
基于SIMD思想的SM4流水线优化设计
2023-09-06 11:44:44陈昆明王佳慧马利民梁兆熙
信息安全研究 2023年9期
陈昆明 王佳慧 马利民 张 伟 梁兆熙
1(北京信息科技大学计算机学院 北京 100101)
2(国家信息中心信息与网络安全部 北京 100045)
3(国家计算机网络应急技术处理协调中心 北京 100029)
(1351007822@qq.com)
随着信息安全上升到国家安全的战略地位,数据安全作为信息安全的重要组成部分,如何保障数据的传输安全是十分重要的.而加密算法是数据传输安全与否的核心[1].长期以来,我国金融、政企等安全要求等级高的行业都是沿用DES(data encryption algorithm),SHA-1(secure hash algorithm 1),RSA公钥系统等国际通用的密码算法体系和标准,加密算法自主性和安全性的提升变得尤为重要[2].所以加密技术是增强我国行业信息系统的“安全可控”能力非常重要的一环,但是加密技术目前存在加密效率低、安全性低等问题[3].
从技术实现的方式来看,目前存在软件加密和硬件加密2种方式.软件加密实现容易,安全级别较低,而且性能无法与FPGA(field programmable gate array)等专用硬件相比,其加解密吞吐量成为网络加解密的瓶颈.为了应对越来越大的网络数据流量和加解密需求,需要更高的加解密速率[4-5].
软件加密时许多重要数据或敏感信息(如作为密码运算的密钥或顾客的个人密码)都可在某个时刻以明文形式存在电脑的内存或磁盘中.几乎全部应用业务系统都用现今流行的通用型操作系统,安全级别低,其本身有很多的安全隐患和漏洞,很容易被非法分子或恶意攻击者侵入或控制.所以用软件加密会让不法分子有机会从不安全的操作系统中读取、利用、修改或删除关键数据,不能确保加密过程中的安全性.
用硬件加密时,涉及的全部重要数据或敏感信息的加解密和密码运算都在加密机或加密卡内部完成,不可能有任何危害客户利益的资料暴露于加密机之外,从而从根本上保证了加密过程中重要数据或敏感信息的安全性.
目前软件实现SM4加解密算法主要是用查表实现,但是由于SM4算法原理和设计等因素,SM4使用查表方法的性能明显低于AES(advanced encryption standard),并且Intel等处理器厂商还推出了用于AES运算的AES-NI指令集,采用该指令集实现AES算法是SM4算法软件实现性能的4.23倍,使得国密SM4算法在软件实现上与AES竞争没有优势[6-7].除此之外,国内外许多学者在x86架构上实现SM4算法,并采用SIMD的并行技术来实现,虽然算法速率得到大幅改善,ECB模式下可以达到4.73cycle/B,但是相比专用硬件实现效率依然不高[8].目前SIMD只用在SM4算法的软件实现上[9].并且根据国家最新颁布的《信息安全技术 信息系统密码应用基本要求》(GB/T 39786—2021),在进行加密技术实现安全等级评定时,各安全技术评定一共分为4个等级,软件实现的安全技术最高只能达到2级要求,要想达到更高的等级要求必须用硬件实现[10].
很多国内外学者也对SM4算法的硬件实现方式进行了研究,目前的硬件实现方式主要有2种:一种是采用循环架构实现SM4的关键路径,即32轮迭代,这种实现方法能够节省大量的资源,仅仅适合部署在资源有限的设备上;另一种是采用LUT流水线的电路构架,在ECB模式下,只需要1个时钟周期就可以完成1次加解密[11-13].这种架构的优势是吞吐量大,但是资源消耗大.此架构密钥需要提前确定,轮密钥需要提前生成.
本文提出了一种面向SM4算法的加速流水线结构优化设计,在整体结构实现过程中,加密和解密都是使用同一套构架实现,节省了资源开销,根据不同任务的切换,进行轮密钥的更新,使得各个不同任务之间可以随意切换.并在此流水线架构基础上,基于SIMD(single instruction multidata)思想对以上流水线结构进行优化,减少了轮密钥生成的任务开销,在流水线基础上实现了单轮密钥生成,多加解密数据流同时运算,极大地提高了吞吐量.
1 SM4算法原理
1.1 算法定义
1) S盒.
S盒为固定的8b输出的置换,记为SBox.
2) 基本运算.
