
跨失真表征的特征聚合无参考图像质量评价
2023-09-13 03:07郝大为张相芬袁非牛
计算机工程与设计 2023年8期
郝大为,张相芬,袁非牛
(上海师范大学 信息与机电工程学院,上海 201418)
0 引 言
目前,图像质量评价(image quality assessment,IQA)方法主要分为两类:主观图像质量评价和客观图像质量评价。客观图像质量评价主要有[1]:全参考图像质量评价、半参考图像质量评价和无参考图像质量评价(no-reference image quality assessment,NR-IQA)。传统的NR-IQA需要事先知道图像的失真类型,然而真实失真场景中的图像失真类型往往都是未知的,这时基于特定失真类型手工设计特征的方法在复杂多变的未知失真类型场景中往往表现出较强的局限性,模型不能准确预测失真图像的质量分数。
近几年发展起来的基于卷积神经网络(convolutional neural network,CNN)的NR-IQA得到越来越多人的关注。这类方法无需针对特定失真类型手工设计特征,直接将原始失真图像输入CNN中提取特征进行预测,利用卷积神经网络强大的特征表达能力,在NR-IQA任务中获得了出色的性能表现。当前基于CNN的NR-IQA按照其网络架构设计主要分为两类。第一类网络结构借鉴迁移学习的思想,把在大规模图像分类数据集ImageNet上预训练的CNN作为主干网络,将模型在NR-IQA任务上进行微调,然后预测失真图像质量分数。例如,Yang D等[2]提出了一个孪生神经网络架构,将预训练的VGG网络作为特征提取网络,通过交叉数据集训练获得了较好的性能。Hosu V等[3]基于InceptionResNet[4]网络结构设计了用于NR-IQA任务的深度学习模型KonCept512。另一类网络结构针对不同尺度下的特征图设计多级特征融合模块,以缓和下采样过程中图像质量特征降质的问题。代表性的有,Wu J等[5]提出一种端到端的用于NR-IQA任务的级联深度神经网络(cascaded CNN with HDC,CaHDC),对图像进行多级特征提取,进而进行质量预测。Li F等[6]提出一个多尺度和分层融合的网络架构(multi-task deep convolution neural network with multi-scale and multi-hierarchy fusion,MMMNet),用来提取图像显著的失真特征。虽然上述基于CNN的模型在当前合成失真图像质量评价数据集上取得了较优的性能,但是在真实失真图像质量评价数据集上往往泛化能力欠佳。
