
KMP算法的优化与应用
2023-08-26 04:13马锐彦
电脑知识与技术 2023年20期
关键词:优化
马锐彦

关键词:KMP算法;next数组;nextval数组;优化;算法应用
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)20-0073-03
1 研究背景
文字,一直都是文明的象征。文字让人类可以更高效地记录信息,将前人的生活智慧与发生的事件一代代地积累下来,形成不同的历史文化。将文字录入文档进行保存,就是主要用于记载和储存文字信息的文本。
文本,一直都是计算机领域中最基本的元素,即使是在多媒体技术绚烂夺目的信息时代,文本一直都作为奠基性质的元老角色而存在着[1]。
在对文本的分析中,经常会遇到模式匹配的问题。模式匹配,可以简单地总结为查找与目标字符串相同的模式字符串的子串,即查找与指定字符串相同的字符串。例如,在一个文本文件中查找“KMP算法”这一词语。当文本具备一定的规模后,需要在大量信息中进行多次搜索,所以,算法每次的执行时间和算法优化所获得的效益因积攒往往比表面上看起来要大得多。
互联网迅速发展的信息爆炸时代,全球的信息量以几何级别增长。人们每时每刻都面对大量的文字信息,如新闻信息、娱乐信息、广告信息、科学技术信息等,想要获取有用信息时,令人无从下手。当信息使用不同的语言,存在大量无法直接理解的信息时,会产生巨大的信息压力。当信息真假难辨时,如何从大量的信息中,准确地筛选出所需信息,一直是令人头痛的问题。
目前,人们已经有一种优秀的字符串匹配算法进行模式匹配,提高了文本编辑响应性能。KMP算法,作为著名且较高效的字符串匹配算法,在文本编辑、未知语言翻译、生物序列模式自动识别等方面都有很好的应用,且仍在不断地发展进化,向着更高的效率进发。
本文将从KMP算法本身出发,阐述其基本原理,对KMP算法所涉及的前缀数组的计算方法进行优化,尝试提高算法匹配效率,并对KMP算法在翻译文本方面的应用进行简单介绍。
2 KMP算法
2.1 KMP算法简介
KMP算法是一种改进的字符串匹配算法,1997年由D.E.Knuth,J.H.Morris和V.R.Pratt三人提出,实际上是三人同时发表了基本思想相同的快速串匹配算法(简称KMP算法),KMP就是由他们三人姓氏开头字母组成的。
KMP算法中前缀数组有next数组和nextval数组之分。两者的意义和作用基本相同,通常情况下可以混用。唯一不同的是,next数组在一些情况下有些缺陷,而nextval的创建是为了弥补这个缺陷。
KMP算法的时间复杂度为O(m+n)。其优点在于:每当一趟匹配过程中出现字符不等时,不须回溯目标串,而是由已经得到的“部分匹配”的结果将模式串向右“滑动”尽可能远的一段距离后,继续进行比较[2]。若将KMP算法与BM算法相结合,分情况选取合适的部分,理论上可以产生一种KMP改进算法,一定程度上能提高KMP算法的匹配效率。
KMP算法在很多领域都有应用,如文献检索、词频统计、敏感信息屏蔽等,本文将基于KMP算法,阐述KMP 算法在文本翻译中的应用,得到文本的最匹配翻译。
2.2 KMP算法代码
主要程序如下:
int KMP(char s1[],char s2[],int next[])
{int i=0; int j=0;
int len1=strlen(s1);
int len2=strlen(s2);
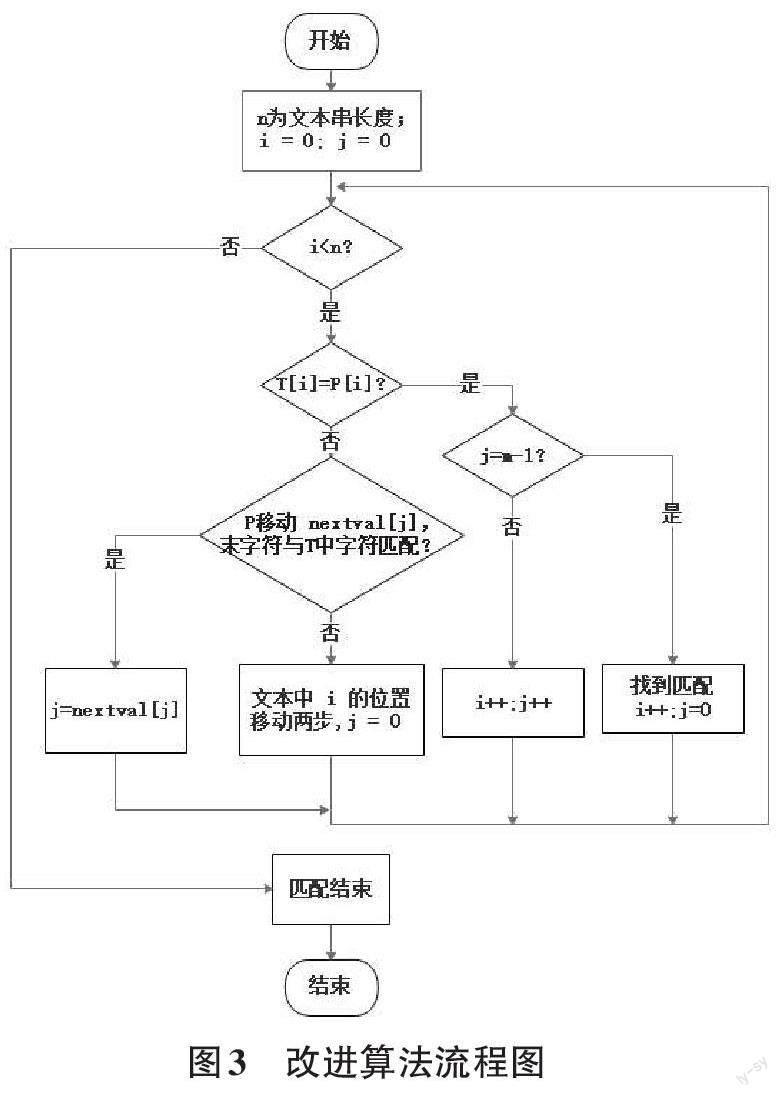
