
基于正则化损失的MeshNet半监督分类
2023-09-05 02:04吕帅君洪沛霖
合肥工业大学学报(自然科学版) 2023年8期
吕帅君, 邢 燕, 洪沛霖
(1.合肥工业大学 数学学院,安徽 合肥 230601; 2.安徽中医药大学 医药信息工程学院,安徽 合肥 230012)
三维形状的获取越来越容易,这对三维物体分类的发展至关重要,目前的主要方法大都依赖卷积神经网络解决三维物体的分类问题。卷积神经网络通过提取物体的各种高维特征对物体进行分类预测。
对于三维形状,有几种比较流行的数据类型:体素[1]、点云[2]、多视角图片[3]和网格[4]。体素在概念上类似于二维空间中的像素,可以看作数据在三维空间中的最小单位。体素表示法是一种规格化的表示方法,但其分辨率的限制导致很多细节缺失。点云是三维坐标系中点的集合,可以表示物体的外表形状;除了最基本的位置信息以外,也可以在点云中加入其他信息,如点的色彩信息等。但由于点与点之间没有连接关系,点云表示方法缺少物体的表面信息。多视角图片(简称多视图)是通过不同视角的虚拟摄像机从物体模型中获取的二维图像的集合。多视图通常需要使用比较多的图片来构建完整的三维模型,在固定图片数量的情况下,容易受到物体自遮挡等因素的影响。网格是由一组多边形表面组成的非结构化数据,目前最普遍使用的是三角网格。多边形网格通过一种易于渲染的方式表示三维物体模型,在三维可视化等领域有很大作用。
近年来,随着神经网络的发展和显卡硬件设备的升级,深度学习在识别、分类、数据挖掘、机器翻译、自然语言处理、语音处理、计算机视觉等领域都取得了很多成果,解决了很多复杂的模式识别难题,甚至在某些领域的识别能力超过人类。卷积神经网络在三维网格处理上的应用也越来越多。文献[4]提出了一种学习网格信息的卷积神经网络,它将面作为最小单元,定义了共享边的面之间的连接,使得网络能够通过逐面处理解决网格数据的复杂性和不规则性;文献[5]提出了一种基于边的能够简化网格模型用于三维网格分类和分割任务的卷积神经网络。
深度学习的成功得益于几十年积累的海量数据,但是对于很多特定任务的标签,数据并不充足,而且获取也相当困难,因此研究半监督、弱监督和无监督学习很必要。弱监督学习[6]是已知数据和其一一对应的弱标签,训练一个智能算法,将输入数据映射到一组更强的标签的过程。半监督学习[7]是指已知部分数据对应的标签,另一部分数据的标签未知,训练一个智能算法,学习已知标签和未知标签的数据,将输入数据映射到标签的过程。
