
基于CiteSpace的机器翻译研究可视化分析
2023-09-14 07:02傅琳凌
黑龙江科学 2023年15期
傅琳凌,刘 磊
(华南师范大学外国语言文化学院,广州 510631)
0 引言
在人工智能技术的发展与驱动下,机器翻译技术迅猛发展。2016年,随着谷歌神经机器翻译系统取得重大突破,翻译准确率显著提高,全球机器翻译领域迎来新一轮研发高潮[1]。2022年,人工智能研究实验室OpenAI推出自然语言处理工具ChatGPT[2],为机器翻译带来人机互动新体验。
本研究基于中国知网(CNKI)文献数据库,利用CiteSpace 6.1.R3软件分析1992—2022年国内机器翻译研究的演进趋势及研究者、研究机构、研究主题等关键指标,梳理了国内机器翻译研究的动态进展与不足之处,并对未来我国机器翻译研究的趋势做出了展望。
CiteSpace 6.1.R3软件兼具图与谱的双重特性,既能显示知识聚类间的网络、结构、互动、交叉、演化或衍生等关系,也可揭示出复杂的知识关系孕育的前沿知识[3]。由于中国知网上检索到国内最早研究机器翻译的文献是1992年黄昌宁发表的《计算语言学简介》,故将检索时间设定为1992—2022年,主题词设定为“机器翻译”,文献来源类别设定为核心期刊(包括SCI、EI、CSSCI、CSCD及中文核心期刊),经人工剔除广告、会议、通知、书评等非研究性文献后得到文献1702篇。将数据导入CiteSpace 6.1.R3软件,自动剔除13条重复或空白数据,得到有效文献1689篇。
1 年发文量
我国机器翻译研究总体呈现稳步上升趋势,以2016年为分界点,可分为以下两个发展阶段。①平稳成长期(1992—2015年):该时期发文量稳步上升,但增幅不大且伴随发文数量的波动。②快速发展期(2016—2022年):该时期发文量增幅明显,2017年的发文数量同比增长超过60%,原因可能在于2016年谷歌翻译等机构在神经机器翻译系统研究领域取得重大突破,给全球机器翻译的研发带来了启迪和动力,吸引大批学者投身机器翻译相关研究;2019年起,年均发文量稳定在110篇以上,2021年达到峰值(133篇)。详见图1。
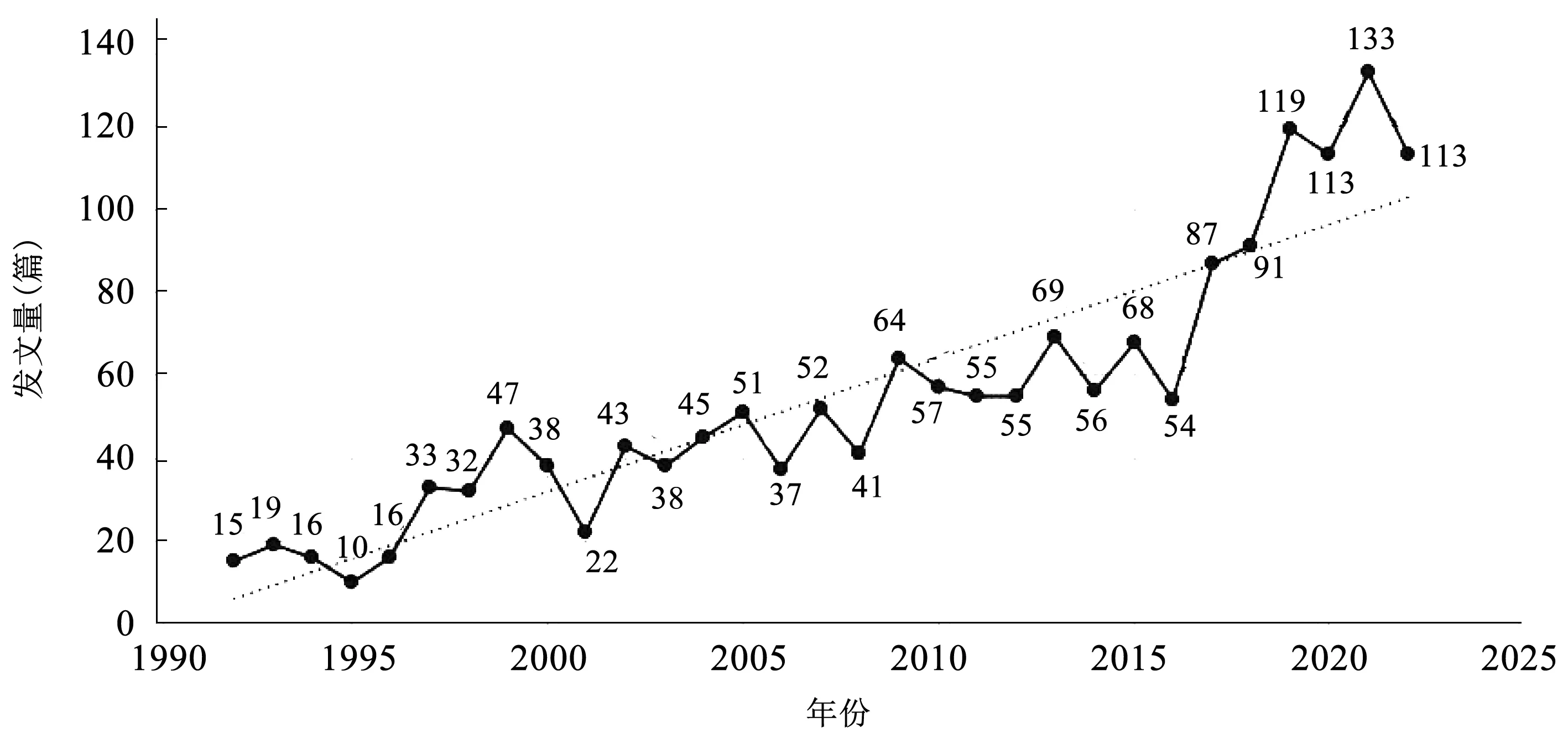
图1 机器翻译研究年发文量Fig.1 Annual distribution of publications on machine translation
2 研究者
分析研究者的发文量及聚类情况,可了解某领域主要学者的文章发表情况及其研究的相关性。机器翻译研究领域发文量在30篇以上的学者有5位,分别是来自中国科学院计算机研究所的刘群,哈尔滨工业大学的李生和赵铁军,国家教育部语言文字应用研究所的冯志伟及昆明理工大学信息工程与自动化学院的余正涛。其中,刘群发文量最多,达40篇。上述学者主要的研究领域均涉及自然语言处理,其中4位学者(占80%)的主要研究方向为机器翻译,2位学者(占40%)的主要研究方向为机器学习。
