
云计算环境下数据安全存储的初始划分与分配策略研究*
2023-08-31 08:39赵鑫宇郭银章
计算机与数字工程 2023年5期
赵鑫宇 郭银章
(太原科技大学计算机科学与技术学院 太原 030024)
1 引言
云存储服务给用户提供虚拟化的存储资源池,数据实际存放在各个CSP 的服务器集群上[1],不受用户直接监管。据调研机构RedLock 公司数据显示,仅2017 年至2018 年就有超半数组织的云存储服务发生数据泄露。针对云存储中数据的安全性问题,大量研究从数据本身安全出发[2],研究数据加密存储技术、完整性审计技术、加密访问控制技术等安全存储策略[3~4]。而从云计算数据存储的过程来看,如何有效地将数据资源划分成合理的数据片,部署在恰当的物理集群位置,以防止个别结点被入侵后,按照存储路径使相邻节点乃至整个云存储系统遭到破坏,已成为云数据存储安全性研究的另一个重要问题。云环境中用户数据存储过程如图1 所示,因此,需要基于安全性考虑,进一步研究云环境下数据存储物理空间布局和存储路径优化策略,以避免数据的泄露和破坏。
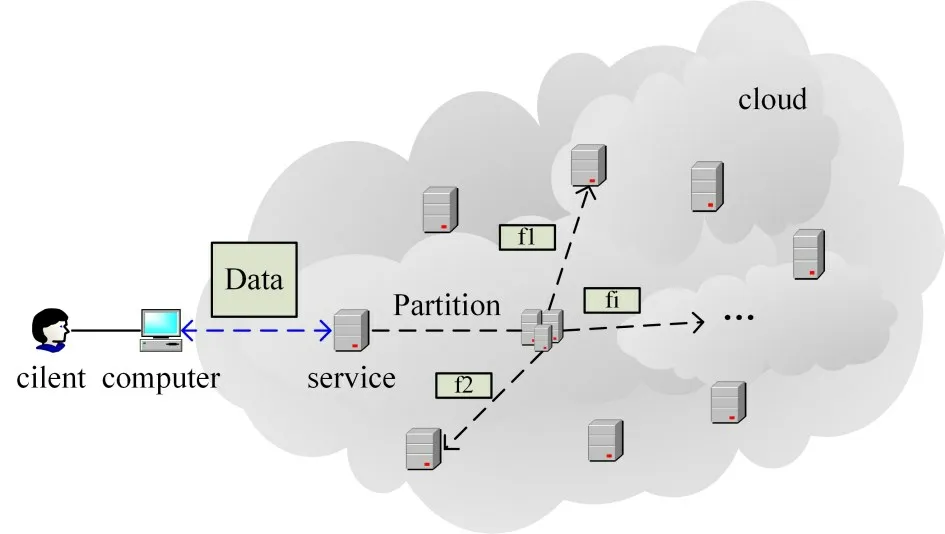
图1 云中数据存储过程
2 相关工作
数据资源初始分布包括数据片段的划分和分配。在数据划分阶段,传统数据库(Oracle、DB2等)[5]采用简单分片技术(hash、Range等)。各大云平台则构建各自的数据存储管理系统,谷歌的GFS和Big Table 均采用默认大小数据分片[6];亚马逊的Dynamo 采用一致性hash 算法[7]随机分片。21 世纪前后,大量复杂分片技术被提出[8~9],文献[10]根据数据属性间相关度垂直分片,添加泄露概率门限、伪造数据等安全措施。
在数据分配阶段,聂世强等[11]结合矩阵表示和聚类算法,提升一致性hash算法的性能。为解决个多应用目标,Wu Q 等[12]提出了一种多目标进化算法。Sharma N K 等[13]结合粒子群和遗传算法,对云环境资源利用率和节能等目标进行优化。
基于安全需求,Ali M 等[14]将数据片段分布问题定义为图着色问题,结合T-color[15]思想提出DROPS策略,通过保持“距离T”降低数据被完整获取的可能,并保证较高数据检索效率。Kang S等[16]开发了SEDuLOUS系统,定义线性规划模型并设定安全等级机制,优化数据检索效率。吴超等[17]借鉴文献[15],按权重合成安全评估、访问效率评估函数为最终适应度函数,用遗传算法求解数据片段分布方案。这些文献中虽然都将安全性作为优化目标之一,但缺少具体数据分片、多备份存储策略,也没有考虑结点发生数据迁移时的负载均衡等问题。
3 云数据资源初始分片策略
