
基于频谱增强的软件多故障定位
2023-08-30 06:59周世健邬凯胜
计算机测量与控制 2023年8期
陈 琪,周世健,樊 鑫,2,邬凯胜,2,肖 鹏,2
(1.南昌航空大学 软件学院,南昌 330038;2.南昌航空大学 软件测评中心,南昌 330038)
0 引言
软件正成为低成本实现各种系统中复杂功能的首选技术,日常生活的许多方面都依赖于软件的正确操作,因此保证软件的质量和及时的维护在每个开发过程中都起着至关重要的作用。测试指的是检查软件的正确性和它是否符合给定的规范的实践状态。虽然测试用例自动生成工具愈渐成熟,仍然存在部分由开发人员手工制作的测试用例,在暴露错误行为方面测试是有效的,但识别失败背后的根本原因仍然主要是一种手动活动,需要大量的时间和成本。
各种故障定位方法用来帮助开发人员定位故障的根本原因,例如,基于频谱的故障定位[1-6],基于切片的故障定位[7-8],基于机器学习的故障定位[9-10],和基于突变的故障定位[11-14]。其中,基于频谱的故障定位技术是研究最广泛的故障定位技术之一。尽管SBFL是一种特别轻量级的方法,但与其他方法相比,它已被证明具有竞争力,且具备与语言无关、易于使用,并且在测试执行时间相对开销较低的特性。
理想的故障定位技术总是将故障程序实体排在前列。然而在实践中,尽管已经提出了各种SBFL技术,如Jaccard/Ochiai[2],Op2[4]和Tarantula[1],没有一种技术可以总是表现最好的,开发人员通常必须在找到真正的错误之前检查各种非故障实体(即程序频谱中的一个维度)。利用失败和成功的测试用例提供的证据,根据被测实体参与错误行为的怀疑程度进行分析和排序。直观地说,一个实体在测试用例失败时使用得越多,它就越可疑,即它就越有可能与这种不正确性的原因有关。类似地,成功的测试用例所使用的实体越多,它就越被认为不可疑。
现有的SBFL技术的一个局限性是,它们不能完全捕获每个已执行的测试用例的结果与所涉及的程序单元之间的本地关系。例如,SBFL技术,如Dstar[15],会假设两个失败的测试用例对在两个测试用例中执行的一个程序单元的怀疑性贡献相同,而不管在测试用例中涉及的程序实体的数量不同。在实践中,一个失败的测试用例可能比其他用例更有价值,因为它只涉及几个程序实体。其次,在许多现有的SBFL技术中,存在一个被忽略的事实,即程序实体可能以不同的方式协作贡献每个测试用例的结果。
