
基于数据挖掘下机器学习算法对学生考研成功因素的研究
2023-09-14 07:35林成范洪志周梓维黄祥豪曾祥坤
电子元器件与信息技术 2023年6期
林成,范洪志,周梓维,黄祥豪,曾祥坤
广东技术师范大学汽车与交通工程学院,广东广州,510665
0 引言
近五年来,考研人数上升较快,2017年考研人数首次突破200万,2021年考研人数已增至371万。未来几年的考研人数依旧会持续性增长,如何帮助考研学生在竞争压力日渐增大的研究生入学考试中获得成功成为当前研究的热点[1]。随着教育大数据时代的到来,通过数据的挖掘,从数据和信息中获取有益的知识和规律,并将数据挖掘相关技术作为教育教学工作的指导工具,有利于提高高校教育教学的工作效率。因此将数据挖掘技术结合到教育教学实践中将会成为未来教育的必然趋势。采用数据挖掘技术中的算法,建立科学的考研成功预测模型,对学生平时的学习行为数据进行挖掘,是帮助考研学生提高考研成功率的关键。由模型分析结果得出影响学生考研成功率的关键因素,为准备考研的学生提供理论指导依据,对引导学生更有效地进行考研复习具有重要的意义。
决策树属于分类数据挖掘方法下机器学习算法的一个分支,该方法结构简单、易于理解和解释,具有高准确率、高效性、运算速度快、能处理多类型的数据等优点[2-3]。决策树算法可以将一组杂乱、无规则的数据按照一定的属性和条件进行决策树模型的构建。在整个决策树模型的构建过程中,采用自上而下的递归方式,从根节点出发,顺着分支到达叶节点。其中,每一条路径都是一条分类规则,将所有规则组合起来,就构成了分类器,即可被用于预测解决问题[4-5]。结合研究情景和研究目的,最终将决策树分析方法作为本研究数据挖掘过程的主要方法。
因此,通过收集学生的平时成绩,根据其考研初试结果进行机器学习算法训练,从而得到相应的决策树模型[6],可以为后续学生的研究生入学考试备考和教师对考研学生的指导提供模型基础。
1 基于决策树算法的考研成功预测
1.1 数据采集与数据预处理
1.1.1 数据采集
本文以广州市某高校2018级毕业生的考研初试情况为研究对象,参与同学所在专业为车辆工程、车辆工程(师范)、汽车服务工程、汽车服务工程(师范 )和交通运输工程,有效数据集为390人,数据集具体情况如表1所示。

表1 学生平时成绩数据集
1.1.2 数据预处理
数据预处理会影响机器学习模型预测的准确度。为了更好地进行数据挖掘,在数据预处理中将车辆工程专业记为“1”,将车辆工程(师范)专业记为“2”,将汽车服务工程专业记为“3”,将汽车服务工程(师范)记为“4”,将交通运输工程记为“5”。学生的专业、课程成绩以及大学4年的综合绩点将会作为机器学习特征值。将“考研成功”设置为机器学习的目标值,学生考研初试成绩上线即记为“1”,不上线即记为“0”。预处理后的数据集具体情况如表2所示,其中有28名同学通过了研究生入学考试初试。

表2 预处理后的学生平时成绩数据集
为了更好地进行机器学习,将表2中专业、课程和综合绩点等标签由对应的英文代替。目标值标签“考研成功”由英文“Success”代替。完成数据的预处理后,将表2保存成CSV文件。
1.2 机器学习
机器学习在Jupyter Notebook软件平台进行,运用开源数据库numpy、pandas读取表2所保存的CSV文件,运用机器学习开源数据库sklearn实现决策树生成,引入开源数据库graphviz实现决策树可视化。
1.2.1 基于CART算法的决策树构建模型
CART决策树算法分为分类决策树算法和回归决策树算法。分类决策树算法使用基尼系数选择特征[7],基尼系数代表了模型的不纯度,基尼系数越小,不纯度越低,特征越好。数据集的纯度可用基尼值来度量[8]:
其中,p(xi)是分类xi出现的概率,n是分类的数目。Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率。因此,Gini(D)越小,则数据集D的纯度越高。
构建CART决策树的步骤如下。
(1)设节点的训练数据集为D,识别各个特征的类型,找出每个特征下的最优切分点;然后比较每个特征的最优切分点的基尼指数大小,基尼指数最小的即为最优特征。
(2)根据这个最优特征和最优切分点,将数据集划分成两个子集D1和D2,同时建立当前节点的左右节点,左节点的数据集为D1,右节点的数据集为D2。生成子节点后将此最优特征的最优切分点剔除。
