
融合信任度的神经网络推荐算法
2023-09-04 09:22:58姜久雷潘姿屹李盛庆
计算机应用与软件 2023年8期
姜久雷 潘姿屹 李盛庆
(常熟理工学院计算机科学与工程学院 江苏 苏州 215500) 2(北方民族大学计算机科学与工程学院 宁夏 银川 750021)
0 引 言
在这个信息激增的大数据时代,数以亿计的用户每时每刻都会面对指数级增长的数据信息。如何使用户快速、有效地从冗余信息中获取自己所需的相关信息,是推荐系统发展的重中之重。推荐系统的核心内容是对推荐算法的不断改进,最早的推荐算法是在20世纪90年代研发中心Xerox Plo Alto开发出的名为Tapestry[1]的软件,目的是协助用户从琳琅满目的邮件中快速找到自己最需要的邮件,协同过滤由此而生。推荐算法经过20多年的积累与沉淀发展至今,已经成为了拥有众多研究成果与应用的热点领域。
应用于社交网络的推荐系统中,朋友之友(FOAF)是最热门的项目之一,近期研究工作表明用户更加倾向于选择有社交信任关系的推荐系统[2],同时偏爱用户个人所认识和信任用户的推荐,因此信任度高的用户引导其他用户访问与其兴趣相关的项目的可能性更大。就此,用户-用户之间的信任问题可以作为数据化社交信息的一个重要依据[3]。文献[4]将用户社交信任加入到构建用户特征模型中,利用概率矩阵分解来预测用户-项目评分。文献[5]在传统用户-项目矩阵分解中引入用户信任特征矩阵,以便提高推荐精度。
在学科融合的推进下,推荐算法与其他热门学科交互发展,其中较前沿的方法是基于深度学习的推荐算法[6]。由于深度学习模型可以拟合非结构化的数据,从中学习隐式表示提取可辨识的特征,将深度学习模型应用到推荐系统中,将推荐问题看作序列化的问题求解,通过学习用户之间的历史交互分布来预测推荐内容。目前已有很多深度学习推荐方法将序列数据建模应用于推荐算法中,例如基于RNN、CNN[7]等的深度神经网络模型,其中最具代表性的就是神经网络协同过滤方法,在深度学习推荐算法发展历程中的一大里程碑事件是由He等[8]提出的利用形式化用户协同过滤的神经网络结构提取隐式数据的NCF框架,通过将传统内积替换成神经结构优化模型对用户-项目数据表示的学习效率,从而改善推荐性能。此后,Bai等[9]首次将邻域信息融合到NCF方法中,很大程度上提升了隐式信息的推荐性能。文献[10]针对神经网络协同过滤中使用大量模型训练参数而导致模型过拟合问题提出了改进的IFE-NCF框架,通过引入隐式反馈嵌入模型增加对项目-项目之间相关性的建模,以便对冷启动用户做合理的推荐。目前越来越多的研究者将深度学习与推荐算法相结合,虽然这种混合推荐算法对于提升推荐性能非常有效,但也存在一些弊端:1) 深度学习方法将所有用户-项目特征一并训练,其中存在大量无相关参数,导致引入噪声降低推荐性能[11];2) 众多基于神经网络的推荐算法只考虑用户-项目的序列特征,而忽略了用户-用户之间的关联表示,对用户间的信任度考虑欠佳[12];3) 社交网络的数据结构多以节点或序列形式记录,往往导致网络泛化能力较差,所提取的特征映射复杂,难以进行后续操作[13]。