将网络中不同地理位置,具备存储功能的数据中心(设备)定义为结点,假定总数为N,用户所须安全标准为L。云数据资源初始分布流程:将用户上传的某份数据data,划分为n个片段,合理分配到N 个结点上,以达到安全等级L。其中需解决的问题有安全等级L 的标准的建立、划分n 个片段的原则、片段划分和分配的策略。
3.1 数据分片标准建立
定义1 最终的安全需求定级L:
其中,Q代表上述环境中,2n个结点被入侵时,数据片段均被非法获取的概率范围。H 即结点间通信需经历的跳数hop,数据存储在单个结点或相邻结点时,hop 均定义为0。如图2 所示的G(V,E)图,在包含8 个存储结点的网络中,深色结点表示满足hop=1 安全标准的一种存储方案,其中所有数据片段所在结点互访时需经历至少一个不存放分片的结点。
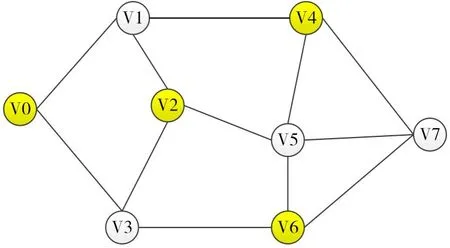
图2 hop=1,着色结果
3.2 数据分割依据确立
定义2 根据3.1 节所述情形,由组合数学可求得数据泄露概率P。
对分片数量n 按升序遍历,求解P 符合安全量级Q的要求,即可获得的详细符合安全标准的分片数量范围。表1 给出低规模结点集群中,Q 对应的最低分片数量标准n。
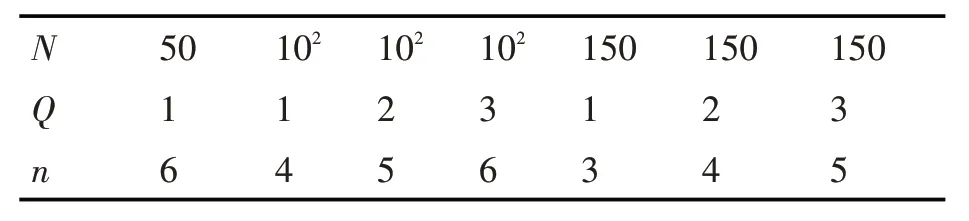
表1 分片数量标准
3.3 数据分片的实施
如图3,该算法对完成range分组且确立了数据划分数量的数据,进行随机大小分片,将划分后的碎片按照大小降序排列,有助于后续数据分配策略的实施。

图3 数据分片算法
4 云数据资源初始分配策略
4.1 数据初始分配策略
数据初始分配由SA-Greedy 算法完成,借鉴了贪心算法和T-color 思想。根据前文中的问题描述,核心问题为在结点分布的G(V,E)图中,保证hop 要求(L 指标之一)的前提下,贪心选择数据片段的存放位置,优化数据检索效率、系统负载均衡等指标。
定义3 为针对目标进行有效优化,本文对数据的检索代价CT做如下定义:
上式主要考虑数据传输代价,由数据的发送时延和传播时延两部分组成,前者为数据大小data_size 与网络传输带宽B 的比值,后者为由信号的传输距离shortest_path 和在传输介质中速度speed_trans的比值。
定义4 为在多个满足限制的结点中选择合适的存储结点,需同时考虑结点负载和传输代价问题,结点的利用率和传输代价均与存储目标负相关,因此本文定义了各个结点的优先程度数组priority[N],作为贪心选择的主要指标。
其中use_rage[i]代表i 结点的使用率,用传输代价和结点利用率乘积的倒数作为评判指标,分配某一片段时选择优先度最高的结点,分配完成后即更新相关属性。
定义5 当前数据存储方案优越性sp:
其中n代表当前数据分片数,priority[i]代表第i 个碎片存储位置的优先级,Si代表当前碎片大小。采用贪心算法进行数据片段的位置选择,可使sp在L需求下取到最大值。
