
基于FPGA+GPU的图像采集处理系统设计
2023-08-30 03:17蒋俊伦丰大强徐新瑞常中坤
计算机测量与控制 2023年8期
蒋俊伦,丰大强,徐新瑞,程 坤,常中坤,王 桢
(山东航天电子技术研究,山东 烟台 255000)
0 引言
近年来,地面扫描观测设备得到快速发展,扫描观测需要实时采集存储数字图像,对图像采集技术的要求也越来越高。图像采集模块采集到的图像的质量对后续设计的准确性有极大的影响。作为图像信号处理系统的重要组成部分,图像采集模块的速度、分辨率、可靠性以及集成性等方面受到了越来越多的关注[1]。目前,图像采集系统大多采用电脑端使用的图像采集卡,这种图像采集卡采集速度快、可以保证较高的采集精度,但体积大、功耗高,而且只能在电脑端使用,无法在便携式产品中使用。从适应性角度考虑要求图像采集系统性价比高,环境的适应能力要强,并且要易安装和使用。嵌入式图像采集处理系统为图像采集提供了新的实现途径,但单纯应用ARM或DSP 等嵌入式平台由于其存储容量有限、处理速度低、扩展性较差的特点,不能满足当前图像采集系统的带宽需求[2]。
图像采集前端模块是整个图像采集系统的核心部件,会直接影响到整个系统的工作执行效率。考虑到目前扫描观测设备的图像数据分辨率高、帧频快,如何使用恰当的方法采集、传输以及存储高质量的图像是一个非常重要的问题。图像采集的整体过程相对比较简单,但是图像采集时,图像的数据量非常的大,系统对实时性要求非常高[3],图像采集的实时性是仅靠软件是无法实现的,开发人员要考虑使用软件与高速硬件系统相结合的方式来完成对图像的高速实时采集[4]。
文献[5]中,采用MSP430单片机作为主控芯片,通过USB数据采集技术实现对监控现场视频数据的采集和传输,但该方案最终达到的数据传输速率仅为8~10 Mbps。对于目前相机来说,常规的相机参数可达到640×512像素,单像素12位采样,帧频100 Hz,数据量可达到375 Mbps。该系统难以满足实际应用需求。
文献[6]中,提出了一种基于现场可编程逻辑门阵列(FPGA,field programmable gate array)的高速图像采集系统硬件方案。采用FPGA 作为图像采集主控芯片,大大简化了系统硬件结构,并提高了系统可靠性,同时可以应用于高速图像采集中。但FPGA操作起来流程复杂,应用门槛较高。
同时为了保证采集到的图像的完整性和连续性,不仅要对图像数据进行采集,而且要对原始数据进行缓存。一般的图像采集模块主要包括存储器单元、CCD或者CMOS相机接口以及总线接口等。系统中设计了一个图像采集处理系统,采用Xilinx公司的XC7K410T FPGA进行相机图像采集以及与其他设备如转台之间的信息交互。采用英伟达公司的Jetson TX2 GPU作为图像数据存储处理的平台。XC7K410T 通过LVDS接口采集相机数据,采集到数据后通过PCIE总线将图像数据传输给TX2,TX2再将数据存储到固态硬盘中,以进行后续的处理。
1 系统结构及原理
对相机图像进行采集存储需要一个可靠性好、携带便捷以及实时性高的完整系统。该系统由电源模块、外设模块、FPGA、GPU、固态硬盘组成。其中:
电源模块为系统中FPGA、GPU、外围电路器件提供供电,典型电压包括:5 V、3.3 V、1.8 V、1.2 V和1.0 V。外设模块实现与相机等外部设备的通信,包括RS422接口、LVDS接口。GPU模块使用TX2模组,TX2使用Linux操作系统作为底层系统,可以充当上位机的功能。与此同时TX2实现通过PCIE从FPGA接收传送的相机数据,将接收图像数据通过SATA接口存储到硬盘中,并执行相应的图像处理算法,将处理出的结果进行转发。FPGA模块通过16路LVDS接收到图像数据并通过PCIE发送到TX2模块中。系统的原理如图1所示。