针对上述问题,本文提出一种融合信任度与注意力机制的协同过滤算法T-NAMF(Trust degree based on Neural Attention and Matrix Factorization network model)。该算法引入信任关系,考虑推荐内容的隐式相关表示;通过构建融合广义矩阵分解块和全连接块的信任模型,采用协同过滤方法训练用户-项目、用户-用户的信任度;突出注意力模块的预测权重,以提高用户信任关系的动态学习效率;最后预测信任评分以提高推荐内容的相关性。
1 改进的信任度值计算方法
1.1 信任分类
在推荐系统中,依据不同的定义,信任被划分为各种不同的类别。在本文中,依据不同的信任路径,将信任划分为直接信任和间接信任[14]。在一个社交网络中用户之间存在不同的信任关联,且信任具有非对称性。如图1所示,箭头方向表示信任方向,例如:0→3表示用户0信任用户3。
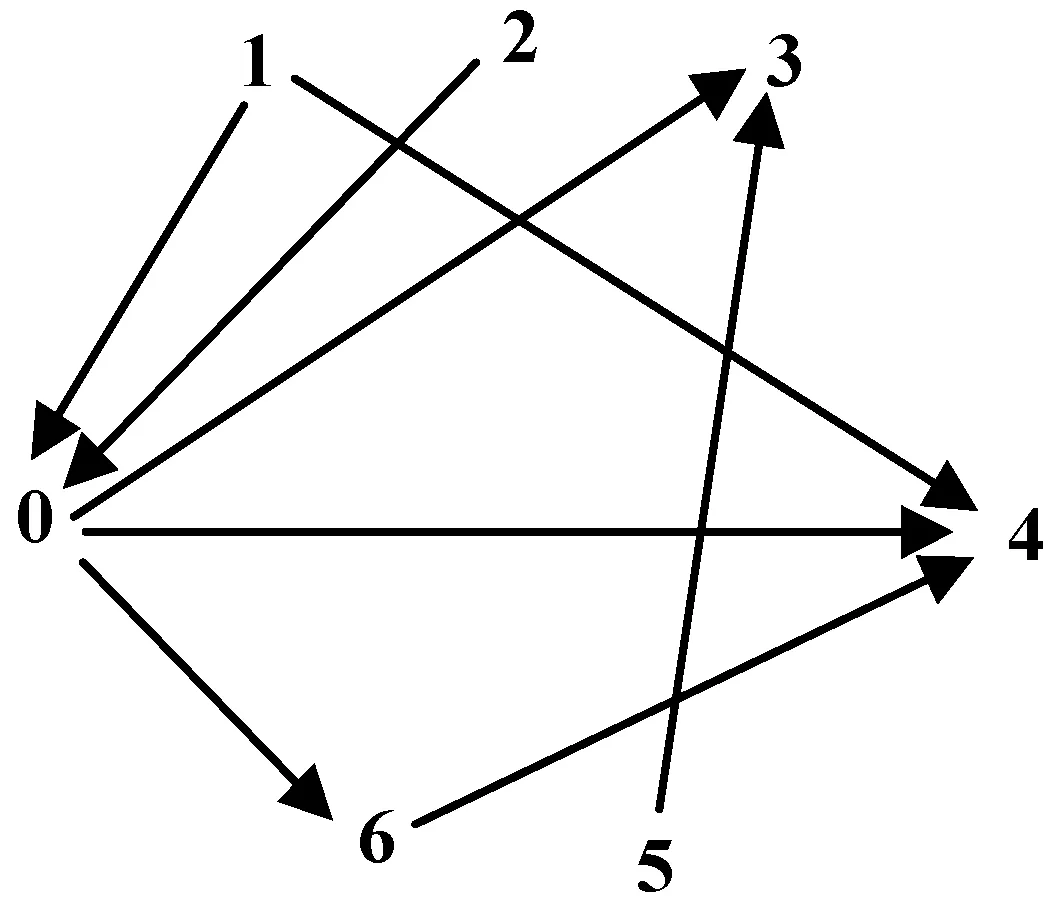
图1 社交网络中信任路径表示图
定义1将用户-用户的信任度表示为Trust,简写为Tr,例如用户u0对用户u3的信任程度表示为Tr(u0,u3)。
定义2令DTr表示直接信任,如果在社交网络中用户A到目标用户B的信任路径可直达,中间没有其他用户的参与,那么用户A对用户B的信任就是直接信任。例如,用户u4到用户u0的信任路径中没有经过其他用户,用户u4对用户u0存在直接信任,记作DTr(u4,u0)。
定义3令ITr表示间接信任,与直接信任相反,在社交网络中用户A到目标用户B的信任路径之间有其他用户的参与,那么用户A对用户B的信任就是间接信任。例如,用户u0到用户u4的信任路径中有用户u6的参与,即用户u0对用户u4存在间接信任,记作ITr(u0,u4)。
1.2 信任度值计算方法的改进
基于传统公式的社交网络节点信任度值计算方法虽然具有计算简单、复杂度低等优点,但是不能适应不同结构的社交网络,并且综合考虑的影响因素也十分单一[15]。本文通过研究社交网络的多种结构,探究影响用户之间信任关系的关键影响因素并提出一种综合多种权重影响因素的信任度值计算方法,细化了计算用户信任度的量化标准,主要有三部分量化因素:用户特征相似度、好友圈吻合度、用户交互紧密度。
定义4令FS表示用户特征相似度(Feature Similarity),其中包括用户基本属性特征和用户兴趣特征。
定义5令BS表示用户基本属性特征(Basic Attributes),指的是两个用户之间的基本信息相似度,其中包括性别、年龄、民族、省份、职业等。
定义6令IC表示用户兴趣特征(Interest Characteristics),指的是用户自身对于不同项目的喜好程度,例如用户喜欢看什么类别的电影、做什么样的运动、读什么类型的书等。
定义7令FM表示用户表示好友圈吻合度(The Degree of Friend Match),即共同好友的数量。
定义8令IN表示用户交互紧密度(User Interaction Tightness),即两个用户之间的交互频率。
1.2.1直接信任度值的计算
在真实社交网络中,两用户之间的信任程度往往是不一致的,通常情况下假如用户Ua信任用户Ub,不能直接推断用户Ub也同等程度地信任用户Ua,因此本文中引入改进的计算直接信任度值DTr(ua,ub)的方法,结合影响信任的多个关键因素为其分配不同的权重。
