
隐私保护的拜占庭鲁棒联邦学习算法
2023-09-07 08:47李海洋郭晶晶刘玖樽刘志全
西安电子科技大学学报 2023年4期
李海洋,郭晶晶,刘玖樽,刘志全
(1.西安电子科技大学 网络与信息安全学院,陕西 西安 710071;2.暨南大学 信息科学技术学院,广东 广州 510632;3.数力聚(北京)科技有限公司,北京 100020)
1 引 言
随着社会的发展,人工智能有着越来越多的实际应用。为应对人工智能面临的数据孤岛问题,联邦学习(Federated Learning,FL)[1]应运而生。不同于传统的数据集中式机器学习,联邦学习是一种分布式机器学习架构,联邦学习系统中节点的本地训练集不出本地,节点间通过共享模型训练的中间参数进行多方协作训练得到共享的全局模型。根据节点的本地训练集特征,联邦学习可分为3种类型[2],分别是数据样本ID空间重叠较少而数据特征空间重叠较多的横向联邦学习(Horizontal Federated Learning,HFL),数据样本ID空间重叠较多而数据特征空间重叠较少的纵向联邦学习(Vertical Federated Learning,VFL)以及数据样本ID空间和数据特征空间均重叠较少的联邦迁移学习(Federated Transfer Learning,FTL)。
横向联邦学习进行一轮训练的流程如下:① 节点在本地进行模型训练,获得本地模型并将模型更新(梯度)上传至聚合服务器;② 聚合服务器首先接收各节点上传的本地模型梯度信息,然后进行聚合生成全局模型梯度,并将模型梯度信息下发至各节点;③ 节点接收全局模型梯度并以此更新本地模型。上述步骤一直循环执行,直至全局模型收敛或者达到预定义的模型迭代训练轮数。
尽管流程①中节点的本地训练集未出本地,但节点上传的中间训练参数同样会泄露隐私[3-4]。针对这一问题,国内外学者提出了许多联邦学习的隐私保护方案,这些方案通过对中间训练参数进行隐私保护来避免节点的隐私泄露。当前的隐私保护方法主要分为以同态加密(Homomorphic Encryption,HE)、安全多方计算(Secure Multi-party Computation,SMC)为代表的加密方法和以差分隐私(Differential Privacy,DP)为代表的扰动方法[5-6]。同态加密是一种无需访问数据本身便可处理数据的技术,即聚合服务器可对密文状态的模型梯度信息进行计算。然而,同态加密计算复杂,要求节点有较高计算能力,因此在当前计算力条件下,同态加密在联邦学习中的实用性不高。安全多方计算可在不泄露原始数据条件下实现全局模型的无损聚合。然而,安全多方计算通常需要复杂的流程设计,有较高的额外计算成本,因此效率不高。差分隐私通过添加噪声来扰动原本极易识别的数据,避免数据的敏感信息泄露,且所添加的噪声不会破坏数据原本的特征[7]。在每一轮联邦学习训练中,首先将节点的本地模型梯度信息进行差分隐私处理,然后再将其发往聚合服务器,从而防止节点隐私泄露。基于差分隐私的横向联邦学习算法主要目标是在精度损失可接受范围内实现隐私预算最小[8]。WEI等[9]提出CRD(Communication Rrounds Discaunting)算法,证明在给定隐私预算时存在一个最优的训练轮数,可在满足差分隐私的同时提升模型性能。差分隐私通过牺牲部分模型精度来实现隐私保护,实现简便,计算开销低,是一种实用的隐私保护技术。
