
超级稻定量供种预测模型研究*
2023-09-11 09:22梁秋艳张晓玲葛宜元迟佳
中国农机化学报 2023年8期
梁秋艳,张晓玲,葛宜元,迟佳
(佳木斯大学机械工程学院,黑龙江佳木斯,154007)
0 引言
在我国水稻面积结构性调减政策下,为兼顾水稻优质与高产,稳定粮食产能,采取的重要措施是种植超级杂交稻[1-3]。超级杂交稻是品质优良、产量高的新型水稻品种,其秧盘育秧精密播种要求(2±1)粒/穴。为达到精密播种要求,需提高超级稻定量供种精度,因此,建立定量供种预测模型,使预测精度达到实际使用要求,运用预测模型为定量供种器确定工作参数提供理论依据,对于提高超级稻的产量具有十分重要的意义[4-5]。
目前,预测模型的研究方法较多,包括灰色预测模型、ARIMA模型、BP神经网络模型、决策树模型以及XGboost模型。灰色预测模型通过少量的、不完全的信息,预测事物未来趋势的变化,然而忽略系统的随机性,中长期预测精度较差[6]。ARIMA模型通过结合历史数据预测未来的值,该模型运算效率高,但仅适用于预测短期时间内变化幅度较小的数据[7]。灰色预测模型、ARMIA模型仅适用于线性数据预测,为了实现非线性数据预测,达到中、长期预测的目的,需要引入BP神经网络模型、决策树模型、XGboost模型。BP神经网络模型由输入层、隐藏层、输出层组成,实现从输入到输出的非线性映射功能[8]。决策树模型适合处理不相关的特征数据集,具有计算简单、易于理解等优势,比较适合处理有缺失值的数据集[9]。XGboost模型求解目标函数时引入正则项,降低模型的复杂性,进一步地提高了算法的效率,适合处理大数据集[10]。
杨万里等[11]以植株和穗部作为自变量,水稻产量为因变量,建立线性、对数以及幂函数模型,根据决定系数R2数值的大小对模型预测值进行评估。徐强强等[12]运用指数平滑法,得到平滑系数,构建水稻产量趋势方程。王雨晨[13]构建灰色预测模型GM(1, 1),对未来6年水稻产量进行科学预测。胡红艳[14]建立ARIMA模型,得到产量预测值,对于指导农作物生产具有重要的现实意义。艾洪福等[15]提出基于BP神经网络模型的拓扑结构,对于精准农业的推广提供参考依据。夏玉红等[16]结合BP神经网络模型泛化能力强的优势,对光照强度传感器、土壤湿度传感器采集的数据误差进行校正,满足农业环境的需要。