
Attention-Based Deep Learning Model for Image Desaturation of SDO/AIA
2023-09-03 01:36:14XinzeZhangLongXuZhixiangRenXuexinYuandJiaLi
Xinze Zhang ,Long Xu ,Zhixiang Ren ,Xuexin Yu ,and Jia Li,5
1 State Key Laboratory of Space Weather,National Space Science Center,Chinese Academy of Sciences,Beijing 100190,China;lxu@nao.cas.cn
2 University of Chinese Academy of Sciences,Beijing 100049,China
3 Peng Cheng Laboratory,Shenzhen 518000,China
4 Department of Automation,Tsinghua University,Beijing 100084,China
5 State Key Laboratory of Virtual Reality Technology and Systems,School of Computer Science and Engineering,Beihang University,Beijing 100191,China
Abstract The Atmospheric Imaging Assembly (AIA) onboard the Solar Dynamics Observatory (SDO) captures full-disk solar images in seven extreme ultraviolet wave bands.As a violent solar flare occurs,incoming photoflux may exceed the threshold of an optical imaging system,resulting in regional saturation/overexposure of images.Fortunately,the lost signal can be partially retrieved from non-local unsaturated regions of an image according to scattering and diffraction principle,which is well consistent with the attention mechanism in deep learning.Thus,an attention augmented convolutional neural network(AANet)is proposed to perform image desaturation of SDO/AIA in this paper.It is built on a U-Net backbone network with partial convolution and adversarial learning.In addition,a lightweight attention model,namely criss-cross attention,is embedded between each two convolution layers to enhance the backbone network.Experimental results validate the superiority of the proposed AANet beyond state-of-the-arts from both quantitative and qualitative comparisons.
Key words: techniques: image processing– Sun: atmosphere– Sun: flares
1.Introduction
The Atmospheric Imaging Assembly (AIA) (Lemen et al.2012) onboard the Solar Dynamics Observatory (SDO)(Pesnell et al.2012)captures full-disk solar images over seven extreme ultraviolet (EUV)(94 Å,131 Å,171 Å,193 Å,211 Å,304 Å,335 Å)wave bands with a temporal cadence of 12 s and an angular resolution of5,providing an unprecedented highdefinition observation of the solar atmosphere,especially finegrained dynamic evolution of solar activities.
However,in case of big solar flares,the incoming photoflux may exceed the threshold of the charge-coupled device (CCD)of SDO/AIA,resulting in saturation/overexposure of the flare’s core region.The imaging system of SDO/AIA is characterized by these two processes,diffraction and diffusion which can be more or less explained by Figure 1.The diffraction replicates the core peak to generate diffraction fringes as shown in Figure 1(a),which is resulted by the convolution with the point-spread function(PSF)of SDO/AIA as shown in Figure 1(b).The diffusion causes the diffusion effect in local area when the input signal goes through the central part of the PSF as shown in Figure 1(c).The diffraction artifact would become apparent against the background in case of high intensity in image core frequently inducing saturation.More precisely,the saturation consists of the primary saturation and blooming/secondary saturation due to two different reasons.The former refers to the fact that the CCD pixels cannot accommodate additional charge for incoming photoflux while the latter names the fact that the primary saturation causes charge to spill into their neighbors.The overall effect of saturation is to flatten and threshold the brightest core of an image anisotropically (north–south direction) as shown in Figure 1(d).

Figure 1.An example of diffraction and diffusion effects,where diffraction fringes scatter to other regions beyond the core peak,while diffusion effect causes some degree of blur in the core peak due to the central part of the PSF.
The imaging process described above is formulated as the convolution between incoming photon flux and PSF,
wherefandIare the incoming photon flux and the recorded signal by SDO/AIA respectively,AcandAdrepresent the diffusion component and diffraction component of the PSF respectively,⊗represents the convolution operator.AcandAdare illustrated in Figures 1(c) and (b),whereAcis a core peak,andAdis the replications of the core peak.It can be observed that diffraction fringes which is the result ofAd⊗fin Figure 1(a).The effect of diffraction fringes comes from a regular,peripheral diffraction pattern of varying intensity inAdas shown in Figure 1(b).In particular,diffraction fringes would become more apparent against the background when increasing the peak off.The other termAc⊗fin (1) results in image saturation which is split into the primary saturation and the second saturation/blooming.As discussed in (Guastavino et al.2019),the blooming cannot be restored while the primary saturation may present in the diffraction fringes due to diffraction effect.In detail,the signalfis coherently and linearly scattered to other regions presenting as diffraction fringes due to diffraction (Guastavino et al.2019) given byAd⊗fas shown in Figure 1(a).Thus,the lost signal can be partially retrieved from diffraction fringes (Schwartz et al.2014;Torre et al.2015).