由于联邦学习的本质是一种分布式机器学习,因此易受拜占庭节点攻击。拜占庭节点攻击的常用手段是发起投毒攻击破坏模型的完整性与可用性,致使联邦学习系统的鲁棒性极低。SHEJWALKAR等[10]提出一种模型投毒攻击,在生成恶意梯度时,使其方向同正常模型梯度方向相反,然后将模型梯度的长度设置为系统防御机制可检测的门限范围内的边缘值,以使恶意梯度的攻击能力最大化。针对拜占庭节点的防御问题,文献[10]中总结了以Krum、Multi-Krum、Buylan等为代表的统计学分析方法,其核心思路为:首先基于模型更新的某种数学指标进行安全聚合,例如中位值、均值等;文献[11-12]这类基于变分自编码器(Auto-Encoder,AE)识别恶意模型参数的机器学习方法,其核心思路为:首先聚合服务器预先在本地预训练一个自编码器模型,然后正式训练过程中基于自编码器计算各节点模型更新的重构误差,以此重构误差判断模型更新的可靠性;文献[13-15]这类基于生成对抗网络(Generative Adversarial Network,GAN)的防御方法,其核心思路为:首先基于生成对抗网络补足异常检测模型训练集,然后基于异常检测模型进行拜占庭检测;文献[13-14,16]这类通过验证模型参数精度来检测恶意模型参数的方法,其核心思路为:首先聚合服务器利用根数据集在本地训练一个同联邦学习任务一致的本地模型,然后基于节点提供的模型,更新和聚合服务器本地训练得到的模型,以更新的余弦相似度计算节点的信任值。无论是哪一类防御方法,其基本策略皆为对节点中间训练参数的某项数据指标进行相互比较,从而找出离群值。而这样的策略存在两个问题:① 数据非独立同分布。真实的横向联邦学习场景中节点间的数据是参差不齐的,如果节点训练数据差别过大,那么节点的中间训练参数的区别也会较大,则此类节点的中间训练参数容易被系统检测机制误判为恶意数据。因此,现有的拜占庭鲁棒算法一般不能直接用于数据非独立同分布的联邦学习环境。② 隐私保护环境。不论是加密还是扰动的隐私保护方法,其基本目的都是隐藏节点中间训练参数的数据特征从而破坏其可分析性。以同态加密为代表的加密方法使得节点中间训练参数的数据特征完全隐藏,致使检测机制无法对密文进行分析;以差分稳私为代表的扰动方法使得节点中间训练参数的数据特征部分隐藏,这使检测机制执行难度增加。因此,现有的拜占庭鲁棒算法一般不能直接用于隐私保护的联邦学习环境。
针对上述问题,文中提出一种可在数据非独立同分布和隐私保护环境下拜占庭鲁棒的联邦学习算法。首先,节点对本地梯度进行隐私保护处理;然后,聚合服务器将节点的历史模型更新依次输入自编码器和长短期记忆(Long Short-Term Memory,LSTM)模型,比较长短期记忆模型输出的预测值和实际值的差距以检测拜占庭攻击;最后,聚合服务器根据评估结果进行全局梯度聚合。针对隐私保护需求,所提算法采用差分隐私技术为节点的本地梯度进行隐私保护处理。针对数据非独立同分布环境下的拜占庭鲁棒需求,所提算法仅对节点上传的历史梯度进行纵向比较,以此对节点的可信度进行评估,不涉及节点间的横向比较,因此不受数据非独立同分布环境的影响。
2 支持隐私保护的拜占庭鲁棒联邦学习算法
2.1 系统模型与假设
系统模型如图1所示,分为节点端和服务端2个部分。服务端由预处理模块、数据检测模块和全局聚合模块组成。预处理模块负责注册节点的基本信息,以及在联邦学习正式开始前进行模型预训练。数据检测模块负责更新和维护历史模型更新信息(即节点上传的本地梯度),并进行拜占庭检测。全局聚合模块则根据数据检测模块的检测结果,选择可信本地模型进行聚合生成全局梯度。