我们的关键见解是,存在一种更丰富的频谱增强形式,考虑了如何增强失败的测试用例中的频谱分析,可以提供更有效的故障定位。详细来说,存在两个测试和,它们都是失败的测试,其中覆盖了100个程序实体,而只覆盖了10个程序。根据我们的直觉,在故障定位方面比较有帮助,因为有一个更小的搜索空间来定位故障(s)。由于每一个执行失败的测试用例都必然执行了错误语句,即错误语句必然被覆盖,那么[16]已经证实了在单故障情况下,将所有执行失败的测试用例的覆盖情况取交集,则会缩小故障语句的覆盖范围,从而提高查找效率。经过频谱增强后的测试用例作为新的增强版测试用例来对程序进行验证。传统的SBFL技术忽略了这些有用的信息,并认为和在SBFL上做出了相同的贡献,例如,和执行的程序实体将被作为相同的处理,而不管测试所覆盖的实体数量。
为了克服现有的SBFL技术的局限性,我们通过明确地考虑失败测试用例的贡献,更有效地增强了现有的程序频谱。基于以上见解,我们提出了基于频谱增强的软件多故障定位方法(SBFL(E),spectrum-based fault localization(enhanced)),充分利用了执行失败测试用例的程序语句覆盖情况,缩减了运行时的执行失败测试用例数量,对基于频谱的故障定位方法进行改良,并将单故障扩展到多故障实验,极大提高了软件故障定位的效率和有效性。
1 软件故障定位
1.1 基于频谱的故障定位
SBFL使用程序频谱和测试结果来定位软件故障。程序频谱是测试用例的覆盖信息和执行结果的集合。一个程序的频谱,通常以一个矩阵的形式出现,它描述了该程序的动态行为。测试结果将记录测试用例是否失败或通过。通过较多失败测试用例的实体,通过较少成功测试用例的实体就越可疑[17-18]。相反,实体通过越少的失败测试用例,通过越多成功的测试用例,实体的可疑度值就越低。程序谱中所涉及的实体类型可以是语句、分支、函数、谓词等,本文以语句作为实体。
SBFL的主要思想是与故障相关的执行信息更有可能是导致程序失效的原因,这些信息往往包含在失败的测试用例,而更少发生在成功的测试用例当中。如图1所示,SBFL分析了实体与测试用例通过或失败之间的动态相关性,这个相关性近似于一个实体导致程序失效的可能性。频谱信息矩阵由M个测试用例和每个测试用例中的N条语句构成,最后得到测试结果向量R。对于一个语句X_MN,其值是二进制的(0/1),“1”表示相应的语句被测试用例执行,“0”表示相应的语句没有被测试用例执行。在结果向量R中,其值也是二进制的,“0”表示测试用例的结果为通过,“1”表示测试用例的结果为失败。
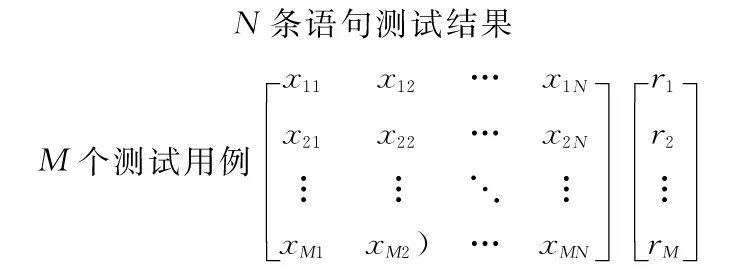
图1 SBFL覆盖信息矩阵图
程序执行信息从图1中提取,表示为四元组(Nef,Nep,Nnf,Nnp),其中Nef代表语句被执行的失败测试用例数,Nep代表语句被执行的通过测试用例数,Nnf代表语句未被执行的失败测试用例数,Nnp代表语句未被执行的通过测试用例数。根据以上4个参数,程序中各单元元素的可疑值可以通过表1中的可疑值计算公式来计算,这里只列出了部分但常用的公式。如果一个语句的Nef值相对较高,而Nep值较低,则该语句的可疑分值较高。

