
遥感图像语义分割的多特征注意力融合网络
2023-09-04 09:22徐翔徐杨,2*
计算机应用与软件 2023年8期
徐 翔 徐 杨,2*
(贵州大学大数据与信息工程学院 贵州 贵阳 550025) 2(贵阳铝镁设计研究院有限公司 贵州 贵阳 550009)
0 引 言
随着全球遥感技术的飞速进步,遥感图像的分辨率越来越高。高分辨率的遥感图像可以捕捉到详细的地物信息,便于对地面场景中的不同目标进行准确的分析。语义分割作为图像解析的基础任务之一,其目标是对图像进行像素分类。随着遥感图像解析的需求日益提升,对高分辨率遥感图像进行语义分割逐渐成为了研究热点,其应用越来越广泛,如城市规划[1]、土地植被分类[2]、道路提取[3]等。
近年来,卷积神经网络[4]因其具有很强的特征表示能力在计算机视觉领域得到快速发展[5-8]。文献[9]提出了全卷积网络FCN,将卷积神经网络的最后的全连接层转换为卷积层,实现了端到端的语义分割。文献[10]提出基于编码和解码结构的语义分割模型Unet,将不同层次的特征图分别拼接到对应的解码结构中,并依次进行上采样,缓解了像素空间位置信息丢失的问题。文献[11]提出金字塔场景解析网络模型PSPNet,利用空间金字塔池化结构来聚合多尺度的上下文信息,提高了获取全局信息的能力。文献[12]提出DeepLabv3+模型,利用不同扩张率的扩张卷积提取不同尺度的特征,通过解码器恢复目标的细节特征。文献[13]提出多任务分割网络UPerNet,将金字塔池化结构的输出与多个语义层次的特征进行融合以此解析多层次的视觉概念。文献[14]受到注意力机制的启发,将高层特征的全局信息作为权重调整低层特征并进行融合,实现特征重用。文献[15]采用自级联的方式连续聚合多尺度的上下文信息,通过残差连接融合多层次特征。文献[16]将自注意力机制引入语义分割任务中,通过对特征图进行重构,融合位置特征和通道特征,增强特征图的语义信息。文献[17]结合了DeepLabv3+和Unet的优点,通过超像素的后处理进一步提高了分割性能。
聚合图像的上下文信息可以缓解由于目标大小不同而导致分割性能下降的问题,然而现有多尺度特征融合方法未能考虑利用通道之间的依赖关系。其次,现有的高层特征与低层特征的融合方法一般直接采用通道维度拼接或像素相加的方式,导致特征融合的有效性不高。因此,本文构建了一个用于遥感图像语义分割的多特征注意力融合网络MAFNet。