
Semantic-aware graph convolution network on multi-hop paths for link prediction①
2023-09-12 07:29PENGFeiCHENShudongQIDonglinYUYongTONGDa
High Technology Letters 2023年3期
PENG Fei (彭 斐),CHEN Shudong,QI Donglin,YU Yong,TONG Da
(Institute of Microelectronics of the Chinese Academy of Sciences,Beijing 100029,P.R.China )
(University of Chinese Academy of Sciences,Beijing 101408,P.R.China )
Abstract Knowledge graph (KG) link prediction aims to address the problem of missing multiple valid triples in KGs.Existing approaches either struggle to efficiently model the message passing process of multi-hop paths or lack transparency of model prediction principles.In this paper,a new graph convolutional network path semantic-aware graph convolution network (PSGCN) is proposed to achieve modeling the semantic information of multi-hop paths.PSGCN first uses a random walk strategy to obtain all k-hop paths in KGs,then captures the semantics of the paths by Word2Sec and long shortterm memory (LSTM) models,and finally converts them into a potential representation for the graph convolution network (GCN) messaging process.PSGCN combines path-based inference methods and graph neural networks to achieve better interpretability and scalability.In addition,to ensure the robustness of the model,the value of the path threshold K is experimented on the FB15K-237 and WN18RR datasets,and the final results prove the effectiveness of the model.
Key words: knowledge graph(KG),link prediction,graph convolution network (GCN),knowledge graph completion (KGC),multi-hop paths,semantic information
0 Introduction
Nowadays knowledge graphs (KGs) are widely used in social media,e-commerce,healthcare and finance[1], such as YAGO[2],DBpedia,Freebase[3],and the analysis of knowledge graphs has become a hot topic of current research.KGs often represent facts by different triples,where each triple is of the form (head entity,relation,tail entity),or a simple form(h,r,t).However,due to the overabundance of factual information in reality,the triples in KGs are usually incomplete[4-5],which brings a great challenge to the study of knowledge graphs,leading to the study of link prediction for knowledge graphs.Link prediction algorithms can automatically complement KGs,which is very important to improve the quality of KGs.
In recent years,graph neural networks (GNNs)have received a lot of attention with the increasing research on KGs.For example,graph convolutional neural networks (GCNs)[6]is the most classical graph neural network model,and the main idea of GCNs is to map nodes into a low-dimensional representation and then update node information accordingly by aggregating the neighborhood information used for message passing,and thus gradually iterate to obtain the final result[7].However,although GNNs make full use of the structural information of the knowledge graph,they ignore the relational paths between nodes,and thus the inference results of the model lack transparency,i.e.,GNNs cannot provide explicit relational paths for model behavior interpretation.In contrast,the path-based inference approach extracts relational paths directly from KGs and models them interpretably.However,since the number of paths in the graph may increase incrementally with the length of the path,these models are difficult to achieve scalability,i.e.,it is very difficult for the models to obtain good computational results when the number of paths is too large.
In this paper,a path semantic-aware graph convolutional network (PSGCN) is proposed for knowledge graph link prediction using semantic information of relational paths.Specifically, the correspondingk-hop path sets are obtained using each node in the graph as the head node,then the set of word vectors of the path sets are obtained using the Word2Sec model[8-10],and the semantic information of thek-hop paths are obtained using the long short-term memory (LSTM) model[11-13],and finally the semantic information is used as the weights of the paths for the message passing of the model.In addition,to further enhance the robustness of the model,this work considers the effect of the value of parameterk(i.e.,path length) of thek-hop path on the effect of the model,and finally chooses the optimalkvalue.Thus,the proposed model PSGCN inherits the scalability of GNN by preserving the message passing formula, while increasing the transparency of the mode's inference results by aggregating the semantic information of multiplek-hop paths of each PSGCN combines the advantages of both approaches node,i.e.,path-based model and GNN model,making the model simultaneously interpretable and scalable,and solving the current problems of knowledge graph link prediction.
The main contributions of this work are as follows.
(1)The node and relationship contents in KGs are encoded as semantic vectors to facilitate better access to the semantic information in the KGs.
(2)The multi-hop path information of each node is added to the aggregated content of the graph neural network, which enriches the corresponding network structure and makes the model have some interpretability based on the inheritance scalability.
(3)The experimental results on two datasets show that PSGCN combines the advantages of both approaches and outperforms the experimental results compared with GNN-based inference models and pathbased inference methods.