表1 SBFL可疑度值计算公式
1.2 单故障与多故障定位
单故障程序指的是在程序中只存在唯一确定的一处故障,导致整个程序的失效;多故障程序则指错误数目不定,存在两处或两处以上的故障影响导致程序失效。尽管各种故障定位技术已经被提出,但它们在多故障程序中的应用仍然有限。多故障定位(MFL,multiple fault localization)是指在一个有故障的软件程序中识别多重故障(一个以上的故障)的定位行为。与单故障定位(SFL,single fault localization)假设软件系统中只包含一个故障的传统做法相比,这种方法更加复杂、繁琐,而且成本高。工作流程对比如图2所示。

图2 单故障与多故障定位
单故障程序中所有失败的测试用例均指向相同的故障,因此测试用例的数量与质量则显得尤为关键,成为优化故障定位方式的突破口。在多故障环境下,除了受到测试用例的影响,更令人棘手的是故障干扰的问题。
这些相互作用可能表现为导致测试用例失败,而通常情况下,由于任何单一故障的存在都不会失败。另外,一个测试通常由于一个故障而失败的测试用例,在增加了另一个故障后,该测试用例可能不再失败,因为它干扰了第一个故障的导致程序失效的作用。当然也存在多个故障于同一个程序中,但不会以通过检查测试用例可以观察到故障的方式相互干扰。在这种情况下。程序中每个故障的影响似乎是独立于其他故障。本文则对故障干扰不做出假设,专注于提升测试用例尤其是失败的测试用例,使用传统的定位技术同时定位多个故障是困难的,因为它们依赖于失败的测试执行来识别错误的语句。
综合来看,单故障与多故障定位的差异除了存在于需要定位的故障数目的不同,也不免对测试用例的统计处理以及失败测试用例的质量造成消极影响。当故障之间的干扰导致程序包含多个故障时,现有故障定位技术的有效性会降低。程序中的故障越多,开发人员就定位故障的复杂性就越高,从而大大增加故障定位的难度与开销成本。
2 动机实例
SBFL是基于程序执行的统计数据设计的,其中包括测试覆盖率和测试结果。执行统计数据可以被视为SBFL分析的信息源,其中决定了SBFL的准确性的关键在于测试用例的性质。冗余的测试用例大大增加了开发人员的时间成本与故障定位的精确性,一个含故障程序实例如表2所示。
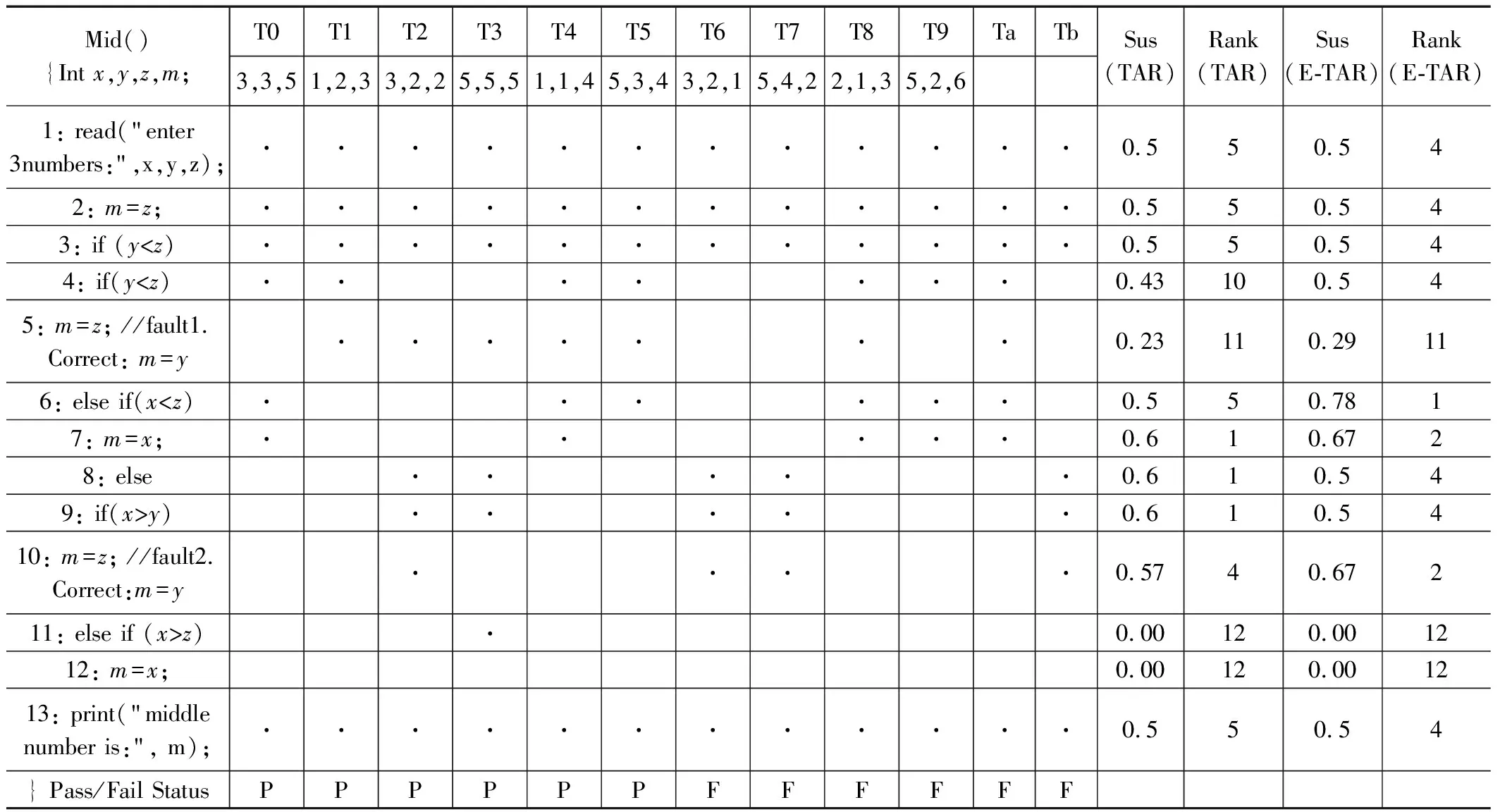
表2 多故障实例