在SM4算法中采用以下基本运算:
⨁ 32b异或;
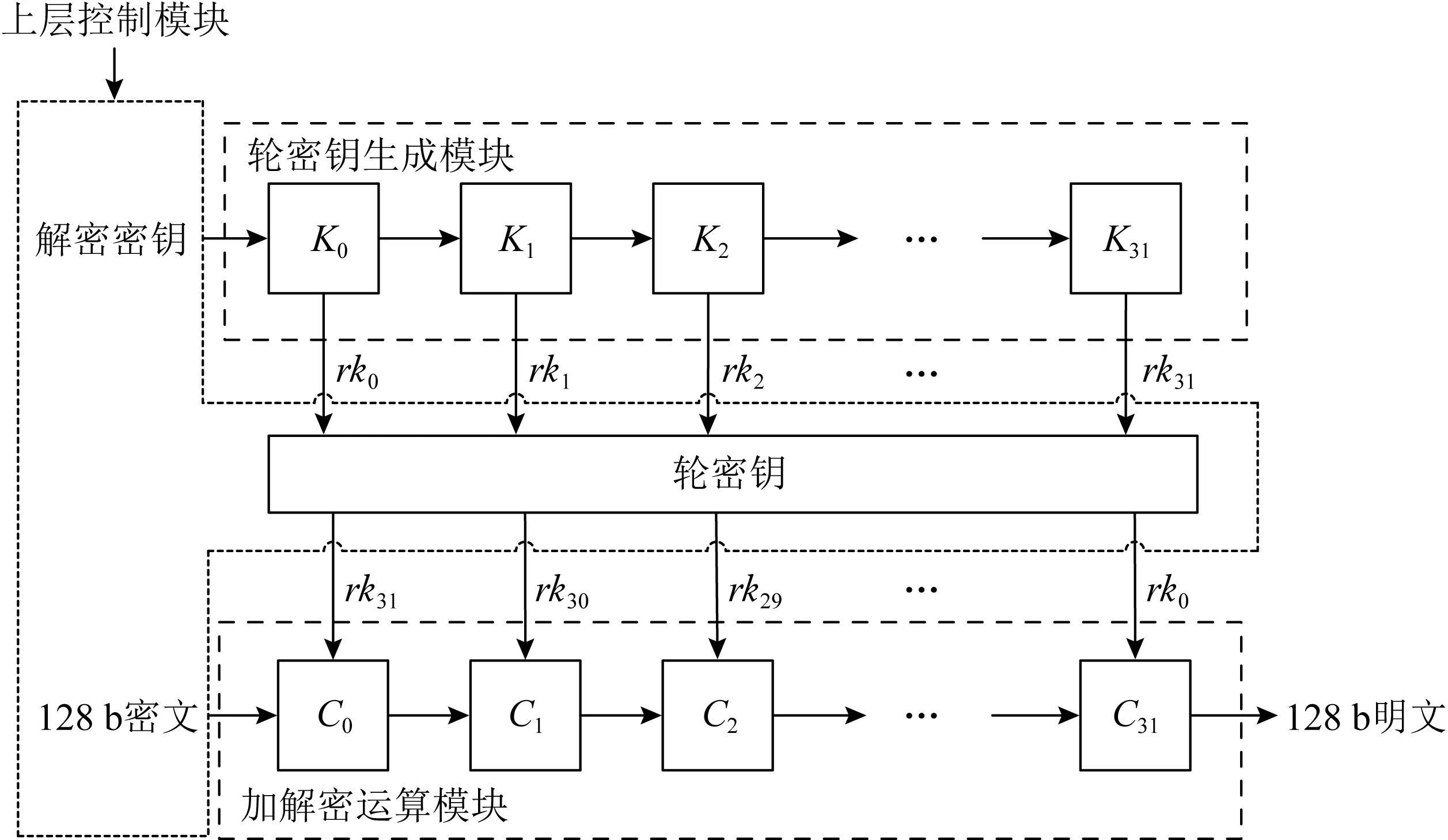
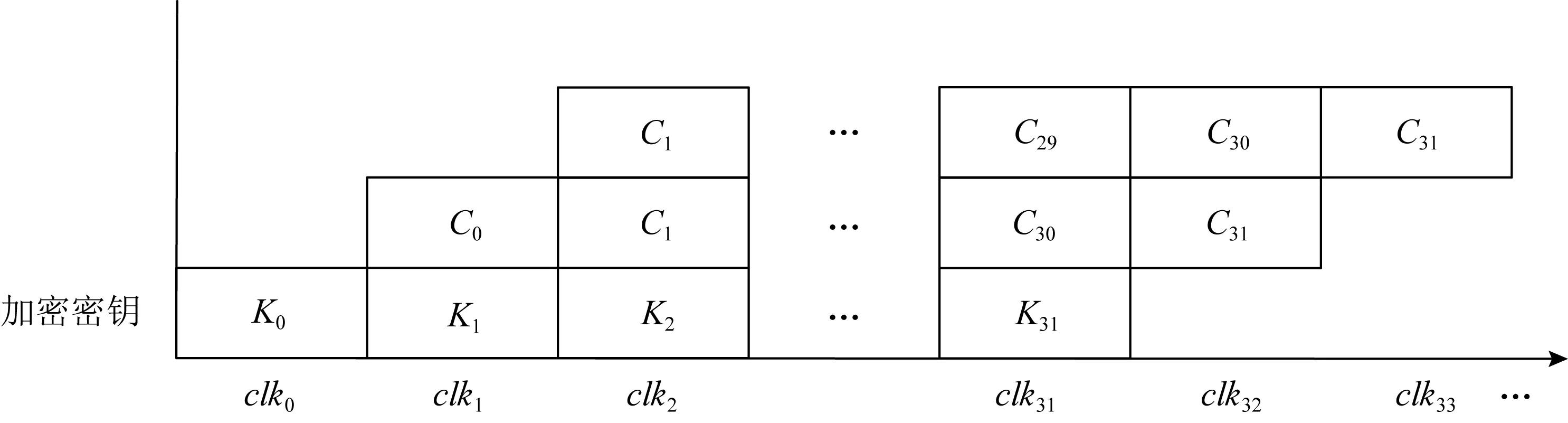
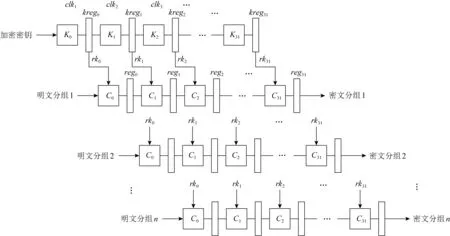
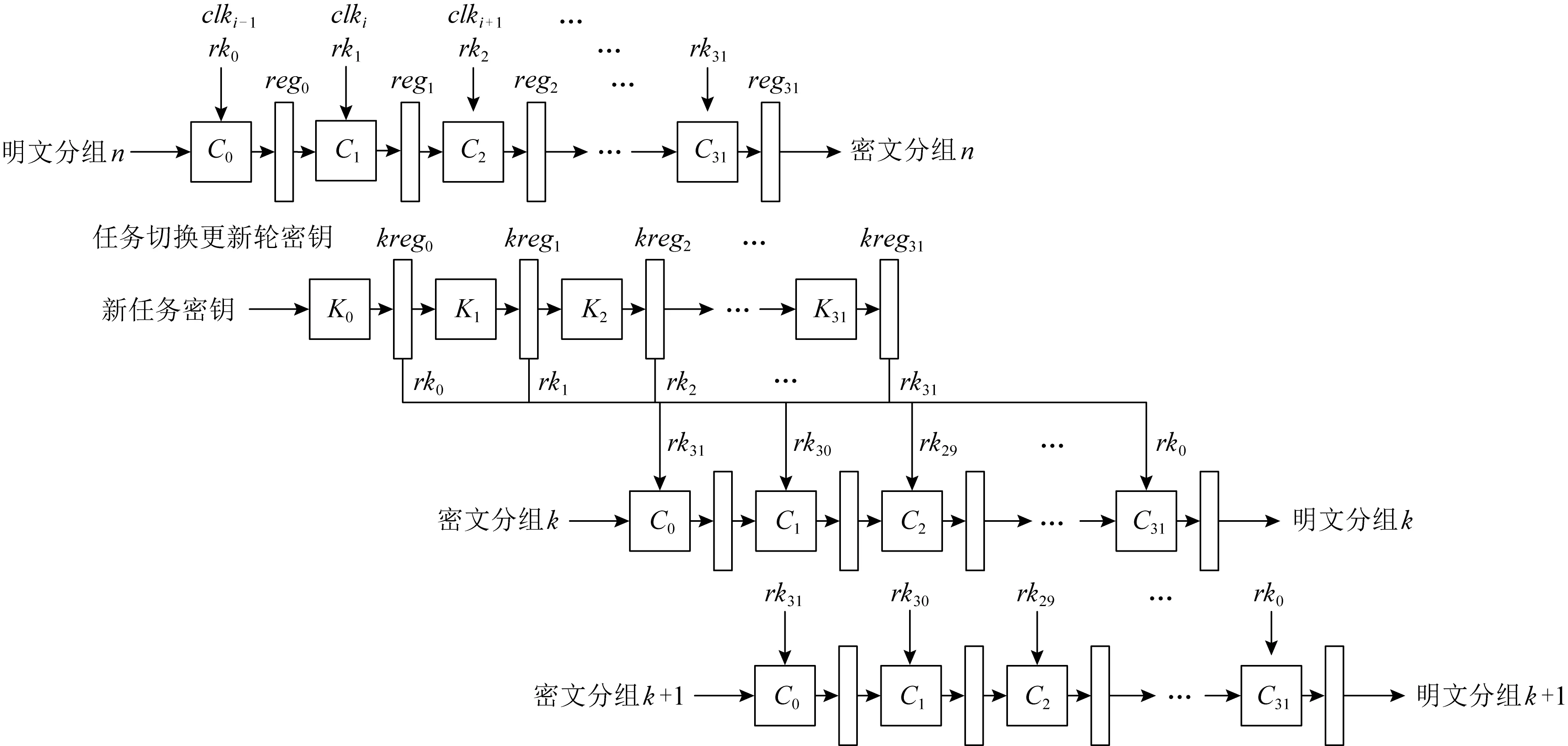
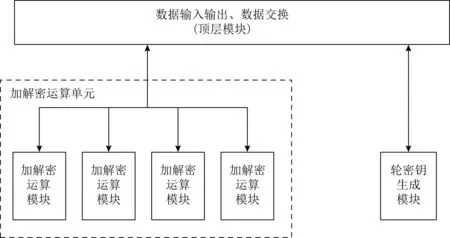
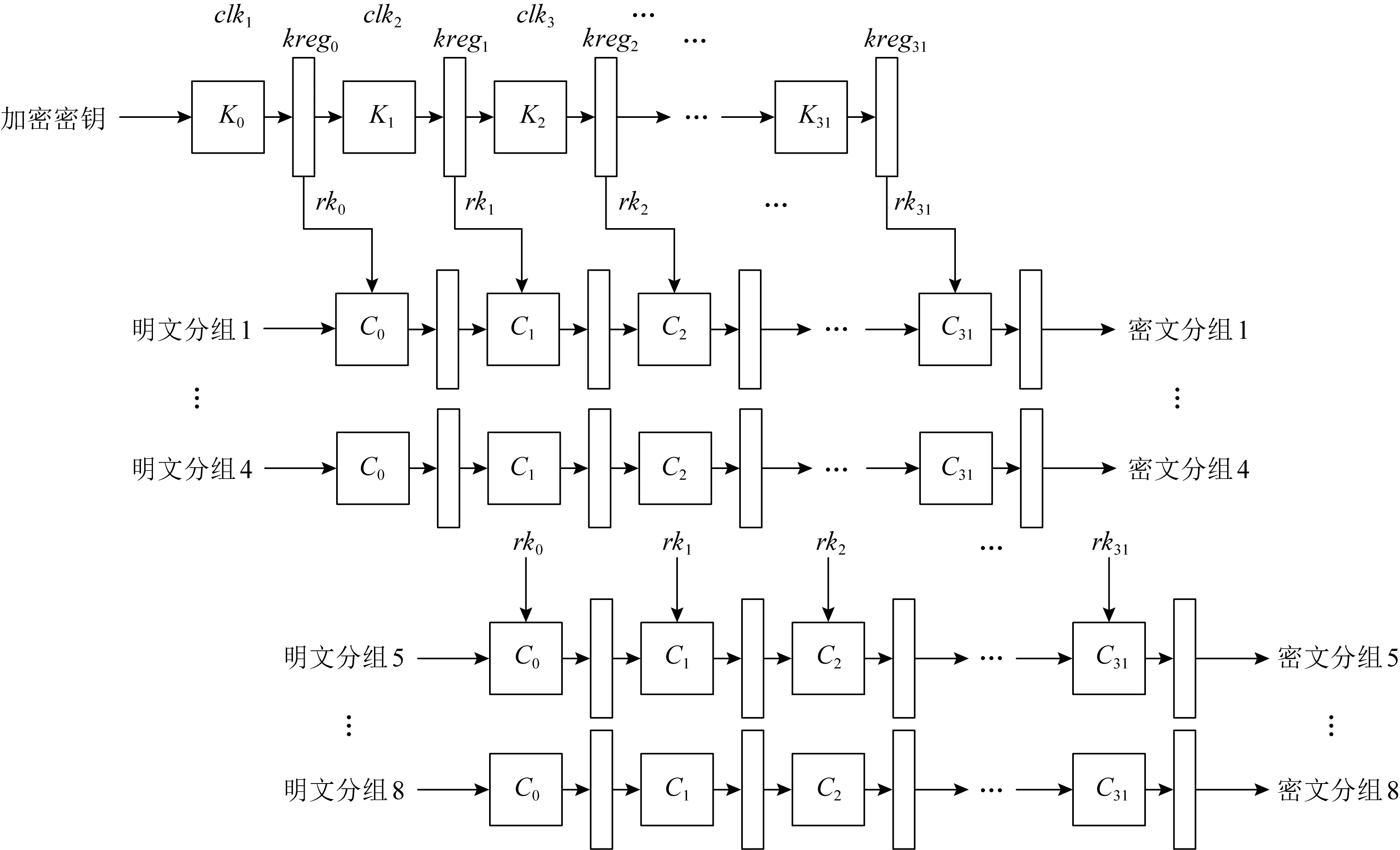
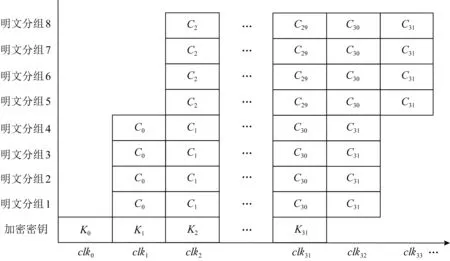
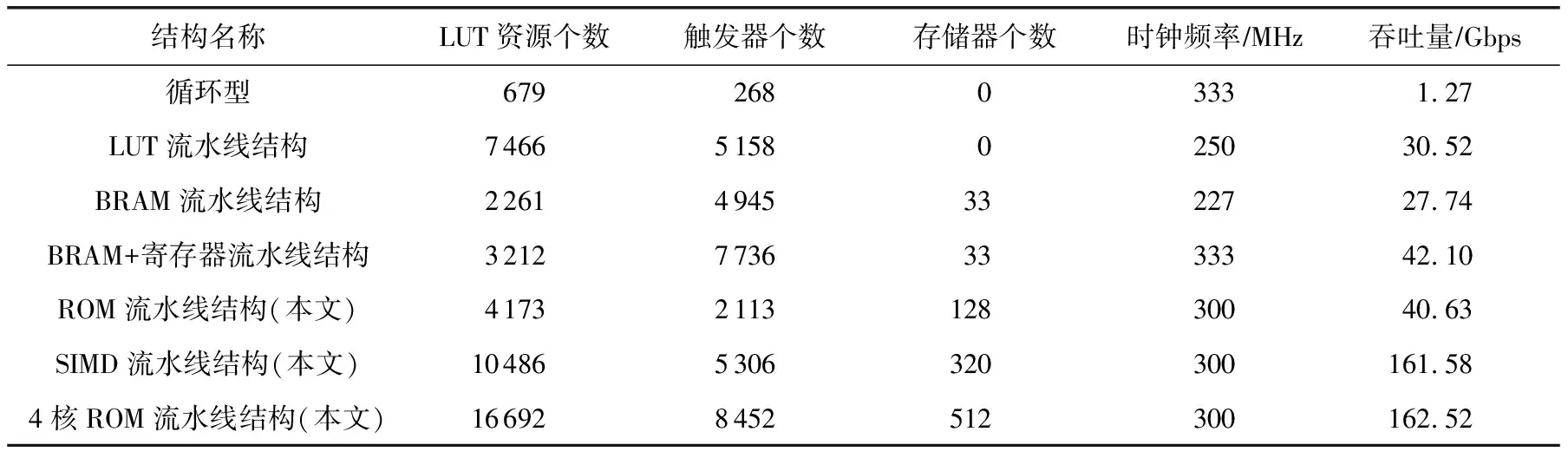
<< 3) 密钥及密钥参量. 加密密钥长度为128b,表示为MK=(MK0,MK1,MK2,MK3),轮密钥表示为(rk0,rk1,…,rk31),其中rki(i=0,1,…,31)为字.轮密钥由加密密钥生成.FK=(FK0,FK1,FK2,FK3)为系统参数,CK=(CK0,CK1,CK2,CK3)为固定参数,用于密钥扩展算法. 4) 轮函数F. F(X0,X1,X2,X3)=X0⊕T(X0⊕X1⊕ 5) 合成置换T. 6) 非线性变换τ. τ由4个并行的S盒构成,S盒为固定的8b的输入和8b输出的置换,记为SBox(·). (b0,b1,b2,b3)=τ(A)=(SBox(a0),SBox(a1),SBox(a2),SBox(a3)). 7) 线性变换L. C=L(B)=B⊕(B<<<2)⊕(B<<<10)⊕ 图1 SM4算法加密流程 Xi+4=(Xi,Xi+1,Xi+2,Xi+3,rki)=Xi⊕ (Y0,Y1,Y2,Y3)=(Y35,Y34,Y33,Y32), 其中以32b为单位的逆序输出是为了加解密的一致性.解密算法与加密算法结构相似,只是轮密钥使用顺序相反.加密时轮密钥的使用顺序为rk0,rk1,…,rk31.解密时轮密钥的使用顺序为rk31,rk30,…,rk0. 密钥扩展算法:SM4算法中加密算法的轮密钥由加密密钥通过密钥扩展算法生成,与加解密流程类似. SM4算法整体结构如图2所示.在算法设计过程中,根据算法功能和加解密流程,将SM4算法的加解密数据输入接口和密钥输入接口都设计在顶层模块,除此之外,加解密运算模块和轮密钥生成模块之间的数据交换也由顶层模块控制.将轮密钥生成模块和加解密模块看成单独的数据处理单元,在顶层控制模块中进行调用,这是第1层原件例化.不管是加解密运算模块还是轮密钥生成模块的非线性迭代,都需要S盒模块的参与,所以S盒模块为第2层的原件例化[14]. 