数据分配算法如图4,代码1~3 行代表输入所需参数,5~31行对数据的每个片段进行位置选择。

图4 数据分配算法
其中7~11 行,求解当前分配片段符合安全要求的结点标号存放在satisfy[]中;求解每个结点的优越性存放在priority[]中。12~26 行,为当前数据的片段i 选择优越性最高、符合安全要求且存储剩余容量满足的结点并更新集群结点状态。26~29行,在当前数据对象完成分配后,判断当前待存储片段是否存储成功。32~33 行重置集群中结点的着色允许状态,以备下一个数据存储。
4.2 算法正确性分析
贪心算法的解的最优性,需证明贪心选择性和最优子结构性质。
1)贪心选择性质
本文策略在为每个数据片段i选择存储位置的时候,总是在所有当前符合L 标准的结点中选择priority值最大的结点,该选择方法符合贪心选择性质。
2)最优子结构性质
对n 个数据片段先按片段大小进行降序排列,假设完成排序后每个片段的大小为Si(S0最大);然后对可选结点根据priority值降序排列,每个结点的的优先级表示为priority[i]。求解前i 个片段的最大sp 值表示为f(i)。正常情况下,集群结点容量充足,对于单次片段的分配过程,可选的n 个最大pri-ority值的结点是固定的。
证明1:
当i=1时,易得f(1)=priority[1]·S1;
当i=2时,Si与priority[i]的组合方式有两种,
假设:S2+x=S1;
priority[2]+y=priority[1](x>0,y>0);
计算可得:
(priority[1]·S1+priority[2·S2)-(priority[1]·S2+priority[2]·S1)=x·y>0;
故:
f(2)=priority[1]·S1+priority[2]·S2;
同理可递推证得,当i=3…n时:
上述性质同时成立证明本问题使用贪心策略能够获取sp的最优值。因此,本文所提算法能在保障安全性的前提下,很大程度提升系统在负载均衡和检索效率方面的表现。
5 实验仿真
本文通过数值模拟方法,求解使用SA-Greedy方法进行数据资源初始分配的结果。对比该策略与DROPS、一致性hash 策略、最远优先存储策略、GA在执行耗时以及各自所得布局方案在系统负载均衡、数据检索效率、安全性能上的表现。
5.1 对比实验组一
基础参数:N=50,M=100,Q=1,hop=1;结点容量取值范围50GB~100GB 的随机值,单个数据大小取1GB~5GB 的随机值,T=300km,结点实际位置:横纵坐标0~1000,面积为1000km*1000km 区域内随机分布。策略实施时n值固定。独立重复完成20次源数据分布后,各项指标的中位数结果如表2。

表2 实验组1中位数结果