阮承治等[17]设计5层神经网络模型,得到预测值满足实际生产需要。柴春花等[18]搭建BP神经网络模型,该模型大大地提高了工作效率。贾玉昆[19]结合历史数据建立决策树算法,该模型更好地实现资源优化配置。彭牡林等[20]提出基于决策树算法,将样本集分为构建决策树以及验证决策树两部分组成,实现智能预警。胡智辉等[21]提出了基于XGBoost算法的预测模型,该模型能更好地实现实时预测。张艳红等[22]结合XGBoost算法的多线程、效率高的特点,建立预测模型。赵振国[23]建立XGBoost预测模型,得到的预测结果更贴近真实值。利用模型预测供种量,可准确地把握机器当前的状态,提高供种精度。
本文针对课题组研制的振动式定量供种装置,选取千粒重、振幅、排种轮转数作为影响因子,进行多因素定量供种试验。通过应用BP神经网络、决策树以及XGboost算法模型,结合机器学习算法训练速度快的优势,对振动式水稻播种装置进行性能预测,以决定系数R2和相对误差为评价指标,对比分析得出最优供种量预测模型。
1 材料与方法
1.1 数据来源
试验平台采用2CYL-450型振动式定量供种装置,选取千粒重、振幅、排种轮转数作为影响因子,进行多因素定量供种试验。该试验利用电子分析天平、电磁振动器以及变频调速电机分别测量千粒重的重量、振幅强度以及排种轮转数并连续测量94组数据。
1.2 供种量计算
1.2.1 定量供种机构
如图1所示,种箱外侧加装调速电机,控制螺旋勺式槽轮的转速,使种子从种箱中定量排出,减少对稻种的机械损伤。种箱内部加装电磁振动装置,调节振幅使种子在槽轮上方的充填区形成勺形流线连续种流,相比常规供种,可缓解堵塞种问题,并提高供种的均匀性[24]。
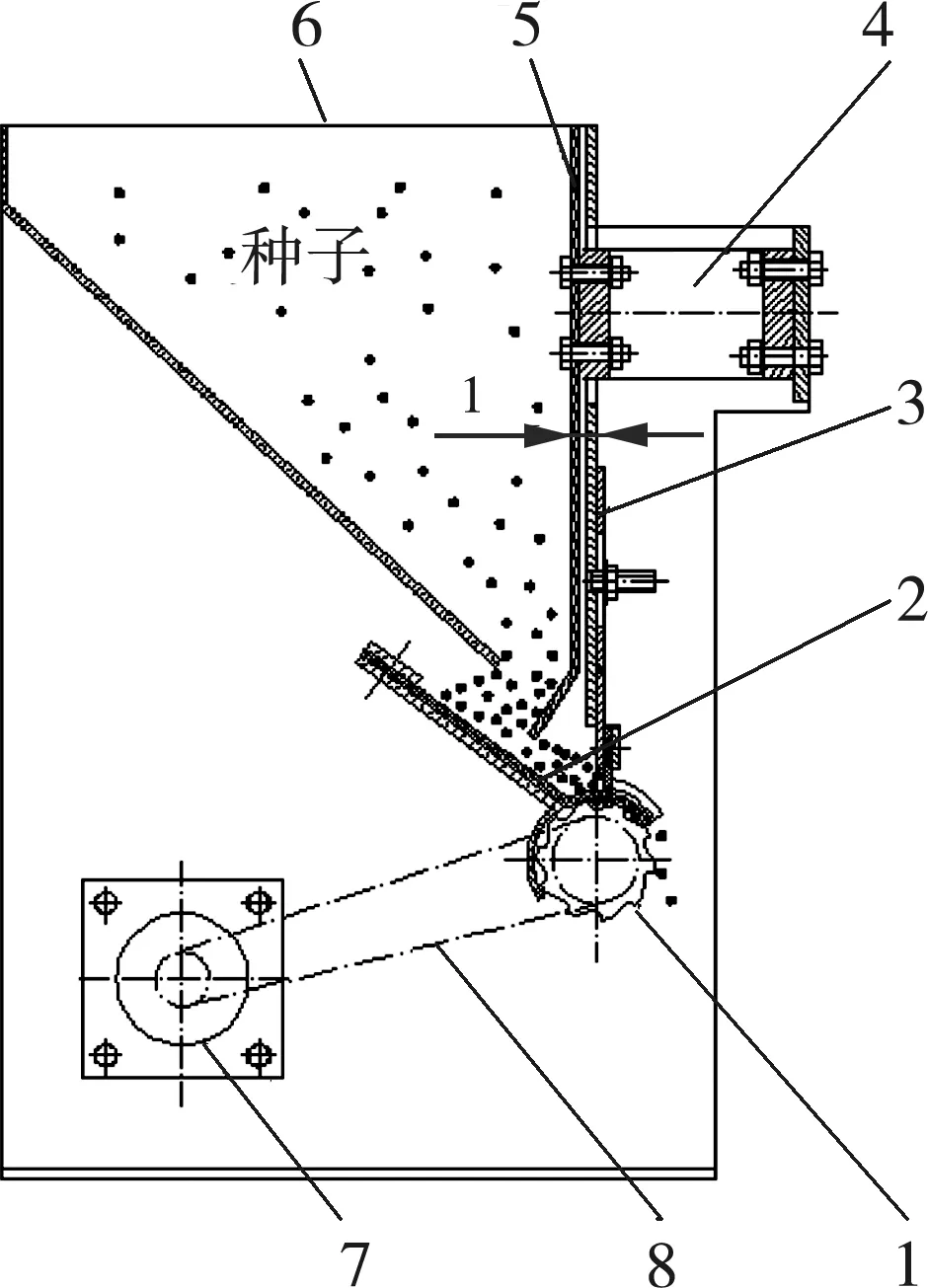
图1 定量供种装置示意图
如图2所示,勺式外槽轮的周围布满勺形种槽,构成的“勺形流线”,沿着外槽轮滑动集种。外槽轮上部的调节门与中间的调节板形成排种盘面,可调节范围为-5°~10°,以满足不同播量的播种要求。
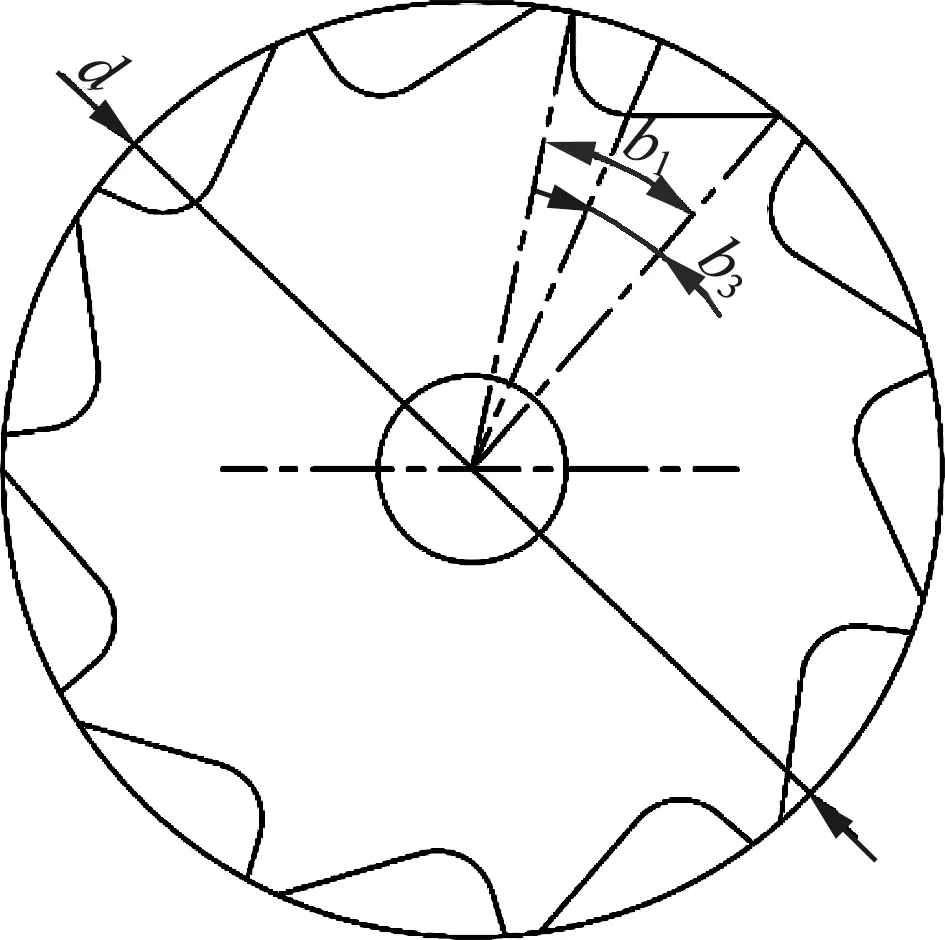
图2 螺旋勺式槽轮
