
融合全局和局部注意力机制的自然语言框架识别方法
2023-09-04 09:33:00郭哲铭王笑月
计算机应用与软件 2023年8期
郭哲铭 张 虎 崔 军 王笑月
(山西大学计算机与信息技术学院 山西 太原 030006)
0 引 言
框架语义分析是通过语义框架刻画事件或场景[1],并以此对自然语言进行语义分析的一种技术。框架语义分析任务主要包括框架识别和语义角色标注两个子任务[2-3]。本文主要围绕框架识别任务展开研究,即给定可激起框架的目标词,根据上下文语境,选取最符合该目标词语境的语义框架。在真实的语言资源中单个目标词会对应一个或多个所属框架,但在具体的上下文场景中其仅可选择一个关联框架。如表1所示,目标词“叫”所属框架有三个,但依据上下文语境S1中“叫”后接地名“茶峒”应属于“命名”框架,而S2中鸟叫声应属于“发声”框架。
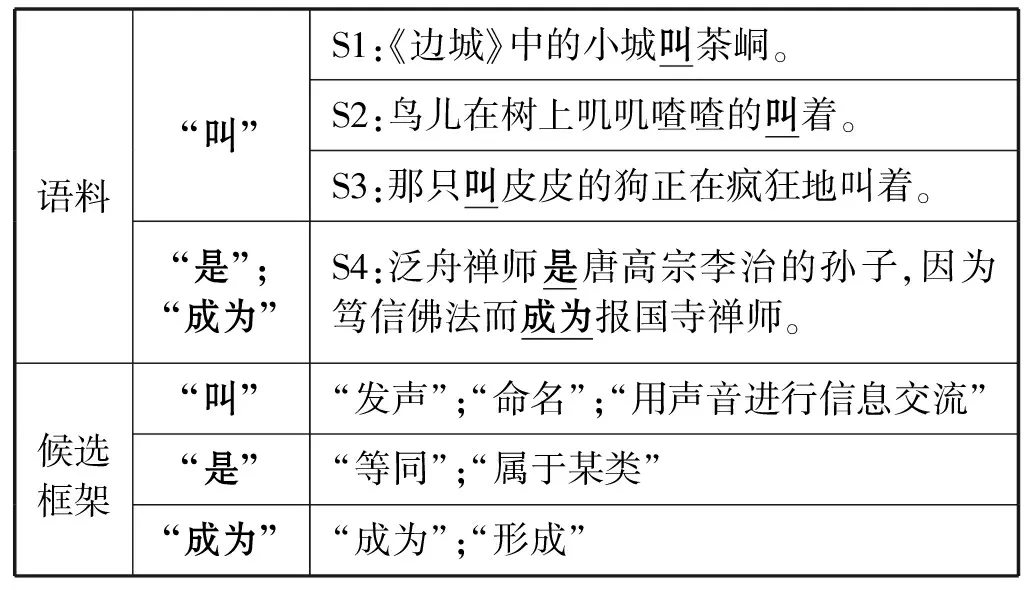
表1 语料示例
早期研究中通常将该任务视为多分类任务,使用传统的机器学习方法以及人工特征建立模型。Johansson等[4]使用支持向量机对不同的词元训练一个分类器,同时将词根、次级框架集合(目标词为动词时)和父子节点等特征融入其中,并在FrameNet[5]英文语料库进行了验证。然而,特征选择的复杂性及庞大的数量导致人工定义特征成本过高,模型难以泛化。面对该问题,Li等[6]提出T-CRF模型,首先采用句法分析工具得到文本的层次结构,之后结合条件随机场模型(CRF)进行汉语框架[7]识别。
深度神经网络的出现使框架识别任务逐渐摆脱对特征规则的依赖,且模型性能也得到了提升。Hermann等[8]使用句法和语法特征并将谓词进行分布式表示,之后将其与通过WSABIE算法得到框架表示计算距离进行框架识别任务。Swayamdipta等[9]提出Open-SESAME,通过Bi-LSTM提取上下文信息,同时为在上下文中表示目标词,将目标词与相邻为1的词语作为前向LSTM的输入。但上述工作只对语料上下文信息进行了提取,忽略了目标词周围的局部信息特征。且已有工作大多为一个目标词训练一个分类器,导致模型缺乏通用性。
通过分析语料发现,目标词周边词语对框架识别有重要作用。如表1中句S1,只需确认目标词周边2个字(即“小城叫茶峒”)就可确定所属框架。且在语料中,不同的字词对目标词框架选择的影响程度不同,如S2中“鸟儿”和“叽叽喳喳”对框架选择的重要程度更高。因此本文引入了局部信息提取机制,强化框架识别中的局部信息;此外,由于基于RNNs的模型存在长距离依赖的问题,故此本文采用大型预训练模型BERT[10]得到文本表示,并基于此使用RNNs进一步捕捉文本的序列化结构。
