
基于深度学习的道路表面裂缝检测研究
2023-09-08 04:47李续稳张青哲
机电信息 2023年17期
李续稳 张青哲
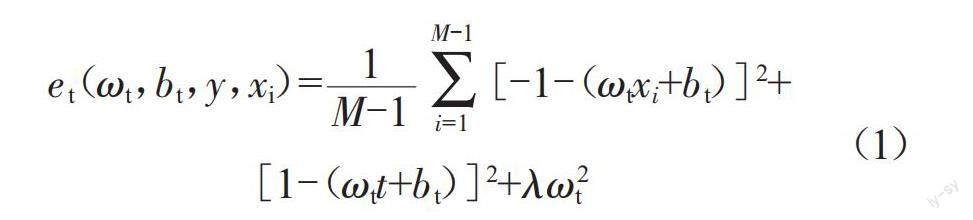
摘要:针对目前道路表面裂缝缺陷检测方法普遍存在识别率低、实时性差以及多尺度特征下检测效果不好等问题,提出一种改进的YOLOv5s算法模型。该算法引入SimAM三维带权注意力机制且不引入额外参数,在模型中融入加权双向特征金字塔进行多尺度特征融合;同时改进预测框损失函数,使得损失函数收敛更快。经过对比实验,改进后模型的裂缝检测均值平均精度提高了2.2%,准确率为90.5%,表明了模型的有效性。
关键词:深度学习;道路裂缝检测;YOLOv5s;多尺度融合;注意力机制
中图分类号:TP391.41 文献标志码:A 文章编号:1671-0797(2023)17-0027-05
DOI:10.19514/j.cnki.cn32-1628/tm.2023.17.008
0 引言
随着深度学习快速发展,具有大量参数的神经网络可以提取到更多的图像特征。张伟光等人基于卷积神经网络搭建了包含3个卷积层和2个全连接层的网络模型,通过对比实验得出结论,卷积神经网络具有更高的精度[1]。为使检测速度更快、精度更高,有学者提出SSD[2]算法。王博等人对此算法进行优化,用MobileNet网络代替SSD特征提取网络中的VGG模块,并通过特征金字塔进行融合,构建出轻量级的道路裂缝检测算法[3]。YOLO系列目标检测算法经过不断更新,检测速度和模型尺寸相比其他检测模型更占优势。J. Zhang等人为提高检测速度,用一些轻量级网络代替YOLOv4中的特征提取网络以使模型加速,减少了参数量和主干网络层数,使模型精度和速度更优,且模型更具轻量性[4]。为了提高复杂路面的识别精度,一些学者对YOLO系列算法进行了变体改进。R. Li等人使用半导体激光投射到路面裂缝上,再用摄像头采集到更容易识别的图像,将图片输进基于YOLO算法的PDNN神经网络以检测路面坑洞,该方法适用于各种天气的路面数据并能计算受损区域面积[5]。D. Ma等人基于改进的YOLO-MF和PCGAN对抗网络对路面裂缝进行计数[6],实现了较高的准确率和F1得分。彭雨诺等人提出了YOLO-lump和YOLO-crack用于提取稀疏表达的多尺度特征,能减少信息损失[7],达到了提高检测精度和响应速度的目的。本文使用YOLOv5s模型对道路裂缝进行检测,并进行了结构改进,以改善对深层特征信息的提取与利用,保证实时检测的同时提高了检测精度。
1 YOLO算法原理
1.1 目标检测
目标检测是计算机视觉领域的重要研究方向之一,目标检测主要完成三个任务:检测出图像中目标的位置且同一张图片可能存在多个检测目标;检测出目标的大小范围;对检测到的目标进行识别分类。最终输出图像中物体的类别和位置坐标。二阶段算法主要通过多个不同尺度的检测框确定目标候选区域,再进行分类回归运算。而YOLO系列则是一阶段目标检测算法,该系列算法能根据多个初始锚框一次性获得多个回归框的位置信息和分类信息,实现单阶段目标检测的网络训练。相比二阶段算法,YOLO系列算法检测速度更快。具有代表性的一阶段算法还有SSD、ATSS和基于锚点的RepPoints等。