首先,将基础网络的输出通过不同大小的全局自适应池化聚合图像的上下文信息,同时利用特征图的重构获取通道的依赖关系,然后采用信息融合提高模型的语义分类能力。最后,基于注意力机制将基础网络中的底层特征依次与高层特征进行选择性融合逐级恢复目标的细节信息。在Potsdam数据集上的实验结果表明,本文模型能够在一定程度上提高语义分割的准确率。
1 多特征注意力融合网络模型
本文提出的MAFNet如图1所示,该模型基于编码和解码结构,包含基础网络、多尺度信息融合模块(Multi-scale Information Fusion Module,MIFM)和多层次特征融合模块(Multi-level Feature Fusion Module,MFFM)三大部分。
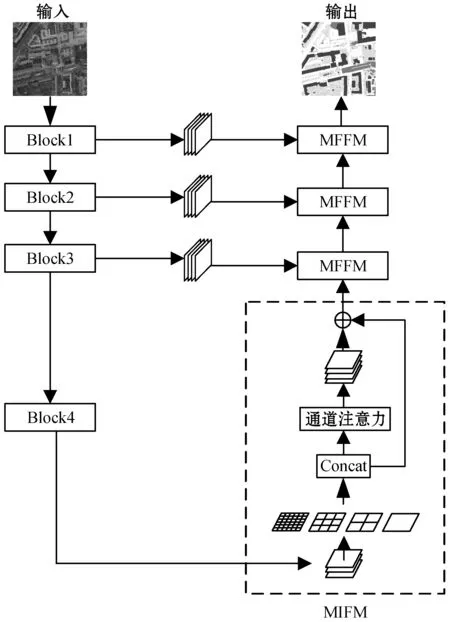
图1 多特征注意力融合网络模型
基础网络包含初始化层,四个残差块Block1、Block2、Block3和Block4。为了提取遥感图像中的目标特征,采用深层网络ResNet101作为基础网络进行特征提取,ResNet101采用跳跃连接融合输入和输出特征,在一定程度上避免了梯度消失的问题。本文在ResNet101的基础上,将初始化层的7×7卷积层改为三个3×3的卷积层,在减少参数量的同时更有效地提取特征。在最后两个残差块Block3和Block4中使用扩张卷积代替下采样操作,这样能够保留更多的细节信息并且不增加额外的参数。基础网络最后输出的特征图尺寸为输入尺寸的1/8。
1.1 多尺度信息融合模块
由于高分辨率遥感图像中存在场景复杂,目标大小不一的情况,而场景复杂度和目标尺寸大小的差异会影响基础网络的特征提取。为了解决这些问题,本文设计了一种多尺度信息融合模块。多尺度信息融合模块如图2所示。
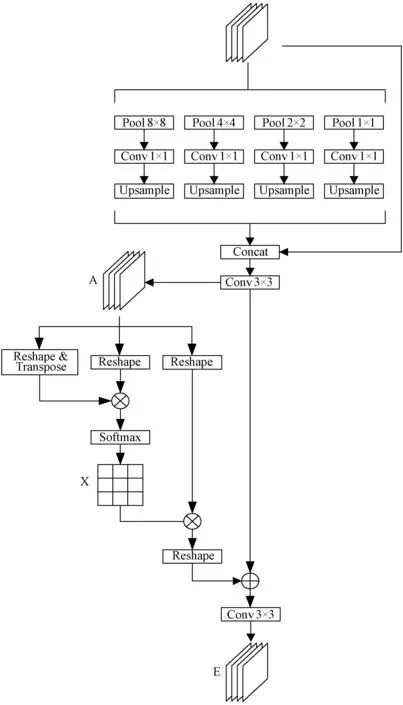
图2 多尺度信息融合模块
为了获取不同尺度的上下文信息,采用空间金字塔池化结构提取多尺度特征。将基础网络提取到的特征分别通过共四个不同大小的自适应平均池化。本文根据不同目标在遥感图像中所占像素区域大小的差异,将自适应平均池化的输出尺寸设置为1、2、4和8,因此每个特征图被划分为1、4、16和64个子区域,然后分别利用1×1卷积减少通道的数量,采用双线性插值的方式将特征图上采样到输入尺寸相同的大小,最后将多个特征图进行拼接融合。