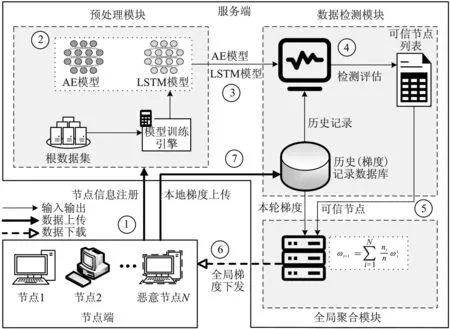
图1 系统模型
节点端由正常节点和拜占庭节点共同组成,这两类节点都持有本地训练集。在联邦学习训练中,正常节点遵从联邦学习协议参与训练,而拜占庭节点则伺机发起投毒攻击破坏联邦学习训练过程。根据恶意梯度的生成方式不同,文中将拜占庭节点的攻击方法分为两类:① 随机生成与全局梯度同维度的恶意梯度;② 在本地梯度的基础上添加一个反方向的干扰向量。此外,本方案中的拜占庭节点可选择从第5轮或第10轮(此设置仅为观察精度降低的攻击效果)开始发起攻击。
为进一步描述所提方案,作如下系统假设:
(1) 横向联邦学习系统中共有N个节点,用集合{P1,P2,…,PN}表示;
(2) 聚合服务器诚实且好奇,且持有根数据集,其与节点的本地训练集类别一致,即均为MNIST/CIFAR10数据集;
(3) 拜占庭节点不在第1轮训练就发起攻击。
图1所示的联邦学习系统进行一轮协作训练的步骤①~⑦的说明如下:
阶段1 注册阶段。
① 节点向聚合服务器发起注册请求并提交必要信息,例如本地训练集的数据量。
② 聚合服务器响应节点请求,协助节点商定模型结构、相关参数设置等。
阶段2 预处理阶段。
③ 预处理模块开始预训练得到自编码器和长短期记忆模型并将其发送给数据检测模块。
阶段3 正式训练阶段。
④ 首先节点开始本地训练得到本地梯度,然后将本地梯度用差分隐私处理后上传聚合服务器,其中差分隐私使用的是(ε,δ)差分隐私,采用高斯机制(即添加高斯噪声)实现。
⑤ 首先聚合服务器接收节点的本地梯度,然后数据检测模块进行拜占庭检测,生成可信节点列表并将其发送给全局聚合模块。
⑥ 首先全局聚合模块选择可信节点所对应的本地梯度,并根据其本地训练集的数据量进行加权聚合得到全局梯度,然后将其下发可信节点。
⑦ 首先节点接收全局梯度并更新本地模型,然后返回步骤④,开始新一轮训练。
上述预处理阶段步骤③中提到的自编码器是一种无监督机器学习,其输入层神经网络数量等于输出层神经网络数量,可用于特征提取和异常检测。长短期记忆模型是一种时间循环网络,可解决一般的循环神经网络存在的长期依赖问题,用于处理序列数据。自编码器[17]和长短期记忆模型[18]在多种场景下都得到了广泛的应用。
2.2 所提算法
所提方案的具体流程分为3个阶段:注册阶段、预处理阶段和正式训练阶段。下面对各个阶段进行详细阐述。

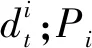
① ift==1 then
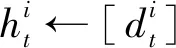
③ else
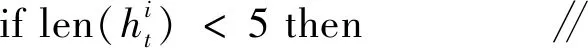
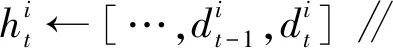

⑧ end if
⑨ end if
2.2.1 注册阶段
此阶段主要任务是节点在横向联邦学习系统内完成注册,聚合服务器同节点协商网络模型结构等训练细节。
2.2.2 预处理阶段
在预处理阶段,聚合服务器首先收集差分时间序列数据集(Differential Time Series Data,DTSD),然后利用差分时间序列数据集先训练自编码器模型,再训练长短期记忆模型,最后确定门限参考列表,为正式训练阶段提供准备。
