
基于CT 组学特征的肺部病变良恶性诊断模型构建研究
2023-09-05 09:27张瑞平陈亚正王志震罗延安
医疗卫生装备 2023年7期
张瑞平,陈亚正,陈 扬,王志震,罗延安,江 波*
(1.天津医科大学肿瘤医院,国家恶性肿瘤临床医学研究中心,天津市恶性肿瘤临床医学研究中心,天津300060;2.四川大学华西第二医院肿瘤放化疗科,成都610041;3.南开大学物理学院,天津300050)
0 引言
肺癌是中国乃至全球癌症相关死亡的主要病因,虽然新技术不断应用,但其总生存率仍不容乐观[1]。由于受肺癌影响的人数众多,在可能治愈的早期阶段提高诊断水平将对人类健康产生重大影响,尤其是对于肺部病变的早期筛查,这是进行适当临床管理的前提,可以避免过度治疗和医疗资源的浪费。因此,肺癌的早期诊断已经成为临床医生关注的难点和焦点[2-3]。近年来,基于CT 影像的组学特征作为一种定量诊断方法已引起高度关注,同时为CT 影像的精准诊断带来了潜在的希望[4-5]。组学特征是通过高通量、非侵入的方式从已有的医学图像中提取病变组织的信息,并将这些信息转化为高维数据[6],能在在体情况下反映整个病变组织的空间异质性。使用统计学方法筛选有价值的特征,利用机器学习方法创建模型,可深入解析临床信息,指导临床实践。张利文等[7]从公开数据中收集916 例肺癌患者的CT 影像,共筛选出20 个有诊断价值的组学特征,并采用支持向量机(support vector machine,SVM)创建肺部肿瘤良恶性质的诊断模型,在训练集和测试集中,模型的准确度分别为82.4%和77.7%[8]。组学特征在鉴别肺癌病理亚型方面存在潜在能力,有研究报道[9],采用逻辑回归模型,基于影像组学特征对周围型肺腺癌和鳞癌进行区分,以7∶3 比例将样本量分为训练集和测试集,其诊断性能指标AUC 值为0.879。Choi 等[10]研究表明,基于放射组学,以8∶2 比例将样本量分为训练集和测试集,利用支持向量机方法对肺部结节的性质进行诊断,其准确率可达84.6%。组学特征在鉴别肺结节良恶性方面也存在潜在能力,研究发现[11],组学特征中的共生矩阵特征在鉴别肺结节性质方面具有良好的性能。兰欣等[12]以综述的形式探讨机器学习在医疗领域中的应用现状,其中支持向量机使用的频率最高,其基本思想是在高维空间中寻找一个最优超平面二分类分割问题,在处理复杂的数据集中具有一定的优势。
基于此,本研究充分挖掘单中心、回顾性的有限样本,基于多组别的组学特征,使用五折交叉验证,利用3 种经典机器学习方法(逻辑回归、随机森林和支持向量机),构建区分肺部病变良恶性的诊断模型,并分析比较3 种模型的诊断性能,选出最优模型,旨在快速识别和创建简单而有效的稳健诊断模型。
1 资料与方法
1.1 患者资料
回顾性分析2014 年1 月至2016 年1 月在我院行增强CT 扫描的肺部病变患者的资料。纳入标准:活检或术后有明确的组织病理报告。排除标准:病变组织中含有钙化、空腔、气泡和支气管肺泡性肺炎;病变组织的三维体积≤1 cm3;病变组织侵袭至胸壁、纵隔或心包。同时收集患者的基本资料,包括性别、年龄、吸烟状况、活检病理报告或术后病理报告以及CT 图像。
1.2 图像获取
整理纳入本研究的135 例患者的CT 影像资料,图像层厚为3.75 mm(120 kVp,100 mA),体素为0.98 mm×0.98 mm×3.27 mm。将图像数据以DICOM标准格式传输至专业放射组学平台(Radcloud,Version 2.1.1.2),同时匿名化处理图像中患者的个人信息。
