
融合语义特征和知识特征的推荐模型
2023-09-13 03:07马新明
计算机工程与设计 2023年8期
郑 光,朱 越,时 雷,马新明,席 磊+
(1.河南农业大学 信息与管理科学学院,河南 郑州 450046;2.河南农业大学 农田环境监测与控制技术河南省工程实验室,河南 郑州 450002)
0 引 言
推荐方法[1-3]可分为基于协同过滤的推荐方法[4,5]、基于内容的推荐方法[6]及混合推荐方法[7,8]。其中应用最广泛的是协同过滤推荐方法,然而协同过滤过度依赖于用户交互数据,当存在数据稀疏性问题时,该方法的准确性较低[9]。
为了缓解传统推荐方法中出现的问题,研究者们将用户的社交关系、物品属性和知识图谱等作为辅助信息引入。为了对辅助信息中蕴含的大量与用户偏好相关的数据进行特征提取,研究者们通常使用深度学习技术对其进行挖掘以提升推荐性能[10]。将知识图谱作为辅助信息引入推荐领域已成为当前的研究热点。知识图谱中蕴含的知识信息能够在一定程度上缓解数据稀疏性问题并增强推荐结果的可解释性。
围绕上述背景,本文将知识图谱引入推荐模型,提出一种融合语义特征和知识特征的推荐模型,借助知识图谱对用户兴趣进行有效扩展,将知识图谱中的语义特征与知识特征融合以获得更准确的用户兴趣偏好;利用知识图谱中的网络结构,依据“偏好扩散”思想[11]获取用户偏好扩散集,使用门控循环单元结合注意力机制挖掘用户深层兴趣。
1 相关工作
1.1 知识图谱
知识图谱本质上是一种语义网络,能够对知识进行结构化的描述[12]。知识图谱已经成为当下的研究热点,知识图谱对互联网中的信息进行结构化的组织将其表示为易于理解的知识形式,推动信息检索领域的发展进程,使得传统的数据服务更新为智能化知识服务。近年来,将知识图谱应用于推荐领域的热度也不断上升,研究者们将知识图谱引入并基于此捕获用户潜在兴趣,提升推荐系统性能。知识图谱中包含的大量实体集信息,可被应用于推荐系统中。例如,在知识图谱中三元组(Bullets Over Broadway,director,Woody Allen)表示Bullets Over Broadway的导演是Woody Allen。在推荐的实际应用场景下,Woody Allen同时导演了Zelig和Hollywood Ending等电影,因此认为电影Bullets Over Broadway和Zelig、Hollywood Ending之间存在一定的关联性,观看Bullets Over Broadway的用户可能会因为喜欢导演而喜欢该导演的其它电影。推荐模型可以借助知识图谱中的实体间关系对用户潜在兴趣进行合理拓展,也能够为推荐结果的原因阐述提供帮助,完善了推荐结果的可解释性。
1.2 知识图谱与推荐系统
基于知识图谱的推荐方法可分为两类,包括基于路径的方法和基于特征学习的方法[13]。
(1)基于路径的方法[14]依托于知识图谱中的链路连接进行知识扩展,为推荐系统提供辅助信息。文献[15]提出一种循环知识图谱嵌入方法,使用循环神经网络对知识图谱中实体间的路径进行建模,从而学习实体关系中蕴含的信息。文献[16]将推荐问题视为马尔科夫决策过程,使用强化学习搜索用户-项目间的合理路径,为用户生成具有可解释性的推荐结果。文献[17]基于实体与关系的语义构建路径序列表示,基于该路径序列对用户偏好进行有效推理。以上方法的优点是能够直观地捕获知识图谱的网络结构,缺点是高度依赖预定义的元路径或元图且参数调优操作较为繁琐,并且该方法通常需要掌握大量领域知识进行预定义工作且提取完整路径的难度较大。
(2)基于特征学习的方法[18]使用知识图谱嵌入技术对知识图谱中的实体进行预处理生成低维度的嵌入向量,使用该嵌入向量丰富用户或项目的表示。文献[19]对新闻项目进行多层级特征挖掘后融合注意力机制获取用户特征表示,从而捕捉用户动态兴趣偏好。文献[20]构建了用户-项目知识图谱,将不同用户行为定义为关系类型,使用平移距离模型TransE将知识图谱中的实体和关系投影为低维向量,基于向量间距离进行相似度评估,基于协同过滤为用户推荐可能感兴趣的项目。文献[21]使用一种联合学习训练方法,将知识图谱嵌入模块和推荐模块通过所设计的交叉压缩单元进行关联并联合训练,并基于该交叉压缩单元进行知识传递,从而弥补自身信息稀疏性的问题,达到改善推荐系统性能的目的。文献[22]使用语义匹配模型DistMult捕获关系语义,基于注意力机制进行关系类型和关系权重两个层面的用户兴趣偏好建模,经过联合学习生成推荐结果。
将知识图谱作为推荐系统中的辅助信息具有以下优势,知识图谱中丰富的语义信息有助于挖掘用户和项目之间的潜在联系,构建更精准的用户兴趣模型,提高推荐结果的准确性[23];借助知识图谱中的关系链路可以对用户潜在兴趣进行合理扩展,为用户提供多样化的信息,避免推荐结果的同质化;知识图谱可以作为用户历史交互信息与候选推荐项目之间的桥梁,为推荐结果提供可解释性,有助于提高推荐性能,优化用户体验。
2 模型设计
2.1 问题定义
在传统的推荐模型中,使用U={u1,u2,…} 和V={v1,v2,…} 分别表示用户和项目的集合。给出用户-项目交互矩阵定义:Y={yuv|u∈U,v∈V}, 如式(1)所示
yuv={1,ifinteraction(u,v)isobserved;0,otherwise.
