
融合高度信息的遥感图像语义分割网络
2023-09-13 03:07钱育蓉
计算机工程与设计 2023年8期
高 梁,钱育蓉+,刘 慧
(1.新疆大学 软件学院,新疆 乌鲁木齐 830046;2.新疆大学 信息科学与工程学院,新疆 乌鲁木齐 830046;3.新疆大学 信号检测与处理重点实验室,新疆 乌鲁木齐 830046;4.新疆大学 软件工程重点实验室,新疆 乌鲁木齐 830046)
0 引 言
遥感图像处理在城市规划、农林管理等方面具有重要作用,传统的研究方法主要依赖于图像的光谱、纹理信息,需要大量的人力、物力,并且这些方法往往只针对某几类的地物进行分类,泛化性能较差。近年来,基于深度学习方法在图像处理领域表现出突出的性能。卷积神经网络(convolutional neural network,CNN)在语义分割任务中具有重要的应用。
基于CNN改进的网络,往往会受限于卷积核的大小,只能获取固定大小的感受野,使得图像的上下文信息没有得到充分利用[1]。为了扩大网络的感受野,一些研究者尝试使用多尺度上下文信息的融合的方法[2]、空洞卷积[3-5]的方法、自注意力的方法[6-8]。基于自注意力的Transfor-mer[9-11]可以通过建模全局的上下文信息[12]。但是,Transformer需要在大量数据的预训练前提下,才能达到较好的性能,对于一些中型或者小型的遥感数据集中表现结果较差[13]。
多模态融合模型[14-16]可以综合利用不同模态信息,能够提高网络的分割性能。常见的遥感图像数据集通过俯视拍摄的方式获取,其真实地物高度信息丢失,使得某些地物在水平方向上具有相似的特征,网络容易误分类。除此之外,遥感图像还具有低照度、多遮挡、空间信息不足的特点。仅仅使用RGB图像进行网络训练,无法充分利用遥感图像中的空间信息,提高网络分割的精度。遥感图像的高度信息可以作为一种特征编码加权普通图像的特征信息。因此,为了进一步提高深度网络在遥感数据集的分割能力,扩大网络的感受野,本文提出了融合高度信息的遥感图像语义分割网络。
1 方法介绍
1.1 总体结构
图1显示了本文提出网络的总体结构。因为编码器-解码器结构可以有效扩大网络的感受野,提高网络获取上下文信息的能力。因此,本文提出的网络也是编码器-解码器结构的。如图1所示,本文提出的网络有5个模块组成:普通图像编码器、数字表面模型(normalized digital surface model,nDSM)图像编码器、位置编码模块(Position Encoding)、Transformer和用于恢复图像分辨率的解码器组成。在解码器结构的设计上,本文并不是简单的对编码器的镜像。本文在解码器中加入自注意力来建模像素之间的语义关联,来提高网络对特征的表达能力。

图1 网络的总体结构
1.2 编码器
本文设计了两个编码器分别从普通图像和nDSM图像中提取特征。除了第一层中输入通道的数量不同外,两个编码器的结构彼此相同。本文选用残差网络(residual network,ResNet)作为提取特征的主干网络。因为语义分割是一个端到端的任务。本文没有使用ResNet中的全连接层,而是只使用了前四层用来提取特征。
普通图像在普通图像编码器的开始阶段依次经过一个卷积核大小为7×7的卷积层(convolution,Conv)、批标准化层(batch normalization,BN)、ReLu激活函数。在nDSM图像编码器中,因为nDSM图像是一个单通道的图像,所以将初始阶段的卷积层的输入通道数设置为1。在后面的特征信息提取过程中,图像会经过池化层来降低特征图的分辨率。然后,图像在经过残差层的过程中,图像的特征信息会被网络提取出来。在高级特征图中,特征图的每一个通道都可以被认为是网络对某一类特征信息的响应。因此,图像经过一系列的残差层之后,网络可以获取输入图像丰富的特征信息。
nDSM图像中包含了地物的高度信息,可以作为一种辅助的信息,来加权网络对某类特征信息的响应。在网络的编码器提取特征的每一个阶段中,nDSM图像编码器将获取的特征信息融入到普通图像编码器中。通过这种方法来增强网络对不同类别特征信息的表达。在编码器的最后阶段,提出的网络将融合的特征图输入到位置编码模块中。
1.3 Transformer
Transformer可以通过自注意力有效捕获上下文信息。首先,将特征图x输入到位置编码模块进行特征融合,增加位置信息,增强标记嵌入模块的特征提取能力,位置编码模块的结构如图2(a)所示。位置编码设计为逐像素的注意力,使得网络可以处理任意大小的输入图像,不需要插值或微调。位置编码模块使用3×3的卷积来获得像素方向的权重,然后通过Sigmoid函数进行缩放。x∈Rc×h×w为输入的特征图,c为特征图的通道数,h和w分别为特征图的高和宽,x在位置编码模块的计算过程如下所示