(1) 用户特征相似度的计算公式如下:
FS(ua,ub)=w·BS(ua,ub)+(1-w)·IC(ua,ub)
(1)
式中:w代表调参系数,取值范围在[0,1],w越大说明用户基本属性信息相似度的作用越明显。用户基本属性相似度和用户兴趣特征相似度的计算分别如下:
(2)

(3)
式中:I-bs(ua)、I-bs(ub)分别代表用户Ua和用户Ub基本属性信息的集合;|I-bs(ua)|、|I-bs(ua)∩I-bs(ub)|、|I-bs(ua)∪I-bs(ub)|分别代表用户Ua基本属性信息集合中数据的数量、用户Ua和用户Ub基本属性信息集合中相同数据的数量、用户Ua或者Ub基本属性信息集合中数据的数量。同理式(3)中的关于用户兴趣属性的相关表示含义,不再赘述。
(2) 好友圈吻合度的计算公式如下:
(4)
式中:Common-friend(ua,ub)表示用户Ua和用户Ub的共同好友集合,依据“150定律”,又叫作邓巴数字,设置150位共同好友数量的最大值。
(3) 用户交互紧密度的计算公式如下:
(5)
式中:分子表示用户Ua和用户Ub的交互次数;分母表示用户Ua和他所有朋友的交互次数。
综合式(1)-式(5),得出两个用户之间的直接信任度值DTr(ua,ub)计算式为:
DTr(ua,ub)=M×FS(ua,ub)+O×FM(ua,ub)+
P×IN(ua,ub)
(6)

1.2.2间接信任度值的计算
由于信任具有可传播性,在真实社交网络中,用户之间除了有直接信任关系还有间接信任关系。由图1的信息可知,用户u1和用户u4之间不仅存在直接信任路径,还存在两条间接信任路径,分别为:用户u1信任用户u0,用户u0信任用户u6,用户u6信任用户u4;用户u1信任用户u0,用户u0信任用户u4。这里设用户u1到用户u4的间接信任路径为:L1064、L104,它们各自的间接信任值计算公式如下:
L1064=DTr(u1,u0)×DTr(u0,u6)×DTr(u6,u4)
(7)
L104=DTr(u1,u0)×DTr(u0,u4)
(8)
根据信任的可传播性可知,一条信任路径上的用户越多,信任度增加的幅度越小,本节利用两级信任路径传播,来计算用户Ua到用户Ub之间经过所有信任传播路径的间接信任值,在这里引入物理学中等效电阻的相关理论[17]来作为信任距离度量方法,如图2所示。
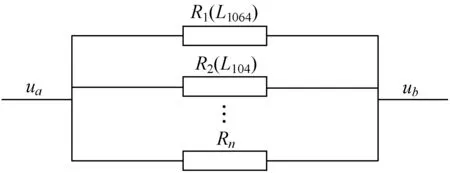
图2 社交网络中模拟电路图的用户之间的信任路径
即R1等效为L1064,R2等效为L104,由并联电阻计算方法式(9)可得,间接信任度值的计算方法为式(10)。
(9)
(10)
1.2.3综合信任度值的计算
通过结合影响信任关系的几个关键维度为其设置不同的权重,最终计算信任值公式如下:
sim-Tr(ua,ub)=
(11)
式中:sim-Tr(ua,ub)表示用户Ua和用户Ub之间的信任度值。当DTr(ua,ub)≠0、ITr(ua,ub)≠0时,说明用户Ua和用户Ub之间同时存在直接信任和间接信任;当ITr(ua,ub)=0时,代表用户之间只存在直接信任;当DTr(ua,ub)=0时,表示用户之间只存在间接信任。
2 融合信任度的神经网络模型
