
面向模型检测的LTL语句自动生成方法
2023-09-13 03:07段喜龙陆智伟陈晋升
计算机工程与设计 2023年8期
段喜龙,陆智伟+,郑 巍,陈晋升,樊 鑫,肖 鹏
(1.南昌航空大学 软件学院,江西 南昌 330063;2.南昌航空大学 软件测评中心,江西 南昌 330063)
0 引 言
模型检测作为软件系统验证中的一个常用手段,已经在多个领域得到了应用。在基于模型开发的软件系统验证中,线性时态逻辑LTL(linear-time temporal logic)用于描述软件的性质,这些性质又被称为线性时间属性。这是迈向构建模型检测理论重要的一步,现已得到了广泛的应用[1-4]。
LTL能得到广泛应用有赖于人们对它的表达能力的研究。文献[5]中给出,LTL的表达能力与一阶谓词逻辑等价。尽管它们的表达能力是一样的,但两者在可满足性问题,可判定问题还有推理问题上的解决难易程度却大不相同。这些问题在一阶谓词逻辑上的解决难度是非初等的,也就是说它的解决方案的复杂度上界是可以无限增长的[6,7]。而在LTL上,这些问题的解决难度都只是PSPACE-完全的[8,9]。这也是能够得到广泛应用的一个重要的理论支撑。而LTL语句生成需要测试人员对被测模型要有充分的了解,而这一过程需要花费很多时间。
在模型检测方面,文献[12]从时间逻辑角度对系统行为进行了刻画,文献[13]采用时间抽象互模拟方法来验证模型;文献[14]分别采用动态层次化UML状态机模型和符号模型进行验证;文献[15]将时间自动机(timed automata,TA)模型转换为有限状态迁移图,并将有限状态迁移图转换为非确定有限状态机(finite state machine,FSM),从而采用基于FSM的方法进行测试;文献[16]是一种通过在运行时验证软件源代码中的断言来检测不一致的方法。但是这些工作都不是完全自动化的,验证人员需要手动的生成LTL语句,验证效率低。因此,研究和实现LTL自动生成的方法是必要的。
本文提出了一个基于自然语言处理的线性时态逻辑自动生成的方法,支持基于模型的开发软件设计的分析。在本文的方法中,通过自动生成线性时态逻辑声明来建立来对模型与需求的进行一致性分析。本文研究的目标是减少在软件开发后期检测需求模型一致性所需的工作。
1 本文工作
本文提出的LTL语句自动生成方法如图1所示。本文采用的输入是需求说明书和UML模型,然后采用关键词提取,基于注释UML模型的LTL生成方法,从而生成LTL语句。

图1 LTL语句自动生成方法
1.1 关键词提取
关键词提取是本文根据需求文档生成LTL验证语句的关键步骤。关键词提取流程如图2所示,首先对需求文档进行分词,采用语言技术平台(language technology plantform,LTP)[17],LTP提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。利用LTP进行分词,接着对词语进行清洗,清洗过程包括单词翻译、分析停用词;最后通过标准化(词干提取和词形还原)得到关键词集合。
