
改进协同训练的肺部CT影像COVID-19病灶分割方法
2023-09-13 03:07汪洋,杨云
计算机工程与设计 2023年8期
汪 洋,杨 云
(云南大学 国家示范性软件学院,云南 昆明 650504)
0 引 言
在新型冠状病毒肺炎(COVID-19)诊疗中,专业医师通过观察患者肺部计算机断层扫描(CT)影像的病灶情况观察病情[1]。利用计算机进行影像配准、分类和分割等任务可以减少医师工作量,其中医学影像分割任务目的在于提取影像中目标区域,描绘出目标区域的影像即标签称为分割图,由专业医师标记的分割图称为金标准数据。医学影像由于复杂且分辨率较高,传统方法效果不佳[2]。
在深度学习方法中,全监督分割网络UNet[3]是大部分研究的基石[4],但依赖金标准数据,半监督学习[5]则利用未标记数据辅助训练。现有的半监督分割研究主要有基于自训练的方法[6,7]构建伪标签数据集[8]加入训练集中迭代训练,通过优化损失函数提升标准协同训练性能[9,10],通过熵最小化[11]和一致性正则化[12-15]得到高质量伪标签,但上述方法未考虑伪标签不确定性问题[16];基于对抗训练的方法[17]通过判别网络和分割网络进行对抗训练提升性能。
针对如何提高伪标签质量和度量伪标签不确定性问题,本文从协同训练[9]方式出发,使用UNet[3]和DeepLabV3+[18]搭建网络,首先集成各网络对未标记数据的输出生成最终伪标签提高伪标签质量;之后,从无监督学习[19]中受到启发,使用JS距离[9]度量伪标签的不确定性,改善伪标签的监督损失。最后在公开的COVID-19数据集上进行实验,结果表明,所提方法改善了伪标签质量,同时减轻因低质量伪标签造成的性能下降。
1 相关工作
1.1 半监督学习
半监督学习目标之一是如何获取质量更高的伪标签。Fan等[7]基于自训练方式通过依次标注定量数据构建高质量伪标签数据集迭代训练;Mean-Teacher[12]从模型出发,最小化学生和教师模型对未标记数据的输出损失,同时利用学生模型更新教师模型,而文献[14,15]通过训练模型对添加扰动的同一数据输出保持一致,获取未标记数据的高质量伪标签;Qiao等[9]通过扩展相似损失和对抗样本损失使各网络学习到更多的互补信息。Zhang等[17]通过引入判别网络和分割网络进行对抗训练不断优化分割网络性能。协同训练则通过各网络互相标记伪标签给予对方训练达到相互指导训练目的。
1.2 不确定性估计
不确定性估计指对预测结果的可信程度进行建模。Kendall等[16]将不确定性的原因总结为数据自身标注不准确程度和模型预测的不准确程度。Zheng等[19]通过多分支网络中辅助分支和主分支之间输出的差异对伪标签不确定性进行建模。本文方法不引入辅助分支,使用JS距离对各网络输出间的差异进行建模来度量伪标签的不确定性,从而给予伪标签监督损失一项正则项,改善分割结果。