1.2 算法结构
YOLOv5s算法有四种模型:YOLOv5s、YOLOv5sm、YOLOv5sl、YOLOv5sx[8]。优点是迁移能力强且识别速度快,对于欠实时系统,YOLOv5s算法速度快于其他二阶段检测模型。本文使用YOLOv5s网络作为基础模型,由四部分组成:输入层、主干网络层、Neck层和输出层。输入层对图像进行预处理、数据增强和自适应锚框计算。在主干层,切片操作能使网络在特征不丢失的情况下实现二倍下采样操作。而CSP结构则是受到CSPNet启发,将CSP1_X和CSP2_X分别引入到Backbone和Neck中。其中CSP1_X由X个残差块和若干卷积操作组成。SPP模块通过使用三个卷积核实现最大池化,从而满足最终输入一致性。
2 算法改进
2.1 SimAM注意力机制
本文引入SimAM注意力模块[9],这是一种轻量级即插即用模块,是受人脑注意力机制启发而提出的一种具有三维权重的注意力模型。如图1所示,在该模型中对明显表现出空间抑制效应的神经元给予更高的权重,权重通过一个能量函数来计算,如式(1)所示:
式中:ωt为权重;bt为偏移量;M为该通道上的神经元数量;i为空间维度上的索引;t和xi为输入特征的单个通道中输入特征的目标神经元和其他神经元;λ为系数,一般设置为0.000 1。
通过计算ωt、bt的解析解以及通道中所有神经元的均值和方差得到最小能量,能量越低,t神经元和其他神经元的区别越大,越重要。在识别裂缝时,SimAM模块通过测量一个目标神经元与其他神经元的线性可分离性从当前神经元中计算出三维权重,即计算每个神经元的能量函数。负责提取裂缝相关关键特征的神经元权重更高,故优先处理该类神经元与任务相关的信息,进而提高了模型检测精度。
本文将注意力机制加入YOLOv5s主干网络的Bottleneck之中,且设计了两种可行方法,如图2所示。第一种方法是将SimAM放在每个C3模块的后面,这样可以使注意力机制看到局部的特征,每层进行一次注意力運算,可以分担学习压力。第二种方法是将SimAM放在backbone部分的最末端,这样可以使注意力机制看到整个backbone部分的特征图,具有全局视野,可以加强目标特征信息的提取。经实验验证,选用第二种方法作为本文的改进方法。
2.2 BiFPN
在道路裂缝数据采集过程中,由于裂缝形状大小不同以及采集距离有远有近,裂缝输入数据的尺寸差别较大,而经过YOLOv5s主干网络中的多个C3模块处理后,图像尺寸会不断缩小1/2且底层位置信息会部分丢失,没有充分利用不同尺度之间的特征,导致网络模型的检测精度有限。
