
基于用户影响力和偏好一致性的社会化推荐
2023-09-14 09:31孙晶晶荀亚玲杨海峰
计算机技术与发展 2023年9期
孙晶晶,荀亚玲,杨海峰
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
0 引 言
互联网的快速发展涌现出海量信息,推荐系统通过对海量信息进行分析和过滤可以有效缓解信息过载[1]。推荐系统一般分为三大类:基于内容的推荐算法[2]、基于协同过滤推荐算法[3]和混合推荐算法[4]。其中,基于协同过滤的推荐凭借其不需要相关领域知识及不依赖推荐对象的特征抽取等特点,得到了广泛应用。然而,协同过滤推荐算法仍面临着严重的数据稀疏性和冷启动等问题。
针对协同过滤算法所出现的问题,额外的信息如社交网络中的社交信息[5]或上下文信息[6]等被引入到协同过滤推荐中。社交网络的兴起产生了大量的社交信息,社会化推荐通过结合评分信息和社交信息为用户提供个性化推荐,有效弥补了传统协同过滤中信息缺乏的问题[7]。传统社会化推荐算法旨在结合显式社交信息为用户推荐,但用户出于对隐私数据的保护导致可利用的信息较少使得推荐效果较差。且现有方法在刻画用户之间的信任度时未考虑到用户之间的偏好差异性[8-10],即用户间在相同的项目上的评分表明偏好存在差异。
此外,单一的直接社交关系并不能准确挖掘出用户的偏好,Li等人[11]通过引入用户间的间接信任关系缓解此问题。根据信任在社交网络中的存在形式,用户间的间接信任关系可以利用信任的传播性实现,而现有研究忽略了信任关系在传播过程中容易造成信任节点信息的丢失及信任在传播过程中信任值过小时两者容易形成不信任关系产生错误推荐。另外,大多数关于社交推荐的最新研究未注意到用户影响力在社交网络对目标用户的影响。研究表明用户影响力在信息传播和用户决策中发挥着关键作用[12]。
基于上述社会推荐所面临的问题,该文提出了一种基于用户影响力和偏好一致性的社会化推荐,该方法挖掘出了用户间隐藏的潜在信息,提高了推荐的准确性。主要贡献包括:
(1)结合评分信息从偏好一致性方向将用户间的信任关系量化,缓解用户的偏好差异性。
(2)引入用户平均信任值动态调整用户的信任网络,筛选出可利用的社交关系。
(3)提出信任传播稳定性最强路径算法(Trust Propagation Stability Path,TPSP),避免了信任节点信息的丢失。
1 相关工作
传统社会化推荐在借助用户的社交信息时[13-14]忽略了数据中隐藏的潜在信息对用户偏好的影响,导致推荐的预测准确性较差。因此,许多学者进行了大量研究。例如,Zhang等人[15]指出用户间缺少明确的社交关系,可从用户对商品的反馈中提取出用户间所隐藏的社交信息,改善推荐系统中社交信息的稀疏性。Guo等人[16]提出了一种基于信任的矩阵分解模型,通过将评级和信任信息融入到矩阵分解中,使得在预测未知项目的评分时,考虑了评分和信任信息的显性和隐性影响。陈碧毅等人[17]提出了一种融合显式反馈和隐式反馈的协同过滤算法,通过结合隐式反馈数据和显式数据训练出用户对物品的预测偏好,以缓解数据的稀疏性。朱敬华等人[9]采用模糊c均值聚类的方式对用户间的关系进行分类并利用信任类预测计算用户间的隐式信任值,提高了推荐的整体性能。然而,这些方法在挖掘用户间的隐式关系时缺乏对社会关系强度简单而有效的设计,导致用户的偏好存在着误差。