算法2Pi第t轮信任度评估算法。
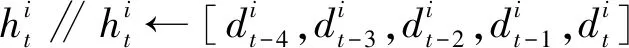
threshold ∥一级门限,对梯度每一层进行判断
tolerance_tn ∥可信节点异常的模型层数的最大值
tolerance_htn ∥半可信节点异常的模型层数的最大值
输出:Pi的信任度。∥分为:可信节点TN,半可信节点HTN,不可信节点AN
① fork←1~4 do
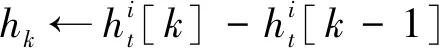
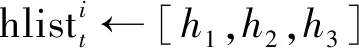
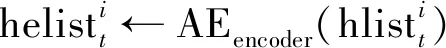
⑤ origin←AEencoder(h4)
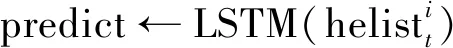
⑦ gradient_euler←‖origin-predict‖ ∥计算L2距离Pi的信任度划分
⑧ ayer_state←0 ∥表示梯度中异常的层数
⑨ for gradient_euler in gradient_euler do
⑩ if layer_euler>threshold then
收集差分时间序列数据集:
(1) 聚合服务器创建初始模型(注册阶段所协商的模型),用根数据集进行n轮模型训练,期间收集训练过程中产生的模型梯度,得到时序梯度数据集G,其中G=
(2) 针对G中的每一个梯度,聚合服务器计算其L2范数,选取其中值最大的m个L2范数,将其均值作为梯度裁剪的阈值c并向各节点广播;
(3) 聚合服务器根据ct=gt/max(1,‖gt‖2/c)对G中的梯度进行裁剪,得到数据集C,其中C=
(4) 聚合服务器根据dt=ct+1-ct计算C中相邻梯度的差值,得到差分时间序列数据集DTSD,其中DTSD=
获取自编码器模型:
聚合服务器首先创建自编码器模型,用差分时间序列数据集作为训练集来训练自编码器模型,然后保存模型。
获取长短期记忆模型:
(1) 聚合服务器用自编码器模型的编码器模块将差分时间序列数据集进行编码处理,得到数据集DTSD_E。
(2) 聚合服务器用长度为4、步长为1的滑动窗口(此处滑动窗口的参数是经验值,在实际情况中也可取其他的值)在DTSD_E上进行采样,生成数据集DTSD_E_L,选取其中前80%的数据作为训练集Data_Train,剩余20%的数据作为测试集Data_Test。
(3) 聚合服务器首先创建长短期记忆模型,用Data_Train训练长短期记忆模型,然后保存模型。
确定门限参考列表:
将Data_Test输入长短期记忆模型,计算每1条预测数据和实际数据的距离(欧式距离),得到门限参考列表euler_dis。在正式训练阶段选取euler_dis中最大的tm(虚门限)个值,计算其均值作为实际门限值。
2.2.3 正式训练阶段
正式训练阶段节点端与服务端的工作流程如下所示:
节点Pi:
(1)Pi设置相关模型参数;
(2)Pi开始第t轮训练,收集本轮训练的模型梯度gt;
(3)Pi对gt进行裁剪,得到ct,其中ct=gt/max(1,‖gt‖2/c);
(4)Pi对ct进行差分隐私处理,得到dt,其中dt=ct+N(0,σ2);
(5)Pi将dt上传聚合服务器;
(6) 若t<5,返回步骤(2),开始新的一轮训练;否则,进入下一步;