(1)
yuv=1表示用户u和项目v存在隐式交互行为,例如分享、点击、购买等。
知识图谱G由“头实体,关系,尾实体”三元组组成,即 (h,r,t)∈G, 其中蕴含着大量知识信息。
本文研究的问题定义为:给定用户-项目交互矩阵Y和知识图谱G,预测用户u对未交互的候选项目感兴趣的概率。在这里,定义预测函数为uv=F(u,v|Θ,G), 其中uv表示用户u与候选项目v的交互概率,Θ为可学习的模型参数。
2.2 推荐方法
本文将知识图谱引入推荐模型,提出一种基于结合注意力机制的门控循环单元的融合语义和知识特征的推荐模型(integrating sematic feature and knowledge feature for recommendation model based on gated recurrent unit with attention mechanism,SKRec-AttGRU)。对知识图谱蕴含的语义信息和知识信息进行特征学习,在此基础上引入门控循环单元结合注意力机制进行特征提取工作,从而优化推荐效果。SKRec-AttGRU模型的总体框架如图1所示,上半部分为基于连续词袋模型的语义特征提取模块,对项目实体进行语义特征学习;图中部表示借助“偏好扩散”思想[11]获取用户兴趣在知识图谱中的传播,从而提取出知识图谱中蕴含的知识特征;在学习到语义特征与知识特征后,借助特征融合策略将其融合并保持其对应关系,使用门控循环单元结合注意力机制对用户-项目间的潜在信息进行挖掘生成最终用户特征表示,输出预测的用户点击概率。

图1 SKRec-AttGRU模型总体框架
2.2.1 语义特征学习
为了丰富用户偏好表示,将蕴含丰富语义信息的项目描述引入,对知识图谱中项目实体的描述进行语义特征学习,以缓解数据稀疏性问题。如图1所示,本文使用语义特征学习模块对项目实体进行特征提取,将其作为对应项目的潜在语义特征表示。使用word2vec模型对项目实体对应的语义信息进行特征学习获得语义特征表示。word2vec是自然语言处理任务中较为常用的语义特征学习方法,通过逻辑回归进行训练,从而获得低维嵌入向量表示,本文所选用的模型为连续词袋模型(continuous bag-of-words,CBoW)。CBoW通过浅层神经网络对输入文本进行训练,训练过程中基于上下文信息对当前词进行预测,从而获得与当前字符对应的包含语义层面信息的低维向量表示。
CBoW模型的第一层是输入层,将目标词的前后c个上下文词作为输入。第二层是投影层,使用2c个上下文词的独热表示以及公用的权重矩阵进行计算,提取相应的词向量后进行加权求和平均操作得到投影层向量表示h。第三层是输出层,经过softmax函数得到所有词向量的概率分布。经过梯度下降法的模型迭代训练过程,获得目标的向量表示。目标词的概率分布如式(2)所示,其中U表示投影层至输出层的权重矩阵,w表示目标词,Context(w) 为w的上下文
p(w|Context(w))=softmax(UT·h)
(2)
通过最大化CBoW模型的目标函数L,不断优化权重矩阵,从而学习得到语义特征向量,目标函数L定义如式(3)所示,其中C表示目标词所组成的语料库
L=∑w∈Clogp(w|Context(w))
(3)