目前,比较火热的结合神经网络的推荐算法——基于神经网络的协同过滤(Neural network based Collaborative Filtering),通过将内部特征替换为可以从数据中学习任意函数的神经结构,它的优点是可以将特征向量映射到向量空间进行表示和学习,也可以作为训练神经网络模型所需要的特征向量[18]。在神经网络的协同过滤算法的基础上已经有IFE-NCF改进算法,经典的基于项目上下文的IFE-NCF框架是将某一层的输出作为下一层的输入,它由输入层、嵌入层、IFE-NCF层、输出层四大部分组成。IFE-NCF的每一层都可以通过定制结构来发现用户-项目之间交互的潜在结构,目的是将潜在向量映射为预测评分传输到输出层,这样的设计比原来固定的内部函数具有更完善的表达能力。它虽然采用多层结构来对用户-项目的交互信息进行建模,在一定程度上可以直接预测用户-项目评分矩阵中的缺失数据,但是它仅凭用户交互过的项目信息来进行预测,忽略了用户和用户之间的相互有关联的关系信息,同时考虑到社交网络中大量冗余的信息,传统的模型仅通过特征工程获得用户主观意识的属性作为研究主体,往往忽略丰富的客观内容。为此,本文通过融合上述信任度值计算方法所得到的关系矩阵,将用户-用户、用户-项目的直接信任及间接信任矩阵嵌入到用户、项目的序列特征中,以提高推荐相关性。
2.1 融合信任度的算法思想
在深度神经网络模型中融合信任度,是充分考虑社交网络中大量数据缺失的研究背景,综合利用上述度量方法计算出的用户之间的信任度对原始数据进行最大能力的补全操作。在现实社交网络中用户兴趣一定是与用户评分行为有某种联系,同时这种联系还需要考虑用户之间的信任关系。图3和图4为本文算法融合信任度值的具体过程。
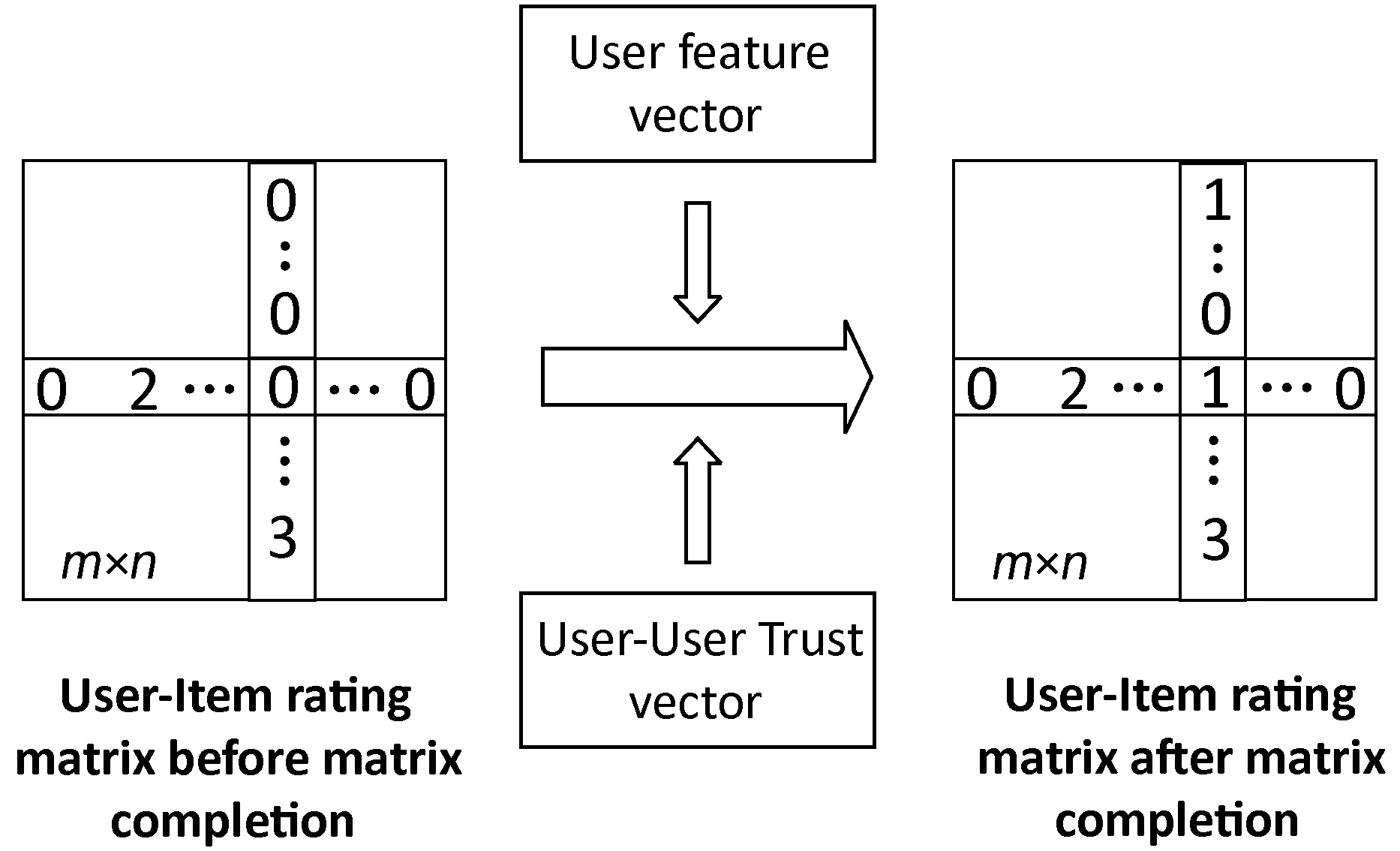
图3 融合信任度与用户特征的矩阵补全模型

图4 融合信任度与项目特征的矩阵补全模型
如图3所示为用户之间信任度与用户自身特征的矩阵补全过程,输入用户自身特征向量和用户-用户信任度值向量,输出补全缺失数据的用户-项目评分矩阵。图4中描述了用户之间信任度与项目基本特征的矩阵补全过程,输入项目基本特征向量和用户-用户信任度值向量,输出补全缺失数据的用户-项目评分矩阵。
然后,将以上两个分别融合信任度进行数据补全的矩阵利用哈达玛积(Element-wise Produce)将其嵌入到用户集(User)和项目集(Item)中构建用户信任矩阵和项目信任矩阵,利用embedding层对用户集和项目集进行向量转换,从而获得输入序列向量。这种补全数据值的方法不同于传统的推荐模型将矩阵中所有缺失数据进行一次性补全的方式,本文方法更加注重社交网络中用户之间信任关系,也着重突出了后续神经网络模型中设计的注意力机制的作用,为融合信任度的特征矩阵分配更大的权重,突出信任关系对预测评分的影响比重。利用量化得出的信任度值将缺失数据尽可能地补全同时又防止后续使用数据集进行实验会出现过拟合现象。
2.2 T-NAMF算法模型
本节提出一个融合信任度的神经注意力机制矩阵分解网络模型T-NAMF,将神经网络中的注意力机制与协同过滤矩阵分解相结合的推荐评分预测模型,模型框架如图5所示。

图5 T-NAMF算法模型
为了详细地解释该协同过滤模型的结构层次,对各个步骤讲解如下。