加权双向特征金字塔网络(BiFPN)[10]是一种具有高效双向特征融合、跳跃连接以及带权特征融合机制的模块,能同时得到包含高层语义信息和低层语义信息的全局特征[11],不同输入层的权重不同且权重可以根据网络自动更新,其结构如图3所示,它能保证网络最大限度地保留全局上下文特征信息,使目标检测网络提取不同尺度特征,大大提高了小目标的检测性能。BiFPN在输入节点和输出节点间加入了横向跳跃连接,不但增加了融合节点的输入,还保留了原始节点的特征信息,使得模型能融合更多特征;同时移除了单输入边没有进行特征融合的节点,简化了网络结构,减少了计算量。BiFPN可以通过重复堆叠的方式进行更多特征的融合,本文在Neck中引入BiFPN模块。
2.3 损失函数改进
YOLOv5s使用CIoU_loss作为预测框损失函数,但当CIoU_loss中宽高比为一定比例时,损失函数中的惩罚项将不再起作用,会降低模型优化速度。EIoU_loss在CIoU_loss的基础上进行改进,LEIoU计算公式如式(2)所示:
式中:LEIoU为EIoU损失函数;IoU为交并比;ρ为预测框与真实框中心点之间的距离;b和bgt为目标框和预测框中心点坐标;w和h分别为预测框的宽和高;wgt和hgt分别为真实框的宽和高;C为能同时包含预测框与真实框的最小矩形框的对角线长度;Cw为该最小矩形框的宽;Ch为该最小矩形框的高。
EIoU_loss将w与wgt、h与hgt之间的差距最小化,使损失收敛速度更快、定位效果更好。
3 模型测试和结果分析
3.1 数据集及环境
数据集的选取对模型检测结果具有重要作用,由于YOLOv5s的特征提取网络对数据进行了5次下采样,所以图像的长和宽需为32的整数倍。本文在公开的CRACK 200、CRACK 500和Bridge CRACK等數据集中经过图像清洗,最后选取了1 280张JPG格式的路面裂缝图片,数据集标签为“Crack” “Map crack”“Hole”。
为证明改进后模型的有效性,需对改进前后模型进行对比实验。将上述标签处理和预处理后的图片输入网络中进行目标识别训练和检测。实验时将模型部署到电脑端PyCharm上,使用Python3.8为编译语言,在Cuda加速和Pytorch深度学习框架下运行。本次研究的实验配置如表1所示。
3.2 评估标准
对模型的裂缝检测能力进行评估,引入了模型的评价指标。准确率P表示预测样本中正样本比例,召回率R表示预测样本中实际正样本数占所有预测样本的比例,其计算公式分别如式(3)和(4)所示:
式中:TP为正确检测出裂缝的样本数量;FP为裂缝检验出现错误的数量;FN为裂缝的未检验数量。
mAP(mean Average Precision)为多个不同类别的平均AP值,每个类别根据不同的置信度和IoU阈值,对应有不同的准确率和召回率,计算准确率和召回率构成的二维曲线图面积即得到AP值。
3.3 训练与检测
选用1 280张大小为1 024×1 024×3的图像作为总数据集,为了保证模型精度,减小泛化误差,将训练集与测试集以8:2的比例划分以进行交叉验证。在实验前需进行参数设置,初始学习率为0.01,下降学习衰减系数为0.000 5,置信度阈值IoU为0.5,批次量为15,迭代次数为200。