1 Related work
There are two common methods for link prediction,and the first one is to model the relational paths in the graph directly,i.e.,to consider the implicit information of the relational paths based on the embedding model.Among them, path ranking algorithm(PRA)[14-15]is a typical algorithm that considers a path as 1 if it exists betweenhandtand 0 otherwise.Since the judgment logic of PRA[14-15]considers only the information of each path itself, the PSTransE[16],PTransE[17],RTransE[18]models are enriched with additional judgment conditions,which consider that the more information in the head entity that is passed through the path to the tail entity,the more reliable the path is.However,the semantic information of the paths is also an equally important judgment factor,for example,as shown in Fig.1,Harry Potter novels→created→J.K.Rowling→career→British author and Harry Potter novels→created→British author are two different paths,but they convey close semantic information.
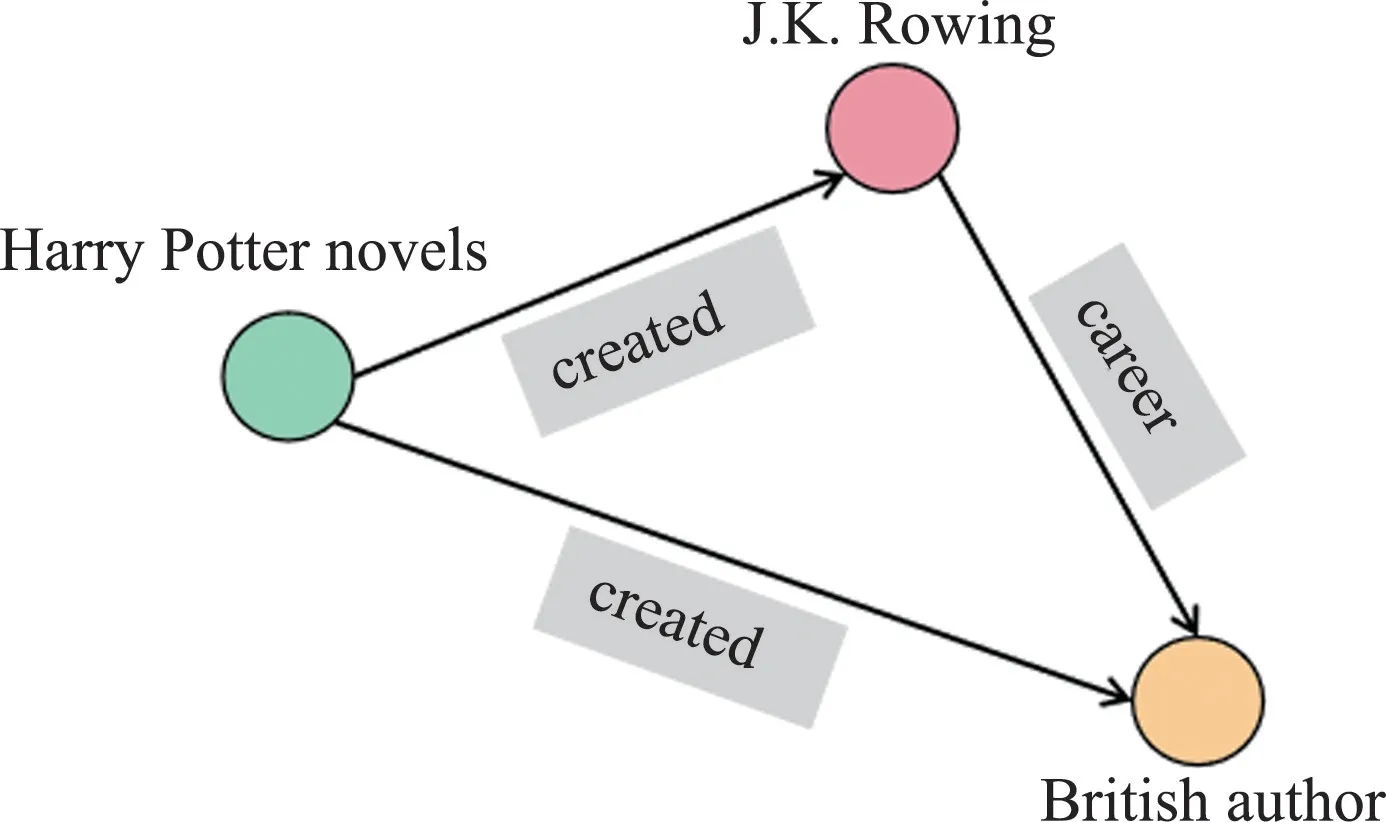
Fig.1 An example of two different paths that convey the same semantics.
Therefore,it is important to add multi-hop path semantic information into the judgment condition of confidence of that path,which is not considered in the above models.Moreover,path-based models are difficult to achieve scalability due to the limitation of path length,so some models resort to using only one-hop paths (i.e.,triples) to balance scalability and inference power.