(7) 接收全局梯度gradient_globalt并更新本地模型;
(8) 返回步骤(2),开始新的一轮训练。
服务端:
(1) 聚合服务器接收节点第t轮上传的dt;
(2) 聚合服务器更新节点的历史记录ht(详见算法1),其记录的是节点上传的本地梯度信息;
(3) 若t<5,则返回步骤(1),开始新的一轮训练;否则,进入下一步;
(4) 聚合服务器根据ht、自编码器模型以及长短期记忆模型评估节点的可信度(详见算法2);
(5) 聚合服务器选取可信节点上传的dt计算全局梯度gradient_globalt(详见算法3);
(6) 聚合服务器向不可信节点发送假数据,向其余节点发送gradient_globalt;
(7) 返回步骤(1),开始新的一轮训练。
在上述正式训练阶段,服务端使用了3个算法。算法1是节点历史模型记录(节点历史模型记录以双端队列形式存储)更新算法,其中步骤①~⑤表示历史记录条数小于5时新的记录直接进入队尾,步骤⑥和⑦表示历史记录条数大于等于5时新的记录进入队尾的同时最早进入的记录需要弹出队头,然后输出节点的新历史模型记录。算法2给出了节点信任度评估方法,其中步骤①~⑦处理节点的历史记录,首先计算历史记录中相邻梯度的差值,得到一个长度为4的差值列表,再用自编码器模型将此列表中的每条数据进行编码处理,然后将此列表的前3条数据作为长短期记忆的输入得到预测值,最后计算此预测值和列表中第4条数据的欧氏距离gradient_eurler;步骤⑧~行将gradient_eurler中每层的值同各自的门限进行比较以得出每一层的异常状态,然后根据总的异常层数判断节点此时的可信度。算法3给出了全局模型聚合方案,以节点的本地训练集的数据量为权重,对所有可信节点的本地梯度进行加权聚合得到全局模型梯度。
算法3全局梯度聚合算法。
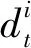
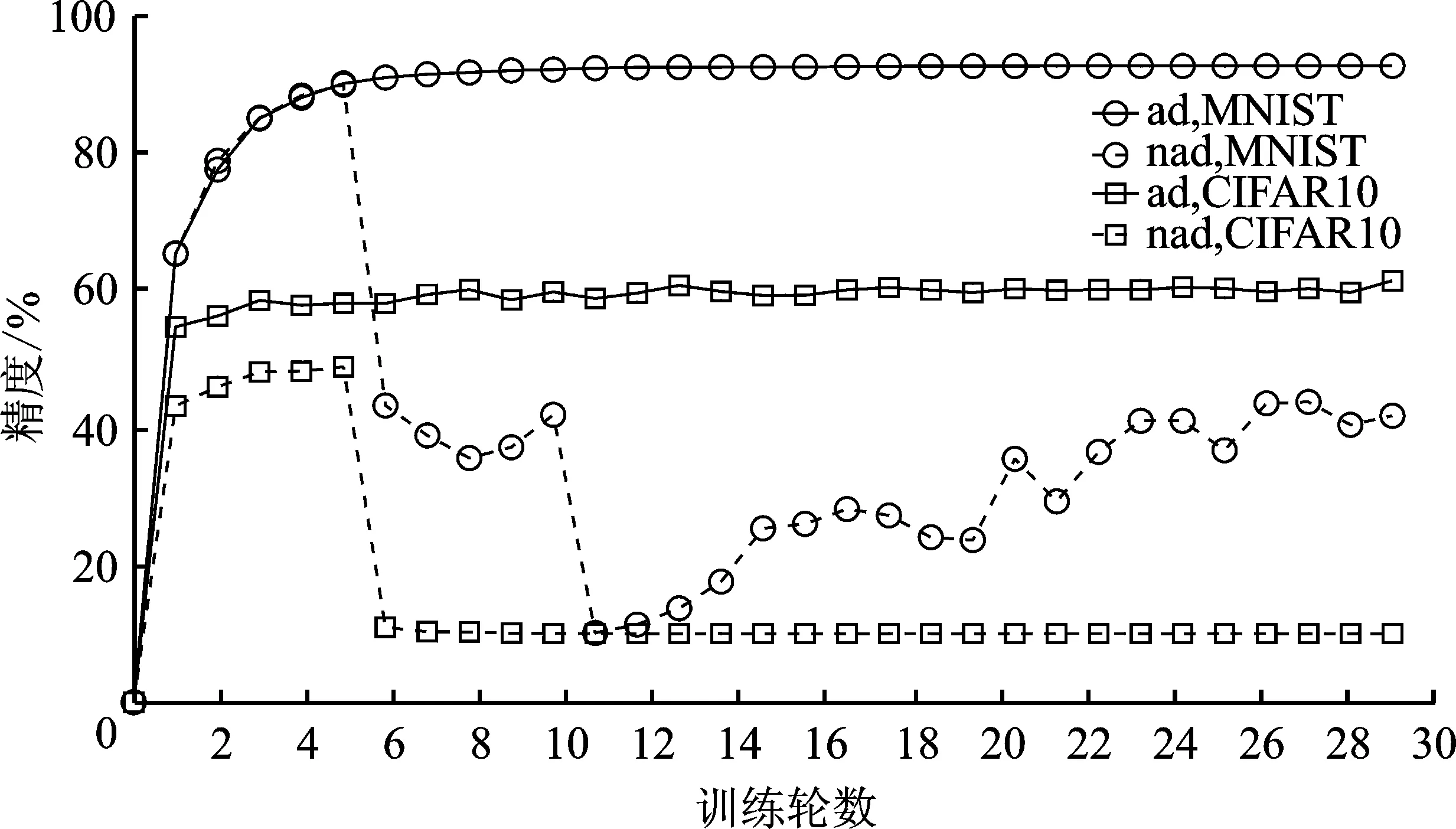
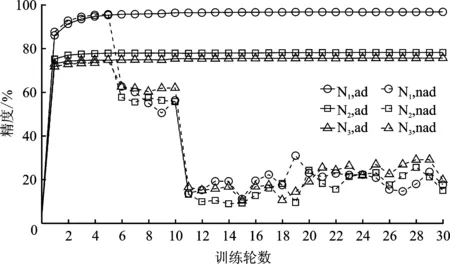
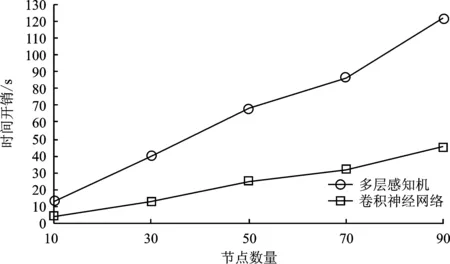
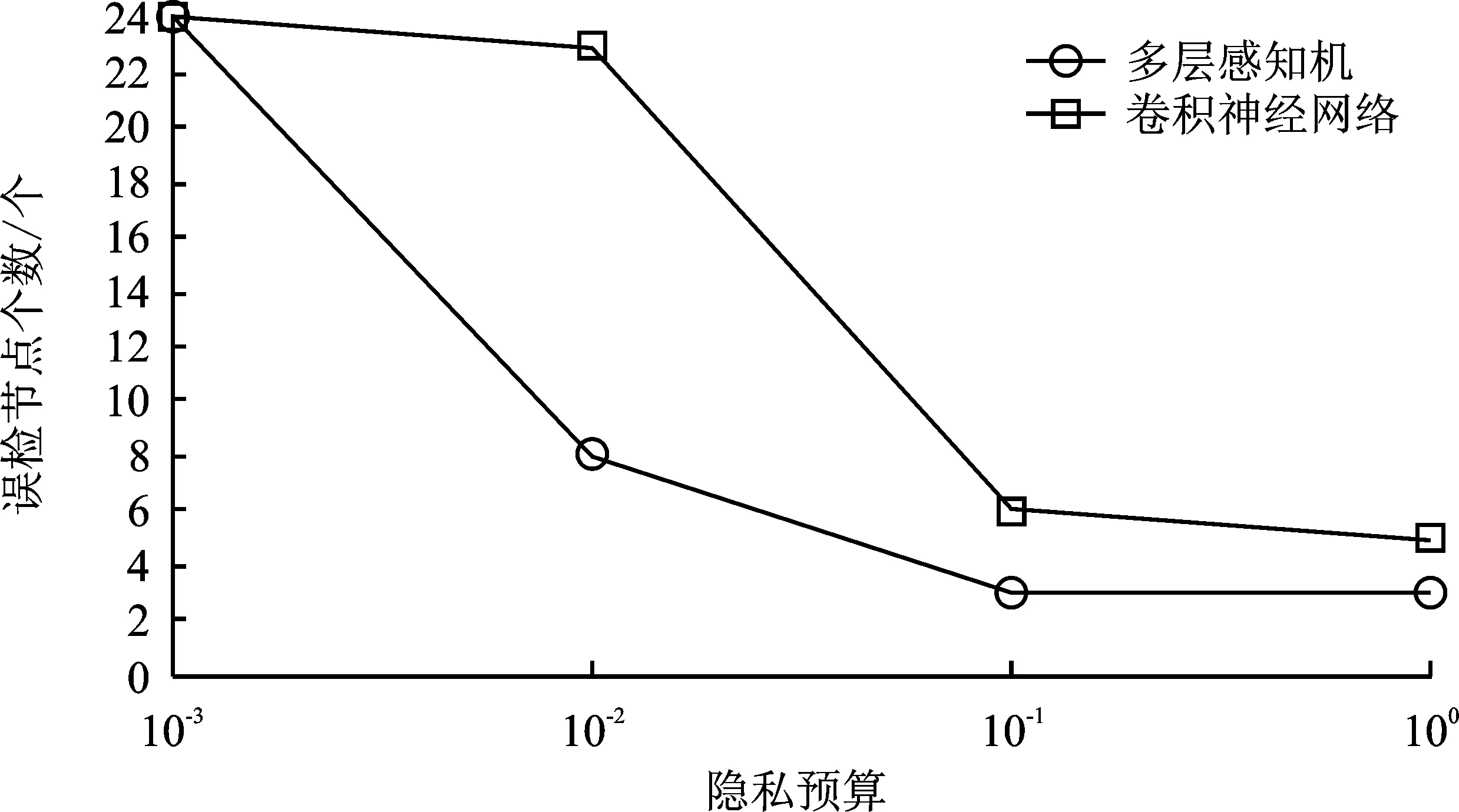
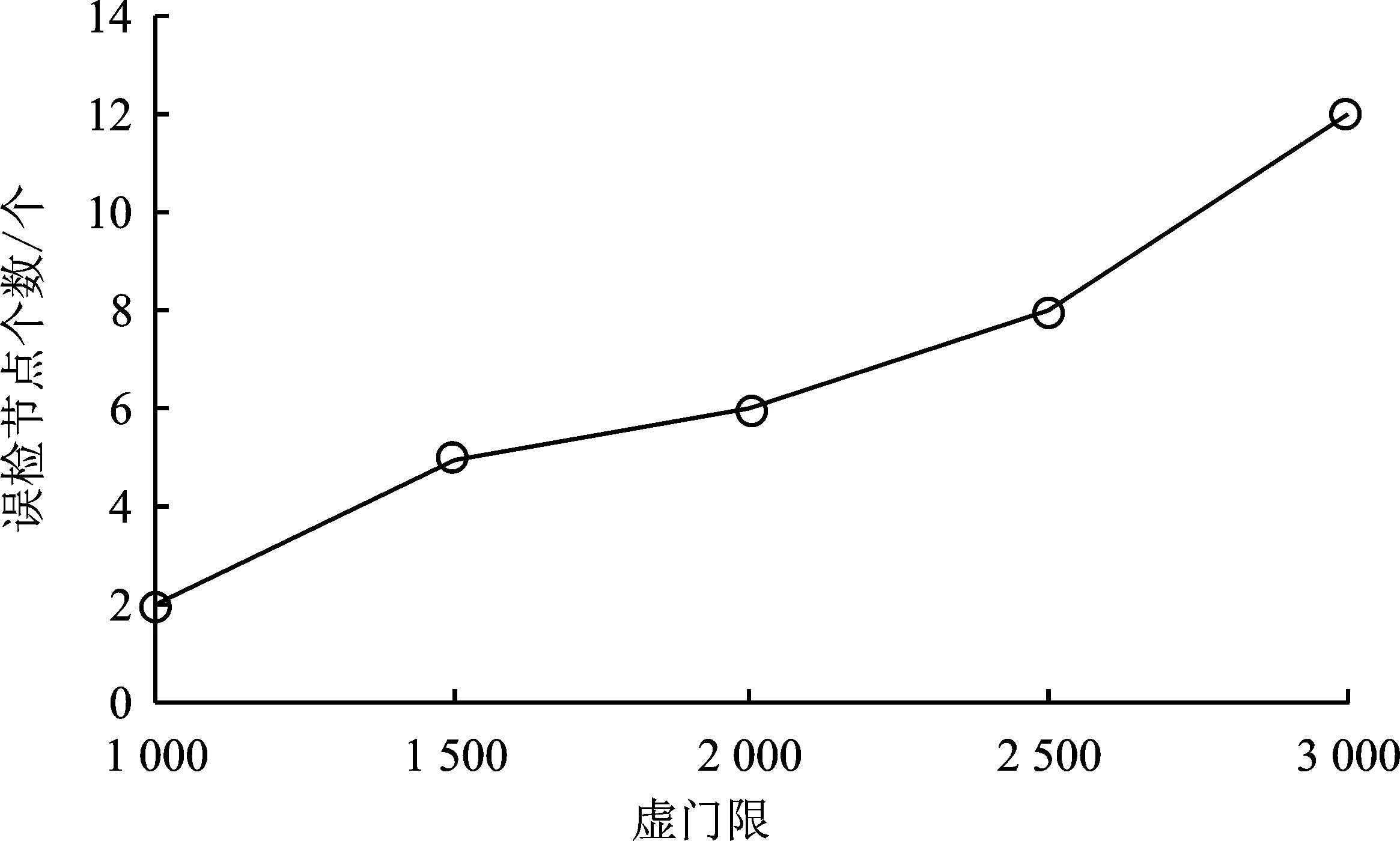
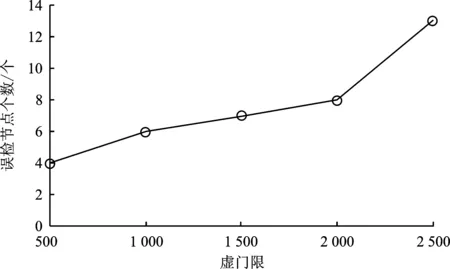
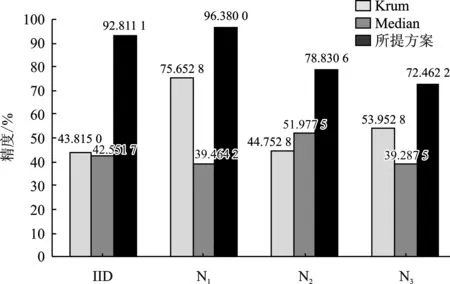
经算法2筛选后有m个节点可信,1 输出:第t轮的全局梯度gradient_globalt ③ return gradient_globalt 为验证所提方案的有效性,文中开展了一系列的仿真实验,下面首先介绍总体的实验设置,然后给出实验结果并对其进行分析。 本实验所采用的平台如表1所示,实验所涉及符号的说明如表2所示。联邦学习系统中节点的本地训练集采用MNIST/CIFAR10数据集,数据分布分为独立同分布(Independent and Identically Distributed,IID)和非独立同分布(Non-Independent and Identically Distributed,Non-IID)两类。其中,通过在MNIST/ CIFAR10数据集中随机、均匀地选取一定数量(文中选取500、1 000条数据)的数据实现节点数据独立同分布的联邦学习环境,而节点数据非独立同分布的联邦学习环境则采用文献[19]所提方法实现。