
面向长文本的抽取式摘要生成方法
2023-08-26 04:13全安坤李红莲
电脑知识与技术 2023年20期
全安坤 李红莲


关键词:长文本;抽取式摘要;主题关键词;义原;冗余信息处理
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)20-0008-05
0 引言
在互联网飞速发展的大数据时代,网络数据呈现出爆发式的增长,通过人工对海量文本数据进行重要信息提取的方式成本大、速度慢,已经变得不现实,信息过载的问题亟待解决。随著深度学习技术的发展与其在自然语言处理领域的广泛应用,可以将该技术应用于自动文本摘要中。
自动文本摘要按照输出类型,可以分为抽取式摘要和生成式摘要[1]。生成式摘要利用深度学习算法对文本中的句子或者词组进行语义内容提取,达到理解文本信息的目的,生成质量较高的摘要,但是其在处理长文本时,仍然存在未登录词问题、生成重复问题和长距离依赖问题[2],导致生成的摘要不能准确地表达文章的主要思想,所以生成式摘要方法一般用于短文本摘要生成任务中,而在实际的应用场景中,需要处理的主要为长文本。抽取式摘要适用于长文本摘要生成,该方法是从原文中选择出能够代表文章主题的关键句组合成摘要,因此该方法生成的摘要在语法方面错误率低,但其在保留原文主要内容的同时,也会引入过多的冗余信息。
早在20世纪50年代,Luhn[3]就提出了基于统计规则的抽取式摘要方法,利用词频等统计信息给句子进行排序,根据排序筛选出关键句组合成摘要,该方法为文本摘要技术的发展奠定了基础。Lead3是一种基于经验的抽取式摘要方法,该方法取文章的前三句内容作为摘要,这种方法简单直接,取得了一定的效果,由于没有考虑整篇文章的信息,所以具有一定的局限性。Mihalcea 等人[4]提出了一种基于图的排序方法TextRank,首先将文章分割成多个句子,每个句子作为图中的一个顶点,句子之间相互连接,构建出一个连接图,并利用算法获取句子之间的相似度作为边的权重,然后通过TextRank算法进行迭代运算,得到每个句子的分值,最后抽取得分较高的句子组合成文本摘要,TextRank 的出现使抽取式摘要方法进一步发展,但是该方法在计算句子相似度时,没有考虑语义层面的信息,而且抽取得到的摘要冗余信息比较多。Sutskever 等人[5] 提出序列到序列(Sequence to Se?quence, Seq2Seq)框架,使生成式摘要变得可行,该框架是一种编码器-解码器结构。目前,在生成式摘要方法中,编码器一般都是基于BERT(Bidirectional En?coder Representation from Transformers)模型[6]构建的,该模型拥有强大的文本特征提取能力,能够挖掘到文本的语义信息,可以让生成的摘要质量进一步提升,但是在进行长文本摘要生成任务时,生成式摘要方法仍然存在长距离依赖等问题。
针对以上抽取式摘要方法存在的语义信息缺失和抽取信息冗余问题,本文提出了一种面向长文本的抽取式摘要生成方法,使用WoBERT(Word-basedBERT)模型[7]获取融入义原信息的文本特征,并通过MMR[8](Maximal Marginal Relevance)算法减少冗余信息,有效解决了语义信息缺失和信息冗余的问题,提升了抽取得到的摘要质量。
1 模型构建
本文提出的方法是由句子特征提取、句子打分、摘要抽取三部分组成。第一部分,使用SAT[9](Sememe At?tention over Target Model)模型引入义原得到能够准确表示语义信息的文本特征,然后将该特征作为嵌入层词向量输入WoBERT模型中获取拥有语义信息的高表征的句子文本特征,第二部分首先是利用余弦相似度算法根据获取的高表征文本特征计算句子间相似度,并将该相似度作为TextRank方法中边的权重进行迭代运算,得到每个句子的TextRank分数,然后利用LDA(Latent Dirichlet Allocation)主题模型得到文章的主题关键词,并根据主题关键词在每个句子出现的频次得到句子的主题关键词得分,最后将这两种分值进行加权求和给句子打分。由于TextRank算法依赖句子间的相似度,这就意味着TextRank分值高的句子可能也非常相似,导致抽取出的摘要存在重复的冗余信息,所以在第三部分中引入MMR算法来减少冗余信息,使最终抽取的摘要内容丰富且更符合文章主题。