The second approach is graph neural networks(GNNs),of which the most commonly used variant is graph convolutional networks (GCNs)[6].Compared with the first approach,GCNs possess transferability.While GCNs perform message passing by aggregating the neighborhood information of each node,they ignore the relation type.Relational graph convolutional networks (RGCNs)[6]add the element of relation type on GCNs by performing relational aggregation,making them applicable to multi-relational graphs.Later,the graph attention network (GAT) model emerged to combine GNN with attention mechanism,while Caps-Net and graph attention network (CGAT),describing relationships graph attention network (DR-GAT) and other variants improve the performance on the basis of GAT.However,neither GCNs nor GATs can provide explicit relational paths for model behavior interpretation,and thus the results are opaque and not interpretable.
Considering the advantages and disadvantages of the above two approaches,this paper chooses to use the semantic information of multi-hop paths as the aggregation element of the GNN model,which makes the model interpretable on the basis of transferability.
2 Problem definition and framework
2.1 Problem definition
In this paper,some common notations are defined to represent the structure of graphs.
The graphGis used to represent a KG,which consists of many triples,i.e.,
whereEdenotes the set of nodes onG,Nis the number of nodes andRdenotes the set of relations onG,Mis the number of relation types.
2.2 Overall framework
The framework has three main components: finding multi-hop paths in the graph using a random walk strategy[19], a combination of Word2Vec[8-10]and LSTM[11-13]to obtain semantic information about the paths,and a graph convolution neural network to perform message passing on multi-hop paths.Fig.2 shows a brief workflow.And the top part of the figure is for word embedding,which uses Word2Vec to get the word vectors of entities and relations.The middle part is the part for path semantic acquisition,which first uses a random wandering algorithm to acquirek-hop paths in the graph and then uses LSTM networks to acquire the path semantic information.The bottom part is a graph convolution network for learning the hidden information in the paths to facilitate link prediction.

Fig.2 The brief architecture of the graph convolution network using semantic information of multi-hop paths
Path setThe set Paths consisting of allk-hop paths in graphGthat satisfiesk≤Kis obtained using a random wandering strategy.
Path weightsBased on the word vectors obtained by Word2Vec,the multi-hop paths in Paths are encoded using LSTM to obtain the corresponding semantic information as the weights of the paths.
Message passing on pathsThe path weights are passed as potential messages in the graph convolution neural network.
3 Proposed method
3.1 Path finding module
Separate triples are kept in the knowledge graph.To obtain different relational paths,this paper makes use of the random walk path finding (RWPF)strategy,which finds multi-hop paths centred on a single head node by randomly wandering over the knowledge graph.For example,because the end node of the triple Harry Potter novels →created →J.K.Rowling and the head node of the triple J.K.Rowling→career →British authors are the same J.K.Rowling,then they can be combined into one relational path,Harry Potter novels →created →J.K.Rowling→career→British authors.
Algorithm 1 shows the discovery process of multihop relational paths.First,a nodee1is randomly selected as the current node from the graph,and the adjacent nodes can be reached by visiting each outgoing edge.A neighboring nodee2is randomly selected as the new current node,and then each outgoing edge of the node is visited to get a random wandering pathP.As long as the number of nodes inPis less than or equal to the path lengthK,the valid path is saved and the wandering continues.The above process is repeated until all valid paths are found.Note that visiting each neighbor node is random with the same probability.
In Algorithm 1,each neighbor node is selected randomly with the same probability,in which the probability of selecting a node and the corresponding current path are as

3.2 Path scoring module
In practical scenarios,it is possible that different triples have different semantics,and these differences may have an impact on the direction of the multi-hop path and gradually affect the final result.For example,if semantics are not taken into account,the triples (Harry Potter novels,created,J.K.Rowling) and (Harry Potter films,directed,Alfonso Cuaron) are only slightly different and would be represented as identical embeddings.But if their semantics are considered,the pathway of the triple (Harry Potter novels,created,J.K.Rowling)could be (J.K.Rowling,husband,Neil Murray),while the pathway of the triple (Harry Potter films,directed,Alfonso Cuaron) could be (Alfonso Cuaron,wife,Anna Lisa),and this differences can gradually accumulate and eventually have a huge impact on the results.As shown in Fig.3,the triples in the dotted box differ little in terms of structure,but once the field of view is widened to look at the nodes after the longer path,it becomes clear that the two triples are very different.