可看出实验中SA-Greedy 在检索效率上表现仅次于单目标遗传算法,比DROPS 高出15%左右;算法耗时长于普通随机策略,显著短于复杂的进化算法;而由于选择的低安全标准和集群规模,在安全性和负载均衡性的表现上无明显优势。
为进一步研究云计算环境下,结点规模、数据量对几种分布策略的性能表现,本文扩展初始环境,调整存储数据量,进一步对比各项指标。
5.2 对比实验组二
基础参数调整:N=100,M=100,200,500、1000、2000;Q=3,hop=2;结点容量取范围500GB~1000GB的随机值,单个数据大小取2GB~10GB 的随机值,T=500km。对于每个M 值进行20 次独立重复实验,实验结果如图5~7。
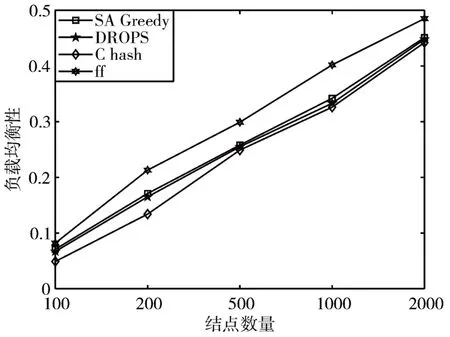
图5 负载均衡对比
在当前环境下,L=6 时,SA-Greedy策略的Safty指标均达到109,达到最优,且能有效避免临近结点变节带来的安全风险。图5 显示SA-Greedy 与DROPS 的负载均衡性均优于最远优先存储策略,略逊于一致性hash策略,但无显著差异。在算法的执行耗时上,图6 说明一致性hash 策略和最远优先存储策略有明显优势,SA-Greedy与DROPS耗时相仿,但由于本次实验耗时仅针对源数据,而DROPS的二轮存储策略的实施极为耗时,故本文所提策略的耗时优于DROPS方法。数据检索效率上,由图7可知,随着数据存储量的增加,SA-Greedy 策略能够更好的保障用户体验。
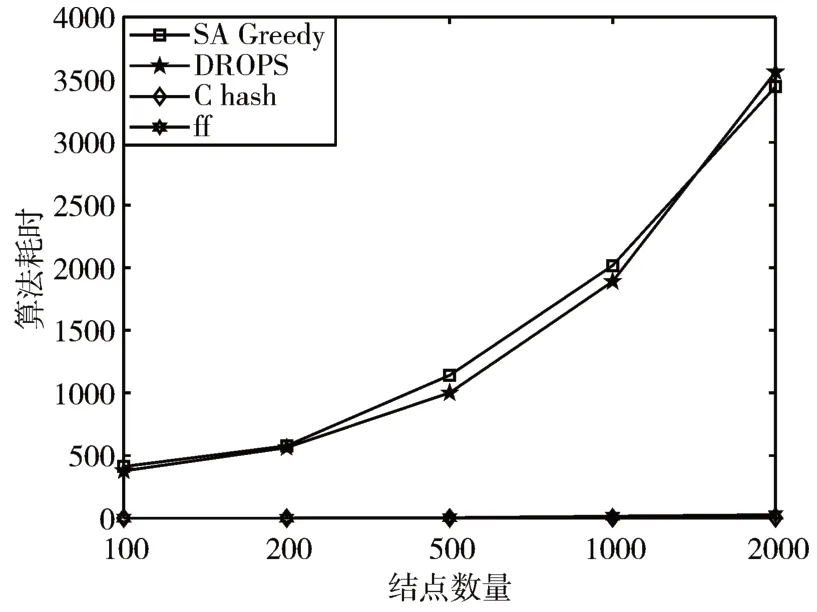
图6 算法执行耗时对比
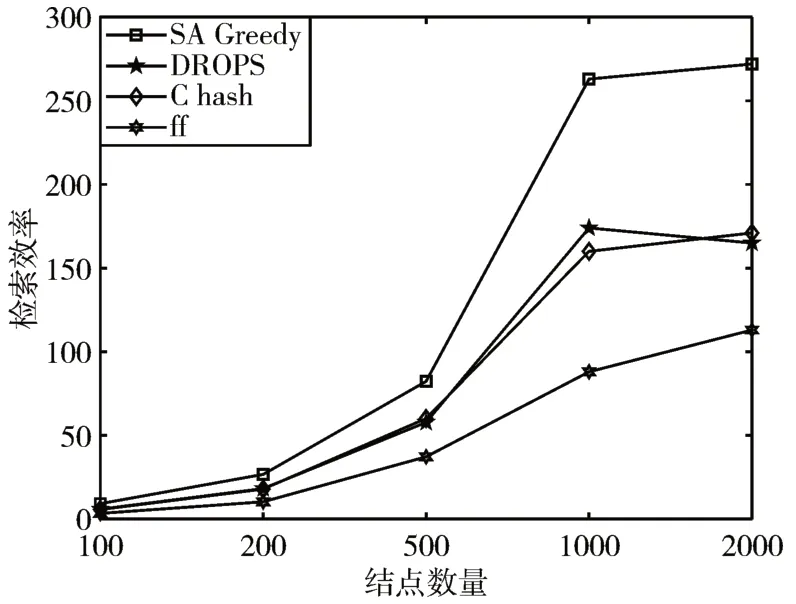
图7 数据检索效率对比
通过上述对比实验可知,SA-Greedy 算法与传统算法相比,在数据的安全性和检索效率上有显著改善。
6 结语
本文所述的SA-Greedy 方法,综合数据分布的分片、分配阶段提出了清晰的安全分级标准L 供客户选择;求解出云中符合标准L 的数据分布方案。实验对比证明SA-Greedy 方法在保障了数据存储安全性的同时,有负载均衡,执行耗时短、检索效率高等优越性。下一步研究:1)针对不同类型数据,提出详细的数据划分依据;2)发生批量数据“删”、“改”操作时,动态调整数据位置来保障系统性能。
猜你喜欢
词学(2022年1期)2022-10-27
中国交通信息化(2022年4期)2022-06-17
数学物理学报(2020年5期)2020-11-26
广东通信技术(2020年10期)2020-10-26
火控雷达技术(2018年4期)2019-01-15
数学物理学报(2018年1期)2018-03-26
装备学院学报(2017年3期)2017-07-21
装备学院学报(2017年2期)2017-06-05
计算机工程(2015年8期)2015-07-03
电子设计工程(2014年12期)2014-02-27