综上所述,本文的主要贡献包括:
(1) 在框架识别任务上将预训练语言模型与RNNs相结合,既缓解了长距离依赖问题,又可同时捕捉到文本固有的序列化信息。
(2) 结合框架识别的特点,提出一种局部信息提取机制,其可以强化框架识别中的局部重要信息。
(3) 在FrameNet和Chinese FrameNet上的实验结果表明本文所提方法可有效提高框架识别准确率。
1 相关工作
框架语义分析最早由Gildea等[11]提出,并通过使用FrameNet进行了可行性验证,后来在2007年的SemEval中被正式以评测任务的方式提出。作为框架语义分析子任务的框架识别也备受瞩目。
现有的框架模型主要依靠两种方式:第一种主要使用传统的机器学习模型进行分类,比如条件随机场(CRF)、支持向量机(SVM)和最大熵(ME)等模型。Bejan[12]使用SVM和ME模型对FrameNet中556个带有歧义的目标词分别构造多分类器进行识别。李济洪等[13]利用词性、依存句法等特征,使用最大熵进行建模。门宇鹏等[14]在其基础上加入语义依存分析特征,并利用支持向量机进行分类。但以上研究大多由研究者自行选择特征,并利用现有的分析系统抽取特征。这不仅加大了研究人员的工作量还由于分析系统自身存在的误差且没有进行修复导致存在误差累计。
随着深度学习技术在自然语言处理领域中相关任务的深入应用,越来越多的研究者也尝试将其引入到框架识别任务中。Das等[3]将多种句法特征融入到半监督学习方法进行框架识别;Hermann等[15]通过引入大型外部数据库来提高框架识别性能;在此基础上张力文等[16]将词语及句子利用分布式表征方法表示,再使用相似度计算的方式进行框架的识别。借鉴以上方法,Botschen等[17]通过将语料中的目标词替换为目标框架进行迭代训练,最后提出该目标词位置的向量作为框架的表示参与框架识别任务。侯运瑶等[18]通过对同一例句同一目标词所激起的框架构建正负例,再经过以hinge-loss为目标函数的神经网络不断学习,得到带有可区别该目标词所属正确框架与错误框架的框架表示向量,并使用该向量进行框架的识别。然而,神经网络自动学习特征的优点并没有体现。因此,赵红燕等[19]将深度神经网络框架与词分布式表征相结合,基于卷积神经网络建立了一个通用的框架识别网络。但以上工作均忽略了目标词周围的局部信息。
2 框架识别模型
框架识别任务是指给定包含目标词的句子S,记为S=(w1,w2,…,wn),其中wi为组成句子的第i个字(英文为第i个词),1≤i≤n。待识别目标词记为WT=(wt1,wt2,…,wtn),Wt∈S。要求通过上下文的语义场景从给定的框架库F={f1,f2,…,fn}中选择出适合的框架ft,记为:
(1)
本文提出一种融合全局和局部注意力机制的框架识别模型,整体架构如图1所示。其主要分为3个部分:① 编码层:通过预训练模型得到文本的向量表示。② 注意力交互层:通过全局注意力和局部注意力分别对上下文及目标词周边信息建模,得到面向目标词的语义信息编码。③ 输出层:融合得到的特征信息经过全连接层变换后输入分类器进行框架的选择。
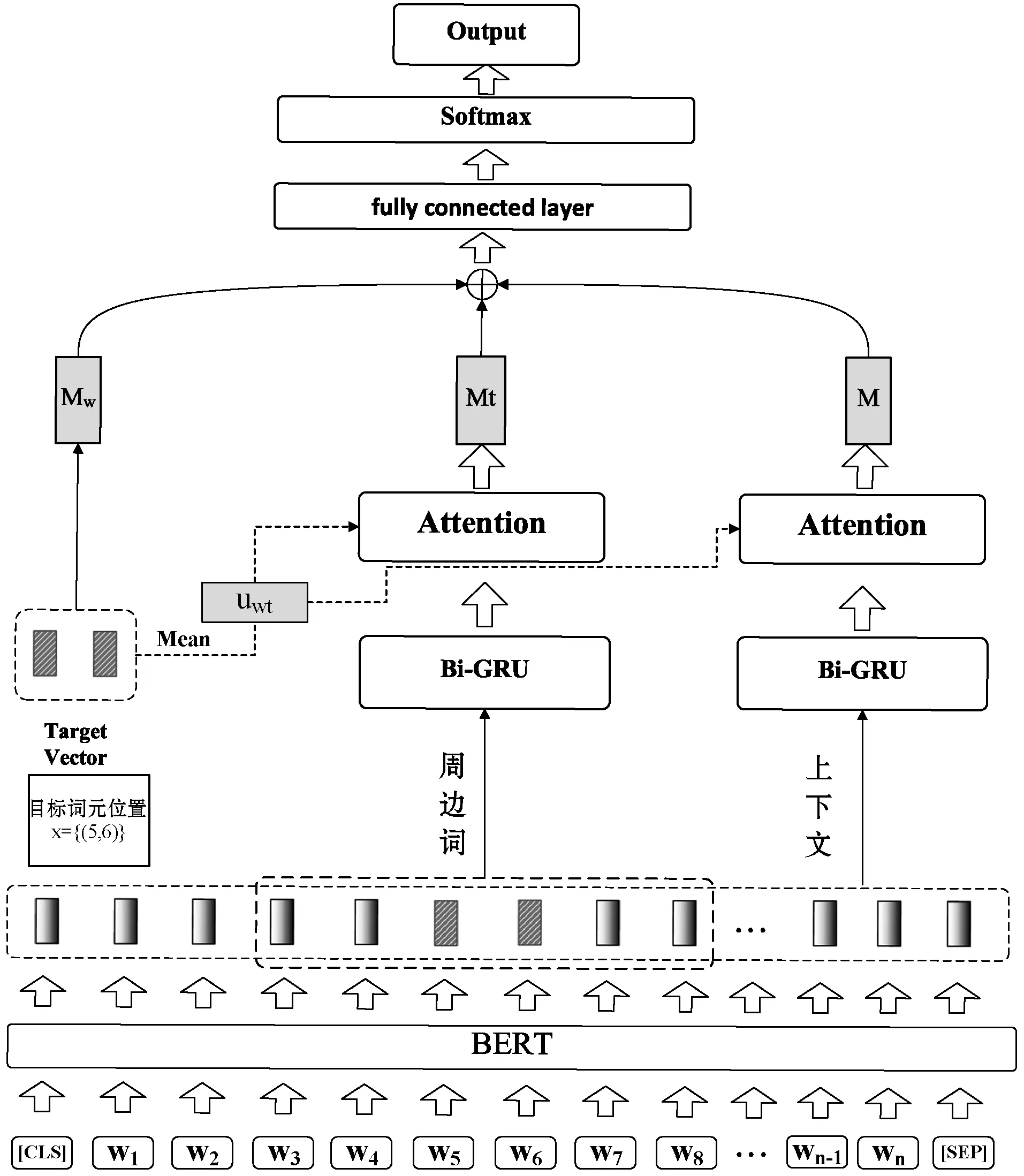
图1 TBGA模型结构
2.1 编码层
本文采用BERT作为文本编码层,将“[CLS]+句子S+[SEP]”作为模型输入X,其模型结构如图2所示。
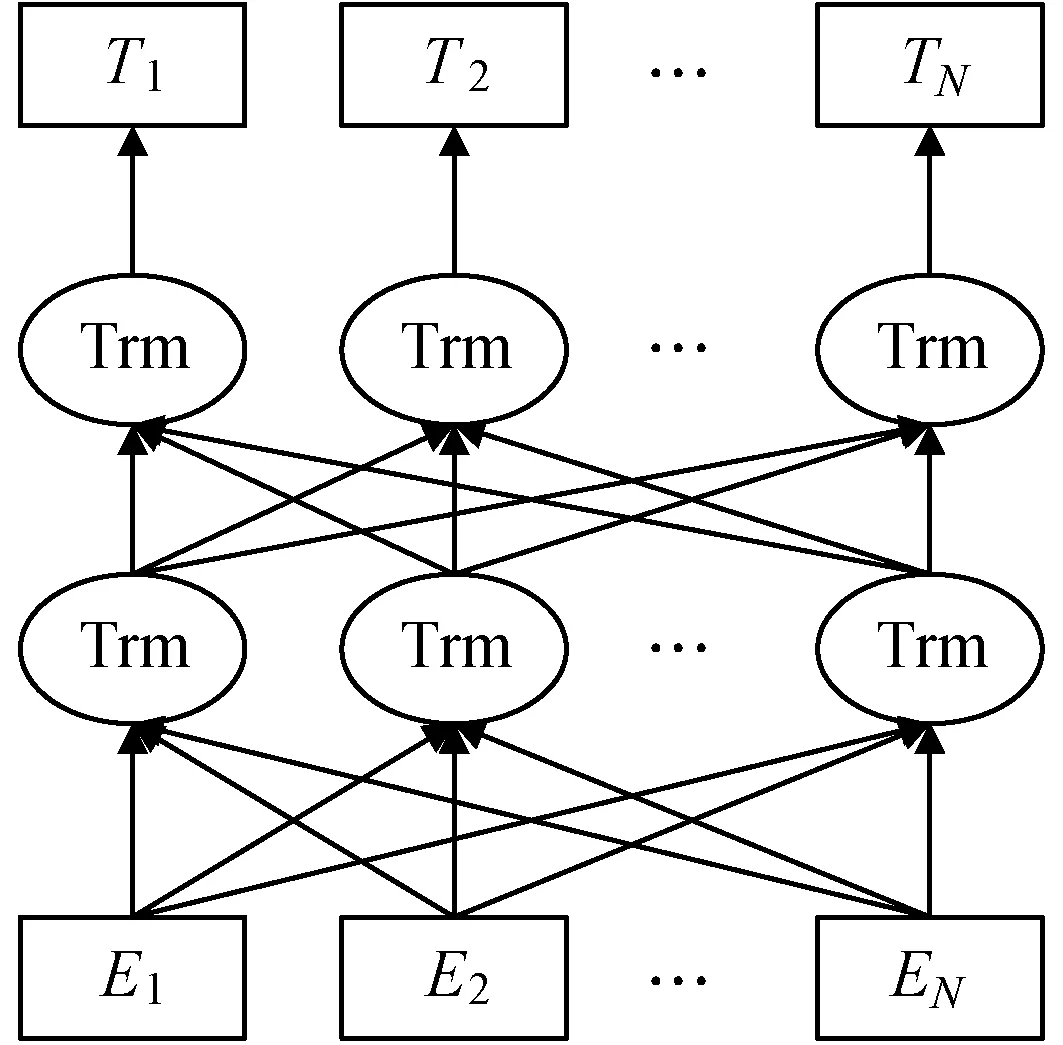
图2 BERT预训练语言模型结构

图3 窗口大小K实验
其使用双向Transformer[20]作为基本结构,将每个词与其上下文信息进行交互,并赋予不同权重,以此得到融合上下文信息的文本表示。
Ei=Etoken(xi)+Epos(xi)+Eseg(xi)
(2)
Hs=BERT(E1,E2,…,En)
(3)
式(2)和式(3)展示了BERT的处理过程,首先将输入X进行分词操作得到标记序列[x1,x2,…,xn],n为序列长度。再分别使用词嵌入、位置嵌入、段落嵌入将每个xi编码为向量Ei,最后将其输入BERT中输出词向量Hs∈Rn×d。
2.2 注意力交互层
框架识别中一条句子可能存在多个框架场景,如表1的句子S4中存在两个目标词“是”和“成为”。同时在同一语料中一个目标词也可属于多个框架,如句子S3中,“叫皮皮的狗”刻画的是对狗的指称,属于“命名”框架;而“疯狂地叫着”体现的是“发出声响”,属于发声框架。因此目标周边信息对框架识别任务格外重要。本文使用Bi-GRU分别对目标词上下文和目标词周边信息进行语义信息提取,捕捉文本语言中的序列结构信息和目标词的局部信息特征。针对语料中各个词语在框架识别任务时重要性差异问题,本文引入注意力机制,从而有效地提供了针对目标词的文本语义信息。
2.2.1序列化特性提取
基于Attention机制的BERT预训练模型无法捕捉自然语言独特的序列化结构。故本文引入双向门控循环网络(Bi-GRU)挖掘BERT所得文本表示中的结构信息。

(4)
(5)
(6)
Shi=[h1,h2,…,hn]
(7)