在预热时,YOLOv5s利用一维线性插值去更新每次迭代的学习率,当达到预设值时,再通过余弦退火算法对学习率进行不断更新。经过训练得到最优权重,将最优权重传入Detect.py文件中用于最终检测。检测结果如图4所示,可以看出该模型能准确识别出裂缝、网状裂缝和坑洞目标,初步达到预定要求。
如图5所示,经过200个迭代周期后改进YOLOv5s_
SA+BF算法对道路裂缝的检测精度逐渐收敛为90.5%,mAP值最后稳定在92.4%。
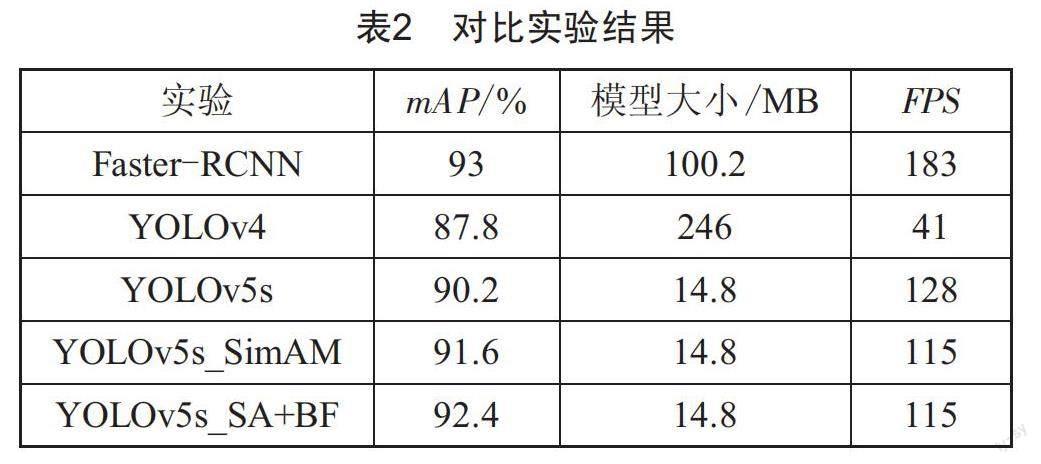
为了验证加入注意力机制后模型在复杂背景下识别不同种类裂缝的能力,与其他主流方法进行了对比实验。首先使用Faster-RCNN和YOLOv4模型对裂缝数据进行训练,再采用YOLOv5s模型和超参数设置相同的改进模型进行训练检验,在实验同时统计各个方法的检测速度和模型大小,对比实验结果如表2所示。
由表2可知,相比YOLOv4和Faster-RCNN算法YOLOv5s更具轻量性和实时性,模型仅有14.8 MB,在模型大小上更具优势。由于SimAM的无参性,改进后的模型对每张图像的推理耗时并未产生影响,每秒可处理52.6帧图片。在平均精度上,加入注意力机制后的YOLOv5s_SimAM算法比原始YOLOv5s算法精度提高了1.4%,而YOLOv5s_SA+BF相比原始算法检测精度提高了2.2%,召回率为94.5%,且检测速度没有太大区别,仍能满足实时性需求。
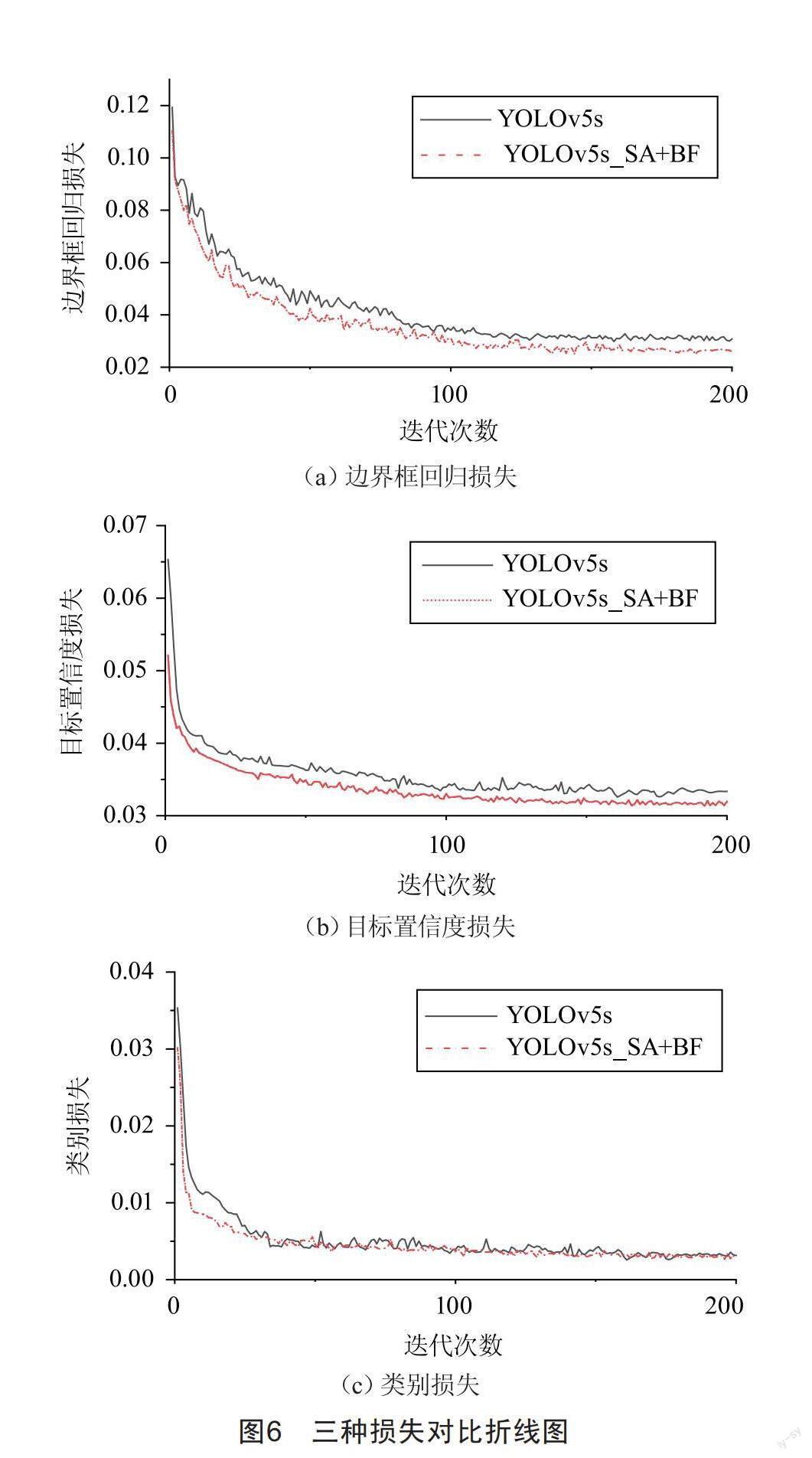
图6为验证集上测试改进后模型检测效果,由模型的回归损失、置信度损失和分类损失的变化可知,改进后的模型置信度损失和边界框回归损失更低,模型收敛速度也相对较快。YOLOv5s_SA+BF模型在200个迭代周期后,各项损失均趋于平缓,不再下降,边界框回归损失达到0.026 3,目标置信度损失为0.031 6,分类损失为0.025 1。可以看出,本文提出的改进算法在三种不同的损失上都有着不同程度的减弱,对模型具有优化作用。
4 结束语
本文提出了一种基于改进YOLOv5s的道路裂缝检测模型,即YOLOv5s_SA+BF,在识别过程中能够优化裂缝特征的提取与检测。该算法在一定程度上提高了对裂缝检测的精确度,且在不引入额外参数的同时只增加了少量推理计算,对裂缝识别速度造成的影响可以忽略不计。实验结果表明,采用该算法,道路裂缝检测的精度、召回率和平均精度均得到了提升。
[参考文献]
[1] 张伟光,钟靖涛,于建新,等.基于机器学习和图像处理的路面裂缝检测技术研究[J].中南大学学报(自然科学版),2021,52(7):2402-2415.
[2] LIU W,DRAGOMIR A,DUMITRU E,et al.SSD:Single Shot MultiBox Detector[J].European Conference on Computer Vision,2016:21-37.
[3] 王博,李齐,刘皎.一种轻量级的SSD道路裂缝检测算法[J].商洛学院学报,2022,36(4):83-90.
