
基于字词特征融合的中文地址匹配算法
2023-08-26 03:08陈剑
电脑知识与技术 2023年19期
陈剑
关键词:地址匹配;深度学习;特征融合
0 引言
地址是描述某种具体空间位置的文本标识,具有重要的地理信息价值。中文地名的匹配和解析是进行中文地址标准化和规范化的基础[1]。但中文地址具有来源多样性和描述差异化的特点,在智慧城市建设和大数据背景条件下,如何提高地址匹配的准确率和有效率是开展后续任务的关键因素。当前对中文地址匹配的研究主要包含以下三块内容[2-4]:一种是基于规则的地址匹配方法,这种方法分为两个阶段,第一阶段是通过比较两个地址字符串的相似程度,进而判断是否为同一地址,此类方法不需要对地址进行解析,没有考虑到地址的语义信息,匹配准确率较低;第二阶段是基于地址要素的地址匹配方法,该方法是根据地址要素特征词进行中文地址的提取,进而实现对地址要素的匹配,但基于地址要素匹配的方法对非标准地址或者复杂地址难以有效解析和提取,适应性较差;另外一种是基于统计和机器学习的方法,该方法是通过大规模语料库获取地名匹配的统计模型,其在考虑地名短语的词法信息之外,结合了在句子上下文信息,可以在一定程度上解决语义歧义问题;最后一种是基于深度学习的方法,通过挖掘数据中潜在的规律特征实现对地址匹配的目的[5-8]。
显然基于规则和统计的方法有一定的局限性,匹配准确度低,依赖标准地址库的构建。对错乱和缺失的地址无法有效处理,缺乏对地址语义的理解,不能有效地提取地址的语义信息。基于神经网络的方法能有效解决语义信息的缺失,和对于地址要素之间的各类差异的效果欠佳问题,但对于这类模型来说,如何有效融合全局与局部范围的上下文信息是一个重要的问题。本文通过分析中文地址结构的特点,提出一种基于字、词特征融合的中文地址匹配方法,该方法不依赖于地址特征库,从地址语义理解的角度出发,实现对中文地址的精准匹配。
1 模型结构
中文地址包含地址要素、词性和句法三大类特征。中文地址的最小语义单元是地址要素,一个中文地址通常是由多个要素构成,每个地址要素属于地名实体中的一个独立部分。地址要素由普通字符与特征字构成,其中特征字更能体现地址要素间的本质区别,并反映出地址的真实语义与位置信息。中文地址要素包含多个层级,将中文地址要素划分多个层级。如省、直辖市为第一层级,省会、地级市为第二层级,区、县为第三层级,街道、乡镇为第四层级,以街道、乡镇为例,可能包含对应地址要素特征集合為:镇、乡、办事处、居委会、社区、街道。因此,特征字是区分地址要素、划分地址层级的标志。在本节中,笔者根据中文地址结构的特点,提出一种基于字、词以及地址特征融合的深度学习网络架构模型。该架构的第一个重要组件负责将字、词标记及其特征转换为向量表示,然后将得到的句子进行融合向量表示获取地址语义信息,最后根据地址语义相似度实现地址的匹配。
1.1 主要模块
本文提出一种基于字词特征融合的中文地址匹配模型,根据中文地址的特点,融合中文地址的字、词属性,建立字词特征融合的中文地址语义匹配模型。具体来说,地址语义匹配模型分为三个阶段:第一阶段为字符嵌入表征,通过融入字符的局部和全局特征,将地址字符信息转变为向量表达。第二阶段为词嵌入表征,通过获取地址文本中词的前向和后向的上下文依赖关系,挖掘基于词的地址语义信息,并且基于地址特征字的关系属性,联合地址要素综合得到地址语义表征。第三阶段为地址的匹配,通过使用地址语义相似度算法,根据设定阈值判断地址是否相似。
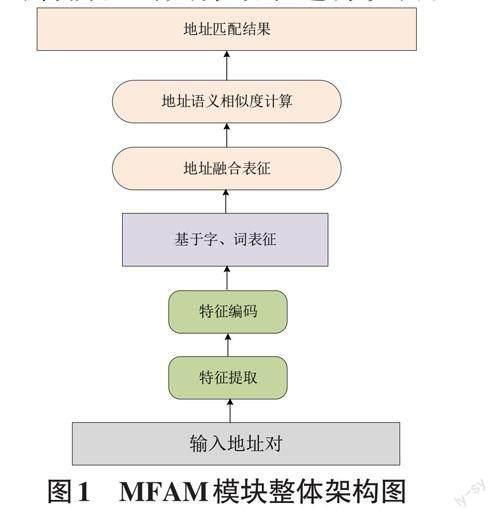