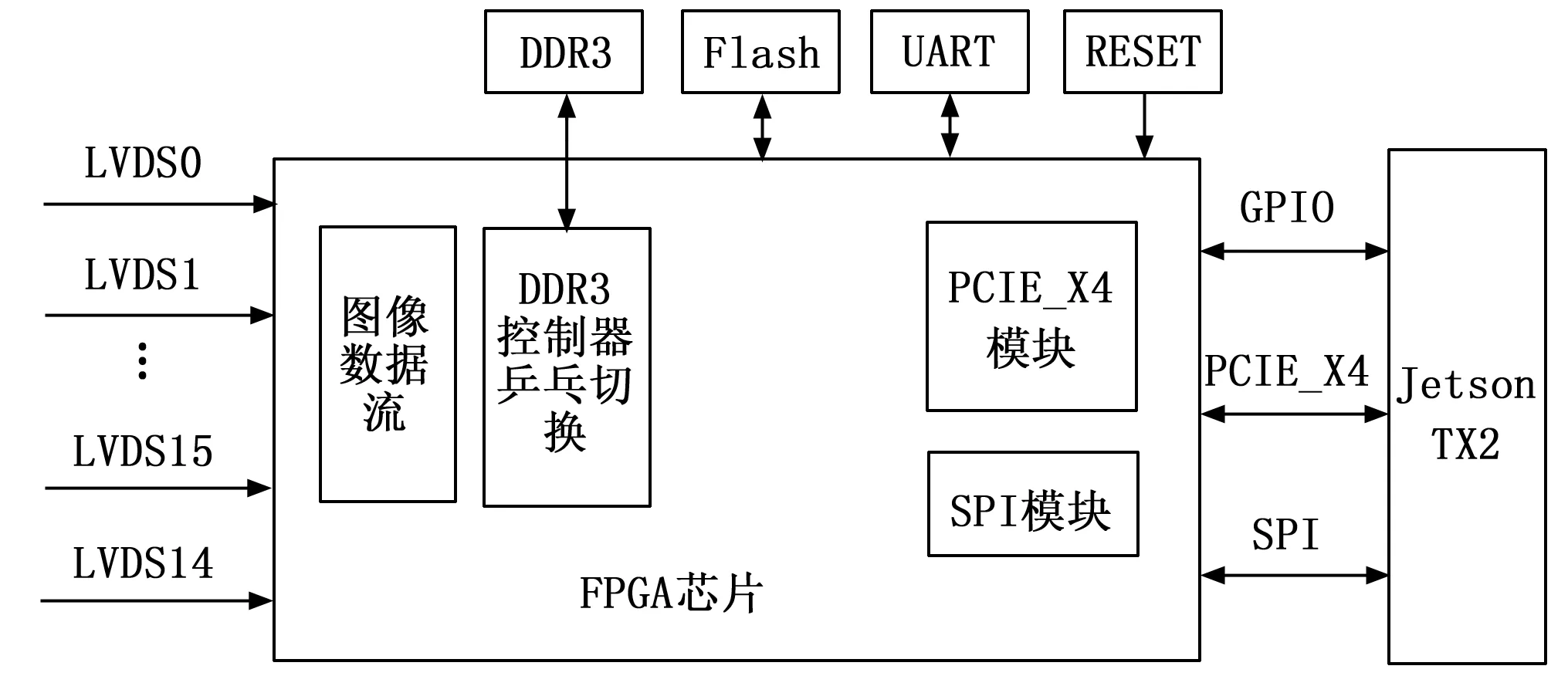
图1 图像采集系统原理图
2 系统硬件设计
2.1 Jetson TX2模块
图形处理器(GPU,graphic processing unit)是一种专门进行图形处理的硬件设备,经过近年来的快速发展,GPU已经从最初的图形处理领域扩展到机器学习、深度学习、三维重建等并行计算领域,其架构从专用于图像处理的固定架构发展到了用于通用计算的并行计算架构[7-8]。相比于CPU,GPU在并行计算、分布计算和浮点运算方面的运算能力可以高出数十倍乃至上百倍。在嵌入式硬件方面,英伟达公司在2013年推出Jeston TX2模组,TX2是一款高性能、低功耗的AI 单模块超级计算机,采用GPU+CPU架构设计,其GPU采用新一代Pascal架构设计,具有256个CUDA 核;CPU使用集成了四核的ARM○R CortexTM-A57处理器(PS-processing system)。外围电路方面该模组还包括10/100/1000BASE-T以太网络接口,同时配备了8 GB的DDR4内存和32 GB eMMC5.1 Flash存储空间。另外具备HDMI、CSI、SATA等外部接口,其浮点计算能力可以达到1.5 Tflops。因此选用TX2作为图像采集处理的核心模块十分方便快捷,其强大的数据处理能力可以将图像数据快速的写入到固态硬盘中,另外TX2还可以通过图形化界面与用户交互,容易操作。
在本系统中TX2的作用包括两部分:一是利用SPI模块发送消息通知FPGA开始进行图像数据采集;二是通过PCIE模块将图像数据从FPGA接收数据,并将数据通过SATA接口写入到固态硬盘中。
2.2 FPGA模块
FPGA是一种可以通过编程来改变内部结构的“特殊芯片”,自Xilinx公司于1984年研发了世界上的首款型号为XC2064的FPGA以来,FPGA的发展经历了多个阶段[9]。目前最新的FPGA逻辑门的数量已经达到亿级以上,工艺尺寸也达到了16 nm左右,无论是功耗还是性能,相比于XC2064都得到了极大的提升[10]。与普通的集成电路芯片相比,FPGA具有许多十分突出的特点,FPGA的可编程特性使它不仅可以用于ASIC(专用集成电路)的设计,同时可以用来完成ASIC芯片的原型验证。FPGA常采用高速的CMOS工艺进行设计,具有低功耗的优势,而且其内部包含丰富的触发器和可编程I/O资源,可以用于实现较大规模的集成电路设计。FPGA在体系结构上有很大的并行度,这使其十分擅长并行数学计算[11]。
FPGA模块采用Xilinx的XC7K410T 芯片,通过16路LVDS接口接收相机数据,其中14位数据,1位GATE,1位选通。1路RS422作为相机控制接口,1路RS422作为遥测遥控接口,一路RS232作为转台控制接口。数据采集转发FPGA具体型号为XC7K410T-2FFG900I,该芯片的主要性能如下[12]:
具有48万逻辑单元;
具有37 Mbit内部RAM;
具有2 800个DSP48E模块;
具有32个GTX接口模块;
具有14个CMT模块;
具有700个HPIO管脚。
由于该FPGA是基于SRAM结构的FPGA,具有设备断电后数据丢失的缺点。需要为XC7K410T-2FFG900I专门配备一个程序存储器用来存储配置数据,在设备上电初始化时完成配置数据的装载。K7系列的FPGA支持×1,×2,×4三种SPI加载方式,Flash选择S29GL512P11TFI010,该芯片+3.3 V供电,容量512 Mb。