为提取目标词周边信息,本文以目标词为中心,使用开窗口的方式选取其周边字组成周边句ST=(wt1-k,…,wt1-1,wtn+1,…,wtn+k)其中k为窗口的大小。通过使用Bi-GRU对周边句进行建模提取特征,Sti记为局部信息表示。如式(8)-式(11)所示。其中xti∈R2k×2d是经过编码后的周边句中的字向量。
(8)
(9)
(10)
Sti=[ht1,ht2,…,ht2k]
(11)
2.2.2双注意力机制
在目标词的上下文中不同的词语对目标词框架选择的影响力不同。如表1的句子S2中“《边城》中的小城”的“小城”更能体现出框架“命名”的场景,而“《边城》”仅起定语的作用。因此对于语料中包含语义角色的词语,定语、补语之类不同程度的修饰词语应在进行句子语义表示时赋予不同的权重。因此本文在Bi-GRU编码层后引入注意力机制,从而使得表达出的语义更加符合当前目标词所表达的语义场景。
如式(12)-式(15)所示,本文将BERT所得的目标词表示uwt∈Rd作为注意力机制中的查询值query,将Bi-GRU得到的句子表示Shi视为key和value,得到关于目标词的注意力权重矩阵。之后将权重矩阵与文本表示Shi加权求和,得到融入目标词信息的文本特征表示M∈Rd。
uwt=mean(WT)
(12)
ui=tanh(Wihi+bi)
(13)
(14)
(15)
同时,为提取更有效的目标词周边信息,对Bi-GRU所得到的目标词局部信息表示Sti也使用了同样操作。如式(16)-式(18)所示,使用目标词词向量uwt计算周边词语的可靠度ati,并将Mt作为周边句的特征向量。
uti=tanh(Wtihti+bti)
(16)
(17)
(18)
2.3 输出层
为充分融合上下文语义特征、周边词语义特征与目标词特征,本文将三种特征进行拼接作为最终的整体信息Q∈Rd×3。其中为了充分体现目标词中每个字的信息,目标词特征Mw为目标词中的每个字向量相加得到,如式(19)-式(20)所示。
Mw=wt1+wt2+…+wtn
(19)
Q=M⨁Mt⨁Mw
(20)
在网络最后使用全连接层进行约束,并将结果输入softmax分类器中进行分类。与其他方法不同,本方法使用一个分类器对不同目标词进行识别,为多分类问题,故采取CrossEntropyLoss损失函数训练整个网络。其输入为真实样本类别分布p(x)和观测样本的预测概率分布q(x),如式(21)-式(22)所示。
q(x)=softmax(Q)
(21)
(22)
3 实验与结果分析
3.1 数据集
本文分别在汉语框架语义知识库(Chinese FrameNet,CFN)和英文框架语义知识库(FrameNet)进行了实验,表2介绍了文中所使用数据集的详细信息。其中FrameNet1.5数据集中目标词歧义的语料较少,无法较好体现出本文所提方法在框架排歧上的优越性。故针对框架排歧实验分析,本文主要采用CFN语料。