图2 SM4算法整体结构 由SM4算法原理可得,轮密钥是由128b的密钥进行32轮迭代变换而产生的长度为32×128b轮密钥,并且轮密钥的生成只与密钥有关,如果加解密的密钥提前确定,轮密钥就可以提前生成[15]. SM4加密算法的核心就是32轮非线性迭代,无论是由主密钥进行密钥扩展,还是在进行加解密操作时,都需要32轮的非线性迭代. 因为轮密钥生成模块和加解密模块的每轮迭代都需要调用S盒模块,所以S盒的模块设计极为重要.目前SM4算法的S盒设计硬件实现主要有3种方案:第1种是基于BRAM的设计架构;第2种是基于LUT的设计架构;第3种是BRAM+寄存器的设计架构[16].使用LUT实现S盒会消耗大量的LUT资源,LUT是硬件实现中的重要资源,各方面的运算都需要LUT的参与,而使用寄存器会增加额外的时钟时延. 本文的S盒是通过组合逻辑和ROM实现的,使用组合逻辑实现S盒可以节省时钟周期,达到在1个时钟周期内处理更多数据的效果,或者在提高时钟周期的情况下,时序不发生错误.使用ROM实现S盒函数,利用存储资源的地址映射特性,在消耗部分ROM资源的代价下,可以节省大量LUT资源.如图3所示,可以将输入字节a0,a1,a2,a3作为ROM的地址,将ROM的数据输出b0,b1,b2,b3作为S盒模块映射相应的值,并且其中的4B替换的ROM是并行执行的,可以使ROM资源得到充分利用. 图3 S盒并行架构 如图4加密流程所示,当进行加密时,首先由上层控制模块输入128b加密密钥到轮密钥生成模块中,然后轮密钥生成模块根据加密密钥生成32×128b的轮密钥输出到上层控制模块,然后加解密运算模块根据顶层模块输入的明文和轮密钥进行加密处理,在经过32轮非线性迭代运算之后生成密文. 图4 加密流程 其中无论是加密操作还是解密操作,轮密钥生成模块和加解密运算模块只进行数据处理,并不进行加解密逻辑分析和任务切换,加解密逻辑分析和任务切换由顶层模块来控制.当任务切换时,顶层模块需要调用轮密钥生成模块进行密钥的更新.如图5所示,当进行解密操作时,加解密运算模块接受轮密钥的参数为加密时的倒序输入. 图5 解密流程 处理单任务加密时,把任务划分为n个明文分组,每个明文分组大小为128b,每个明文分组为加解密处理的最小单元,每进行32轮非线性加密迭代处理1个明文分组. 单任务加密流水线时空图和结构如图6和图7所示,当单任务(加密任务)到达时,把任务按长度分成n个明文分组,每个明文分组长度为128b,其中rki(i取值范围为0~31)为由密钥生成的轮密钥,生成之后保存在相应的寄存器中.其中第i轮加解密非线性迭代加解密运算原件为Ci(i取值范围为0~31),需要的输入为第i-1轮迭代的输出结果(第1轮运算输入为明文分组)和轮密钥的第i部分rki;把第i轮非线性迭代的结果暂存到寄存器regi(i取值范围为0~31),提供给下一轮非线性迭代运算使用,经过32轮迭代之后生成密文分组,至此128b数据处理结束. 