主要有以下几方面的原因:①现有的合成失真图像质量评价数据集一般包含不超过30张的参考图像,图像内容单一,且失真类型较少,使得CNN的学习能力受限,模型很容易出现过拟合的现象。②目前基于深度学习的方法所设计的特征提取网络没有充分挖掘相同或相似失真类型之间共有的失真信息。
在图1中我们展示了6张来自Kadid-10k数据集[7]中的图像,图1(a)~图1(c)为3张基于对比度改变的失真图像,其差异主观质量分数均为3.27,图1(d)~图1(f)为3张具有相同内容的图像,其失真类型分别为颜色相关失真、压缩失真、空域失真,差异主观质量分数均为3.27。从图1(a)~图1(c)和图1(d)~图1(f)可以看出,对于相同失真类型的不同图像内容或是不同失真类型相同图像内容,其主观质量分数有时表现为相同或相近,这就要求模型能够充分学习相似失真类型以及跨失真类型的特征表达,因此对模型的辨识能力提出了更高的要求。此外,我们进一步对图1(a)~图1(c)和图1(d)~图1(f)中的失真图像分别进行0°到180°方向的radon变换得到图2(左)和图2(右),通过可视化图1失真图像的显著性特征,再次印证了相同失真类型以及不同失真类型的图像往往包含共有的失真先验知识这一结论。

图1 来自Kadid-10k数据集[7]的6张失真图像
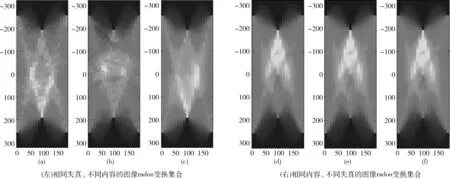
图2 0°到180°方向的radon变换集合
本文借鉴人类视觉系统的特性,即使得NR-IQA模型能够像人类一样,通过学习一种或几种失真类型信息快速推理新的失真类型特征信息并预测质量分数。本文贡献如下:
(1)设计了基于不同失真类型的元任务,采用与模型无关的元学习优化算法对模型进行优化,得到具有跨失真类型推理能力的(cross-distortion representation of feature aggregation,CDR-FA)NR-IQA框架;
(2)构建了具有跨不同失真类型推理能力的元知识图结构,学习不同失真类型共有的失真先验知识,帮助模型适应未知的失真类型;
(3)引入了基于注意力机制的特征融合操作来获得失真图像的显著性加权因子;
(4)所提出的方法不仅超出了当前在真实失真图像质量评价数据集上表现较优的方法,而且在合成失真图像质量评价数据集上也获得了具有竞争力的成绩。
1 基于元学习优化的CDR-FA框架
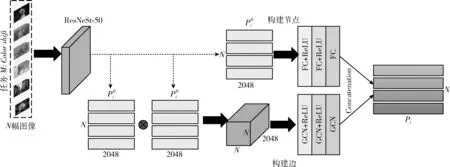