社会影响在社会化推荐中发挥着重要作用,当信息在社交网络中传播时,网络中的用户会受到其社交关系的影响,导致用户间的偏好具有相似性[18-19]。Jain等人[20]利用用户的中心性计算每个用户的目标函数,并根据鲸鱼算法识别局部和普遍的意见领袖。Riquelme等人[21]提出一种检测意见领袖的新方法,意见领袖是专注于特定主题的一类重要的有影响力的用户,通过自由调整用户对某个特定主题的兴趣和排他性来识别出社交网络中具有影响力的用户。凌子豪[22]提出具有高影响力的用户信任性更高,通过对用户评分进行影响力加权来区分高影响力用户对其他用户评分的影响。除了利用已有的信任关系,还可以利用信任网络上的信任传播来搜索可信任的用户。信任的传播性在社交网络中帮助用户提高了推荐的预测准确性。Golberk等人[23]提出了一种算法,该算法在信任网络中执行改进的广度优先搜索以找到间接邻居并聚合其信任值。Wang等人[24]通过考虑一跳或多跳来计算用户之间的直接和间接信任。信任信息的利用提高了推荐的准确性,除了信任信息外用户之间可能存在着不信任的关系可以结合信任感知网络收集的不信任信息,不信任信息有助于调节用户的信任网络,对信息的传播起到了筛选。Lee等人[10]通过引入指定的不信任关系和从信息传播中隐式推断的不信任关系对用户的关系进行筛选,降低了用户在推荐过程中的错误指引,提高了推荐的评级预测。虽然信任的传播性缓解了数据的稀疏性,但在传播过程中容易造成信任节点信息的丢失,对推荐结果产生负面影响。
综上所述,引入用户的偏好一致性刻画信任度丰富了用户的社交网络信息使得用户的偏好差异降低。此外,结合用户的影响力找路径,避免了信任节点信息的丢失。
2 基于用户影响力和偏好一致性的社会化推荐
根据社会关联理论,用户好友在用户的偏好上发挥着重要作用,志同道合的好友往往更能产生相互影响。该推荐算法通过结合用户的评分信息和社交信息挖掘用户间的隐式信任,用于构建用户的社交网络,并结合用户的信任传播阈值对社交网络进行筛选及引入用户的社会影响帮助找到目标用户的最佳信任邻居。基于用户影响力和偏好一致性的社会化推荐主要包括四个步骤:(1)根据评分信息计算用户的相似度;(2)结合用户项目评分信息和社交信息刻画用户的信任度;(3)利用TPSP算法找到用户间一条最佳信任传播路径;(4)结合用户的相似度和信任度进行协同推荐。该算法的框架如图1所示。
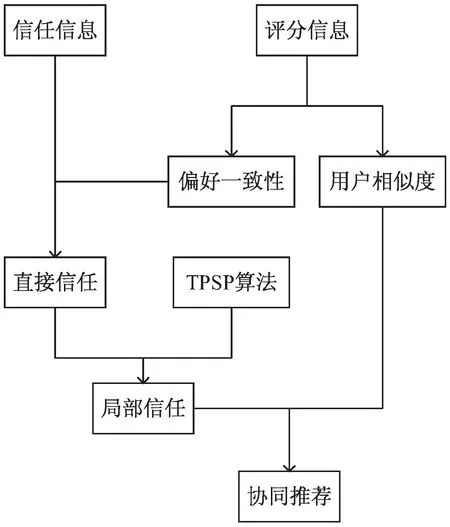
图1 基于用户影响力和偏好一致性的社会化推荐
2.1 用户相似度计算
推荐系统中,用户评分数据包含了用户对每个项目的偏好,基于用户的协同过滤算法从相似用户的偏好出发,为用户进行推荐。余弦相似度根据用户对项目的评分度量用户间的相似度,夹角的余弦值表示用户的相似度,其值越大用户的偏好越接近,适应于非用户偏好场景。首先将用户的评分信息转变成评分矩阵,然后根据用户的评分矩阵采用余弦相似度[25]得到用户间的相似度,其计算公式如下所示:
(1)
其中,Ruk、Rvk为用户u和用户v对项目k的评分,当两用户无共同项目时表示两用户的偏好相似度为0。
2.2 用户间的信任计算
