
基于ELMo-TextCNN的网络欺凌检测模型
2023-09-06 11:45:14叶水欢葛寅辉
信息安全研究 2023年9期
叶水欢 葛寅辉 陈 波 于 泠
1(南京师范大学计算机与电子信息学院/人工智能学院 南京 210023)
2(江苏省大规模复杂系统数值模拟重点实验室(南京师范大学) 南京 210023)
(shuihuanye@qq.com)
传统欺凌行为一般是指用肢体和语言去伤害、威胁、孤立他人的行为,网络、通信技术的发展为现实中的传统欺凌行为提供了新途径——网络欺凌.加拿大青少年网络欺凌研究专家Belsey[1]最早给出了网络欺凌的定义——“以现代信息与通信技术作为支持,针对个人或者群体进行恶意的、重复的、敌意的行为,造成受害者心理上或生理上的伤害.”英国心理学会的Simth等人[2]认为,“网络欺凌是个人或群体利用电子交流方式,针对无自我保护能力的个人或群体持续实施的具有攻击性的有意的行为.”
网络欺凌在社交网络中造成的危害甚深,其缺乏理智的言行会很容易煽动社交用户的情绪或者给人带来心理上的伤害,尤其是年龄层较低的未成年用户价值观正处于塑造阶段,对网络欺凌的抵御能力低,更容易受到伤害.
《2020年全国未成年人互联网使用情况研究报告》[3]显示,未成年网民在网上遭到讽刺、谩骂的比例为19.5%.长期遭到网络欺凌将导致青少年产生一些较严重的心理、行为问题,如情绪低落、焦虑、害怕、难以专心学习等[4],青少年易遭受网络欺凌这一问题亟待解决.美国已有48个州的法律条文中涵盖了应对网络欺凌的内容[5].我国教育部颁布的2021年9月1日起实施的《未成年人学校保护规定》[6]明确对包括网络欺凌在内的欺凌行为进行预防、制止.
本文在总结网络欺凌检测领域已有工作的基础上,针对已有研究在训练样本较少、难以处理多义词、分类性能不理想等问题,采用词向量加深度神经网络的思路,将ELMo(embeddings from language models)和TextCNN(text convolutional neural network)相融合,构建检测模型.利用预训练的ELMo生成的动态词向量,解决训练样本较少、难以处理多义词的问题,通过TextCNN提高分类效果.
1 相关工作
网络欺凌检测通常是一个分类问题,对一个数据样本(如来自社交平台的帖子、消息、评论等)抽取合适的特征,交给分类器判断样本是否属于欺凌行为,因此网络欺凌检测通常涉及文本表示、分类器这2个方面的主要工作.
1.1 文本表示
网络欺凌检测的实现依赖于检测分类器的训练,但是自然语言无法直接作为分类器的输入,以自然语言形式存在的检测样本需要经过向量化处理才能作为分类器的输入.
词袋(bag of words,BoW)模型是解决文本表示的基本模型,该模型忽略文本的词序、语法、句法,将文本当作单词的集合,使用文本中单词出现的频率对文本进行描述,将1个文本表示成1个1维的向量.Xu等人[7]是最早从事网络欺凌检测技术研究的学者之一,他们使用BoW模型表示文本序列.
虽然BoW模型表示文本简单、便捷,但无法关注词语之间的顺序关系.N-gram模型是一个基于概率的判别模型,引入了马尔科夫假设(Markov assumption),1个词的出现仅与它之前的若干个词有关,可以获取局部的上下文信息.Waseem等人[8]使用N-gram模型对16000多条推文进行了文本表示,研究结果表明N-gram的应用提高了网络欺凌检测的准确度.