为了获取高层特征中不同通道之间的关联信息,引入通道注意力结构选择性地强调不同通道的特征。首先将多尺度特征融合后的输出特征图A∈RC×H×W通过降维处理改为A∈RC×N,N=H×W,其中,C、H、W分别表示特征图的通道、高度、宽度。接着A与自身的转置矩阵AT∈RN×C相乘,再通过Softmax得到通道特征图X∈RC×C,如式(1)所示。
(1)
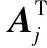
然后,将X∈RC×C与A∈RC×N矩阵相乘,再乘以尺度系数β后通过升维处理改为原来形状,最后与输入的特征图A∈RC×H×W逐像素相加得到最后的输出E∈RC×H×W,如式(2)所示。
(2)
式中:β为尺度系数,初始化为0,通过逐渐学习得到更大的权重。
最后,多尺度信息融合模块将不同尺度的上下文信息和具有辨别性信息的通道特征进行融合,增强对多尺度目标的捕获和分类能力。
1.2 多层次特征融合模块
遥感图像的语义分割过程中,高层特征图包含丰富的语义信息,但是下采样操作在扩大感受野的同时丢失了对象的空间位置信息,这导致分割目标的细节难以恢复。低层特征中包含丰富的边缘细节信息,有效利用低层特征成为了提高语义分割效果的关键之一。传统的语义分割将高层特征直接上采样得到输出,导致分割的精细化程度不高。本文设计了一种多层次特征融合模块,如图3所示。
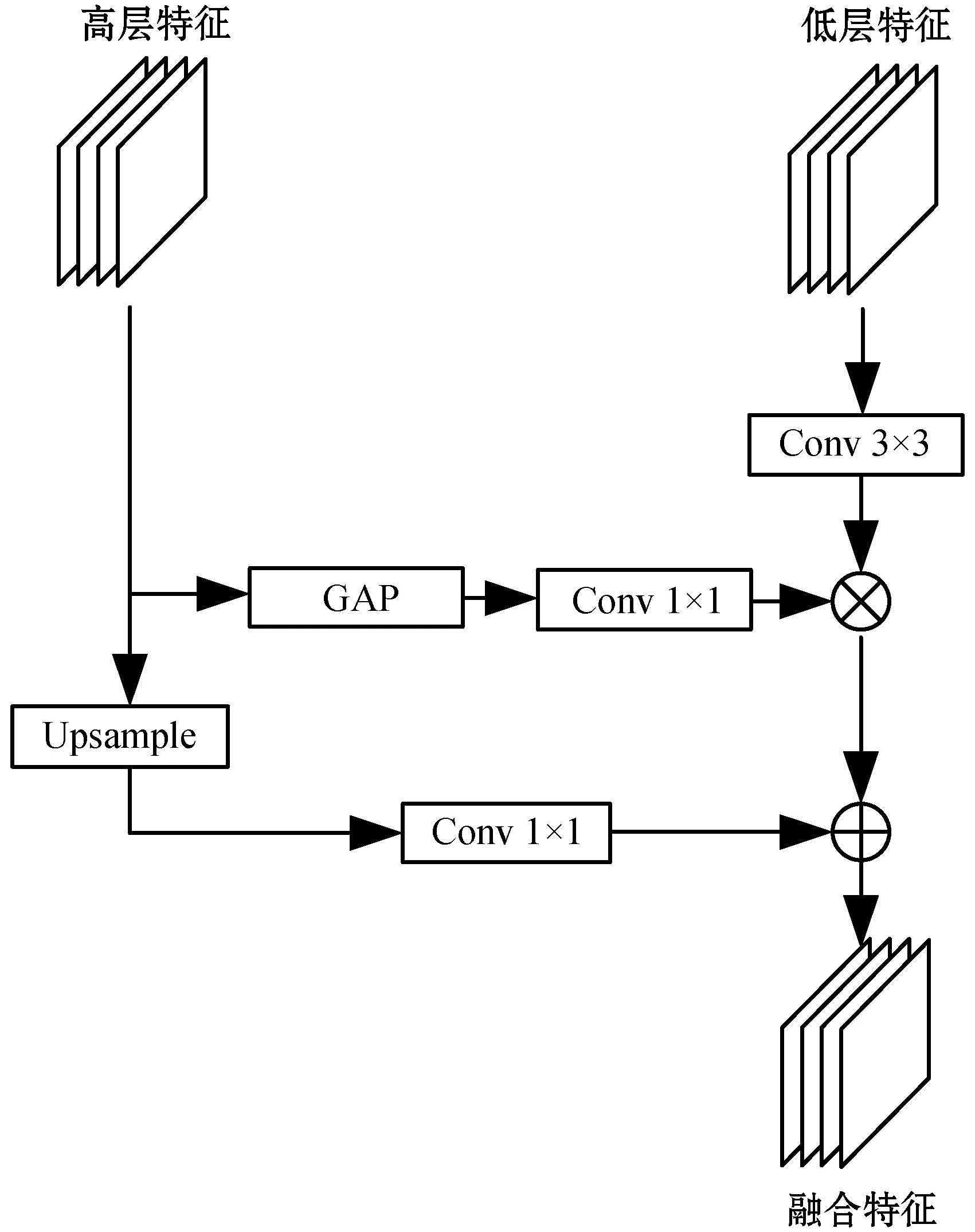
图3 多层次特征融合模块
首先将低层特征通过3×3的卷积减少特征图的通道数,然后通过全局平均池化(Global Average Pooling,GAP)和1×1卷积提取高层特征的全局信息,并将全局信息作为权重与低层特征相乘,以此强调有用的特征、抑制无用的特征。然后,采用双线性插值的方式对高层特征进行上采样,并通过1×1卷积减少通道的数量。最后,利用像素相加融合得到新的特征。MAFNet分别将ResNet101中Block1、Block2和Block3的输出特征图依次输入到多层次特征融合模块中,通过逐级上采样恢复目标的细节特征。
2 实验与分析
为了验证MAFNet的分割性能,在公开的Potsdam数据集和Vaihingen数据集上进行了实验。
2.1 数据集介绍