由于相机输出14位宽的数据,帧频100 Hz,相机像素分辨率640×512,由此将产生14 bit×100 MHz×640*512(约为437.5 Mbps)的数据量,考虑到TX2使用的是Linux系统,Linux是一种非实时响应的操作系统,这么快速的数据量即所谓的迸发数据流没有办法直接通过DMA传送给TX2,需要将图像数据临时存储在内存条(DDR3 SDRAM)中。DDR3存储器是一种采用时钟双沿工作的高速存储器,是处理器常用的片外存储器。与静态随机访问存储器(SRAM,static random access memory)所采用的CMOS 工艺不同,DDR3存储器采用动态随机访问存储器(DRAM,dynamic random access memory)动态电路工艺,多采用电容储值,读写之前必须先对数据线进行预充电;读是破坏性的,读后必须写回;漏电流的存在使得DDR3 必须保持定期刷新(读出放大后再写回)[13]。
FPGA通过对DDR3 SDRAM的访问存储器控制,实现大容量迸发数据的读、写、刷新等时序操作。当FPGA收到图像数据后将数据缓存到DDR3内,当收满一副图像后FPGA将数据放到DMA内通过PCIE总线发送给TX2。
2.3 电源模块
电源模块为整个系统供电,采用+28 V电源作为输入电压,将直流+28 V供电转化成设备各组件工作所需的+12 V、+5 V电源等,其中TX2模块供电模块与FPGA供电模块分别采用不同的电源模块,实现TX2模块与FPGA模块的相互独立。
+12 V为TX2模块供电,+5 V为FPGA模块供电。直流28 V输入电源后,首先经过滤波后供给DC/DC转换模块,转换成设备所需的工作电压,滤波后输出给各用电设备组件。供电模块原理如图2所示。
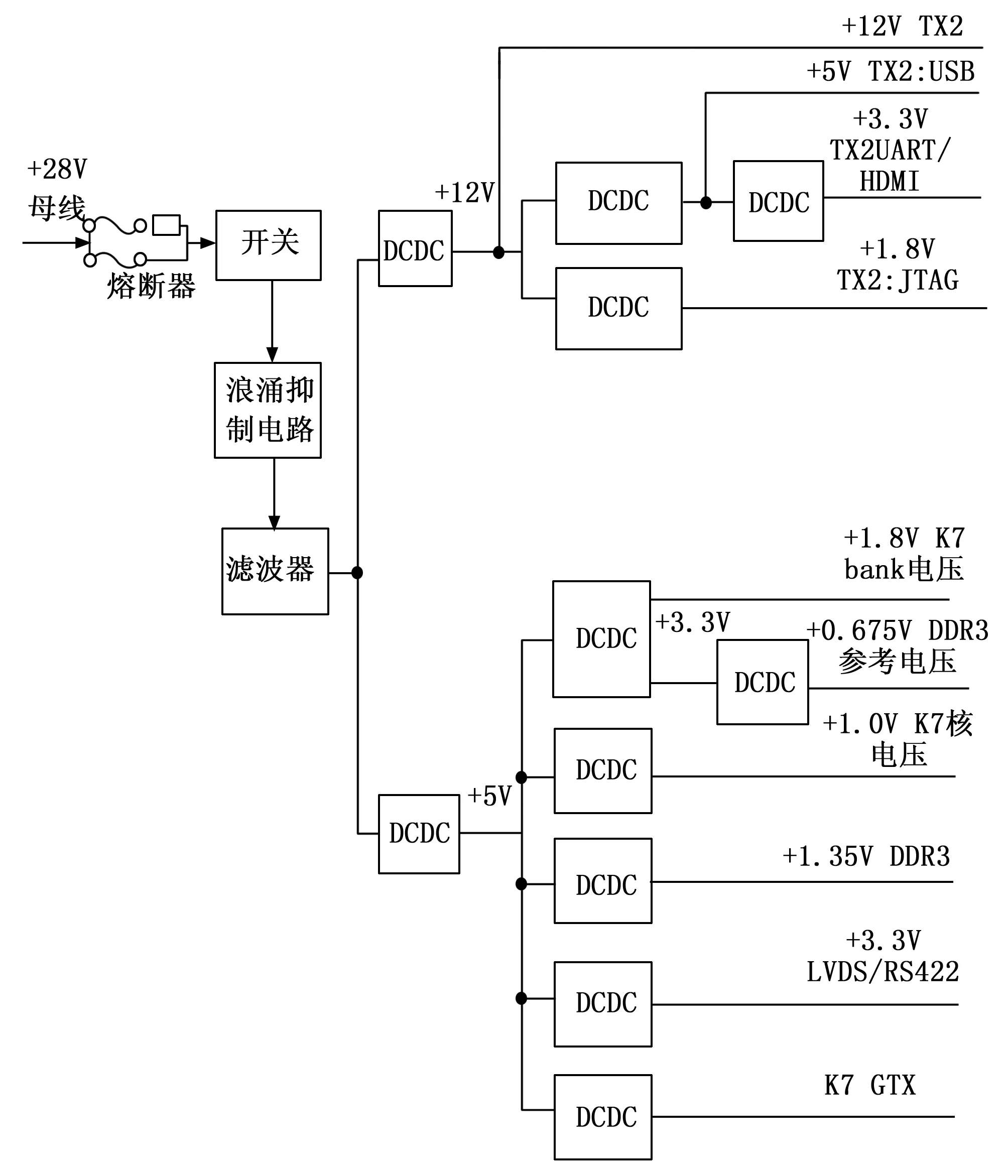
图2 供电模块原理框图
2.4 外设模块
本系统中外设模块主要包括低电压差分信号(lowvoltage differential signaling,LVDS)接口、RS422接口,LVDS共16路,其中14路为数据、1路为选通、1路为时钟,时钟速率为31.25 Mbps。LVDS接口用于保证图像采集和传输,可以将图像高速数据实时的进行传输存储。RS422接口用于相机控制、转台控制等。
3 系统软件设计
基于FPGA+GPU的图像采集处理系统软件程序主要包括FPGA程序设计、TX2驱动程序设计和TX2应用程序设计。FPGA开发基于Xilinx公司的Vivado集成开发仿真环境。TX2本身自带Linux操作系统,可以在Linux上安装VScode软件,使用VScode对TX2驱动程序和应用程序进行编写编译。
本系统中TX2是系统软件的运行主体,当系统启动后,操作人员通过TX2上位机界面,发送图像采集指令给FPGA,FPGA接收到指令后对指令进行解析处理,读取图像数据,并将数据发送给TX2。系统软件的程序流程如图3所示。
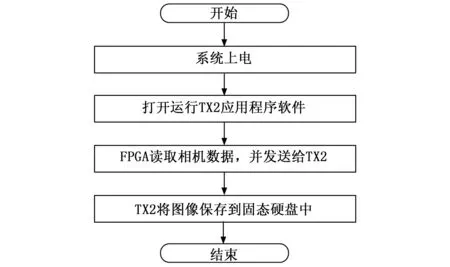
图3 系统流程图
3.1 软件设计思路和编程方法
3.1.1 FPGA程序设计
FPGA内部逻辑结构如图4所示,包括PCIE模块,PCIE协议处理相关模块,DDR3缓存模块和SPI及串口模块。系统上电后进入复位状态,复位完成后接收TX2通过PCIE发送的指令进入相应的工作模式,包括空闲模式和采集模式及系统复位模式。TX2通过PCIE接口配置相关的寄存器来实现对设备工作模式的修改,实现TX2对相关外设的控制。
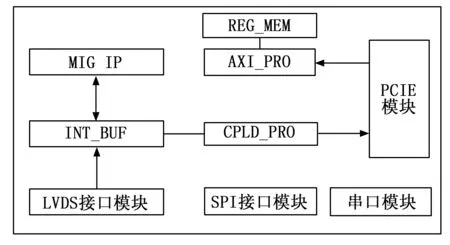
图4 FPGA逻辑框图
