},∀j∈Vl添加到Ωk末尾,令i=j;
Step4:判断下列三种情况:若车辆k达到载荷上限或最长工作时间,Vl中还存在未服务客户则随机选择车辆k=k',重新生成子路径Ωk并返回步骤3;若车辆k未达到载荷上限和最长工作时间,Vl中客户已完全服务,则返回步骤2;若车辆k达到载荷上限或最长工作时间,且Vl中客户已完全服务,则进行步骤5;
Step5:判断客户是否全部分配完成:是,则初始化完成;否,则回到步骤1。
2.3 邻域变换
该文使用四种邻域变换方法:insert、swap、two-swap、载重少车辆重新分配(redistribution)。insert为将总路径Ω中随机位置的客户插入到此路径的其他位置当中;swap是随机选取Ω中两个不同的客户互相交换其位置;two-swap是同时选4个不同客户两两交换位置(two-swap相当于执行两次swap)。在每次迭代时多次搜索当前解邻域,尽可能找到使目标函数值更好的解。
由于编码的特殊性质,使得前三种变换方法不用处理子路径内及子路径间的区别,且车辆编号与客户编号在同一编码当中,使得前三种变换方法产生了两种不同的变换形式,见图1和图2。

图1 insert变换

图2 swap变换
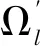
Step1:检测总路径中每条子路径载货率是否达到标准h;
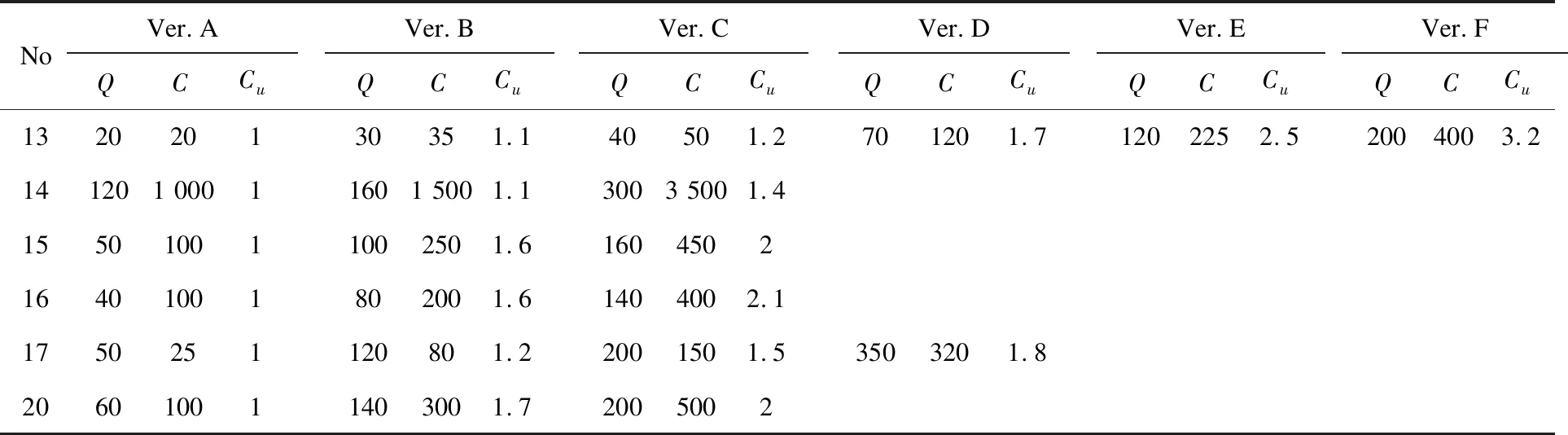
Step2:将所有未达到标准的子路径从总路径中删除,生成客户子集Vl;
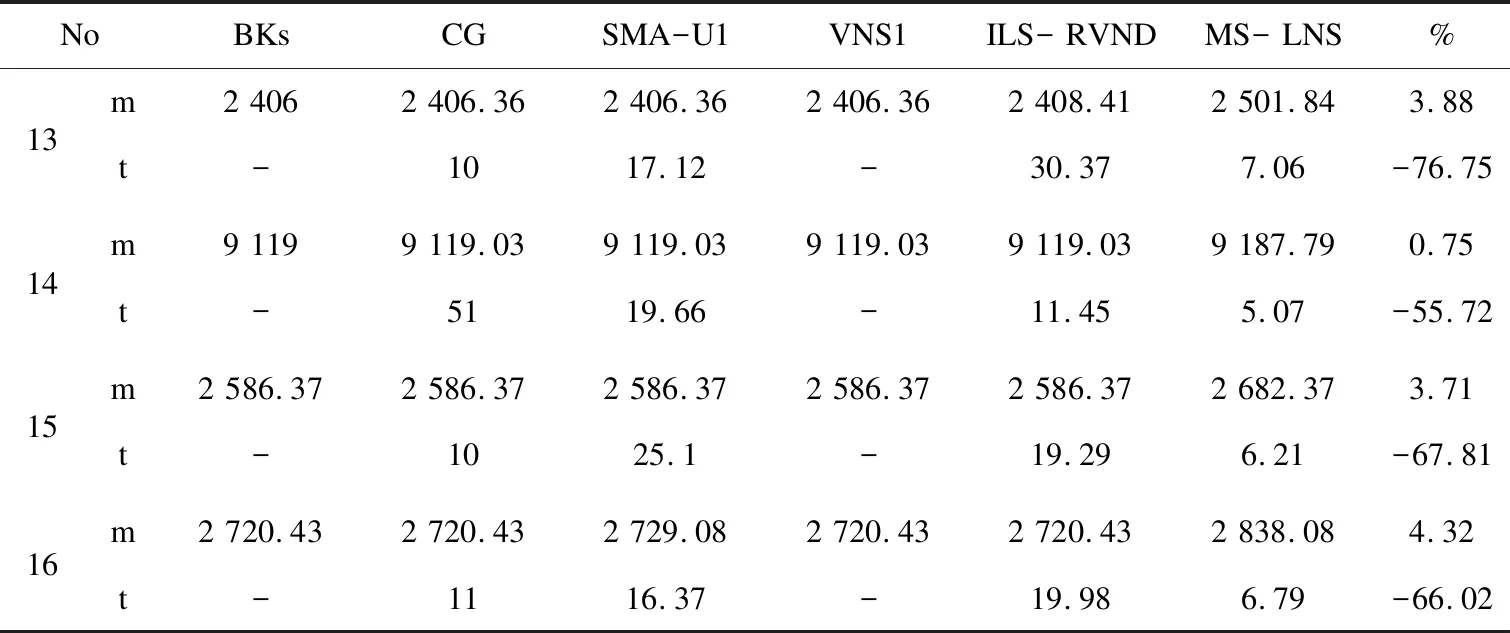
Step3:计算Vl中总客户需求量Qd,判断其与不同车辆载荷间的关系:若Qd>max{Qk},∀k∈K则转到步骤4;若Qk>Qd>hQk,∃k∈K则转到步骤5;若Qd Step5:选择对应车辆k,按照总路径初始化方式生成子路径; 该文采用模拟退火算法的接受准则判断每次变换后的路径能否替换当前解。当前解的目标函数值高于当前个体最优解时,通过计算公式(7)得到接受概率,再通过轮盘赌形式决定是否接受当前解。其优点在于前期温度值T较高时使粒子具有较大的容错能力,可以让粒子在邻域内快速移动;而后期T值减小使粒子容错能力减弱,增强了粒子邻域搜索能力,加快收敛进程。每当接受准则成功执行时需要更新温度值T=ρT。其中ρ为温度变化率。 P=e(F(Papb)-F(Ω))/T (7) 算法流程见图3。 