播种机工作时,变频调速电机启动,链条带动螺旋勺式槽轮传动。经电磁振动器带动振动板簧,实现充种区域稳定续种,最终种子从气动振盘均匀排出,实现定量供种。
1.2.2 理论供种量计算模型
单位时间内的理论供种量与种子千粒质量、种子体积、排种轮的转速以及排种轮每圈内排出的种子体积有关。如图3所示,螺旋勺式槽轮的播种截面面积fl由圆弧面积fl1、三角形面积fl2、扇形面积fl3以及圆弧面积fl4组成。

图3 螺旋勺式槽轮播种截面
稻种颗粒模型近似为椭球体,通过计算该模型的体积来计算供种装置的充种体积,单粒种子的体积计算如式(1)所示。
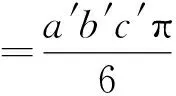
(1)
式中:a′——修正后的种子长度,mm;
b′——修正后的种子宽度,mm;
c′——修正后的种子高度,mm。
螺旋勺式槽轮单位时间的理论供种量ql可用式(2)表示。
(2)
式中:el——槽轮排种槽的带动层面积,mm2;
B秧——秧盘的宽度,mm;
n——排种轮转速,r/min;
g——水稻种子千粒质量,g;
b1、b3——对应的圆心角,(°);
h2——勺形流线直线段长度,mm;
r2——扇形面半径,mm;
d——螺旋槽轮直径,mm。
2 定量供种预测模型建立
2.1 BP神经网络算法
通过深度学习,基于Tensorflow框架,搭建BP神经网络模型,对供种量进行预测。BP神经网络由输入层、隐含层、输出层组成,输入层是信息的输入端,确定神经元的个数,隐藏层是信息的处理端,通过正向传播,结合激活函数,对信息进行处理,而输出层是信息的输出端,与期望信息相差过大时,通过反向传播修正误差,得到最终的预测值[25]。如图4所示,输入层由千粒重、振幅以及排种轮转数组成,隐藏层通过Relu作为激活函数,正向传播训练模型,而输出层得到的训练集预测值与试验值对比,MAE绝对误差不在预期范围内,则通过该模型内部的Adam优化器,进行反向传播修正误差,经过多轮迭代训练模型,最终建立BP神经网络模型。

图4 BP神经网络算法预测流程图
2.2 决策树算法
由于决策树算法本身存在运算速度快、不容易过拟合等优势,故采用决策树搭建预测模型。一棵完整的决策树,本质是树模型,采用自顶而下的结构,由根部节点、叶子节点以及分支组成,根部节点划分样本集,通过Gini系数计算,对决策树的叶子节点进行剪枝处理得到最优解,而树的分支主要是存储预测结果[26]。