受到弱监督的图像分割任务[8-9]的启发,本文针对半监督三维网格数据的分类问题,在文献[4]的全监督MeshNet网络的基础上,利用网格数据的结构相似性和几何一致性,在一般的交叉熵损失函数中加入正则化损失。这一针对网格分类任务的正则化损失的设计,有效提高了网格分类的准确率。
1 本文方法
三维形状的网格数据包括顶点、边和面,边由2个顶点确定,封闭的边组成面。文献[4]将面看作最小处理单元,并将面的特征分为空间特征和结构特征。空间特征用三角形的中心点坐标表示;结构特征包括三角形中心点到3个顶点的角向量、三角形的单位法向量和三角形邻域面的索引,如图1所示。
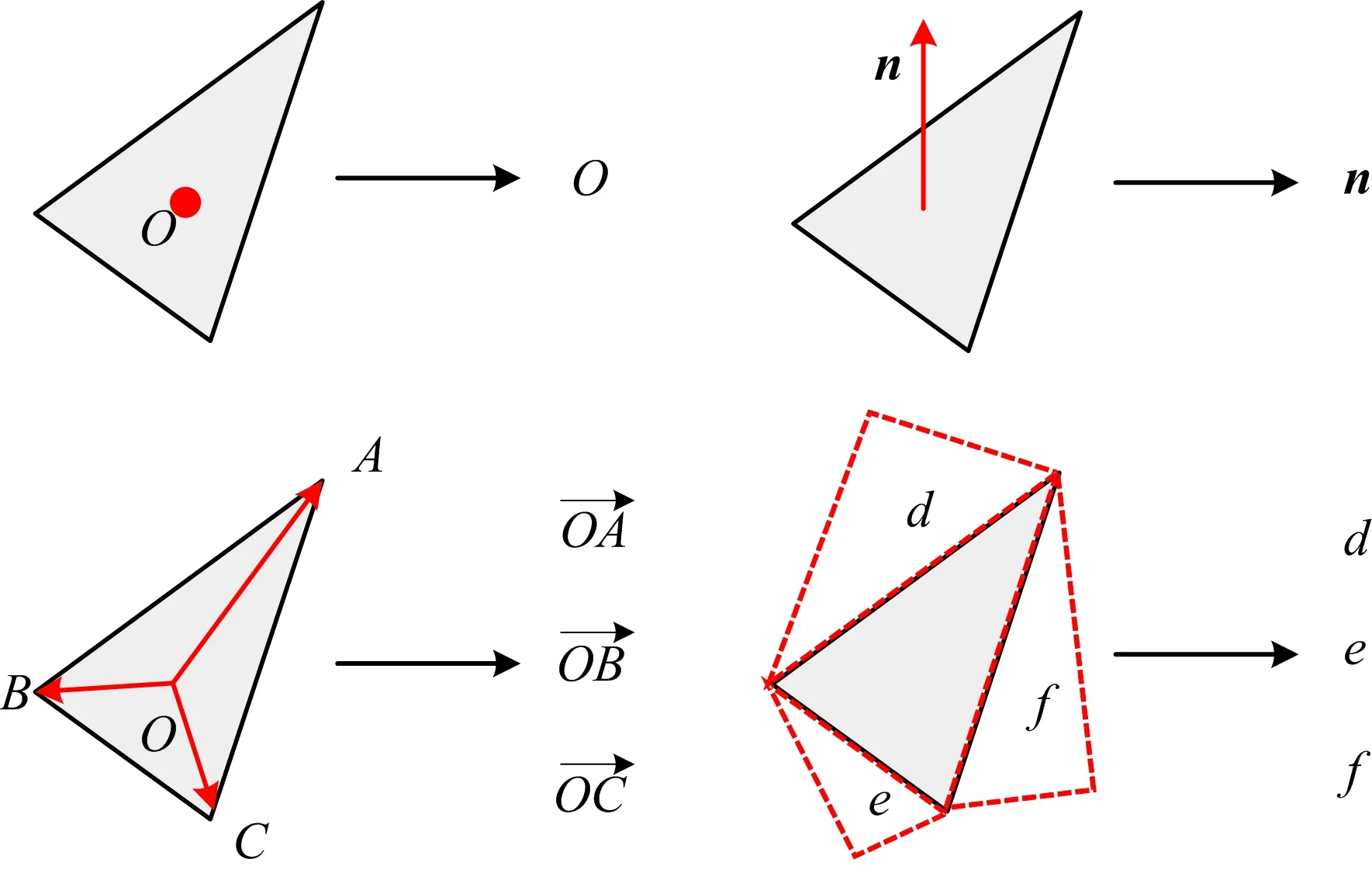
图1 三角面的各种特征
文献[4]是在全监督的情况下对数据集进行分类,本文针对标签数据不足的半监督情况,增加正则化损失,提高分类准确率。为了测试本文提出的正则化损失在不同标注数据比例下的效率,对10%、30%、50%、70%、90%的标注数据均进行了实验。实验结果表明,增加的正则化损失可使在各种标注比例的数据集上训练所得的模型获得更高的分类准确率。
1.1 网络结构
本文采用MeshNet网络,网络架构如图2所示。
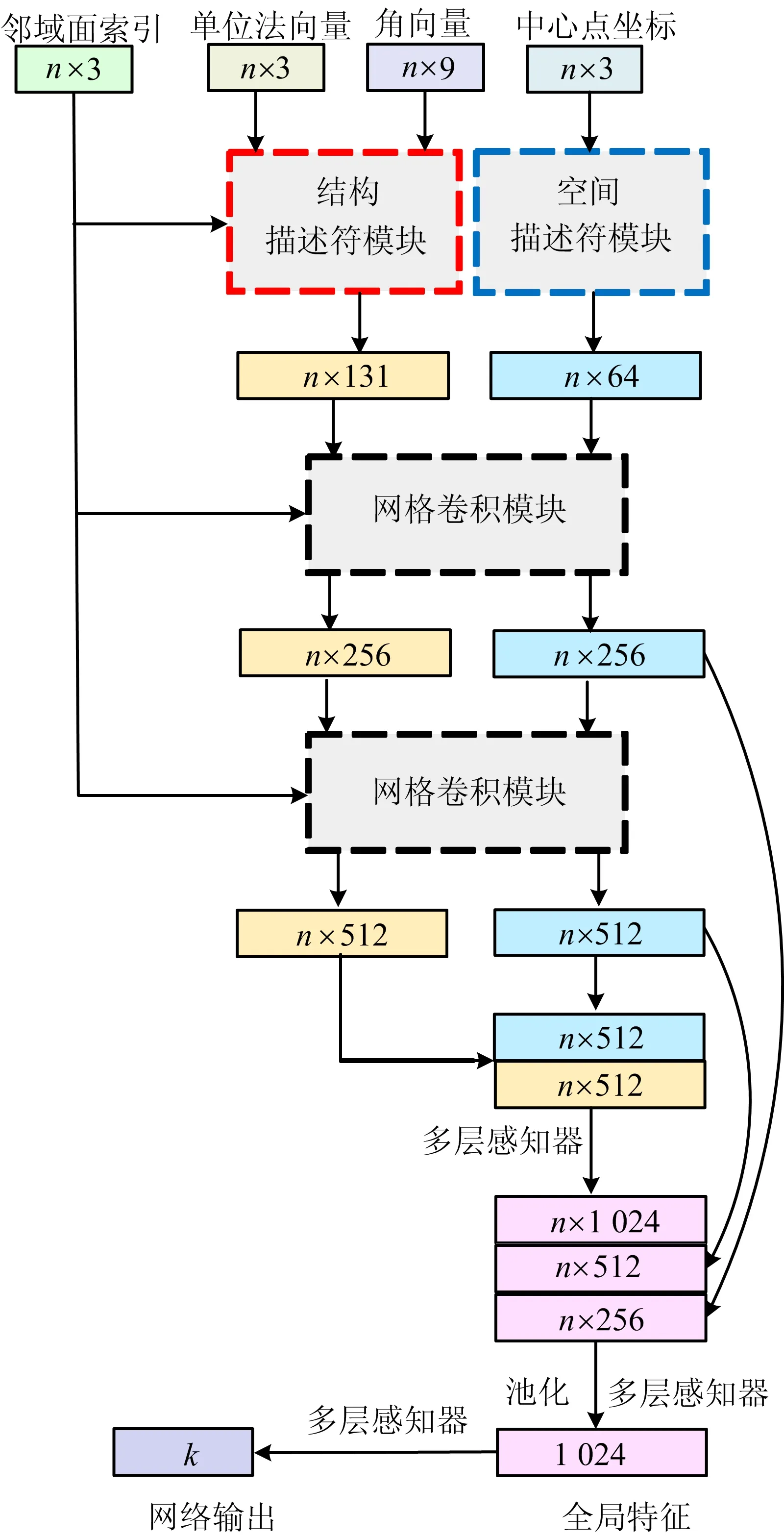
图2 MeshNet网络架构
网络的输入是三角面相关的一系列初始值,如三角形中心点坐标、单位法向量、角向量、邻域面索引(图1)。经过空间描述符模块和结构描述符模块产生初始的空间特征和结构特征。随后这些特征与邻域面索引被聚合到网格卷积模块,并输入到一个池化函数中,输出用于后续任务的全局特征。
与空间位置相关的初始值是中心点坐标。在空间描述符模块中,对每一个中心点坐标简单地应用一个共享的多层感知器,输出初始的空间特征,如图3所示。

图3 空间描述符模块
结构描述符模块比较复杂,包括面的旋转卷积和核相关操作。面旋转卷积(face rotation convolution, FRC)考虑面的形状信息,获取的是面的内部结构,而面核相关(face kernel correlation, FKC)考虑面的周围信息,获取的是面的外部结构。
FRC模块以面的角向量作为输入,假设面的角向量分别为v、v2和v3,则FRC模块的输出定义如下:
(1)