在对原始文本进行分词、停用词过滤等预处理后,使用CBoW模型对项目实体进行语义特征提取,从而获得与其对应实体的语义特征表示Si,后续将融合项目实体表示后进行知识特征挖掘,从而获得项目实体的深层表示,提高推荐结果的准确性。
2.2.2 知识特征学习
知识图谱中蕴含着大量与项目相关的隐藏的知识信息,而知识图谱中的关系路径可被有效翻译,在推荐模型中借助知识图谱中的关系路径可对用户潜在兴趣进行挖掘,例如用户对于某存在过行为交互的项目的偏好可通过关系路径传递至另一项目实体,也就是“偏好传播”。基于“偏好传播”思想,通过三元组获取与用户兴趣对应的知识特征,将用户历史交互项目沿链路传播的到达的尾节点的集合称为用户的兴趣偏好扩散集。知识图谱中的链路长度对用户兴趣传播效果的影响已被研究者验证[11],与水中波纹衰减现象相似,随着链路长度的增加,基于知识图谱挖掘到的用户潜在偏好与用户间的关联度逐渐减弱,并且可能会带来更多的噪声数据,影响对用户的兴趣偏好描述的准确度。在实验中将探索链路长度对推荐效果的影响,以确保在知识图谱中挖掘用户潜在偏好时,确保远端实体和用户间的存在相对较高的关联强度。
本文基于“偏好传播”的思想构建用户偏好扩散集,以获得用户兴趣在知识特征层面的表示。基于给定的知识图谱G和用户-项目交互矩阵Y,将用户偏好扩散集,即在知识图谱中与用户u历史交互项目k跳距离的相关实体集合定义为εku={t|(h,r,t)∈Gandh∈εk-1u},k=1,2,3,…n。 其中,h,r和t分别表示知识图谱G中头实体、关系及尾实体,n表示沿知识图谱扩散的链路长度。当k=0时,ε0u=Yu={y|yuv=1} 表示用户历史交互项目的集合。在知识图谱中,以用户历史交互项目为起点沿着关系链路向外扩散,最终获得用户偏好扩散集ε0u=ε0u∨ε1u∨ε2u…εnu, 其中n表示链路长度。
在知识图谱中每个项目v均存在对应的向量表示,该向量表示为v∈Rd。 如图1中知识特征模块所示,根据用户交互项目为偏好扩散集中的三元组分配对应的关联概率,如式(4)所示
pi=softmax(vTRihi)=exp(vTRihi)∑(h,r,t)∈εuexp(vTRihi)
(4)
其中,v为用户历史交互项目,Ri∈Rd×d,hi∈Rd分别是知识图谱中关系和实体的向量表示。pi的含义为:用户历史交互项目v与实体hi之间的关联度。
2.2.3 特征融合及结果生成
为了以更细粒度的方式刻画用户兴趣偏好表示,提出一种基于门控循环单元的融合语义特征和知识特征的推荐方法,将项目实体的语义特征和知识特征融合以挖掘用户潜在兴趣偏好。为了学习到的语义特征和知识特征进行融合,针对不同特征设计关系权重进行加权融合,并在此基础上进行用户对于偏好扩散集响应的计算,如式(5)所示,onu为用户u对偏好扩散集εnu的实体响应,由该节点的语义特征和知识特征加权融合得到
onu=∑(hi,ri,ti)∈εnu(piti+αiSi)
(5)
其中,ti表示实体hi沿着关系ri到达的尾实体;pi为知识特征学习模块中学习到的关联度;Si表示语义特征学习模块中学习到的该实体对应的语义特征向量表示;αi表示与尾实体ti对应的语义特征Si的权重。
在获得用户u在偏好扩散集下的实体响应后形成由内层至外层的偏好特征序列,针对该特征序列引入门控循环单元结构进行深层特征提取并融入注意力机制进行权重分配,从而在用户偏好扩散集中捕获到对用户更重要的特征表示,细化用户兴趣描述粒度。门控循环单元(gated recurrent unit,GRU)作为循环神经网络的变体,使用门结构缓解循环神经网络面临的长期依赖问题[24],GRU的模型框架如图2所示。