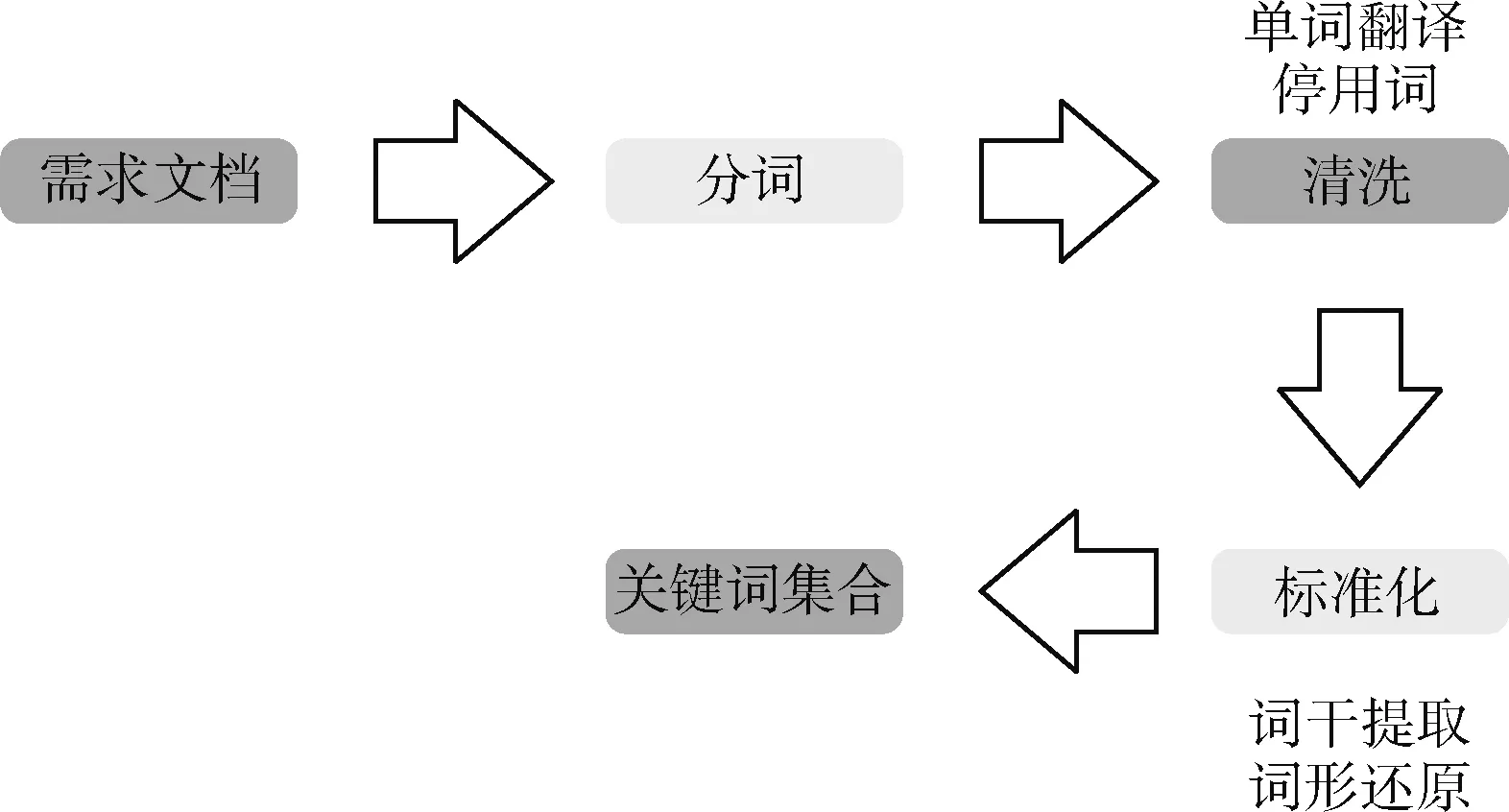
图2 关键词提取流程
本文采用的关键词提取算法为TextRank算法[18]。
TextRank 模型表示为一个有向有权G=(V,E) 由点集合V和边集合E组成,E是V×V的子集
WS(Vi)=(1-d)+d*∑nViwij∑VkwjkWS
(1)
式(1)表示的是TextRank中一个单词长度i的权重取决于与在长度i前面的各个点长度j组成的长度 (j,i) 这条边的权重,以及长度j这个点到其它边的权重之和。
WS(Vi) 表示的是句子的权重,右侧的求和表示每个相邻句子对本句子的贡献程度,在单文档中本文可以大致认为所有的句子都是相邻的,不需要像多文档一样进行多个窗口的生成和抽取。Wij表示两个句子的相似度,WS表示上次迭代出句子的权重,d为阻尼系数,一般为0.85。
例如,文本中有句子“通过贷款人数据信息,并进行风险分析”,“风险”和“分析”均属于候选关键词,则组合成“风险分析”加入关键词序列。最后得到DataSet{d1,d2,…,di} 集合。DataSet集合是所有数据属性和调用操作的集合,是通过TextRank算法从需求文档中得到的。
1.2 基于注释UML模型的LTL生成算法
基于注释UML模型的LTL生成算法流程如图3所示。
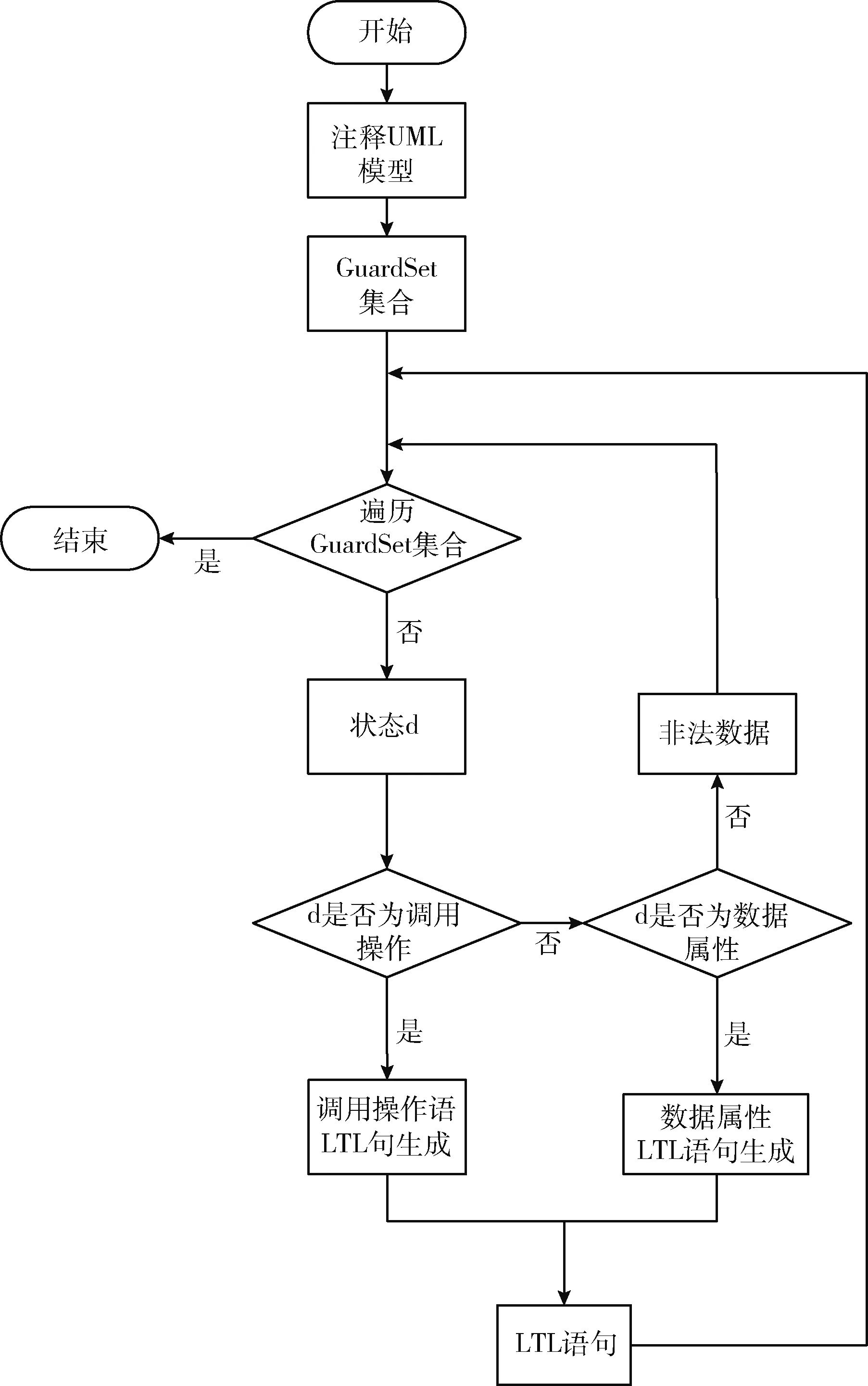
图3 基于注释UML模型的LTL生成算法流程
LTL生成算法采用UML模型m和关键词集合作为输入,输出一组LTL语句。首先对UML进行注释,通过分析注释后的UML模型得到GuardSet集合 {g1,g2,…,gi} (GuardSet集合是关于DataSet集合的一组使用条件)。接着对GuardSet集合进行遍历得到状态d,判断d是否是调用操作,若是调用操作则生成一条相应的调用操作LTL语句。若不是,则判断d是否为数据属性,若是则生成一个相应的数据属性LTL语句。否则将d归类为非法数据,开始判断下一个状态d。
1.2.1 注释UML模型
在处理需求文档时,将UML模型用数据信息进行注释,产生的文件称为UML模型的UML注释文件(UMLnotes)。UMLnotes内容是UML的扩展并允许相关的数据在UML模型中指定数据信息。还引入了UML安全概要UMLsec的子概要。UMLnotes 的一些信息在注释UML模型简介见表1。

表1 注释UML模型简介
在生成LTL语句过程中,在UMLnotes配置文件中有一个称为“《critical》”的类型,这是从UMLsec配置文件中重用的一个类型。在 UMLsec中此构造型注释可能包含数据的类。在本文的工作中,使用了这个扩展类型来注释可能包含受需要验证的字符类。如表1所示,扩展了这个带有{protectedData}标签的构造型允许定义受保护的字符与注释为《critical》的类有关的特征。