1.3 评价指标与损失函数
医学影像分割任务中,常用指标包括基于分割图相似程度和基于混淆矩阵的指标。相似度方面本文选取Dice系数和IOU分,其中X、Y分别为预测分割图和真实分割图,如式(1)、式(2)
Dice(X,Y)=2|X∩Y||X|+|Y|
(1)
IOU(X,Y)=|X∩Y||X∪Y|
(2)
混淆矩阵用于描述二分类问题的分类结果。在COVID-19影像中,定义病灶区域为前景区域,其像素为阳性,非病灶区域为背景区域,其像素为阴性。
如表1所示,TP为真阳性,即预测值和真实值都为病灶区域;FP为假阳性,即预测值为病灶区域但真实值为背景区域;TN为真阴性,即预测值和真实值都为背景区域;FN为假阴性,即预测结果为背景区域但真实值为病灶区域式(3)即敏感度也称召回率,表示真实分割图中有多少阳性像素被预测出来,式(4)即精确率,表示在预测分割图中,真阳性像素预测正确的比例有多少,由于TPR和精确率互斥,因此引入式(5)F1分数评价综合性能。在分割问题中TP、FP、TN和FN值均为一个分割图中所有像素分类结果的总和。上述指标值越大则越优异。
TPR=TPTP+FN
(3)
Precision=TPTP+FP
(4)
F1=2×Precision×TPRPrecision+TPR
(5)
Jadon等[21]总结了不同场景下图像分割任务中常用的损失函数。主要包括交叉熵损失,用于衡量预测分布和真实分布差异,Dice损失衡量集合相似度。
二分类交叉熵损失定义如下式(6)
BCE_loss=E[∑nj(-yjilog(ji)+(1-yji)log(1-ji))]
(6)
Dice损失由Dice系数演变而来,定义如下式(7)
Dice_loss=1-2|X∩Y|+eps|X|+|Y|+eps
(7)
为防止分母出现0,式(7)中定义一个极小值eps,在本文中值为1e-6。
本文将Dice损失和二分类交叉熵损失进行组合,定义为Total_loss,如式(8),其中权重α=0.5
Total_loss=α×Dice_loss+(1-α)×BCE_loss
(8)
2 本文方法
本节介绍本文方法,首先阐述问题定义,之后分别介绍集成伪标签的优势、改善损失函数的方法和整体框架。
2.1 问题定义
在协同训练中,定义f1(v1)=f2(v2),f1和f2表示两个模型,v1和v2表示有标签数据集L={xi,yi}Mi=1下同一数据的不同视图,U={ui}Ni=1和P={ui,pi}Ni=1表示未标记数据集和模型输出,P经过argmax函数处理后得到伪标签数据集Y^={ui,i}Ni=1, 协同训练假设在训练过程中f1和f2互相从未标记数据集U中标记数据构建伪标签数据集P到各自的L中迭代训练,从而互补各自的信息。但从单模态数据中获取同一数据的不同视图条件较难满足,Wang等[20]证明从不同网络角度出发也可以获取较好的性能。