图2 GRU模型框架
GRU使用重置门rt控制信息的遗忘程度;使用更新门zt对前一时刻隐藏状态信息进行遗忘和选择性保留;基于更新门的激活结果计算获得候选隐藏状态t, 在此基础上进行计算获得当前时刻t的隐藏状态ht,计算过程如式(6)~式(9)所示
rt=σ(Wrxt+Urht-1)
(6)
zt=σ(Wzxt+Uzht-1)
(7)
t=tanh(Whxt+Uh(rt*ht-1))
(8)
ht=(1-zt)*ht-1+zt*t
(9)
其中,σ表示Sigmoid激活函数;Wr和Ur表示重置门的权重参数;Wz和Uz表示更新门的权重参数;符号*表示Hadamard乘积。
考虑到在偏好扩散集εnu中用户偏好强度随着链路长度增加而降低,距离更远的实体对于用户兴趣偏好表示的重要性更低,所以按照内层至外层的顺序将获取到的用户u在知识图谱中不同链路长度下的实体响应输入GRU,为了对该偏好扩散集进行关键特征提取,采用注意力机制为GRU提取到的特征向量进行权重分配,进而生成用户的最终向量表示u,如式(10)所示
u=∑nj=1θjnhnu
(10)
其中,n表示偏好扩散集εnu扩散的最大链路长度;hnu为用户u对偏好扩散集εnu的实体响应onu在GRU单元中的隐藏状态向量表示;θjn为当前第j个隐藏状态向量对应的权重,表示该隐藏状态向量的相对重要性。
加权特征融合策略将获取到的语义特征与知识特征进行融合,获得更全面的用户潜在兴趣表示。基于梯度下降算法最小化损失函数,从而确定最佳权重。加权融合操作能够对不同特征中的有效信息进行提取,减少冗余信息,从而避免高维度特征梯度下降问题。最后,将用户最终向量表示和候选项目向量表示进行组合,经过计算得到预测的用户点击概率,公式如式(11)所示
uv=σ(uTv)
(11)
其中,σ表示Sigmoid函数。
2.2.4 模型训练
为了获得最接近真实值的预测值,使用交叉熵作为损失函数进行模型训练,该损失函数如式(12)所示
Lpre=-∑yuv∈Y[yuvlguv+(1-yuv)lg(1-uv)]
(12)
Loss=Lpre+λ1LKG+λ2Θ22=-∑yuv∈Y[yuvlguv+(1-yuv)lg(1-uv)]+λ1∑r∈RIr-ETRE22+λ2(V22+E22+∑r∈RR22+α22)
(13)
其中,V为项目的向量表示;E为知识图谱中实体的向量表示;R为知识图谱中关系的向量表示;Ir为项目在关系r下的真实向量表示;ETRE为计算得到的项目在关系r下的嵌入向量表示;λ1为知识图谱嵌入损失权重;λ2为L2正则项权重;α表示知识图谱语义特征的权重向量。损失函数共由3个部分组成:第一部分是评估预测概率分布与真实概率分布之间差异的交叉熵;第二部分是知识图谱嵌入表示损失;最后一部分是降低模型出现过拟合的概率的L2正则化项。
3 实验与分析
为了验证所提出模型的推荐效果,在内存为16 GB,处理器型号为Intel(R)Xeon(R)CPU E5-2683 v4 @2.10 GHz 2.10 GHz的Windows server 2016服务器中,使用深度学习框架Tensorflow,在Python3.6的环境下设计对比实验进行性能分析。