《interpretation domain》注释了一个模型状态机,它会去记录类的会发生的行为,将其注释为一些标签注释UML所包含的标签如图4所示。本文的模型包含以下几个标签。
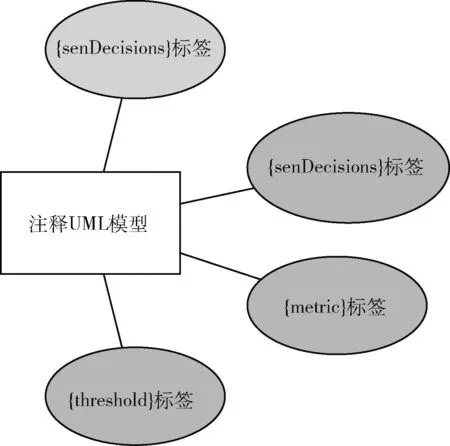
图4 注释UML所包含的标签
(1){senDecisions}标签,它允许定义特定数据属性的设置值或调用操作事件是不应该基于特定的一些属性。
(2){expData}标签,它允许定义使用一些数据属性来区分是可以接受的状态。
(3){metric}和{threshold}标签。这些标签可用于根据模型的历史数据库识别属性的数据以防数据信息不可用。{metric}和{threshold}标签允许指定要使用的相关度量和数字成为验证标准。对于灵活性问题,不限制规格{metric}标记到一组特定的指标,只要它具有到实现中的函数的映射即可,此标签就可以将任何字符串作为输入。
实现过程见LTL自动生成算法如算法1所示的第(1)行~第(6)行中。
1.2.2 对UML模型状态分类
接下来对于每个被定义为数据属性的,将执行以下操作:所有可以分配给di的可能值将从UML模型m中检索并存储在rangeSet中。rangeSet会将验证模型用到的数据分配给di。
当di∈DataSet是数据属性时如式(2)所示
LTLgidi={(gi→◇di==ti),!(gi→◇di==ti)}
(2)
在算法的假设中,可以分配给数据属性的可能值的数量是有限的。按照规则,属于LTLgidi的每一对由两个声明组成:
(1)如果gi条件为真,数据属性di的值最终将等于ti。
(2)如果gi条件为假,数据属性di的值最终将等于ti。 其中,ti是可分配给si的一个可能值。
当di是调用操作事件时如式(3)所示
LTLgidi={(gi→◇eventquenue?[calld]i==ti),!(gi→◇eventquenue?[calld]i==ti)}
(3)
在这种情况下,LTL由一对两个声明组成:
(1)如果gi条件为真,调用操作事件call_di最终将被添加到事件队列中。
(2)如果gi条件为假,调用操作事件call_di最终将添加到事件队列中。
实现过程见算法1的第(4)行~第(16)行中。
1.2.3 生成LTL语句
在算法中还声明了一个空集LTL。该集合将用于算法来存储可以生成的所有LTL。
对于图3中每个使用数据的条件gi, 相对于di, 一条LTL语句将被定义如下:对于每个value属于rangeSet,将定义一对声明和添加到LTL中。每对声明都应具有其对应的线性时间逻辑的格式。遍历rangeSet中的所有值后,该LTL将被添加到LTL总的集合中。对于图3中每个定义为调用操作的事件,将执行以下操作:对于每个使用的条件gi, 一条LTL语句将被生成。每个生成的LTL将被添加到LTL总的集合中。
实现过程见算法1的第(17)行~第(38)行中。
算法1:LTL自动生成算法
(1)generateLTL (m, Requirements);
