
人工智能生成内容(AIGC)在虚拟现实交互影像中的应用与探索
2023-09-07 05:28赵宇
现代电影技术 2023年8期
赵 宇
北京师范大学艺术与传媒学院,北京 100875
20 世纪50 年代,人工智能(AI)开始了早期萌芽,之后经历了不断发展和沉淀积累,至2010年前后出现了突飞猛进的进步。人工智能在自然语言处理(NLP)和语音识别方面开始走向应用,通过深度学习(DL)和循环神经网络(RNN),实现了语音识别、机器翻译、文本生成等功能[1]。2022 年,随着OpenAI 发布的ChatGPT 大模型面世,作为人工智能技术浪潮的一部分,深度学习算法不断迭代,人工智能生成内容百花齐放。其中,人工智能在与影视的结合中,不断创新探索、出奇出新。2023 年2 月,纽约举办了一场人工智能电影节,艺术家们使用Midjourney 制作出了极具想象力的影像作品,以及使用神经辐射场(Neural Radiance Fields, NeRF)技术将2D 照片变成3D 虚拟影像。2023年2月,日本Netflix 也推出了全球首例使用AIGC 制作的动画短片《犬与少年》,小冰日本分公司rinna 负责动画场景部分的AI 制作,Production I.G 与WIT STUDIO 共同协力完成[2]。该动画中的所有场景和人物都是通过人工智能自动生成,这也标志着人工智能与影视的结合不局限在实验阶段,而逐步推向了市场,影视的类型也渐渐多样化。人工智能与虚拟现实(VR)、增强现实(AR)、混合现实(MR)等技术的结合也在探索和创新中。
1 人工智能的技术原理及其在虚拟现实领域的应用场景
虚拟现实作为一种计算机图形模拟真实世界、创造想象世界的技术,为观看者提供了一种新的全景互动体验。它由沉浸式显示和沉浸式交互组成,通过计算机图形学(CG)和3D 成像来显示图像信号,通过动作捕捉采集交互动作并使用机器视觉系统进行交互的判断决策,为体验者提供沉浸式交互需求的3D 实时影像数据[3]。其中成像显示与交互之间相互作用,图像显示交互反馈,交互数据输入图像之中。显示系统一般为头戴式显示器,通过屏蔽现实世界,直接向用户的眼睛显示图像,从而营造一种沉浸感。除了视觉的全部接管,也在听觉方面增强了体验者的沉浸感,使用空间设计让体验者从不同方向听到声音。触觉方面则增加了反馈装置,利用物理感觉来模拟触摸,与虚拟世界中的物体互动来创造一种沉浸感。
人工智能涵盖机器学习(ML)、深度学习(DL)等技术,能够对问题做出连贯和智能的反应[4]。这项技术主要依赖于高级编程,旨在让机器像人类一样回答问题和做出决策。人工智能的发展起始于20世纪50 年代,但直到最近几十年,由于计算能力的提升、大数据可用性以及深度学习算法的引入,人工智能取得了显著的进步。人工智能在虚拟现实和增强现实中的应用也备受瞩目,实现令人惊叹的虚拟场景和角色的同时,还能进行情感建模,实现多种形式的交互体验,且不仅限于简单的触碰和控制,而是多模态的沉浸式互动[5]。人工智能的介入使得虚拟现实和增强现实有了更加生动、逼真、个性化的环境,为用户提供了前所未有的沉浸式互动体验。
作为一种结合人工智能和图形内容的技术,AIGC 旨在提升图形设计、内容创作和视觉效果的质量与效率,以大数据、算法模型和算力为基本前提保障发挥巨大作用[6]。2022 年中国信息通信研究院和京东探索研究院在《人工智能生成内容(AIGC)白皮书》中将AIGC 定义为“既是一类内容,又是一种内容生产方式,还是用于内容自动化生成的一类技术集合”[7]。