步骤1以融合信任度之后的u-Tr和i-Tr作为输入映射到序列特征中。
步骤2用embedding分别从u-Tr和i-Tr中提取用于广义矩阵分解块和全连接块的输入向量MF_User_Vector、FC_User_Vector、MF_Item_Vector、FC_Item_Vector,以便获得user和item的隐式反馈信息,利用哈达玛积(Element-wise Produce)来进行user和item向量的交互。
步骤3对MF_User_Vector和MF_Item_Vector采用Element-wise Produce操作融合用户-项目向量矩阵,作为GMF的输入特征,利用向量矩阵的稀疏性降低计算复杂度。
步骤4将步骤2中FC_User_Vector和FC_Item_Vector串联起来,作为全连接块的输入向量,通过拟合user和item之间的非线性表示,提高语义特征的可识别性。
步骤5将通过GMF和FC层所得的特征送入Attention Module,通过对融合特征的系数矩阵进行缩放,提高推荐内容的相关度。
步骤6将信任矩阵内部评分做等级化处理,分为0-5级,用户-项目数据映射得到的信任值作为标准,采用Log loss作为损失函数,对预测信任评分进行评估,从而优化模型训练。
步骤7对训练的网络模型中的参数微调,进一步提高预测模型的精确度。
2.3 输入层
输入层中主要包括的数据信息有:用户id、项目id、用户-项目之间的交互信息,虽然在每个数据集中都包含有数百万条的交互信息,但同时数据集的稀疏度也高达95%。本节利用第1节中提出的信任度值计算方法及现有数据信息计算用户-用户的信任度值,相当于在数据集中添加一列信任数据。首先,在模型的输入层中将信任度值数据分别映射到用户和项目的特征矩阵中,再对用户id、用户特征和项目id、项目类别等数据进行one-hot编码预处理,目的是将非数值化的数据进行数值化处理,并且这种预处理方法的处理效果明显优于其他神经网络类型的编码方式,one-hot编码可以对每一维的特征数据进行归一化处理,以起到有扩充特征数据的作用。在预处理编码之后,分别输入用户-信任向量和项目-信任向量。
2.4 嵌入层
嵌入层中输入的是输入层中输出的用户-信任潜在向量和项目-信任潜在向量,并将它们描述成关于用户和项目分别基于信任度的潜在向量,其中关于用户的潜在向量输入单元为8units,关于项目的潜在向量输入单元为32units。本文用vu、vi、vTr分别表示用户特征向量、项目特征向量和信任特征向量,将信任特征向量映射之后的用户-信任向量和项目-信任特征向量表示为:
vut=vu·vTr;vit=vi·vTr
(12)
另外用Vu和Vi分别表示两者的嵌入向量:
(13)
式中:用MFu∈Rm·k代表用户特征的嵌入矩阵,MFi∈Rn·k代表项目特征的嵌入矩阵,k表示嵌入维度的大小,m表示用户特征个数,n表示项目特征个数。
2.5 NAMF层
NAMF层是本文算法改进的核心部分,其中包括广义矩阵GMF层、全连接FC层和注意力模块。首先,GMF中的特征提取始于嵌入层中MF-User向量和MF-Item向量的嵌入,得到一个8×8的二维矩阵,经过矩阵分解,输出神经元(units)数量为8的神经元网络。FC全连接层是提取社交网络中的用户、项目、信任信息作为特征向量,作为FC嵌入层中的输入维度,接着合并FC和MF中的项目向量来升维空间向量,然后用几个全连接层结合ReLU激活函数输出该神经网络。
