
TcmYiAnBERT:基于无监督学习的中医医案预训练模型*
2023-09-01 12:59:02卢彦杰石玉敬
医学信息学杂志 2023年7期
胡 为 刘 伟 盛 威 卢彦杰 石玉敬
(湖南中医药大学信息科学与工程学院 长沙 410013)
1 引言
中医医案是中医医师临床实施辨证论治的文字记录和实施临床诊断的宝贵经验[1]。但目前中医医案信息化程度低,各医案相对零散且缺乏联系,非结构化数据多,对医案结构化数据的定义难以形成统一标准,严重影响中医医案数据挖掘工作的推进,因此,研究如何从海量中医医案数据中挖掘有用信息具有重要意义。近年来,人工智能在自然语言处理、计算机视觉等领域均取得重要突破,计算机技术已应用于中医药各领域,如中医医案命名实体识别、实体关系抽取、知识图谱构建等。2018年双向编码器表征(bidirectional encoder representations from transformers,BERT)预训练模型[2]问世,并被应用于各类通用自然语言处理任务,准确率大幅度提升。预训练模型先在一个原始任务上预先训练一个初始模型,然后在目标任务上使用该模型针对目标任务特性,对初始模型精调,达到精准完成目标任务的目的。目前BERT预训练模型是基于通用语料训练的,受限于领域知识,难以在各中医医案自然语言处理下游任务中取得良好效果。因此,有些学者研究基于特定领域的预训练模型,如将面向古文、基于BERT的继续训练迁移至古汉语模型得到SikuBERT模型[3],训练面向生物医学领域的预训练模型BioBERT[4]、面向临床医学领域的预训练模型ClinicalBERT[5]、面向科学领域的预训练模型SciBERT[6]、面向专利领域的预训练模型PatentBERT[7],但目前还没有面向中医医案领域的预训练模型。本文基于BERT预训练模型技术,利用光学字符识别(optical character recognition,OCR)技术和爬虫技术获取大量中医医案数据语料,构建首个面向中医医案领域专有预训练模型(traditional Chinese medical YiAn bidirectional encoder representation from transformers,TcmYiAnBERT),并在多个中医医案自然语言处理下游任务实验中证明其优越性。
2 中医医案数据集与预训练模型构建
2.1 数据集构建
本文数据集来源于两方面。一是《中国现代名中医医案精粹》[8]《古今医案按》[9]《明清十八家名医医案》[10]《丁甘仁医案》[11]等中医医案经典书籍,通过Python语言编写OCR程序,将PDF文本转为TXT文本,得到10万条中医医案,共512万字。二是“中医中药网”“中医资源网”“经方派”“道医网”等中医药网站,通过Python语言提供的Request和BeautifulSoup等爬虫库及正则表达式等技术得到120万条中医医案,共4 100万字。剔除一些禁用字、识别错误的字、非中文标点符号的字等,最终得到的数据集共有汉字44 121 245个,对数据集中的每个句子按照15%进行掩码操作,最后按照8∶1∶1构建训练集、测试集和验证集。
2.2 预训练模型
在自然语言处理的各类任务中都需要考虑如何将文本信息转化为计算机能识别的数据形式,早期主流做法是以Word2Vec[12]和Glove[13]为代表的基于预训练静态词向量技术。该技术通常将词汇用多维向量表示,但构建的词向量没有考虑语境,因此无法解决一词多义问题。且该方法本身属于一种浅层结构的静态词向量,在句子较长时无法学习到长距离依赖的上下文语义信息。