实验采用的Potsdam数据集和Vaihingen数据集来自ISPRS二维语义标注挑战赛。数据集均有6类标注,分别是道路、建筑、低植被、树木、汽车和背景。其中,Potsdam数据集共包含38幅尺寸为6 000×6 000的高分辨率遥感图像,地面采样距离为5 cm。本文实验从38幅图像中选取24幅用于训练,14幅用于测试。Vaihingen数据集包含33幅高分辨率遥感图像,图像的平均大小为2 494×2 064,本文实验中选取16幅图像用于训练,17幅用于测试。为了便于训练,本文使用滑动窗口裁剪法对图像进行裁剪,每幅图像大小为512×512,重叠128像素。通过随机旋转、垂直翻转、模糊处理和增加椒盐噪声等数据增强操作后,Potsdam数据集生成共13 500幅图片,Vaihingen共生成11 000幅图片。
2.2 实验设置
所有实验基于深度学习框架PyTorch。采用Softmax作为分类器,它可以计算每个类别的概率,所有的类别的概率之和为1,像素l属于类别i的概率如式(3)所示。
(3)
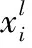
优化器采用随机梯度下降,初始学习率为0.01,动量为0.9,权重衰减为0.000 1。学习率衰减采用Poly策略,最大迭代次数为200,能量因子为0.9。第iter轮的学习率如式(4)所示。
(4)
式中:lr0为初始学习率;max_iter为最大迭代次数;power为能量因子。
2.3 评价标准
为了定量地评估实验的分割效果,实验设置了两个常用的评价指标,分别是像素精度(Pixel Accuracy,PA)、平均交并比(mean Intersection Over Union,mIOU)。计算式如式(5)和式(6)所示。
(5)
(6)
式中:k为类别总数;Pii表示预测正确的像素个数;Pij表示实际类别为i、预测类别为j的像素个数;Pji表示实际类别为j、预测类别为i的像素个数。值得注意的是,本文实验中mIOU均不包括背景这一类别。
2.4 消融实验结果与分析
为了验证各个模块的有效性,设计了MAFNet的消融实验。实验结果如表1所示。消融实验使用Potsdam数据集,选择ResNet101作为基本对比网络。首先,采用ResNet101+MIFM验证多尺度信息融合模块的有效性,MIFM表示多尺度信息融合模块。然后,采用ResNet101+MFFM验证多层次特征融合模块的有效性,MFFM表示多层次特征融合模块。最后,将两大模块整合在一起,验证网络模型MAFNet的性能。