图6 单任务流水线时空图 图7 单任务流水线结构 在第1个时钟周期,密钥生成原件K0,进行第1部分轮密钥的生成处理,将生成的轮密钥rk0存储在寄存器kreg0中,密钥生成原件K1至K31处于空闲状态,密钥加解密原件C0至C31处于空闲状态. 在第2个时钟周期,密钥生成原件K1,进行第2部分轮密钥的生成处理,将生成的轮密钥rk1存储在寄存器kreg1中,密钥生成原件K0,K2至K31处于空闲状态,加解密运算原件C0进行明文分组1的数据处理,其余31个加解密运算原件处于空闲状态,加解密运算原件C0输入明文分组1和保存在寄存器kreg0中的轮密钥的rk0部分,并把运算结果暂存到寄存器reg0中. 在第3个时钟周期,密钥生成原件K2,进行第3部分轮密钥的生成处理,将生成的轮密钥rk2存储在寄存器kreg2中,密钥生成原件K0,K1,K3,…,K31处于空闲状态,加解密运算原件C1继续进行明文分组1的数据处理,加解密运算原件C0进行明文分组2的处理,其余30个加解密运算原件处于空闲状态,加解密运算原件C1的输入为reg0中的第1个周期的加解密运算原件C0的计算结果和保存在寄存器keg1中的轮密钥的rk1部分,并把运算结果暂存在寄存器reg1中,供明文分组1的下个周期下一轮非线性迭代使用,加解密运算原件C0输入明文分组2和保存在寄存器中的轮密钥的rk0部分,并把运算结果暂存在寄存器reg0中,供明文分组2的下个周期下一轮非线性迭代使用. 依此顺序进行下去,在单任务状态下,在第33个周期处理完明文分组1,在第34个周期处理完明文分组2,在第i(i>33)个周期处理结束第i-32个明文分组. 综上所述,当处理单任务加密时,仅需要n+32(n为单任务的明文分组个数,一般远远大于32)个时钟周期就可以处理完1个文件加密. 如图8所示,前i-1个时钟周期只对第1个任务进行加密,处理模式和单任务处理相同,第1个任务将在31个时钟周期之后全部处理结束,在这31个周期内既处理第1个任务也处理新任务,处理流程如下: 图8 面向多任务的轮密钥切换结构 在第i个时钟周期,新的加密任务到来,需要逐步更新轮密钥,进行新加密任务执行,此时旧加密任务已经无需任务1的轮密钥rk0参与,但是还需要rk1至rk31的参与,在第i个时钟周期,密钥生成原件K0的输入为128b的新任务密钥,生成的新的轮密钥第1部分rk0存储在寄存器kreg0中,将任务1的轮密钥rk0更新,加解密运算原件C0处于空闲状态,加解密运算原件C1至C31正在处理旧加密任务; 