表2 数据集的分布
3.2 评价指标
实验采用准确率(accuracy)作为评价指标,计算的是所有正确预测的样本数占总预测样本数的比值,不考虑预测的样本是正例还是负例。本次在实验中就是在所有目标词标签预测的目标句中,标签预测正确的句子占有的比例。计算公式如下:
(23)
式中:TP+TN是正确识别框架的例句数;TP+TN+FP+FN是框架识别的例句总数。
3.3 参数设置
实验的参数设置如表3所示,本文将最大序列长度设置为128,训练批量大小为16,使用Adam优化函数,初始学习率为5e-5,并设定随着训练的进行将学习率逐渐降低,衰减率为0.05,epoch为5。Bi-GRU隐层节点数也为768维。

表3 参数设置表
3.4 结果分析
本文主要进行了四组实验:实验一、二分别使用两种数据集与现有模型方法进行了对比;实验三针对窗口大小的选择进行了分析。实验四通过消融实验验证了模型各个模块的作用。
3.4.1CFN数据集上实验结果及分析
在进行框架识别任务时,汉语的复杂性导致一词多义及目标词包含语义场景的现象较多,因此CFN相比FrameNet更能体现模型在排岐上的有效性。故选取文献[18]中的最好结果作为基线对比,记为C&W_FR。但该方法仍是针对目标词进行建模,受限于目标词语料规模,为得到更可靠的实验对比,将语料按照论文方式划分成四个大小相同子集并保证目标词所属语料均匀分配到每个子集。然后将其中任意两块作为测试集,其他两块作为训练集进行3×2折交叉验证实验,结果如表4所示。此外,本文还比较了其他两种通过框架表示进行识别的模型,结果如表5所示。

表4 CFN实验(%)

表5 CFN实验(%)
可以看出,本文提出的框架识别模型(BTGAT)在六组实验中均高于基线模型的最好结果,其平均结果相较于基线模型提升了2.38%。同时,表5的结果表示本文的方法显著优于其他方法。以上结果验证了所提方法针对歧义词元的识别具有优越性。
3.4.2FrameNet1.5上实验结果及分析
为验证模型的通用性与延展性,本文比较了其他三种不同的方法并在英文数据集上进行了实验。表6展示了在使用FrameNet1.5作为数据集时的实验结果。

表6 FrameNet实验(%)