社交信息作为推荐系统中重要的辅助信息,起到了缓解数据稀疏性的作用。在社交网络中用户与用户之间常以二值信任的形式存在,该社交信息未描述出用户间的信任差异性。在社交网络中,用户间的信任关系具有主观性,不同用户间的信任度存在着差异。
用户间信任度的评估方式具有多样性,现有研究仅仅从用户的社交信息角度度量用户间的信任权重,该文结合评分数据和社交信息挖掘用户间的隐式信息。使用评分数据时,在beta信任模型[26]的基础上进一步做了改进,从用户之间的偏好一致性出发并结合用户的社交信息量化用户间的信任值。在实际情况中,评分的不同,用户间会存在着偏好差异,评分标准的不同也会导致偏好发生变化。因此,可根据用户之间对公共项目评分的差异程度衡量用户之间在评分数据上的信任强度,偏好差异越小,用户之间的信任度越大。b(u,v)表示用户在同一项目上的偏好差异性,g(u,v)表示两个用户针对同一个项目表现出的偏好一致性。b(u,v)和g(u,v)计算公式如下所示:
(2)
g(u,v)=1-b(u,v)
(3)
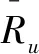
定义1 评分信任度trust(u,v):当用户间的评分差异越小时,用户的偏好越偏向于一致并结合项目占比可得到用户间基于评分的信任。trust(u,v)计算公式如下所示:
(4)
(5)
(6)
其中,G(u,v)为用户对相同项目表现出偏好一致性的总和,B(u,v)为用户对相同项目表现出偏好差异性的总和。Iuv为用户u和用户v共同评价的物品数量,Iu为用户u评分的项目总数。
定义2 用户在社交关系上的信任度P(u,v),计算公式如下所示:
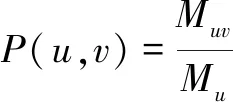
(7)
其中,Muv表示两个用户的共同好友的数量,Mu为用户u的好友数量。
定义3 直接信任度DTrust(u,v),计算公式如下所示:
(8)
用户之间的信任度不仅体现在项目的评分差异,还体现在交互项目的数量,由公式(8)计算得到用户之间的信任度,不仅量化了用户的信任强度还确定了用户间信任的方向。基于隐式信息构建的信任网络详细描述如算法1所示。

算法1构建隐式信任网络输入:用户-项目评分信息R,信任关系矩阵T输出:基于隐式信任信息的信任网络1For u,v in R2 common=Iu∩Iv3End for4For s in common5由式(2)^式(6)计算用户间评分信任度6End for7For u,v in T8 由公式(7)得到用户在社交关系上的信任度9End for10由公式(8)计算得到隐式信任网络
2.3 TPSP算法思想
将信任的传递性引入到社交网络中,挖掘出了用户间的隐式联系。借助信任在社交网络的传播,可以推断用户之间的间接社会关系。间接社会关系往往存在于没有直接关系但有着相同兴趣的用户之间。在社交网络中,两个未连接的用户可能存在着若干条路径,不同的路径对信息的传播会产生不同的影响。虽然社交网络中包含了所有的节点信息,但节点数量较多且节点间的信任值、信任方向不同及信任传播过程中容易造成信任节点信息的丢失,故提出TPSP算法帮助用户找到一条最佳信任传播路径,以便更准确地评估用户间的间接信任值。算法2描述如下:
Step1:计算节点影响力,根据节点入度和出度的比值求出节点的社会影响。