1.3 感兴趣区(region of interest,ROI)勾画和放射组学特征提取
由2 位高年资医学影像医师勾画ROI,即病变部位,应避开邻近病变组织的血管、胸壁和纵隔组织[13]。对于边界模糊的ROI,先利用治疗计划系统的自动分隔方法对ROI 进行初步描绘,然后进行手动修改,以最大限度地避免操作者间的差异性和较低的重复性。
为了在提取组学特征之前消除医学图像的差异和各向异性,本研究首先对CT 图像进行标准化处理,并重新采样为1 mm×1 mm×1 mm。共提取1 029 个组学特征,分为一阶强度特征(first-order features)、形状特征(shape features)和纹理特征(texture features)。其中,纹理特征包括灰度共生矩阵(gray level cooccurrence matrix,GLCM)、灰度运行长度矩阵(gray level run length matrix,GLRLM)和灰度尺寸区域矩阵(gray level size zone matrix,GLSZM)3 个亚组别。所有组学特征的定义及公式可参考https://pyradiomics.readthedocs.io/。
1.4 组学特征选择并构建诊断模型
为了构建稳定且重复性好的诊断模型,同时考虑有限的样本量,本研究采用交叉验证法进行组学特征筛选、模型训练和模型验证。首先,使用五折交叉验证将样本随机分为5 个相等大小的子集,其中1 个子集用作测试集,其余4 个子集作为训练集,分别重复5 次以确保5 个子集的每1 个子集仅1 次作为测试集。训练集和测试集均经过特征标准化、特征选择和模型构建3 个过程,具体过程如下。
1.4.1 特征标准化
放射组学特征进行筛选之前,首先对所有特征值进行标准化处理,即每个组学特征减去其均值,然后除以标准差。具体公式如下:
式中,i为第i个特征;j为第j个患者;Xij'为标准化后的特征;Xij为初始特征;μi和σi分别为初始特征的平均值和标准差。
1.4.2 特征选择
在筛选组学特征过程中,首先采用最小绝对收缩和选择(least absolute shrinkage and selection operator,LASSO)方法[14]选择有诊断价值的特征。LASSO 方法在处理高维度和冗余的特征时表现出色,能够在保留特征本质的同时缩减特征数量。在该方法中,最优正则化系数是通过在训练集上进行十折交叉验证和最小均方差确定的。最终的组学特征则为LASSO 方法中非零系数所对应的特征。为了避免过拟合现象,本研究采用正向选择方法对组学特征进行进一步的筛选。从无特征开始,根据LASSO 模型中特征系数的绝对值从大到小的顺序,逐步添加特征。当模型的预测结果稳定后,停止添加特征,以达到特征筛选的目的。
1.4.3 模型创建
基于选择的组学特征,分别使用逻辑回归、随机森林和支持向量机3 种经典的机器学习方法构建肺部病变良恶性的诊断模型。该模型的创建过程是在Anaconda 平台上(https://www.anaconda.com/)利用scikit-learn 程序包(https://scikit-learn.org/)完成,在模型训练中使用的超参数如果无特殊说明均为程序的默认值。
1.5 统计学分析
采用AUC 值、准确率、敏感度和特异度指标评估模型的诊断能力。预测良恶性的临界值由Youden 指数的最大值确定[15],该值对应ROC 曲线上距离对角线最远的曲线。同时,本研究还使用Delong-test 检验方法[16]对基于逻辑回归、随机森林和支持向量机创建的模型进行比较和分析。对于患者临床信息统计,连续变量(例如年龄)用平均值±标准差表示,类别变量(病理类型、性别和吸烟状态)用百分比表示。双尾P值小于0.05 认为差异具有显著统计学意义。