(3)对左右的子节点递归调用(1)-(2)步,生成决策树。
1.2.2 采用CART决策树分类算法构建决策树
本文在Jupyter Notebook平台下采用Python语言实现该算法,主要包括以下步骤。
(1)调用train_test_split()函数将样本数据集进行随机分组,其中样本数据集中80%的数据用作决策树算法的训练数据集,20%的数据用于测试决策树模型的准确度。
(2)调用DecisionTreeClassifier()函数建立分类决策树对象estimator,再以训练数据集为参数运行estimator.fit()函数构建相应的决策树模型。
(3)以测试数据集参数调用estimator.score()函数得到训练好的决策树模型的预测准确度情况。
(4)通过调用export_graphviz()函数实现决策树的可视化。
(5)使用estimator.feature_importances_函数对数据进行特征重要性分析。
1.2.3 决策树数据分析
由于在决策树算法中常常出现“过拟合”问题[9-10],即过于紧密或精确地匹配特定数据集,以致无法良好地拟合其他数据或预测未来的观察结果。因此,通过适宜的后剪枝法(将决策树层数缩减为10层)使得训练好的决策树模型在步骤(3)的预测准确度达到91.026%。图1为经过步骤(4)得到的决策树图。
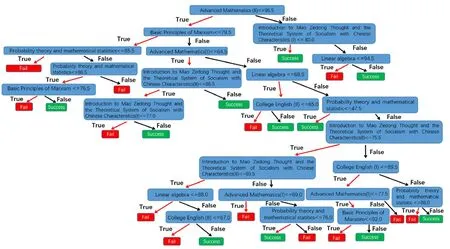
图1 决策树
得到相应的决策树模型后,使用特征重要性分析各个课程的成绩对研究生入学考试成功结果的影响。图2展示了图1的决策树模型的各特征重要性。从图2可以看出,数学方面的课程(高等数学、线性代数、概率论与数理统计)对通过研究生入学考试初试预测的影响程度占总体的54.81%,英语方面的课程为13.92%,政治方面的课程占31.28%,而综合绩点对于考研结果预测的影响基本没有。对于理工科来说,研究生入学考试的总分为500分,数学占总分的30%(150分),英语占总分的20%(100分),政治占总分的20%(100分),专业课占总分的30%(150分)。所以对于研究生入学考试的备考学生来说,数学方面的备战复习是最重要的,其次是政治和英语。值得一提的是,在数学课程中高等数学对于考研成功的影响为43.4%、概率论与数理统计为29.87%、线性代数为26.71%,而在研究生入学考试的数学一试卷中高等数学的分值占总分的56%、概率论与数理统计占总分的22%、线性代数占总分的22%。高等数学对于考生通过研究生入学考试的影响低于其在数学一中的分值占比并不代表着复习好高等数学在考研数学中作用下降,而是表明了目前研究生入学考试竞争激烈,大部分考生在高等数学方面都准备充分,所以拉开考生分数差距的部分主要集中在概率论与数理统计和线性代数方面。所以在今后的备考中,考生除了做好高等数学方面的复习,还要在概率论与数理统计和线性代数方面多花精力,才能提高自己的考研初试成功率。
2 结论
本文采用广州市某高校2018级毕业生的平时课程成绩作为样本数据,通过CART决策树算法构建相应的考研预测模型。同时,本文进行了各个课程的成绩对研究生入学考试结果的特征重要性分析。结果表明,数学课程的成绩对通过研究生入学考试初试预测的影响程度占比为54.81%,英语课程的成绩影响程度占比为13.92%,政治课程成绩的影响程度占比为31.28%,而所有课程成绩的综合绩点对考研结果没有什么影响(0%)。因此,想要考研的同学应该更注重数学课程的平时学习,打好深厚的大学数学课程基础才能提高考研的成功率。
猜你喜欢
环球时报(2022-06-09)2022-06-09
科学大观园(2022年8期)2022-05-18
环球时报(2021-02-03)2021-02-03
云南教育·中学教师(2020年11期)2021-01-07
新教育时代·学生版(2019年42期)2019-10-21
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
歌剧(2017年4期)2017-05-17
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
世界教育信息(2015年20期)2016-01-06