1.1 句子特征提取
1.1.1 文本预处理
使用分词工具根据WoBERT模型的词表对输入的长文本进行分词,然后再对其去除特殊字符和无意义词,示例如表1所示。
1.1.2 融合义原信息的文本特征表示
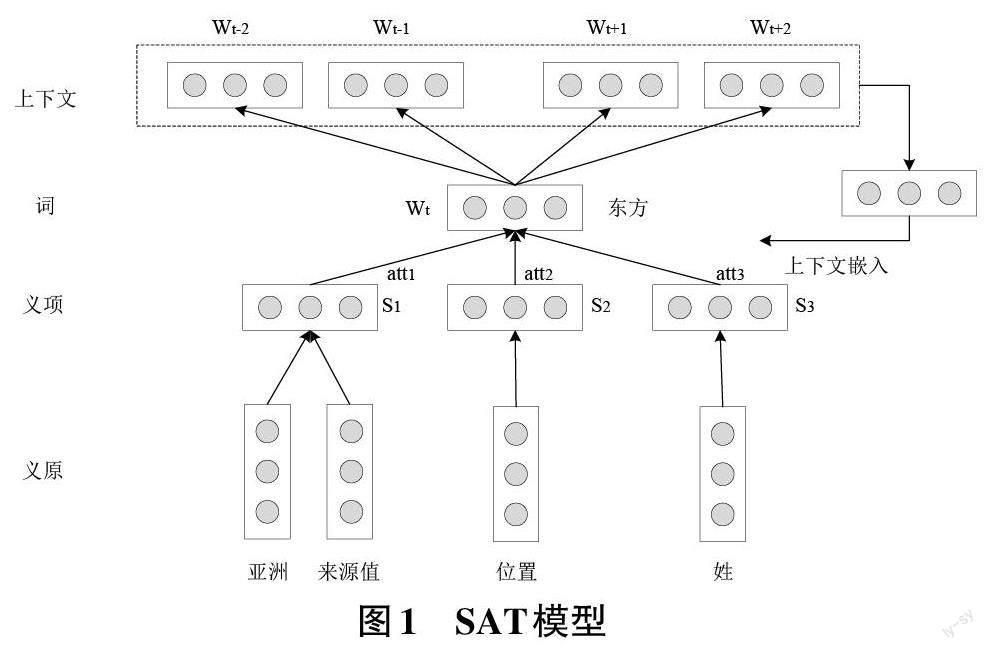
本文使用SAT模型来获取融合义原信息的文本特征表示,以增加文本特征中所包含的语义信息。SAT模型是在Skip-Gram[10]模型上改进所得,融入了HowNet[11]义原信息,相比Skip-Gram模型,SAT模型既考虑了词语的上下文信息又考虑了词语的义原信息,有效提升了文本特征的语义信息,模型如图1所示。
1.1.3 文本高表征特征提取
在获取文本的高表征特征时,本文采用了WoB?ERT模型,该模型是基于BERT模型改进所得,BERT 是谷歌团队基于Transformer[12]的编码器堆叠且以无监督方式在海量标记文本语料上训练得到的语言模型,相比于传统语言模型,它可以同时利用文本序列的正反两个方向的信息,使得到的文本特征能够更加准确地对文本进行表示。WoBERT利用了BERT的这一特点及其训练机制,以词为单位进行训练来获取文本特征,相比于BERT在训练中文文本特征时以字为单位,WoBERT以词为单位可以让输入序列变短,加快训练速度,并且在中文文本中词比字的语义信息更精准。
本文使用融合义原信息的文本特征作为WoBERT 模型嵌入层的单词嵌入向量进一步抽取文本的高表征特征,使获取的文本特征包含了丰富的语义信息。使用WoBERT获取高表征的文本特征框架如图2所示。
2 实验及结果分析
2.1 数据集
目前,针对中文长文本进行自动文本摘要任务的数据集较少,本文使用的是2017年CCF国际自然语言处理与中文计算会议(NLPCC2017) 提供的数据集,该数据集是一个中文的中长文本新闻摘要数据集,共包含50 000 条数据,每条数据由一篇平均长度约1000字的新闻文本与其对应的平均长度约44字的摘要组成。本文按照8:1:1的比例对数据集进行了划分,选取前40 000条数据作为训练集,验证集和测试集各5 000条数据。
2.2 评估指标
ROUGE[14] (Recall-Oriented Understudy for GistingEvaluation)作为评估文本摘要的指标之一,该指标通过将网络模型生成的摘要与参考摘要进行比较计算,得到相匹配的基本单元数目,从而对生成的摘要进行质量评价。ROUGE指标又包含了多个评价指标,本文采用标准的ROUGE-1、ROUGE-2和ROUGE-L 对生成的摘要进行质量评价。具体的计算方法如公式(14) 所示。
2.3 参数设置
实验是在Ubuntu16.04、Tesla V100 的环境下进行,使用的PyTorch版本为1.6.0,Python版本为3.7.4。实验中,在给句子打分时,TextRank分值权重系数α取值为0.8,关键词分值權重系数β 取值为0.2,利用MMR算法控制冗余信息时,调节参数λ 设置为0.7,在使用WoBERT模型获取高表征文本特征时,最大输入词数限制为512,对超过该长度的文本序列进行截取,不足的使用特殊符号进行补齐,批处理大小取值为16,学习率取值为1e-3,嵌入层词向量与隐藏层的维度设置为768。
2.4 实验结果分析
为了验证本文提出方法的有效性,在NLPCC2017 数据集上将该方法与以下三种方法进行了实验对比。
Lead3:该算法认为文章的前三句内容可以代表整篇文章的主题思想,所以抽取前三句文本组合为原文摘要。
TextRank:该算法将文章中的句子作为顶点,句子间相似度作为边的权重来构建图模型,然后进行迭代运算得到每个句子的TextRank值,最终选取值最高的一句或者几句组合为原文摘要。