The recovery of lost signal from degraded signal is traditionally described as an inverse problem.To resolve an inverse problem,an extra constraint is additionally required.Usually,the extra constraint is given by typical image priors,like sparsity,non-local and total variation.This processing is well known as the regularization method which optimizes both data fidelity term and regularization (prior) term.In DESAT(Schwartz et al.2015),lost signal recovery in saturated regions was first formulated into an inverse diffraction issue as
whereIdis the known recorded image in diffraction regions,Bdis the unknown saturated image background related to diffraction fringes.Then,the regularization method was employed to resolve(2)to recoverf.In Schwartz et al.(2015),Bdis estimated from the interpolation of two neighbor unsaturated images which are provided by short-time exposure of SDO/AIA.This short-time exposure of SDO/AIA can be automatically triggered once solar flare occurs.However,in case of large solar flare,the neighbor images of short-time exposure are also saturated,resulting in failure of DESAT.To address this problem,a Sparsity-Enhancing DESAT (SEDESAT) Guastavino et al.(2019) was proposed to estimateBdfrom only current image instead of its neighbors.Nevertheless,desaturated result is limited by the segmentation of diffraction fringes and primary saturation regions and the estimation of background.In addition,the blooming regions cannot in principle be restored in both DESAT and SEDESAT.
Inspired by great success of deep learning,Mask-Pix2Pix(Zhao et al.2019),PCGAN (Yu et al.2021) and MCNet (Yu et al.2022) have been proposed to desaturate solar images in our previous efforts.Different from DESAT (Schwartz et al.2015) and SE-DESAT (Guastavino et al.2019) which explicitly model the recovery of saturation (desaturation) as an inverse diffraction,our models implicitly describe the desaturation as an image inpainting task with the help of deep learning.In addition,relative to DESAT and SE-DESAT,our models could compensate both the primary and second saturations with advanced image generation techniques of deep learning.Moreover,it is not necessary to segment primary saturation and blooming,and estimate background from the image superposed diffraction fringes,which were however two big challenges for both DESAT and SE-DESAT.Besides,partial convolution(PC)(Liu et al.2018)was used in PCGAN(Yu et al.2021)instead of standard convolution for processing invalid pixels within a convolution block.
As discussed in Equation (1) and Figure 1,a peripheral regular diffraction patternAdreplicates the core peak to generate diffraction fringes distributed outside of the core peak.These diffraction fringes carry information about the core region to scatter outside the core region.They can be utilized to restore the saturated region through an inverse process of diffraction,which has been successfully formulated by convolutional neural networks (CNNs) in our previous efforts(Yu et al.2021,2022).However,due to the small receptive field of CNN,we cannot efficiently unitize the diffraction fringes spread throughout the entire image,result in a compromise of desaturation.In this work,considering the non-local property of diffraction fringes,an lightweight attention module,namely criss-cross attention (Huang et al.2019),is employed to enhance CNNs to exploit global diffraction fringes for desaturation.This attention model has the receptive field of the entire image,so it can efficiently synthesize the information of the entire image through different weights.
The rest of paper is organized as follows.Section 2 introduces the network architecture,convolutions and loss functions of the proposed AANet in details.Experimental results are provided in Section 3.Conclusion and discussion are given in Section 4.
2.Method
The desaturation problem has been formulated as an inverse problem as given in Equation (2).The traditional solution was through regularization method (Guastavino et al.2019) which was however challenged by the decision of the primary saturation region and the estimation of the background signal.Deep learning has been widely acknowledged as a universal approximator (Cybenko 1989;Hornik 1991),which has achieved a big success in a variety of image processing tasks,such as image denoising,enhancement,super-resolution,inpainting,deconvolution and etc.In this section,an attention augmented convolutional neural network (AANet) is constructed to exploit attention mechanism for image desaturation.First,the network architecture of the proposed AANet is presented in details.Second,the loss function is presented and discussed in details for the optimization of the proposed model.