AIGC 通过算法和数据驱动,利用计算机视觉(CV)、机器学习(ML)、自然语言处理(NLP)和生成式对抗网络(GAN)等领域的技术,实现对图形和内容的智能处理和生成。其核心目标是通过人工智能辅助,提供更快速、更精确、更创新的图形和内容创作工具和方法。它可以应用于各种领域,包括动画制作、电影特效、游戏开发、虚拟现实和增强现实等。借助AIGC 技术,创作者可以更高效地完成复杂的视觉效果和内容创作任务,同时也能够拓展创作的想象力和创新性。
1.1 角色设计
在虚拟现实和增强现实领域,通过算法和深度学习,AIGC 能够从海量角色数据中提取出有用的信息和规律,进而自动生成虚拟人物的外观、动作、语音和行为,并根据环境和用户的交互进行实时调整和优化。通过学习和迭代改进自己的行为与表现,以便更加智能地适应用户需求。这种自主学习和适应性能力使得虚拟角色能够更好地满足不同用户和场景的需求,提供个性化、定制化的体验。
1.2 场景生成
在分析大量的图形和内容数据后,AIGC 可以根据剧情需求自动生成场景,快速地创建逼真的视觉效果,包括虚拟场景、特殊效果和物理模拟等。从质感、纹理、光照等角度加强场景细节的构建,从而提高制作效率和质量,优化场景布局和设计,以提供更具吸引力和沉浸感的虚拟体验。
1.3 行为和情感识别
通过情感计算、情感识别和情感生成等技术,AIGC 能够识别和理解用户的情感,并表达出适当的情感反应,如喜悦、愤怒、悲伤等。此外,AIGC 能够推断出用户的意图、偏好和情感状态,从而建立起与用户的虚拟关系。通过情感建模,人工智能可以模拟和表现虚拟人物的情感和认知能力,使其在虚拟现实场景中更加智能和逼真,通过与用户的情感互动,产生情感共鸣。
1.4 个性定制
通过分析用户数据和行为模式,人工智能可以为用户提供多样化的虚拟现实体验。通过机器学习和推荐算法等技术,根据用户的偏好和兴趣,定制虚拟场景、虚拟人物和虚拟关系,使用户能够享受到更加符合自己需求的虚拟现实体验。
综上,在AIGC 的帮助下,虚拟现实交互艺术家们在虚拟角色设计、感官体验、用户行为预判、交互生成、虚拟场景构建、编写剧本和音乐等方面,将会更加精确和具有效率。随着AIGC 技术的逐渐成熟,其在虚拟现实交互体验领域的应用是大势所趋。
2 AIGC 在虚拟现实交互影像内容生成中的探索
在虚拟现实交互领域,人工智能主要在自然语言处理、机器视觉、虚拟现实应用程序接口和智能代理方面介入虚拟现实的构建[8]。论述人工智能与虚拟现实体验的探索中,学者们已经总结出了人工智能的诸多应用:在人工智能对艺术创作的影响上,王嘉奇等[9]认为其作用体现在模仿学习以及创新工具等方面,它并不是完全代替人的创造力,而是为人类的创造提供了有效方式;在影像的美术风格创作中,薄一航[10]认为人工智能以及人机协同技术无疑会提升效率,计算机的海量存储能力和计算能力将会为艺术家的创作提供灵感;高锐[11]详细阐述了AIGC 技术如何协助创作者设计和绘制动画短片中的角色和场景,并展示了AIGC 技术在剧本创作和音频处理等方面的出色表现。总而言之,AIGC 在跨模态生成能力、大型预训练模型的发展逐步成熟。
2.1 虚拟现实场景生成与整合
虚拟现实兼具戏剧的舞台空间、电影的叙事特点和游戏的交互特征。360°全景呈现是对全感官的最大调动,交互体验将空间与叙事结合,视觉塑造与情感调动同时进行。虚拟现实影像通过呈现与真实世界维度一致的虚拟时空,消除了需要想象的环境、人物、位置、角度、运动、方向、关系等元素,制造出了与现实世界几乎一致的视听维度和存在感知,让观众获得了与现实世界相似的感知体验。技术赋予虚拟现实空间以逼真感观和体验,甚至具有了比真实感官更真实的超真实性(Hyperreality)[12]。虚拟现实影像艺术家们通过视角转换、角色代入等方式为体验者提供一种进入虚拟故事空间的机会,在360°的虚拟空间包裹下,体验者以身临其境的方式参与到故事发生的时空中,跟随着人物、情节的推进去体验故事。沉浸感是虚拟现实体验者的最大感受,依赖于逼真的场景和环境,置身于此的体验者能够迅速代入环境和角色中。场景的构建是虚拟现实世界的基础,也是人工智能发挥能力代替人力的领域。