半监督学习中一个问题在于伪标签由模型输出产生,这并不能保证伪标签的准确性,如果使用低质量伪标签迭代训练,则模型会越训练越差,因此多数方法目的在于尽量获取高质量伪标签i,其次问题在于伪标签最理想情况下可以达到i=yi,但多数时候伪标签i无法和真实标签yi相比,即对同一数据xi来说,i和yi之间仍存在误差,因此半监督算法性能上限为全监督算法。从以上两点出发,本文方法首先以平均集成方式获取高质量伪标签i,之后对伪标签i的不确定性进行建模,即估计i和yi之间的误差,为伪标签的监督损失提供一项正则项。
2.2 集成伪标签
如图1所示,图1(a)、图1(b)、图1(c)和图1(d)图分别为真实标签、集成伪标签、UNet和DeepLabV3+输出的伪标签。

图1 加权集成效果对比
集成策略如式(9)
pi=12(piu+pid)
(9)
其中,piu和pid分别为UNet和DeepLabV3+的输出概率分布,pi为集成结果,pi中各像素值经过softmax函数映射到[0,1]的概率值,i则由其经过argmax函数处理得到。首先在Dice系数上,集成方法相比较DeepLabV3+的Dice系数提升1.27%,相比较UNet提升0.99%。从可视化结果可以发现图1(b)消除了图1(c)中错误多余的部分,而相比较图1(d),边缘更细腻,整体Dice系数也有一定提升。实验结果表明,在迭代训练过程中,这种集成方式获取的伪标签相比较标准协同训练互相给予标签更可靠。
2.3 改善损失函数
使用bias表示伪标签i和真实标签yi之间的误差,而i由pi得来,如式(10)
bias=pi-yi
(10)
在监督任务中,由于存在真实标签,因此使用损失函数计算模型输出和yi之间的误差,最小化这个损失将使得预测值逐渐逼近真实值。在半监督学习中并没有真实标签yi,因此使用i替代yi,即bias≈pi-i,对单个网络的训练来说应计算网络输出和i之间的误差,以UNet为例,式(10)可以更改为下式
bias≈piu-i
(11)
在本文方法中,式(11)已经在单个网络的伪标签训练中进行优化,而协同训练一个核心思想是基础网络能够互相优化,充分训练后对同一数据的输出趋于一致,最终两者达到最佳性能,如果两个模型对同一数据的输出不一致,两个模型输出之间的差异就是两者不确定的地方,而pi由式(9)集成而来。因此使用两个模型的输出差异近似bias,式(11)可以改为下式(12)
bias≈piu-pid
(12)
其中,piu和pid分别为UNet和DeepLabV3+的输出概率分布,在实验中使用JS距离来度量bias,如式(13)、式(14)
KL(K‖Q)=∑x∈XKxlogKxQx
(13)
JSD(K‖Q)=12KL(K‖M)+12KL(Q‖M)
(14)