在现有的研究方法中,我们考虑了一个有缺陷的程序来评估我们技术的效率。Zakari等人[19]用一个例子来解释3种方法:一次调试方法、并行调试方法和多次调试方法。在本文中,我们采用了同样的例子程序来展示我们的方法的工作过程。余晓菲等人[16]已经证实了频谱增强在单故障程序中的有效性,因此表2实例仅对多故障程序进行详细分析。在表2中,我们显示了示例程序。原始的程序测试套件T由10个测试用例(T0,T1,T2,T3,T4,T5,T6,T7,T8,T9)和13条程序语句组成,其中语句5和语句10都是错误的。标有“●”的语句执行标志着该语句在该测试运行中被测试用例执行,否则为空。测试用例(T6,T7,T8,T9)是失败的测试用例,而(T0,T1,T2,T3,T4,T5)是通过的测试用例。在这个例子中,每个语句的可疑性是用Tarantula系数计算的,这是SBFL中常用的故障定位技术之一。
对于单次故障的调试很简单,根据语句的可疑度得分,开发人员通过使用Tarantula,检查4条语句就能清楚地识别出有故障的语句10(可疑度值为0.57)。然而,在多故障情况下,在语句10中发现的故障必须被修复,并且程序必须被重新测试以发现第二个故障语句5(可疑度值为0.23)。在多故障调试过程中,开发人员在找到语句10中的第一个故障后不会停止,而是继续搜索下一个故障,直到找到所有故障或预先指定的搜索上限。设置上限的方法(即开发人
员在进入下一个迭代之前可以搜索可疑语句排名列表的70%或60%)已被现有研究采用[20-21]。在我们的研究中,我们没有设置搜索上限,而是在找到所有故障之前停止搜索。
采取多故障场景下频谱增强的方法,实例为双故障程序,覆盖第一个故障语句5的失败测试用例仅为T8,因此频谱增强后的测试用例Ta保留T8的覆盖信息并剔除原有T8。失败测试用例T6和T7覆盖了第二个故障语句10,且覆盖信息高度重合,对二者进行测试用例精简,采取逻辑与运算得到测试用例Tb,并将T6和T7从测试用例集中去除。频谱增强后可用测试用例为T0~T5以及T9~Tb,再进行SBFL可疑度值计算。
表2清楚地显示,Tarantula计算的错误语句的等级为4和11。在采用频谱增强的方法进行优化后,我们的技术分别给有问题的语句分配了等级2和等级11。这表明,我们的研究方法比其他现有的方法更有效地优化了可疑性分数,并且能够定位那些使程序失效的语句。
3 基于频谱增强的软件故障定位
对基于频谱的故障定位方法而言,故障定位的效果和效率都高度依赖于测试用例,所以测试用例的选取以及使用测试用例的多少都对实验有至关重要的影响。针对测试用例的研究,本文引入频谱增强方法,充分利用了执行失败测试用例的程序语句覆盖信息,精简了运行时的执行失败测试用例数量,从而提升了测试用例的质量以及软件故障定位的效率。
由于语句执行的覆盖信息都为二进制表示方法,因此将所有失败测试用例的覆盖信息做逻辑与运算,则能够精简频谱信息,从而缩小查找故障语句的范围,并且通过频谱增强后的测试用例一定会覆盖存在故障的语句。我们将与运算操作取得的覆盖信息这个操作称为频谱增强。再使用增强过的频谱信息进行SBFL可疑度值计算,最后根据优化后的可疑度排名列表进行更高效的故障定位。整体流程如图3所示。