在场景的设置和优化中,人工智能通过生成式对抗网络(GAN)和深度学习,学习空间的不同物理组件,如纹理、照明等,实时创建更加逼真的环境。人工智能算法还在生物反馈应用中根据用户的反馈和行为,实时调整场景以提供更符合用户需求的体验;实时修改和优化虚拟现实环境中的场景,包括场景的自动化生成,在地形、建筑、天气、动态物体的表现上更加细致、逼真。随着大型预训练模型的逐步成熟,文字生成图像(Text-to-Image)、文字生成视频(Text-to-Video)等跨模态生成能力逐步提高。如Runway 出品的AI 视频编辑工具Gen-2,在前序版本“将实拍视频进行动画转变”的基础上,能够轻易实现文字生成视频(Text-to-Video),实现人物在不同时空、不同人种(物种)之间的瞬间穿越。
在创建场景的人工智能技术中,英伟达(NVIDIA)的GET3D 是2D 转为3D 的代表工具。该软件通过对2D 图像进行训练,生成具有高保真纹理和复杂几何细节的三维图形,同时允许将其形体导入3D 渲染器,这使得用户能够轻松地将对象导入游戏引擎、3D 建模软件和电影渲染器并进行编辑。NVIDIA 近期推出的AI 模型Neuralangelo 则能够将视频片段转化为细节层次丰富的高精3D 模型,并且可以准确呈现复杂材料的质地,例如屋顶瓦片、玻璃窗格和光滑的大理石。在虚拟现实影像的应用中,NVIDIA 又推出了GauGAN360 工具以实现3D 场景的360°呈现。此外,基于与NVIDIA 最初GauGAN AI 绘画应用程序相同的技术,可让用户以景观的整体形式进行绘画,并让GauGAN360 生成匹配的立方体贴图或等距矩形图像。
2.2 虚拟现实交互影像中的人物塑造
在虚拟现实的时空中,故事中的人物扮演着至关重要的角色,对用户的体验和情感联结起着重要作用。人物一般在虚拟现实场景中充当着引导者或叙事者的角色,有助于用户更好地理解和探索虚拟环境,让体验更有目的性和连贯性。同时,通过人物的表情、姿态和语言等传递情感和表达情绪,以增强用户与虚拟环境之间的情感连接和情绪体验。
由Epic Games 开发的MetaHuman Creator 是一款具有代表性的创建虚拟人物的智能工具。该工具利用高度逼真的数字人物技术,旨在提供一种快速、直观的方式来创建高质量的虚拟人物模型[13]。Meta-Human Creator 允许用户通过简单的拖拽来创建虚拟人物的外观和特征,包括面部特征、发型、服装和身体比例等。以计算机图形学(CG)和渲染技术为支撑,MetaHuman Creator 可以在短时间内生成逼真、高质量的虚拟人物模型,用户能够对虚拟人物的面部表情、眼睛、嘴唇、头发、肤色等各个方面进行自定义。这种高效且直观的方式,无疑为快速生成逼真的数字人物模型节省了大量时间和人力成本。
2.3 虚拟现实体验中的交互设计
对于人物、场景、环境等的逼真描摹是为了增强“真实感”,但虚拟现实要实现的效果不止于此,其逼真效果还会调动体验者的多感官系统,最终达到一种“在场感”。虚拟现实通过充分调动用户视觉、听觉、味觉、嗅觉等多重感观实现对事件的多重解构,在创造性空间中,带领体验者真正嵌入重塑的情境中,以体验者的“在场”感知重新体会认知某一事件的“本真性”[14],在虚拟现实体验设计中,多模态体验设计是一项重要的任务之一。其中,最关键的是如何将不同感官的信息融合在一起,让用户感受到真实且统一的感觉[15],即组合多维度的感官信息输入,进一步提高虚拟现实场景的逼真度和互动性,其中包括视觉、听觉、触觉、嗅觉等诸多认知刺激的整合与应用。同时,认知科学的引入为虚拟现实体验设计提供了一种非常科学化的设计者工具,可以指导设计者精细迭代,影响到虚拟现实体验中人类行为模式的制定与修正。