图2 位置编码器和Transformer设计细节
=BN(Conv(x))×Sigmoid(Conv(BN(Conv(x))))
(1)

图3 EMSA设计细节
EMSA(q,k,v)=IN(Softmax(Conv(qkTdk)))v
(2)
在这里,Conv(.) 卷积核的大小为1×1,它可以模拟不同头部之间的相互作用
x′=+EMSA(LN())
(3)
在EMSA之后加入了前馈神经网络(feed-forward network,FFN),以进行特征变换和非线性处理
x=x′+FFN(LN(x′))
(4)
1.4 解码器
编码器主要是用来获取富含语义信息的特征图。在解码器部分,高级特征图通过特征映射逐渐恢复到输入图像的分辨率。在本节中,将详细描述本文设计的解码器结构,该结构的设计细节如图4所示。

图4 解码器层结构
图像的上下文信息对于语义分割至关重要,提高网络获取上下文信息的能力可以提高语义分割的精度。自注意计算可以获得像素之间的语义关联,通过计算得到的协方差矩阵,可以判断两个像素之间的特征是相似和迥异。一个像素和特征图中的其它像素进行自注意计算,就可以获取该像素与特征图中其它像素之间的关系。高级特征的每个通道的图可以看作是一个类特有的响应,不同的语义响应是相互关联的。通过利用任意两个通道图之间的依赖关系,本文改进了相关语义的特征表示。因此,本文将注意力加入到解码器中来建模任意两个通道之间的依赖关系。具体的,输入的特征图x∈Rc×h×w,c为图像的通道数,h为图像的高度,w为图像的宽度。在x和x的转置之间执行矩阵乘法。计算公式如下所示
ej,i=exp(xj×xi)∑Ci=1exp(xj×xi)
(5)
其中,ej,i第i个通道对第j个通道的影响
Ej=∑Ci=1(ej,ixi)+xi
(6)
另外,本文将ej,i与xi的转置进行矩阵的乘法,得到的结果与xi进行元素求和的操作,最终得到经过特征增强的特征图E∈Rc×h×w。Ej中的每个值都代表了当前通道图与其它所有的通道图的加权和,这模拟了通道之间的长期语义相关性。
2 实验细节
为了验证所提出方法的有效性,本文使用韦兴根和波茨坦数据集进行网络的测试。在这一节中,本文首先介绍数据集。然后,本文介绍了实验中设置的一些参数。
2.1 数据集
2.1.1 韦兴根
韦兴根数据集包含33张图像,每张图像由从较大的正射影像镶嵌图中提取的真实正射影像组成,地面采样距离为9 ms,每个图像约为2500×2500分辨率大小。本文使用的图像包含3个波段,分别对应于近红外(near infra red,NIR)、红色(Red,R)和绿色(Green,G)波长,即NIRRG图像。本文使用了nDSM作为另外一种数据源输入到网络中。nDSM就是将数字表面模型(digital surface model,DSM)中的地表信息过滤,得到了所有高于地面的地物相对于地面的高度信息,能够反映地物的真实高度。这种高度信息对于区分遥感图像中不同类型地物(如建筑物与不透水表面、树与矮植)具有重要作用。
请注意,本文使用了目标边缘未经侵蚀的真实图用于测试。本文按照官方的划分原则,将其中的16张作为训练集(图像id:1,3,5,7,11,13,15,17,21,23,26,28,30,32,34,37),另外的17张作为测试集(图像id:2,4,6,8,10,12,14,16,20,22,24,27,29,31,33,35,38)。为了适应本文实验设备的GPU内存大小,本文将提供的原始图片裁剪为256×256的小图片,使用了随机的横向翻转和纵向翻转来增强数据集。
2.1.2 波茨坦
波茨坦语义标注数据集由38张图像组成,地面采样距离为5 ms,每个图像约为6000×6000分辨率大小,该图像为RGB图像,使用nDSM图像作为一个辅助数据源。本文按照官方的划分原则,将其中的13张作为测试集(因为提供的标签数据集中缺少03_13,所以选用的图像id:02_13,02_14,03_14,04_13,04_14,04_15,05_13,05_14,05_15,06_13,06_14,06_15,07_13),另外的24张作为训练集(图像id:2_10,2_11,2_12,3_10,3_11,3_12,4_10,4_11,4_12,5_10,5_11,5_12,6_7,6_8,6_9,6_10,6_11,6_12,7_7,7_8,7_9,7_10,7_11,7_12)。本文同样使用了没有经过边缘侵蚀的地面真实值用于测试,并且采用了和韦兴根数据集相同的数据增强方式。