1)DDR3控制器:DDR3控制器使用Xilinx官方IP核,该IP核为免费IP,其内部包含了基本的时钟和复位处理模块、物理层接口处理模块、延时控制单元、读写控制器、数据缓存单元及用户接口等模块。其中时钟和复位处理模块通过内部的PLL生成IP核所需的时钟网络和相应的复位信号。物理层接口模块负责完成和物理芯片的交互,对DDR3物理接口的高速DDR时序进行处理,通过延时控制单元完成数据相位的延时和相位对齐等操作。此外IP核内部还利用FPGA内部的缓存器实现对物理层数据的跨时钟域缓存,以实现数据位宽的转换以及物理层时钟向用户层时钟的跨时钟域设计。用户接口模块负责对用户的指令进行译码,缓存用户数据以及对用户的数据实现流控。设计中采用的DDR3硬件数据位宽为16位,容量为2 Gbit,理论读写速率可达50 Gbps,考虑在实际控制时的带宽损耗,即使是在带宽效率为50%时带宽也可达到25 Gbps,而实际应用时相机的速率为2.5 Gbps,满足传输速率要求。
设计中的INT_BUF模块负责对DDR3用户数据的打包和缓存,实现时采用片上FIFO进行缓存及实现跨时钟域的处理,根据设计指标,片上FIFO的读写位宽为128位,深度为一帧图像中的三行数据。
系统上电后,进入复位转台,复位完成后状态机为IDLE状态,在该状态下,等待上位机发送的读写指令。在空闲状态下,图像数据虽然实时采集,但是不进入DDR3缓存,当收到采集指令时通过LVDS协议区分数据格式的开头和结尾,对数据进行读取和传输。
FPGA与TX2之间大容量数据传输设计原理如下:当图像数据采集开始,FPGA将接收到的图像数据写入DDR3中,并开始将DDR3中的数据转存到DMA空间中,等待TX2发起读数据请求。由于DDR3和FPGA的速度极高,而TX2是非实时操作系统,所以在图像数据的转存系统设计过程中,要着重考虑两者之间数据传输的同步问题。在进行图像数据传输过程中,FPGA应时刻检测当前周期内从DMA中读出的数据是否已经被TX2接收完毕,若未完成接收,则不能继续将数据从DDR3写入到DMA中,直到TX2完成数据接收存储,才进行DDR3下一周期的数据读取。
2)PCIE模块:PCIE 总线从PCI总线演化而来,PCI总线使用层次式体系结构,通过PCI桥将父总线和子总线连接起来。PCIE总线是一种全新的串行总线技术,可以实现全双工点对点的传输。它彻底变革了PCI总线的并行技术,克服了PCI总线在系统带宽、传输速度等方面的固有缺陷[14]。PCIE总线的发展也是高速IO总线的过程,PCIE总线相比PCI总线具有以下特点:PCIE总线在数据传输模式上,采用双通道全双工串行传输。一条PCIE通道包括一条发送通道,一条接收通道,速率可达到2.5 GB/s。同时针对不同通信带宽的设备,PCIE可根据具体需求配置成×1、×2、×4、×8的并行通道。在软件方面PCIE总线完全兼容PCI总线,驱动程序可直接一直到PCIE系统中。
目前PCIE 总线凭着传输速率快、质量高等特点,逐渐取代PCI 总线占据高速数据总线的主导地位,在数据采集系统传输中发挥了极大的作用。
PCIE 总线层次结构如图5所示,从图中可以看到数据在PCIE总线接口传输过程。
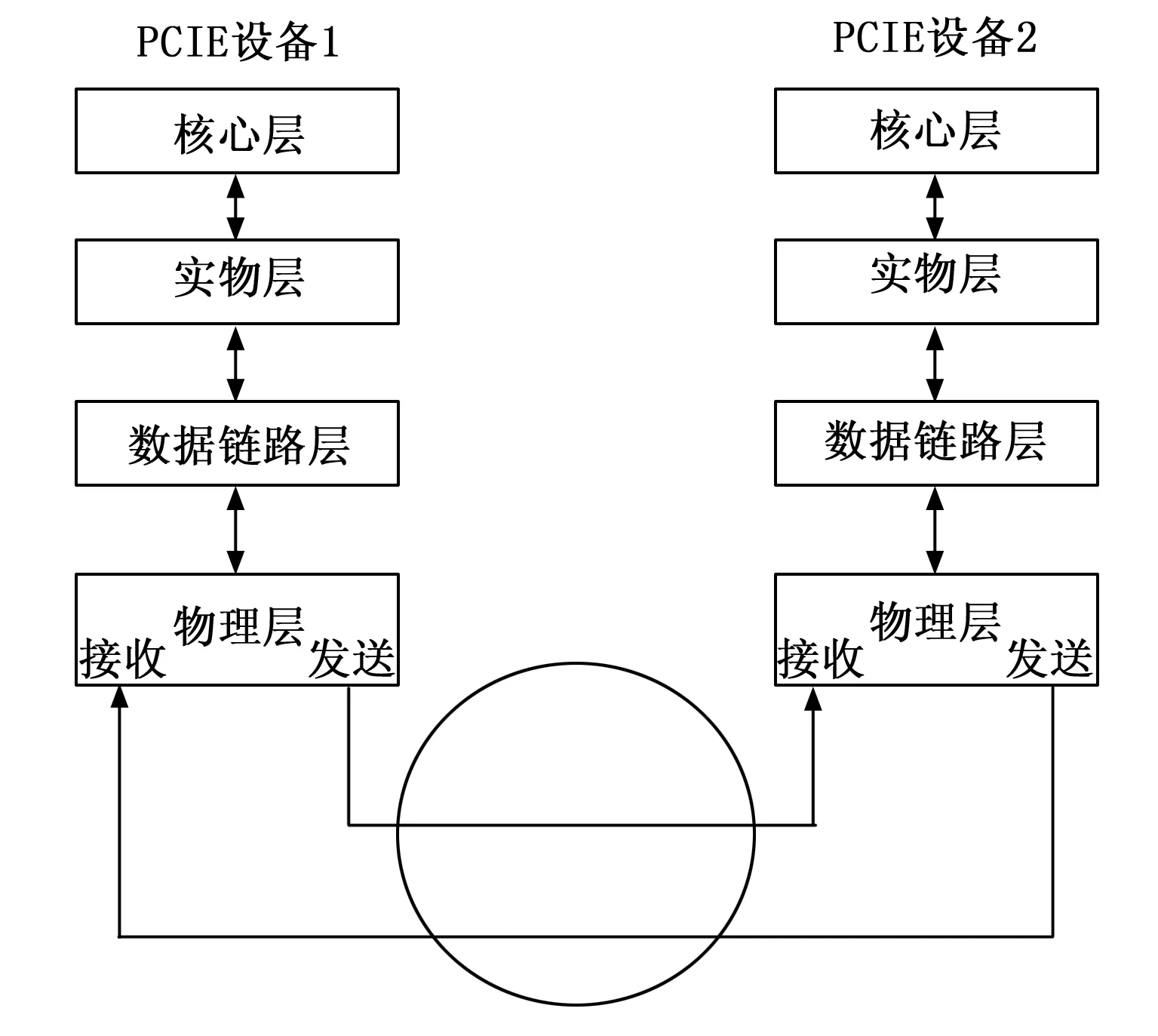
图5 PCIE总线的层次结构图
FPGA代码设计过程中,常用的代码设计技巧包括以下几种:乒乓操作、串行信号并行化设计、流水线操作设计。合理的使用上述技巧可以提高代码的可行性,节省FPGA资源,保证系统的鲁棒性,此外还可以提高代码的执行效率以及稳定定。
乒乓操作是一种用来对高速数据流进行处理的设计思想,它的基本思想就是一种以面积换取速度,从某种层面来看,乒乓操作可以看成一种比较特殊的串并转换方式。乒乓操作实现的关键部分在于要保证不同通路间的数据处理是互斥的,使得输入的数据流能够按照一定的节拍,相互配合进行切换,从而实现数据的无缝缓冲和处理[15]。