N-gram模型得到的向量过于稀疏,存在维度灾难,词向量(word embedding)的出现解决了这一问题,它可以将单词映射到一个低维空间.词向量最早出现于Bengio等人[9]提出的神经网络语言模型(nerual network language model, NNLM).2013年,Mikolov等人[10]在NNLM模型的基础上提出了Word2Vec(word to vector)模型.该模型用1个1层的神经网络将one-hot形式的稀疏词向量映射为1个n维(n一般为几百)的稠密向量.另外,它能够对单词使用代数运算计算相似的单词.Word2Vec模型有2种方法实现:一种是基于连续词袋(continuous bag of words, CBOW)模型;另一种是基于Skip-gram模型.Gada等人[11]使用Word2Vec模型对Twitter网络欺凌数据集进行了文本表示.
Pennington等人[12]针对Word2Vec模型没有考虑词序、文本全局的统计信息的不足,提出全局词-词共现矩阵,结合全局矩阵分解和局部上下文窗口方法,得到一种新的词向量GloVe(global vectors for word representation)模型,充分有效地利用了语料库的统计信息,仅仅利用共现矩阵中的非零元素进行训练.Banerjee等人[13]在网络欺凌检测系统中使用GloVe进行文本表示.
但是上述模型均属于静态词向量,存在无法捕捉上下文信息,从而无法处理多义词的问题.本文引入ELMo向量解决了这个问题.于2018年提出的ELMo[14]是一种基于特征的预训练模型,采用双层双向长短期记忆(bi-directional long short-term memory, BiLSTM)网络.长短期记忆(long short-term memory, LSTM)网络作为一种特殊的循环神经网络(recurrent neural network, RNN),能够学习长期依赖关系,目前应用较多.ELMo向量在初始化后并不是直接交给分类器进行训练,而是先获取某个单词的上下文信息,根据上下文信息对其对应的词向量进行调整,使之更能表达在对应上下文中的具体含义,从而解决多义词问题.
1.2 分类器
分类器的选择事关网络欺凌检测效果.
Xu等人[7]使用条件随机场(conditional random field, CRF)算法作为分类器对社交媒体信息进行欺凌检测,证实了网络欺凌自动化检测技术的可行性.Zhao等人[15]使用线性支持向量机(linear support vector machine, LinearSVM)作为分类器,并在Twitter语料库上验证了其有效性.
但这些传统机器学习检测方法大多依赖于特征选择,同一特征在不同数据集的检测性能不够稳定,不合适的特征会降低检测精度.为了解决机器学习在处理网络欺凌检测工作中存在的局限性,有学者开始研究抛开繁琐的特征工程与经典机器学习算法,使用分类性能更为强大的深度神经网络训练性能更强的网络欺凌检测模型.Ön等人[16]研究表明,同一个YouTube数据集上,基于深度学习的模型的欺凌检测效果优于机器学习模型.
卷积神经网络(convolutional neural networks, CNN)最初用于处理图像,刘小乐等人[17]用其检测Exploit Kit攻击活动,而文献[18-19]将其应用于文本分类.文献[18]使用基于单词向量的卷积神经网络,提出了TextCNN文本分类模型.该模型采用整行卷积策略,1行代表1个单词,从而保持了单词的完整语义.文献[19]使用基于字符向量的卷积神经网络,提出了字符级卷积神经网络(character-level convolutional neural networks, CharCNN)文本分类模型.该模型是一个6层卷积神经网络模型,以词向量表示字符,以字符向量作为模型输入.这2种模型在文本分类上都取得了较好的效果,其中,TextCNN的性能更好.Le等人[20]在5个文本分类任务实验中发现,以单词序列作为文本输入时,增加卷积网络的深度并不能提升文本分类性能,浅层模型TextCNN甚至优于DenseNet[21]等深层模型.Laxmi等人[22]实验结果表明,TextCNN可以更好地检测数据集上的网络欺凌推文.