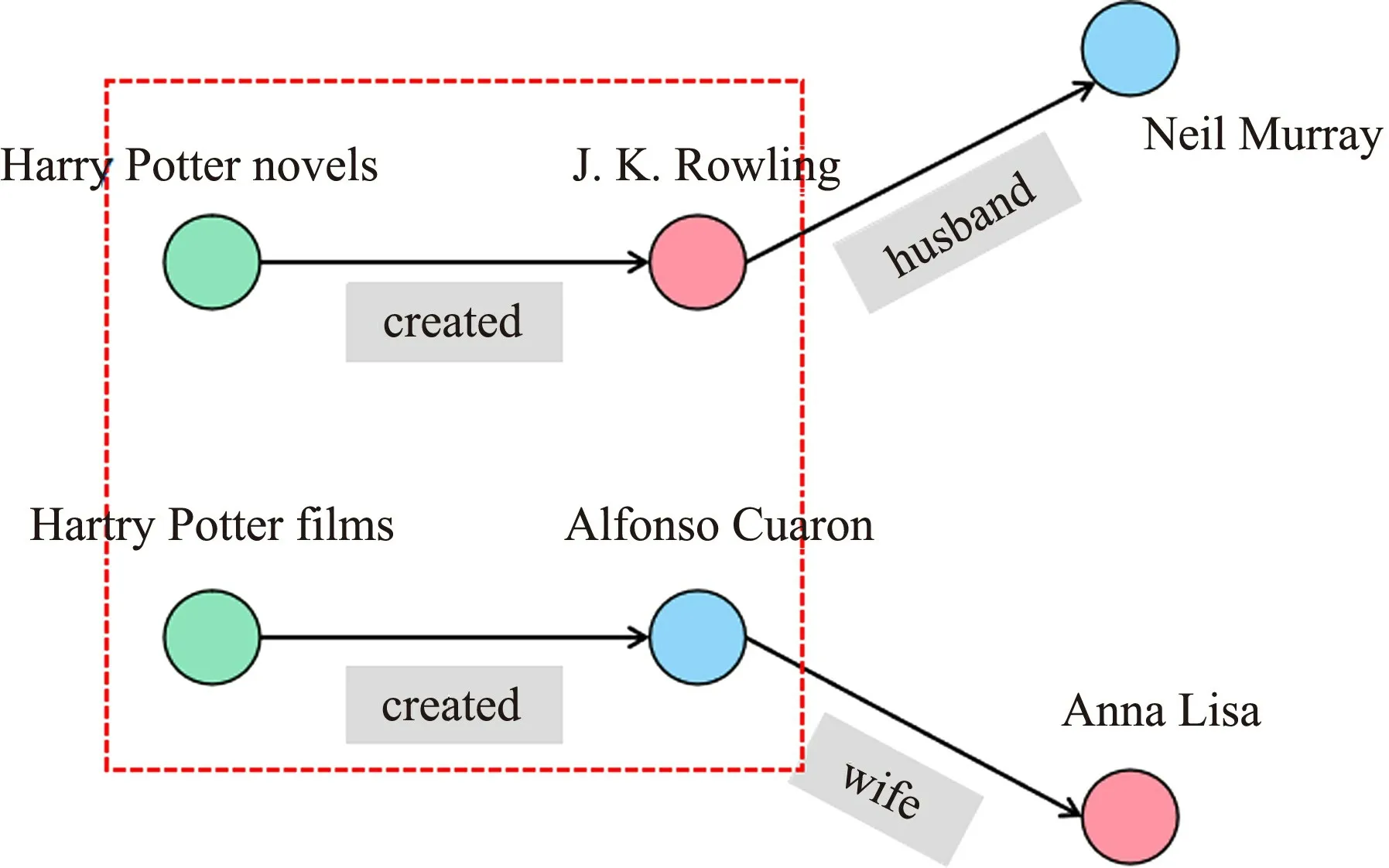
Fig.3 An example of a path that influences the node characteristics.
It is therefore important to explicitly incorporate the semantics of entities and relations into path representation learning.
Embedding part The contents of entities and relations in the triples are often independent and there are no stopwords.Therefore,the Word2Vec[8-10]model is used for word embedding in order to obtain semantic information about the content of each entity and relation,and obtain anm-dimensional preprocessed word vector,which is convenient for later concatenating word vectors according to the multi-hop path.Algorithm 2 shows the process of connecting the semantics of the paths.

Algorithm 2 Semantic connection of paths Input: Multi-hop path set P,the set of entity word vectors We and the set of relational word vectors Re;Output:Multi-hop path feature set F;1: Definition: define p as a cell path,s as any triple in the path;2: Initialization: initialize festure set F to null;3: for each p in P do 4: for each s in E do 5: //h is the head node of s,often s[0];

?
LSTM partRNN models can describe a path through a sequence and generate a vector of them to represent its overall semantics.Among various RNN methods,LSTM is used because LSTM is able to remember long-term dependencies in a sequence,and this memory and understanding of the sequential information of a sequence is essential for computing the confidence of a multi-hop relational path.