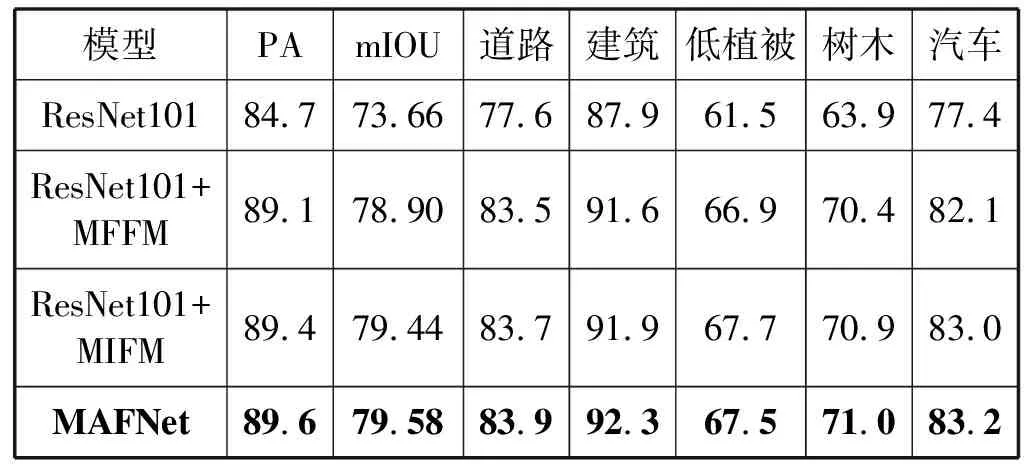
表1 消融实验结果(%)
根据表1实验结果,ResNet101+MIFM的表现相较于ResNet101,PA值和mIOU值分别提升了4.7百分点和5.78百分点。实验证明MIFM通过将提取的多尺度特征与通道关联信息进行融合提高了语义分割的精度。此外,ResNet101+MFFM的PA值为89.1%,mIOU值为78.9%,分别比ResNet101高出4.4百分点和5.24百分点。MFFM将提取的多尺度特征与通道关联信息进行融合。实验证明MFFM可以有效融合高层特征与低层特征,在一定程度上缓解了图像中目标边缘细节丢失的问题。最后,本文提出的MAFNet将所有模块集成到一起,进一步提高了性能。与ResNet101相比,PA提升了4.9百分点,mIOU提升了5.92百分点。
消融实验表明,本文提出的多尺度信息融合模块和多层次特征融合模块都能在一定程度上提高遥感图像语义分割的性能。消融实验可视化结果如图4所示。

(a) 遥感图像 (b) 标签 (c) ResNet101
2.5 不同模型的对比实验结果与分析
为了验证MAFNet的分割效果,与其他的模型进行了对比实验,对比模型选择了FCN[9]、UNet[10]、PSPNet[11]、DeepLabv3+[12]和UPerNet[13]。
(1) Potsdam数据集的对比实验。从表2结果可以看出,MAFNet的PA值达到89.6%,mIOU值达到了79.58%,与表现较好的UPerNet相比,PA提升了1.0百分点、mIOU提升了1.22百分点,不同类别的IOU值分别提高了1.6百分点、1.3百分点、0.5百分点、0.5百分点和2.2百分点。在比较的其他方法中,虽然FCN8和UNet考虑了高层特征与低层特征的融合,但是特征融合的方法只是简单的特征图拼接或者相加,未能考虑不同层级的特征关系。本文提出的MAFNet采用多层次特征融合模块,逐级恢复目标的边缘细节信息,提高了分割边界的精细化程度。尽管PSPNet和DeepLabv3+使用不同的方式提取多尺度特征,然而未能考虑不同通道之间的依赖关系增强语义表征能力。本文提出的MAFNet采用多尺度信息融合模块,将用于提取多尺度特征的空间金字塔池化进行改进以适应遥感图像的尺寸差异,并与通道之间的关联信息进行融合,提高了对目标的定位和分类能力。
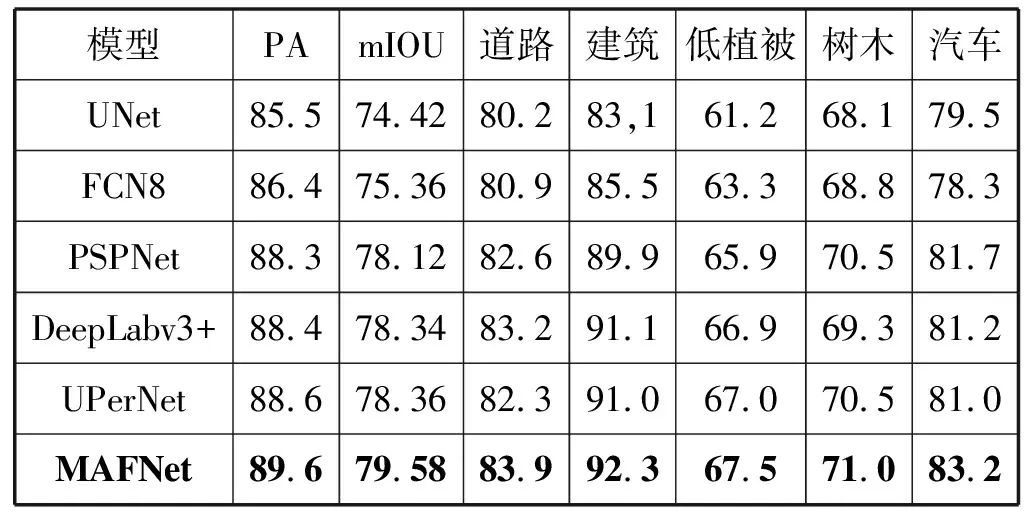