[4] ZHANG J,QIAN S R,TAN C.Automated Bridge Crack Detection Method Based on Lightweight Vision Models[J].Complex and Intelligent Systems,2023,9:1639-1652.
[5] LI R B,LIU C.Road Damage Evaluation via Stereo Camera and Deep Learning Neural Network[C]// 2021 IEEE Aerospace Conference,2021:1-7.
[6] MA D,FANG H Y,WANG N N,et al.Automatic Detection and Counting System for Pavement Cracks Based on PCGAN and YOLO-MF[J].IEEE Transactions on Intelligent Transportation Systems,2022,23:22166-22178.
[7] 彭雨诺,刘敏,万智,等.基于改进YOLO的双网络桥梁表观病害快速检测算法[J].自动化学报,2022,48(4):1018-1032.
[8] 邵延华,张铎,楚红雨,等.基于深度学习的YOLO目标检测综述[J].电子与信息学报,2022,44(10):3697-3708.
[9] YANG L X,ZHANG R Y,LI L D,et al.SimAM:A Simple,Parameter-free Attention Module for Convolutional Neural Networks[C]//38th International Conference on Machine Learning,2021:11863-11874.
[10] 仇天昊,陈淑荣.基于EfficientNet的双分路多尺度联合学习行人再识别[J].计算机应用,2022,42(7):2065-2071.
[11] TAN M X,PANG R M,LE Q V.EfficientDet:Scalable and Efficient Object Detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),2020:10781-10790.
收稿日期:2023-05-08
作者简介:李续稳(1999—),男,河南驻马店人,硕士研究生,研究方向:机器视觉。
通信作者:张青哲(1971—),男,陕西韩城人,博士,副教授,研究方向:道路質量控制。
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
软件工程(2017年11期)2018-01-05
智能计算机与应用(2017年5期)2017-11-08
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