At step l of the current path,the LSTM hidden layer outputs a vectorhl-1and the current embedding of the entityeland the relationrlare connected as the input vector.
where ⊕is the connection operation.Note that ifelis the last entity,then an empty relationrlis filled at the end of the path.Therefore,in order to make the input vector contain not only the sequential information of the nodes in the path,but also the semantic information of the entity and its relation to the next entity,hl+1andxlis used to learn the state of thel-th hidden layer of the LSTM as
where,il,ol,fldenote input gates,output gates and forgetting gates,respectively;cl∈Rd,dl∈Rddenote the cell state vector and information conversion module,respectively,anddis the number of hidden cells;Wc,Wi,Wf,WoandWhare mapping coefficient matrices,andbc,bi,bfandboare bias vector;σ(·) is the activation function.
In order to score the different paths,i.e.,to get the semantic confidence of the multi-hop pathpkas a whole,therefore the final output is used into the score using a fully-connected layer,given by
where,Wfcis the fully connected layer coefficient weights and the ReLU function is used as the activation function.
3.3 Messaging module
In order to equip GNN with the ability to capture multi-hop path information,the semantic information ofk-hop paths is modeled directly in the message passing process of GNN.And the set of validk-hop relational paths is defined as

whereCei,rrefers to the total number of relationship types in all paths withehas the head node.AndWe=LSTM(e) ,e∈{eh,…,et} ,Wr=LSTM(r) ,r∈{r1,…,rk}.
Information from paths of different lengths is aggregated via attention mechanism as

whereWselfandWzare learnable model parameters,andσis a non-linear activation function.
The purpose is to predict new triples,i.e.,to calculate the scoresfh,r,tof possible triples (containing possible edges) (h,r,t) ,and thus determine the confidence of these edges.Firstly the negative sampling is samplingωnegative samples for each positive sample by randomly replacing the head and tail nodeshandtwith other entities.And then the plausibility scores of the positive samples are maximized by minimizing the cross-entropy loss as follows.
whereω^isω+1 ,ρis the sigmoid function,andyis an indicator set toy=1 for positive triples andy=0 for negative ones.And DistMult[20]is used as the scoring function,i.e.,all otherk-hop relational paths (k>1)fromhtotcan be associated as a matrixPr,sofh,r,tis denoted as:fh,r,t=eThPreo.
4 Experiments
4.1 Datasets
FB15K-237 is a subset of FB15K and FB15K is a subset of Freebase.WN18RR is a subset of WN18 and WN18 is a subset of WorldNet.Although both FB15K and WN18 have a large number of test triples,they can be obtained simply by inverting the training triples[21],while FB15K-237 and WN18RR avoid this problem,and therefore they are more convincing datasets.In this paper,these two more convincing datasets,FB15k-237 and WN18RR,are chosen to validate the proposed model.The details of the datasets are shown in Table 1,where PER denotes the average number of triples for each relationship type.
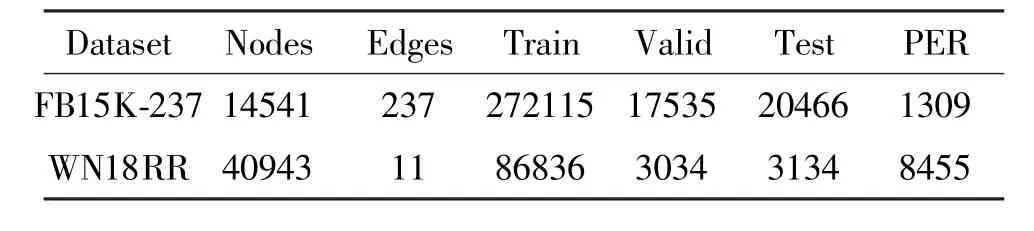
FB15K-237 14541 237 272115 17535 20466 1309 WN18RR 40943 11 86836 3034 3134 8455
Few relations in the FB15K-237 dataset have hierarchical characteristics.Therefore,this dataset is sparse(as shown in the table,the number of entities corresponding to each class of relations is small),and the network hierarchical characteristics are not obvious.In contrast,the WN18RR dataset contains hierarchical relationships between words,such as hypernym,has_part.Therefore,the dataset is dense (as shown in the table,the number of entities corresponding to each type of relationship is larger),with a natural hierarchical structure,and the network hierarchical characteristics are obvious.
4.2 Evaluation metrics and parameter settings
Mean reciprocal rank (MRR) and Hitratio@ K(Hits@K) are used to compare the performance of the model in experiments,where for Hits@K,Hits@1 and Hits@10 (the proportion of correct answers ranked in the top 1 and top 10 in all candidate sets) are chosen as the evaluation metrics.And all three metrics (MRR,Hits@1 and Hits@10) have higher values for better model performance.