本系统中FPGA通过GTX端口与TX2的PCIE接口进行连接,GTX单个端口速率最高可达12.5 Gbps[16]。PCIE模块采用Xilinx的IP核来实现PCIE物理层和传输层等相关的PCIE协议。根据协议,PCIE的节点分为Leagcy、Endpoint以及Root complex。根据设计,在FPGA中实现的应该为Endpoint类型,所以设置IP核工作在Endpoint模式[2]。上电后TX2要完成对EP端的遍历和配置,根据协议规范,在EP模式下,配置空间为type0模式,新的PCIE规定配置空间的大小为4 KB,前256字节保持与以往PCIE协议兼容。
上电后TX2完成对作为EP端的FPGA PCIE外设的内存映射,为该节点分配相应大小的内存。配置IP核的所需空间为128 MB,该信息被记录在BAR0寄存器中,上电后TX2遍历找到该EP后读取该EP内的BAR0寄存器,译码后获得所需的内存的128 MB,然后TX2为其分配相应的存储空间。设计中分配对应的起始地址开始的128个连续地址为控制寄存器区,TX2通过向该地址区域写入数据来配置寄存器的值,更改相关的工作模式。数据传输时采用DMA传输机制配合乒乓操作进行图像数据传输,首先在PCIE空间开辟两块内存,分别是内存块1和内存块2,当第一帧图像传输时,TX2配置对应地址寄存器,告知FPGA本次所需传输数据的大小以及要写入的内存块1起始地址后,FPGA自动进行数据打包和传输;当第二帧图像传输时,TX2配置对应地址寄存器,告知FPGA本次所需传输数据的大小以及要写入的内存块2起始地址后,FPGA自动进行数据打包和传输。将传输完成后进入等待模式。
3)SPI模块:设备预留有SPI接口,通过该接口对外设进行控制,SPI接口的时序如图6所示。

图6 SPI时序图
SPI接口的码速率为1 Mbps,时钟上升沿对准数据中间,数据高位在前低位在后,数据长度为16 bit。
4)LVDS模块:LVDS是一种低摆幅的差分信号技术,采用一对差分线实现高速信号传输,使信号能在差分PCB线对或平衡电缆上以几百MB/s的速率传输[17]。设计中采用了低至400 mV的电压摆幅和大约3.5 mA的低电流驱动输出,加之差分对线的共模抑制功能,LVDS具有低噪声和低功耗的优点[18]。
LVDS数据发送和接收均采用三线制同步接口,包括三种信号:门控、时钟和数据,时钟频率可设置,且时钟连续不间断。发送端门控和数据信号的边沿均与时钟信号的上升沿对齐,接收方在时钟的下降沿读取数据。时序图和时间关系如图7所示,时钟上升沿与数据之间的延时为4 ns。接口特点为:
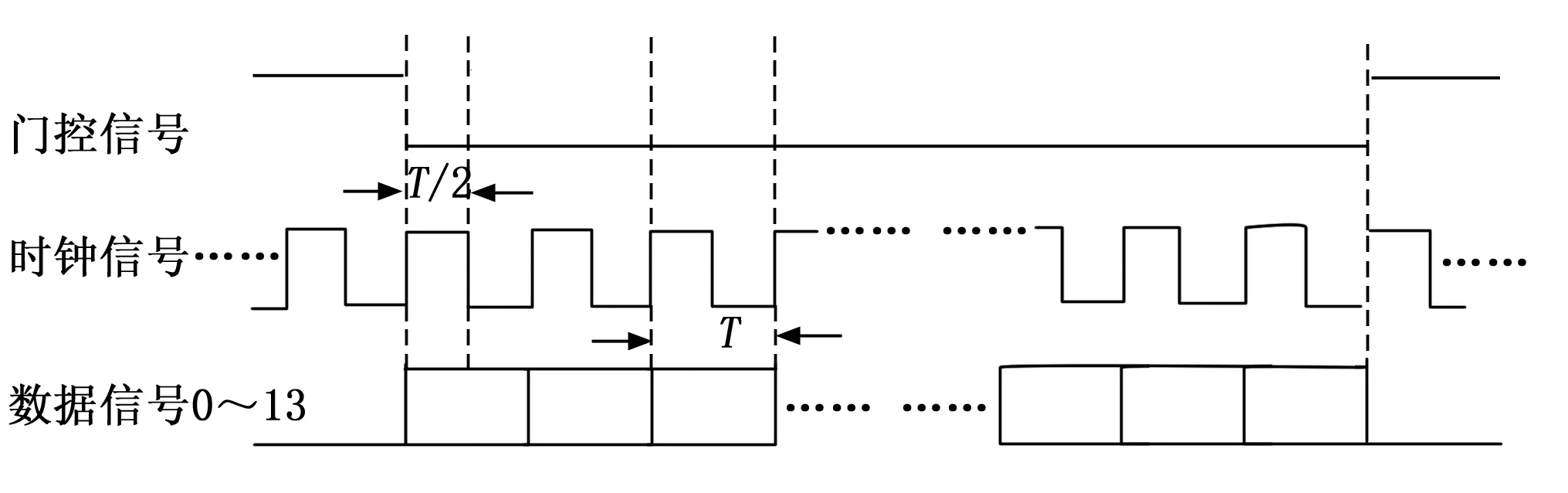
图7 LVDS时序图
1)门控信号低电平有效,一个有效门控内的数据定义为一帧;
2)门控信号下降沿到来时开始传送数据;高位先输出、低位后输出;
3)时钟占空比:45%~55%。
3.1.2 TX2驱动程序设计
TX2自带的Linux系统中已经编写了SPI驱动和UART驱动,因此只需对PCIE驱动程序进行设计。
PCIE驱动程序需要对PCIE 配置空间进行读写操作。驱动程序通过PCIE的配置空间与硬件进行通信,通信的过程中一般需要读取设备ID、厂商ID以及PCI 类设备三个寄存器,完成匹配后再对基地址寄存器0(BAR0)进行操作。PCIE 配置空间可以将PCI 配置空间完全兼容,PCI配置空间如图8所示[19],包含由16个双字组成的PCI 头标区,和由18个双字组成的PCI 设备寄存器。PCIE空间在PCI空间的基础上增加了960双字的配置空间,并在PCI的基础上增加了PCIE 的高级错误报告、虚通道、电源预算以及设备序列号等功能[20]。