Step2:计算信任传播阈值,不同的用户在社交网络中具有不同的信任传播阈值,可根据与用户存在着直接信任关系的用户求平均值并将其设置为阈值。
Step3:由信任阈值动态更新用户的信任网络。
Step4:结合用户的社会影响力查找用户之间存在的最短路径。

算法2信任传播稳定性最强路径TPSP输入:隐式信任网络trustnetwork;目标用户u输出:信任传播稳定性最强的一条路径path1For s in trustnetwork2 caluate influence(s)3 caluate aver //信任传播阈值δ=aver4End for5Update trustnetwork(u)6If v not in trustnetwork7 continue8Else remove edge(u,v) 9Insert influence to trustnetwork10Path=dijkstra(u,v)11If len(path)==012 continue13Then restore path
2.4 基于信任传播的信任值计算
在社交网络中用户之间的信任值是通过直接联系体现的,而用户之间的间接信任值却隐藏在用户的社交网络中无法直接体现。考虑到信任在社交网络中具有传递性,可根据信任的传递性计算用户间的间接信任值[27],其计算公式如下所示:
ITrust(u,v)=min(Tuw,Twv)
(9)
其中,ITrust(u,v)表示用户u和用户v的间接信任度,Tuw表示用户u和用户w的直接信任度,Twv表示用户w和用户v的直接信任度。
结合用户的直接信任度和间接信任度得到用户的局部信任度,其计算公式如下所示:
Trust(u,v)=DTrust(u,v)+ITrust(u,v)
(10)
2.5 评分预测
结合用户的相似度和信任度,α为调节用户的信任度和相似度所占权重的参数,计算公式如下所示:
ST(u,v)=(1-α)sim(u,v)+αTrust(u,v)
(11)
当α为0时,表示只根据用户的相似度对用户进行推荐。随着α的增加,信任度所占的权重逐渐增加,表现为相似度和信任度两个因素对用户偏好的影响。当α增加到1时,则表示仅考虑用户的信任度对用户进行推荐。评分预测通过调节参数α找到K个最近邻对未评分项目进行评分预测,其计算公式如下所示:
(12)
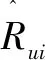
3 实验结果与分析
本节重点介绍了实验的数据集、对比算法、参数设置、评估指标和实验结果。
3.1 实验数据集与结果描述
使用了两个公开的数据集:FilmTrust数据集、CiaoDVD类别数据集。FilmTrust是一个名为FilmTrust的电影评级网络站点捕获的数据集。CiaoDVD是一个产品评论网站,用户可以通过写评论来评价产品。这两个数据集提供了大量的评级信息和社交信息。在FilmTrust数据集中评分范围从0.5到4,信任关系为0、1。在CiaoDVD数据集中,评级范围从1到5,信任关系为0、1。表1提供了关于两个真实数据集的详细情况。
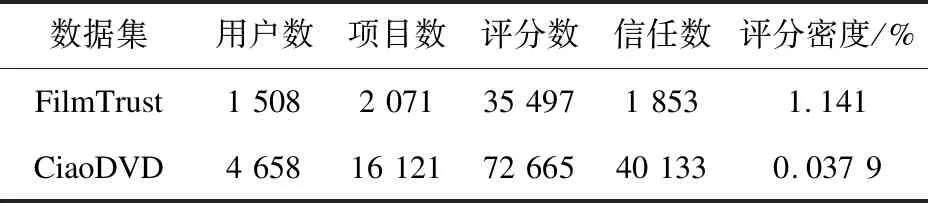
表1 数据集描述
3.2 参数分析