在这一部分,我们介绍了所提出的CDR-FA NR-IQA框架,如图3所示。输入不同的元训练任务集合,每一个任务代表一种失真类型,总共有M种不同的失真类型。CDR-FA NR-IQA框架由3部分组成:主干网络提取低级语义特征;图表示模块聚合相同失真类型共有的失真先验知识,输出图表示向量;基于注意力特征聚合模块产生相同失真类型的显著特征向量,将显著性特征向量输入Softmax层提取每种失真类型不同空间尺度信息,得到注意力向量;将注意力向量和图表示向量进行逐通道的融合得到特征融合向量;最后,将特征融合向量输入到质量回归预测模块预测失真图像的质量分数。

图3 跨失真表征的特征聚合无参考图像质量评价框架
我们定义CDR-FA模型为Fθ(·)
=Fθ(I)
(1)
其中,I代表输入图像,代表输入图像的预测质量分数,θ代表网络整体权重参数集合。
我们使用监督学习中常用的回归损失函数均方误差(mean squared error,MSE)函数作为整体框架的损失函数,其表达式为
L=q-22
(2)
其中,L表示输入图像I的真实质量分数q与预测质量分数之间的差值。我们通过最小化损失函数L来优化模型参数。
2 针对NR-IQA任务的元学习算法
本文以Finn C等[8]提出的与模型无关的元学习(model-agnostic meta-learning,MAML)优化算法为理论基础,针对NR-IQA任务,设计基于优化的元学习算法提升NR-IQA模型的泛化性能。
首先,基于特定类型失真的NR-IQA任务建立元训练集合Up(T)meta={UTms,UTmq}Mm=1。 其中,UTms代表第m个任务的支持集,UTmq代表第m个任务的查询集,M表示任务的总数(即M种不同的失真类型)。
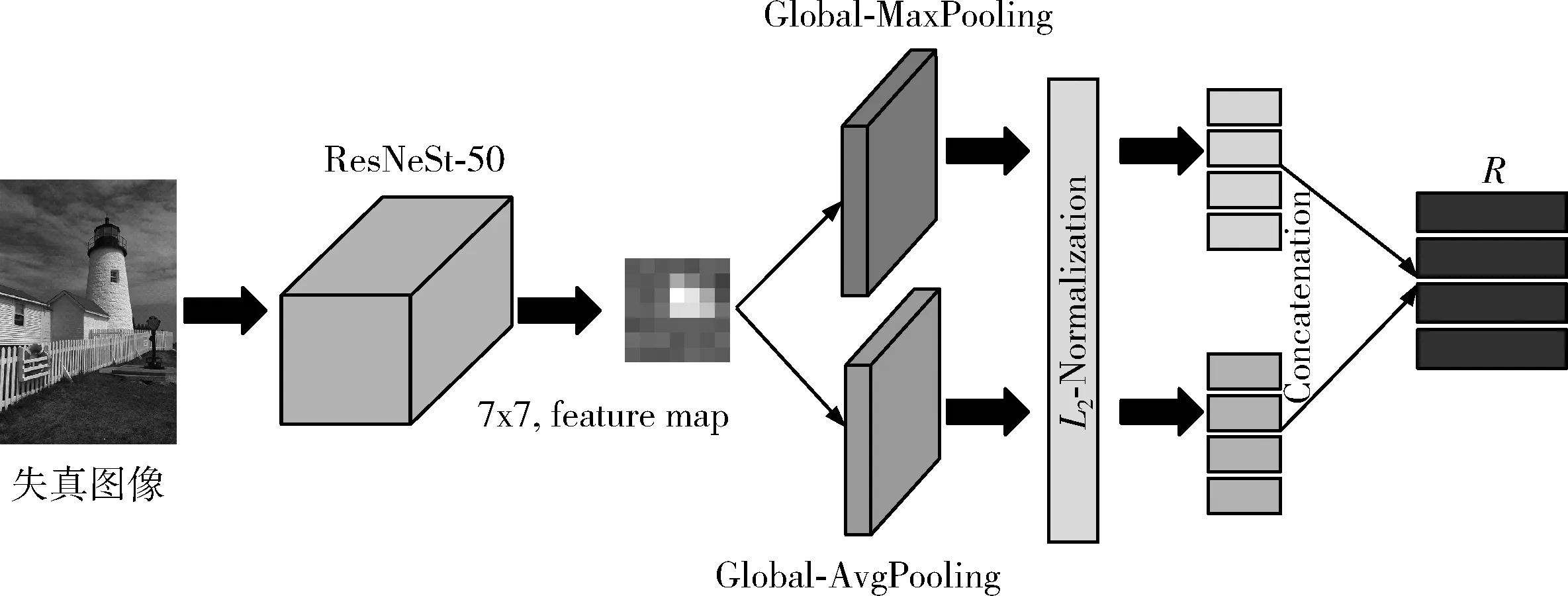
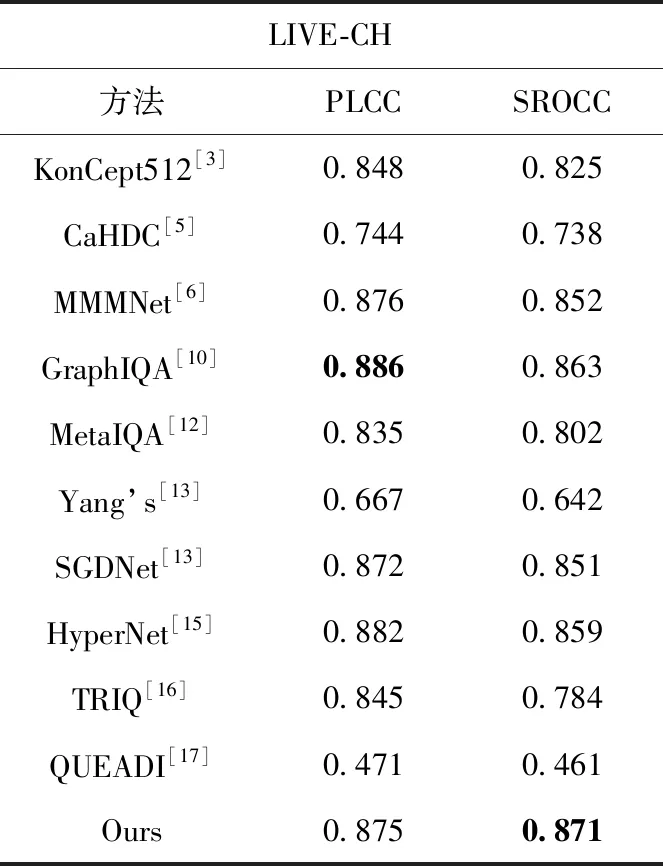
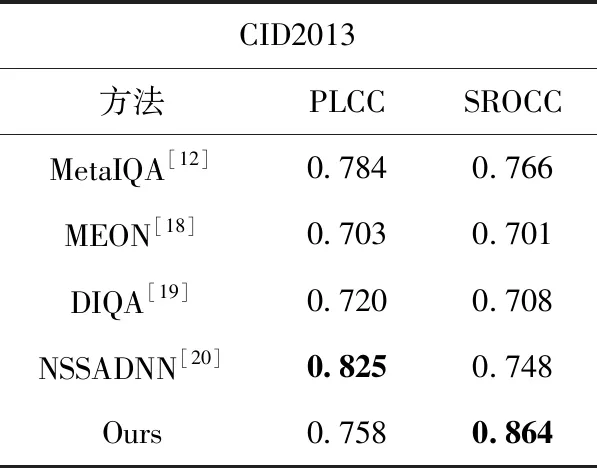
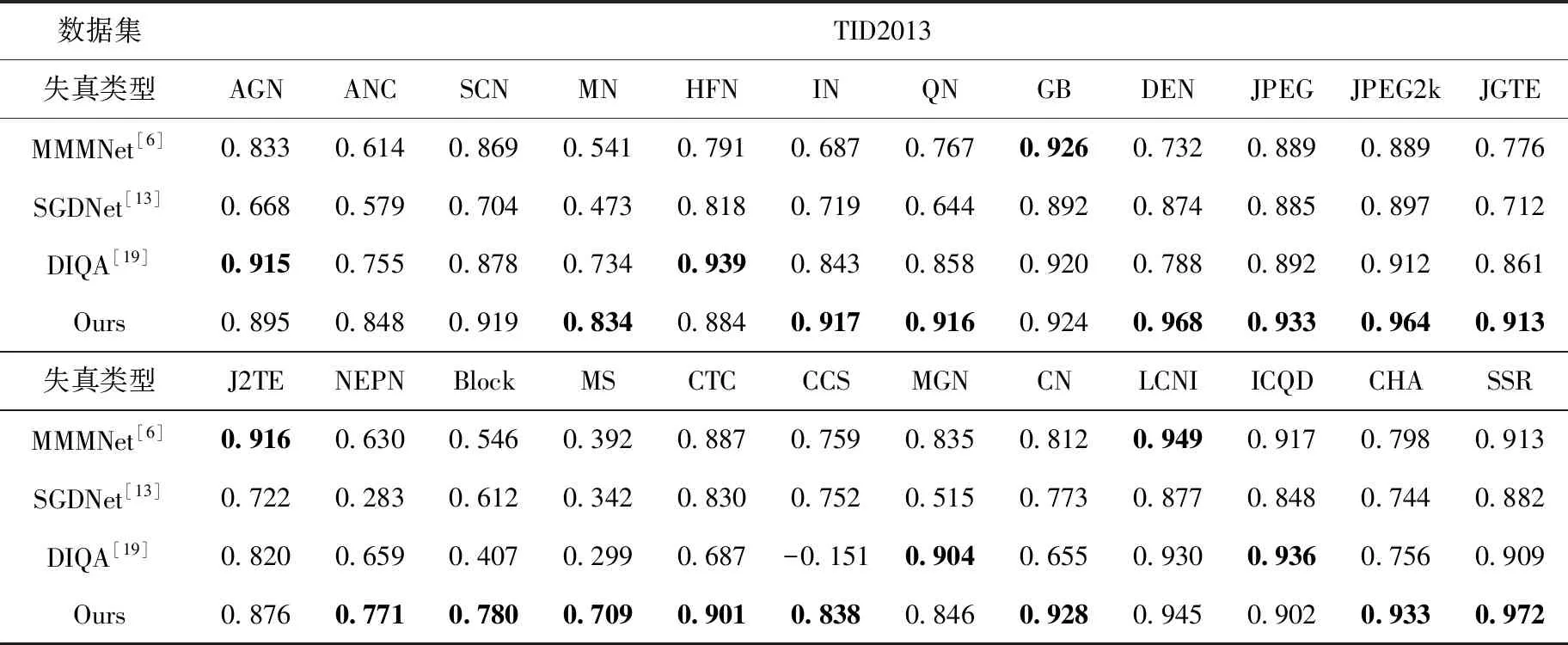
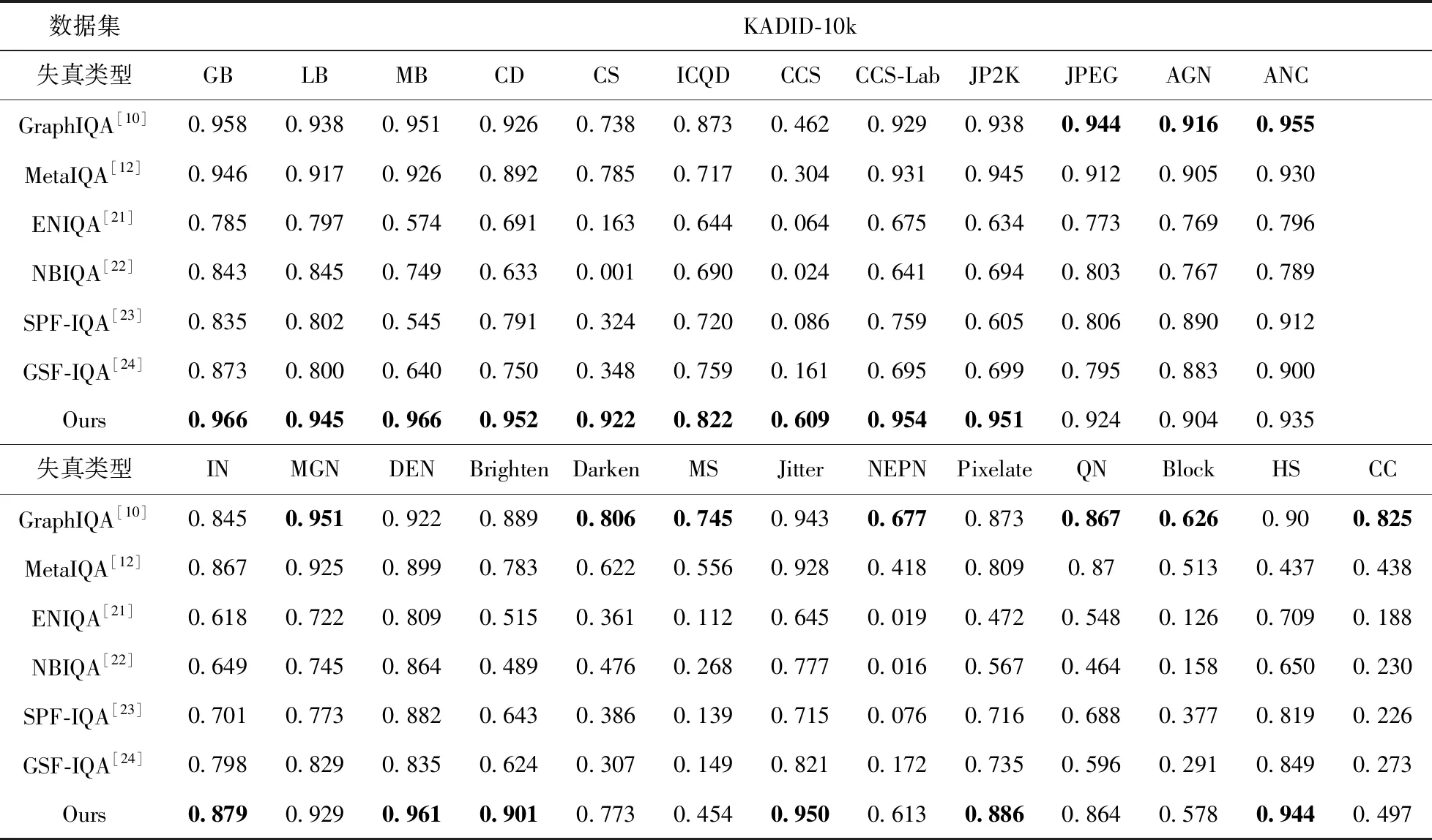
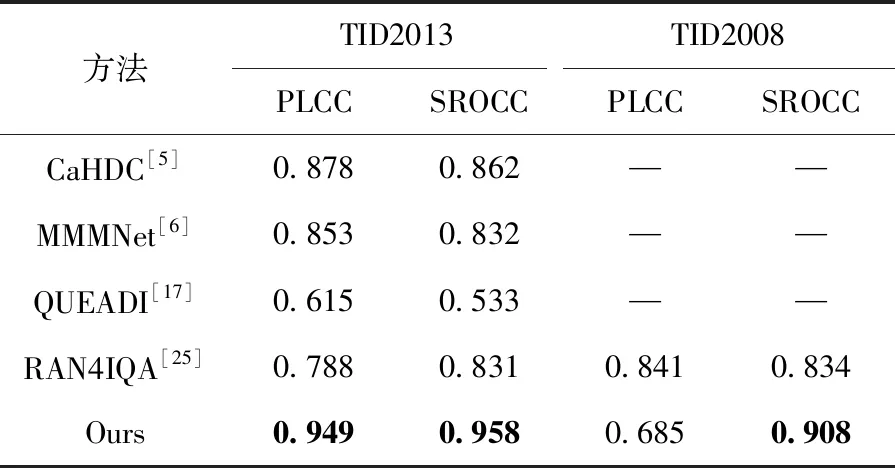
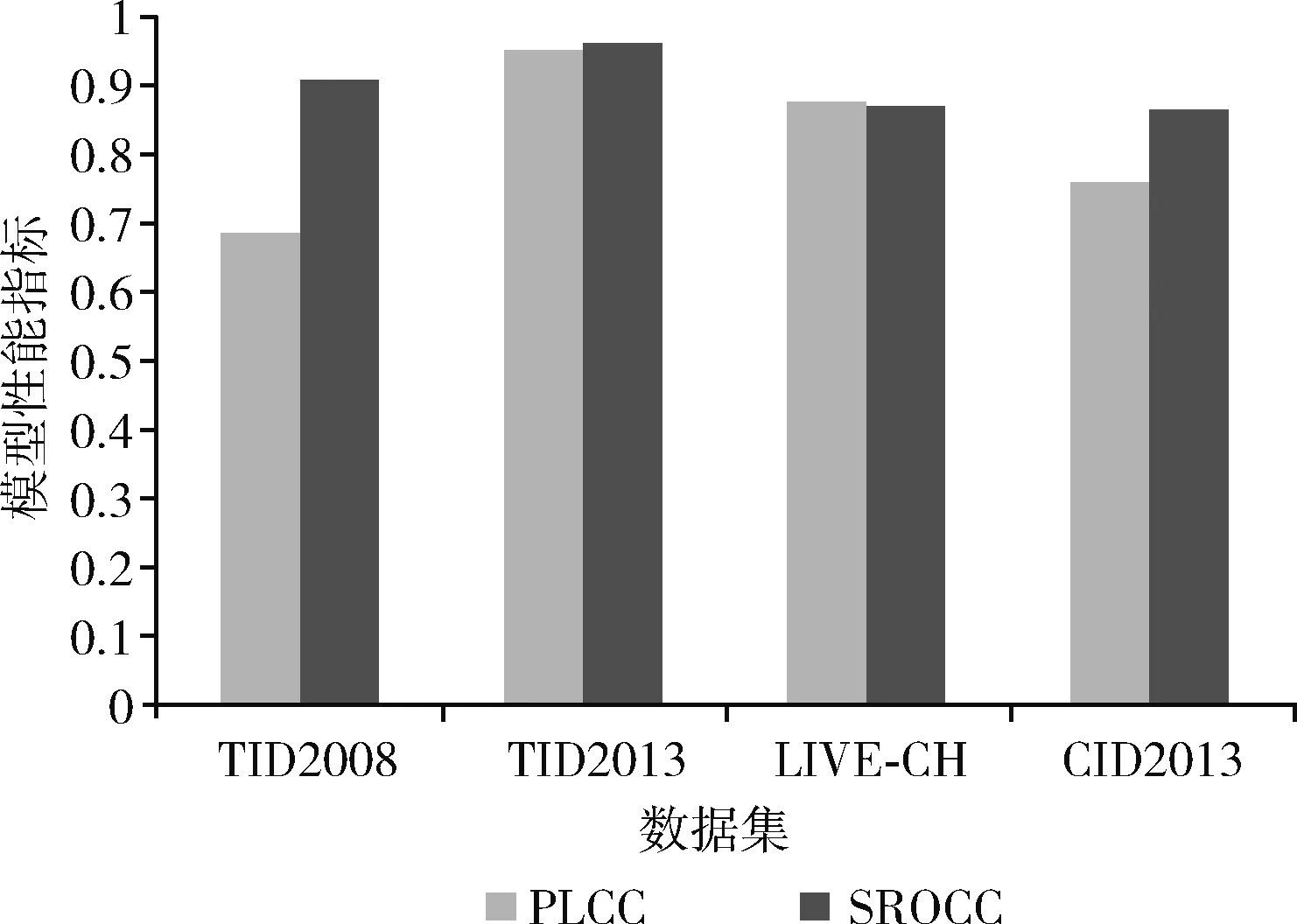