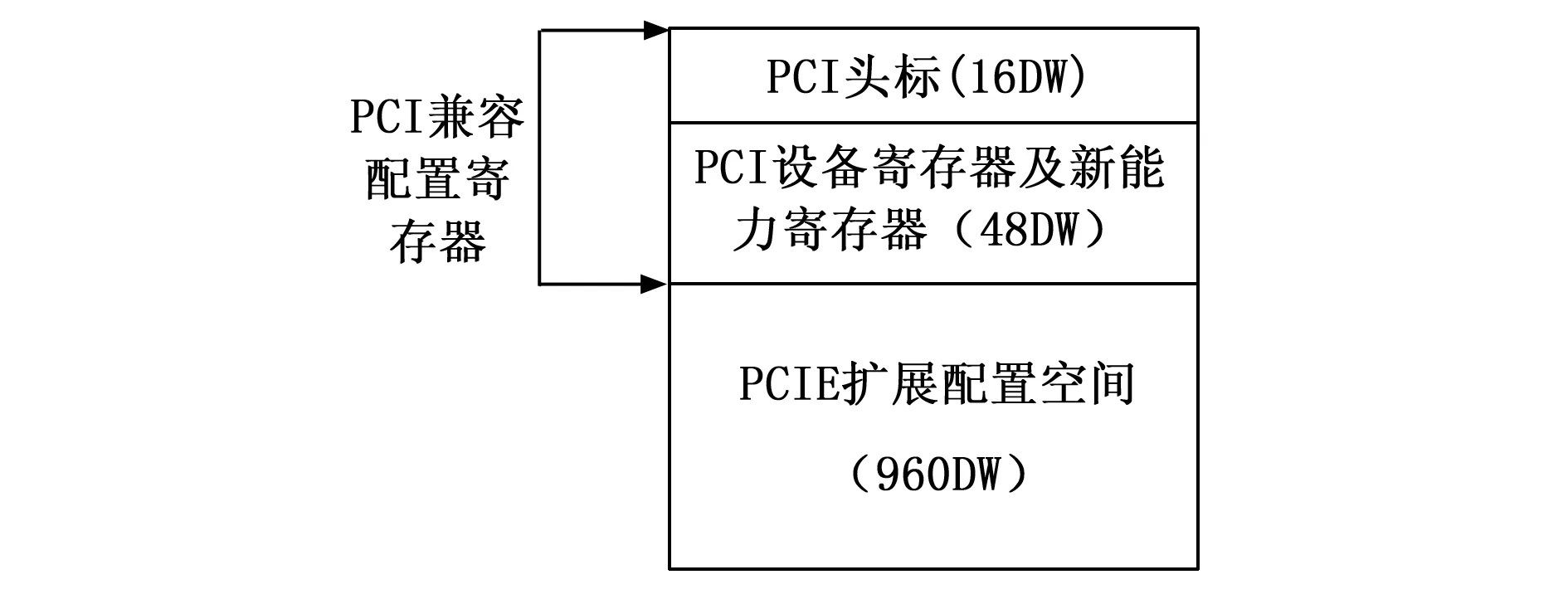
图8 PCIE配置空间示意图
系统中TX2操作系统使用Linux 操作系统,首先在内存中开辟两块DMA 缓冲区用来完成底层硬件内存与TX2应用程序之间数据的传输,DMA缓冲区在PCIE底层硬件TX2应用程序之间相当于桥梁。FPGA将数据发送到TX2的PCIE接口,PCIE驱动程序将数据存放到DMA缓冲区,通过MSI(message signaled interrupt)中断机制通知TX2应用程序对数据进行操作。PCIE驱动程序的总体流程如图9所示,系统硬件启动后,TX2在加载驱动程序时,首先会在驱动程序入口对PCIE硬件检测,检测到PCIE设备后,对驱动程序进行初始化,主要包括以下步骤:使能PCIE设备、使能PCIE总线主设备、读取EP设备号、申请IO内存区域、虚拟内存映射、使能MSI中断、申请DMA 缓冲区以及注册字符设备等[4]。在上述步骤完成后,还需要对中断进行处理,以及在IO操作中实现对DMA缓冲区的读写。完成数据传输后,需要应在卸载驱动前将申请的内存空间进行释放。
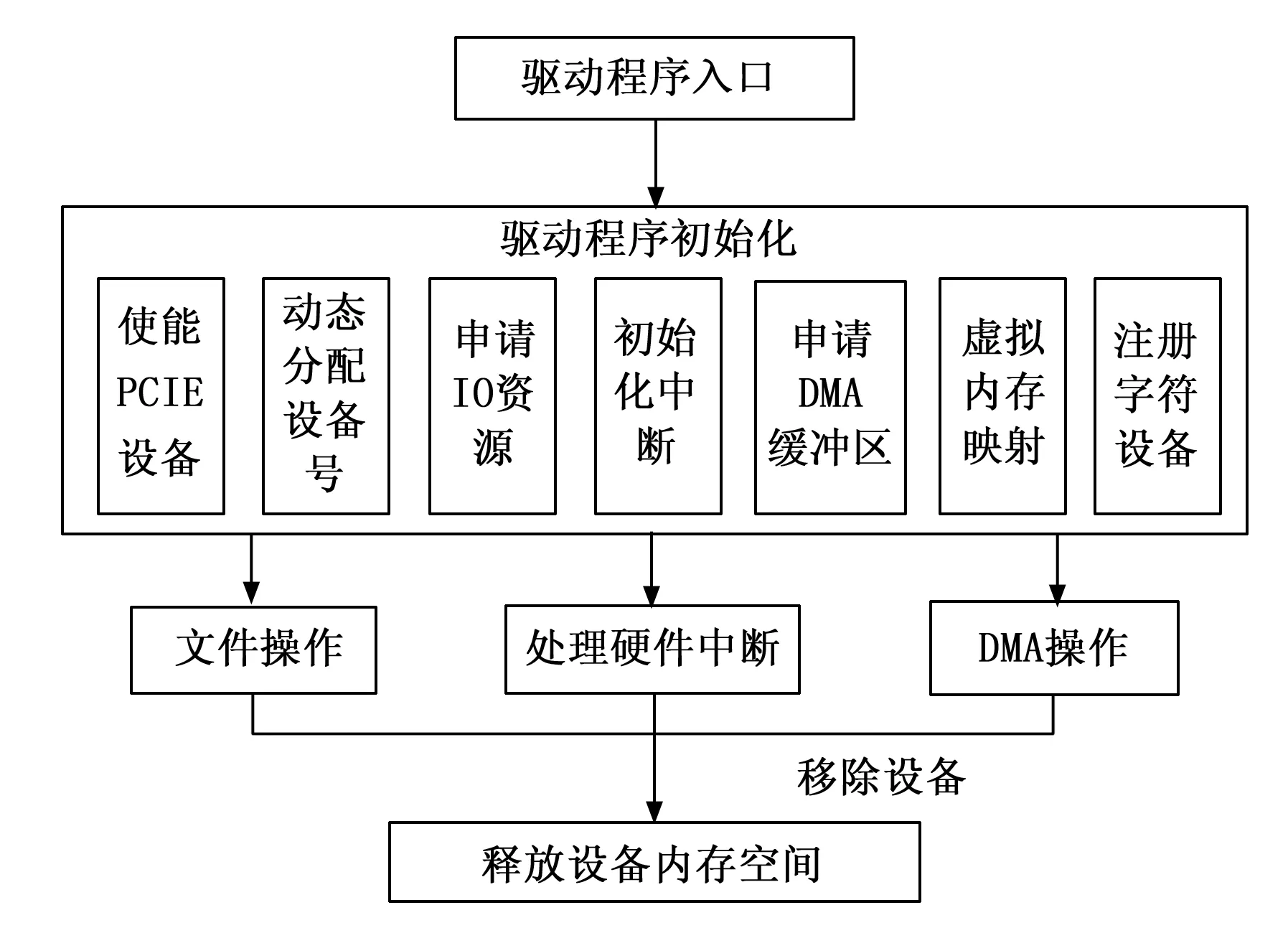
图9 PCIE驱动程序流程图
PCIE驱动程序的具体操作流程如下:
1)打开以及关闭PCI设备。驱动程序中首先要做的是使能PCI设备,只有完成该步骤后,驱动程序才能够访问设备IO内存和中断。调用pci_enable_device()函数,该函数会将PCI配置空间中命令区域中最低两位置为1。当PCIE驱动程序完成任务后,会调用关闭PCI设备函数pci_disable_device()。该函数会将PCI配置空间中命令区域中最低两位置为0。
2)申请PCIE IO资源和内存资源,并在程序使用完成后进行资源释放。
首先获取IO资源的基地址以及长度。
sc -> bar0_addr = pci_resource_start(pdev, 0); //获取PCIE BAR0空间基地址
sc -> bar0_len = pci_resource_len(pdev, 0); //获取PCIE BAR0内存大小
将驱动程序中申请的IO资源通过ioremap函数将IO资源映射到虚拟地址。
error = pci_request_regions(pdev, sc -> name); //申请IO内存区域
sc->bar0 = ioremap(sc ->bar0_addr, sc -> bar0_len); //将BAR0空间的IO内存映射为内核可用的虚拟内存
pci_release_regions(pdev); //程序最后释放IO 资源
iounmap(sc->bar0); //取消IO 资源映射
3)将TX2端设置为总线主设备模式。将PCI命令寄存器中的总线主设备位设置为1,在该模式下,设备可实时获得总线占有权,处于DMA模式下。
pci_set_master(pdev); //设置PCIE总线主设备模式
4)使能、请求MSI中断以及禁止、释放MSI中断[7]。PCIE中通MSI包进行中断响应。调用pci_enable_msi(dev)函数使能中断。然后调用request_irq(dev -> irq,intrpt_handler,IRQF_SHARED,sc -> name,sc)函数绑定中断响应函数。
当驱动程序释放时关闭MSI中断,并将中断释放。
pci_disable_msi(pdev); //关闭MSI 中断
free_irq(pdev ->irq, NULL); //释放中断