while(i {if(j==-1||s1[i]==s2[j]) {i++;j++; }else j=next[j]; }if(j>=len2) return i-len2+1; else return -1; } 3 KMP前缀数组 3.1 前缀数组 在KMP算法中,前缀数组有next和nextval数组两种。前缀数组的数值应为简单的整数,取值范围应为样本长度,作为KMP算法中的关键,其特点是模式串每一位对应的数组值仅依赖模式串本身,而与主串无关。 next数组求解过程为:依据其定义可知,第一位和第二位分别为0 和1。当判断所求位置的next 值时,需要将前一个位置的字母X和其next值相等的字母Y进行比较。若X与Y相同,则将X的next值加一即为所求。若X与Y不同,则依次向前比较,直到相同为止。其中,若一直到首位都没有相等的内容,则将所求位上的next值置为1。 nextval数组的求解是基于next数组。第一位为0。其余位置求解时需要将本位字符与next数组所对应的字符相比较。如果相等则为nextval数组所对应的next的值,如果不相等则为next数组所对应的值。 3.2 next 和nextval对比 在给定模式串无太多重复字符时,二者无太大差别。当给出的模式串有大部分重复时,next数组会重复多次无实际效果的代码,使用nextval数组可一定程度上减少冗余的步骤。 为体现nextval的优势,可选取较为特殊的字符串进行举例。例如模式串T=‘a a a a d与主串S=‘a a ab a c a a a a d e在匹配时,当i=4,j=4时,S[4]≠T[4],由next[4]=3可知下一步需進行i=4,j=3的比较,又由于S[4]≠T[3],需要依次向前比较,直到j=1。进行了多次数据与步骤完全相同的比较,过程拖沓冗长。而且实际上,很容易看出模式串的前四个字符完全相等,因此主串中的第4个字符无须再和模式串中的前三个字符进行比较,可以将模式串一次性向后滑动4个字符的位置,直接进行i=5,j=1时的字符比较[3],即直接从字符不同的地方开始,减少冗余的步骤。 4 KMP改进算法 4.1 BM算法 BM(Boyer-Moore) 算法,由Boyer和 Moore在1977 年提出的经典算法,是一种局部立体匹配算法,它采用坏字符和好后缀两项规则。 BM算法在进行匹配时,采用从右向左比较的方法,同时,引入两种启发式跳转规则,即坏字符算法和好后缀算法,来决定模板向右移动的步长。 坏字符跳转规则定义如下图1所示,针对的是文本串,其中ch为文本T与模式P比较时出现的不匹配文本字符: 当模式串中没有对应的坏字符,则直接后移到坏字符后面。若模式串中包含坏字符,则移到最后一个坏字符处。 好后缀跳跃规则与其类似但针对的是模式串,当匹配失败时,后移到好后缀位置,向前比较。 在匹配的时候要同时根据坏字符跳跃表和好后缀跳跃表,模式串的右移量为两者的最大值[4]。 4.2 KMP改进算法 KMP改进算法的优化思路可简单理解为:在匹配阶段出现不匹配的字符时,结合BM算法和KMP算法的优点,利用已知部分,令模式串最大程度地后移。 匹配阶段在遇到T、P不匹配时进行两个部分操作。第一部分是计算模式串移动nextval[j]后末字符在文本中的位置;第二部分是比较目标串和模式串在该位置的字符是否匹配,如果两字符不匹配,则文本该位置的字符应进行坏字符跳转,否则按KMP的匹配过程继续比较[5]。 KMP改进算法的流程如下图3所示: 4.3 程序代码 匹配阶段的核心代码如下: while(i {if(j==-1||T[i]==P[j]) {if(j==m-1) {i++;j=0;//找到一个匹配 }else{i++;j++;} }else{ //计算模式串移动 nextval[j]后末字符在文本中的位置 tLast=T[i+pLen-nextval[j]-1]; //判断该位置的文本字符与末字符是否匹配 if(tLast!=pLast) {j=0;//进行坏字符跳转 i=i+bmBc[tLast]-nextval[j]; }else j=nextval[j]; }} 改进后的KMP算法在理论上可以弥补KMP算法从左开始对比的局限性,当左边的判断移动效率不高时,改为从右开始对比的BM算法坏字符跳转,结合两者的优点,减少比较次数。 5 KMP 算法在翻译文本的应用 5.1 翻译基础 1) 分词 在进行翻译之前需要先讨论“分词”的概念。词是语言表达的最小单位,相比于有明确分界符的西方拼音语言,一些亚洲语言的词之间没有明确的分界符,所以做进一步自然语言处理的基础是对句子进行分词。 