然后,为了学习不同失真类型共有的先验知识,我们随机挑选出k(1 Li=∑x(j)y(j)~TiF(x(j);θ(j))-y(j)22 (3) (4) 其中,α代表内循环学习率,Fθ表示CDR-FA模型。 最后,为了验证模型的泛化性能,我们在查询集UTiq(i=1,2,…,k) 上更新模型参数θ′i, 进而整合所有任务的梯度更新模型参数θ, 即 (5) 其中,β代表外循环学习率,箭头右边的θ表示更新后的模型参数。 主干网络采用在大规模图像分类数据集ImageNet上预训练的ResNeSt-50[9],该网络共有4个block,如图4所示,每个block由不同的split-attention模块组成。该网络分别借鉴了GoogleNet中的Multi-path机制、ResNeXt的组卷积机制、SE-Net中的通道注意力机制以及SK-Net中的基于特征图的注意力机制,在很多下游任务(如图像分类、目标检测、实例分割、语义分割等)上均获得当前最先进的性能。此外,在不增加计算量的情况下,性能优于现有的ResNet-50。 在CDR-FA架构中,图表示模块和特征聚合模块共享主干网络提取的基础特征信息。在基于CNN的NR-IQA任务中,随着CNN层数的加深,所提取的失真图像质量特征越具有全局和高级语义的信息,所以模型对于高级语义特征的辨识能力决定着NR-IQA模型预测的准确性。基于此,我们设计了图表示模块和特征聚合模块来提取失真图像的高级语义信息。 为了学习相同失真类型之间的共性信息,缓和图像内容对质量预测的影响,我们提出采用图表示模块聚合相同失真类型的共性信息,如图5所示。 图5 图表示模块 通过基于MAML的优化算法,使得图表示模块具有跨不同失真类型的推理能力,解决相同图像内容不同失真类型下NR-IQA难辨识的问题,进一步提升NR-IQA模型对于未知失真类型的辨识能力。 我们设计了第t种失真类型的元知识图结构Gp(T)meta={Vt,Et,At}Mt=1, 其中Vt代表节点集合;Et代表边的集合,用来描述相同失真类型之间的关系;At代表图的邻接矩阵。假设输入是含有k个任务的集合,每个任务含有N个相同失真类型的样例。第i(i=1,2,…,k) 个任务输入主干网络ResNet50中,得到第i种失真类型的失真原型向量P0i∈N×C, 其中C表示每个节点原型向量的特征维度。我们将P0i(i=1,2,…,k) 作为节点嵌入向量,使用一组堆叠的全连接层学习节点表示,提取每种失真类型样例的特征。邻接矩阵Ai(i=1,2,…,k) 表示第i种失真类型样例之间语义关系。 在构建边的过程中,为了获得更多节点之间的失真信息,我们借鉴Sun等[10]的思路,将二维邻接矩阵扩展成三维邻接矩阵Ai∈N×N×C′(i=1,2,…,k), 在本文中我们令C=C′=2048。 