表1 实验数据集
LSTM是RNN中特殊的一类,由遗忘门、输入门、输出门控制整个时间序列中的信息,能够从序列中学习长期依赖关系.Agrawal等人[23]把LSTM作为分类器进行了网络欺凌检测.Mahat[24]在Wikipedia,Twitter,Formspring这3个平台上,使用LSTM作为分类器进行网络欺凌检测,得到了良好的检测效果.
何力等人[25]总结了当前深度学习在文本分类领域的发展情况,并分析了多种典型分类方法的特点和性能,结果表明,卷积神经网络具有优秀的分类性能和泛化能力.Akhter等人[26]在网络欺凌检测实验中对比了CNN,LSTM,BiLSTM,CNN-LSTM[27]这4种不同的模型,结果表明,CNN优于其他模型.
2 ELMo-TextCNN模型
利用深度学习进行网络欺凌检测时,需要考虑一词多义问题,同时也要考虑如何在有限的网络欺凌小样本情况下提高模型检测效果.为此,本文将双层双向的LSTM构成的ELMo模型生成的动态词向量输入TextCNN进行分类训练,以解决上述3个问题.本文设计的网络欺凌检测模型如图1所示.模型由4部分组成:
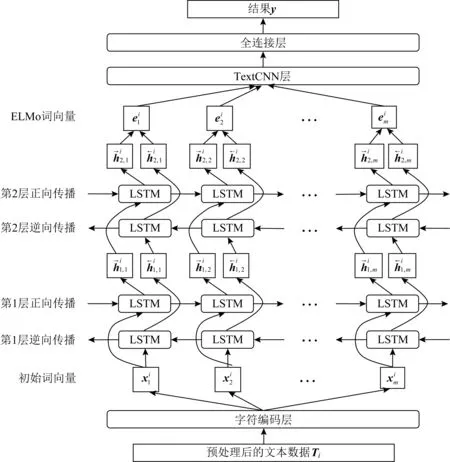
图1 检测模型结构
1) 预处理.负责对语料进行预处理,获得后续生成初始词向量所需要的文本序列.
2) ELMo编码.ELMo是一种基于双向语言模型的、动态的、语境化的词向量表示方法,能够根据上下文生成相应词的向量表示.在编码时,ELMo接受预处理后的文本序列,通过CharCNN生成初始化的词向量,然后由双层双向的LSTM结构对初始化的词向量进行上下文适应性调整.
3) TextCNN层.TextCNN是用来作文本分类的卷积神经网络,通过定义不同大小的卷积核实现对不同局部特征的提取,结构简单,效果好,因而在文本分类领域应用广泛.在ELMo编码完成后,TextCNN对生成的ELMo词向量进行学习,提取文本序列中的欺凌信息.
4) 全连接层.通过全连接网络收集TextCNN层输出的特征信息,整合输出欺凌类别.
下面着重介绍ELMo编码、TextCNN网络和全连接层.
2.1 基于迁移学习思想的ELMo编码
ELMo模型应用于分类任务时,分为2个阶段:一是生成初始化的词向量;二是对初始化的词向量进行上下文适应性的调整.
首先通过CharCNN生成初始化的词向量,如式(1)所示:
(1)