地址语义匹配模型接受地址输入,并分别基于字、词生成地址的语义向量表示,接着通过字词特征融合表征地址语义,最后使用地址语义相似度算法实现地址匹配。模型整体构造如图1所示。MFAM模型整体分为编码模块、语义表征模块、相似度计算模块组成,下文对各阶段的具体细节进行说明。
1.2 地址语义表征
本文采用结合字词特征融合的地址语义表征。具体来说,首先从输入句子中获取基于字符嵌入向量表示,并通过卷积网络实现最大时间离散化,生成的基于字符的标记序列表示被传递Bi-LSTM的输入层;其次,输入序列通过分词和预训练语言模型进行词向量表征,并连接到词嵌入层。
1) 基于字符表征
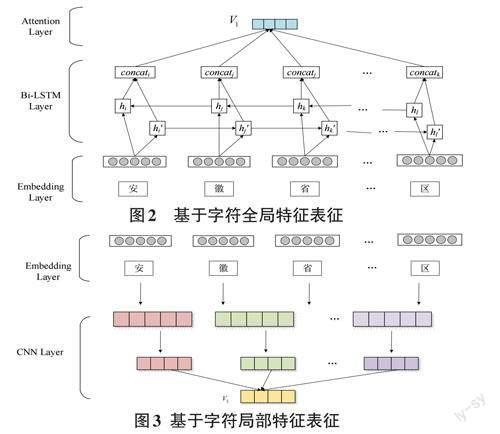
1) 基于字符表征本文将中文地址中的汉字字符特征作为一个特征输入,分别从全局和局部的角度学习语义信息。具体来说,首先使用BiLSTM对输入字符进行双向语义表征学习,然后使用自注意力机制有效获取任意两个字符之间的关系,获取字符全局信息。接着使用卷积神经网络对字符进行特征提取,基于最大池化的方法获取主要信息,获取字符的局部特征。基于字符全局特征表征结构如图2所示。
对于在t 时刻的地址字符wt',首先采用预训练语言模型BERT将其转换为字符嵌入形式wt,BERT模型采用了双向Transformer语义模型,可以充分获取字词的上下文信息,接着将字符的嵌入表征输入BiLSTM 网络,获取字符表征输出为ht = [ ht ; ht ],其中ht 和ht分别表示BiLSTM网络的前向和后向的输出。BiL? STM是一种改进的循环神经网络模型,通过引入门结构可以有选择地保存上下文信息,对于长距离信息进行有效利用,可以有效克服梯度爆炸问题。在BiL? STM网络的输出结果之上,采用自注意力机制捕获任意两个字符之间的关系,相关计算公式如下所示:
其中,ct 是上下文向量,wa,wb,wc 是权重矩阵,χ 是随机初始化的参数向量。
基于字符局部特征表征结构如图3所示。
使用卷积神经网络提取字符的局部特征,并且叠加最大池化操作从学到的特征中保留最主要的特征。对于一个输入字符,采用CNN进行特征提取,相关公式如下所示:
2)基于词表征
本文在使用字符级特征基础之上,采用词级别特征,引入基于字词编码的方法,充分利用词的边界和语义信息。将模型的字符和词的信息编码成联合表示。具体地,该方法为每个字符分配B、M、E和S共4 个标签,其中B表示当前字开头的潜在词集合,M表示中间包含当前词的集合,E表示当前字结尾的潜在词集合,S表示当前字本身。
为每个词定义一个集合,集合包含了该词以及该词对应的B、M、E和S的集合,并使用基于词频计算的权重加权方式求和多个词向量,最后拼接当前字的向量表示及其对应的B、M、E和S的集合的向量表示作为字词信息的联合表示,用作模型的最终输入:
1.3 特征融合
对于已获取的字符级特征,包含全局特征和局部特征,使用字词特征融合的策略进行表示。字词特征融合是一种具有鲁棒性和高效性的策略,能充分利用最显著的特征达到更好的效果。基于字符级的特征融合能将多个相关特征组合成原始输入序列的全局信息表示。在特征融合阶段,采用一种能自适应的连接策略对全局和局部特征进行融合,字词特征融合表示如下:
其中,htA 和htC 是从1.2节中获取的特征,u1 是用来调节这两个特征重要性程度的参数。
最后,将融合的字符级表示ht 和增强的字词编码表示Emb(B,M,E,S) 进行特征的拼接,得到最终输入层的表示。
2 地址语义相似度计算
對待匹配地址和标准地址集中的每一个地址进行相似度计算,获取到与待匹配标准地址的相似度,设定相似度阈值,查找到符合阈值的相似地址。
3 实验
3.1 实验环境