2.2 评价指标
本文使用了数据提供者建议的评价指标,有:交并比(intersection over union,IoU)、F1分数(F1)、总体精度(overall accuracy,OA)、平均IoU(mean intersection over union,mIOU)、平均F1分数(mean F1-score,mF1)。在介绍这些指标的具体公式之前,先介绍混淆矩阵的一些符号:真正例(true positive,TP)、真负例(true negative,TN)、假正例(false positive,FP)和假负例(false negative,FN)
precision=TPTP+FP
(7)
recall=TPTP+FN
(8)
其中,precision代表了标记为正类的元组实际为正类所占的百分比。recall代表了正元组标记为正的百分比。
IoU和mIoU的计算公式如下
IoU=A∩BA∪B
(9)
mIoU=1N∑Nk=1IoU
(10)
其中,A代表了真实值,B代表了预测值,N为目标类别数。
F1、mF1和OA计算公式如下
F1=2precision×recallprecision+recall
(11)
mF1=mean(2precision×recallprecision+recall)
(12)
OA=TP+TNTP+FP+FN+TN
(13)
2.3 实验参数
本文使用的实验环境的参数版本为:PyTorch 1.4.0,CUDA 10.1,Python 3.7和CuDNN 7.6.5。这些网络使用Adam优化器,权重衰减为0.0002。为了减轻不平衡类别的影响,本文采用的交叉熵损失权重如下所示
Wclass=1log(Pclass+c),c=1.12
(14)
Pclass是类别平衡参数,主要是解决数据集类别分布不平衡的问题。韦兴根和波茨坦数据集中,本文将批处理大小设置为16,以适应本文的GPU内存,初始化学习率为0.0005,网络在单个2080TiGPU上跑200 epochs。
3 实验和讨论
在这一章节中,本文通过一系列的消融实验讨论了提出网络的有效性。然后,本文将提出的方法在韦兴根和波茨坦数据集中与最先进的方法进行比较,并且讨论了实验的结果。
3.1 消融实验
在这一节中,本文将提出的网络与基线网络(fully convolutional network,FCN)进行实验对比,FCN[1]将CNN中的全连接层替换为卷积层实现了端到端的输出,使用了能够增加特征图尺寸的反卷积层,实现了精细的分割结果,极大推动了深度学习在像素级别的语义分割任务中的应用。在韦兴根数据集中的定量比较结果见表1,黑色字体代表性能最好。双分支网络同样使用了ResNet作为特征提取网络,使用NIRRG和nDSM图像作为输入图像,而双分支+改进解码器与双分支网络相比,多了一个基于自注意的解码器。最后,本文提出网络与双分支+改进解码器网络相比多了一个Transformer。
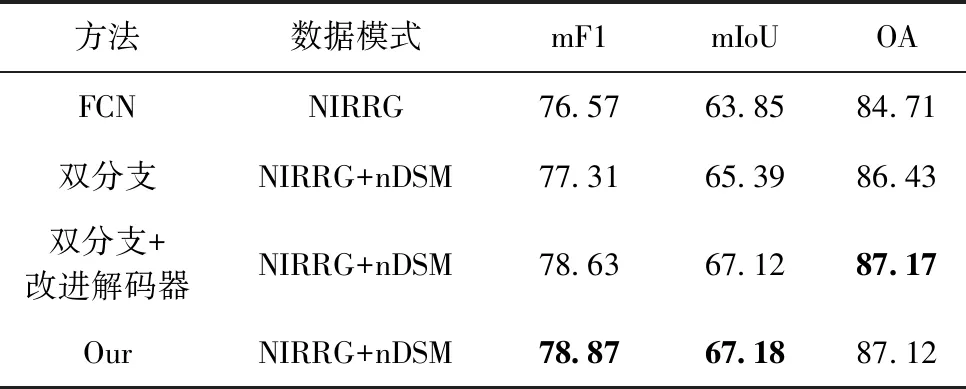
表1 消融实验结果
通过表1可以看出双分支的网络会比单分支的网络实验的结果要好,这应证了本文的猜想,多个数据源可以为网络提供更多的特征信息,提高网络的分割的精度。对比双分支网络和加了改进解码器的网络,可以看到提出的解码器可以进一步提升网络的特征提取能力。对比双分支+改进解码器网络和本文提出的网络,可以看到Transformer能够进一步提升网络性能。总的来说,本文提出的网络在消融实验中,比单分支网络FCN提高了2.3%mF1、3.33%mIoU和2.41%OA。
3.2 类激活映射图
为了更加清晰地展示本文提出的网络的特征提取能力,使用了类激活映射的方法对FCN和本文提出网络的最后一个卷积层进行了可视化,如图5所示,图像中的高亮区域代表了网络对特定类别的重点关注区域,而在图像暗的区域,则代表的是网络不关注区域。类激活映射可以展示网络对不同类别地物的识别能力。类激活映射图最初在文献[18]中提出,通过将特征图与某个类对应的权重相乘,然后用热力图归一化,最后将这些图恢复到输入图像的大小,就可以看到网络的重点关注区域。图5中的第一列的第一行是输入的普通图像,第一列的第二行是标签图。图5从第二列到第五列分别代表了网络对不同类别的地物特征的识别能力。对比第一行和第二行的类激活映射图,可以看到本文提出的网络对特征识别能力更强。