我们使用一个三层的图卷积神经网络(graph convolutional network,GCN)[11]聚合所有节点及其邻居节点的特征,在第i种失真类型中,H(l)i代表第l层的输出,H(l+1)i代表第l+1层的输出,则 H(l+1)i=ReLU(A^iH(l)iθ(l)1,i),l=0,1,2 (6) 其中 H(0)i=Ai (7) A^i=- 12ii- 12i= - 12i(Ai+I)- 12i (8) 在式(6)中,θ(l)1,i代表第l层的GCN的训练参数,A^i代表尺度化后的邻接矩阵。 为了获取每种失真类型的显著性特征表达,我们设计了特征聚合模块(如图6所示)。我们对ResNeSt-50做了改动,去掉最后一个BottleNeck后面的全局平均池化层和全连接层,添加一个全局平均池化(global average pooling,GAP)层和一个最大全局池化(global max pooling,GMP)层对失真类型特征进行聚合,同时在每个池化操作后添加标准的L2正则化,输出两个维度为2048的特征向量,两个特征向量合并为一个维度为4096的特征向量,我们对特征向量进行降维得到最终的特征聚合向量Ri∈N×2112(i=1,2,…,k)。 图6 特征聚合模块 最后,我们将特征聚合向量Ri输入到Softmax层获得每种失真类型不同空间尺度的信息,得到注意力向量Wi∈N×2112(i=1,2,…,k) Wi=Softmax(Ri) (9) 在特定失真类型下,我们将图表示模块的输出Pi(i=1,2,…,k) 与注意力向量Wi进行逐通道的融合,获得表征失真图像质量的特征融合向量Bi(i=1,2,…,k) Bi=Ri⊗Pi (10) 为了预测失真图像的质量分数,我们设计了质量回归预测模块(如图7所示),输入特征融合向量Bi(i=1,2,…,k), 输出失真图像的质量分数。 图7 质量回归预测模块 为了评估模型的性能,我们分别在5种公开的IQA数据集上进行实验,实验数据集分别为:TID2008、TID2013、KADID-10k、LIVE-CH和CID2013。其中,前3个数据集为合成失真图像质量评价数据集,后两个为真实失真图像质量评价数据集。 在真实失真图像质量评价数据集中:LIVE-CH数据集包含1162张来自真实世界中摄像机所拍摄的照片,相较于实验室合成的失真图像,这些照片包含更加复杂的失真类型。CID2013数据集共有6个子集,包含来自79种不同的数字照相机所拍摄的480张真实失真场景下的图像。在合成失真图像质量评价数据集中:TID2008、TID2013、KADID-10K分别包含1700、3000和10 125张合成失真图像。KADID-10k包含25种失真类型,分为5种失真等级。TID2013包含24种失真类型,分为5种失真等级。 