To make the model work best,the same configuration for the following hyperparameters are used: initial embedding dimension of entities and relationsd=100,word vectors dimensionwd= 100,dropout rateμ=0.5,learning rateγ=0.001,the initial value of the threshold for path lengthsK= 2,and the number of units of LSTM is set to 128 according to the path length of FB15K-237 and WN18RR datasets.In addition ,the GNN depthlis set to 4 for the FB15K-237 dataset and 2 for the WN18RR dataset.The reason is that the FB15K-237 dataset has more data than the WN18RR dataset,so a deeper neural network is needed for training.
4.3 Baseline
In order to evaluate our method in terms of both knowledge transfer learning ability and multi-hop path information capture ability,several representative methods corresponding to them are selected for comparison.
Basic group (models without considering path information) including RGCN[6], DistMult[22], ComplEx[23],TransE[24],ConvKB[25],CGAT[26]and DRGAT[27]are chosen.
Path group (adding path information into the embedding vector) including PSTransE[16], PTransE[17]and RTransE[18]are chosen.
4.4 Results and analysis
The results of the different models on FB15K-237 and WN18RR are given in Table 2.For the overall experimental results the comparison shows that the proposed method outperforms the other methods,including the basic and path groups.
Specifically,in the basic group, (1) for the FB15K-237 dataset,Hits@ 1 is improved by about 10.94%,Hits@ 10 is improved by about 15.15%,MRR is improved by about 9.18%; (2) for the WN18RR dataset,Hits@10 is improved by about 5.53%,MRR is improved by about 5.57%.This demonstrates that adding path information can improve the effect.And in the path group,(1) for the FB15K-237 dataset,Hits@1 is improved by about 78.45%,Hits@10 is improved by about 11.83%,MRR is improved by about 42.32%; (2) for the WN18RR dataset,Hits@10 is improved by about 1.48%,MRR is improved by about 17.37%.This demonstrates the effectiveness of using GCN for learning about path information.

Methods FB15K-237 WN18RR Hits@1 Hits@10 MRR Hits@1 Hits@10 MRR Basic RGCN 0.140 0.380 0.194 0.180 0.487 0.193 DistMult 0.198 0.419 0.281 0.39 0.504 0.430 ComplEx 0.194 0.450 0.278 0.409 0.510 0.449 TransE 0.199 0.471 0.291 0.123 0.532 0.366 ConvKB - 0.421 0.289 - 0.525 0.248 CGAT - 0.432 0.295 - 0.528 0.242 DR-GAT 0.158 0.425 0.257 0.164 0.493 0.238 Path PTransE(3-step) 0.164 0.443 0.268 0.156 0.560 0.368 RTransE(3-step) - 0.487 0.281 - 0.562 0.398 PSTransE - 0.476 0.279 - 0.571 0.390 This work 0.209 0.483 0.294 0.420 0.573 0.454
According to Table 2,it is clear that PSGCN is less effective on the FB15K-237 dataset than the WN18RR,which is supposed to be due to the high number of paths in the FB15K-237 dataset,resulting in a large amount of information redundancy.Therefore,to confirm the above conjecture,experiments are conducted on the threshold value of the multi-hop path length(i.e.parameterK) and results are shown in Table 3 and Fig.4.
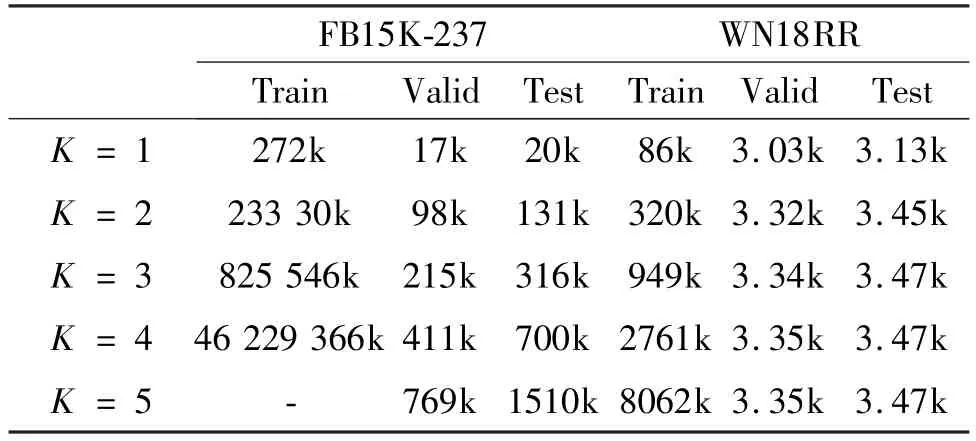
FB15K-237 WN18RR Train Valid Test Train Valid Test K = 1 272k 17k 20k 86k 3.03k 3.13k K = 2 233 30k 98k 131k 320k 3.32k 3.45k K = 3 825 546k 215k 316k 949k 3.34k 3.47k K = 4 46 229 366k 411k 700k 2761k 3.35k 3.47k K = 5 - 769k 1510k 8062k 3.35k 3.47k

Fig.4 Changes in the number of k-hop paths with the threshold value K
It is clear that the number of paths in FB15K-237 grows very rapidly as the path length thresholdKincreases,clearly far exceeding the rise in WN18RR.Specifically,a sharp increase in the number of paths occurs whenK≥3.In order to investigate the effect of a larger number of paths on the effect of the model,experiments on the FB15K-237 and WN18RR datasets are conducted to obtain the variation of the effect of the model at differentKvalues,and the results are shown in Tables 4 -5 and Figs 5 -6.