除了通过各种感官体验带来“在场感”之外,与虚拟场景中的元素进行交互也会增加观众的“沉浸感”,这也是虚拟现实体验与二维影像相比更具优势之处。交互性被称为交互影像中最具颠覆性的特质,是虚拟场域中对多元对象的操作性和从适时环境中得到自然反馈程度的体现[16]。机器视觉技术的支持是眼动交互、手势交互和姿势交互等技术的基础[17]。典型的机器视觉系统包含光源投射、图像采集、图像数字化、数字处理、判断决策和信号反馈六大模块[18]。通过对信息进行判断决策,该系统将结果反馈到人机交互界面,生成相应的变化。机器通过对人类面部表情、手势和体态的捕捉和识别,来观察和学习用户偏好,响应用户的语音命令,更好地理解用户的意图和交互行为,帮助创造更加身临其境的体验。例如Omniverse 的云原生超级计算机(Avatar Cloud Engine,ACE)是一套基于生成式AI 技术的模型代工服务,它能够为游戏中角色的语音、对话及动作交互提供AI 模型。ACE 支持下的NeMo 服务会根据预先输入的角色背景知识,构建、定制并部署相应的语言模型;Riva 则用于识别体验者的语音、实现文本和语音互转化,让AI 人物给出实时语音对话;Audio2Face 用于即时创建匹配语音的AI 人物的面部动作,并直接添加到Epic Games 的虚幻引擎5 或其他工具中[19]。
在现有的虚拟现实交互设计中,用户往往只能依靠手柄等外接设备来控制角色的移动和行为,有些体验甚至是完全靠视觉沉浸来实现。但是,通过人工智能生物反馈技术应用,体验者可以通过呼吸、心跳等生理数据来为角色提供实时控制信号,从而增加虚拟现实中的身体体验、情感和互动[20]。例如,在虚拟环境中进行武术对决,用户可以通过呼吸来控制角色的招式和力度,增强用户沉浸感,提高互动性。人体动作生成(Human Pose Generation)即为一项计算机视觉和机器学习技术,通过分析现实世界中的人体姿势数据,生成逼真的动画角色姿势,以此快速生成复杂的角色动作,并在影视制作中降本增效。
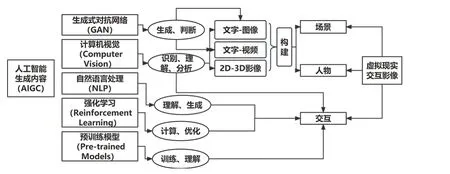
图1 人工智能技术在虚拟现实交互影像生产中的应用
3 AIGC参与制作的虚拟现实交互影片分析
2017 年,当时的Facebook 公司把基于生成式对抗网络(GAN)、风格迁移(Style Transfer)等方法的图像生成和处理技术运用到了VR影像中。Facebook巴黎AI 研究院和电影制作公司OKIO 工作室、Saint George VFX 工作室以及导演Jérôme Blanquet 合作完成了VR影像作品《变动》(Alteration)。影片人工智能技术生成虚拟环境和虚拟人物,同时探讨了虚拟现实和人工智能在塑造人类体验和身份认同方面的潜力。人工智能在这部影片中的突出贡献是风格迁移技术的使用[21]。以Julien Drevelle 作品衍生出来的风格为目标,巴黎AI 研究院的技术团队选择了17 种变体,以此为基础来训练一个神经网络,并使其修改影像的每一帧。彼时,风格迁移在360°立体图像上还是一个全新领域,Facebook 团队用768×768 的图像训练了神经网络[22],通过将每个目标样式应用于单个帧来生成高分辨率测试图像,最终实现了导演所希望的画面风格,也保证了双眼看到的立体效果。可以看到,人工智能在风格迁移的学习和制作中表现颇佳。它使用卷积神经网络(CNN)和生成式对抗网络(GAN),将一幅图像的内容与另一幅图像的风格进行分离,然后将内容图像与风格图像进行合成,从而实现风格的迁移。除了图像风格迁移,它还可以应用于视频、音频等领域。例如,将电影的风格应用于个人视频,或将艺术家的音乐风格应用于其他音频作品[23]。