(2)Inputs: a UML model m and a Requirements
(3)Output: a set of batches of LTL
(4)P← ∅
(5)P←Participle(Requirements);
(6)sm←getIndividualFairnessStateMachine(m);
(7)DataSet←∅;
(8)guardSet←∅;
(9)DataSet←P.data;
(10)guardSet←getGaurds(m);
(11)LTL←∅;
(12)foreach state ∈ model do
(13) expSet←∅;
(14) expSet←getExplanatory(sm,state);
(15) usedConditionsSet←∅;
(16) usedConditionsSet←getUsedConditions(m,P,DataSet,sm, guardSet);
(17) if state is a data attribute then
(18) rangeSet←∅;
(19) rangeSet←getRange(state, m);
(20) foreach g ∈ usedConditionsSet do
(21) batch←∅;
(22) foreach v ∈ rangeSet do
(23) batch.add(
(24) {g→<>state == v}, {!g→<>state==v});
(25) end
(26) LTL.add(batch);
(27) end
(28)end
(29)else
(30) foreach g∈usedConditionSet do
(31) batch←∅;
(32) batch.add(
(33) {g→<>(event_queues?[call_s])},{!g→<>(event_queues?[call_s])});
(34) LTL.add(batch);
(35) end
(36) end
(37)end
(38)return LTL
2 实验和结果
本文采用模型验证的流程来验证生成LTL语言的准确性。模型检验流程如图5所示,展示的是模型验证的一般流程。首先利用转换转换规则将UML模型转换为Promale验证语言。根据本文生成的LTL语句,通过使用SPIN model checker来验证模型,以此来研判本文生成LTL语句的准确性。

图5 模型检验流程
2.1 LTL自动生成案例
贷款管理系统基于真实业务流程模型,该模型由荷兰金融机构的事件日志生成。贷款管理系统包括两个主要流程,即贷款申请管理和风险分析管理。前者验证是否会接受贷款请求。后者为每个接受的贷款请求创建一个贷款申请,并进行风险分析,以决定是否批准该申请。本文从StatlogCredit数据集中提取数据,该数据集存储了1000条数据。实验的目标是检查如果两个贷款申请人的数据在特定的地方存在差异,是否会调用风险分析方法。