图3 MS-LNS算法流程 先使用聚类算法将客户分为多个子群,而后对每个子群使用贪婪算法,这样既能兼顾贪婪算法对初始解群的优化,也能保证初始种群的多样性。该文通过单链编码方式改进变换方法使得每次变换的空间更大,搜索速度更快。对于使用率较差的车辆使用redistribution变换重排。以此三种方式对LNS算法进行改进,加快LNS求解速度。 使用Golden[14]及Penna[15]提供的13-17、20号算例和对应车辆数据(表1中共有六种不同的运输车辆Ver.A-Ver.F),以及Solomon[16]中c201、r201、rc201算例进行实验。Solomon算例使用20号算例中车辆数据进行实验。表1中Q为车辆载荷,C为车辆固定成本。 表1 车辆数据 为保证算法的收敛速度与跳出局部最优的能力,需要优化现有的算法参数。文中算法涉及两个参数,即聚类算法扫描半径r和模拟退火温度变化量ρ。分别通过以下两种方式计算适合文中算法的参数值: 3.2.1 聚类算法扫描半径r 为保证使用均值漂移聚类时不会出现过多孤立点,保证客户集合分类符合实际,采用箱型图检测客户点距离并尝试1/4位数,中位数,3/4位数做扫描半径的效果。15、16号算例为50个客户点(图4(a)),17号算例为75个客户点(图4(b)),20号算例为100个客户点(图4(c))。 图4 四组数据在1/4位数时的客户分类 四组客户数据在取中位数作为扫描半径时都无法对客户集合进行分类,取1/4位数时每组的分类情况如图4所示。在1/4位数周围取值进行验证时发现,相较于rc201,15号及17号客户数据的分类对扫描半径的取值十分敏感,令15号数据的扫描半径r=20.7时,分类个数缩减到3个。令r=19时分类的数据较r=20.2时有比较明显的变化,而r=17时15号客户数据则被分为六类。为保证分类质量,在3.2节计算当中使用1/4位数进行计算求解。 3.2.2 模拟退火温度变化率ρ 采用多组不同的变化率对算例进行检测,以检查不同变化率之间的差别,找到尽可能好的参数值。如图5所示,共设置4组参数值0.95、0.9、0.8、0.7。依照算法生成50个粒子迭代变换1 000次,总计10次实验的平均结果。 图5 模拟退火温度变化率ρ变化曲线 模拟退火的接受条件(7)中粒子每接受一次变换,温度变量T便会依照变化率ρ进行变化,当ρ过大时会导致温度T变化缓慢,粒子变换的容错能力过强,不利于粒子的局部搜索;而当ρ过小时T变化过快,会导致算法过快收敛,无法跳出局部最优解。