5)申请与释放DMA 缓冲区[6]。调用Linux系统中的内核函数pci_alloc_consistent申请DMA缓冲区,通过这种方式获得的DMA缓冲区可以保证数据的一致性。主设备申请DMA缓冲区后,主设备和从设备均可以访问DMA缓冲区。
nzy_read_vir = pci_alloc_consistent(pdev, BUF_SIZE, &(nzy_read_phy)); //分配DMA缓冲区
pci_free_consistent(pdev, BUF_SIZE, sc -> dma_read_vir, sc -> dma_read_phy); //释放DMA缓冲区
6)文件操作:完成上述PCIE驱动相关工作后,通过file_operation结构体设置字符设备驱动程序设计的主体内容,包括open()、write()、read()、close()等函数。open()函数用于打开字符设备;write()/read()函数实现对字符设备读/写操作;ioctl()控制字符设备函数,对DMA寄存器读写操作;release()函数用于关闭设备。
static const struct file_operations fpga_fops = {
.owner = THIS_MODULE,
.unlocked_ioctl = fpga_ioctl,
.fasync = fpga_fasync, //向应用提供驱动异步通知响应
.mmap = my_mmap //将物理地址映射到应用空间虚拟地址
};
7)DMA操作:本系统中传输的图像数据量大、传输速度快,为了实现数据的完整性,采用DMA的方式对图像数据进行传输。DMA 传输的过程中,处理器可以进行其他操作,提高了系统的性能。此外DMA是直接内存读写操作,相比于处理器读写速度更快。
DMA读操作流程如图10所示。DMA传输时需要将DMA块的起始地址、要传输的数据块长度以及数据传输启动指令发送给FPGA端。FPGA收到启动指令后,将相机数据存放到DMA缓冲区内,当传输完成后,FPGA发送MSI中断信息,TX2收到中断信号后进去到驱动中的中断函数,中断函数中SIGIO信号触发应用程序中断,进而应用程序对数据进行存储。
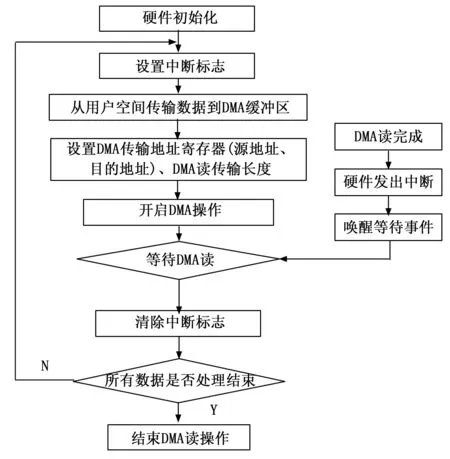
图10 DMA操作流程图
部分代码如下:
write_reg(fpgas[io.id], DMA_READ_LOW, ((fpgas[io.id] -> dma_read_phy) + BUF_SIZE/2)); //将地址写入DMA写的低32位地址
write_reg(fpgas[io.id], DMA_READ_HIGH, 0); //DMA写的高32位不使用
write_reg(fpgas[io.id], DMA_READ_SIZE, io.len); //DMA要写的大小写到寄存器中
write_reg(fpgas[io.id], DMA_READ_ENABLE, 1);
static irqreturn_t intrpt_handler(int irq, void *dev_id) //中断处理函数
{
kill_fasync(&dma_async, SIGIO, POLL_IN); //read mem data
return IRQ_HANDLED;
}
8)处理硬件中断:在中断函数中,通过kill_fasync函数将中断信号发送给应用程序。
kill_fasync(&dma_async, SIGIO, POLL_IN);
3.1.3 TX2应用程序设计