可以看出本文通过对上下文和目标词周边信息进行自动加权提取的特征可以有效地进行框架的预测。其中SEMAFOR为Das等[3]对SemEval 2007最佳模型[2]的改进,采用基于图的半监督学习方法和对偶分解算法进行识别。对比SEMAFOR系统,本文的模型识别效果提升了4.79百分点。相比于同样未使用语法特征的Open-SESAME[9]系统和Hermann等[15]的方法,模型效果分别提高了1.45百分点和0.76百分点,说明本文通过对周边句提取特征可以有效地提高识别能力。作为通用模型,本文的实验在英文数据集中的结果均优于其他模型。且本模型不是针对词元进行建模,因此若出现与训练框架相似的新词元不需要针对其进行新的建模训练,可直接通过语料自动提取特征进行识别。故本方法拥有其他模型不具备的鲁棒性和延展性。
3.4.3窗口大小K实验
本文通过调整例句中以目标词为中心开窗口K的大小,得到对框架识别效果提升最大的目标词周边信息。以CFN实验中的最佳效果为例,当选择的窗口大小过大导致目标词左边或右边没有词语时,为保证输入注意力机制的向量维度一致,本文使用0向量进行有顺序的填充。
可以看出,对于中文,选取大小为4的时候效果最佳。当窗口小于4时,可能过短的周边词语无法提取出对框架识别有用的信息导致效果不佳。而当窗口过大时可能导致提取的特征与上下文信息部分重复,影响最终的预测。对于FrameNet数据集,当K为2时效果最佳。原因可能为中英文分词差异,周边为2的英文词汇包含信息与中文周边4个字组成的目标句信息对识别效果最佳。
3.4.4消融实验
为了分析神经网络模型中各个组成部分的有效性,本文在中文的数据集上进行了消融实验,具体结果如表7所示。

表7 消融实验(%)
可以看出,上下文特征贡献度大于周边词特征。且在加入上下文(+C)和目标词周边(+R)的特征之后,框架的准确度在两个数据集上分别提高了2.54百分点和1.16百分点,这表明通过Bi-GRU提取到的特征对框架识别是有意义的。而对得到的两个特征引入注意力机制(+A)使得准确度进一步提升了2.21百分点和1.47百分点,说明注意力机制通过加权使得语料中的重要信息得到体现。针对同语料目标词不同问题,将目标词作为注意力的参照目标对特征进行提取,相比之前结果分别提升了0.96百分点和0.87百分点,表明该方案得到的特征更加符合当前目标词所刻画的语义场景。此外,从表7中可以看出在该任务中,GRU的序列化特性提取性能优于LSTM且双向提取的信息高于单向。
对比两个数据集及其实验结果,由于中文数据集的词元均有歧义而英文数据中歧义词元较少,导致该模型在中文数据上各个模块之间的提升幅度较大而英文相对幅度较小,表明该模型对歧义框架的识别提升明显。
3.4.5错误结果分析
本文在两个数据集分别选取了测试集中的50条错误数据进行了分析,错误数据如表8所示。其错误类型主要有以下几点。

表8 错误分析