为了衡量图像质量评价模型的性能,我们采用了两种性能指标——斯皮尔曼等级相关系数(Spearman rank-order correlation coefficient,SROCC)和皮尔逊线性相关系数(Pearson’s linear correlation coefficient,PLCC)。 SROCC定义为 SROCC=1-6∑Sw=1d2wS(S2-1) (11) 其中,dw代表第w幅图像的主观质量分数与由客观质量评价模型得到的失真图像质量预测分数之间的差值,S表示测试图像的个数。 PLCC定义为 PLCC=∑Sw=1(pw-)(sw-)∑Sw=1(pw-)2∑Nw=1(sw-)2 (12) 其中,sw代表第w幅图像的主观分数,pw表示由客观质量评价模型得到的失真图像质量预测分数。和分别表示为主观分数和预测分数的均值,S表示测试图像的个数。 SROCC和PLCC的取值均在0-1之间,并且取值越高表明客观质量评价模型预测的准确性和单调性就越好。 我们在设备NVIDIA Tesla V100 GPUs上训练和测试PyTorch框架下的模型。CDR-FA NR-IQA框架由内循环和外循环两个学习过程构成。ResNeSt-50中的Split-Attention(图8展示了Split-Attention的模块细节,图8中 (h,w,c) 分别表示输入图像的(高度,宽度,通道数))参数设置为:radix=2,groups=1。输入由元训练集合中的支持集和查询集图像构成。此外,所有的训练图像和测试图像都被随机剪裁成224×224大小以适应模型的输入。在支持集上训练我们的模型,然后在查询集上进一步微调模型超参数。设置epoch总数为50,外循环学习率β设置成1e-2, 内循环学习率α设置为1e-4; 每个mini-batch的大小k设置为5(与Zhu等[12]实验所采用的mini-batch大小保持一致),即每次随机挑选出k个任务作为元训练集合中的小训练集。 图8 Split-Attention模块细节 为了评估CDR-FA NR-IQA模型在真实失真场景下对失真图像质量预测的准确性,我们分别在真实失真图像质量评价数据集LIVE-CH和CID2013上进行实验,主要和当前最具有代表性的传统NR-IQA算法以及基于CNN的NR-IQA算法进行对比。我们与文献[12]保持相同的实验设置,为了避免随机性,所有的实验都被实施10次,我们将10次实验的SROCC和PLCC计算其平均值列在表1和表2中,其中加粗字体表示最好的结果。在LIVE-CH和CID2013数据集上,本文提出的CDR-FA NR-IQA模型PLCC值优于现有的绝大多数无参考图像质量评价模型。