2.1.Network Architecture
The overall network of the proposed model is a generative adversarial network (GAN) as shown in Figure 2,consisting of a generator and a discriminator.The generator is a U-Net which architecture is shown in Figure 3.It consists of an encoder of eight convolutional layers and a decoder of eight deconvolutional layers.The basic modules of the generator include criss-cross attention(Huang et al.2019),PC,regional composite normalization (RCN) (Wang et al.2021),and ReLU/LeakyReLU.They are stacked repeatedly in the generator.In addition,the skip connection connects the encoder and the decoder at each layer.The detailed parameters are listed on the left side of network architecture,where the name of each module and volume of each module are provided.Moreover,the PC instead of the standard convolution is employed for processing invalid pixels in a convolution block.As illustrated in Figure 3,a mask image is provided to indicate “normal” and “saturated” pixels in an image for guiding the PC.In the encoder,invalid region gradually becomes smaller along with the mask updating in Liu et al.(2018).Finally,all pixels become valid,and the mask image converges to an all-ones matrix.During convolution process,the mask image is provided to image branch to guide extracting image features.

Figure 2.The overview of the proposed model.

Figure 3.The generator of the AANet,which learns a mapping from Im and Id to Igt.The discriminator supervises the learning process of the generator by an adversarial loss for discriminating fake{Id,Ig,Igg}and real{Id,Igt,Igtg}pairs.It finally minimizes the distance between two probability distributions of{Ig}and{Igt}.
The discriminator is a general CNN consisting of convolution layers.Specifically,it is a PatchGAN (Isola et al.2017;Zhu et al.2017) which means that each image is divided into small patches(e.g.,8×8)rather than a whole for discriminating real/false (real: positive or false: negative).The output of discriminator is aH/8×W/8 binary matrix where“0”and“1”indicate the probability of each patch being real or false.From Figure 4,mean square error(MSE)is computed to measure the loss of the discriminator.
2.2.Attention
Concerning image inpainting,attention mechanism is of great importance for exploring global/contextual information in an image,which is equivalent to exploring non-local prior in traditional image processing.In the literature,there have been many attention models,including non-local(Wang et al.2018),SENet (Hu et al.2020),GCNet (Cao et al.2019),CCNet (Huang et al.2019) and transformer (Vaswani et al.v 2017).
In this work,a lightweight attention,namely criss-cross attention (CCNet) (Huang et al.2019) is employed for low computational complexity.It exploits contextual information to further augment image convolutional features for recovery of saturated region of an image.The diagram of a CCNet is given in Figure 5,where an input image is first passed through convolution layers to produce feature maps.Then,these feature maps are fed to a criss-cross attention module for further enhancing image features,producing new feature maps.The criss-cross attention aggregates contextual information for each pixel in its criss-cross path,which means only the pixels in the same row and column as the current pixel are concerned.It is worth pointing out that two times of aggregation of criss-cross path are implemented in a CCNet.Thus,for each pixel,a CCNet actually aggregates the contextual information of all pixels of an image block.Such a recurrent aggregation is named as recurrent criss-cross attention (RCCA).To explore global contextual information over local feature representation,the non-local attention module(Wang et al.2018)generates a dense attention map size ofH×Wfor each pixel as shown in Figure 5(a),while the criss-cross attention module generates a sparse attention map only size ofH+W−1.However,going through two criss-cross operations,each pixel of the final output feature map can gather contextual information from all pixels as shown in Figure 5(b).

Figure 5.Diagrams of non-local and criss-cross attention modules.(Computational complexity isO (H ×W )(H ×W))andO (H×W)×(H +W − 1),respectively.)
2.3.Convolutions
Using deep learning,image restoration is accomplished by referring to the degraded image itself and the statistical distribution of massive unimpaired images.In this work,the desaturation of solar image is regarded as an image inpainting task.Solar images are impaired by saturated regions/holes as big flares happen.In image inpainting,convolution across intersection region between valid pixels and invalid pixels need to be designed specifically.First,invalid pixels should be excluded from standard convolution,namely partial convolution (PC) (Liu et al.2018).Second,the deviation caused by PC should be compensated so that output energy of PC remains the same relative to standard convolution.Given the input degraded image/feature mapx,convolution weightwand biasb,standard convolution is described as
wherey(i,j)denotes the(i,j)-th position of output feature mapy,R confnies the receptive feild of convolution.For example,3×3 receptive feild is formulated asR={(− 1,−1),(−1,0),...,(0,1),(1,1) }.When receptive feild of convolution slides across the boundary of impaired hole,both valid and invalid pixels participate in convolution operation.