在第i+1个时钟周期,旧加密已经无需任务1的轮密钥rk1参与,还需要rk2至rk31的参与,密钥生成原件K1输入为寄存器kreg0中128b的新任务的轮密钥rk0,生成新的轮密钥的第2部分rk1存储在寄存器kreg1中,将旧任务的轮密钥rk1更新,加解密运算原件C0的输入为新任务的明文分组k和存储在kreg0中的新任务的轮密钥rk0,输出为明文分组k的第1轮迭代结果,长度为128b,存储在寄存器reg0中,加解密运算原件C1处于空闲状态,加解密运算原件C2至C31正在处理旧加密任务的剩余部分; 依此顺序进行,在第i+31个时钟周期,旧加密任务已经全部处理完,密钥生成原件K31输入为寄存器kreg30中128b的新任务的轮密钥rk30,生成新的轮密钥的第32部分rk31存储在寄存器kreg31中,将任务1的轮密钥rk31更新,加解密运算原件C31处于空闲状态,至此新任务的轮密钥全部更新完毕.在没有新的加密任务到来之前,轮密钥不会发生变化,轮密钥生成模块处于空闲状态. 综上所述,当处理多任务加密时,仅需要n+m+31(n为多任务的明文分组个数,一般远远大于32,m为要处理加密任务的数量)个时钟周期即可处理完m个文件任务加密. 加密与解密的不同之处在于:在进行加密时,每轮非线性迭代加解密运算原件使用轮密钥的顺序依次为rk0,rk1,…,rk31;而在解密运算时,每轮加解密运算原件使用的轮密钥顺序与加密相反,依次为rk31,rk30,…,rk0. 如图9所示,前i-1个时钟周期只对第1个任务进行加密,处理模式和单任务处理相同,第1个任务将在31个时钟周期之后全部处理结束,在第i个时钟周期,收到新的解密任务,进行加解密任务切换,在31个周期内既处理第1个任务,也处理新任务轮密钥的更新,但是不进行解密运算,具体处理流程如下: 图9 面向多任务的加解密流水线结构 在第i个时钟周期,新的解密任务到来,需要逐步更新轮密钥,进行新的解密任务的轮密钥生成,此时加密任务已经无需任务1的轮密钥rk0参与,但是还需要rk1至rk31的参与,在第i个时钟周期,密钥生成原件K0的输入为128b的新的解密任务密钥,生成的新的轮密钥第1部分rk0存储在寄存器kreg0中,将任务1的轮密钥rk0更新,加解密运算原件C0处于空闲状态,加解密运算原件C1至C31正在处理加密任务; 在第i+1个时钟周期,更新解密任务轮密钥的第2部分,此时加密任务已经无需任务1的轮密钥rk0和rk1参与,还需要rk2至rk31的参与,密钥生成原件K1输入为寄存器kreg0中128b的新任务的轮密钥rk0,生成新的轮密钥的第1部分rk1存储在寄存器kreg1中,将任务1的轮密钥rk1更新,加解密运算原件C0和C1处于空闲状态,加解密运算原件C2至C31正在处理加密任务; 依此顺序进行,在第i+31个时钟周期,加密任务的所有明文分组已经处理完,新的解密任务的密钥扩展已经全部完成,加解密运算原件Ci都处于空闲状态,在下一个任务到达之前不会更新轮密钥. 