PGN:指针生成网络,是一种生成式摘要方法,该模型采用一个双向的LSTM作为编码器对输入文本进行编码,并采用一个单向的LSTM作为解码器。利用指针机制避免生成重复。
以上方法的实验对比结果如表2所示。
从表2可以看出,本文提出的方法在NLPCC2017 数据集上的结果,相比于其他摘要生成方法在ROUGE指标上有所提升。Lead3方法抽取文章的前三句作为摘要,没有考虑文章的全局信息,导致部分重要信息丢失,所以效果不是特别好。TextRank算法在进行抽取式摘要任务时依赖于句子之间的相似度,但是该算法在相似度计算时只考虑了句子间共现词的出现次数,并未考虑句子语义、句子位置和关键词特征等信息,且利用该算法抽取的摘要句包含了一定的冗余信息,因此使用该方法获取的摘要质量相比于Lead3方法没有太大的提升。指针生成网络是一种生成式摘要方法,该方法中的编码器和解码器都使用了LSTM,在一定程度缓解了长距离依赖问题,且该方法引入了覆盖机制,避免了生成摘要中存在大量的重复,因此,该方法的ROUGE分数提升较大。本文提出的方法相比于指针生成网络,在ROUGE-1、ROUGE-2和ROUGE-L上分别提升了1.86%、4.35%和2.78%,由于本文利用WoBERT模型提取了融入义原信息的高表征文本特征,且利用余弦相似度算法代替了Tex?tRank算法中原有的相似度计算方法,还考虑了文章的关键词特征,最后使用了MMR算法进行冗余信息处理,使抽取到的摘要更符合文章主题。实验选取了测试集中的样本数据,使用上述四种方法分别得到的摘要实例如表3所示。
为了研究本文方法抽取出的句子数量对摘要质量的影响,选取句子数量为2、3、4,在NLPCC2017数据集上开展了实验,实验结果如表4所示。
从表4中可以看出,当抽取4个句子作为摘要时,摘要质量降低了,说明过多的文本引入了冗余信息,因此本文最终选择抽取三个重要句子组合成文章摘要。
2.5 消融实验
为了验证本文方法的有效性,进行了如下的消融实验,实验结果如表5所示。
实验1:将本文方法中WoBERT模型的嵌入层随机初始化,不使用融入义原信息的词向量。
实验2:在对句子进行TextRank分数计算时,句子的相似度计算方法使用TextRank中原有算法。
实验3:不考虑主题关键词特征对摘要质量的影响,其他结构与本文方法相同。
实验4:不使用MMR算法进行冗余信息处理,直接根据句子打分结果抽取重要句作为摘要。
从表5可以看出,相比实验1,本文融入了义原信息提取高表征文本特征,使得到的特征向量能够更准确地表示对应文本。相比实验2,本文在计算句子的TextRank分值时,利用余弦相似度进行句子相似度计算,避免了原有算法只考虑句子间共现词的影响。相比实验3,本文考虑了文章的主题关键词特征,由于关键词能够反映一篇文章的主题,所以使用关键词特征可以提升摘要质量。相比实验4,本文使用MMR算法进行冗余度控制,避免摘要中包含大量冗余信息,有助于摘要质量的提升。
3 结束语
本文提出了一种面向长文本的抽取式文摘要生成方法,该方法使用WoBERT模型获取融入义原信息的文本特征,同时使用TextRank算法与关键词特征对句子进行打分,并利用MMR算法进行冗余信息处理,使得到的摘要质量有所提升。由于本文使用的数据集来源于新闻领域,所以本文方法的泛化性有待验证,未来将考虑在其他领域数据集上验证方法的有效性。
猜你喜欢
开放教育研究(2020年2期)2020-03-31
疯狂英语·新策略(2019年10期)2019-12-13
制造技术与机床(2019年10期)2019-10-26
当代陕西(2019年10期)2019-06-03
电子制作(2018年18期)2018-11-14
数学小灵通·3-4年级(2017年9期)2017-10-13
现代语文(2016年21期)2016-05-25
小学教学参考(2015年20期)2016-01-15
大连民族大学学报(2015年2期)2015-02-27
语文知识(2014年1期)2014-02-28