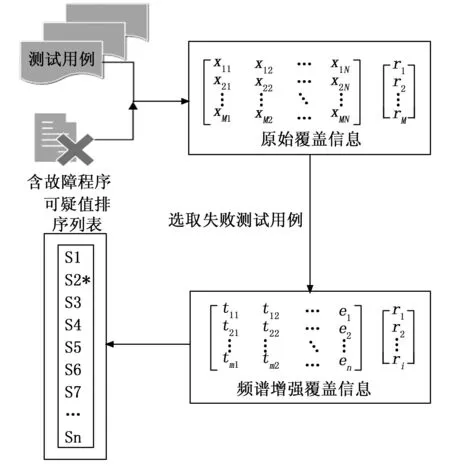
图3 SBFL(E)流程图
单故障场景下,频谱增强后得到唯一的失败测试用例。程序运行时,唯一的故障语句必然被所有失败测试用例所覆盖,否则测试用例通过,运行结果正确,程序成功执行。而多故障场景中,并不是所有的故障语句都被每一个失败测试用例所覆盖,我们采取根据多故障数量k进行频谱增强的方式,最后得到k个频谱增强后的失败测试用例。
将失败测试用例集设为T,T={T1,T2,…,Ti,…,Tm},其中Ti为第i个失败测试用例的执行情况,具体失败测试用例的覆盖信息设为集合t,t={ti1,ti2,…,tij,…,tin},其中i为执行失败测试用例编号,j为语句行号,n为总语句数,ti为第i个执行失败测试用例的执行情况,tij为第i个执行失败测试用例的第j条语句的覆盖情况,覆盖情况取值为0或1,0为未被覆盖语句,1为被覆盖语句b。频谱增强E={e1,e2,…,el,…,en},其中:
(1)
以表2中多故障程序Mid为例,执行失败测试用例数为4,语句总数为13,故障,有4个失败执行覆盖t6,t7,t8和t9,其中以t6为例,t6={1,1,1,0,0,0,0,1,1,1,0,0,1}。利用频谱增强的定义,通过频谱增强方法可以得到该例子中E1={e1,e2,…,el,…,en}。
4 实验结果与分析
为验证本文方法的有效性,实验比较了SBFL(未经过频谱增强)和SBFL(E)(经过频谱增强)的故障定位性能。实验运行环境为Windows10和Ubuntu系统,2.60 GHz Intel(R)i5四核处理器,16 GB 物理内存。
4.1 实验数据集
我们采取基准程序进行了5个案例研究,其中3个程序是西门子(Siemens)程序套件的一部分,其余两个程序来自Defects4j,数据集的详细信息在表3中列出。基于人工故障的西门子程序选取了Tcas,Totinfo和Printtokens2;基于真实故障的Defects4j程序选取了Apache Common Lang和JFree Chart。这些C语言(Siemens)和JAVA(Defects4j)程序被广泛用于软件测试和故障定位的实验中,也用于我们之前的研究工作当中。
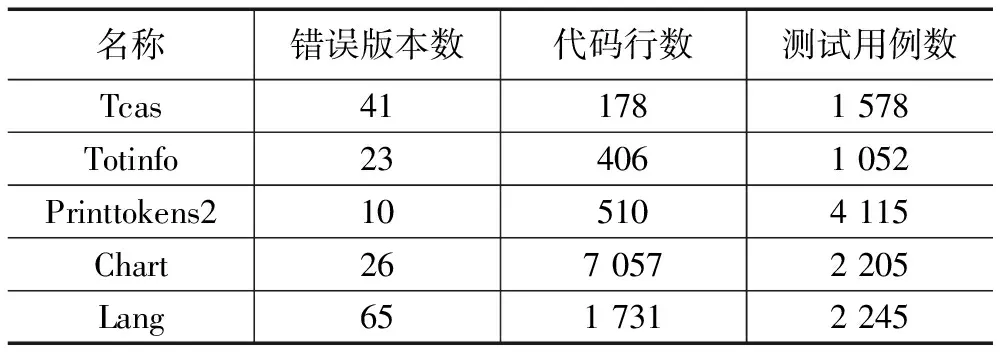
表3 数据集
所有基准程序的单故障版本可以分别从SIR(software-artifact infrastructure repository)和Defects4j资源库下载。在多故障版本中,故障是手动播种到原始程序中的。由于大多数程序都是单故障,我们将单故障版本结合起来,建立多故障版本。Rui[22]和Zakari[19]也创建了包含2、3、4和5个故障的多故障版本,以产生Siemens-M案例研究。