贷款管理系统设计模型如图6所示显示了贷款管理系统设计的模型。实验检测creditHistoryStatus和save相关的部分。UML类图,类图通过显示软件的类、它们的属性、操作以及类之间的关系来描述软件的结构。此类图中的一个类是“LoanManagement”。
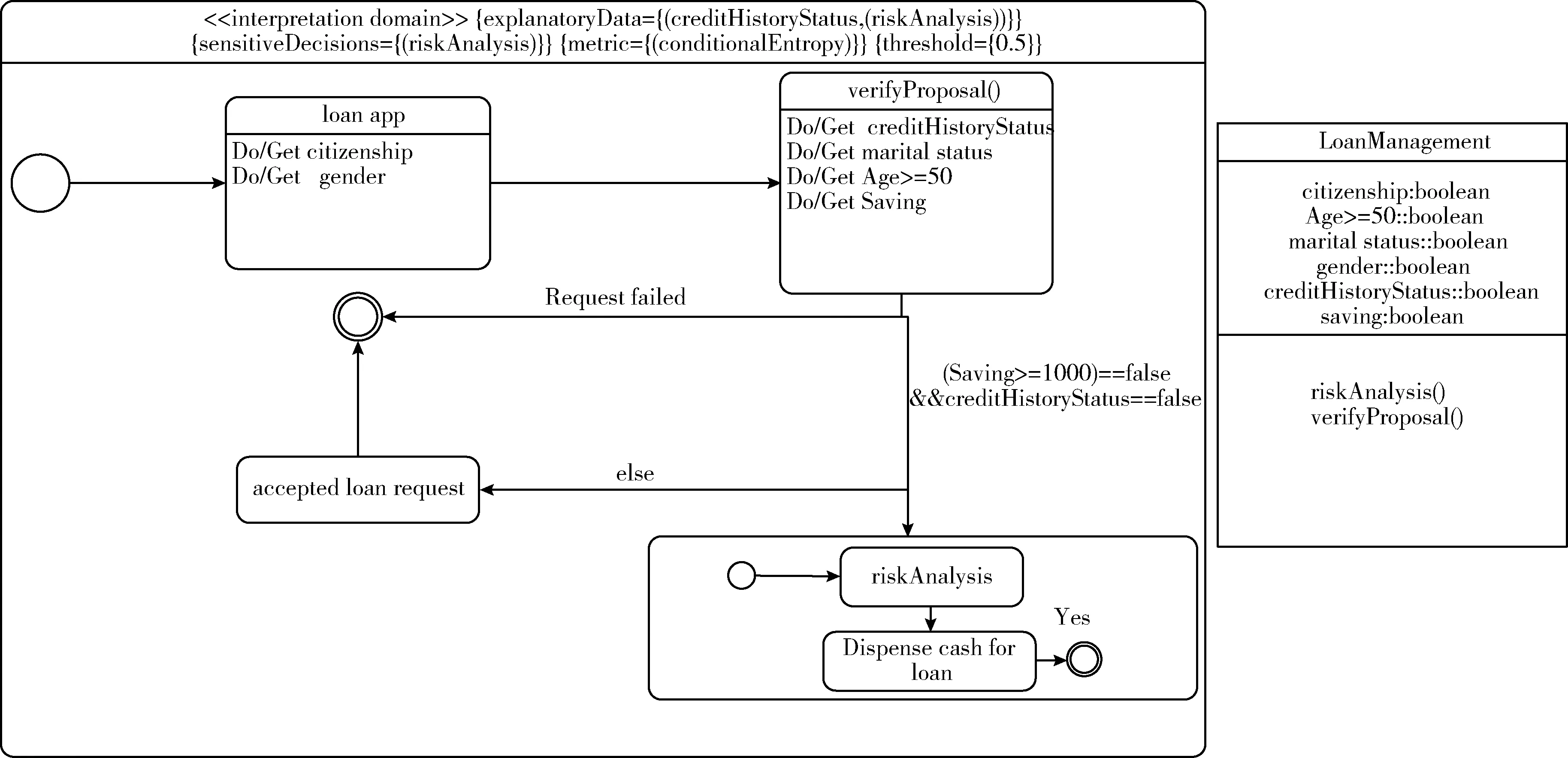
图6 贷款管理系统设计模型
“citizenship”是一个字符串数据属性。代表贷款申请人的国籍。“gender”是一个布尔类型属性。表明一个申请人的性别,“男”为true,“女”则为false。“Age>=50”是一个布尔类型属性,表示一个贷款申请人的年龄是否大于50岁,“marital status”是一个布尔类型属性,表示贷款申请人是否已婚,“creditHistoryStatus”是一个布尔类型属性,如果贷款申请人有很好的信用记录则为“true”,否则为“false”。“saving”是一个整数类型属性,表示贷款申请人的存款数目。
操作的一个示例是“verifyProposal()”。在模型注释完成后可以表示“LoanManagement”类的对象可以接收到的信号,并在模型的生命周期内接收。物体对接收到的信号作出反应并找到到其类的指定行为。
图6是一个UML状态机它描述“LoanManagement”类行为。UML状态机描述实体(例如对象)的状态序列,例如调用操作,连同它的响应动作。状态机包含状态和转换。状态表示的是执行状态机行为的一种情况,在此期间某些不变条件成立,状态用方框表示。
图6中的状态是“空闲”和“riskAnalysis”。该状态可以是调用操作或接收到的信号,它的动作可以是一个属性的数据分配,一个调用操作或发送信号。在图6中,如果一个对象在“verifyProposal()”中状态和条件 “[creditHistoryStatus==false&&saving>=1000==false]” 是true,并进入“riskAnalysis”状态。若分析结果为“yes”则接受用户贷款。
贷款管理系统的需求如下:
系统应提供贷款申请管理和风险分析管理的功能,前者验证是否会接受贷款请求。后者为每个接受的贷款请求创建一个贷款申请,通过贷款人数据信息,并进行风险分析,以决定是否批准该申请。具体见贷款人数据信息说明见表2。
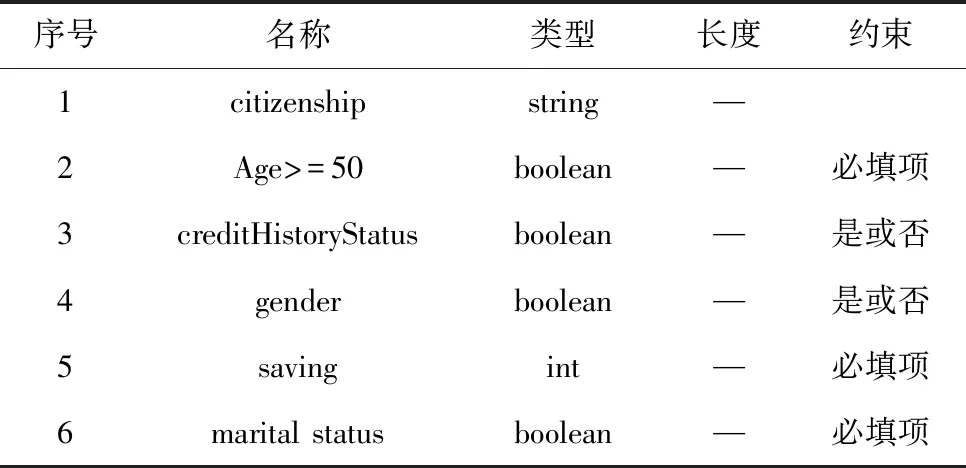
表2 贷款人数据信息说明
2.2 生成线性时态逻辑
在贷款管理系统示例中,通过1.2中的基于注释UML模型的LTL生成算法,首先,以成对LTL语句的要求表达“信用状态”对“存款”的所有组合,其中每对LTL要求单独考虑关于一个可能属性的声明要求。其次验证是否恰好一对的声明得到满足(即,最终为真),而另一对的声明被违反(即,始终为假)。也就是说,“信用状态”与“存款”没有关联。这些产生的效果表示为成对的LTL声明,即p1和p2。p1的LTL对“信用状态”属性检查“调用风险分析”是否为真,p2的LTL对“存款”属性检查其是否为假。