树的左侧叶子节点决策结果如式(3)所示。
(3)

N1——树的左侧切分点样本容量;
j——最优切分变量;
s——最优切分点;
R1(j,s)——左侧特征空间;
xi——样本类别;
yi——样本值。
树的右侧叶子节点决策结果如式(4)所示。
(4)

N2——树的右侧切分点样本容量;
R2(j,s)——右侧特征空间。
通过叶子节点中的决策结果,计算损失函数值,选择最优切分变量j与最优切分点s,找到最优切分点,如式(5)所示。
(5)
式中:L(j,s)—计算模型中的损失函数。
在(j,s)划分区域求解相应的输出值如式(6)所示。
(6)
将特征空间划分为M个区域R1,R2,R3,…,RM,生成决策树,如式(7)所示。
(7)
式中:I——表示指示函数。
通过定量供种试验,采集周期为94次的数据集,如图5所示,使用Jupyter Notebook环境中的pandas库导入文件,然后对其进行划分,将前80次的数据作为训练集,后14次的数据作为测试集。根据训练集准确率调节模型的最佳参数,进行决策树的算法建模,预测后14次测试集的数据,得出测试集的供种量预测值。结合训练集数据,对决策树进行网络搜索法调参,包括树的最大深度max_depth、最大特征数max_features以及随机种子数random_state,其中最大特征数主要是为了防止训练集建模出现过拟合情况,而随机种子数是确保每次仿真的运行结果一致,最终建立决策树预测模型。
2.3 XGboost算法
相比决策树算法,XGboost算法属于集成学习模型,具有训练速度快、预测精度高,由多棵决策树构成,且每棵决策树之间是相互关联的[27]。该算法预测的结果是每棵决策树预测值相加得到的值,XGboost算法的预测值计算如式(8)所示。
(8)
式中:fk——第k棵树模型;
K——树的数量;
F——所有回归树的集合。
求出该模型的损失函数,该函数取值为最小时,模型达到最优化的效果,如式(9)所示。
(9)


Ω——第k棵树的正则项。
正则项主要是用于控制XGboost模型的复杂度,为了降低方差、防止过拟合现象,需要在目标函数中添加正则项,由式(10)求得。
(10)