可以看出不论在图5(a)还是在图5(b),当变化率ρ=0.9时,算法收敛能力最好。当ρ=0.8或0.7时,算法收敛能力相差不大,但都弱于ρ=0.9的时候,说明ρ=0.9时可以保持良好的收敛性能,具有较快的下降速度。 进行了三组仿真实验。实验一通过比较同种车辆下与异种车辆下的总成本、总路径长度及实际平均载货率,验证异构车辆在VRP中是否存在优势。实验二通过比较20号数据、c201、r201、rc201在MS-LNS算法及LNS算法下的实验结果,检验均值漂移算法是否对算法收敛有增益效果。实验三使用文中算法计算13-16号算例并与Penna[15]中结果进行比较。该文使用java编程,在Intel(R) Core(TM) i5-4200H CPU @ 2.80 GHz计算机上运行。 实验一:对17号算例进行10次计算,每次计算共得出四组数据:总成本、固定成本、移动成本及载重比,再将所得数据按照总成本大小顺序排列。为减少数据区间不同所造成的影响,使用相对数进行比较,其计算公式为:qR=qA/q,其中qR代表相对结果,qA代表数据绝对值,q代表各组数据的平均值。计算结果如图6所示。 图6 17号算例实验结果 其中,车辆类型B的使用量与总成本成反比,而载重比在总成本不断升高情况下有着逐渐下行的表现,说明在车辆低载重比的情况下难以达到最优解。分别比较异构车辆与其中四种单一车辆的计算结果,观察总成本、总路径长度及实际平均载货率之间的差别。 由表2可知,B类车辆的计算结果与异构车辆的计算结果十分相近,且比A、C、D类结果要好,该结果正好和图6中显示的各类车辆数量与总成本之间的关系相对应,且异构车辆问题中车辆的平均载重比在五类数据中最大,表示异构车辆问题中所有种类车辆都得到了充分的利用。由此可以证明,异构车辆的VRP模型相较于单一车辆的VRP模型具有一定优势。 实验二:运用MS-LNS算法和LNS算法分别计算20号算例、c201、r201及rc201算例10次,其中实验结果的平均值如图7所示。 图7 MS-LNS算法与LNS算法比较 可以看出,图7(a)和7(c)中两种初始化方案尚未产生较大差异,比较(a)(c)两图的迭代曲线可知:两种算法的收敛速度相当。在图7(b)和图7(d)中均值漂移算法使得初始值相较于使用贪心算法有较大改进,图7(b)中虽然MS-LNS在起始点位置的目标函数值与LNS相比稍差,但后续迭代过程中MS-LNS的收敛速度却比LNS的收敛速度要快,使得1 000次迭代后MS-LNS算法的结果要比LNS算法的更好。 