To solve this issue,the PC (Liu et al.2018) is introduced,which is described as
wheremrepresents the mask image where “0” stands for saturated pixels and “1” stands for normal pixels,it is updated by Equation(5)for each operation.The symbol 1 is a constant matrix with all entries equal to 1,with the same size asm.From Equations (4) and (5),PC only depends on valid pixels by introducing a mask to exclude invalid pixels in convolution,while the deviation caused by invalid pixels is calibrated by scaling the output of PC,and the scaling factor is proportional to the number of valid pixels in receptive field.
2.4.Loss Functions
To optimize a neural network for image generation,a hybrid loss function was usually raised.It includes both pixel-level and feature-level image losses,providing image high-fidelity and photorealistic effect respectively.The pixel-level loss is represented by theL1norm andL2norm,i.e.,mean absolute error (MAE) and mean square error (MSE) functions.It measures the pixel-level difference between generated image and ground-truth in supervised learning.Inspired by the classical image priors in image processing,image gradient and image smoothness are of great importance to the perception of human visual system.Thus,two additional losses,namely gradient loss(Ma et al.2020)and total variation loss(Johnson et al.2016) are included in the loss function of the proposed model.Relative to pixel-level loss,the feature-level loss could well describe the photorealistic property of an image,but ignores the pixel-level difference.In this work,perceptual loss(Johnson et al.2016),and style loss (Gatys et al.2016) are employed to measure feature-level difference between generated image and ground-truth.The last but not the least,an adversarial loss (Mao et al.2017) is included in the loss function,which optimizes a generator through zero-sum game against a discriminator (Goodfellow et al.2014).
LetIdbe the input degraded image,Imthe initial binary mask image,Igthe generated image,andIgtthe ground-truth,the pixel-level loss given byL1norm is defined as
where∥·∥1denotesL1norm,λhand λvare two weights for combining recovered saturated region and normal region.They are empirically set to 100 and 10,indicating more weight is allocated to the recovered saturated region in Equation (6).
The gradient loss (Ma et al.2020) is adopted to ensure that the generated image has sharp structures and edges of objects,which is defined as theL1loss over image gradient map as
where ∇represents a gradient operator (Ma et al.2020) to compute image gradient,and′are two weights(empirically set to 300 and 10),assigning different weights to saturated regions and normal regions.
Total variation loss (Johnson et al.2016) is included to ensure image smoothness,especially around the boundary between normal and saturated regions.It is defined as
wherePindicates the region connecting saturated and normal regions.
The adversarial loss (Mao et al.2017) is adopted to ensure photorealistic effect of generated image from feature-level,which is formulated as
The perceptual loss (Johnson et al.2016) is adopted to capture high-level semantic information and alleviate gridshaped artifacts in recovered regions(Liu et al.2018),which is formulated as
whereIc=(1 −Im)⊙Ig+Im⊙Igtindicates the combination of the recovered region and the normal region extracted directly from the ground-truth.It can be seen that the perceptual loss computesL1norm in feature domain forIgandIc,respectively,where Ψirepresents the feature map of thei-th pooling layer of VGG-16(Simonyan&Zisserman 2015).In this work,the first three pooling layers (T=3) are used in Equation (10).
The style loss (Gatys et al.2016) has been proved to be effective for capturing image semantic information,which first computes Gram matrix for each feature map of VGG-16,and then calculatesL1norm of Gram matrix.Therefore,it is defined as
whereKiis a weight for scaling,which is given by 1/HiWiCifor thei-th layer of VGG-16,Ψi(I) represents the operator of Gram matrix,which outputs a feature map size ofHi×Wi×Ci.
3.Experimental Results
For evaluating the proposed AANet,experiments are performed to first compare our model with two state-of-theart desaturation methods,PCGAN(Yu et al.2021)and MCNet(Yu et al.2022).Then,the effectiveness of criss-cross attention module is verified by an ablation study.The source code of AANet can be accessed via GitHub (https://github.com/filterbank/AANet).