不同研究者的研究相关性可通过聚类图进行分析,聚类图中研究者间的距离越近,代表其研究成果的关联性越强。我国机器翻译领域形成以“机器翻译评测”“模式”“融合”“机器训练语料选取”“回译”等主题研究为核心的作者群。其中,“机器翻译评测”主要涉及对特定翻译系统或翻译算法的评价与测试,常见的机器翻译评测方法包括人工评测与基于n元匹配的自动评测,如“通过引入模糊匹配,BLEU的性能得到显著提高”[4];“模式”相关研究成果主要涉及机器翻译系统的计算模式及模式匹配算法研究;“融合”相关成果主要研究通过融合新模型、机制或知识如何进一步提升机器翻译的性能,融合的目标多数服务于机器翻译的模型训练,故“融合”与“翻译模型”这两个研究主题的空间距离较近;无论是统计机器翻译还是神经机器翻译,用于机器训练的大规模、高质量平行语料是决定翻译效果的核心要素,“训练语料选取”是机器翻译研究领域的核心主题;“回译”是“翻译中重要的数据增强方法”[5],通过精准性测试回译训练机器模型,是提高机器翻译准确度的重要手段。详见图2。

图2 研究者聚类图Fig.2 Clustering knowledge atlas of researchers
3 研究机构
分析文献发表单位有助于了解特定领域的研究机构及其发文特点。机器翻译领域的研究机构主要集中在计算机与信息工程类院校及研究所;前10所高产研究机构中仅有2所在2000年前发表过机器翻译相关研究成果,其余8所机构均是2000年后开始发表机器翻译相关主题文章的,可见我国机器翻译研究发轫于1992年,研究中坚在2000年以后才陆续出现。详见表1。

表1 前十位高产研究机构发文量及首发年份Tab.1 Number of publications among top 10 prolific organizations and the year of their first publication
从发文内容看,各机构的研究重点有所不同:苏州大学计算机科学与技术学院、中国科学院计算技术研究所、中国科学院计算技术研究所智能信息处理重点实验室、中国科学技术信息研究所及北京大学计算语言学研究所这5家单位多以研究自然语言处理方向为主;中国科学院新疆理化技术研究所、昆明理工大学信息工程与自动化学院、新疆大学信息科学与工程学院及内蒙古工业大学信息工程学院这4家单位的研究内容呈现出明显的地域特色,重点关注少数民族语言与汉语或外语的机器翻译问题。外语类院校在机器翻译研究领域的发文量明显少于计算机类院校,发文量最高的外语院校为上海外国语大学,在高产研究机构中排在第12位;此类院校主要关注翻译教学中机器翻译的应用、机器翻译与人工翻译的异同、机器翻译产出的质量管理等主题。
4 关键词聚类
在CiteSpace 6.1.R3软件的功能与参数板块中,设置时间切片(Time Slicing)为“From 1992 Jan. To 2022 Dec.”以完整覆盖所有有效数据,年份切片(Year Per Slice)为1,选取关键词(Keywords)为参数,得到关键词聚类图及前十位高频关键词表。在CiteSpace 6.1.R3软件生成的关键词聚类图中,节点的大小代表其总被引次数[6]。节点越大代表该关键词出现的频次越多,研究热度越高。CiteSpace 6.1.R3软件还通过自动聚类将关键词划分为不同主题,划分依据是关键词的共现关系及强度,若多个关键词集中于某个主题范围内,则说明这些研究热点间的联系更为密切。