在GMF和FC层中,不同的嵌入层很有可能会限制融合模型的性能,由于两种模型之间的结构差异很大,所以本文设定GMF和FC使用相同的嵌入维度大小为数据集的最佳嵌入大小。为了给融合模型提供更多的灵活性,允许GMF和FC单独学习嵌入层数据并进行组合,最终连接这两个模型的是它们的隐藏层,表示如下:
(14)
(15)

NAMF层中最关键的部分是本模型中设计的全局注意力模块,通过FC全连接层的全局最大池化和GMF广义矩阵分级的全局平均池化来提取特征向量和通道权重。在注意力模块的输入操作中,将GMF和FC的特征同时输入进行通道融合,通过一层卷积层将多维通道的特征压缩成一维通道的特征,以便减少多维通道之间的特征信息对注意力机制的干扰。将前面操作中的最大池化层和平均池化层合并输入到Sigmoid函数中,归一化获取权重信息,最后将特征信息和初始的输入特征对应单元进行相乘。具体结构如图6所示。

图6 注意力模块内部结构
在Attention模块中,本文借鉴文献[19]中提出的局部推理方法实现对特征数据的融合处理,将GMF中的平均池化层和FC中的最大池化层进行特征融合,表示如下:
(16)
式中:⊕表示使用合并的方式来提取特征,这种融合特征的方法相比于传统的直接做点积,在构建模型时更关注不同特征所占的权重不同,这样学习出的神经网络模型会减少对于关键特征的损失。
2.6 输出层

(17)
3 实 验
3.1 数据集与参数设置
在本文实验中采用的数据集是推荐算法中常用的两个公开数据集,其一是MovieLens-1m,其中包含了6 040个用户对3 652部电影的1 000 209个评分;另一个数据集是Pinterest-20,它是一个基于图像内容隐式反馈来进行推荐的数据集,产生一个包含55 187个用户和1 500 809个交互的数据子集。原始数据中没有信任相关的统计,需要先进行数据预处理,将用户评阅、点赞、收藏他人主页等统计数据来作为统计信任关系数的依据,考虑到隐式反馈的性质,0表示间接信任,1表示直接信任。在本实验中对数据集以10∶1的比例进行信任关系划分,统计信息如表1所示。

表1 数据集的数据统计信息
利用改进信任度值计算方法计算得出的具体信任度值融合到原有数据集中,即新添加信任度值一列,样本示例如图7所示。
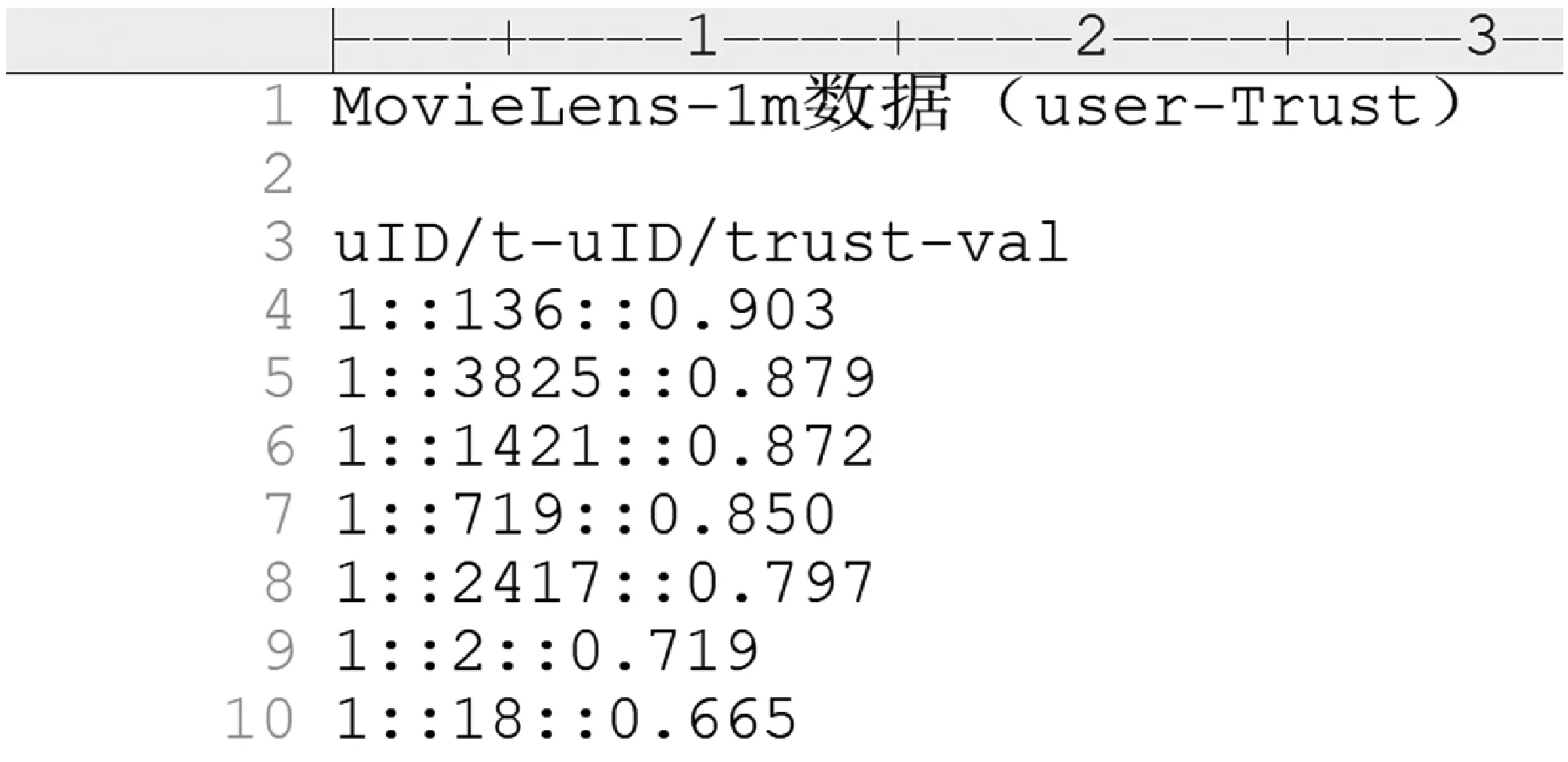
图7 MovieLens-1m中添加用户-信任数据
图7为截取MovieLens-1m数据集中添加用户-信任数据的样本示例,将信任度值依据TOP-N排序,以便后续实验获取源用户信任的目标用户。图8为截取同数据集中添加项目-信任数据的样本示例,能够在新的异构网络中挖掘用户之间的信任度。可见,融合信任度的推荐算法可以很大程度上缓解社交推荐系统中用户信任关系挖掘不充分的问题,提高推荐效果。
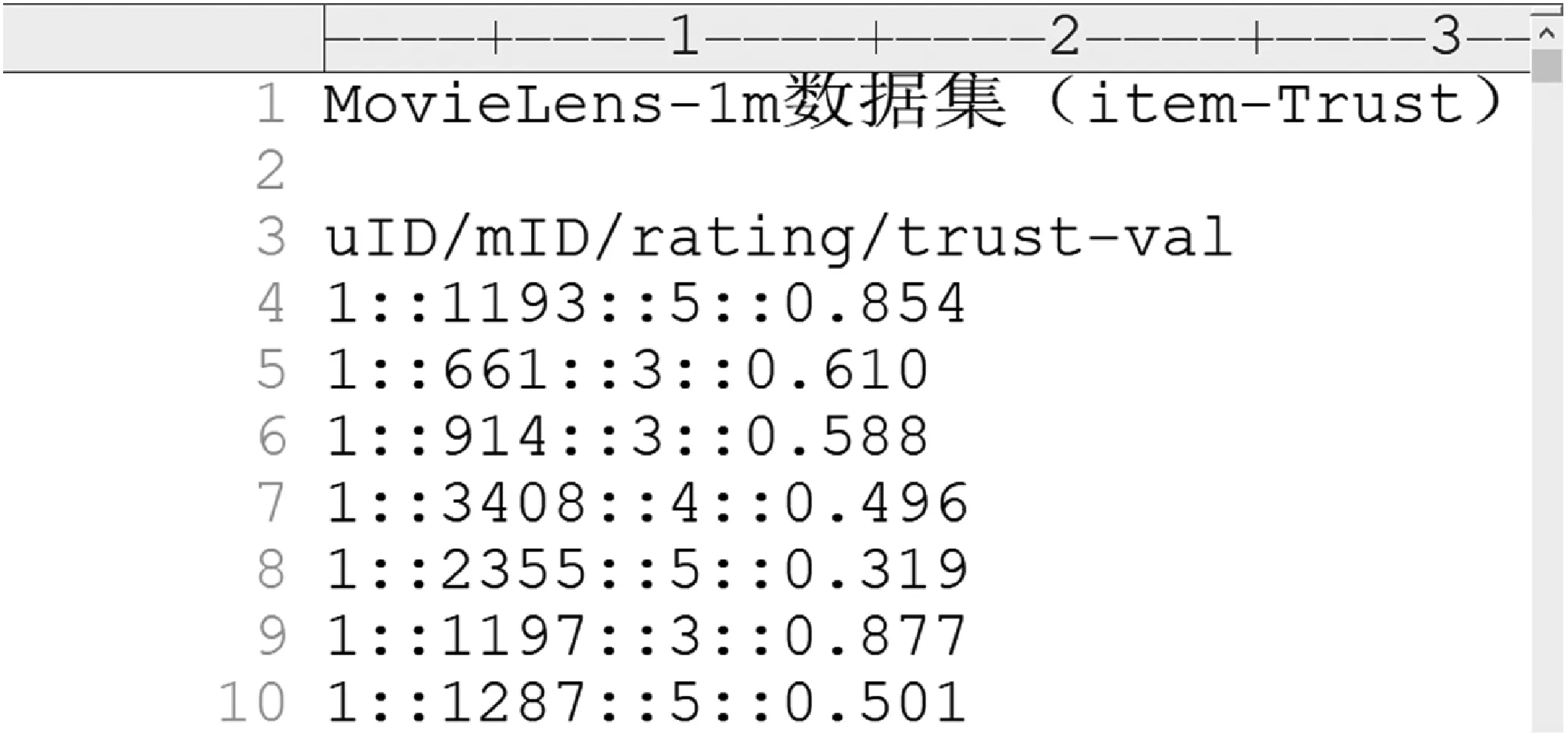
图8 MovieLens-1m中添加项目-信任数据