图5 消融实验的类激活映射
3.3 混淆矩阵
混淆矩阵作为精度评价一种方式,可以看出网络的分割性能。混淆矩阵中的主对角线是被正确分类数目的占比。在韦兴根数据集结果的对比如图6所示,混淆矩阵主对角线图像块的颜色越深,被认为是被正确分类的数据越高。从图6中可以看出,树和矮植容易被误分类,这主要是因为树和矮植在水平方向上特征相似,类间差异小,单数据源的FCN无法有效区分这两种地物。但是将具有高度信息的nDSM图像加入到网络当中去时,可以看到本文提出网络对这两种地物误分类降低。除此之外,从图6中可以看出小尺度的车也容易被分到不透水表面的那一类中。这是因为小尺度的车在卷积运算获取特征的过程中,容易受周围的不透水表面特征的影响,本文提出的网络因为使用了具有自注意力机制的解码器,可以增强对特征的提取能力,因而本文提出的网络可以较好的识别这两种地物。除此之外,Transformer可以建模全局的上下文信息,使得网络能够识别当前像素与图像中其它像素的关系,因而本文提出的网络可以对像素进行更加准确分类。
3.4 韦兴根数据集的实验对比
本文在韦兴根数据集上将本文的网络与Unet[19]、RESUnet[20]、Fast-scnn[21]、PSTNet[16]、MAVNet[22]、MFNet[23]、RTFNet[24]进行实验对比。Unet采用了一个编码器-解码器的结构来扩大网络的感受野,并且通过级联的方式将低级细节信息融入到高级的特征图当中,但是Unet冗余信息太多,导致网络训练很慢。RESUnet主要实现了Unet和Resnet的结合。Fast-scnn针对卷积运算进行了改进,减少了重复计算。PSTNet是一个融合RGB图和热图的网络,但是该网络在处理nDSM图像时,出现了网络不收敛的情况,考虑到PSTNet不能有效的从nDSM图像中获取高度信息,在实验中主要是针对普通图像进行了实验。MAVNet 是一种用于微型飞行器的高效残差分解卷积网络。MFNet是一种融合RGB图像和热图的网络,解决了夜间能见度低和恶劣天气条件下获取的RGB图像分割精度低的问题。在RTFNet融合了RGB和热图实现了低照度和眩光条件下的高精度语义分割。
本文分别对比了单一数据源和多数据源网络的实验性能。对于单分支的网络,NIRRG图像是三通道的图像可以直接输入。除此之外,为了验证高度信息在单分支网络中的作用,本文还将NIRRG和nDSM图像合并为四通道图像输入到单分支网络中。对于双分支的网络,NIRRG和nDSM图像可以分别输入到编码器当中。所有网络都经过训练,直到损失收敛,实验结果见表2,黑色字体表示最好的结果,下划线表示次好。