3.1.Dataset
For training deep learning models,a new large-scale data set beyond the previous one (Yu et al.2021) is established in this work.In this new data set,raw data of 14 bit-FITS format instead of “png” images are included,so that the high fidelity of scientific computing and physical plausibility of computing results can be guaranteed.Each sample of the data set consists of a ground-truth given by the image of short-time exposure without overexposure,a mask image labeling saturated pixels provided by the image of long-time exposure and a manually overexposed image flatten by a preset threshold.We gather M-class and X-class solar flare data at 193 Å of SDO/AIA(Lemen et al.2012) from 2010 to 2017.The short time exposure images closest to the overexposure one of long time exposure are taken as the ground-truths.In addition,they are normalized by the time of long time exposure.A sample of the data set is shown in Figure 6,where the saturated imageIsatis only used to deduce a more realistic mask (denoted byIm) of saturated region by imposing a threshold onIsat,degraded imageIdresults fromIgt⊙Im(⊙represents element-multiplication operator),andIgtis given by the image of short-time exposure closest to the long-time overexposed one.During model training,the triplet {Id,Im,Igt} is fed to our proposed network to optimize the model parameters.The whole data set contains about 18,700 samples.To train and test the network with multiple splittings of the data set,we split the data set into eight equal portions to alternatively select seven of them for training and the rest for testing.Thus,a mean and standard deviation (STD) value on the performance measures can be provided.

Figure 6.An sample in desaturation data set established by Yu et al.(2021),which is composed of four images:Isat,Igt,Im and Id.Isat is a saturated image and Igt is the nearest unsaturated image of short-time exposure. Im is a binary mask which indicates saturated and unsaturated pixels of Isat by 1 and 0,respectively. Id is the simulated degraded image which is obtained by Igt ⊙Im.
3.2.Implementation Details
We evaluate the AANet on our established data set.It should be pointed out that there are two versions of AANet,one is PCGAN plus criss-cross(CC)attention and the other is MCNet plus CC.In our experiments,we employ the well-known data augmentation techniques to augment the training data set,including randomly cropping input image triplet (degraded image,corresponding mask and ground-truth) from 350×350 to 256×256,and randomly rotating (no rotating,90°,180°and 270°) and flipping them.The proposed AANet is implemented by the well-know PyTorch package,trained by a NVIDIA GeForce RTX 3090 GPU with batch size of 28 and epoch number of 200.The convolution weights are initialized by the method in He et al.(2015)and optimized by the ADAM algorithm (Kingma &Ba 2014) with β1=0.500 and β2=0.999.The initial learning rate is set to 2e−4,and then decays half at the 100th and 150th epoch successively.
3.3.Comparisons with State-of-the-Arts
The proposed AANet is compared to the three benchmarks,SE-DESAT(Guastavino et al.2019),PCGAN(Yu et al.2021)and MCNet (Yu et al.2022).
For subjective comparison,seven samples of different saturated sizes are selected from the data set as shown in Figure 7.It can be observed that both the AANet and two benchmarks can recover the whole image well with sharp object edges and rich image structures,but the MCNet (Yu et al.2022)and AANet have more consistent structure with the ground-truth.The MCNet (Yu et al.2022) and AANet can generate a finer texture structure while PCGAN has a slight blocking artifacts at the peak of saturation sometimes,indicating the benefits of non-local information for image desaturation.Specifically,the MCNet employs validness migratable convolution (VMC) to exploit non-local information by copying surrounding pixels before convolution operation.While the AANet refers to non-local pixels through a lightweight attention module.For objective evaluation,peak signal-to-noise ratio (PSNR) and structural similarity (SSIM)(Wang et al.2004) are computed over the testing set for each splitting of the data set,and their means and STDs are listed in Table 1.It can be seen that the two AANets outperform the two benchmarks respectively.The two AANets achieve the PSNR improvements of 1.0 dB,0.54 dB over PCGAN and MCNet respectively.The success of the two AANets is due to the exploration of non-local information.In addition,the “CC” is more beneficial to PCGAN than MCNet since the latter has explored non-local information through the VMC.We also give the STDs of PSNR and SSIM in Table 1.It can be observed that the STDs of PSNR/SSIM are quite small,indicating the models are stable.In addition,they are comparable among all the tested models.
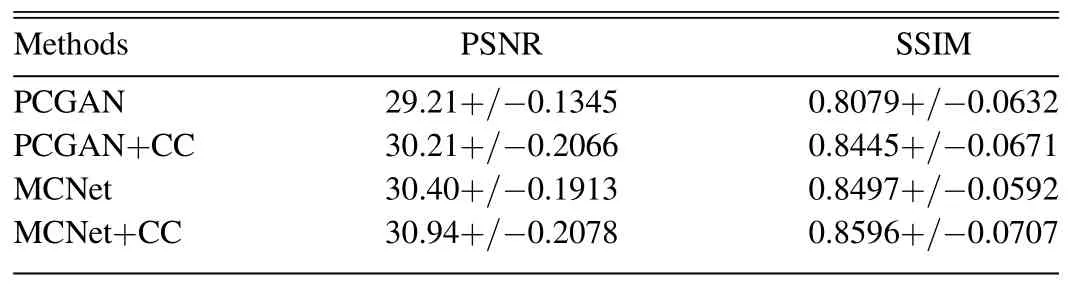
Table 1Quantitative Comparison of PSNR/SSIM (Mean/std) between two AANetModels (PCGAN+CC and MCNet+CC) and Two Benchmarks (PCGAN,MCNet)

Figure 7.Subjective quality comparison among SE-DESAT(Guastavino et al.2019),PCGAN(Yu et al.2021),MCNet(Yu et al.2022)and AANet(“PCGAN+CC”and “MCNet+CC,” where “CC” represents criss-cross).