另外,为了确定T-NAMF算法中设置的超参数,本文随机抽取了每个用户的一个交互行为数据作为验证数据,并且调整优化了其中的超参数,整个实验过程都是通过优化算法Adam的对数损失来学习的,其中对每个正实例采样四个负实例,对于从零开始训练的T-NAMF模型,利用高斯分布(均值为0,标准差为0.01),设置学习率α=0.001,随机初始化模型参数测试数据集。另外设置影响因素取值为8、16、32、64,刚接受过训练的a值被设置为0.5,允许预先训练的GMF和MLP对T-NAMF的初始化贡献相等。
3.2 评价指标
本文使用命中率(HR)和归一化折扣累计增益(NDCG)两个指标作为实验的评价指标。其中HR可以直观地衡量是否测试项目在前十名列表中,从而评估推荐排名列表的性能,其定义如下:
(18)
式中:|GT|表示所有测试数据集合;分子表示的是推荐列表中属于测试数据集合的数量。
NDCG是基于列表排名位置这所因子的体现,其衡量标准是推荐内容的位置在推荐列表中越靠前,它的相关度就越高,定义如下:
(19)
式中:求和公式是求1到N的和,N是推荐列表排名个数,在本文的算法中取N=10,即取前10个排名进行评估;Z取值0/1,0为隐式反馈,1为显式反馈。
本文提出的融合信任度和注意力机制的T-NAMF是针对基于项目上下文的IFE-NCF的改进模型。为了验证T-NAMF在实验评估指标上的推荐表现,选择改进的基础模型IFE-NCF以及初始模型GMF和MLP作为本实验的对比基准,以便较为全面地衡量本文算法的各项性能。
3.3 实验分析
(1) 引入信任度值对实验效果的分析。为了研究基于信任度的T-NAMF模型对用户推荐项目的表现,本文实验分别将MovieLens-1m和Pinterest-20两个数据集的用户按照信任度值分为三组:用户之间信任度值小于等于0.33的属于低信任组,用户之间信任度值大于0.33且小于等于0.66的属于中信任组,其余的用户属于高信任组。
图9显示的是在相同的实验背景下,使用两个不同的数据集分别利用低信任组、中信任组和高信任组用户观察MLP、GMF、IFE-NCF、T-NAMF四个不同的模型关于HR@10和NDCG@10的表现状况。T-NAMF模型的推荐效果明显优于其他三个模型,HR@10指标在MovieLens-1m和Pinterest-20两个数据集的低、中、高信任组中最高分别提升了6.05%、1.75%、2.30%和16.12%、5.40%、4.18%;NDCG@10指标在两个数据集的低、中、高信任组中最高分别提升了15.86%、13.98%、5.83%和8.20%、6.54%、7.79%。

(a) MovieLens-1M
另外,通过观察可以发现:T-NAMF模型越是在低信任组的用户中越有更好的推荐效果,这是由于本改进模型通过引入用户之间的信任度值来度量用户之间隐式关系,由此看来,T-NAMF模型可以填补缺失数据,很大程度上能够缓解用户的冷启动问题。
(2) 在Top-N方面的推荐表现效果。为了研究MLP、GMF、IFE-NCF、T-NAMF四个不同的模型关于不用长度推荐列表的实验真实效果表现,在实验中为每个用户设置影响因子factor为8,单次训练迭代次数为50,batch_size为512,变量设置长度K为1~10的推荐列表,获取并记录在两个数据集上四个模型有关NDCG@10和HR@10评价指标的真实反馈表现,如图10所示。