实验主要包括4个部分:进行参数调整实验以达到模型的最优效果;与基线模型进行对比实验以验证所提出模型的优越性;进行消融实验以探究模型中各个模块对推荐效果的影响;进行稀疏性验证实验探究在不同稀疏度数据集下所提出模型的表现。
3.1 数据集
选用公开数据集MovieLens进行实验,该数据集是推荐模型效果评估实验中较为常用的数据集,其中包含用户对上千部电影的评分情况。本实验目的为预测用户对未交互项目有兴趣的概率而非用户评分情况,因此隐式交互数据更适用于本实验,所以需要将该数据集中的显式反馈数据转换为隐式反馈,通过设置评分阈值将所有评分大于等于阈值的数据作为正样本。
知识图谱数据来源于互联网电影数据库IMDb中的公开数据。根据MovieLens数据集中电影项目对应的统一资源定位符在互联网电影数据库中的映射,获取电影对应的导演、编剧、电影简介等信息从而构建电影知识图谱。

表1 实验数据集
实验选用电影数据集MovieLens,考虑到用户在挑选电影的过程中,电影简介是一项重要参考依据,且其中蕴含着丰富的信息有助于挖掘用户潜在兴趣,本实验基于电影项目实体对应的电影简介进行语义特征学习。
3.2 评价指标
实验考虑两种推荐场景,分别是点击率预测以及Top-K推荐。在点击率预测场景下选择AUC(area under curve)和正确率(Accuracy,Acc)作为评价指标;在Top-K推荐场景下选择召回率Recall@K和精确率Precision@K作为评价指标对生成的推荐列表进行质量评估[25]。为了更加清楚地解释评价指标,构建如表2所示的混淆矩阵。

表2 混淆矩阵
(1)点击率预测场景
在该场景下,选取AUC指标和正确率Acc作为评估指标,计算公式如式(14)和式(15)所示。式(14)中,i表示属于正样例的样本,ranki表示在点击率预测实验中按分数排序后该样本的序号。AUC,即ROC(receiver opera-ting characteristic)曲线下方的面积大小,AUC的含义为依据预测正样例排在负样例之前的概率。正确率表示所有预测正确的样本在总数中的占比
AUC=∑i∈Posranki-P×(P+1)2P×N
(14)
Acc=TP+TNP+N
(15)
(2)Top-K推荐场景
在该场景下,采用召回率Recall@K和精确率Precision@K作为衡量推荐列表的指标,计算公式如式(16)和式(17)所示。召回率Recall@K表示用户喜欢的项目中会被推荐模型推荐的比例。精确率Precision@K表示被模型推荐的所有项目中用户喜欢的比例
Recall@K=TPTP+FN
(16)
Precision@K=TPTP+FP
(17)
3.3 参数设置与对比分析
使用AUC和Acc作为评估指标,在点击率预测场景下针对实验中的重要参数进行探讨分析获得最佳参数以达到模型最优效果。其中,d表示特征维度大小,k表示在进行偏好传播时的最大链路长度,m表示每层偏好扩散集的尺寸,λ1表示知识图谱嵌入损失权重,λ2表示L2正则项权重。
由于特征维度d的取值对模型的推荐效果存在一定影响,为了确定最佳特征维度大小,设置d=4,8,16,32,64进行实验,结果见表3,可以观察到当d=8时推荐效果达到最佳。最初评价指标随着维度增加而提高,然而当维度增大到一定程度带来过多信息时,容易出现过拟合现象,导致推荐效果下降。