基于深度学习算法的另一个特点是各类任务都需要考虑构建大规模带标注的数据集,以便使程序学习到相关的语法和语义信息,但标注数据需要消耗大量低技术的人工成本。自2018年以来,以BERT[2]为代表的超大规模预训练语言模型可有效弥补自然语言处理一词多义及处理数据标注耗时耗力的问题。BERT是一个超大规模的语义表征预训练模型,它从维基百科大规模语料库通过无监督学习到通用的语义表示信息,且该模型可通过微调适应各种下游任务。该模型采用Transformer架构的Encoder模块,基于Transformer的双向编码模型具有强大的特征提取能力,最终生成的字向量融合字词上下文语义信息,能更充分地表征字词的多义性。
2.3 TcmYiAnBERT预训练模型构建
本文预训练模型构建的总体流程,见图1。

图1 TcmYiAnBERT预训练模型构建总体流程
2.3.1 模型的输入 对数据集中每一句文本进行编码得到3个向量,见图2。其中字向量Token Embeddings通过查询字向量表将每个字转换为该字的字编码,句子嵌入编码Segment Embeddings表示文本的全局语义信息,位置嵌入编码Position Embedding表示文本中每个字所在的位置语义信息。
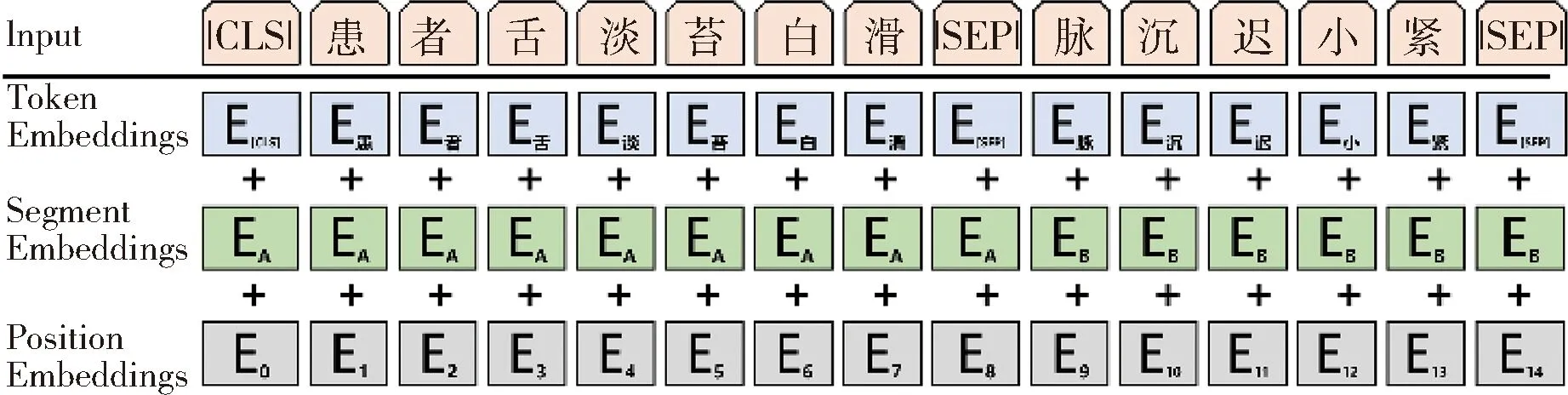
图2 TcmYiAnBERT模型输入
2.3.2 模型训练任务 以BERT模型的掩码语言模型(maskedlanguage model,MLM)和下一句预测(next sentenceprection,NSP)预训练任务为基础进行训练。MLM任务采用在句子中随机掩盖掉若干字的方式学习该字在上下文的语义信息。如将“患者舌淡苔白滑脉沉迟小紧”这个句子掩盖若干字后变成了“患者[mask]淡苔[mask]滑脉沉[mask]小紧”,然后通过模型训练预测[mask]处的字信息,见图3。NSP任务主要目标是预测两个句子是否连在一起,令模型学习两个连续句子的关系,使模型具有更好的长距离上下文语义学习能力,如“患者舌淡苔白滑”和“脉沉迟小紧”同时输入模型,最后模型输出这两个句子是否连在一起。
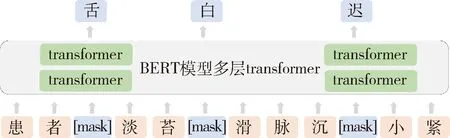
图3 TcmYiAnBERT模型 MLM任务示例
2.4 TcmYiAnBERT预训练模型发布
采用Pytorch 1.15框架、Python 3.7版本环境,模型参数与BERT模型一致,设置12层Transformer、12个Attention-head、768个隐藏层单元,整个模型有110兆参数。实验过程中,将BERT模型参数最大句子长度设置成256,批处理大小设置成64,训练轮数设置为100。最终在单台V 100显卡机器上经过680小时的训练得到本文的TcmYiAnBERT预训练模型,并且将该模型发布到Huggingface网站(https://huggingface.co/lucashu/TcmYiAnBERT)。
3 实验结果与分析
3.1 验证实验数据集和任务
采用中医医案命名实体识别任务对TcmYiAnBERT模型性能进行验证,验证模型包括TcmYiAnBERT预训练层、BiLSTM层和条件随机场(conditional random field,CRF)层,见图4。