2 结果
2.1 患者资料
共135 例肺部疾病患者纳入本项研究,平均年龄为(58±11)岁,年龄范围为17~85 岁,其中87 例男性(64%)、48 例女性(36%),40%患者诊断为良性病变,60%患者诊断为恶性病变。本研究中良性病变54例,其中肉芽肿性病变23 例(17.0%)、炎性假瘤29例(21.5%)、血管瘤1 例(0.7%)、纤维细胞瘤1 例(0.7%);恶性病变81 例,鳞状细胞癌22 例(16.3%)、腺样细胞癌48 例(35.6%)、大细胞癌7 例(5.2%)、鳞状和腺样细胞癌混合癌2 例(1.5%)、弥漫性大B淋巴瘤1 例(0.7%)、胸腺瘤1 例(0.7%)。
2.2 放射组学特征
五折交叉验证中,按照出现的频率计数,确保频率数至少为1,共筛选出10 个具有潜在诊断价值的组学特征。形状特征“SurfaceVolumeRatio”每次交叉验证均出现,频率计数为5,强度特征“RootMean-Squarel”频率计数为3,其余的8 个组学特征频率计数均为1。10 个组学特征的频率计数统计结果如图1 所示。

图1 五折交叉验证中组学特征的频率图
2.3 模型诊断能力
在构建诊断模型时,采用了逻辑回归、随机森林和支持向量机3 种方法。在不同分组中,这些模型的平均AUC 值分别为0.747、0.771 和0.820,平均准确率分别为0.688、0.696 和0.740,平均敏感度分别为0.690、0.691 和0.740,平均特异度分别为0.685、0.704 和0.740。同时,在合并五折交叉验证后,各分组的AUC 值分别为0.740、0.762 和0.790。
表1 详细列出了3 种诊断模型的评价结果,图2 展示了3 种诊断模型以及各分组合并后的诊断结果。通过统计分析,发现3 种诊断模型在诊断能力上差异无统计学意义(P>0.05)。
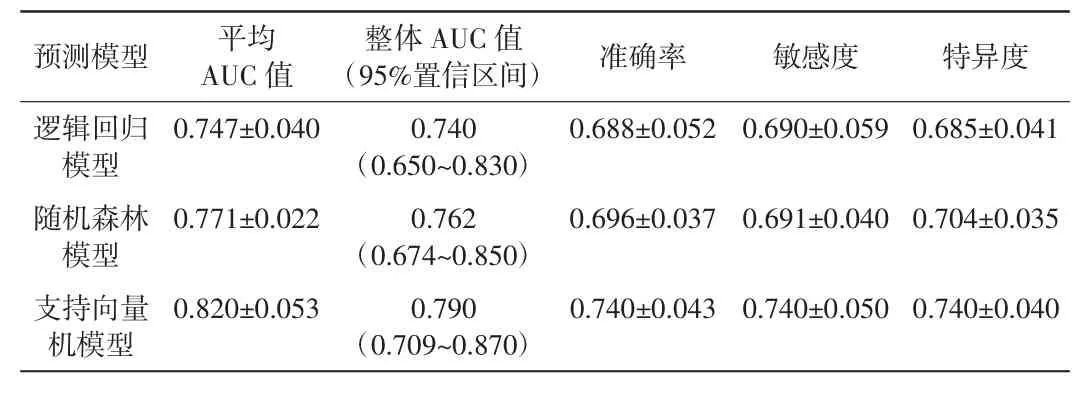
表1 3 种模型诊断性能对比
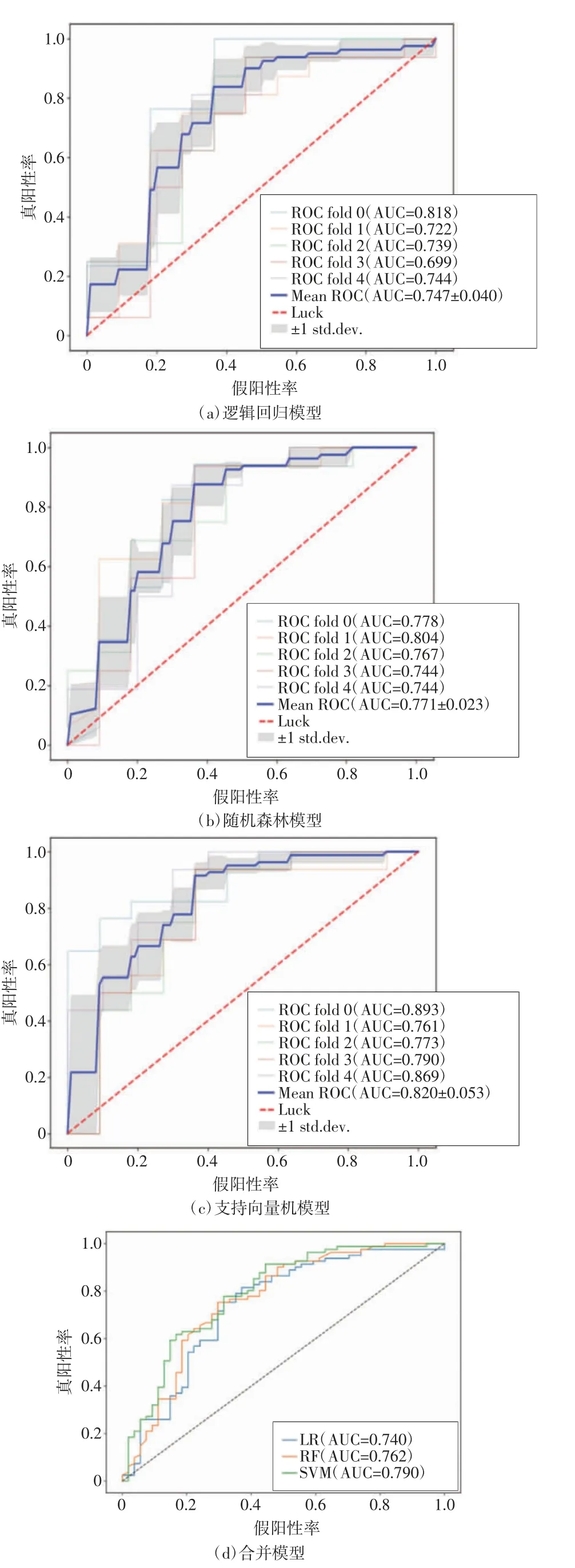
图2 3 种机器学习方法创建的诊断模型比较
3 讨论
本研究采用随机森林、逻辑回归、支持向量机3种临床常用方法,根据在交叉验证中出现的频率计数选择有潜在诊断价值的组学特征,从而构建诊断模型用以区分肺部病变的良恶性。结果表明,该模型对肺部病变的良恶性具有一定的预测能力。本研究方法具有一定的优势:(1)提取多种组别的组学特征,包括强度特征、形状特征和纹理特征;(2)Berenguer等[17]在回顾性研究中发现,组学特征易受各种干扰因素影响,尤其纹理特征表现出较大的不稳定性,为了尽可能避免出现不稳定的特征,本研究分两步筛选组学特征,以防将冗余特征和不稳定特征纳入模型中,导致模型的不确定性;(3)对于单中心的回顾性研究,一般情况下,小样本量居多,为了最大化挖掘有限的数据,同时确保研究结果的重复性和稳定性,使用五折交叉验证等量分割成子集,循环使每1个子集充当1 次测试集。