目前国内机器翻译研究关注的热点话题包括“人工智能”“翻译技术”“深度学习”,以及与“句子对齐”“句法分析”“中间语言”等密切相关的自然语言处理。在主题分布上,“名词短语”“句法分析”“多义词”及“名词词组”等关键词联系紧密,这些研究内容均从属于自然语言处理领域;“人工智能”“信息检索”“神经网络”等关键词附近的词项多涉及新兴前沿方向。“人工智能”是仅次于“机器翻译”的高频关键词,研究者对人工智能的关注几乎与机器翻译研究同步发端。“翻译技术”是排名第三的高频词,与“译后编辑”“语言服务”等词聚类关系明显。与机器翻译紧密相关的研究阵营主要包括主攻机器翻译系统开发的计算机技术阵营及促进机器翻译技术普及的翻译研究阵营,后者往往将机器翻译作为“翻译技术”的代表以讨论技术转向[7]、技术伦理[8]及技术应用情况[9]等。学界对“机器翻译”“人工智能”“人工翻译”及“译后编辑”等内容关注较早,而“翻译技术”“深度学习”“神经网络”等则是机器翻译研究领域较新的关注热点,均在2010年后受到重点关注。详见图3、表2。
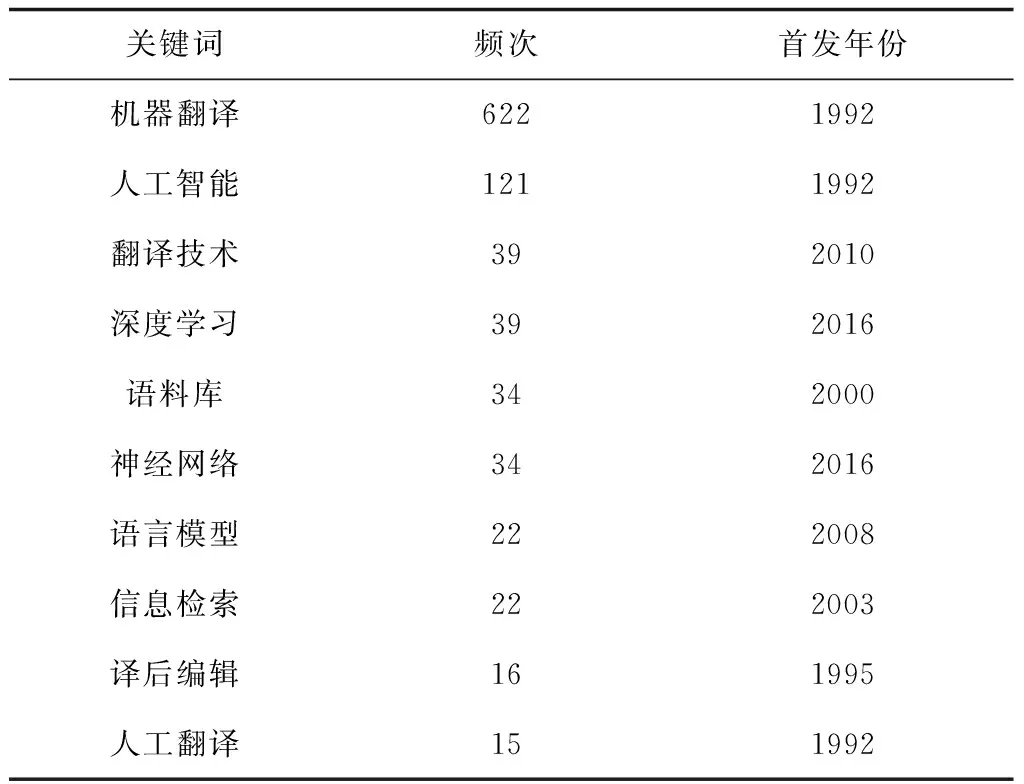
表2 前十位高频关键词Tab.2 Top 10 high-frequency keywords

图3 关键词聚类图Fig.3 Clustering knowledge atlas of keywords
“语料库”“深度学习”“信息检索”等均为研究热点,且这三个关键词联系紧密,原因在于平行语料库是机器翻译系统开发的重要原料,深度学习是机器翻译水平提升的突破口,信息检索模型是机器翻译训练中数据选择与优化的关键环节。作为机器学习(Machine Learning)的新方向,深度学习(Deep Learning)未来的发展方向更趋近于人工智能,“凭借庞大的数据集和强大的计算能力建立深层次神经网络,并基于其深度、隐性学习与算法正则化的显性特征模拟人脑机制完成对数据的分析,进而提高不同层次上对数据的解释能力”[10]。广义的深度学习也常被用于处理多模态翻译实践中的声音、图像等非文本信息。
“神经网络”也是机器翻译研究的高频关键词,多见于神经机器翻译(NMT)的研究中。神经机器翻译系统“根据双语语料库进行深度学习,就可实现机器翻译,不再需要规模宏大而艰巨的‘语言特征工程’,几乎完全抛弃了基于语言规则的符号主义方法”[11]。神经机器翻译的核心之一在于计算机神经网络技术的应用,让机器翻译系统模仿人类大脑神经元进行翻译,故神经网络成为机器翻译研究者重点关注的对象。机器翻译的发展离不开人工翻译,二者相辅相成,二者的异同分析、机器翻译对人工译者的影响等成为研究焦点,故“人工翻译”也出现在高频关键词表中。
5 关键词突现
关键词突现点列表以关键词突现开始的时间顺序由远及近排列,反映各研究热点受到高度关注的时段,由近五年开始突现的关键词可管窥相应领域的研究前沿。