参数α为信任聚合的调和参数,不同的α表明用户的信任度和相似度所占的比例不同,其取值范围为[0,1],当α为0时,表明信任关系对用户的偏好不产生影响;当α为1时,表明用户的相似性对用户的偏好不产生影响;当0<α<1时,表明综合信任关系和相似性对用户偏好产生的影响。通过调节参数α评估算法的推荐质量。
3.3 实验评价指标
为验证所提算法的有效性,采用平均绝对误差(MAE)和均方根误差(RMSE)作为评估指标。MAE通常用于评估预测评级与真实评级的接近程度,RMSE为真实评分值和预测评分值之间的偏差。两指标的值越小,表明评级预测的准确度越高。其计算公式如下所示。

(13)
(14)
3.4 基准实验对比算法
(1)基于用户信任和项目评级的显性和隐性影响的协同过滤(TrustSVD)[16]:在SVD++方法的基础上集成显式和隐式信任作为额外的来源,以缓解数据稀疏和冷启动问题。
(2)用于推荐的社会关系的深度建模(DeepSoR)[28]:利用信任语句作为丰富的辅助信息,结合蚁群优化算法。
(3)社交推荐系统的协作用户网络嵌入(CUNE)[15]:采用DeepWalk从每个用户的反馈中提取社会信息,并将这些信息集成到MF中进行评级预测。
(4)具有基本偏好空间的社会化推荐(SREPS)[29]:利用推荐系统和社交网络中用户偏好的差异,以进一步改进社会推荐。
(5)基于有向信任的概率矩阵分解推荐算法(PMFTrustSVD)[30]:使用PMF分解信任矩阵提取信任者和受托者在社会影响力上的差异,并结合评分信息提取用户间的信任用于评级预测。
3.5 实验结果与分析
3.5.1 参数α对算法的影响
图2和图3中显示了参数α在FilmTrust数据集和CiaoDVD数据集上对MAE和RMSE两指标的影响。
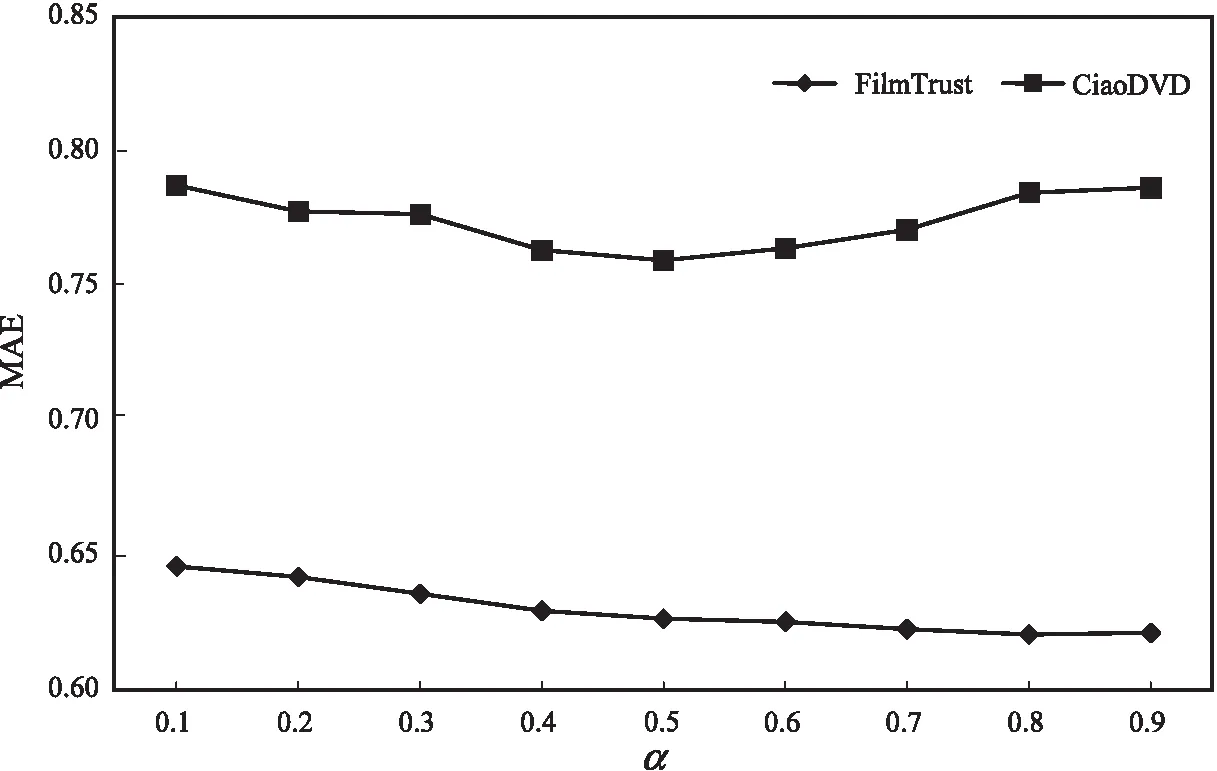
图2 参数α对MAE值的影响
从两图中可以观察到,随着α的增加MAE和RMSE呈现出先下降后上升的趋势。在FilmTrust数据集上,当α=0.8时,MAE和RMSE出现最低点,表明当α为0.8时在该数据集上推荐性能达到了最佳。在CiaoDVD数据集上,当α=0.5时,MAE和RMSE出现最低点,表明当α为0.5时该数据集上推荐性能达到了最佳。这是由于伴随着信任信息的增加,将会为目标用户提供更加可靠的信息,但过度采用用户的信任关系将导致用户的偏好出现多样性,使得推荐性能下降。该实验结果表明适当调整用户的相似度和信任度所占权重有助于提高推荐的准确度。
3.5.2K值对算法的影响
从图4和图5可以观察到近邻用户K在FilmTrust数据集和CiaoDVD数据集上对MAE和RMSE的影响。由实验结果可以看出,不同的K值对目标用户将会产生不同的影响。

图4 近邻用户K对MAE值的影响

图5 近邻用户K对RMSE值的影响
在FilmTrust数据集上,当K值为20时,MAE和RMSE出现最低点。在CiaoDVD数据集上,当近邻用户K为50时,MAE和RMSE出现最低点。由两图可知,随着K值的增加,该算法的评价指标出现了拐点,该拐点为该算法的性能指标最佳点。实验结果表明,伴随着近邻用户的增加将会有更多的邻居为目标用户提供推荐,从而提高了推荐的准确性,而过多的邻居将会对用户的偏好产生干扰导致推荐的准确性降低,故应根据数据集的实际情况,选择合适的近邻用户数为目标用户进行推荐。