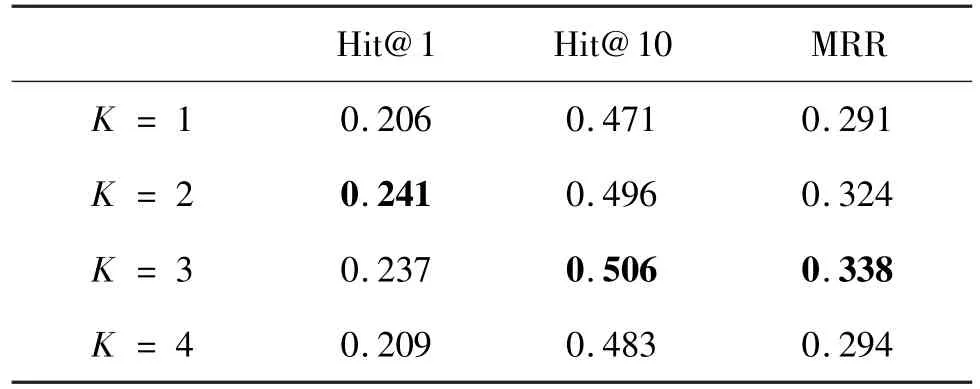
Hit@1 Hit@10 MRR K = 1 0.206 0.471 0.291 K = 2 0.241 0.496 0.324 K = 3 0.237 0.506 0.338 K = 4 0.209 0.483 0.294
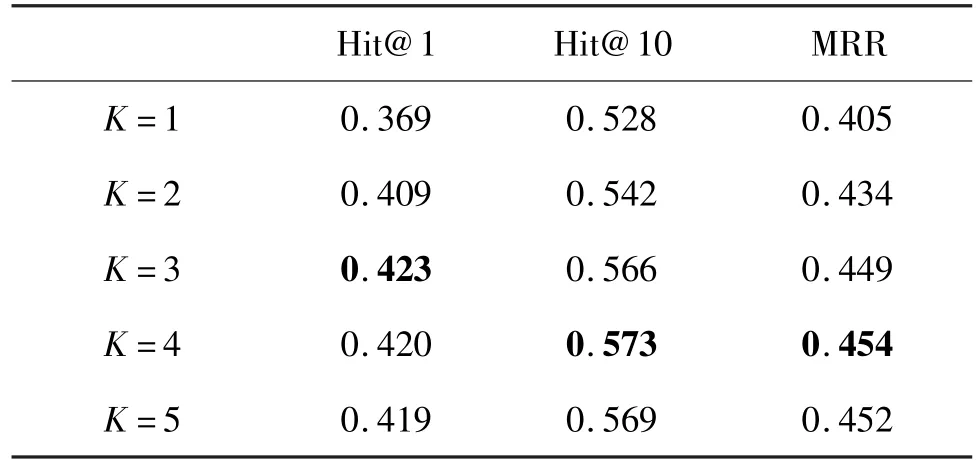
Hit@1 Hit@10 MRR K=1 0.369 0.528 0.405 K=2 0.409 0.542 0.434 K=3 0.423 0.566 0.449 K=4 0.420 0.573 0.454 K=5 0.419 0.569 0.452

Fig.5 Performance at different K on FB15K-237

Fig.6 Performance at different K on WN18RR
From Table 3 it can be seen that the number of paths in the test set in WN18RR remains essentially constant afterK≥3.Accordingly,the impact ofK=3,K=4 andK=5 is basically stable for the WN18RR dataset,as shown in Fig.6 and Table 5.