在LIVE-CH数据集上,相比于性能第2的模型,SROCC值提高了1%;在CID2013数据集上,相比于性能第2的模型,本文提出的CDR-FA NR-IQA框架其SROCC值提升10%。 表1 真实失真IQA数据集LIVE-CH上整体性能对比 表2 真实失真IQA数据集CID2013上整体性能对比 为了验证本文提出的CDR-FA NR-IQA模型应对未知失真类型的泛化能力,我们在TID2013和KADID-10K数据集中的每种失真类型上进行测试,使用留一法对比当前最具有代表性的NR-IQA模型,即假设一个数据集有M种失真类型,我们使用 (M-1) 种失真类型进行训练,剩下的一种失真类型进行模型性能测试。为了公平起见,所对比的NR-IQA方法都按照原作者所公开的代码在相同的训练测试规则下进行实施。表3和表4列出了我们的方法和当前最具代表性的NR-IQA方法在TID2013和KADID-10K数据集中每一种失真类型上的SROCC的测试结果,我们将在每种失真类型上测试得到的最好结果用黑体加粗强调。在TID2013数据集24种失真类型中,我们的方法在16种失真类型上获得了最佳的性能;在KADID-10K数据集25种失真类型中,我们的方法在15种失真类型上获得了最优的性能。此外,在TID2013和KADID-10K数据集上,我们的方法在超过一半的失真类型上测试得到的SROCC值要大于0.9。 表3 TID2013数据库不同失真类别SROCC值比较 表4 KADID-10k数据库不同失真类别SROCC值比较 图9展示了TID2013数据集每一种失真类型对应的SROCC结果以及KADID-10K数据集每一种失真类型对应的SROCC结果。在TID2013数据集24种失真类型中,我们的方法在16种失真类型上获得了最佳的性能;在KADID-10K数据集25种失真类型中,我们的方法在15种失真类型上获得了最优的性能。此外,在TID2013和KADID-10K数据集上,我们的方法在超过一半的失真类型上测试得到的SROCC值要大于0.9。 图9 TID2013数据集和KADID-10K数据集不同失真类型对应的SROCC值 我们也在当前具有代表性的合成失真质量评价数据TID2013和TID2008上进行实验,实验性能指标SROCC和PLCC值见表5。在TID2013数据集上,相比于性能第2的模型,本文提出的CDR-FA NR-IQA框架其PLCC值提高了7%,SROCC值提高了9%;在TID2008数据集上,相比于性能第2的模型,本文提出的CDR-FA NR-IQA框架其SROCC值提升4%。 