图4 TcmYiAnBERT-BiLSTM-CRF模型
验证实验用的数据集是从《中国现代名中医医案精粹》中选取的1 000条高质量医案,并由多位经验丰富的中医学者对数据集标注。数据集采用命名实体识别任务通用的BIO标注法,共设计功效实体、辨证实体、治则实体、症状实体、方药实体、人群实体6类实体类别。
3.2 验证实验任务评价指标
采用命名实体识别任务常用的精确率(P)、召回率(R)和F1测度值评估模型性能。假设Tp表示模型识别正确的实体个数,Fp表示模型识别错误的实体个数,FN为模型没有识别出的实体个数。计算方式如下:
(1)
(2)
(3)
3.3 验证实验任务结果
选取命名实体识别3种经典模型,对比验证TcmYiAnBERT模型在下游任务的效果,见表1。
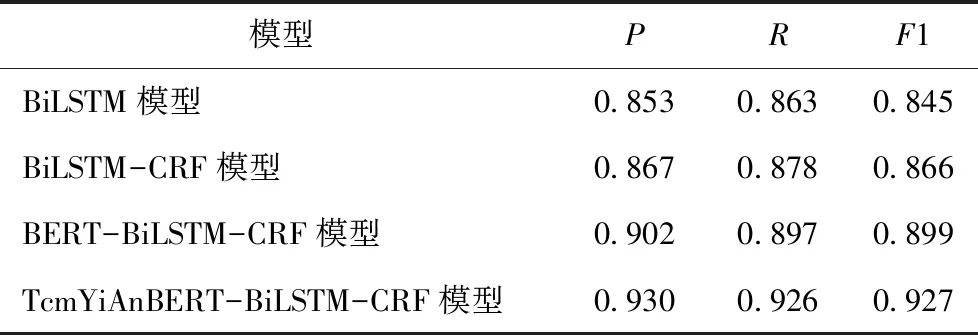
表1 对比模型实验结果
TcmYiAnBERT-BiLSTM-CRF模型得到的各类症状实体评价指标,见表2。
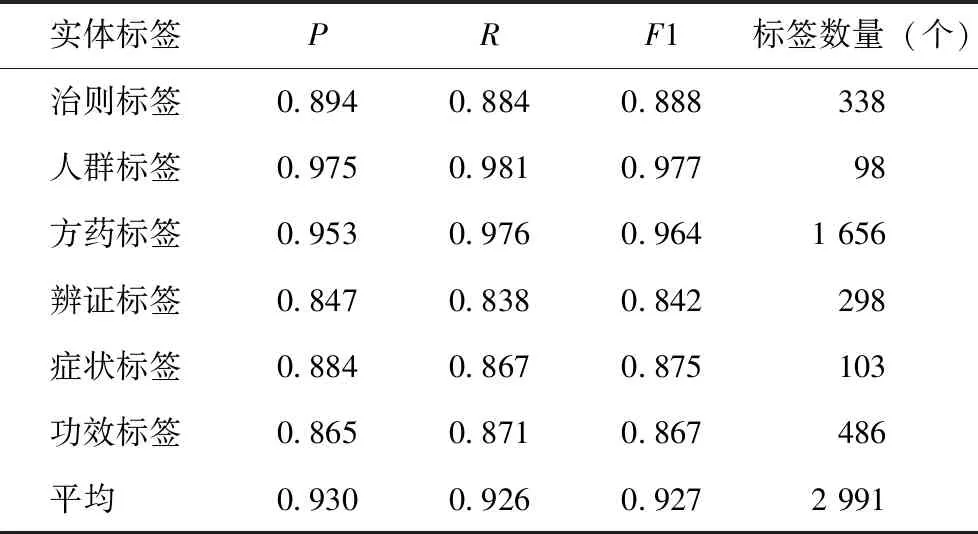
表2 TcmYiAnBERT-BiLSTM-CRF模型各类实体识别结果
从结果可以看出,加入中医医案领域专有预训练模型TcmYiAnBERT后,在命名实体识别任务中不同实体标签结果存在一定差异。
3.4 实验结果分析
从实验结果可以看出,在中医医案自然语言处理命名实体识别任务中,相比于传统的BiLSTM模型,加入CRF后准确度有所提升,加入预训练模型BERT后准确率提升效果较明显,而加入中医医案领域专有预训练模型TcmYiAnBERT后,准确率有更大提升,说明在中医医案自然语言处理任务中,专有领域的预训练模型TcmYiAnBERT比通用领域的预训练模型BERT更具优势。其原因是预训练模型TcmYiAnBERT通过MLM任务和NSP任务已经提前学到了大量中医医案语义信息,在中医医案下游任务中,只需要在该模型上微调即可达到较高的准确率。
从6类实体识别结果可以看出,方药实体标签和人群实体标签的准确率较高,治则、辨证、功效实体标签的准确率低于前面两类标签。其原因既与命名实体识别任务数据集划分有一定关系,又与预训练模型的数据来源有一定关系,预训练模型的数据来源于中医医案经典著作和中医医案网站,在预训练模型训练过程中学到的方药实体标签和人群实体标签语义信息较多。后续将增大数据集,进一步提高中医医案各类自然语言处理任务的准确率。
4 结语
本文构建首个面向中医领域专有预训练模型TcmYiAnBERT,并在中医医案自然语言处理下游任务命名实体识别任务上实验证明其优越性。该预训练模型对中医医案的分词任务和实体关系抽取也将有一定帮助,进而为中医药信息化提供技术支撑。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
中国外汇(2019年18期)2019-11-25 01:41:54
基层中医药(2018年4期)2018-08-29 01:25:46
基层中医药(2018年3期)2018-05-31 08:52:03
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
中国中医药现代远程教育(2014年23期)2014-03-01 04:33:52