3 种模型诊断能力虽不存在统计学上的显著性差异,但根据评估指标,从高到低的排序为支持向量机、随机森林、逻辑回归,支持向量机方法的性能稍加突出(见表2,如图2 所示)。这种现象的出现可能与支持向量机本身的特点有关。支持向量机是一种有效的监督式机器学习方法,特别适用于有限样本量和高维空间的情况。为了避免过拟合,支持向量机使用多个训练样本,并基于特定的核函数和惩罚参数构建决策函数。与此相关的研究结果与兰欣等[12]的研究所得出的统计分析结果一致。在临床实践中,支持向量机方法被广泛应用;随机森林方法是一个集成分类器,基于产生的多个决策树进行整合预测,样本量越多预测结果越准确[3];逻辑回归方法具有简单和可操作性强的特点,虽然能广泛地应用于临床研究,但如果处理小样本容易出现过拟合现象。
有研究利用支持向量机构建一种区分肺部病变良恶性的诊断模型,从中提取60 个组学特征,并采用最小冗余最大相关方法筛选特征,最终选择了20个有预测价值的组学特征,该诊断模型显示出较好的性能,其在训练集和测试集上的阳性预测率分别为82.5%和87.6%[8],阴性预测率分别为82.2%和65.9%。该研究在进行特征筛选时无形中纳入了冗余特征,使得测试集的阴性预测率远低于训练集。Petkovska等[11]研究显示组学特征中的共生矩阵特征在诊断能力方面优于其他类型的特征。共生矩阵特征能够分析组织内部像素与像素之间的距离和方向特性,对于结节而言,通常其空间位置和形状特征不太明显。类似地,Choi 等[10]对72 例肺部结节良恶性的研究发现,在103 个组学特征中,仅纹理特征和强度特征存在显著的统计学意义(P均<0.001)。该研究基于这2类特征,采用支持向量机方法构建了诊断模型,结果表明该模型具有较高的诊断能力(AUC 值为0.89,准确率为84.6%)。然而,本研究发现,与其他10 个组学特征相比,形状特征“SurfaceVolumeRatio”最有价值。这种情况可能是因为对于小尺寸的结节,形状特征在其上的表达可能不够明显,但在早期阶段,肺部病变体积在临床上相对于结节尺寸更具意义。此外,本研究还发现,采用3 种方法构建的模型中,支持向量机模型的平均AUC 值(0.820±0.053)与文献[8,10]中的研究结果相似,进一步证实在3 种经典机器学习方法中,支持向量机具有一定的优势。因此,根据目前的研究结果,在区分肺部结节良恶性时,能够解析组织内部结构的纹理特征显示出显著的标志性,而区分肺部病变良恶性时,形状特征起到主导作用。这些发现为临床实践提供了有价值的指导。
本研究为一项回顾性研究,包括了不同病理类型的良性和恶性患者。然而,样本量相对较小,数据分布不均匀。虽然本研究提供了大量的CT 图像,但设备设置参数不仅在不同机构之间存在差异,还在同一机构的不同患者之间存在变化。在从CT 图像中提取放射组学特征时,需要考虑特征的可靠性、重复性,以及扫描参数和层厚等成像参数对预测结果的影响。为减少特征的不确定性和不稳定性,本研究采用了五折交叉验证,进行了图像预处理,包括归一化和自动分割病变区域。未来,为了更好地将研究成果泛化应用于临床实践,需要在图像采集、重建设置、分割方法以及组学特征分析等方面进一步标准化。此外,还需更加关注肺部病变不同病理类型的数据平衡问题,以提高模型的可靠性和普适性。
猜你喜欢
云南医药(2021年3期)2021-07-21
甘肃科技(2020年20期)2020-04-13
中国临床医学影像杂志(2019年5期)2019-08-27
国际口腔医学杂志(2019年3期)2019-05-31
天然产物研究与开发(2018年2期)2018-04-04
分子影像学杂志(2015年3期)2015-12-04
医学研究杂志(2015年11期)2015-06-10
中国卫生标准管理(2015年8期)2015-01-26
科技经济市场(2014年5期)2014-09-09
西南军医(2014年4期)2014-01-19