式(13)和式(14)分别表示KL和JS距离计算方式。在式(14)中,K和Q分别为在X下的两个概率分布,M为两者的平均值。KL距离交换分布K和Q结果不同,不满足对称性,JS距离满足对称性,范围在[0,1]之间,能较好的度量两个模型的输出差异。在式(14)中,即K=piu,Q=pid,bias≈E[JSD(piu‖pid)], E表示求解期望值。
如图2所示,图2(b)图和图2(c)图分别为两个模型对同一数据的输出,图2(d)为根据式(12)计算的各像素上JS距离经过归一化后的可视化图像。图4(g)为真实标签和集成伪标签之间的差值,同样经过归一化后进行可视化。在图4(d)中,颜色深度越接近0代表越相似,越接近1越不相似;在图4(g)中,颜色深度等于0代表两个像素值相同,其它深度表示两个像素值不同。可以发现图4(d)和图4(g)中的噪声处相似,因此使用两个模型的输出差异来度量bias。
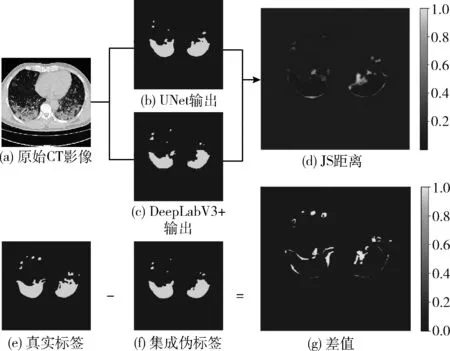
图2 对JS距离可视化
原始JS距离越小表示越相似,所以本文将其取负并带入以e为底的指数中,当此值越大时,说明两个分布越相似。此时,定义伪监督损失Pseudo_loss,对伪标签的损失函数改善如式(15)
Pseudo_loss=exp{-E[JSD(piu‖pid)]}×Total_loss+E[JSD(piu‖pid)]
(15)
当E[JSD(piu‖pid)] 较小时,exp{-E[JSD(piu‖pid)]} 值接近1,此时模型认为Total_loss是可信的,各模型优化式中第一项;当E[JSD(piu‖pid)] 较大时,exp{-E[JSD(piu‖pid)]} 接近0,此时,模型认为Total_loss是不可信的,同时由于第一项值接近0,各模型优化第二项,即优化两个模型输出不同之处,这和Qiao等[9]所指出的给予一项各网络输出间的相似损失类似,加快基础网络的收敛。由于有标签数据集存在真实标签,因此其监督损失不进行正则化。
2.4 训练框架
本文方法在标准协同训练模式上进行改进。如图3所示,首先以有标签数据集预训练两个模型,之后在未标记数据集中随机选取n个未标记数据,使用两个网络推理各自对未标记数据的输出后,通过将双方输出平均集成获得最终伪标签,得到由n个未标记数据和对应的伪标签组成伪标签数据集,并将伪标签数据集加入到训练集当中组成新的训练集,训练过程中遇到伪标签和真实标签按照2.3节分别使用不同的损失策略,直到未标记数据集为空停止训练。
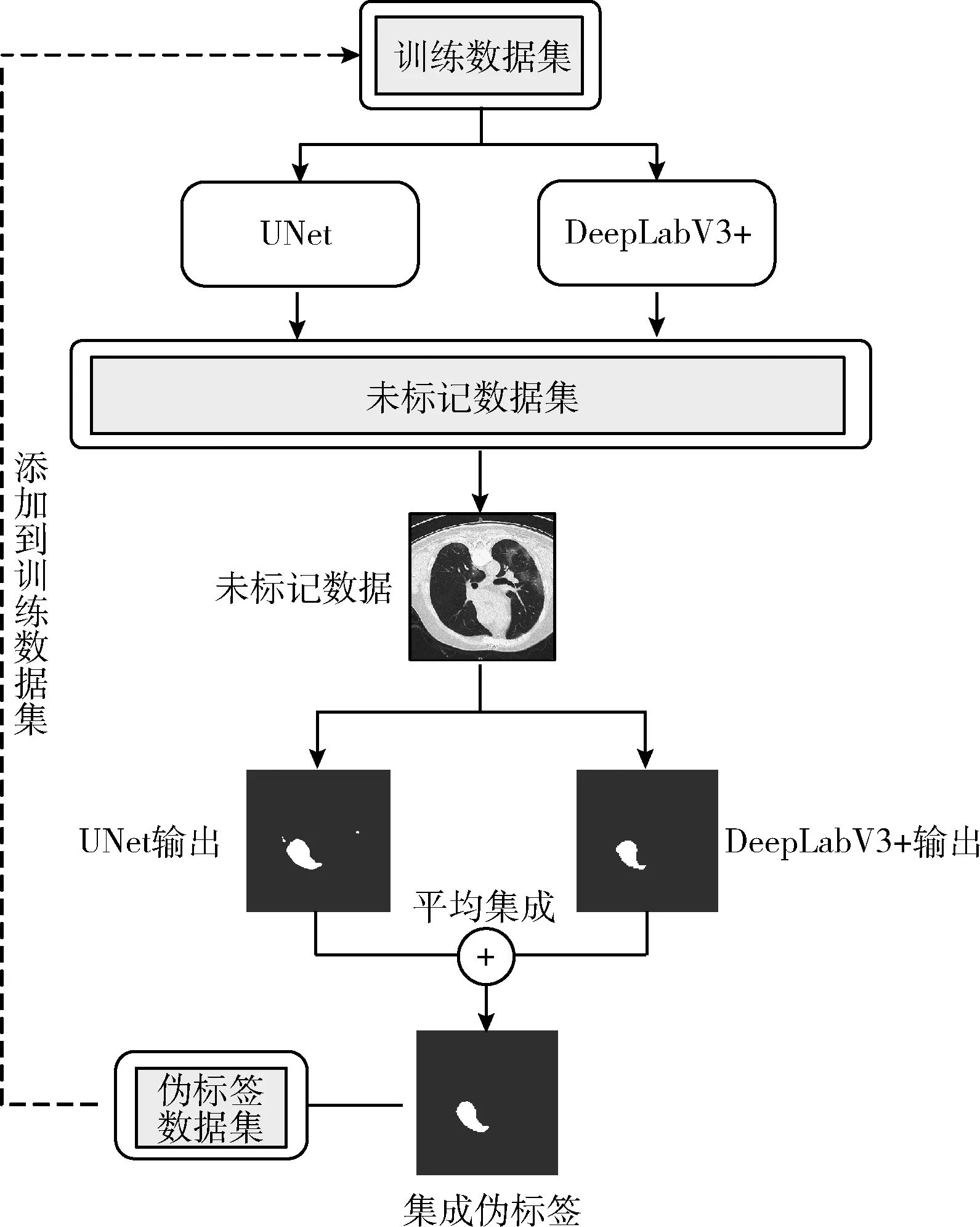
图3 训练框架
下面是具体算法步骤。首先定义:训练数据和未标记数据为D=L∪U,其中L={xi,yi}Mi=1为有标签数据集,U={ui}Ni=1为未标记数据集;DeepLabV3+和UNet网络分别为fd和fu;网络的输出和集成伪标签分别为Pd={pid}M+Ni=1、Pu={piu}M+Ni=1和Y^={i}Ni=1; 循环次数为K;步骤如下所示:
(1)初始化:使用L预训练网络fd和fu;
(2)循环K次:
(3)随机选取n个未标记数据:U′={ui}ni=1, 循环U′:
(4)使用fd和fu推理ui得到 {pid}ni=1和 {piu}ni=1;
(6)得到伪标签数据集U′={ui,i}ni=1;
(7)将U′加入L中,此时L=L∪U′;
(8)使用数据集L={ui,i}ni=1∪{xi,yi}Mi=1训练fd和fu;
(9)从L中随机采样一个批次数据;
(10)如果是{xi,yi},则根据式(8)分别计算fd和fu的输出损失;
(11)如果是{ui,i},则推理另一网络对ui的输出并根据式(15)分别计算fd和fu的输出损失;
(12)各网络计算一个批次数据的损失期望值,更新网络;
(13)达到最大循环次数时,训练结束。
最终结果由各自最佳模型通过加权集成得到,加权系数定义如式(16)
wu=Dice(piu,yi)Dice(piu,yi)+Dice(pid,yi)
(16)
pi=wu×piu+(1-wu)×pid
(17)
其中,piu和pid分别表示两个网络的输出,yi表示真实分割图。wu为UNet输出的权重,1-wu为DeepLabV3+输出的权重,按照式(17),通过两个权重计算最终的输出pi并通过argmax函数处理得到预测分割图。
3 实验与分析
3.1 数据集与处理
本文选用Ma等[22]公布的COVID-19公开数据集,该数据集包含20例患者的CT扫描影像,由放射学专家标注感染区域,数据集示例如图4所示。

图4 数据集示例
本文针对肺部感染区域进行分割任务。由于影像均包含由胸前连续扫描形成的几十到几百张切片,因此首先去除其中非肺部扫描切片,得到1720幅肺部CT切片,并且按照文献中所给方法,将CT切片的Hu值缩放到[-1250,250],标准化至[0,255],在输入网络时,则将所有像素值归一化到[0,1]。在实验中,随机选取400幅切片作为训练集,1120幅切片作为未标记数据集,200幅切片作为测试集。
3.2 实验设置
本文方法中两个网络的优化器均选用Adam,学习率设为1e-4,权重衰减系数设为1e-4,循环次数K设为28,每隔5次,降低学习率至原始0.9倍,每个批次的大小设为8。其中每次共同标记40幅未标记切片加入到训练集当中。在计算Dice损失时两个网络的输出经过softmax函数映射到范围为[0,1]的概率分布。实验设备为Tesla V100(16 GB),框架使用Pytorch搭建,采用不同随机种子进行实验。
在验证本文方法的有效性方面,使用优化损失函数的方法DCT[9],熵最小化方法Advent[11],基于一致性的方法MT[12]、UAMT[13]、ICT[14]、CCT[15]和基于对抗训练的DAN[17]等半监督算法与本文方法对比,均以UNet作为骨干网络,同时对比在标准协同训练上的提升;以两个网络在训练集上监督训练的评价分数作为基准,在训练集和未标记数据集的全部数据上监督训练的评价分数作为性能上限。之后,进行消融实验验证第二节中各个改进部分对最终分割性能的影响。