Comparing AANet with MCNet,they have the different mechanisms of non-local information exploring.The former is through a specially designed convolution operator,namely VMC,and the latter is through the popular attention module.From Table 1,the former is slightly superior to the latter with respect to both PSNR and SSIM.In addition,the attention module is more flexible to explore non-local information.It can be easily embedded in any backbone neural networks,and easily optimized to adapt to the specific task.
We also apply the trained AANet to real saturated images corresponding to long time exposure to evaluate its performance in real scenario.The visual quality comparison among SE-DESAT (Guastavino et al.2019),PCGAN,MCNet and AANet(“PCGAN+CC,”“MCNet+CC”)is shown in Figure 8.It can be observed that the saturated region can be repaired more or less by all of the competitive models,where the size of saturated region shrinks obviously.Compared to PCGAN and MCNet,AANet demonstrates more natural and appealing visual effect,especially for large holes.

Figure 8.Subjective quality comparison for real saturated images among SE-DESAT(Guastavino et al.2019),PCGAN Yu et al.(2021),MCNet Yu et al.(2022)and AANet (“PCGAN+CC” and “MCNet+CC,” where “CC” represents criss-cross).
3.4.Exploring Attention
To study how the attention module is embedded for the best trade-off between efficiency and complexity,we performed a set of experiments by embedding the attention module in the different layers of the network.The backbone network of AANet is a U-Net,where both encoder and decoder can embed the attention module in the different layers.The experiments are listed in Table 2,where“E”and“D”represents encoder and decoder respectively,“CC”represents criss-cross attention,the numbers in parentheses indicate the layers where“CC”module is embedded.

Table 2Quantitative Comparison with State-of-the-art Methods on Testing Set
From Table 2,we can conclude: 1) attention module contributes more to the low-level image features,i.e.,the shallow layers of a neural network.The first three layers with attention module have obvious improvement;2) the encoder benefits more than the decoder from attention module since the former can encode original pixel-level information into the compressed features through attention module while the latter can only access the high-level image features.This is consistent with the result of VMC in MCNet (Yu et al.2022);3) testing over individual layer and combined layers demonstrate that embedding the attention module into the first two layers achieves a good trade-off between efficiency and complexity.
4.Conclusions and Discussion
This paper proposes a criss-cross attention augmented deep neural network,namely AANet,to repair saturated images of SDO/AIA.The experimental results verify that the attention mechanism really makes a difference in the image desaturation task.Unlike general image denoising or enhancement,the information of saturated regions is completely instead of partially lost in our task.Thus,attention module which borrows information from the non-local regions is significantly important to recover lost information.Compared to the benchmarks,the AANet performs better with respect to both qualitative and quantitative comparisons,which attributes to criss-cross attention module for exploring non-local information efficiently.
Acknowledgments
This work was supported by the National Key R&D Program of China(Nos.2021YFA1600504 and 2022YFE0133700),the National Natural Science Foundation of China (NSFC) (Nos.11790305,11873060 and 11963003).
 Research in Astronomy and Astrophysics2023年8期
Research in Astronomy and Astrophysics2023年8期
- Research in Astronomy and Astrophysics的其它文章
- HI Galaxy Detections in the Zone of Avoidance with FAST
- Effect of Neutrinos on Angular Momentum of Dark Matter Halo
- Nonlinear Variability Observed with Insight-HXMT in MAXI J1820+070 and MAXI J1535-571
- A New Method of Frequency Fluctuation Estimation and IPS Processing Results Based on the Downlink Signal of Tianwen-1
- Timing and Single-pulse Study of Pulsar J1909+0122 Discovered by CRAFTS
- Gas Phase Hydrogenated and Deuterated Fullerene Cations