实验三:将文中算法与四种算法进行比较,数据如表3~表5所示。其中FSMFD模型的目标函数为固定成本与移动成本总和最小,FSMF模型为固定成本最小,FSMD模型指移动成本最小。BKs指目前对应算例中的最优解值,CG算法及计算结果由文献[17]给出,SMA-U1由文献[18]给出,VNS1由文献[19]给出。时间(t)单位为秒。%为MS-LNS算法与ILS-RVND算法的增量百分比。从表3可以看出,文中算法在最优值(m)上与Penna[15]的改进算法还有一定差距。文中算法最优解与ILS-RVND算法的平均差距为2.67%。在求得文中算法最优解情况下所耗时间(t)要少,算例13所耗时间比ILS- RVND少20.39 s,算例14的时间少6.25 s,算例15少6.15 s,算例16少10.97 s。 表3 FSMFD模型结果 表4 FSMF模型结果 表5 FSMD模型结果 在FSMFD模型中MS-LNS算法的平均耗时较ILS-RVND算法减少了59.33%;在FSMF模型中平均耗时减少了66.58%;在FSMD模型中减少了66.15%。由此验证了文中算法的高效性和可行性。 在基本HVRP模型的基础上,根据客户点分布的空间特性,提出了结合均值漂移聚类的大邻域搜索算法,设计了三组仿真实验。三组仿真实验结果分别验证了异构车辆配送方案在求解VRP问题中的效果更好,表明均值漂移聚类算法在随机分布和聚类分布这两类客户数据下对LNS算法的收敛速度提高更有效果。未来的研究方向可以对车辆的不同属性,如车辆载荷、车辆移动成本等因素进行敏感性分析,研究不同属性变化情况对目标函数的影响。
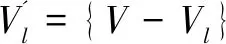
2.4 变换后解的接受准则

3 仿真实验
3.1 实验数据
3.2 参数设计


3.3 实验结果




4 结束语
猜你喜欢
中国纤检(2021年3期)2021-11-23
山东工业技术(2019年13期)2019-05-30
电子测试(2017年15期)2017-12-18
中国科技纵横(2017年14期)2017-08-17
中国经贸(2017年7期)2017-05-02
雷达学报(2017年6期)2017-03-26
中国学术期刊文摘(2016年2期)2016-02-13
新乡学院学报(2015年6期)2015-11-06
电网与清洁能源(2015年2期)2015-02-28
电子设计工程(2015年6期)2015-02-27