式中:T——叶子节点数量;
wj——叶子节点权重;
γ、λ——惩罚项的系数。
考虑到XGboost算法是一种加法模型,随着模型里面树的棵数增加,前t-1棵树对第t棵树影响,通过迭代的方式拟合上一棵树的预测误差,该算法得到的最终预测值,由式(11)求得。

(11)
定量供种试验采集94次数据,将试验中的前80次作为训练集,以Python语言为算法框架,结合网络搜索法对决策树棵数n_estimators、学习率learning_rate以及树的最大深度max_depth等参数进行寻优,其中学习率是为了防止上一棵决策树产生训练误差的权重过高,影响下一个决策树的结果,从而避免训练集中的模型出现过拟合的现象。如图6所示,结合训练集数据,通过多棵决策树迭代计算训练误差,直至得到最后一棵树的预测结果与每棵树的训练误差总和,最终建立XGboost模型。

图6 XGboost算法预测流程图
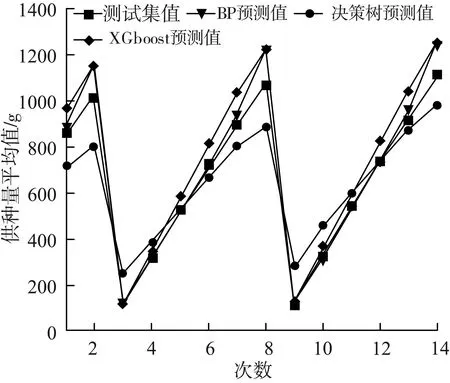
图7 各模型预测的拟合图
3 结果与分析
3.1 模型性能评价指标
通过定量供种试验获得样本数据共94个,将该数据划分训练集以及测试集,前80次作为训练集用作数据建模,而后14次作为测试集,得到供种量的预测值,验证模型的预测效果。R2为预测模型的判定系数,取值范围为[0,1],R2的取值越接近1,说明定量供种预测模型的精度越高,即模型的性能越好[28],如式(12)所示。
(12)

为了对比分析各个模型的实际预测效果,以相对误差为评价指标,数值越小表示预测值更贴近测试集值,如式(13)所示。
误差=|fi-yi|/yi×100%
(13)
3.2 各模型的预测效果
利用网络搜索法得出BP神经网络、决策树、XGboost模型的最优参数,其中BP神经网络模型的最优参数为迭代次数为100轮、激活函数为Relu,得出训练集的准确率为0.70;决策树的最优参数为最大深度max_depth为10、最大特征数max_features为‘sqrt’,得出训练集的准确率为1.0;XGboost的最优参数为决策树棵数n_estimators为50、学习率learning_rate为0.2以及树的最大深度max_depth为5,得出训练集的准确率为1.0,为了验证模型的合理性,预测后14次的效果,将各模型的预测值与测试集值相比,R2分别为0.87、0.91、0.95。