在最少词数分词原理的基础上,可以运用统计语言模型得到最佳分词效果。即应确保分完词后这个句子出现的概率是最大的。 关于分词的讨论与分析,参照已有知识,需要说明三点。首先,每种方法都有其局限性,虽然利用统计语言模型的数据可以得到最佳效果,但也不是完全准确。尤其在特定情况下,无法消除文本原有的二义性。第二,分词问题属于已解决问题,只要采用基本的统计语言模型,再加上一些已有技巧就能得到很好的分词效果,不值得再花很大精力去研究。第三,分词技术不只针对于亚洲语言,在识别西方拼音语言的手写体时,原本的分界符不够明显,因此原本用来对中文进行分词的技术,也在英语手写体识别中派上了用场。 2) 翻译与KMP算法 当面临不同语言的文本,尤其是未知语言的文本时,在每段文本中重复出现的序列片段通常情况下具备某种固定的含义,可以将其作为分析的依据。找出文本中在误差允许范围内相同的字母序列片段,为该语言的翻译研究提供重要的理论依据。 当分词结束后,收集分词结果形成词汇库,依据词汇库运用KMP相似字符串搜索匹配算法进行对比分析。可以进行高频词的统计,常用短语、词组等语言分析。 5.2 KMP 算法翻译文本的思路 在进行文本翻译,尤其是未知语言文本的翻译时,需要先对机器进行训练得到双语语料库。对于高频词或最佳翻译的分析,可以运用KMP算法。 首先,运用已知的分词技巧得到语料库;其次,运用KMP算法统计文本中出现字符串的次数,并将次数较多的设为高频词;第三,依据出现次数,进行分析,得到该语言初步的常用词或短语;第四,根据语法语义等进行逐词翻译,并通过语言统计模型进行统计,得到最可能的翻译。 5.3 缺点分析 1) 工作量较大,需要大量的文本作为分词基础,当文本不充足时,若直接采用分词会导致分词不准确。需要加入人工进行校对,需要很大的工作量才能得到有效的分词。虽然通过数据驱动的机器学习进行语料库的创建,可减少人工的投入,但一旦涉及远距离调序,译文的生成难度就非常大,往往效果不够好。整个译文感觉往往语句不通顺,同时还会引入漏译问题。 2) KMP算法匹配时有限制,当采用KMP算法对生成的文本数据进行匹配,发现符合条件的字母序列数量非常少时,可以对KMP算法进行改进。例如添加容错范围参数,即找出与随机字符串相似的字符串,进行统计,可有效地提高效率。 在KMP算法的基础上加入变异的概念,以KMP为基础的相似字符串搜索匹配模型,以提高匹配的准确度。当匹配失败但在设定容错范围内时,忽略错误,继续进行比较。这样,算法的准确度会大大提高[6]。 6 结束语 在当今的信息社会中,每天都有大量的信息产生,如何高效地得到有用信息是亟待解决的问题。利用字符串匹配算法可以有效地得到所需信息,利用算法对不同语言的文本信息进行分析,有助于对该语言的理解与翻译。本文通过对著名的字符串匹配算法——KMP算法的分析,挖掘KMP算法本身的优化方式,并简单阐述算法在翻譯文本时的应用思路。 KMP算法的前缀数组有两种选择,在有较多重复字符时选取nextval数组的方式,可以有效地提高算法效率。将KMP算法的前缀数组回溯方式与BM算法的坏字符跳转方式相结合,虽然在时间复杂度上与KMP 算法相同,但是在字符集较大的情况下,KMP改进算法的比较次数和运行时间均低于KMP算法和BM算法。当遇到未知文本时,运用KMP算法的匹配,在语料库的基础上,可以有效地进行分词,并得到高频词和常用语,有利于文本翻译并了解一门新的语言。
猜你喜欢
房地产导刊(2022年5期)2022-06-01能源工程(2022年1期)2022-03-29中学生数理化(高中版.高二数学)(2021年12期)2021-04-26中学生数理化(高中版.高考数学)(2021年12期)2021-03-08今日农业(2020年16期)2020-12-14消费导刊(2018年8期)2018-05-25家庭影院技术(2018年4期)2018-05-09电子制作(2017年20期)2017-04-26北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