(1) 框架之间具有总分关系:启程和出发的框架定义相近,但总框架分别为位移和旅行,故不仅需要上下文语境,还需分析激起框架中具有的框架关系,并选择符合此时语境的上位框架。
(2) 篇章关系:如识别词元“出航”时,只从给出的当前语料无法判定其语境为“旅游”还是为“位移”。
(3) 语句情感:“表达”与“陈述”框架均使用了信息交流框架,区别在于“表达”框架偏向于刻画信息传递者的思想、感情等抽象化信息,而“陈述”框架则是重点刻画说话者传达信息的场景。但计算机无法对该语料中所传达的信息进行分辨。
(4) 权重分配问题:目标词“party”的预测框架“Organization”在人工标注时无法激起,说明抽取出的上下文及周边词特征之和对该词元的影响力过大,导致目标词特征无法准确定位框架。
4 结 语
本文提出了一种BTGAT模型,首先针对多义词问题,使用BERT对语料训练增强了词向量的词义表征能力。其次,通过Bi-GRU对上下文及周边句信息进行语义表示,再使用全局和局部注意力机制以词元作为参照目标对语义表示进行针对性建模,得到符合当前目标词所刻画场景的特征。最后将得到的特征拼接后送入分类器进行框架识别。实验结果表明,该模型在两个数据集上的性能均优于基线。同时,本模型不仅可用于多种语言且统一训练参数,而非对不同词元训练不同分类器,因此具有通用性和延展性。此外,本文还对目标词周边窗口大小对实验结果的影响进行了研究。结合错误分析,在今后的工作中将重点研究框架关系对识别的影响,尝试将候选框架之间的联系进行建模,利用上位框架等信息进行过滤。针对篇章关系,可引入标注的篇章语料,通过保留上文重要信息进行识别。同时可对提取的不同特征通过分配不同的权重,缓解次要特征影响力过大问题,进一步提高框架识别的准确性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
开放教育研究(2020年2期)2020-03-31 01:54:14
传媒评论(2017年3期)2017-06-13 09:18:10
海外华文教育(2016年1期)2017-01-20 08:21:58
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
现代语文(2016年21期)2016-05-25 13:13:44
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
大连民族大学学报(2015年2期)2015-02-27 08:28:11
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