1)主程序:主程序中通过open()、read()、write()等函数接口去调用内核空间的相应驱动函数对设备进行操作。设计中要求使用PCIE进行大数据传输,在应用程序中需要指定要读写的数据量RW_TIME。以接收为例,首先打开要写入的文件,判断当前写次数的奇数次还是偶数次,分别不同的内存块中将数据写入文件。应用程序部分代码如下:
FILE* fp = fopen(tSaveFileInfo.LocalFile, "a+"); //打开存盘数据文件
fpga = (fpga_t *)malloc(sizeof(fpga_t)); //分配内存
fpga->fd = open("/dev/"DEVICE_NAME, O_RDWR | O_SYNC); //打开设备文件
ioctl(fpga -> fd, IOCTL_FILL_COPY, 0xBB); //启动DMA数据传输
fseek(fp, 0, SEEK_END);close(fd); //关闭设备
fclose(fp);//关闭存盘文件
在本系统中,应用程序与驱动程序之间的通信主要包括以下几个方面:
(1)在应用程序中使用open()函数打开设备文件,对应到底层驱动是打开PCIE设备。
(2)通过ioctl()函数调用驱动层的ioctl()函数实现与PCIE的数据读写。
(3)通过close()函数关闭设备文件。
2)中断程序:在应用程序中,使用Signal函数将驱动层中断信号传输到应用层。
signal(SIGIO, vSigHandleFunc);
在中断处理函数中首先判断当前接收中断的次数,如果是奇数次则从DMA缓存的上半区读取数据,如果是偶数次则从DMA缓存的下班去读取数据。并将读取到的数据写入到文件中
ioctl(fpga -> fd, IOCTL_FILL_COPY, 0xBB); //从DMA缓存的上半区读取数据
fseek(fp, 0, SEEK_END);
fwrite(pRead, 1, VIR_ADDR_SIZE/2, fp);
4 实验结果与分析
测试环境及条件:
1)烧写固化FPGA程序;
2)TX2预先安装好Ubuntu操作系统;
3)将系统通过LVDS接口连接相机,相机帧频100 Hz,像素数为640×512,单像素数采样为14位将系统SATA接口连接固态硬盘;
测试步骤及测试项目:
1)给板卡上电后,电源指示灯点亮,运行sudo insmod *.ko 加载PCIE驱动,驱动正常加载后终端输出如图11所示,并加载PCIE驱动程序;
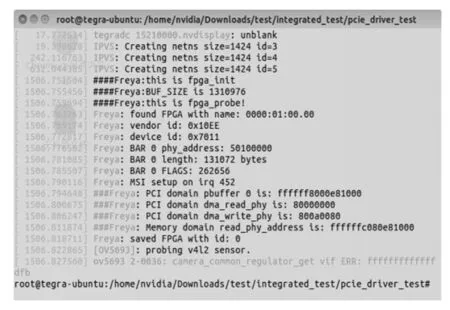
图11 驱动加载
2)运行TX2端应用程序;
3)打开相机,系统接收相机数据并将数据存储到固态硬盘中;
4)读取固态硬盘中存储的相机数据并对图像帧计数进行判断有无丢失数据情况。
通过测试发现,当相机以437.5 Mbps的速率传输数据时,系统可以完整接收相机数据,数据完整无丢失情况,
5 结束语
本项目采用了新型的处理架构进行图像采集存储,并开展了相应的软硬件设计。该系统采用FPGA+GPU的形式,采用PCIE总线实现FPGA与GPU之间的高速通信,实现了高速数据传输。系统体积小,可应用多种平台。为后续的图像智能处理提供了硬件以及底层基础。
猜你喜欢
高技术通讯(2021年5期)2021-07-16
当代陕西(2019年13期)2019-08-20
电子制作(2018年17期)2018-09-28
时代英语·高二(2017年4期)2017-08-11
解放军健康(2017年5期)2017-08-01
电子设计工程(2014年19期)2014-02-27
测绘科学与工程(2014年5期)2014-02-27
赤峰学院学报·自然科学版(2012年19期)2012-10-14
微处理机(2012年4期)2012-06-13
电脑爱好者(2009年13期)2009-07-07