4.2 评价指标
在本文中,我们采用EXAM和Top-N用于评估我们提出的SBFL(E)方法的性能的指标,并将其与其他故障定位技术的有效性进行比较。
根据Wong等人提出的评价标准[23],我们的研究采用EXAM作为评价指标,其定义为发现程序中所有故障时需要检查的代码行数占程序总代码行数的百分比。具体公式为:
(2)
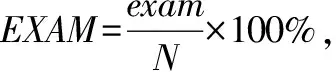
Top-N用于评估故障元素的绝对排名,它通过检查排名列表的前n个位置来计算成功定位的故障总数。N越小,故障定位技术就越有效。值得注意的是,程序员在实践中会更多地关注最可疑的元素,他们不是一个一个地检查排名列表中的语句,而是在排名列表中的不同位置之间表现出某种形式的跳跃,直到关于故障原因的假设得到确认[25]。此外,排名靠前的位置很少被程序员跳过,所以Top-1对于评估故障定位技术的有效性和准确性极为关键。
4.3 结果分析
基于上述提出的方法,本节对实验进行了详细描述和分析。我们建立了一个名为SBFL(E)的故障定位技术,它通过频谱增强来优化SBFL,为了评估我们方法的有效性,我们采用了4个常用的SBFL技术作为基准。
在我们的实验研究中,我们执行了5个基准程序,包括3个西门子套件和两个Defects4j实用程序,每个程序中都包含一个故障。图4显示了Dstar,Jaccard,Ochiai和Tarantula对3个西门子程序(Tcas,Totinfo和Printtokens2)的推广技术的比较;Defects4j数据集中Chart和Lang的整体表现也可以在图5中见证。在每张图中,横轴表示EXAM分数的百分比,而纵轴表示能检测到存在故障版本的百分比。
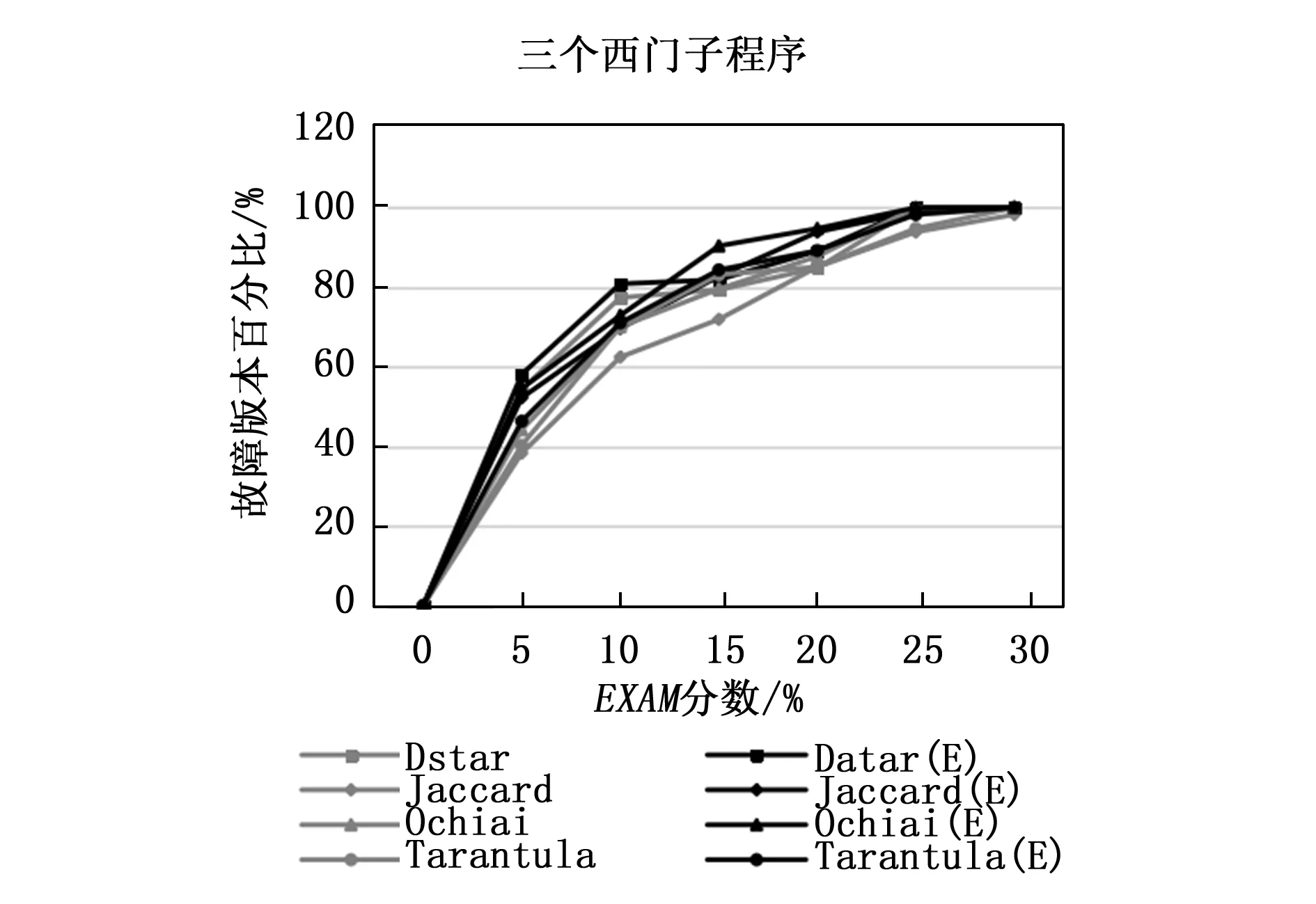
图4 单故障西门子程序EXAM指数
图5 单故障Defects4j程序EXAM指数
从图4和图5的结果分析中,我们发现由频谱增强的技术在寻找单一故障方面比现有的技术表现得更好,尤其是Ochiai(E)方法EXAM在分数为15%~20%时表现突出,它能够定位90%以上的故障版本。Jaccard(E)和Dstar(E)也在图5中的相同范围内保持了类似的趋势,能够定位大约95%的故障版本。
我们在单故障程序中手动添加了一个故障,从而得到双故障程序。我们执行每个有两个故障的基准程序,计算了EXAMF和EXAML值,以评估我们技术的准确性,如图6和7所示。并介绍了4种技术对西门子程序的EXAMF和EXAML的比较。同样,对于Defects4j程序,4种技术的比较见图8和9。从结果分析中,我们可以看到,所提出的技术SBFL(E)在大多数情况下都优于传统SBFL。