表5 合成失真IQA数据集上整体性能对比 以上实验结果(如图10所示)表明我们所提出的CDR-FA NR-IQA模型无论是在真实失真图像质量评价数据集,还是在合成失真图像质量评价数据集上均具有较优的性能,再次表明我们的模型具有较强的泛化性能。 图10 在真实失真IQA数据集和合成失真IQA数据集上模型整体性能表现 为了验证各个模块的有效性,主干网络采用基于元学习的训练框架(Method-1),分别验证元学习算法结合图表示模块(Method-2)、元学习结合特征聚合模块(Method-3)以及CDR-FA框架(CDR-FA)的有效性。在验证阶段,我们统一在KADID-10K数据集上训练,然后分别在LIVE-CH、CID2013和TID2013上进行测试,SROCC和PLCC值分别列在表6中。 表6 验证模型各模块整体性能表现 对比3种方法,CDR-FA架构表现出较强的泛化能力,也再次验证了我们的方法能够有效解决NR-IQA问题中模型过拟合以及泛化性不强的问题。 本文提出了一个CDR-FA NR-IQA框架对真实失真场景中的失真图像质量进行预测,解决现有NR-IQA模型容易过拟合以及对于相同失真类型的不同图像内容或是具有不同失真类型的相同图像内容难辨识的问题。CDR-FA NR-IQA框架基于MAML的优化算法,其特征聚合模块提取每种失真类型最显著的特征,图表示模块提取相同失真类型共有的失真质量信息,以减少图像内容变化对质量预测准确性的影响。最终本文提出的CDR-FA NR-IQA框架具有跨失真类型表征的能力。
3 网络框架
3.1 主干网络
3.2 图表示模块
3.3 特征聚合模块
3.4 质量回归预测模块

4 实验结果与分析
4.1 图像质量评价数据集
4.2 评估指标
4.3 实施细节
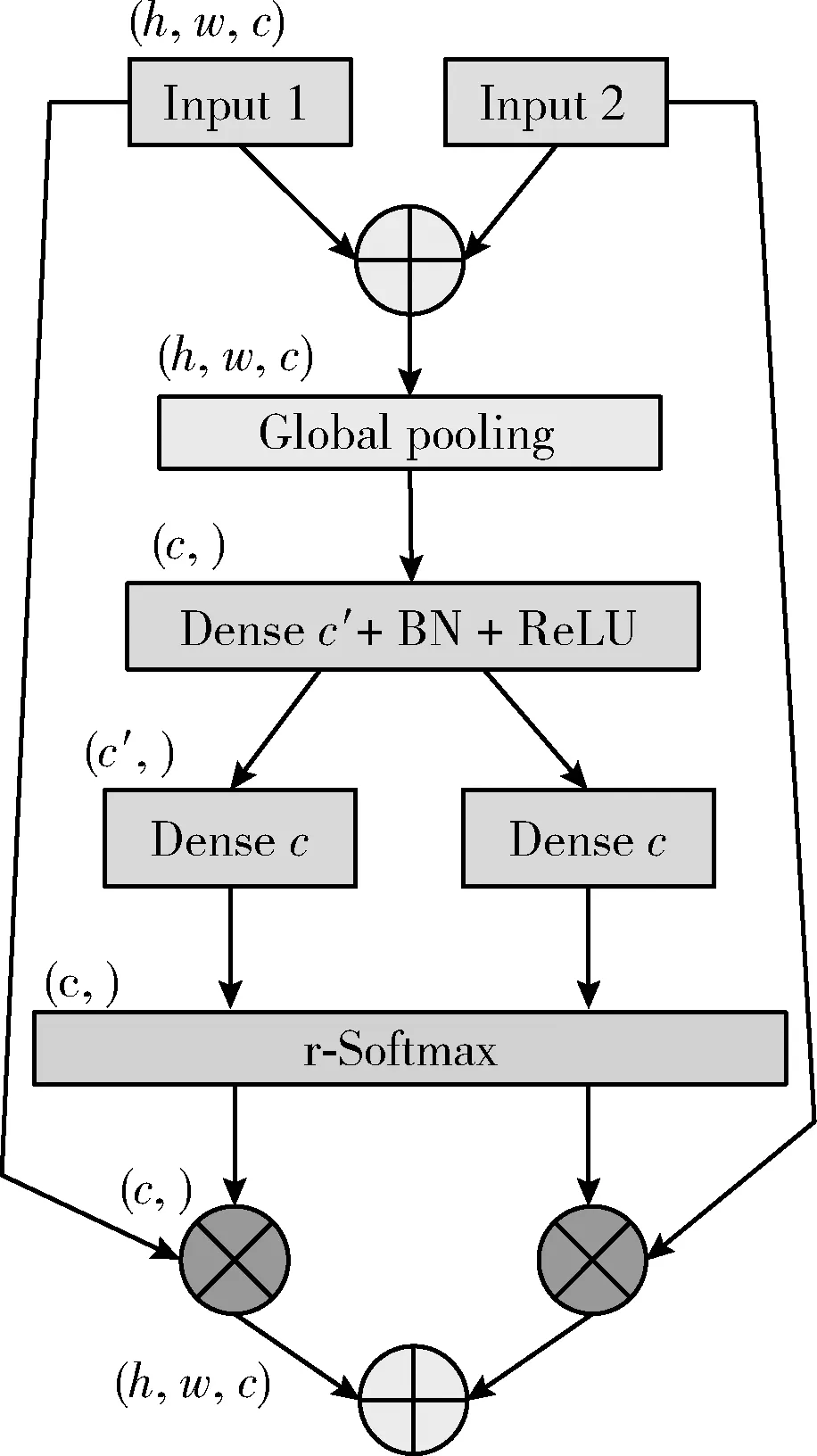
4.4 实验结果与分析

4.5 消融实验

5 结束语
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
疯狂英语·新策略(2019年10期)2019-12-13
家庭影院技术(2019年8期)2019-08-27
当代陕西(2019年10期)2019-06-03
数学物理学报(2017年5期)2017-11-23
数学小灵通·3-4年级(2017年9期)2017-10-13
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
火炸药学报(2014年1期)2014-03-20