其中,f(·,·):R3×R3→RK1和g(·):RK1→RK2是由待学习的权值形成的函数,K1、K2分别表示函数f(·,·)和g(·)输出的维度。
FKC模块将面的单位法向量和邻域面索引作为输入,计算面和可学习的核之间的相关性。第i个面和第k个核之间的核相关定义如下:
(2)
其中:|Ni|为第i个面和它的邻域面的法向集合的元素个数;|Mk|为第k个核中法向集合的元素个数;核函数Kσ(·,·):R3×R3→R度量2个向量的亲和度,实验选用高斯核函数。核相关可以挖掘网格中的局部结构[10-11]。
网格卷积模块包括空间特征与结构特征的联合部分和结构特征与邻域特征的聚合部分。空间特征与结构特征的联合是将它们串联起来并使用1个多层感知器来生成新的特征。结构特征与邻域特征的聚合是先将结构特征与3个邻域面特征分别串联,并经过1个共享的多层感知器处理,再对结果应用最大池化得到新的特征。
1.2 正则化损失
深度学习中,正则化项有防止过拟合、提高泛化能力的作用。当模型参数过多时,网络会发生过拟合,即对训练数据拟合得很好的模型通常无法很好地拟合测试数据。一般地,过于复杂的模型会引起过拟合,此时模型泛化能力比较低;相反,模型相对简单时,模型拟合能力较低,而泛化能力相对较高。引入正则化项是利用人们对问题的认识和对解的估计的先验知识。先验知识增加了对模型的限制,可以降低模型的方差,提高模型的稳定性,但也会使模型的偏置增大。偏置与方差之间的权衡是机器学习的基本主题之一。
本文利用“特征相似的网格更加可能属于同一类别”这样的先验知识提高分类准确率。网络学习得到的特征向量包含网格可用于分类的各种结构特征和空间几何特征,利用特征向量差值的L2范数的平方来度量不同网格之间的差异。正则化损失定义如下:
1‖yi-yj‖≥δexp(-‖fi-fj‖2)]
(3)
其中:y为预测的分类概率向量;f为网络学到的网格特征向量;fi和fj分别表示从网络模型得到的第i个和第j个网格的特征向量;yi和yj分别表示第i个和第j个网格的网络预测输出(属于不同类别的概率向量);1‖yi-yj‖<δ、1‖yi-yj‖≥δ是指示函数,分别表示条件‖yi-yj‖<δ和‖yi-yj‖>δ为真时等于1,否则等于0;δ为区分是否属于同一类别的阈值。
模型最终的损失函数如下:
l=D(y,g)+λR(y,f)
(4)
其中:D(y,g)为数据项,是预测结果y与真实标签g之间的交叉熵损失;R(y,f)为式(3)定义的正则化项;λ为平衡因子,用来平衡数据项和正则化项,λ越大,正则化项的作用越大,不同的λ值会导致不同的分类结果。根据经验,实验中设置λ=5×10-6。