3.3 结果分析
3.3.1 对比实验结果分析
如表2所示,在结果中可以发现,各网络相较于基准均有所提升,在大多数指标上本文方法获得了更好的性能。

表2 对比实验结果
首先分析基于分割图相似度的指标。本文方法相比较较好的MT方法Dice系数提升1%,IOU分数提升1.74%。基于一致性的方法ICT和CCT在相似度指标上表现不佳,这是因为一致性方法鼓励模型对同一数据添加不同扰动后的输出保持一致,其中ICT通过插值方式获得扰动数据,CCT则通过添加噪声方式获得扰动数据,首先医学影像数据像素值变化范围大,添加扰动后数据变化较大,其次有标签数据较少这使得解码器本身不可靠,因此不能保证扰动数据的输出一致性,这使得伪标签不可靠,因此在医学影像分割任务上表现不佳。不同的是MT和UAMT从模型出发,通过学生模型更新教师模型,这和协同训练中相互指导训练思想类似,因此获得了较高分数,由于教师模型参数由学生模型得到,这使得两者网络通常为同一结构,因此最终分数和本文方法有差距。本文方法相比较DAN的Dice系数提升2.25%,这表明对抗训练并不适合本文任务。DCT增加一项对抗样本损失,对抗样本的产生通过添加噪声实现,标签则由对方网络生成,这不能保证对抗样本对应标签的准确性,因此效果不佳。Advent由于减少了伪标签的熵,因此改善了网络的输出伪标签质量,也获得了不错的分数。
在分析基于混淆矩阵的指标中,首先可视化TPR和精确率指标之间的差异,如图5所示。
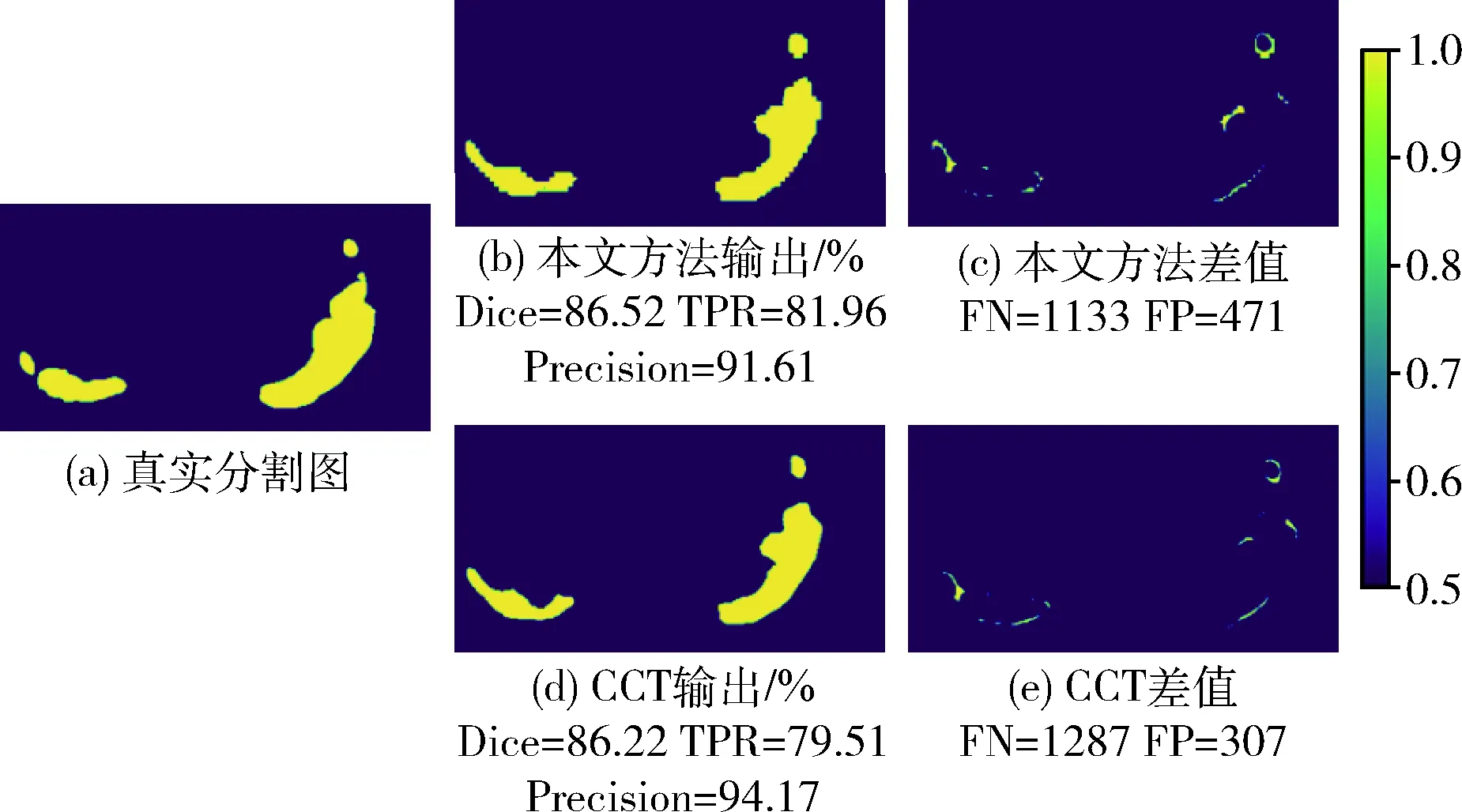
图5 Dice、TPR和精确率指标可视化
在图5中,图5(a)为真实标签,图5(b)为本文方法预测结果,图5(c)为本文方法预测结果和真实标签各像素的差值可视化,图5(d)为CCT预测结果,图5(e)为CCT结果和真实标签各像素的差值可视化,图5(c)和图5(e)中颜色深度等于0.5区域为假阴性区域,颜色深度等于1区域为假阳性区域。从结果可以发现本文方法Dice和TPR分数更高,表明本文方法识别到了更多的阳性像素,对病灶区域更敏感,偏向将像素预测为阳性,因此在图5(c)中,FN数量低于图5(e),FP数量高于图5(e);而CCT则精确率指标更高,这是由于CCT更关注预测的阳性是否正确,因此在图5(e)中,假阴性FN数量较高,而假阳性FP数量较少,模型更偏向将像素预测为阴性,对病灶区域不敏感。从颜色深度可以发现图5(c)相比较图5(e)假阴性区域更少。