在机器翻译研究领域内,“大数据”“数据增强”“迁移学习”“回译”这四个关键词突现的起始时间集中在近五年之内(即2018年及以后),说明近五年研究者对这四个领域的关注度显著提升。“数据增强”“迁移学习”及“回译”有助于提升低资源或稀缺资源语种的机器翻译训练性能,如蔡子龙等在汉藏、汉英语对实验中利用数据增强技术使得两种语对与基准系统相比均多出4个BLEU值,发现数据增强技术可有效解决神经机器翻译因训练数据太少而导致的泛化能力不足问题[12];数据增强是在不实质性增加数据的原则下,通过对已有数据进行随机裁剪、随机对比,让有限的数据发挥更大的作用。迁移学习则是将模型(NMT)学习到的参数迁移到相近的任务上,利用高资源翻译任务得到的参数改善低资源翻译任务的性能[13],如Zoph通过迁移学习有效提高了4组低资源语对5.6个BLEU值[14]。回译可以分为术语回归回译与翻译精确性测试回译[15],不仅可直接用于检验机器翻译中两种语言转换的准确度,还可在高资源与低资源语对转换中间接提升低资源语对的翻译质量,如张文博等将汉语单语数据按照领域相似性划分成多份单语数据,通过回译方法分段利用不同的单语数据训练翻译模型,借助模型平均、模型集成等方法进一步提升了维汉、蒙汉翻译质量[16]。近五年机器翻译领域内的四个突现关键词均与低资源语对有关,可见如何提高低资源语对的机器翻译质量是当下机器翻译研究的前沿问题。详见图4。
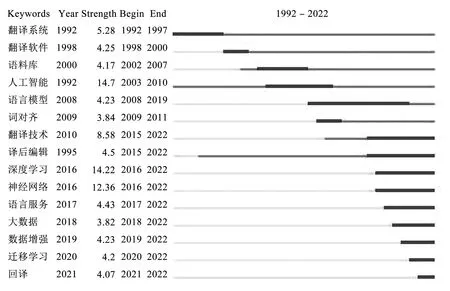
图4 前十五位关键词突现情况Fig.4 Top 15 keywords with the strongest citation bursts
6 结论
1)从演进趋势来看,近三十年机器翻译相关研究成果总体呈稳步上升趋势,且自2016年起呈现明显的增长趋势。2019年后,国内机器翻译相关研究成果稳定在年均110篇以上,且发文量在2021年达到峰值。机器翻译研究的增长态势不仅反映了人们日常工作生活对机器翻译的现实需求,也体现了人工智能时代各类技术更新迭代的内在发展需求。
2)从研究群体来看,机器翻译研究领域高产出、高影响力的学者主要具备计算机专业背景,这是由于机器翻译的开发与优化离不开计算机技术;其他领域学者对机器翻译的关注与研究成果产出较为分散。
3)从研究机构来看,计算机科研院所为主力军,与翻译紧密相关的语言类院校研究力量仍未凝聚。机器翻译的开发与突破离不开计算机技术,技术的发展推动机器翻译从传统基于统计、规则的算法升级到基于神经网络的发展阶段;但是,机器翻译要取得重大突破,单纯依靠算法还不够,还需语言学、脑科学等多领域学者通力合作,无论技术发展到何种程度,人依然是机器学习无法绕开的参照物,也是机器翻译系统优化的旨归。