1.3 模型的实验设置
本文模型使用的数据集来自文献[1]的ModelNet40数据集,数据集包括来自40个类别的12 311个网格模型,其中9 843个用于训练,2 468个用于测试。为了统一输入数据格式,每个网格被简化或扩充为1 024个面的网格,再被平移到网格的几何中心并归一化到单位球内。训练过程中,通过一个均值为0、标准差为0.01的高斯噪声抖动顶点位置来增强数据。
模型训练采用的优化算法为随机梯度下降法,初始学习率为0.01,动量为0.9,学习率的衰减率为0.000 5。设置最大epoch次数为150,批大小为64。
本文实验在Python3.6,Intel(R) Core(TM) i9-9900K CPU @3.60 GHz×16, RAM 32 GiB和Nvidia RTX 2080Ti GPU环境上运行的。
2 实验结果与讨论
2.1 数值指标
关于分类的数值指标,本文选用常见的准确率(accuracy)和平均精度均值(mean average precision,mAP)。
首先引入4个符号:
TP:预测正确的正例样本个数;
TN:预测正确的负例样本个数;
FP:标签为负例,被错分为正例的样本个数;
FN:标签为正例,被错分为负例的样本个数。
准确率(A)是正确分类(即预测与标签一致)的样本数与样本总数之比。对于某一类别,计算公式如下:
(5)
其中:分子是预测正确的样本数,包括预测正确的正样本数TP和预测正确的负样本数TN;分母为样本总数,包括预测正确的样本数(TP+TN)和预测错误的样本数(FP+FN)。
平均精度均值(用mAP表示)指标需要先定义查准率和召回率:
P=TP/TP+FP
(6)
R=TP/TP+FN
(7)
其中:P为查准率(precision),表示真实的正例占预测为正例的样本比例,它针对预测为正例的结果;R为召回率(recall),表示被正确预测的正例占总正例的比例,它针对正例标签的样本。
平均精度(average precision,AP)的定义如下:
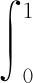
(8)
其中,P(R)为系统在召回率为R时的查准率。
因为实验中的样本一般为离散量,所以求解AP的积分一般用离散求和形式替代,具体表达式为:
(9)