由于确保频谱增强技术确实在多故障程序中起到了优化作用,我们在每个西门子和Defects4j基准程序中手动添加到3个故障,准备了三故障程序来进行进一步实验研究。图10~12分别给出了4种技术对西门子程序的EXAMF,EXAMM,以及EXAML值的比较。对于Defects4j程序,类似的比较如图9所示。综合来看,我们提出的技术比现有的SBFL技术表现得更好。
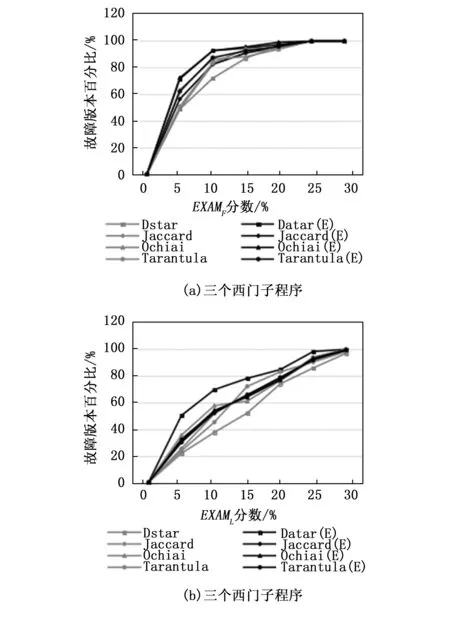
图6 双故障西门子程序EXAMF和EXAML指数
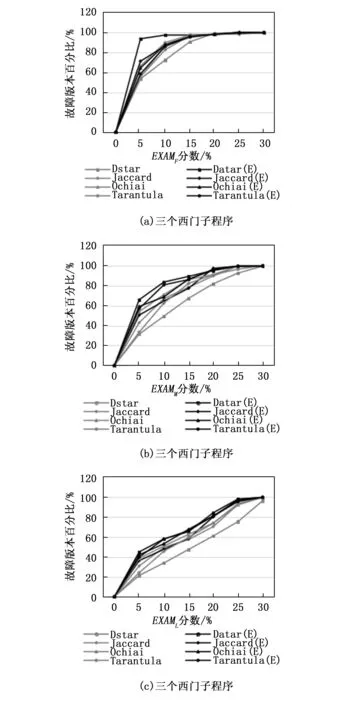
图8 三故障西门子程序EXAMF、EXAMM和EXAML指数
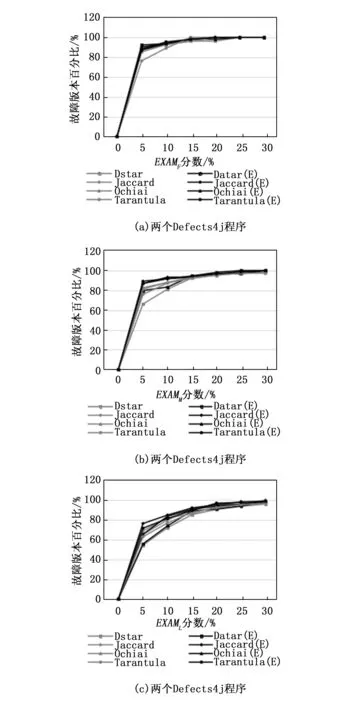
图9 三故障Defects4j程序EXAMF、EXAMM和EXAML指数
为了评估他们对顶级可疑元素的表现,使用了Top-n作为测量指标。95%的审查都是从排序列表中的第1个可疑元素开始的,这意味着首位很少被程序员跳过。因此,如何提高故障定位的准确性,特别是Top-1可疑元素,对故障定位的实用性至关重要。如表4所示,SBFL(E)技术通过检查单故障程序中的Top-1、Top-3和Top-5可疑语句,分别成功定位了数量更多的故障。表4突出了西门子程序的性能,每一种技术都得到了不同程度的改善,其他采用频谱增强技术在Top-1上比传统技术可以多定位到约20%以上的故障,在Top-3和Top-5上都有同比增长。同样,表4也显示了Defects4j中同样的8种技术进行比较,所有的SBFL技术的效率都因为频谱增强所提升。最明显的变化是Dstar(E)在重要的Top-1上,故障定位数量从49增加到61。
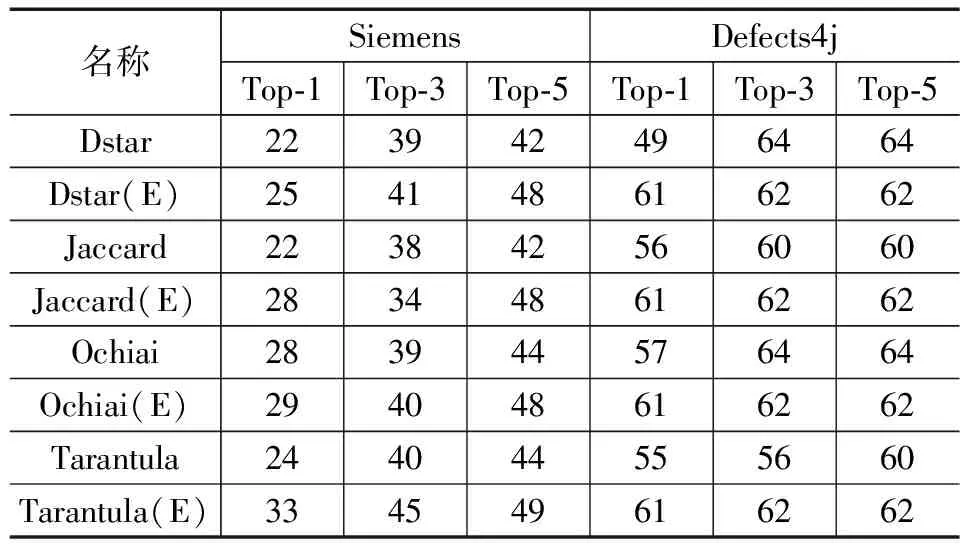
表4 单故障程序中Top-N指数名称
在多故障程序中,Top-N在SBFL和SBFL(E)技术之间展示了不同程度的增长。如表5所示,在双故障的西门子程序中,Dstar(E)通过检查前1、3和5条可疑语句,可以分别定位24、53和66个故障(约占所有故障的20.3%、44.9%和55.9%)。Dstar(E)和Tarantula(E)保持着类似的趋势,且表现比Ochiai(E)好。如表5所示,在3个故障的西门子程序中,Dstar(E)通过检查前1、3和5条可疑语句,分别可以定位36、67和88个故障(约占所有故障的19.6%、36.4%和47.8%)。Jaccard(E),Ochiai(E)和Tarantula(E)的存在相同的趋势,且差异较小。如表5和6所示,在多故障Defects4j程序中的优势更为显著,SBFL(E)在Top-1,Top-3以及Top-5中都保持较好的性能,尽管在少数情况下,与传统的SBFL技术相比,它未能定位更多的故障。