2019 年西南偏南电影节最佳VR 叙事奖作品——沉浸式VR 动画电影《咕鲁米的眼睛》(Gloomy Eyes)也是一部使用人工智能技术创作的VR 影片。AIGC 系统在学习了大量相关电影和视觉效果后,使用深度学习和计算机视觉技术生成了影片的场景和人物。故事场景包括了暗黑森林、水下世界、深海城市等,角色包括巨型生物、AI 机器人、机器怪兽、僵尸角色等。这些元素均由人工智能技术制作而成,虽然还存在着帧速率不高、清晰度不够等问题,但已经显示出了人工智能的作用。影片中涉及人工智能的制作包括虚拟角色的智能行为、根据观影者的行为和互动作出的智能反应以及情感反馈等,例如回应观影者的笑容或哭泣,通过人工智能语音识别技术将观影者的语音指令转化为指令。此前这种技术在《掌声》(Clap)、《库松达》(Kusunda)等VR 影片中也有使用,通过语音输入进行交互,与剧中人物产生互动。除此之外,通过识别体验者的动作产生对应效果的动作交互也有不少应用,如VR 交互影片《一瞥》(Glimpse)中,体验者会自动代入主人公的角色,拿取和阅读场景中的物品,甚至可以吹灭虚拟场景中的蜡烛,通过动作交互来参与剧情,体验主人公的情感变化。
虽然人工智能技术已经在影视制作方面进行了一些探索,也取得了一定的进步,但也仍然存在沉浸感不强、交互性不够自然等问题。针对这些问题,邵将等[24]提出可以借用机器学习技术中的典型算法来增强VR 电影体验效果,“包括针对沉浸感缺失的基于卷积神经网络学习技术的应对策略,以及针对真实感困境提出的决策树、层次聚类算法下的优化方案等”。
4 AIGC 的不足及其在虚拟现实交互应用上的思考
尽管AIGC 技术在图形和内容创作方面取得了显著进展,但仍存在一些技术上的限制。首先,AIGC技术的准确性和真实性仍需进一步提高。虽然机器学习和算法能够通过大量的数据进行学习和训练,但在某些情况下,AIGC 技术生成的图形和内容可能仍然缺乏真实感和细节,特别是在需要高度逼真和精确的视觉效果时,AIGC 技术可能无法完全满足需求。其次,AIGC 技术的知识和数据依赖性也是一个挑战。AIGC 技术需要大量的图形和内容数据进行学习和训练,以便生成高质量的结果。然而,获取和处理这些数据可能会面临困难,尤其是涉及人像生成、专有数据和知识产权的问题。AIGC 技术还需要领域专家的知识和经验来指导和验证其生成的结果。此外,一些艺术家和设计师更倾向于手工创作和表达,而AIGC 技术则可能限制了他们的创作自由度。确保AIGC 技术的合法性、道德性和隐私保护亦成为亟待解决的问题。
AIGC 在数字建模、虚拟人、场景合成和艺术创作等领域的迅速扩展,是随着产业界虚拟现实、数字孪生和融合共生等场景的不断丰富而实现的。未来,人工智能还将与其他技术如增强现实、混合现实等进行更深入的融合,创造更加综合、交互性强的虚拟现实体验。这种融合可以通过机器学习和计算机视觉等技术实现对真实世界的感知和理解,进一步提升虚拟现实的沉浸感。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
作文小学中年级(2020年6期)2020-07-24
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
汉语世界(2017年3期)2017-06-05
商周刊(2017年24期)2017-02-02
海外星云(2016年7期)2016-12-01
南风窗(2016年19期)2016-09-21
自然资源遥感(2014年3期)2014-02-27