表3 特征维度对点击率预测结果的影响
由于链路长度k的取值对模型的推荐效果存在一定影响,实验设置k=2,3,4,5以寻找最佳链路长度,实验结果见表4。结果显示当链路长度k=2时推荐效果最好。随着链路长度的增加,远端实体与用户间关联度逐渐降低,将挖掘到更高比例的噪声数据,链路长度过长会导致挖掘出过多无效的知识特征,过短则会导致无法探索知识图谱中的远距离依赖。
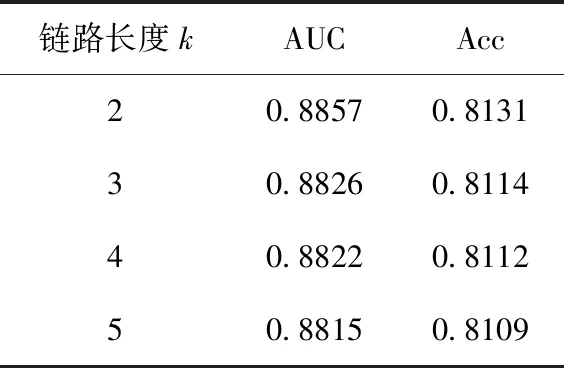
表4 链路长度对点击率预测结果的影响
由于每层偏好扩散集尺寸m的取值对模型的推荐效果存在一定影响,实验设置m=8,16,32,64确定其最佳取值,结果见表5。结果显示当m=32时推荐效果最优,最初随着偏好扩散集尺寸不断增大,AUC和Acc随之提高,然而当其增长到一定程度会带来更高比例的与当前中心实体关联较低的特征,影响推荐效果。
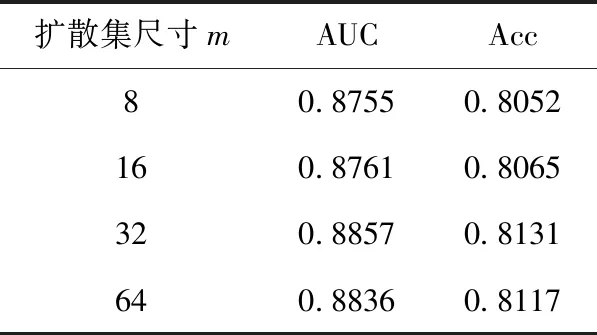
表5 扩散集尺寸对点击率预测结果的影响
为了确定损失函数中知识图谱嵌入损失权重λ1和L2正则项权重λ2的大小,设置实验进行参数调整寻求最佳效果,实验结果见表6和表7。实验结果表明当知识图谱嵌入损失权重λ1=0.5,L2正则项权重λ2=10-7时模型的推荐效果最佳。
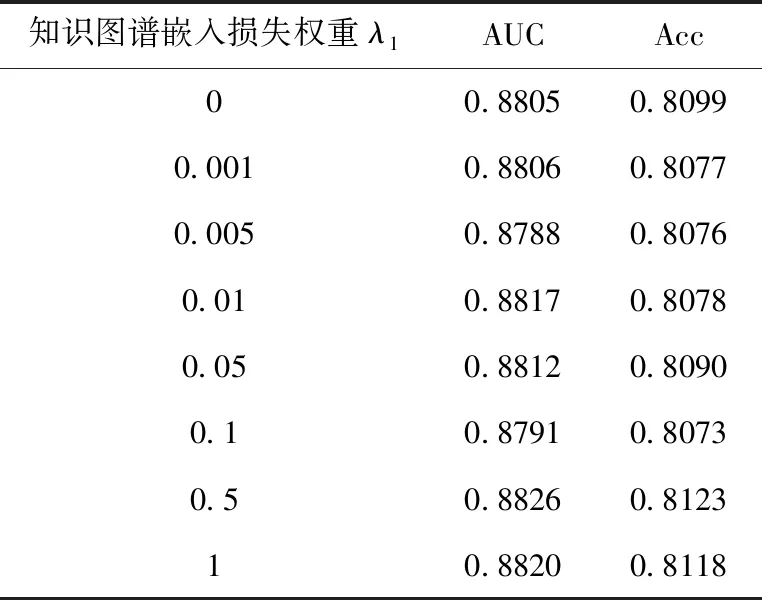
表6 知识图谱嵌入损失权重对点击率预测结果的影响
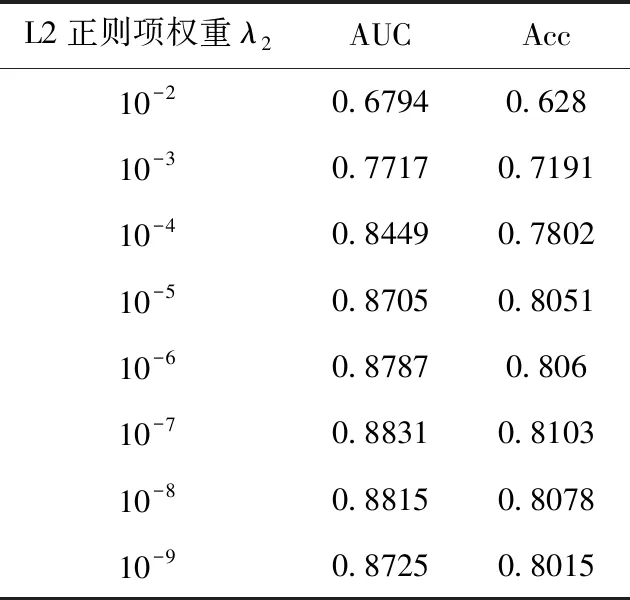
表7 L2正则项权重对点击率预测结果的影响
综上所述,当实验参数设置为特征维度d=8,链路长度k=2,偏好扩散集尺寸m=32,知识图谱嵌入损失权重λ1=0.5,L2正则项权重λ2=10-7时获得最佳结果。
3.4 对比实验结果及分析
为了探究本文提出的融合语义特征和知识特征的推荐模型的性能表现,选取以下推荐模型作为基线模型进行对比实验。在点击率预测场景下的实验结果见表8,在Top-K推荐场景下的实验结果如图3所示。
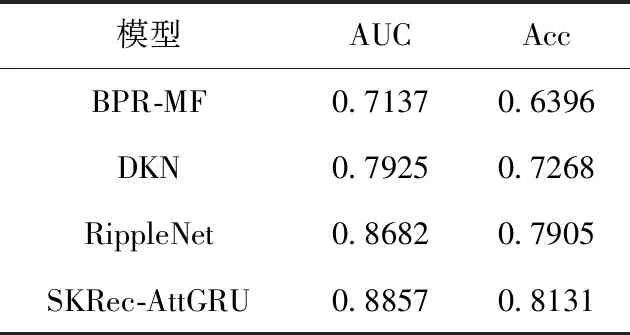
表8 点击率预测场景下的实验结果
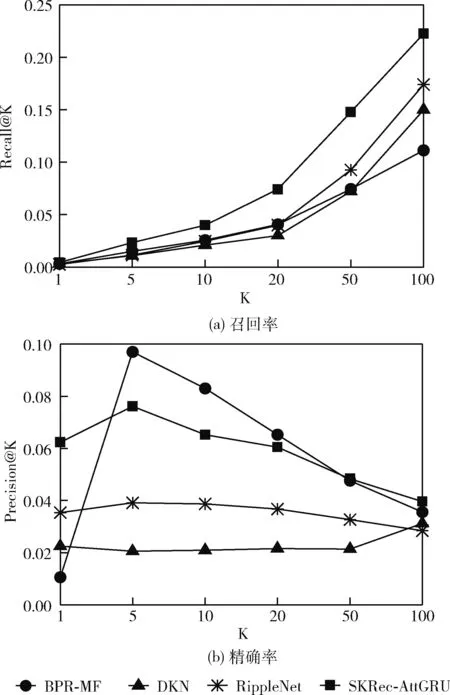
图3 Top-K预测场景下的实验结果
(1)BPR-MF(matrix factorization base bayesian personalized ranking)[26]:最为常用的矩阵分解方法,该方法考虑到用户对于不同项目具有不同的喜好程度,引入贝叶斯个性化排序,基于矩阵分解方法进行用户建模。
(2)DKN(deep knowledge-aware network)[19]:基于知识图谱提取实体的3个层级的特征表示,基于卷积神经网络进行特征融合获得项目表示,为用户进行推荐。
(3)RippleNet[11]:基于“偏好扩散”思想获取用户偏好扩散集,捕获用户高阶兴趣偏好,进而构建用户偏好模型。
根据以上实验结果,综合考虑两个场景下的各模型表现可得出以下结论:
(1)在实验中,BPR-MF的总体效果略微逊色于其它基于知识图谱的基线模型,说明将知识图谱作为辅助信息能够优化推荐结果,图谱中丰富的实体间关系有助于对用户兴趣进行合理扩展,从而提升推荐效果。