接下来执行新的解密任务: 在第i+32个周期,加解密运算原件C0进行密文分组k的数据处理,其余31个加解密运算原件处于空闲状态,加解密运算原件C0输入密文分组k和保存在寄存器kreg31中的轮密钥的rk31部分,并把运算结果暂存到寄存器reg0中; 在第i+33个时钟周期,加解密运算原件C2继续进行密文分组k的数据处理,加解密运算原件C0进行密文分组k+1的处理,其余30个加解密运算原件处于空闲状态,加解密运算原件C1的输入为reg0中的第1个周期的加解密运算原件C0的计算结果和保存在寄存器kreg30中的轮密钥的rk30部分,并把运算结果暂存在寄存器reg1中,供密文分组k的下个周期下一轮非线性迭代使用,加解密运算原件C0输入密文分组k+1和保存在寄存器中的轮密钥的rk31部分,并把运算结果暂存在寄存器reg0中,供密文分组k+1的下个周期下一轮非线性迭代使用; 依照此顺序执行新解密任务.综上所述处理p个加密任务和q个解密任务需要的时钟周期数为p+32×q+n+32(其中n为所有任务的明文或者密文分组数量). 由第3节的ROM流水线结构可知,流水线中大部分工作是由加解密运算模块完成的,而轮密钥生成模块并不是一直在运算,只有当新任务来临时,轮密钥生成模块才进行密钥更新.SM4算法一般处理的是文件加解密,任务量比较大,当处理10Mb的加密任务时,更新密钥操作只占整个任务处理的1.2%,SM4算法的使用场景往往为大任务的文件加解密,然而轮密钥生成模块和加解密运算模块的资源消耗几乎相同,占整个加密系统资源的47.6%. 所以本节对第3节中的加密流水线结构进行进一步优化,基于SIMD的思想,提出了一个单轮密钥生成、多加解密处理的流水线结构. 图10为1个单轮密钥生成4路加解密的结构,当任务到来时,顶层模块首先把密钥交由轮密钥生成模块进行轮密钥生成,加解密的数据交由加解密运算单元4个加解密运算模块并行处理,由于4个加解密运算模块处理的是1个任务,所以只进行1次轮密钥生成即可. 图10 单轮密钥生成4路加解密结构 以单任务加密为例,如图11和图12所示:在第1个时钟周期,依然是调用密钥生成原件K0进行第1组轮密钥rk0的生成;在第2个时钟周期,调用密钥生成原件K1进行第2组轮密钥rk1的生成,并且调用4个加解密运算模块中的加解密运算原件C0分别对明文分组1~4进行第1轮加密迭代运算,运算结果保存在加解密运算模块相应的寄存器中;在第3个时钟周期,调用密钥生成原件K2进行第2组轮密钥rk2的生成,并且调用4个加解密运算模块中的加解密运算原件C1分别对明文分组1~4进行第2轮加密迭代运算运算,调用4个加解密运算模块中的加解密运算原件C0分别对明文分组5,6,7,8进行第1轮加密迭代运算,运算结果保存在加解密运算模块相应的寄存器中.依此顺序进行,此结构最多1周期可调用4×32=128个加解密运算原件进行运算.