表2 Potsdam测试集的对比实验结果(%)
相较于其他模型而言,MAFNet对汽车等小目标的分割性能有明显的提升。如图5所示,由于汽车在总训练图像中所占的像素比例很小,并且容易被建筑物和树木遮挡,其他模型很难提取出相应的特征,进而实现正确的像素分类。在此基础上,MAFNet采用多尺度信息融合模块以提高对目标的定位和分割能力,解决了遥感图像中目标尺寸差异大导致分割精度不高的问题。因此,即使目标在图像中占据较小的区域,也可以提取并融合成有效的特征,从而进行正确的分割。

(a) 遥感图像 (b) 标签
(2) Vaihingen数据集的对比实验。从表3得到的结果来看,MAFNet在Vaihingen数据集上的PA为89.1%,mIOU的平均值为75.98%,分别比其最接近的竞争对手方法PSPNet高出1百分点和0.82百分点。虽然Vaihingen的数据量比Potsdam的数据量要小,但是MAFNet仍然获得了不错的分割效果。

表3 Vaihingen测试集的对比实验结果(%)
如图6所示,MAFNet对建筑物这类大尺度目标的内部像素的分类更为准确,目标边缘轮廓更为清晰,而其他模型的错误分割现象严重,精细化程度不高。实验结果表明MAFNet较好地解决了目标边缘细节难以恢复的问题。从Vaihingen数据集的对比实验可以看出,MAFNet的分割泛化性较强,不具有单数据集的偶然性,对不同的遥感数据集依然表现良好。

(a) 遥感图像 (b) 标签
3 结 语
针对遥感图像中背景复杂、目标差异大等问题,本文提出一种用于遥感图像语义分割的多特征注意力融合网络MAFNet。设计了一种多尺度信息融合模块增强特征图的语义表征能力,利用空间金字塔池化结构提取多尺度特征,同时与特征通道的关联信息融合。设计了一种多层次特征融合模块精细化目标的分割边界,基于注意力机制将高层特征和低层特征自适应地融合。实验表明,MAFNet的分割精度高于其他比较的模型,各个模块对于基础网络的分割性能均有不同程度的提升。由于遥感图像的语义分割属于监督学习,考虑到图像数据的标注工作量很大,下一步的研究方向是对于弱标注的遥感图像进行语义分割。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
时代英语·高三(2014年5期)2014-08-26
电视技术(2014年19期)2014-03-11