In addition,as shown in Fig.5 and Fig.6 there is an interesting phenomenon that the effect of the model on the FB15K-237 dataset decreases significantly atK≥3,while the effect of the model on WN18RR increases significantly atK≤3,which indicates that the model does not make effective use of the path information for the FB15K-237 dataset.Considering the sparsity of datasets,the experiments on FB15K-237 on the number of layerslof the neural network are conducted to study the effect of PSGCN's complexity on the inference performance of the model.And the experimental results are shown in Table 7.
When the threshold valueKof path length is fixed as 1,2,3,respectively,the performance changes of the model when setting different neural network layerslare shown in Figs 7 -9.

Hits@1 Hits@10 MRR l=2,K=1 0.187 0.398 0.223

l=2,K=2 0.196 0.403 0.258 l=2,K=3 0.194 0.417 0.257 l=3,K=1 0.192 0.442 0.258 l=3,K=2 0.220 0.471 0.303 l=3,K=3 0.202 0.481 0.295 l=4,K=1 0.206 0.471 0.291 l=4,K=2 0.241 0.496 0.324 l=4,K=3 0.237 0.506 0.338 l=5,K=1 0.210 0.476 0.294 l=5,K=2 0.262 0.511 0.336 l=5,K=3 0.248 0.512 0.342 l=6,K=1 0.213 0.479 0.294 l=6,K=2 0.258 0.512 0.331 l=6,K=3 0.244 0.509 0.341
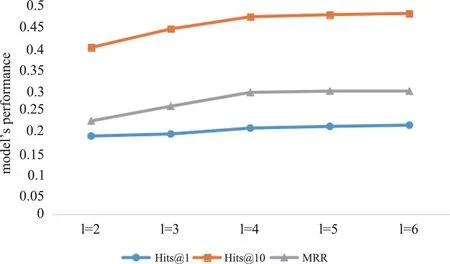
Fig.7 The variation of model performance with parameter l for K = 1

Fig.8 The variation of model performance with parameter l for K = 2
According to Table 7 and Figs 7 - 9,it can be seen that the model has the best inference performance on the FB15K-237 dataset when the number of neural network layerslis taken as 5 or 6.Since the size of the FB15K-237 dataset is positively about 5 to 6 times larger than that of WN18RR,this phenomenon appears probably because the complexity of the model and the size of the dataset are closely and positively correlated.
Therefore,the effectiveness of the model to perform inference is related to the sparsity of the dataset.For datasets with more sparse data (e.g.,FB15K-237),the number of paths in the dataset is higher and the amount of data that the model can process is larger,so the depth of the network structure in the model should be increased (the number of neural network layerslis set a bit higher) in order to effectively utilize these path data.Meanwhile,previous work onK-value illustrates that when theK-value is too high, the FB15K-237 dataset has a large amount of redundant information,which will lead the model to learn some useless data and eventually lead to poor performance of the model.Therefore,combining the two parameterslandK,the model should be set with higherland lowerKfor more sparse and larger datasets,and conversely,for denser and relatively smaller datasets (e.g.,WN18RR),the model should be set with lowerland higherKaccordingly.
5 Conclusions
Most existing link prediction methods are divided into two types.One approach is based on graph neural networks for inference,and only focuses on the topological information of neighboring nodes in the graph data,while ignoring the knowledge paths and the semantic information of the paths in the graph data,which also leads to the models without interpretability;the other approach is to perform inference by path derivation only.Although such model can explain inference results by knowledge paths,their results are unstable when dealing with large datasets.To obtain an interpretable and efficient inference method,in this work,a neural network PSGCN capable of capturing semantic information of multi-hop paths is proposed to solve the link prediction problems,while achieving the interpretability of multi-hop path inference methods and the scalability of GNNs that are efficiently applicable to large datasets.In addition,experimental results show that the impact of the path length threshold parameterKand the number of neural network layerslon the effectiveness of the model is important,and the most appropriate parameterKvalue andlvalue are finally chosen in this work to further improve the results.In short,PSGCN combines the advantages of both GNNs and path-based inference models to efficiently perform multi-hop relational inference in an explicit and interpretable manner,obtaining better results on the FB15K-237 and WN18RR datasets.
 High Technology Letters2023年3期
High Technology Letters2023年3期
- High Technology Letters的其它文章
- Joint UAV 3D deployment and sensor power allocation for energy-efficient and secure data collection①
- Experimental study on the failure factors of the O-ring for long-term working①
- Research and experimental analysis of precision degradation method based on the ball screw mechanism①
- In-flight deformation measurement for high-aspect-ratio wing based on 3D speckle correlation①
- A greedy path planning algorithm based on pre-path-planning and real-time-conflict for multiple automated guided vehicles in large-scale outdoor scenarios①
- Design of two-dimensional spatially coupled LDPC codes for combating burst erasures①