具体方法如表3所示。节点的本地训练模型采用多层感知机(Multi-Layer Perceptron,MLP)和卷积神经网络(Convolutional Neural Network,CNN)这两类模型,其中多层感知机模型结构为[784,256,10],卷积神经网络自定义模型包含2个卷积层、2个池化层。 表1 实验平台表 表2 对工艺库的迁移性评估 表3 非独立同分布数据划分 仿真实验的基础设置为:节点数量u=30,训练轮数epoch=30,隐私预算epsilon=2,拜占庭节点比例mn=0.2。实验结果的主要衡量指标为聚合服务器进行数据检测的时间开销、全局模型精度(由聚合服务器用完整的MNIST/CIFAR10测试集测试得出)以及数据检测模块的性能(误检率)。 首先进行可行性分析。图2给出了节点数据独立同分布且训练模型为卷积神经网络模型的条件下,分别选择MNIST和CIFAR10作为训练集的全局模型精度随训练轮次的变化过程,其中ad表示聚合服务器端部署了所提方案,nad则表示无异常检测。从图2可以看出,在第5轮和第10轮全局模型的精度出现大幅度降低,这是因为拜占庭节点分为两批发起攻击,其中一批从第5轮开始发起攻击,另一批从第10轮发起攻击。可以看出,如果服务器部署了文中所提方案,则在第5轮与第10轮迭代后全局模型精度并未出现波动,在整个训练过程中全局模型的精度均高于未部署所提方案时全局模型的精度。此外,实验日志显示,数据检测模块及时准确地检测出了联邦学习系统中所有拜占庭节点。因此,所提拜占庭节点检测算法在节点数据独立同分布条件下,可以准确地检测出系统中的拜占庭节点。图2中训练集为CIFAR10时所得全局模型的精度低于训练集为MNIST时所得全局模型的精度,这是由CIFAR10数据集特性以及本实验所采用的简单卷积神经网络模型模型结构所致。在相同条件下,未部署所提方案的CIFAR10训练集训练得到的全局模型精度更低。 图2 数据独立同分布条件下卷积神经网络模型的精度 图3给出了MNIST数据集作为训练集,训练模型为卷积神经网络模型,节点数据非独立同分布条件下全局模型精度随训练轮次的变化过程。从图3可以看出,不同非独立同分布条件下全局模型的最终精度存在一定的差异。然而,相同非独立同分布条件下,未部署所提异常检测机制时在第5轮和第10轮训练结束后全局模型均出现了精度突然降低的现象。因此,所提方案可在隐私保护且节点数据非独立同分布条件下准确地检测出系统中的拜占庭节点。图3中节点数据分布为N2和N3两种情况时得到的全局模型精度低于节点数据分布为N1时得到的全局模型精度,这是因为N1划分主要体现了节点的本地训练样本数量的不同,而单个节点所拥有的数据较为完备,因而其精度远高于另外两种划分时得到的全局模型精度。 图3 数据非独立同分布条件下卷积神经网络模型的精度 接下来进行所提方案的计算开销分析。图4给出了MNIST数据集作为训练集,训练模型为卷积神经网络模型,节点数据独立同分布条件下数据检测模块进行异常检测的时间开销随节点数量变化的过程。从图4可以看出,不论是以多层感知机还是卷积神经网络模型作为训练模型,异常检测的时间开销随着节点数量增加大体呈线性增长的态势,多层感知机作为训练模型时单个节点的检测耗时在1~2 s之间,卷积神经网络模型作为训练模型时单个节点的检测耗时在1 s以内。 