(a) MovieLens-HR@K
分析图10可知:
1) 推荐列表的长度(横坐标表示的K值)在一定程度上影响推荐预测的准确性,K值从1增加到10的过程中,四个模型的推荐效果都呈现逐渐提升的状态,但是每个模型的优化程度不同。
2) 从四个模型在MovieLens-1m数据集的推荐表现来看,本节提出的T-NAMF模型在整个K值取值范围内比其他三个模型的推荐效果都要好,当K取值较小时,对比IFE-NCF模型提升的幅度较大,在K=10时,HR指标相比IFE-NCF模型只提升了0.89%;从图10(b)中可以看出T-NAMF模型的推荐表现明显优于其他对比三个模型,在K=10时,NDCG指标相比于IFE-NCF模型提升了5.40%。
3) 就数据集Pinteres-20来看,从图10(c)中的推荐表现可以看出,当K<5时,T-NAMF模型比IFE-NCF模型的推荐表现略好一点,之后随着K值的不断增大,前者的HR指标比后者稍差一点,但是明显优于MLP、GMF两个模型的推荐水平;图10(d)的反馈信息跟图10(c)类似,在K>7的取值范围中,T-NAMF模型比IFE-NCF模型的NDCG指标略差一点。
上述情况出现的原因是由于在数据集Pinterset-20中的数据都是基于图片的内容,数据本身就有描述不准确性,T-NAMF模型在基于图片的应用场景下发挥的推荐效果还有待提升。另外,TOP-K并非越大越好,就实验结果来看,K值取小于3的推荐效果最好,结合现实推荐系统的应用目的是将预测评分最高的项目推荐给用户,TOP-K中的K值选取应尽量小且推荐指标尽量高,因此K=3是最佳选择。
4 结 语
本文充分考虑社交网络中用户与用户之间的信任关系,将其量化计算并作为隐式推荐系统中的一个特征因素,同时将深度神经网络中添加注意力机制应用到推荐算法中,在原有的基于项目上下文的NCF框架的基础上提出一种新的T-NAMF框架。在现有的数据集信息类别有限且数据量稀疏的情况下,利用已有的显式数据综合多种权重影响因素,有效缓解了数据稀疏问题。在训练模型部分加入全局注意力机制模块,以增强对于关键特征的学习。通过实验结果可以证明,T-NAMF框架增大了权重特征的比重,在召回率和归一化性能方面都有很好的优化效果。但是,T-NAMF也存在一定不足,不能够普适所有类型的应用场景,在基于图片内容的场景中推荐表现欠佳;另外在没有信任度值的数据集中需要先对数据集做预处理计算出用户之间的信任度值,这部分工作量较大。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
少年博览·小学高年级(2018年10期)2018-12-10 09:00:04
环球时报(2018-01-23)2018-01-23 05:25:53
桃之夭夭B(2017年2期)2017-02-24 17:32:43
知音海外版(上半月)(2016年12期)2017-01-13 13:10:09
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
计算机工程(2015年4期)2015-07-05 08:27:45
高中生·青春励志(2014年11期)2014-11-25 10:07:54