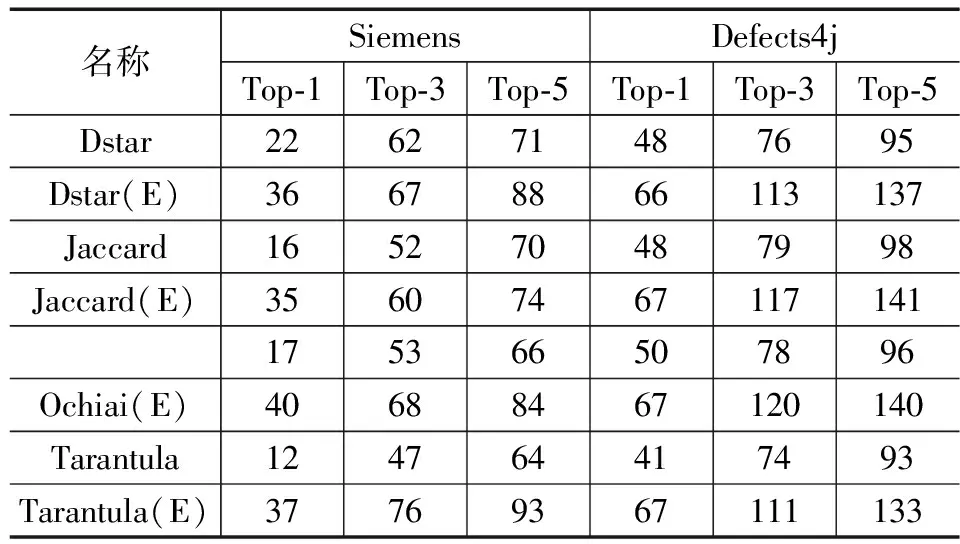
表6 三故障程序中Top-N指数名称
5 结束语
故障定位是困难且代价高的,这就是为什么我们在过去20年中看到了各种故障定位技术被提出。多故障定位正在成为软件测试研究领域中最关键的问题之一。在实践中,我们发现在传统的SBFL中冗余的失败测试用例会给故障定位效率带来消极影响,这阻碍了程序员在调试故障时的效率和生产力。此外,我们注意到使用频谱增强的逻辑与运算可以有效精简失败测试用例的频谱信息,优化可疑度值以提高故障元素的等级。
在本文中,我们提出了基于频谱增强的多故障定位方法。首先,使用频谱增强的方法精简失败的测试用例,再利用SBFL的统计公式对新的频谱信息进行评估,并根据其可疑度对潜在的故障语句进行排序。最后,被SBFL(E)排在前N位的语句根据其新的分数排序。所提出的故障定位方法缓解了SBFL的缺点,提高了故障定位的准确性。通过使用5个开源基准程序的案例研究来评估我们框架的性能。为了显示我们提出的技术的效率,将我们的工作与4个密切相关的故障定位技术,即Dstar、Jaccard、Ochiai和Tarantula进行了比较。实验结果表明,与典型的SBFL定位方法相比,基于频谱增强的方法可以显著减少代码检查的范围,尤其是在高性能范围内(即EXAM5%和Top-1),明显提高了故障定位的性能。
但是在这个领域还有很大的发展空间,也有一些问题需要解决。存在程序中如果失败测试用例过少的问题,而测试用例质量及其数量对结果有很重要的影响;以及频谱增强的思想能否运用到其他故障定位方法当中。后期研究人员还需要努力减少其负面影响,甚至解决这些问题。虽然本实验选择的基准程序在故障定位领域具有代表性,具有说服力,但在今后的工作中,我们将把重点放在更真实的工程程序上。总的来说,随着研究界对SFL研究的极大兴趣,以及最近该领域出版物的一致性,我们希望在未来几年会有更多具体的解决方案来解决多故障问题。
猜你喜欢
空间科学学报(2021年6期)2021-03-09
铁道通信信号(2020年6期)2020-09-21
新世纪智能(语文备考)(2020年4期)2020-07-25
测控技术(2018年7期)2018-12-09
传感器与微系统(2018年7期)2018-08-29
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
语文知识(2014年4期)2014-02-28
电子设计工程(2014年19期)2014-02-27
电子设计工程(2014年18期)2014-02-27
空间控制技术与应用(2010年3期)2010-12-23