综上所述此结构处理单个加密任务所需要的周期数为n/4+32(n为任务的明文分组个数),单轮密钥生成4路加解密流水线结构在处理大任务时将近ROM流水线结构效率的4倍. 图11 单轮密钥生成4路加解密流水线结构 图12 单轮密钥生成4路加解密流水线时空图 该结构在处理多加密任务轮密钥更新和解密任务轮密钥更新时,处理方法与3.4节ROM流水线处理方法相同.基于SIMD思想的单轮密钥生成多加解密流水线结构采用了4个加解密运算模块,相比普通的4核运算,节省36.39%的资源,是使用相同资源进行SM4算法加解密处理的效率的1.6倍. 如表1所示,本文提出的ROM流水线结构资源消耗LUT资源数量为4173,触发器资源数量为2113,存储器个数为128,在时钟频率为300MHz时,吞吐量为40.63Gbps,相比循环型硬件结构使用LUT资源是其6.15倍,触发器资源是其7.88倍,吞吐量是其31.99倍;相比LUT流水线结构,增加了存储器使用数量,但是LUT资源和触发器资源消耗都有明显降低,吞吐量提高了1.33倍;相比BRAM流水线结构,LUT资源是其1.84倍,触发器个数是其42.7%,多使用了95个存储器,吞吐量是其1.46倍;相比BRAM+寄存器流水线结构,LUT资源是其1.30倍,但是触发器个数只是其27.2%,多使用了95个存储器,吞吐量是其96%,在节省了大量资源情况下,吞吐量没有明显下降. 表1 资源消耗和性能对比 基于ROM流水线结构进一步优化,本文提出了SIMD的流水线结构,SIMD流水线结构为单轮密钥生成4路加解密结构时,使用资源仅为ROM流水线结构的2.51倍,吞吐量是ROM流水线结构的3.98倍.基于SIMD思想的单轮密钥生成多加解密流水线结构采用4路加解密比4核ROM流水线结构运算节省36.39%的资源,吞吐量相差无几. 本文提出了一个基于SIMD的国密SM4算法的硬件流水线结构.针对目前软件的安全性和效率以及硬件资源消耗等问题,根据国密SM4算法的特性,设计了一种适用于国密SM4算法ECB模式的基于ROM的流水线结构,相比传统流水线消耗资源更少,对任务切换带来的轮密钥更新问题进行了优化,介绍了单任务处理的工作流程,多任务切换、多任务加解密切换过程中是如何进行轮密钥的更新.并且在此基础上进一步进行优化,基于SIMD的单指令多数据流的思想,提出了一种单轮密钥生成多加解密的流水线结构,使国密SM4算法在ECB模式下进行加解密时的效率有了大幅提升.此结构为相似场景提供了解决问题的思路,本文中设计和实验的结构是1轮密钥生成4路加解密结构,可以根据具体场景设计其他结构,例如1轮密钥生成8路加解密结构等.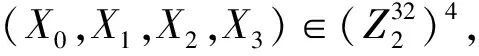
X2⊕X3⊕rk).