本文使用基于CUDA 10.0的深度学习框架Keras i27.3-.707构00建 In网tel络(R)模 C型ore,(T实M验) C在PU内,存NVDIDDIRA4 G3e2FGo,rc3e.6 GGTHXz 1080 Ti的Ubuntu 18.04 LTS系统上进行。
3.2 数据集
为了评估本文提出模型的稳定性,本文使用标准地址库构建了一个包含约30W条芜湖市地址信息的数据集,将其中的25W条数据作为训练集,剩余5万条数据作为测试集数据,其中训练集和测试集的正负样本比例约为3:1。
3.3 实验设置
本文将汉字字符特征的维度设定为 20维度,用 word2vec模型对每个汉字进行编码向量化,将不足20 维的地址数据编码用0补足为20维编码,然后将地址数据中的每个单词表征为对应词向量,并将其融合作为整个地址数据的向量表示。在超参的设置上,针对地址数据可能的长度,在语义表征层中,设置每一个词的输出维度为768维,表征后输出的地址数据语义表征维度均为100维,完成语义表征后,将获得的两个语义向量分别输入下一层网络结构中。
3.4 实验结果与分析
在评价指标上,为了对预测结果进行有效的评价,本文选取相应的参考指标去衡量最终结果,包括准确率(accuracy) 、精确率(precious) 、召回率(recall) 与F1得分(F1-score) 。其中准确率越高,证明模型对于地址相似度计算结果越精确;而F1得分越高,证明模型整体性能越好。
为了验证本文提出的MFAM模型的有效性,将本文提出的模型与经典模型进行对比实验,本文设置以下几组对比模型实验:第一组使用BiLSTM模型;第二组使用BiLSTM模型,并添加注意力机制进行实验;第三组结合CNN网络获取局部上下文信息,使用BiLSTM-CNN模型进行实验;最后一组即为本文所提出的MFAM模型,在BiLSTM 中引入注意力机制,并结合CNN网络进行共同训练。
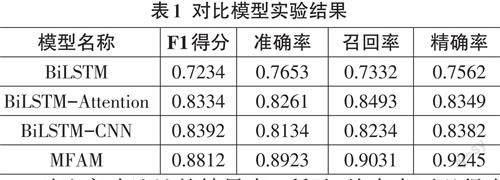
对比实验地址的结果表1所示,从表中可以得出本文提出的MFAM模型在准确率、召回率以及F1值上均取得了最好的结果,表明本文方法在中文地址匹配方面的有效性。从表1中可以看出,第二组采用结合注意力机制的地址匹配方法,使得模型的整体效果都得到了提升,表明添加注意力机制,可以从全局的角度学得有效特征,有助于模型的训练。而从第三组实验结果中,发现使用CNN获取局部有效特征也可对模型的性能进行提升。同时,对比第四组、第二组和第三组实验结果,可以看出本文提出的模型在F1得分上相比其他模型性能提升了5~7百分点,这个结果证明了在仅考虑注意力机制或者CNN获得的局部信息的情况下,模型无法有效地捕捉地址中的部分关键信息,导致模型的整体性能下降。同时,F1得分证明,MFAM模型的精度提升并非受到数据集中正负样例的比例影响,而是模型的整体学习能力相较于其他消融模型确实获得了增强。
4 结论
本文在分析现有中文地址数据特征的基础上,研究了中文地址要素并分析了可能存在的组合模式,针对传统的中文地址匹配方法存在的不足,提出了一种基于字词特征融合的中文地址语义匹配模型。在自主构建的数据集上,本文提出的方法相对于传统的方法提高了5~7 个百分点,验证了MFAM 方法的有效性,为中文地址的匹配提供了新的方法和思路。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
少儿美术(快乐历史地理)(2018年7期)2018-11-16
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
大连民族大学学报(2015年2期)2015-02-27