在表2中可以发现各方法对敏感度和精确率的侧重点不一样。本文方法精确率相比较MT提升2.82%,CCT则获得了最高的精确率,这表明CCT预测出的阳性像素正确率最高,而本文方法TPR指标更高,这表明本文方法召回了更多的阳性像素,倾向于将像素预测为阳性。F1分数则显示本文方法综合性能最高,相比较MT方法提升2.38%。在基于混淆矩阵指标的任务中,选取合适的方法可以获得更好的结果。
同时,本文随机可视化了一些不同病灶大小的预测分割图,如图6所示,从中可发现在病灶较小时,本文预测分割图的Dice分数也高于其它方法,相应的也更接近真实标签。

图6 分割结果可视化对比
3.3.2 消融实验结果分析
本节分析在第二节各个改进部分对最终分割性能的影响。首先以标准协同训练作为基准,之后对比加入集成方式和在此基础上优化损失函数进行对比。
结果见表3。

表3 消融实验结果
首先在表3中可以看出,各项改进相比较标准协同训练指标均有所提高。集成方式相比较标准协同训练Dice系数提升1.55%,优化损失函数后,相比较集成方式Dice系数提升0.63%,TPR指标提升幅度达到1.98%。从整体上看,集成方式的精确率达到了最高值,这表明在训练过程中集成方式得到的伪标签正确阳性像素的比例高,在迭代训练后,精确率也达到了最高值,同时精确率指标也得到一定提升,最终的F1分数也最佳。在此基础上改善伪标签监督损失后,相比较集成方式其余各项指标均有提升,其中敏感度提升最大,精确率有所降低,这表明优化损失后网络召回了更多的阳性像素,在病灶区域占比较小时,优化损失函数更容易发现病灶区域,最终的F1分数和集成方式相比也差距较小。
4 结束语
在新型冠状病毒肺炎(COVID-19)的诊断中,使用计算机辅助医师诊疗有着重要意义,半监督学习则可以减少对金标准数据的需要。结合两者,本文首先以协同训练方式构建半监督医学影像分割网络,利用共同标记未标记数据伪标签,之后以集成方式获取质量更高的伪标签;在伪标签的不确定性问题中,本文使用JS距离对伪标签的不确定性进行建模,改善伪标签的监督损失。实验结果表明,在测试集整体性能上,本文方法均有较好表现。未来工作还可在如何生成置信度更高的伪标签和不确定性估计上进一步探究,并将本文方法引入到其它任务中。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
数学小灵通·3-4年级(2021年5期)2021-07-16
红领巾·萌芽(2019年8期)2019-08-27
今日农业(2019年15期)2019-01-03
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
中国与非洲(法文版)(2017年10期)2017-11-23
公民与法治(2016年10期)2016-05-17
CHIP新电脑(2016年3期)2016-03-10
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