表2 韦兴根数据集定量比较结果
通过表2可以看出本文提出的网络在综合指标mF1、mIoU和OA取得最好的性能,并且对建筑物、矮植、不透水表面有一个好的分割结果,但是在树和车这两个类别中可以得到第二好和第三好,主要的原因是树和矮植特征相似,网络在获取树的特征容易受到周围矮植特征的影响,这个问题在其它网络的分割结果中也有所体现。因此遥感图像中的这种类间相似性对分割模型的性能有较大的影响,仍然是当前遥感领域需要研究的问题。车相较于其它地物高度信息不明显,nDSM提供的高度信息不能有效提高车的识别结果。
在韦兴根数据集中的定性比较结果如图7所示。通过图7可以看出本文提出的网络可以对不同大小的地物有一个较好的识别,并且对不同大小的地物边界识别较为精确。遥感图像中的类间相似性也是影响网络识别性能的重要因素,方框的区域来看,树和矮植就是具有这种类间相似性的两种地物。这两种相似的地物如果仅仅只通过NIRRG图像来看,肉眼很难分辨出两种地物的边界。从图7中可以看出UNet_3、RESUnet_4、Fast-scnn_3、Fast-scnn_4、PSTNet、MAVNet不能对树的边界实现有效的识别,而本文的网络可以从高度信息特征和全局上下文信息的层面获取关于地物的特征信息,实现较为精确的分类。

图7 韦兴根数据集定性比较结果
3.5 波茨坦数据集的实验对比
本文在波茨坦数据集中对比了单一数据源和多数据源网络的实验性能,实验结果见表3,黑色字体表示最好的结果,下划线表示次好。对于单分支的网络,RGB图像是三通道的图像可以直接输入。除此之外,为了验证高度信息在单分支网络中的作用,本文还将RGB和nDSM图像合并为四通道图像输入到单分支网络中。对于双分支的网络,RGB和nDSM图像可以分别输入到编码器当中。所有网络都经过训练,直到损失收敛。

表3 波茨坦数据集定量比较结果
通过表3可以看出,本文提出的网络可以对不同大小的地物有个较好的识别。总的来说,本文提出的网络在指标mIoU、OA和mF1均能达到最好的结果。但是针对树和车这类目标仍然存在着一些性能上的不足,针对无法通过高度信息融合来提高分类精度的地物,仍然需要探寻其它有效的方法来提高遥感图像语义分割的精度。
在波茨坦数据集中的定性比较结果如图8所示。从图8中可以看出本文对不同类别的地物均有一个较为准确的识别。特别的,在图8中方框区域,汽车的右边有一棵树,但是因为树只有枝干,肉眼很难分辨出树特征。网络对于这样的地物特征也很难处理,导致Unet_4、RESUet_3、RESUet_4、Fast-scnn_3、Fast-scnn_4、PSTNet、MAVNet对于这一区域识别的不够准确,出现了大量的误分类。本文提出的网络可以从多个数据源上获取特征信息,并且利用Transformer有效获取特征图的上下文信息。因此,本文提出的网络实现较为准确的分割。

图8 波茨坦数据集定性比较结果
4 结束语
本文提出了一个融合高度信息的遥感图像语义分割网络。该网络采用了双分支的结构,分别提取普通图像和nDSM图像的特征信息。针对传统的卷积网络无法有效获取上下文信息的问题,本文提出的网络融合Transformer,Transformer通过EMSA获取特征图的全局上下文信息,能够提高网络的特征提取能力。除此之外,本文还将自注意力加入到解码器当中,使得解码器对于高级特征图的语义信息建模的更加准确。通过类激活映射图可以看到本文提出的网络对于地物的特征信息更加敏感。通过对比实验验证本文提出的网络与其它先进的网络相比,取得了一个具有竞争力的结果。通过实验发现对于某些地物不能通过融合高度信息提高分割的精度,后续将继续进行多模态语义分割的研究,来提高模型的分割精度,并考虑推广到城市规划的实际应用当中。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
开放教育研究(2020年2期)2020-03-31
家庭影院技术(2019年8期)2019-12-04
成都信息工程大学学报(2018年3期)2018-08-29
电子设计工程(2017年20期)2017-02-10
现代语文(2016年21期)2016-05-25
电子器件(2015年5期)2015-12-29
大连民族大学学报(2015年2期)2015-02-27