3.3 模型对比分析
为检验各模型的实际预测效果,基于上述模型的求解结果,从表1可以看出,BP、决策树、XGboost模型的相对误差分别为18%、11%、5%,说明XGboost预测模型在测试集中得到的预测值,相比BP神经网络模型、决策树模型,更贴近于测试集值。可见,XGboost算法具有更高的预测精度,预测性能更优,更适用于供种量预测。
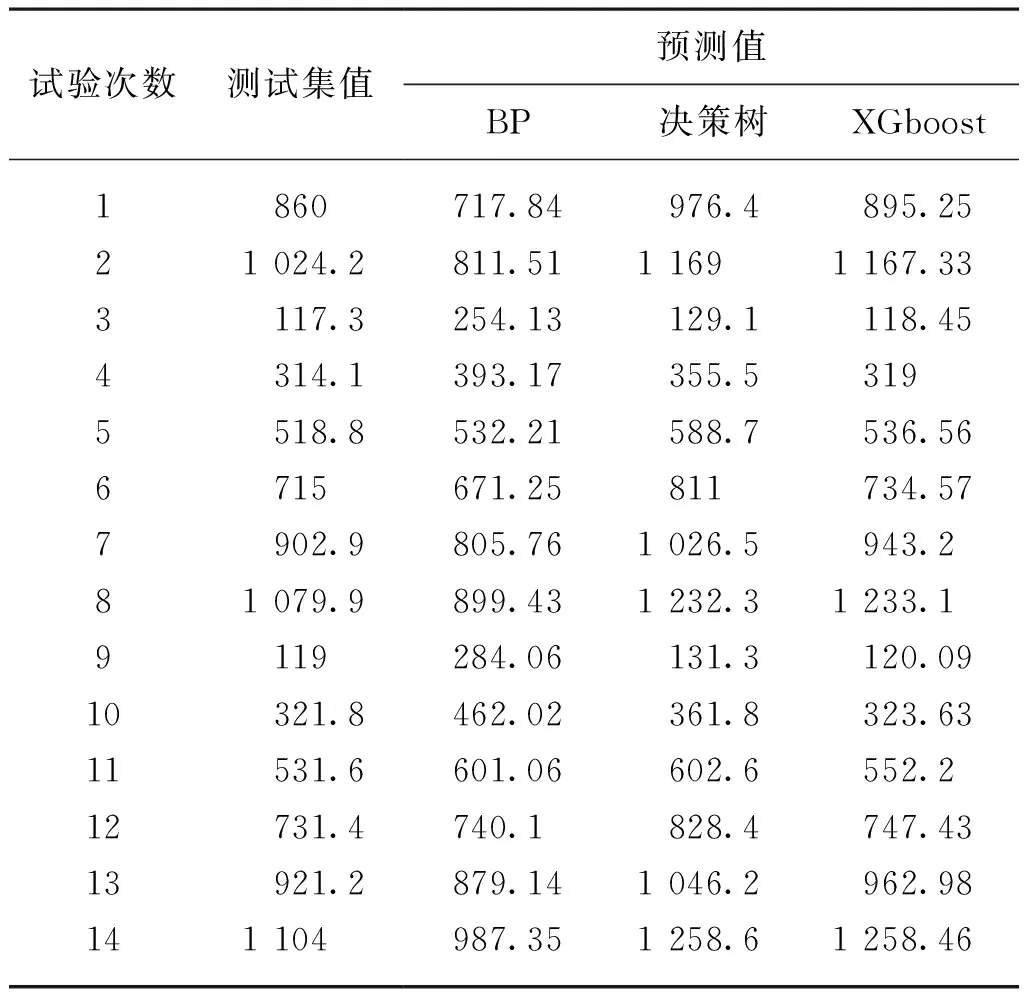
表1 模型测试集数据Tab. 1 Model test set data
4 结论
为实现超级稻精密播种,提高水稻产量,降低伤种、堵种的风险,本文以秀优5号超级稻为研究对象,进行供种理论及供种量预测的研究,以Python为算法构架,分别适用BP神经网络、决策树、XGboost的预测模型,并将模型验证结果与相关模型对比,得出以下结论。
1) 通过定量供种试验,采集周期为94次的数据集,以数据前80次为训练集,采用BP神经网络、决策树以及XGboost进行算法建模,得到训练集的准确率为0.70、1.0、1.0。
2) 应用BP神经网络、决策树、XGboost的供种量预测模型,以R2为衡量模型性能评价指标,分别为0.87、0.91、0.95。相对误差反映各模型得到的预测值与测试集值拟合效果,分别为18%、11%、5%。结果表明,XGboost模型相比其他两种模型预测效果更好,进一步地为定量供种器确定工作参数提供理论依据。
猜你喜欢
模具技术(2022年4期)2022-10-17
农业机械学报(2022年6期)2022-08-05
农业工程学报(2022年7期)2022-07-09
沈阳农业大学学报(2021年6期)2021-02-13
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
农业机械学报(2018年5期)2018-05-31
西安航空学院学报(2018年1期)2018-02-05
农产品加工(2016年16期)2016-09-27
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