(B<<<18)⊕(B<<<24).1.2 加解密算法
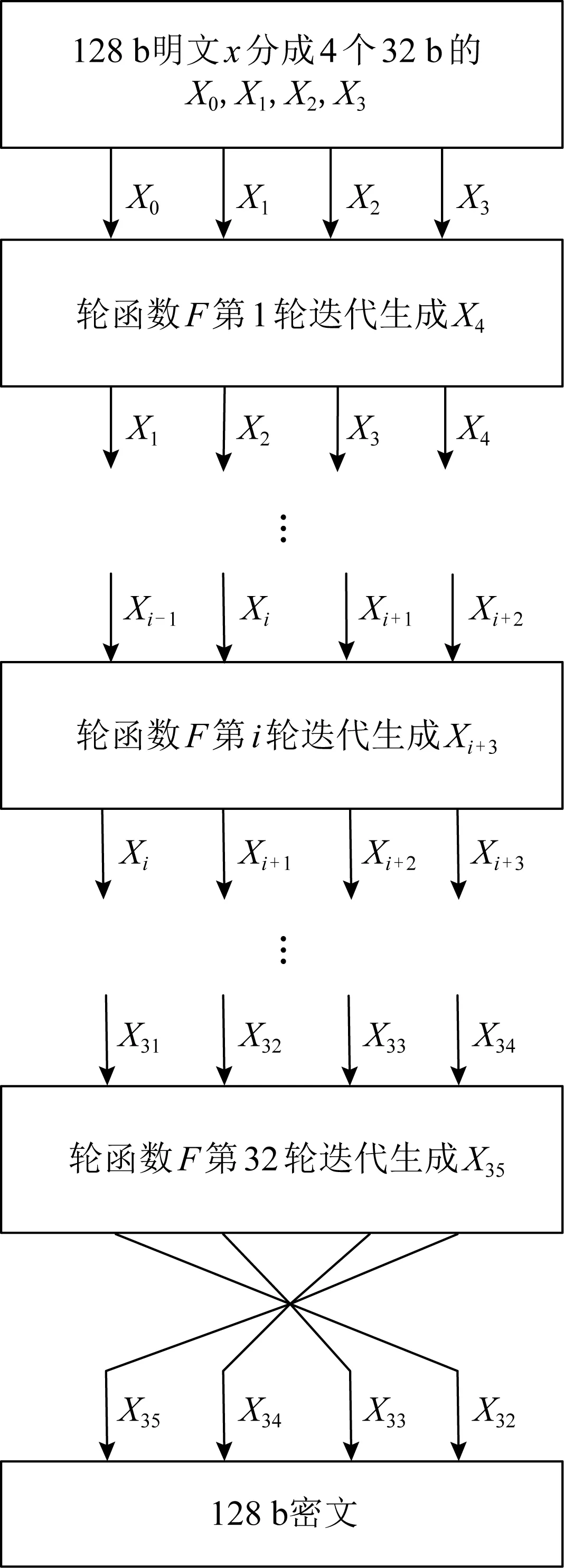
T(Xi+1⊗Xi+2⊗Xi+3⊗rki),2 SM4算法基本硬件结构设计
2.1 基于ROM的并行S盒设计

2.2 加解密基本流程

3 流水线结构设计
3.1 面向单任务的SM4-ECB模式加密流水线结构
3.2 面向多任务的轮密钥切换SM4-ECB模式加密流水线结构

3.3 面向多任务的轮密钥切换的SM4-ECB模式加解密流水线结构
4 基于SIMD思想流水线结构设计
5 实验及数据分析
6 结 语
猜你喜欢
计算机应用(2020年5期)2020-06-07 07:06:44
新少年(2018年6期)2018-08-03 10:27:52
视野(2018年5期)2018-03-29 05:14:36
单片机与嵌入式系统应用(2017年7期)2017-07-31 21:57:23
网络空间安全(2016年3期)2016-06-15 20:27:07
电子技术应用(2016年6期)2016-03-18 05:41:13
软件工程(2014年11期)2014-11-15 20:02:46
出版广角(2014年15期)2014-08-30 12:14:37
电脑知识与技术(2013年7期)2013-04-29 00:44:03
网络安全与数据管理(2011年24期)2011-08-08 02:31:52