图4 异常检测的计算开销 为了分析隐私预算对数据检测模块的性能影响,图5给出了节点数据独立同分布,节点总数u=30,拜占庭节点比例mn=0.2条件下数据检测模块在不同隐私预算下的误检节点个数。从图5可以看出,当隐私预算为0.000 1时,误检节点总数为24,即全部正常节点均被误判为恶意节点,数据检测模块完全失效。随着隐私预算逐渐增大,数据检测模型误检的节点个数也逐渐减小。这是因为隐私预算越小,隐私保护越强,但数据可用性越弱,因此误检率高。 图5 隐私预算对异常检测的影响 采用虚门限tm替代实际门限值以给出更具体的门限设置参考。为了分析虚门限对数据检测模块的性能影响,图6和图7给出了节点数据独立同分布条件下,分别以多层感知机和卷积神经网络模型作为训练模型时,数据检测模块在不同虚门限下的误检节点个数。从图6和图7可以看出,随着虚门限的增加,数据检测模块误检节点数量随之增加。这是因为虚门限越大,实际门限值越小,对数据的要求更加严格,因此误检情况会增加。 图6 多层感知机模型下虚门限对异常检测的影响 图7 卷积神经网络模型模型下虚门限对异常检测的影响 为了分析拜占庭节点比例对数据检测模块的性能影响,图8给出了节点数据独立同分布条件下,不同拜占庭节点比例对应的联邦学习环境的全局模型的最终精度。从图8可以看出,随着拜占庭节点比例从0.2增加至0.8,全局模型的精度几乎未变,且实验日志显示全部拜占庭节点一旦发起攻击便被数据检测模块识别,因此所提方案不受拜占庭节点比例的影响。其中,尽管正常节点数量在减少,然而全局模型精度却基本保持不变。这是因为在实验的节点数据独立同分布设置下,单个节点分配的数据较多,仅需要少数节点甚至仅仅单个节点所训练的模型精度就已近乎收敛。 图8 拜占庭节点比例对异常检测的影响 同现有的拜占庭鲁棒联邦学习算法相比,所提算法具有可在数据非独立同分布和隐私保护环境下执行的优势,为验证上述优势,选取Krum[20]和Median[21]这两个经典的方案进行对照实验。设置如下两个实验场景:①场景1:节点上传数据为密文(文中使用差分隐私技术)、节点数据独立同分布、本地训练模型为卷积神经网络模型,用以分析本方案与对比方案在隐私保护环境中的有效性;②场景2:节点上传数据为明文、节点数据非独立同分布(文中使用N1、N2和N3这3种划分方式),本地训练模型为卷积神经网络模型,用以分析本方案与对比方案在数据非独立同分布环境中的有效性。 图9为所提方案与Krum和Median的对照实验结果。在场景1中,所提算法的全局模型精度达到92%,而Krum和Median聚合方案的全局模型精度最高没有超过50%。主要原因是Krum和Median只适用于数据以明文形式传输的环境,而此时数据是经过差分隐私处理的密文数据,导致Krum和Median在一定程度上失效。所提算法利用自编码器模型对节点相邻两轮的本地模型梯度的差值进行编码(提取特征),而差分隐私处理后的模型参数只损失部分精度,仍有可用性,因此数据的内在特征基本不变,所以自编码器对原始数据和经过差分隐私处理的数据进行编码的结果差别不大。在场景2中,所提算法的全局模型精度仍远远高于Krum和Median的全局模型精度,例如数据分布为N1时,所提算法的全局模型精度达到96.38%,而Median的全局模型精度只有40%左右。主要因为Krum和Median本质上是在众多数据之间进行横向比较,当节点数据非独立同分布时,节点上传的数据间的区别比较大,原本正常的数值此时容易被误判为离群值。