mAP可表示K个类别的AP均值或K次查询的AP均值,定义如下:
(10)
2.2 对比实验
实验中,将本文方法与以往有代表性的方法作对比,结果见表1所列。本文方法使用了与MeshNet相同的实验参数设置,其他对比方法沿用了其论文中最高性能的参数设置,表1中的数据有些直接摘自其发表的论文。由于MeshNet网络架构充分利用了网格的空间特征和结构特征,加上精心设计的先验损失,本文所提的分类方法在全监督分类性能上比以往方法都有所提升,既远远超出传统的基于网格的SPH方法[12]和基于多视图的LFD方法[13],又能与基于体素的3DShapeNets[1]、基于点云的PointNet[2]、基于多视图的MVCNN[3]和基于网格的MeshNet[4]等深度学习的方法相媲美。

表1 ModelNet40数据集上的分类性能比较 %
为进一步验证所提的正则化损失的有效性,本文对ModelNet40数据集选择不同的标注比例进行半监督实验,实验结果的2种数值指标分别见表2和表3所列。

表2 ModelNet40数据集上半监督分类的准确率 %

表3 ModelNet40数据集上半监督分类的mAP指标 %
同时,表2和表3也给出了消融实验的结果用以对比。从表2和表3可以看出,增加的正则化项在不同比例的标注数据下都提高了分类准确率。
3 结 论
本文针对半监督三维网格数据的分类问题提出一种基于正则化损失的MeshNet半监督分类方法,利用数据的结构相似性和几何相似性提高了分类准确率,多种量化指标都优于仅用交叉熵损失的分类。本文所提的分类方法不仅适用于网格分类问题,而且在网格分割、网格去噪、图像处理、语音处理等领域均可以使用。在后续的工作中,将探讨超参数的设定,如式(3)中δ的选取,并探索设计更好的与任务相适应的先验项来提高网络性能。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
数学年刊A辑(中文版)(2019年1期)2019-01-31
数学杂志(2018年5期)2018-09-19
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
北京航空航天大学学报(2018年1期)2018-04-20
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
数学年刊A辑(中文版)(2014年5期)2014-11-01