(ltl claim1{(LoanRequest_creditHistoryStatus== true) -> <>(event_ queues[1]? [call riskAnalysis])},
ltl claim2{(LoanRequest_ creditHistoryStatus== true) -> <>(event. queues[1]? [call_riskAnalysis]})p1
(ltl claim3{(LoanRequest_saving>= 1000) -> <>(event_ queues[1]? [call_riskAnalysis])},
ltl claim4{!(LoanRequest_saving>=1000)-><>(event_queues[1]? [call_riskAnalysis])})p2
2.3 验证生成线性时态逻辑的准确性
在生成一批LTL验证语句之后,实验根据LTL语句验证UML模型。利用p1和p2去验证图6的UML模型的正确性。验证结果见贷款管理系统验证结果见表3。

表3 贷款管理系统验证结果
为了解释结果,本文用模型检查器为违反的LTL语句生成的反例。从生成的事件跟踪部分如算法2所示的是一个节选的痕迹Spin事件,作为违反示模型中p1,p2两个声明的反例。考虑图6的两条说明:“LoanRequest_credit-HistoryStatus = 0”,“LoanRequest_saving >=1000审批与存款和信用状态之间存在联系。
算法2:生成的事件跟踪部分代码
(1)claim claim2
(2)LoanPrposal 5 [9] 10 loanSystem.pml:14 ((!(!(!((LoanRe-quest_saving>=1000))))&&!(event_queues[1]?[4])))
(3)LoanPrposal 5 [1] 5 loanSystem.pml:14 (1)
(4)LoanPrposal 10 [10] 10 loanSystem.pml:19 (!(event_queues[1]?[4]))
(5)claim claim4
(6)LoanPrposal 5 [3] 10 loanSystem.pml:36 ((!(!(!((LoanRe-quest_creditHistoryStatus==1))))&&!(event_queues[1]?[4])))
(7)LoanPrposal 5 [1] 5 loanSystem.pml:36 (1)
(8)LoanPrposal 10 [4] 10 loanSystem.pml:41 (!(event_queues[1]?[4]))
2.4 实验结果
实验还利用上述方法对另外4个系统进行研究。