然后将其交给双层双向LSTM结构,每层LSTM神经元分为正向、逆向这2部分,分别用于获取当前单词的上文信息、下文信息.
正向LSTM由2层LSTM组成.第1层的LSTM单元结构如式(2)所示:
(2)

(3)
其中Wf和bf分别为遗忘门的权重和偏置值,Wj和bj分别为输入门的权重和偏置值,WC和bC分别为通过函数tanh创建新值候选向量的权重和偏置值.
第2层的LSTM单元结构如式(4)所示:
(4)
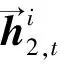
经过残差连接得出正向LSTM的词向量,如式(5)所示:
(5)

(6)
最后对词向量进行拼接,从而得到相应的ELMo词向量表示,如式(7)所示,此时不同上下文中的相同单词就会在下游任务中携带不同的甚至截然相反的信息.
(7)

本文采用迁移学习思想,在10亿单词基准的大规模语料库上预训练ELMo模型,得到初始化共享参数[14],再迁移至网络欺凌小样本中训练,解决网络欺凌样本数据规模小的问题;ELMo模型根据单词的上下文信息对其对应的词向量进行调整,最终获得的ELMo词向量融合了词语本身和词语所在上下文的语义特征,可以很好地表示多义词的不同语义.
2.2 TextCNN网络提取欺凌信息
TextCNN是CNN的一个变体,包含卷积层和池化层,通过设置不同大小的卷积核实现多样性特征提取,从而进行文本分类.
1) 卷积层.
卷积层采用4种不同大小的卷积核,提取不同层次的特征.另外使用ReLU函数作为卷积层的激活函数.该层结构如式(8)所示:
(8)
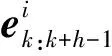
2) 池化层.
本文采用最大池化法对特征进行降维,如式(9)所示:
zi=max(Mi),
(9)
其中zi为第i条文本的特征图经最大池化层提取的特征向量.
由于本文的网络欺凌样本为短文本数据,而TextCNN擅长处理短文本数据,简单的浅层网络TextCNN分类、泛化能力强,所以TextCNN网络通过卷积层和池化层对编码后的ELMo词向量进行学习,提取了网络欺凌文本序列中的欺凌信息.
2.3 全连接层整合输出欺凌类别
使用Dropout方法随机失活一定比例的神经元,降低节点间的高度依赖关系,减少过拟合现象的发生.本文Dropout的比例设置为0.5.最后使用softmax函数输出分类结果,如式(10)所示:
y=softmax(p(Wdzi+bd)),
(10)
其中y为分类结果,p为Dropout的比例,Wd和bd分别为全连接层的权重和偏置值.
通过全连接网络收集TextCNN层输出的特征信息,最终整合输出网络欺凌类别.
3 实 验
3.1 实验数据
欺凌检测任务本质上属于分类任务,需要大量带标签的社交网络文本数据,本文主要考虑使用网络欺凌检测领域已公开的数据.Waseem等人[8]于2016年的一个有关社交网络仇恨言论的研究中,收集了16914条推特数据并对其进行了标注,最终获得3383条性别歧视样本以及1972条种族主义样本,数据样本中包含推文id以及其对应的欺凌标签;Reynolds等人[28]从Formspring网站爬取了18554条用户的数据,获得了3915条消息样本,其中369条为欺凌数据;Hosseinmardi等人[29]收集了Instagram网站中的用户信息及评论,通过众包平台获取了1954条消息样本,其中567条为欺凌样本.但是上述文献中的数据集目前均无法获得,因此,本文通过“cyberbullying data”“toxic comment”等关键词搜索,从GitHub上获取了2份实验数据,另外从Kaggle平台上获取了1份实验数据.本文使用的3份数据集均已标注,如表1所示:
考虑到非欺凌样本数量远超欺凌样本,可能会引起模型的惰性学习出现过拟合现象,本文使用过采样算法和欠采样算法对数据集进行平衡,将DS_GM的非欺凌样本减少至36845个,DS_KS的欺凌样本增补至12179个,DS_GF的非欺凌样本减少至20620个.
实验所用数据中训练集和测试集的比例为8∶2.
3.2 评估指标
本文使用分类领域常用的3个指标:精确率(Precision)、召回率(Recall)、F1-score来衡量模型的性能.Precision侧重于衡量模型的精确度,如式(11)所示:
(11)
其中TP为真正类,FP为假正类.
Recall侧重于衡量模型的查全能力,如式(12)所示:
(12)
其中FN为假负类.
尽管上述2个指标对于分析模型的性能都很重要,但是不够全面,F1-score兼顾了2个指标的侧重点,如式(13)所示:
(13)
3.3 实验结果与分析
1) 迭代次数测试.
在DS_GM,DS_KS,DS_GF这3个数据集上,ELMo-TextCNN模型准确率随着迭代次数的变化趋势如图2所示:

图2 ELMo-TextCNN模型在3个数据集 上的准确率对比
如图2所示,ELMo-TextCNN模型准确率在3个数据集上的初始准确率较高,总体变化趋势为先上升后趋于平稳,这是因为ELMo模型在大规模文本数据上进行了预训练,所以再迁移至网络欺凌的数据集上训练时,就能在1次迭代后获得较高的准确率;经过多次迭代后,训练出更有效的参数,ELMo-TextCNN模型效果逐渐提高;最后模型趋于拟合,准确率较为平稳,结果变化不明显.由于DS_GM和DS_GF数据集比DS_KS数据集大,所以经过1次迭代,前2个的准确率比后者的准确率高,并且前2个的准确率在20次迭代后就处于平稳状态,而DS_KS数据集上的准确率在40次迭代后才能趋于平稳.
2) 模型对比实验.
当前网络欺凌检测方法的主要思路是词向量加深度神经网络,涉及N-gram词向量加CNN、Skip-gram词向量加BiLSTM.为验证本文提出的ELMo-TextCNN网络欺凌检测模型的有效性,对N-gram+CNN,Skip-gram+BiLSTM,ELMo+BiLSTM这3种组合模型进行了对比实验,同样使用了表1中的3个数据集进行实验.
由表2可知,在DS_GM数据集上,本文提出的模型相较于对比的3种组合模型,F1-score分别提升了0.01,1.4,1.1个百分点;由表3可知,在DS_KS数据集上,本文模型相较于对比的3种组合模型,F1-score分别提升了0.12,3.97,1.75个百分点;由表4可知,在DS_GF数据集上,本文模型相较于对比的3种组合模型,F1-score分别提升了0.19,3,2.86个百分点.

表2 DS_GM中本文模型与已有模型的对比 %

表3 DS_KS中本文模型与已有模型的对比 %

表4 DS_GF中本文模型与已有模型的对比 %
由于ELMo采用动态词向量技术,能够根据单词的上下文信息调整单词的词向量表示,所以更能表示单词在语境中的具体含义,更好地处理一词多义的问题;另外卷积神经网络具有优秀的分类性能和泛化能力,所以在DS_GM,DS_KS,DS_GF这3个数据集上,与N-gram+CNN,Skip-gram+BiLSTM,ELMo+BiLSTM模型相比,ELMo+TextCNN模型在综合评估指标F1-score上均有所提高,说明本文模型在网络欺凌检测方面具有更好的表现.
4 结 语
针对目前网络欺凌检测方案存在的训练样本少、难以处理多义词、分类性能不理想的问题,本文提出了一种ELMo-TextCNN网络欺凌检测模型.该模型引入迁移学习中共享参数的思想,利用ELMo模型在大规模语料库上进行了预训练,获得语法语义知识,弥补了网络欺凌检测数据量少的不足,使用预训练的ELMo进行编码使得生成的词向量包含更多的上下文信息,从而解决多义词问题,通过TextCNN模型优秀的分类和泛化性能,处理其擅长的网络欺凌短文本数据,从而获得良好的网络欺凌检测效果.实验结果表明,本文模型优于已有的方案,是兼具ELMo和TextCNN优点的模型结合,既有ELMo模型擅长处理多义词的优点,又有TextCNN擅长处理短文本、分类和泛化效果好的优点,具备良好的网络欺凌检测效果.
本文使用的数据集标签只是表示某一样本是否为欺凌,缺乏对于某一欺凌样本的欺凌程度的考虑.另外,本文使用了目前主流的依赖恶词、关键词等文本特征的欺凌检测思路.在未来的研究中,将考虑细化欺凌程度这一指标,以及在文本特征的基础上加入发文用户特征(如年龄、性别等)或进一步提取社交文本中表达的情感内涵作为情感特征,通过融合多种特征研究更好的网络欺凌检测方法.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