4)从研究热点与前沿来看,机器翻译研究领域的热点呈现多样化特征与智能化趋势,前沿问题主要集中于如何通过大数据、数据增强、迁移学习及回译等方法在已有高资源语对平行语料的基础上,解决低资源语对由于原始数据不足导致的机器翻译质量不如人意的难题。多样化的特征体现在如今的机器翻译已不再囿于传统自然语言处理领域,而是与语料库、人工智能、深度学习及翻译技术等领域相互融合。智能化趋势集中体现在大数据叠加机器翻译催生的前沿翻译技术,特别是2013年神经网络机器翻译(NMT)模型兴起后,机器翻译超越了基于规则与统计的机器翻译,跨入神经网络翻译时代[17]。国外的谷歌、微软,国内的百度、有道等企业不断探索人工智能、大数据、语音识别技术(ASR)、深度学习等技术,旨在进一步提升机器翻译产出的质量和效率。
7 展望
基于近三十年的研究动态,国内机器翻译研究者应更加注重在研究方向、研究群体、研究应用与技术推广等维度的跨学科、跨领域合作,让技术的研发与普惠齐头并进。
1)在研究方向层面,模型开发、训练语料选取、计算机自然语言处理等仍为机器翻译研究领域的热点话题。面向低资源语对的机器翻译系统研发将继续成为机器翻译研究界的攻坚核心[18]。为顺应当前人工智能的发展趋势,翻译技术、机器深度学习、神经机器翻译将成为未来机器翻译研究相关成果的主要增长点。
2)在研究群体层面,机器翻译系统研发的瓶颈突破需融合计算机科学及翻译学、认知语言学等多学科的力量。学科交叉与融合是各专业研究及人才培养的共同趋势,以翻译学科为例,未来的翻译人才培养目标将不再局限于专职翻译,而是既懂翻译、又通晓技术的翻译+语言工程师的融合体[19]。目前倡导的语言智能学科也是学科交叉的一个典范,有机融合了语言、认知、计算三大要素[20]。
3)在研究应用层面,机器翻译系统研发的目的在于服务人类生活与生产的现实需求。未来机器翻译的技术开发与研究还应注重对机器翻译“功用”的追踪,通过实际“功用”去调整语料的选取及算法、模型的设计。机器翻译如何有效匹配人们在旅游、就医、科技传播、语言教学等不同情境的使用需求,如何满足非通用语言使用者对机器翻译的需求,如何实现低资源语言的平行语料库资源建设等均是未来机器翻译研发需重点调研的领域。
4)在技术推广层面,机器翻译作为一种易操作、易获取的信息技术,在教学、医疗、旅游等多领域均有实践意义与推广价值。以教学情境为例,《教育信息化2.0行动计划》提出,要加强学生课内外一体化的信息技术知识、技能、应用能力以及信息意识、信息伦理等方面的培育[21]。作为具有代表性及可操作性的信息技术,机器翻译不仅可以赋能外语课堂的教与学,还能消除多语言课堂情境下师生、生生间的语言障碍,推动形成和谐的多语言学习交流环境。机器翻译还可有效提升不同国家和文化间资讯共享的效率,减少文化冲突,促进交流合作。
猜你喜欢
今日农业(2020年14期)2020-08-14
青年生活(2019年23期)2019-09-10
阅读(低年级)(2018年10期)2018-05-14
阅读(低年级)(2018年11期)2018-05-14
阅读(低年级)(2018年12期)2018-03-23
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
中共南宁市委党校学报(2015年4期)2015-02-28
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