(1)学校奖学金管理系统,该系统描述学生申请学校奖学金的情况。在系统的活动中,结果是奖学金申请成功与否,但是需求中要求它不应根据申请人的个人特征(如性别和身体健康状况)来影响奖学金申请成功。本文创建了一个数据集以检查其模型与需求的一致性。该数据集包含20个人的6个数据属性。
(2)快递管理系统,以亚马逊配送管理系统为基础,展示了一个真实的事件。基于事件描述设计了交付系统的UML模型。亚马逊的软件为那些订单超过35美元,并且住在亚马逊商店附近的邮政区里的主要客户提供免费送货服务。本文创建了一个包含30个人5个数据属性的数据集来验证模型的一致性。
(3)精简电梯模型,电梯的功能包括上行、下行、报警、显示、开/关门等。在验证过程中可以增加一条和某一行为需求描述相似的变迁,对其进行取反操作,观察模型检验能否检测出与需求不一致的行为。本文创建了一个包含20个人4个数据属性的数据集来验证模型的一致性。
(4)前主桨舵机系统,前主桨舵机是飞行控制系统的执行机构,接受来自电传控制计算机的指令,进行相应的动作,拉动倾斜器前倾或后倾,以实现对飞机的俯仰控制。对其旋转直接驱动阀(rotary direct drive valve,RDDV)模块进行检验。本文创建了一个包含15条3个数据属性的数据集来验证模型的一致性。
UML模型的概述见表4。第二列显示了模型中UML元素的数量。例如,贷款系统模型由27个要素组成。元素的数量包括类、属性、操作、状态机、状态和转换的数量。第三列和第四列分别提供了模型生成的LTL语句数量和验证所需的时间。例如,贷款系统模型产生了4项LTL语句。Spin模型检查器花了36 s来验证这4项声明,成功验证并发现了模型中存在的错误。这些测试工作是在一台配有Intel i5处理器和16 GB内存的计算机上进行的。
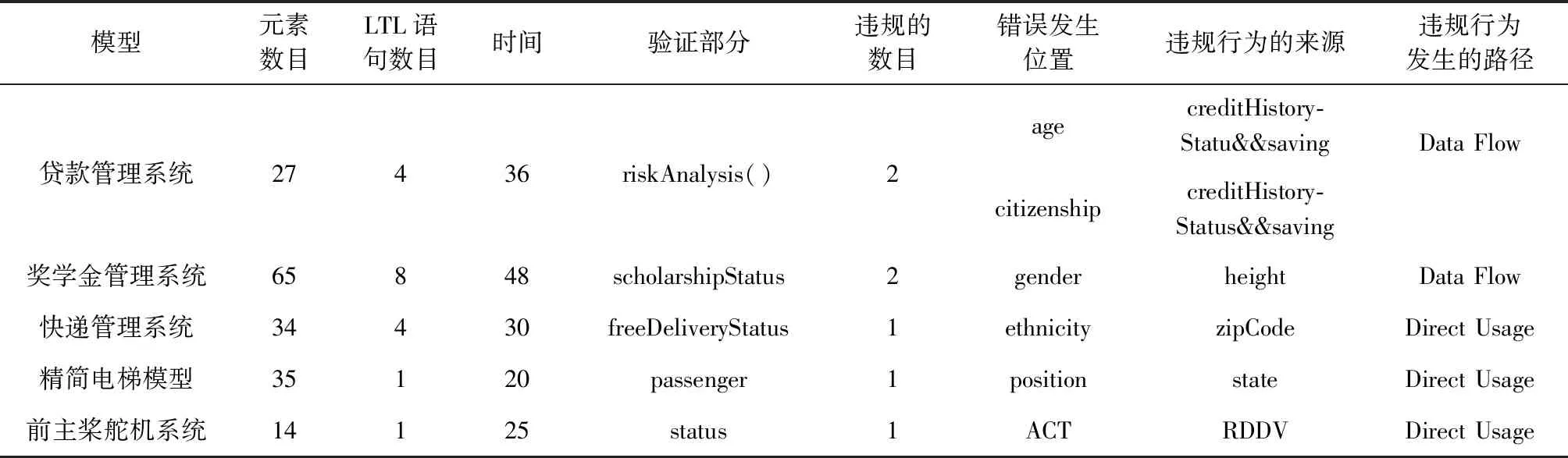
表4 UML模型的概述
表4提供了分析模型中检测到的一致性违规数量。对于每个检测到的不一致行为,该表提供了:①违规行为发生的受保护数据;②违规行为的来源(即,导致违规行为的数据段);③违规行为是由于数据流还是直接使用违规行为源而发生的。例如,在触发“riskAnalysis()”调用操作时,该表显示了贷款系统模型违反了需求模型一致性,其中两项错误违反由于“信用状态”和“存款”而发生的。
2.5 实验对比
由于现有针对软件需求文档UML模型等编程语言模型的形式化验证的研究比较缺乏,历史有关研究并不多,因此本文利用已有的ST语言模型形式化验证方法与本文提出的基于注释UML模型的LTL生成方法验证模型的时间效率进行分析和对比。文献[19]提出一种ST语言模型形式化验证方法。首先针对ST语言模型进行分解,通过数据流分析得到模型程序依赖图,最后根据程序依赖图生成NuSMV的输入模型。ST语言模型形式化验证方法的研究对象为逻辑控制器程序,与本文的研究对象模型与需求的一致性比较类似,其中实例的模型都利用程序语言编写。两种方法都利用了模型形式化检测工具,所以可以进行时间效率的对比,两种方法的对比见ST模型与UML模型形式化验证方法对比见表5。