(2)SKRec-AttGRU在点击率预测及Top-K推荐场景下的性能表现均优于RippleNet,RippleNet仅获取用户偏好扩散集未挖掘其中潜在信息,而本文所提出模型使用结合注意力机制的门控循环单元挖掘其中深层次特征,从而进一步捕捉用户潜在兴趣,表明加入该结构有利于改进模型的推荐效果。
(3)BPR-MF在Top-K推荐场景下精确率表现较好,而召回率与精确率是一对矛盾的指标,需确保两个指标相对平衡,综合该模型的召回率以及点击率预测场景下的表现可知,该模型实际推荐效果表现一般。
(4)综合考虑两个场景下的实验结果,可得出SKRec-AttGRU的推荐效果最佳,因为它基于知识图谱将语义嵌入特征和知识嵌入特征进行融合,使用门控循环单元结构融合注意力机制对用户偏好扩散集进行挖掘,使得对用户兴趣偏好的建模更细粒度,有助于改善推荐效果。
实验结果表明:本文提出的推荐模型能够更好地捕获知识图谱中的潜在信息以提升推荐效果,验证了该模型的优越性。
3.5 消融实验
为了验证所提出模型中语义特征提取模块和知识特征提取模块以及基于结合注意力机制的GRU的特征提取模块的预测效果,设计变体模型进行消融实验。
(1)基于知识特征的推荐模型(exacting knowledge feature for recommendation model,KRec):该模型仅考虑基于知识图谱学习到的知识特征,未考虑语义特征也未使用GRU进行深层特征提取工作。
(2)基于语义和知识特征的推荐模型(integrating sematic feature and knowledge feature for recommendation model,SKRec):该模型基于知识图谱进行了语义特征与知识特征的获取和融合工作,未使用GRU进行深层特征提取。
(3)基于门控循环单元和知识特征的推荐模型(exac-ting knowledge feature for recommendation model based on gated recurrent unit,KRec-GRU):该模型基于知识图谱进行了知识特征学习后使用GRU进行深层特征提取,未考虑项目对应的语义特征。
(4)基于门控循环单元的融合语义和知识特征的推荐模型(integrating sematic feature and knowledge feature for recommendation model based on gated recurrent unit,SKRec-GRU):该模型基于知识图谱学习了语义特征与知识特征并将其融合,在此基础上利用GRU进行深层特征提取,所使用的GRU未结合注意力机制。
(5)SKRec-AttGRU:该模型基于知识图谱进行了语义特征与知识特征的获取,在此基础上利用结合注意力机制的GRU进行深层特征提取。
在点击率预测场景和Top-K推荐场景下进行对比实验,结果如表9和图4所示。
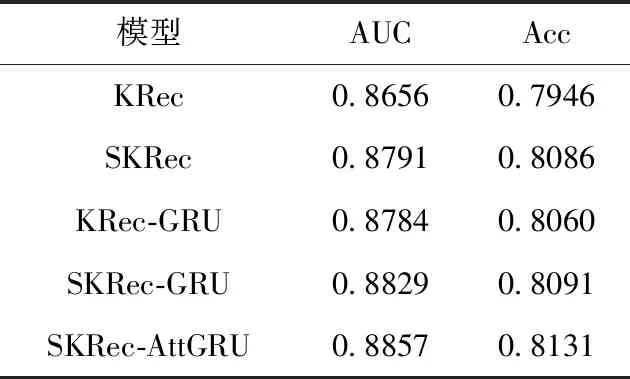
表9 不同特征下的点击率预测结果
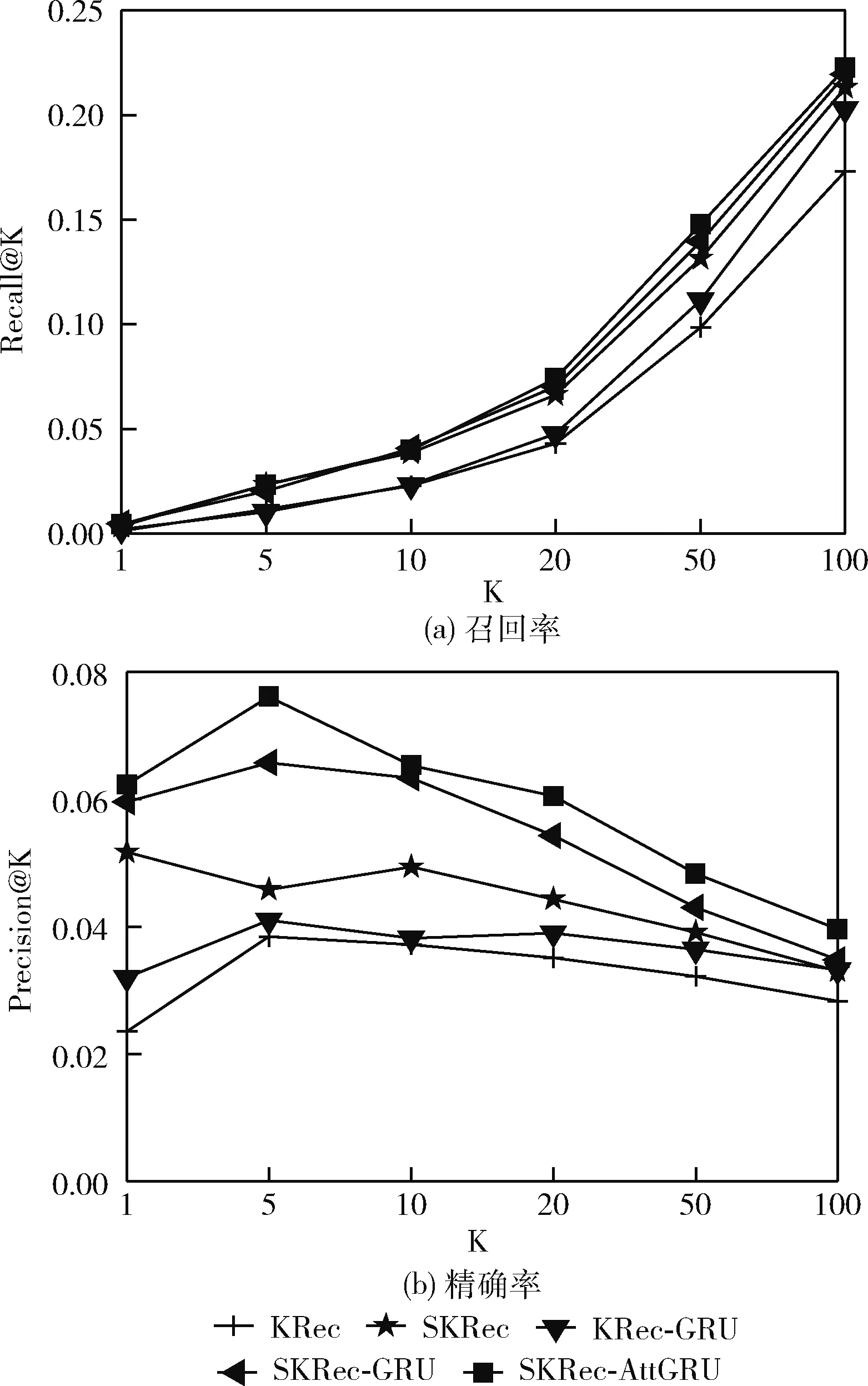
图4 不同特征下Top-K推荐结果
由实验结果可以得出:
(1)SKRec模型的推荐效果优于KRec模型,说明基于知识图谱提取的语义特征模块的引入能够在一定程度上缓解数据稀疏性问题,该模块对推荐结果预测具有重要作用;
(2)KRec-GRU模型的推荐效果优于KRec模型,说明基于GRU的深层特征提取模块有助于构建更精准的用户兴趣模型,能够有效提高推荐效果;
(3)SKRec-AttGRU模型的推荐效果优于未使用注意力机制的SKRec-GRU模型,说明结合注意力机制的GRU能够增强对用户偏好扩散集中关键信息的提取效果;
(4)SKRec-AttGRU模型的推荐效果相较于其它4个变体模型均有所提高,说明了在基于知识图谱进行知识特征提取的基础上引入语义特征以及使用结合注意力机制的GRU进行深层特征提取模块的重要性。
综上,SKRec-AttGRU模型优于其它4种变体模型,融合语义特征与知识特征后基于结合注意力机制的GRU进行深层特征提取能够对用户潜在兴趣偏好进行有效捕获,提高推荐效果。
3.6 稀疏性验证
为验证本文所提出的推荐模型在缓解数据稀疏性问题中的表现,分别设置3个不同的数据子集进行稀疏性验证实验。分别在原训练集中随机选取20%、50%和80%的数据,构成不同数据密度的数据子集1~3(Set1~Set3)进行对比实验,设置K=1,5,10,20,50,100,比较各模型在不同稀疏度数据集下的召回率,实验结果如图5所示。
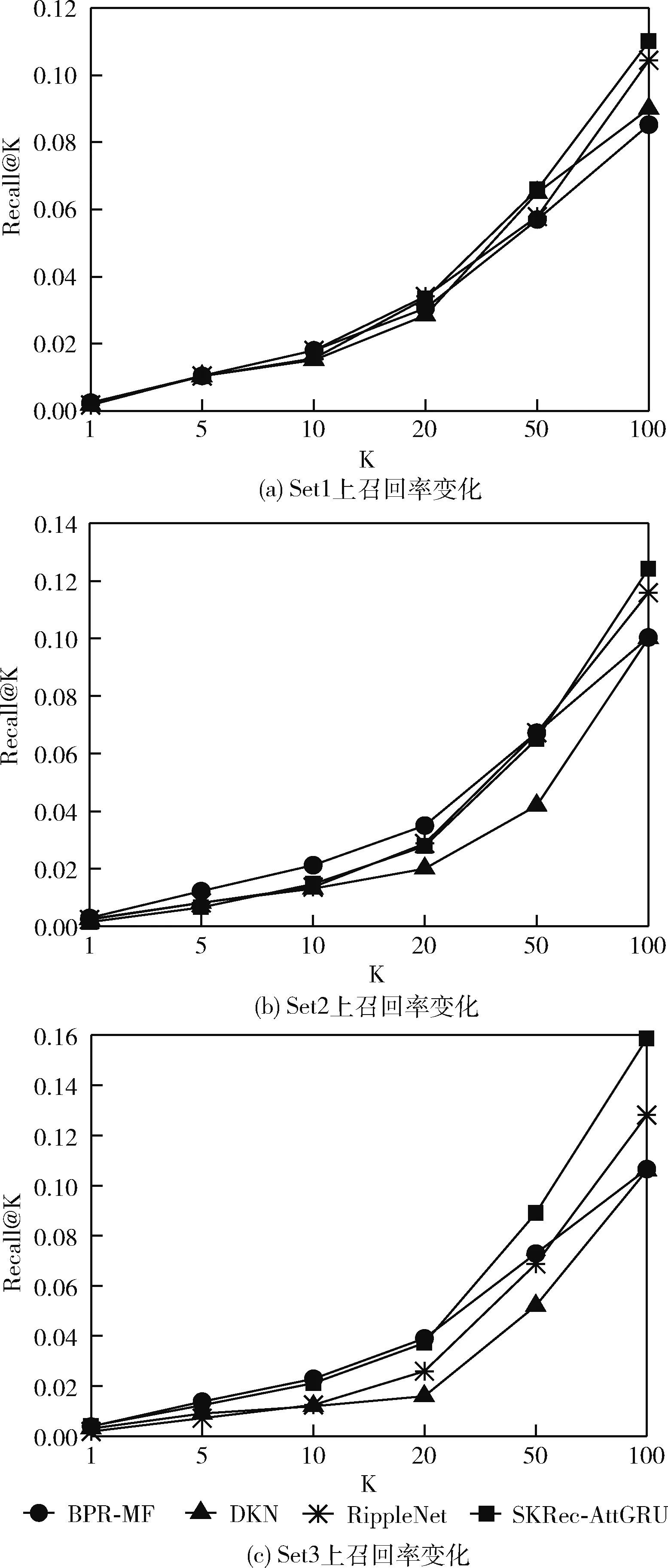
图5 不同稀疏度数据集对实验结果的影响
由图中的实验结果可以得出以下结论:
(1)各个模型的召回率随着数据子集中数据密度的增加而有所提高,说明用户交互数据的稀疏性是影响推荐模型效果的重要因素,数据密度越高表示获取的用户交互数据越详细,模型学习到的用户兴趣特征信息更丰富,推荐结果的质量越高。
(2)SKRec-AttGRU与同样是借助知识图谱作为辅助信息进行用户兴趣建模的RippletNet在数据极度稀疏的情况下,召回率高于其它模型,说明融合知识图谱的推荐模型能够较好地缓解数据稀疏性的问题,提高推荐性能。
(3)SKRec-AttGRU在数据较为稀疏的数据子集set1上表现较好,验证该模型在用户-项目交互数据极度稀疏的情况下仍能保持较好性能,验证了其优越性。
总之,相较于基线模型,所提出模型在数据较为稀疏的情况下仍可保持较好的推荐效果,验证该模型能够有效地缓解数据稀疏性问题。
4 结束语
为了缓解当前推荐方法面临的数据稀疏性问题,提出一种基于结合注意力机制的门控循环单元的融合语义和知识特征的推荐模型。基于知识图谱,对用户项目交互信息蕴含的语义与知识特征进行挖掘并融合,使用融合注意力机制的门控循环单元进行用户深层兴趣捕获,增强推荐效果。实验结果表明,本文所提出模型的各个模块均对推荐结果有重要影响,且该模型能够有效提升推荐效果并缓解数据稀疏性问题。在后续研究中将尝试融合图片或视频等其它多模态信息,对用户潜在兴趣进一步挖掘,进一步提升推荐模型的性能。
猜你喜欢
移动通信(2021年5期)2021-10-25
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
数字通信世界(2017年1期)2017-02-13
领导科学论坛(2016年9期)2016-06-05
中国交通信息化(2014年3期)2014-06-05