所提算法在设计之初便是基于节点历史数据的角度(纵向比较)考虑,一个节点上传的数据是否恶意仅与自己的历史数据有关,同其它节点无关,因此可以有效解决数据非独立同分布的问题。 图9 对照实验结果 文献[22]和文献[23]也在隐私保护场景下提出各自的拜占庭鲁棒算法,因为这两个算法和所提算法的隐私保护机制不同,因此仅从理论角度将其与本方案进行对比分析。文献[22]首先利用掩码加密模型更新信息,然后基于可验证的秘密共享协议计算量化的秘密值之间的距离,以此距离值进行异常检测。而本方案计算简单,且基于差分隐私的隐私保护方案比基于掩码加密的隐私保护方案更有普适性,所提算法可运行在任意基于差分隐私的隐私保护环境下。文献[23]基于加法同态加密和安全两方计算保护隐私,假设存在两个非共谋服务器且存在根数据集,服务器首行基于此根数据集进行同步训练,然后服务器计算节点上传的模型更新和服务器本地模型更新的汉明距离进行异常检测。文献[23]本质是对各节点上传的模型更新信息进行横向比较,不适用于节点数据非独立同分布的联邦学习环境。而本方案的执行无需依赖同态加密这类高计算复杂度的运算过程,且本方案可在节点数据非独立同分布的环境下有效检测出拜占庭节点。 本方案提出一种可在隐私保护和数据非独立同分布环境下拜占庭鲁棒的联邦学习算法。其首先采用差分隐私技术对模型梯度进行隐私保护处理,然后基于节点的历史数据对节点进行信任度评估,最后聚合服务器根据评估结果对可信节点的数据进行加权聚合,得到全局模型梯度。不同于以往的拜占庭鲁棒算法需要对系统中各节点间的本地梯度进行相互比较,所提算法仅对节点的历史数据进行纵向比较,可应用于数据非独立同分布环境,且不受拜占庭节点数量的影响。实验结果表明,在拜占庭节点占比为20%~80%的联邦学习环境下,所提算法对拜占庭节点进行检测的误检率和漏检率均可达到0%,其中检测模块对单个节点进行检测的平均耗时约为1 s,并且检测模块的总耗时随着正常节点数量的增加呈线性增长的态势。然而,文中所提拜占庭检测算法存在冷启动问题,还有待优化。 下一步可从提高拜占庭检测性能和降低系统假设限制这两个方面进行研究。在第一个方面,可考虑选用性能更好的特征提取工具替换自编码器,例如变分自编码器;还可考虑选用更好的序列预测工具替换长短期记忆模型,例如长短期记忆模型的变体循环门单元(Gated Recurrent Unit,GRU)。在第二个方面,可考虑基于生成对抗网络生成根数据集;还可考虑在模型预训练时选用同联邦学习训练集同类型的已有数据集,例如两者皆为语音数据集、图像数据集等。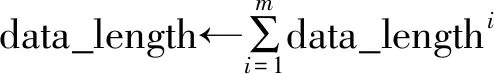
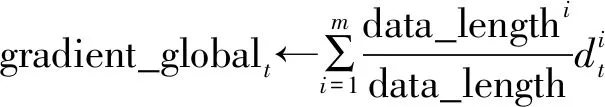
3 实验分析
3.1 实验设置


3.2 结果分析

4 结束语
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
数学物理学报(2021年6期)2021-12-21
内蒙古民族大学学报(社会科学版)(2020年1期)2020-11-03
应用数学(2020年2期)2020-06-24
数学年刊A辑(中文版)(2018年2期)2019-01-08
金桥(2018年4期)2018-09-26
中学历史教学(2018年1期)2018-04-04
古代文明(2016年1期)2016-10-21
凤凰生活(2016年2期)2016-02-01