实验将贷款管理系统、奖学金管理系统、快递管理系统、精简电梯模型、前主桨舵机系统共5个UML模型,将本文验证方法和ST程序模型验证方法进行对比实验,每种系统模型测试3次,然后计算模型验证花费时间的平均值。本文提出的基于注释的UML模型的LTL生成方法测试结果在UML模型验证性能分析图如图7所示;ST语言模型形式化验证方法测试结果在ST模型验证性能分析如图8所示。在图7两条折线分别代表基于注释UML模型到验证语句的生成时间(UML_LTL时间)以及总时间。图8所示两条折线分别表示ST模型到程序依赖图生成时间(PDG时间),以及总时间。
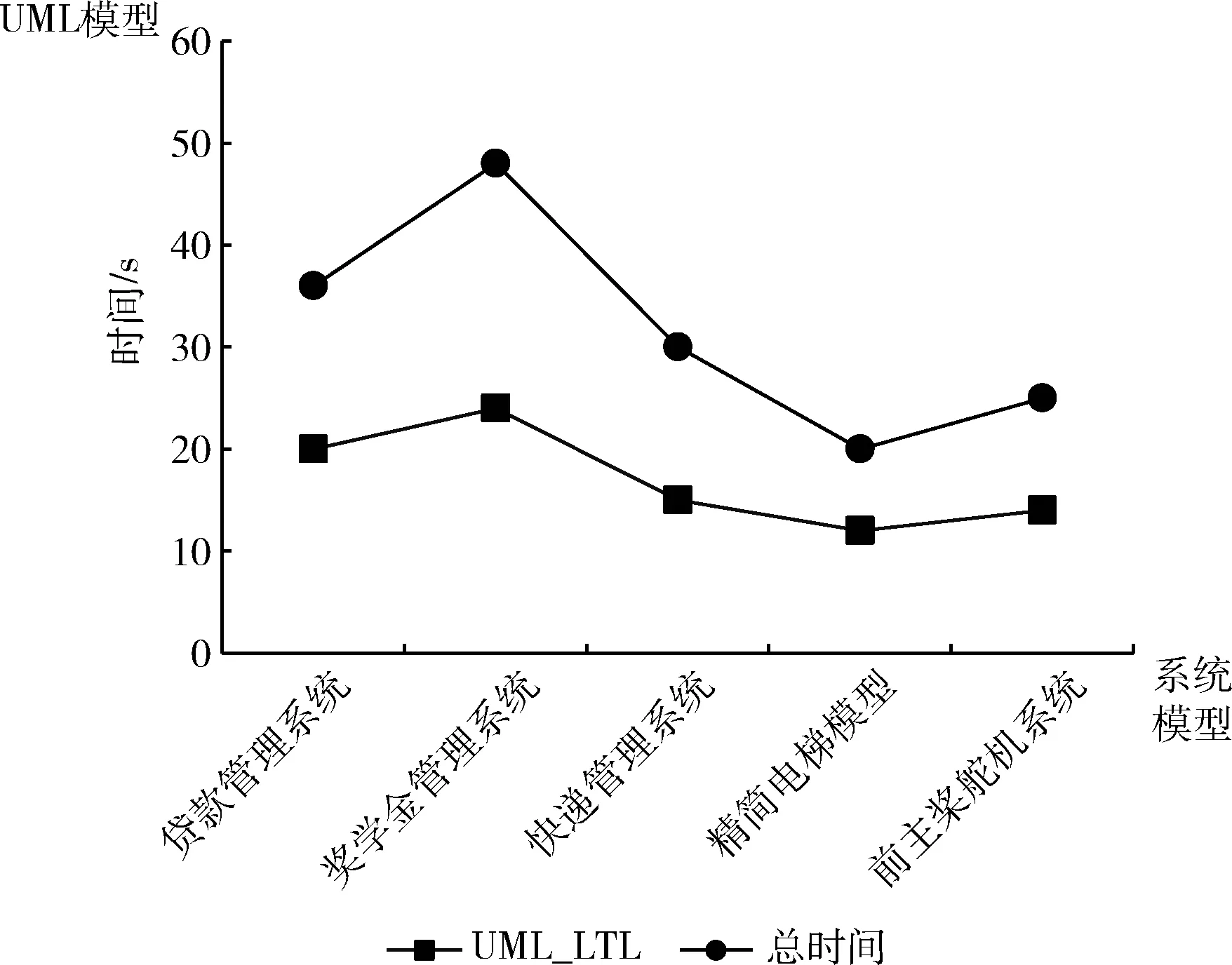
图7 UML模型验证性能分析
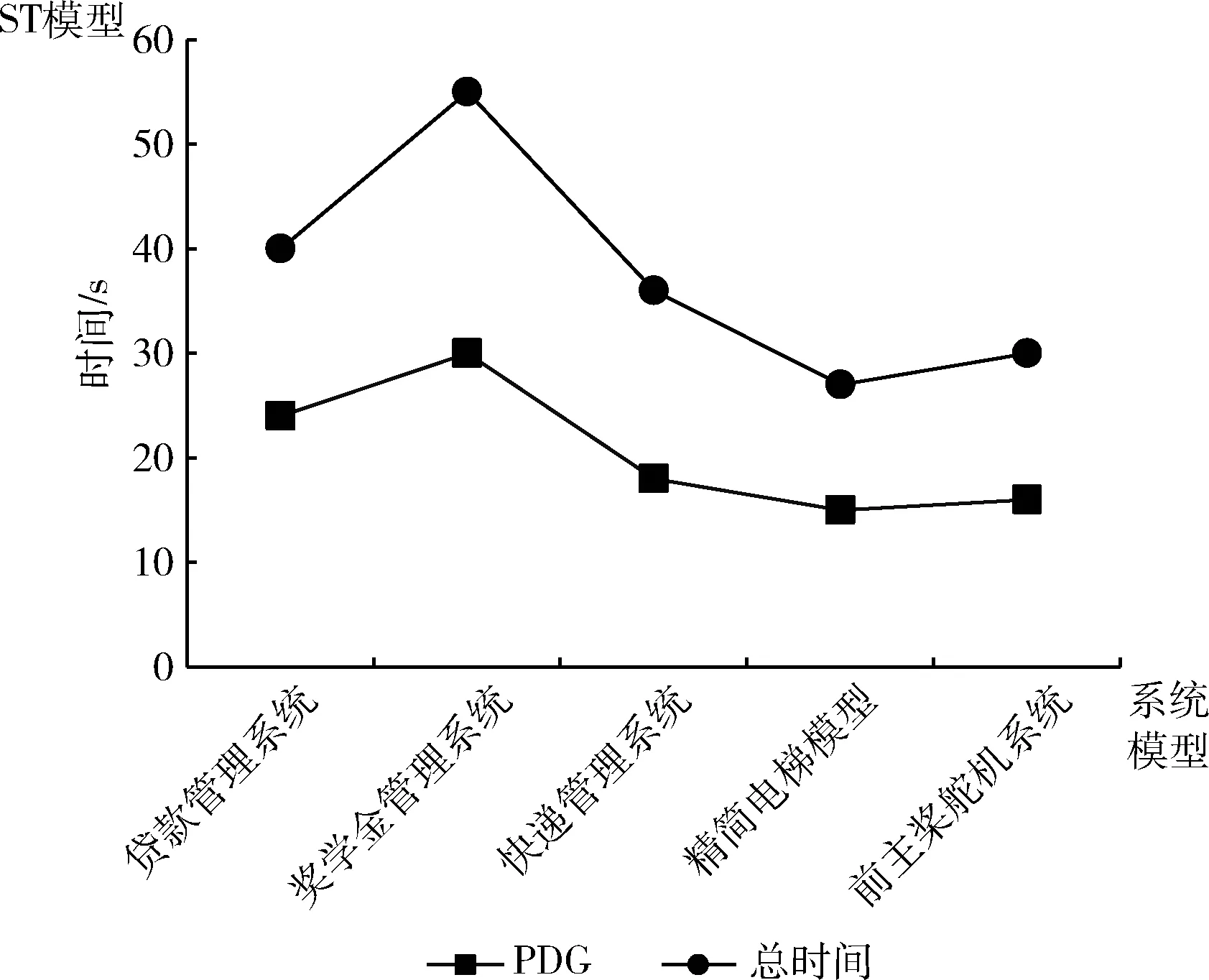
图8 ST模型验证性能分析
由图7所示可得,UML模型到LTL语句转换耗时较少,在UML模型代码行数较少时,生成中间模型耗时较少,并且随着UML模型规模的增加,总时间增长比较缓慢,说明本文提出的基于注释UML模型的LTL生成方法更适合规模较大模型的转换与验证。
由图8所示可得,由ST模型到中间状态生成消耗时间较多,NuSMV模型验证花费时间较少。在ST模型规模不大时,程序依赖图生成过程花费的时间相对较多,随着ST模型规模的增加,总时间增长缓慢。说明针对模型规模较小的ST模型在生成中间状态过程中效率相对较低,不适合规模较大的模型进行转换。
由对比结果可以了解到,本文的基于注释UML模型的LTL生成方法的时间效率优于已有的ST语言模型转换方法生成NuSMV模型的时间效率,并且适合各种规模模型的验证。
3 结束语
基于注释UML模型的LTL验证语句自动生成方法,经过了一个完整的模型验证过程,发现可以提高了模型检测的效率并能准确发现模型中存在的错误,减少了测试人员模型检测的时间。目前存在的问题是:本文的方法搜索单个属性LTL验证语句,而有时一个LTL验证语句需要用到多个属性。由于UML模型具有很大的可变性,因此无法保证生成完整的LTL语句。为了解决这些问题需要考虑多属性LTL语句,确定开发人员在建模过程中必须遵循的约束,以便验证生成的LTL验证语句的完整性。优化自然语言处理算法对需求文档关键词的提取过程,用以丰富生成的LTL验证语句中的属性。
猜你喜欢
承德医学院学报(2022年2期)2022-05-23
新世纪智能(语文备考)(2020年4期)2020-07-25
商品与质量(2019年34期)2019-11-29
测控技术(2018年5期)2018-12-09
中国交通信息化(2018年8期)2018-11-09
中国船检(2017年3期)2017-05-18
信息安全研究(2016年4期)2016-12-01
塔里木大学学报(2014年3期)2014-03-11
语文知识(2014年4期)2014-02-28
中国信息化·学术版(2013年1期)2013-05-28