3.5.3 算法推荐性能对比
为了验证SR-UIPC算法的性能,选取五个带有社交信息的基准算法分别在FilmTrust、CiaoDVD两个数据集上进行训练和测试,并将数据集按照4∶1的比例进行划分,随机选择其中4份用作训练集,1份作为测试集。相比于其他算法,SR-UIPC算法在FilmTrust数据集上,当α=0.8,K=20取得最佳性能,在CiaoDVD数据集上,当α=0.5,K=50取得最佳性能。
从表2中可以看出,SR-UIPC算法在MAE和RMSE两评估指标上整体表现最佳。与传统协同过滤算法相比,TrustSVD算法虽然引入了用户的信任关系却未考虑到用户的信任强度是不平等的,导致推荐在预测评分的准确性上存在偏差。CUNE算法通过引入间接用户的影响缓解信任数据的稀疏性,却忽略了信任在传播过程中容易造成信任节点信息的丢失使得用户间的预估间接信任值准确性较差,进而导致整体预测准确度较差。DeepSoR算法基于神经网络学习用户的非线性特征,然而数据的稀疏性导致难以捕捉用户之间偏好,使得用户间的偏好存在着偏好差异性。SREPS算法虽然考虑了社交网络中用户间的偏好差异,但仅考虑了用户的一阶邻居对用户偏好的影响,未考虑到用户的高阶邻居对用户所产生的影响,造成了信息的丢失。PMFTrustSVD算法不仅考虑到了用户的偏好差异性,还考虑到了信任者和受托者在社会影响力上的差异,但忽略了信任的传播性使得用户的偏好存在着偏差。

表2 不同算法在FilmTrust和CiaoDVD的性能对比
对比于其他算法在FilmTrust、CiaoDVD数据集上的表现,SR-UIPC算法挖掘出用户间所隐藏的隐式信任关系,为社会化推荐系统提供了更加丰富的信息,并且通过将用户的社会影响引入到信任传播中,缓解了信任在传播过程中信任节点信息的丢失进而提高了推荐的预测准确性。同时从数据集的稀疏性上可以看出,与FilmTrust数据集相比,MAE和RMSE两评估指标在CiaoDVD数据集上都出现了一定程度的上涨,但整体效果表现较好,表明数据的稀疏性在推荐预测准确性上有着一定的影响。
4 结束语
针对传统社会化推荐系统所面临数据稀疏性和难以准确刻画用户之间的信任差异性等问题,提出了一种基于隐式信任的社会化推荐。该方法根据评分信息从偏好一致性出发挖掘用户间的隐式信任信息,并结合社交信息对用户间的信任度进一步刻画。其次,结合用户的影响力找到一条信任传播稳定性最强的路径,避免了信任节点信息的丢失。从实验结果可以看出,该算法提高了推荐的推测准确性。此外,用户所处的地理位置也会对用户的偏好产生影响,如何将用户的社交信息和用户的地理位置结合起来预测用户的偏好未来可做进一步研究。
猜你喜欢
英语世界(2023年6期)2023-06-30
意林彩版(2022年2期)2022-05-03
第一财经(2020年4期)2020-04-14
文苑(2018年17期)2018-11-09
环球时报(2018-01-23)2018-01-23
桃之夭夭B(2017年2期)2017-02-24
计算机工程(2015年4期)2015-07-05
高中生·青春励志(2014年11期)2014-11-25
IT经理世界(2014年5期)2014-03-19
